神经网络权值存储方法、读取方法及相关设备
文献发布时间:2023-06-19 12:07:15
技术领域
本申请涉及计算机技术领域,尤其涉及一种神经网络权值存储方法、读取方法及相关设备。
背景技术
随着AI(Artificial Intelligence,人工智能)芯片的计算能力越来越强,神经网络模型越来越深,AI处理器在进行训练或推理时,需要读取大量的权值数据用于计算。为了降低芯片的功耗和成本,相关人员在神经网络权值存储方面做了深度研究,目前主流的存储方案有高速DDR(Double DataRate,双倍速率同步动态随机存储器)结合Cache缓存,或者采用超大容量的SRAM (Static Random-Access Memory,静态随机存取存储器),进一步还有采用乒乓缓存的方案。然而,上述方案仍然存在种种弊端,比如传输带宽大、存储占用空间大或者难以使芯片的吞吐量达到较优状态,导致芯片的功耗和成本居高不下。
发明内容
针对上述问题,本申请提供了一种神经网络权值存储方法、读取方法及相关设备,有利于使芯片的吞吐量达到较优状态,从而降低芯片的功耗和成本。
为实现上述目的,本申请实施例第一方面提供了一种神经网络权值存储方法,应用于直接存储器访问控制器,该方法包括:
直接存储器访问控制器在系统初始化时将神经网络首层的权值固化在静态随机存取存储器的静态内存中;
直接存储器访问控制器获取静态随机存取存储器的循环缓存中所述神经网络各层的权值累积长度;
直接存储器访问控制器根据权值累积长度将各层中的目标层的权值固化在静态内存中;
直接存储器访问控制器执行下一次获取权值累积长度的操作,重复执行多次获取权值累积长度的操作,直至各层中不存在目标层;
直接存储器访问控制器根据各层中不存在目标层时对应的权值累积长度设定循环缓存的大小。
结合第一方面,在一种可能的实施方式中,直接存储器访问控制器获取静态随机存取存储器的循环缓存中神经网络各层的权值累积长度,包括:
直接存储器访问控制器在系统未运行的情况下,对循环缓存中各层的累积权值进行曲线拟合,得到权值累积长度曲线;
直接存储器访问控制器根据权值累积长度曲线得到各层的权值累积长度;
或者,
直接存储器访问控制器在系统运行的情况下,实时监测循环缓存的缓存空间的大小,得到权值累积长度。
结合第一方面,在一种可能的实施方式中,直接存储器访问控制器对循环缓存中各层的累积权值进行曲线拟合,得到权值累积长度曲线,包括:
直接存储器访问控制器根据处理器的计算能力、双倍速率同步动态随机存储器的传输带宽、循环缓存中各层的权值长度以及预设参数对循环缓存中各层的累积权值进行曲线拟合,得到权值累积长度曲线。
结合第一方面,在一种可能的实施方式中,权值累积长度曲线的公式如下:
其中,D(N)表示循环缓存中第n层的权值累积长度,t
结合第一方面,在一种可能的实施方式中,若第n层的权值固化在静态内存中,则s
结合第一方面,在一种可能的实施方式中,在获取静态随机存取存储器的循环缓存中神经网络各层的权值累积长度之前,该方法进一步包括:
直接存储器访问控制器从双倍速率同步动态随机存储器中读取各层的权值,并向循环缓存中写入读取的权值。
结合第一方面,在一种可能的实施方式中,在向循环缓存中写入读取的权值之前,该方法进一步包括:
直接存储器访问控制器确定循环缓存的缓存空间未满。
结合第一方面,在一种可能的实施方式中,该方法进一步包括:
直接存储器访问控制器在确定循环缓存的缓存空间已满的情况下,暂停向循环缓存中写入权值。
结合第一方面,在一种可能的实施方式中,静态随机存取存储器被划分为静态内存和循环缓存,循环缓存采用环形缓冲区或环形队列实现。
结合第一方面,在一种可能的实施方式中,目标层为权值累积长度为0 的神经网络层,权值累积长度为0表示循环缓存出现下溢。
本申请实施例第二方面提供了一种神经网络权值读取方法,应用于处理器,该方法包括:
处理器在系统运行时从静态随机存取存储器的静态内存或循环缓存中读取神经网络各层的权值;神经网络首层和目标层的权值被固化在静态内存中,神经网络除首层和目标层以外的神经网络层被缓存在循环缓存中;目标层是根据循环缓存中神经网络各层的权值累积长度确定的。
结合第二方面,在一种可能的实施方式中,处理器在系统运行时从静态随机存取存储器的静态内存或循环缓存中读取神经网络各层的权值,包括:
处理器在当前待读取的神经网络层为首层或目标层的情况下,从静态内存中读取首层或目标层的权值;
或者,
处理器在当前待读取的神经网络层为首层和目标层以外的神经网络层的情况下,确定循环缓存已经预取完成当前待读取的神经网络层的权值;
处理器在循环缓存已经预取完成当前待读取的神经网络层的权值的情况下,从循环缓存中读取当前待读取的神经网络层的权值。
结合第二方面,在一种可能的实施方式中,在从循环缓存中读取当前待读取的神经网络层的权值之后,该方法进一步包括:
处理器对从循环缓存中读取到的神经网络权值进行处理;
处理器在该读取到的神经网络权值处理完成的情况下,将该已读取到的神经网络权值从循环缓存中释放。
结合第二方面,在一种可能的实施方式中,该方法进一步包括:
处理器在循环缓存未预取完成当前待读取的神经网络层的权值的情况下,等待循环缓存预取完成当前待读取的神经网络层的权值。
结合第二方面,在一种可能的实施方式中,权值累积长度在系统未运行的情况下是根据权值累积长度曲线得到的,权值累积长度曲线由直接存储器访问控制器对循环缓存中各层的累积权值进行曲线拟合得到;权值累积长度在系统运行的情况下由直接存储器访问控制器对循环缓存的缓存空间的大小进行实时监测得到。
结合第二方面,在一种可能的实施方式中,权值累积长度曲线进一步是根据处理器的计算能力、双倍速率同步动态随机存储器的传输带宽、循环缓存中各层的权值长度以及预设参数对循环缓存中各层的累积权值进行曲线拟合得到的。
结合第二方面,在一种可能的实施方式中,权值累积长度曲线的公式如下:
其中,D(N)表示循环缓存中第n层的所述权值累积长度,t
结合第二方面,在一种可能的实施方式中,若第n层的权值固化在静态内存中,则s
结合第二方面,在一种可能的实施方式中,静态随机存取存储器被划分为静态内存和循环缓存,循环缓存采用环形缓冲区或环形队列实现。
结合第二方面,在一种可能的实施方式中,目标层为权值累积长度为0 的神经网络层,权值累积长度为0表示循环缓存出现下溢。
本申请实施例第三方面提供了一种神经网络权值存储装置,该装置包括:
存储模块,其被配置为在系统初始化时将神经网络首层的权值固化在静态随机存取存储器的静态内存中;
处理模块,其被配置为获取静态随机存取存储器的循环缓存中神经网络各层的权值累积长度;
存储模块,其进一步被配置为根据权值累积长度将各层中的目标层的权值固化在静态内存中;
处理模块,其进一步被配置为执行下一次获取权值累积长度的操作,重复执行多次获取权值累积长度的操作,直至各层中不存在目标层;
处理模块,其进一步被配置为根据各层中不存在目标层时对应的权值累积长度设定循环缓存的大小。
本申请实施例第四方面提供了一种神经网络权值读取装置,该装置包括:
读取模块,其被配置为在系统运行时从静态随机存取存储器的静态内存或循环缓存中读取神经网络各层的权值;神经网络首层和目标层的权值被固化在静态内存中,神经网络除首层和目标层以外的神经网络层被缓存在循环缓存中;目标层是根据循环缓存中神经网络各层的权值累积长度确定的。
本申请实施例第五方面提供了一种电子设备,该电子设备包括输入设备和输出设备,进一步包括处理器,适于实现一条或多条指令;以及,计算机可读存储介质,所述计算机可读存储介质存储有一条或多条指令,所述一条或多条指令适于由所述处理器加载并执行如上述第一方面或第二方面所述方法中步骤。
本申请实施例第六方面提供了一种计算机可读存储介质,所述计算机可读存储介质存储有一条或多条指令,所述一条或多条指令适于由处理器加载并执行如上述第一方面或第二方面所述方法中步骤。
本申请实施例第七方面提供了一种计算机程序产品,其中,该计算机程序产品包括存储了计算机程序的非瞬时性计算机可读存储介质,该计算机程序可操作来使计算机执行如上述第一方面或第二方面所述方法中步骤。
本申请的上述方案至少包括以下有益效果:
本申请实施例中,通过将静态随机存取存储器划分为静态内存和循环缓存,根据权值累积长度将神经网络的目标层的权值固化在静态随机存取存储器的静态内存中,将神经网络首层和目标层以外的神经网络层的权值写入静态随机存取存储器的循环缓存中,有利于解决循环缓存下溢的问题,另外,在神经网络各层中不存在目标层的情况下,根据获取到的对应权值累积长度来设定循环缓存的缓存空间大小,有利于解决循环缓存上溢的问题,从而能够以较小的SRAM空间和较低的DDR传输带宽达到芯片较优的吞吐量,进而降低芯片的功耗和成本。
附图说明
为了更清楚地说明本申请实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本申请的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本申请实施例提供的一种现有神经网络权值存储和读取方案的示意图;
图2为本申请实施例提供的另一种现有神经网络权值存储和读取方案的示意图;
图3为本申请实施例提供的另一种现有神经网络权值存储和读取方案的示意图;
图4为本申请实施例提供的一种神经网络权值存储和读取架构的示意图;
图5为本申请实施例提供的一种神经网络权值存储方法的流程示意图;
图6A为本申请实施例提供的一种权值累积长度曲线的示意图;
图6B为本申请实施例提供的另一种权值累积长度曲线的示意图;
图6C为本申请实施例提供的另一种权值累积长度曲线的示意图;
图7为本申请实施例提供的一种神经网络权值读取方法的流程示意图;
图8为本申请实施例提供的一种神经网络权值存储装置的结构示意图;
图9为本申请实施例提供的一种神经网络权值读取装置的结构示意图;
图10为本申请实施例提供的一种电子设备的结构示意图。
具体实施方式
为了使本技术领域的人员更好地理解本申请方案,下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本申请一部分的实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都应当属于本申请保护的范围。
本申请说明书、权利要求书和附图中出现的术语“包括”和“具有”以及它们任何变形,意图在于覆盖不排他的包含。例如包含了一系列步骤或单元的过程、方法、系统、产品或设备没有限定于已列出的步骤或单元,而是可选地进一步包括没有列出的步骤或单元,或可选地进一步包括对于这些过程、方法、产品或设备固有的其它步骤或单元。此外,术语“第一”、“第二”和“第三”等是用于区别不同的对象,而并非用于描述特定的顺序。
在本申请中提及“实施例”意味着,结合实施例描述的特定特征、结构或特性可以包含在本申请的至少一个实施例中。在说明书中的各个位置出现该短语并不一定均是指相同的实施例,也不是与其它实施例互斥的独立的或备选的实施例。本领域技术人员显式地和隐式地理解的是,本申请所描述的实施例可以与其它实施例相结合。
需要说明的是,本申请所提到的神经网络可以是神经网络(Neural Network,NN)、深度神经网络(Deep Neural Network,DNN)、卷积神经网络(convolutional neuronnetwork,CNN)、循环神经网络(recurrent neural networks,RNN)等,应当理解的,神经网络通常包括输入层、隐含层和输出层,层与层之间的神经元通常是全连接的,比如说,第i层的任意一个神经元一定与第i+1层的任意一个神经元相连。神经网络一般应用于图像处理、语音处理、自然语言处理等场景,其各层通常都有对应的权值,比如,第二层的第3个神经元到第三层的第2个神经元的权值定义为
请参见图1,在神经网络权值存储方面,现有技术提出了高速DDR存储结合L2Cache(二级缓存)的方案,神经网络各层的权值存储在DDR中,处理器在计算时,通过高速DDR接口把待处理的权值加载到Cache中,但是,在处理器计算能力越强的情况下,该方案所需的DDR传输带宽也就越大,不利于降低芯片的功耗和成本。
另外,请参见图2,采用超大容量的SRAM进行神经网络权值存储也是目前主流的存储方式之一,神经网络各层的权值被固化在SRAM中,神经网络模型越大,所需的SRAM空间越大,比如采用ResNet50(Residual net50,残差网络50)网络,该方案存储神经网络权值所需的空间为25M(Megabytes,兆字节),仍无法有效降低芯片成本。
另外,请参见图3,乒乓缓存作为目前主流的存储方式之一,DMA(Direct MemoryAccess,直接存储器访问)控制器从DDR中读取神经网络权值并向乒缓存或乓缓存中写入权值,比如当处理器读取乒缓存中的权值时,DMA控制器预取下一层权值并写入乓缓存,该方案由于处理器与DMA控制器需要保持严格的同步关系,在任意一层,处理器的计算时间都需要小于DMA控制器的预取时间,否则无法使芯片的吞吐量达到较优状态。
本申请实施例提供一种神经网络权值存储和读取方法,以解决现有技术中难以使芯片的吞吐量达到较优状态,进一步降低芯片的功耗和成本的问题。该神经网络权值存储和读取方法可基于图4所示的神经网络权值存储和读取架构实施,如图4所示,该架构包括处理器、小容量的SRAM、DDR和DMA 控制器,其中,SRAM被划分静态内存和循环缓存两块存储区,静态内存用于固化神经网络中的出现下溢(underflow)的层,循环缓存用于预取和存储神经网络中未出现下溢的层。DMA控制器用于从DDR中读取神经网络权值并向循环缓存中写入读取的权值,处理器用于从静态内存或循环缓存中读取权值以进行计算,比如GEMM(General Matrix Multiplication,通用矩阵乘)运算等。
应当理解的,DMA控制器向循环缓存中写入读取的权值,处理器从循环缓存中读取权值,若DMA控制器写的速度大于处理器读的速度,权值在循环缓存中逐渐累积,当权值累积长度达到循环缓存的大小时,则会出现缓存上溢(overflow),此时DMA控制器会停止权值的搬运,无法达到最优的DDR 吞吐量;若DMA控制器写的速度小于处理器读的速度,权值在循环缓存中逐渐减少,当权值在循环缓存中的累积长度减少到0时,则会出现缓存下溢。
本申请将出现缓存下溢的神经网络层的取值固化到静态内存中,有利于解决循环缓存下溢的问题,当神经网络各层中不存在出现下溢的层时,将获取到的对应权值累积长度的最大值设定为循环缓存的最大存储空间,有利于解决循环缓存上溢的问题,从而能够以较小的SRAM空间和较低的DDR传输带宽达到芯片较优的吞吐量,进而降低芯片的功耗和成本。
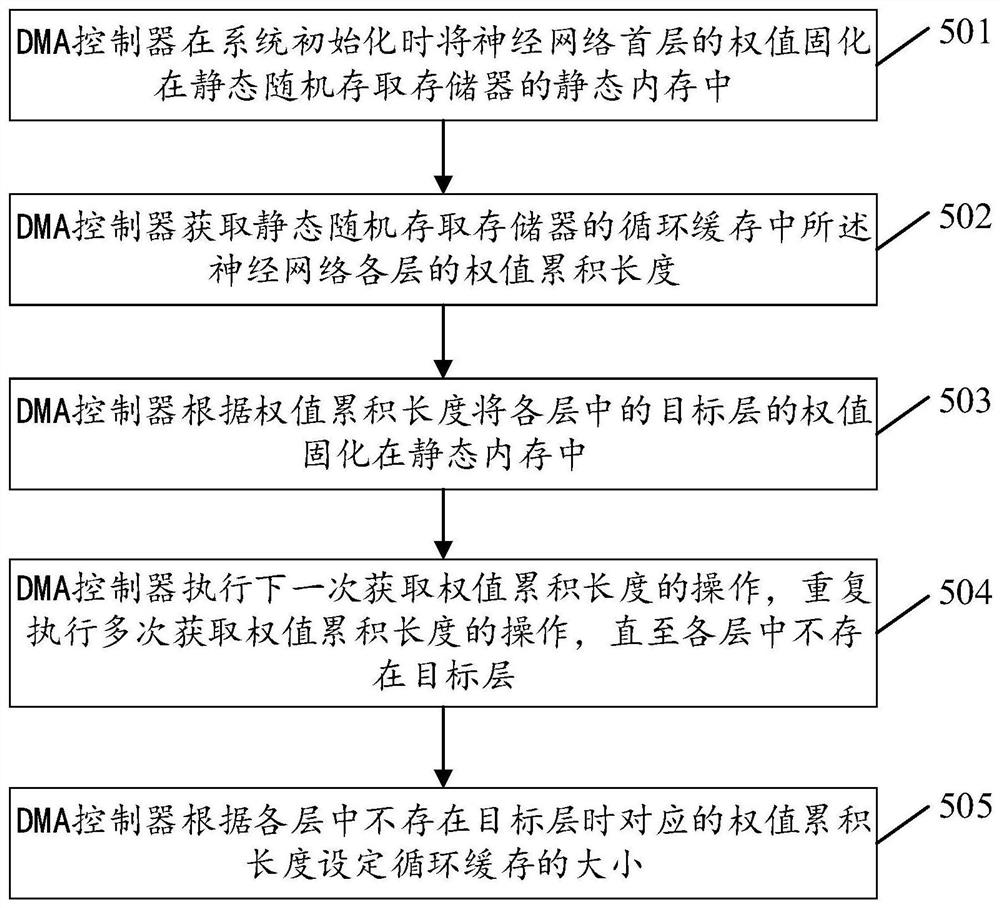
请参见图5,图5为本申请实施例提供的一种神经网络权值存储方法的流程示意图,该神经网络权值存储方法可基于图1所示的架构实施,应用于DMA 控制器,如图5所示,包括步骤501-505:
501:DMA控制器在系统初始化时将神经网络首层的权值固化在静态随机存取存储器的静态内存中;
本申请实施例中,静态随机存取存储器被划分为静态内存和循环缓存,其中,循环缓存采用环形缓冲区(circular buffer)或环形队列(circular queue) 实现,其工作模式如同蓄水池。
502:DMA控制器获取静态随机存取存储器的循环缓存中所述神经网络各层的权值累积长度;
503:DMA控制器根据权值累积长度将各层中的目标层的权值固化在静态内存中;
本申请实施例中,DMA控制器从DDR中读取神经网络各层的权值,并向循环缓存中写入读取的权值,进一步的,DMA控制器在向循环缓存中写入读取的权值之前,确定循环缓存的缓存空间是否已满,在循环缓存的缓存空间已满的情况下,DMA控制器暂停向循环缓存中写入权值,直到循环缓存中有缓存空间可用;在循环缓存的缓存空间未满的情况下,DMA控制器执行向循环缓存中写入权值的操作。
DMA控制器向循环缓存中写入权值,处理器从循环缓存中读取权值, DMA控制器的写操作和处理器的读操作没有严格的同步关系,只要循环缓存的缓存空间未满,DMA控制器可一直写入权值。同时,DMA控制器会获取循环缓存中写入各层后的权值累积长度,以确定哪些层的权值需要固化在静态内存中。示例性的,DMA控制器获取循环缓存中神经网络各层的权值累积长度,包括:
DMA控制器在系统未运行的情况下,对循环缓存中各层的累积权值进行曲线拟合,得到权值累积长度曲线;
DMA控制器根据权值累积长度曲线得到各层的权值累积长度;
或者,
DMA控制器在系统运行的情况下,实时监测所述循环缓存的缓存空间的大小,得到所述权值累积长度。
具体的,系统运行是指神经网络的训练或推理,根据系统是否运行,本申请采用不同的方法获取各层的权值累积长度,针对系统未运行的情况,即仍在初始化时,DMA控制器根据处理器的计算能力、DDR的传输带宽、循环缓存中各层的权值长度以及预设参数对循环缓存中各层的累积权值进行曲线拟合,得到权值累积长度曲线。其中,权值累积长度曲线的公式如下:
其中,D(N)表示循环缓存中第n层的权值累积长度,t
以ResNet50网络为例,假设AI处理器的计算能力为24TOPS,DDR的传输带宽为50G(Gbps),在将ResNet50网络首层的权值固化在静态内存中后,DMA控制器根据处理器的计算能力、DDR的传输带宽、循环缓存中各层的权值长度以及预设参数画出循环缓存中的权值累积长度曲线,可如图6A 所示,图6A中横坐标表示ResNet50网络的神经网络层index(即层标识索引),纵坐标表示循环缓存中的权值累积计长度(即权值累积长度),其单位为KB(Kbytes),图6A中,权值累积长度曲线的斜率为正时,表示写入该层后,循环缓存中的累积权值在增加;权值累积长度曲线的斜率为负时,表示写入该层后,循环缓存中的累积权值在减少;权值累积长度为0时,表示该层神经网络层出现下溢。
通过图6A中所示的权值累积长度曲线,确定出最早出现下溢的目标层,即最早出现权值累积长度为0的神经网络层,然后将该目标层的权值固化在静态内存中,比如ResNet50网络最早出现权值累积长度为0的神经网络层为第64卷积层,则将该第64卷积层的权值固化在静态内存中。该实施方式中,将权值累积长度为0的神经网络层的权值固化在静态内存中,有利于解决循环缓存中下溢的问题。
504:DMA控制器执行下一次获取权值累积长度的操作,重复执行多次获取权值累积长度的操作,直至各层中不存在目标层;
本申请实施例中,在第一次获取循环缓存中的权值累积长度,且将最早出现下溢的目标层的权值固化在静态内存后,处理器需要从静态内存中读取该目标层的权值,那么,从循环缓存读取权值的时间就会发生变化,在这种场景下,DMA控制器再次执行获取循环缓存中的权值累积长度的操作,并重新拟合出权值累积长度曲线,如ResNet50网络可再次拟合出图6B所示的权值累积长度曲线,类似的,通过图6B中所示的权值累积长度曲线,再次确定出最早出现下溢的目标层,然后将其权值固化在静态内存中,比如ResNet50 网络的第68卷积层。重复执行多次获取循环缓存中权值累积长度、确定最早出现下溢的目标层、将该目标层的权值固化在静态内存的操作,直至神经网络各层中不存在目标层,即如图6C中所示的权值累积长度曲线中不存在权值累积长度为0的神经网络层。
另外,针对系统运行的情况,DMA控制器通过实时监测循环缓存的缓存空间的大小得到各层的权值累积长度,比如,监测到循环缓存剩余的缓存空间持续变大,说明权值累积长度在持续减少,直到处理器处理完某层后,循环缓存中权值累积长度减少到0,则确定该层的下一层将出现下溢,此时系统停止运行,DMA控制器将该下一层的权值固化在静态内存中。
505:DMA控制器根据各层中不存在目标层时对应的权值累积长度设定循环缓存的大小。
本申请实施例中,经过多次将出现下溢的目标层的权值固化在静态内存中,神经网络各层中已经没有下溢的情况,根据图6C所示的权值累积长度曲线,将此时对应的权值累积长度的最大值(曲线顶点)设定为循环缓存存储空间的大小,比如设定循环缓存的大小为6760KB,有利于解决循环缓存上溢的问题。在图6A-图6C所示的实施方式中,神经网络首层、第64层和第68 层的权值被固化在静态内存中,静态内存的大小为4617KB,循环缓存的大小为6760KB,总计消耗SRAM内存为11377KB,有利于节省SRAM存储空间。
可以看出,本申请实施例中,通过将静态随机存取存储器划分为静态内存和循环缓存,根据权值累积长度将神经网络的目标层的权值固化在静态随机存取存储器的静态内存中,将神经网络首层和目标层以外的神经网络层的权值写入静态随机存取存储器的循环缓存中,有利于解决循环缓存下溢的问题,另外,在神经网络各层中不存在目标层的情况下,根据获取到的对应权值累积长度来设定循环缓存的缓存空间大小,有利于解决循环缓存上溢的问题,从而能够以较小的SRAM空间和较低的DDR传输带宽达到芯片较优的吞吐量,进而降低芯片的功耗和成本。
与上述神经网络权值存储方法对应的,本申请实施例还提供一种神经网络权值读取方法,请参见图7,图7为本申请实施例提供的一种神经网络权值读取方法的流程示意图,该神经网络权值读取方法同样可基于图1所示的架构实施,应用于处理器,如图7所示,包括步骤701:
701:处理器在系统运行时从静态随机存取存储器的静态内存或循环缓存中读取神经网络各层的权值;神经网络首层和目标层的权值被固化在静态内存中,神经网络除首层和目标层以外的神经网络层被缓存在循环缓存中;目标层是根据循环缓存中神经网络各层的权值累积长度确定的。
本申请实施例中,系统运行是指神经网络的训练或推理,静态随机存取存储器被划分为静态内存和循环缓存,其中,循环缓存采用环形缓冲区 (circular buffer)或环形队列(circular queue)实现。在系统初始化时,DMA 控制器将神经网络首层的权值固化在静态内存中,DMA控制器从DDR中读取神经网络各层的权值,并向循环缓存中写入读取的权值,DMA控制器向循环缓存中写入权值与处理器从循环缓存中读取权值没有严格的同步关系,只要循环缓存的缓存空间未满,DMA控制器可一直写入权值。同时,DMA控制器会获取循环缓存中写入各层后的权值累积长度,以根据权值累积长度确定出需要将权值固化在静态内存中的目标层,并将其权值固化在静态内存中,而首层和目标层以外的神经网络层被缓存在循环缓存中。其中,目标层为权值累积长度为0的神经网络层,权值累积长度为0表示循环缓存出现下溢。
示例性,在系统未运行的情况下,权值累积长度是DMA控制器根据权值累积长度曲线得到的,权值累积长度曲线是DMA控制器通过对循环缓存中各层的累积权值进行曲线拟合得到的。具体的,DMA控制器根据处理器的计算能力、DDR的传输带宽、循环缓存中各层的权值长度以及预设参数对循环缓存中各层的累积权值进行曲线拟合。在系统运行的情况下,权值累积长度是 DMA控制器对循环缓存的缓存空间的大小进行实时监测得到的,进一步的,权值累积长度曲线的公式如下:
其中,D(N)表示循环缓存中第n层的所述权值累积长度,t
进一步的,DMA控制器重复执行多次获取循环缓存中权值累积长度、确定最早出现下溢的目标层、将该目标层的权值固化在静态内存的操作,直至神经网络各层中不存在目标层,从而有利于解决循环缓存下溢的问题。
进一步的,DMA控制器在神经网络各层中不存在目标层时,将对应权值累积长度曲线中的最大值设定为循环缓存的大小,从而有利于解决循环缓存上溢的问题。
示例性的,处理器在系统运行时从静态随机存取存储器的静态内存或循环缓存中读取神经网络各层的权值,包括:
处理器在当前待读取的神经网络层为首层或目标层的情况下,从静态内存中读取首层或目标层的权值;
或者,
处理器在当前待读取的神经网络层为首层和目标层以外的神经网络层的情况下,确定循环缓存已经预取完成当前待读取的神经网络层的权值;
处理器在循环缓存已经预取完成当前待读取的神经网络层的权值的情况下,从循环缓存中读取当前待读取的神经网络层的权值。
示例性的,在从循环缓存中读取当前待读取的神经网络层的权值之后,该方法进一步包括:
处理器对从循环缓存中读取到的神经网络权值进行处理;
处理器在该读取到的神经网络权值处理完成的情况下,将该已读取到的神经网络权值从循环缓存中释放。
比如,在处理器从循环缓存中读取ResNet50网络的第45层的权值后,使用第45层的权值进行计算,在计算完成的情况下,将第45层的权值从循环缓存中释放,以节省循环缓存的缓存空间。
示例性,该方法进一步包括:
处理器在循环缓存未预取完成当前待读取的神经网络层的权值的情况下,等待循环缓存预取完成当前待读取的神经网络层的权值。
可以看出,本申请实施例中,处理器可以从静态随机存取存储器的静态内存或循环缓存中读取神经网络权值,权值的读取操作与写入操作没有严格的同步关系,有利于提高神经网络权值的读取和处理效率。
基于上述神经网络权值存储方法实施例的描述,本申请还提供一种神经网络权值存储装置,所述神经网络权值存储装置可以是运行于终端中的一个计算机程序(包括程序代码)。该神经网络权值存储装置可以执行图5所示的方法。请参见图8,该装置包括:
存储模块801,其被配置为在系统初始化时将神经网络首层的权值固化在静态随机存取存储器的静态内存中;
处理模块802,其被配置为获取静态随机存取存储器的循环缓存中神经网络各层的权值累积长度;
存储模块801,其进一步被配置为根据权值累积长度将各层中的目标层的权值固化在静态内存中;
处理模块802,其进一步被配置为执行下一次获取权值累积长度的操作,重复执行多次获取权值累积长度的操作,直至各层中不存在目标层;
处理模块802,其进一步被配置为根据各层中不存在目标层时对应的权值累积长度设定循环缓存的大小。
在一种可能的实施方式中,获取静态随机存取存储器的循环缓存中神经网络各层的权值累积长度方面,处理模块802具体用于:
在系统未运行的情况下,对循环缓存中各层的累积权值进行曲线拟合,得到权值累积长度曲线;
根据权值累积长度曲线得到各层的权值累积长度;
或者,
在系统运行的情况下,实时监测所述循环缓存的缓存空间的大小,得到权值累积长度。
在一种可能的实施方式中,在对循环缓存中各层的累积权值进行曲线拟合,得到权值累积长度曲线方面,处理模块802具体用于:
根据处理器的计算能力、双倍速率同步动态随机存储器的传输带宽、循环缓存中各层的权值长度以及预设参数对循环缓存中各层的累积权值进行曲线拟合,得到权值累积长度曲线。
在一种可能的实施方式中,权值累积长度曲线的公式如下:
其中,D(N)表示循环缓存中第n层的权值累积长度,t
在一种可能的实施方式中,若第n层的权值固化在静态内存中,则s
在一种可能的实施方式中,处理模块802进一步用于:
从双倍速率同步动态随机存储器中读取各层的权值,并向循环缓存中写入读取的权值。
在一种可能的实施方式中,处理模块802进一步用于:
确定循环缓存的缓存空间未满。
在一种可能的实施方式中,处理模块802进一步用于:
在确定循环缓存的缓存空间已满的情况下,暂停向循环缓存中写入权值。
在一种可能的实施方式中,静态随机存取存储器被划分为静态内存和循环缓存,循环缓存采用环形缓冲区或环形队列实现。
在一种可能的实施方式中,目标层为权值累积长度为0的神经网络层,权值累积长度为0表示循环缓存出现下溢。
根据本申请的一个实施例,图8所示的神经网络权值存储装置的各个模块可以分别或全部合并为一个或若干个另外的单元来构成,或者其中的某个 (些)模块还可以再拆分为功能上更小的多个单元来构成,这可以实现同样的操作,而不影响本发明的实施例的技术效果的实现。上述单元是基于逻辑功能划分的,在实际应用中,一个单元的功能也可以由多个单元来实现,或者多个单元的功能由一个单元实现。在本发明的其它实施例中,神经网络权值存储装置也可以包括其它单元,在实际应用中,这些功能也可以由其它单元协助实现,并且可以由多个单元协作实现。
根据本申请的另一个实施例,可以通过在包括中央处理单元(CPU)、随机存取存储介质(RAM)、只读存储介质(ROM)等处理元件和存储元件的例如计算机的通用计算设备上运行能够执行如图5中所示的相应方法所涉及的各步骤的计算机程序(包括程序代码),来构造如图8中所示的神经网络权值存储装置设备,以及来实现本申请实施例的神经网络权值存储方法。所述计算机程序可以记载于例如计算机可读记录介质上,并通过计算机可读记录介质装载于上述计算设备中,并在其中运行。
基于上述神经网络权值读取方法实施例的描述,本申请还提供一种神经网络权值读取装置,所述神经网络权值读取装置可以是运行于终端中的一个计算机程序(包括程序代码)。该神经网络权值读取装置可以执行图7所示的方法。请参见图9,该装置包括:
读取模块901,其被配置为在系统运行时从静态随机存取存储器的静态内存或循环缓存中读取神经网络各层的权值;神经网络首层和目标层的权值被固化在静态内存中,神经网络除首层和目标层以外的神经网络层被缓存在循环缓存中;目标层是根据循环缓存中神经网络各层的权值累积长度确定的。
在一种可能的实施方式中,在从静态随机存取存储器的静态内存或循环缓存中读取神经网络各层的权值方面,读取模块901具体用于:
在当前待读取的神经网络层为首层或目标层的情况下,从静态内存中读取首层或目标层的权值;
或者,
在当前待读取的神经网络层为首层和目标层以外的神经网络层的情况下,确定循环缓存已经预取完成当前待读取的神经网络层的权值;
在循环缓存已经预取完成当前待读取的神经网络层的权值的情况下,从循环缓存中读取当前待读取的神经网络层的权值。
在一种可能的实施方式中,读取模块901进一步用于:
对从循环缓存中读取到的神经网络权值进行处理;
在该读取到的神经网络权值处理完成的情况下,将该已读取到的神经网络权值从循环缓存中释放。
在一种可能的实施方式中,读取模块901进一步用于:
在循环缓存未预取完成当前待读取的神经网络层的权值的情况下,等待循环缓存预取完成当前待读取的神经网络层的权值。
在一种可能的实施方式中,权值累积长度在系统未运行的情况下是根据权值累积长度曲线得到的,权值累积长度曲线由直接存储器访问控制器对循环缓存中各层的累积权值进行曲线拟合得到;权值累积长度在系统运行的情况下由直接存储器访问控制器对循环缓存的缓存空间的大小进行实时监测得到。
在一种可能的实施方式中,权值累积长度曲线进一步是根据处理器的计算能力、双倍速率同步动态随机存储器的传输带宽、循环缓存中各层的权值长度以及预设参数对循环缓存中各层的累积权值进行曲线拟合得到的。
在一种可能的实施方式中,权值累积长度曲线的公式如下:
其中,D(N)表示循环缓存中第n层的所述权值累积长度,t
在一种可能的实施方式中,若第n层的权值固化在静态内存中,则s
在一种可能的实施方式中,静态随机存取存储器被划分为静态内存和循环缓存,循环缓存采用环形缓冲区或环形队列实现。
在一种可能的实施方式中,目标层为权值累积长度为0的神经网络层,权值累积长度为0表示循环缓存出现下溢。
根据本申请的一个实施例,图9所示的神经网络权值读取装置的各个模块可以分别或全部合并为一个或若干个另外的单元来构成,或者其中的某个 (些)模块还可以再拆分为功能上更小的多个单元来构成,这可以实现同样的操作,而不影响本发明的实施例的技术效果的实现。上述单元是基于逻辑功能划分的,在实际应用中,一个单元的功能也可以由多个单元来实现,或者多个单元的功能由一个单元实现。在本发明的其它实施例中,神经网络权值读取装置也可以包括其它单元,在实际应用中,这些功能也可以由其它单元协助实现,并且可以由多个单元协作实现。
根据本申请的另一个实施例,可以通过在包括中央处理单元(CPU)、随机存取存储介质(RAM)、只读存储介质(ROM)等处理元件和存储元件的例如计算机的通用计算设备上运行能够执行如图7中所示的相应方法所涉及的各步骤的计算机程序(包括程序代码),来构造如图9中所示的神经网络权值读取装置设备,以及来实现本申请实施例的神经网络权值读取方法。所述计算机程序可以记载于例如计算机可读记录介质上,并通过计算机可读记录介质装载于上述计算设备中,并在其中运行。
基于上述方法实施例和装置实施例的描述,请参见图10,图10为本申请实施例提供的一种电子设备的结构示意图,如图10所示,该电子设备至少包括处理器1001、输入设备1002、输出设备1003以及计算机可读存储介质1004。其中,电子设备内的处理器1001、输入设备1002、输出设备1003以及计算机可读存储介质1004可通过总线或其他方式连接。
计算机可读存储介质1004可以存储在电子设备的存储器中,所述计算机可读存储介质1004用于存储计算机程序,所述计算机程序包括程序指令,所述处理器1001用于执行所述计算机可读存储介质1004存储的程序指令。处理器1001(或称CPU(CentralProcessing Unit,中央处理器))是电子设备的计算核心以及控制核心,其适于实现一条或多条指令,具体适于加载并执行一条或多条指令从而实现相应方法流程或相应功能。
在一个实施例中,本申请实施例提供的电子设备的处理器1001可以用于进行一系列神经网络权值存储处理:
在系统初始化时将神经网络首层的权值固化在静态随机存取存储器的静态内存中;
获取静态随机存取存储器的循环缓存中所述神经网络各层的权值累积长度;
根据权值累积长度将各层中的目标层的权值固化在静态内存中;
执行下一次获取权值累积长度的操作,重复执行多次获取权值累积长度的操作,直至各层中不存在目标层;
根据各层中不存在目标层时对应的权值累积长度设定循环缓存的大小。
再一个实施例中,处理器1001执行获取静态随机存取存储器的循环缓存中神经网络各层的权值累积长度,包括:
在系统未运行的情况下,对循环缓存中各层的累积权值进行曲线拟合,得到权值累积长度曲线;
根据权值累积长度曲线得到各层的权值累积长度;
或者,
在系统运行的情况下,实时监测循环缓存的缓存空间的大小,得到权值累积长度。
再一个实施例中,处理器1001执行对循环缓存中各层的累积权值进行曲线拟合,得到权值累积长度曲线,包括:
根据处理器的计算能力、双倍速率同步动态随机存储器的传输带宽、循环缓存中各层的权值长度以及预设参数对循环缓存中各层的累积权值进行曲线拟合,得到权值累积长度曲线。
再一个实施例中,权值累积长度曲线的公式如下:
其中,D(N)表示循环缓存中第n层的权值累积长度,t
再一个实施例中,若第n层的权值固化在静态内存中,则s
再一个实施例中,在获取静态随机存取存储器的循环缓存中神经网络各层的权值累积长度之前,处理器1001进一步用于:
从双倍速率同步动态随机存储器中读取各层的权值,并向循环缓存中写入读取的权值。
再一个实施例中,在向循环缓存中写入读取的权值之前,处理器1001进一步用于:
确定循环缓存的缓存空间未满。
再一个实施例中,处理器1001进一步用于:
在确定循环缓存的缓存空间已满的情况下,暂停向循环缓存中写入权值。
再一个实施例中,静态随机存取存储器被划分为静态内存和循环缓存,循环缓存采用环形缓冲区或环形队列实现。
再一个实施例中,目标层为权值累积长度为0的神经网络层,权值累积长度为0表示循环缓存出现下溢。
在另一个实施例中,本申请实施例提供的电子设备的处理器1001可以用于进行一系列神经网络权值读取处理:
在系统运行时从静态随机存取存储器的静态内存或循环缓存中读取神经网络各层的权值;神经网络首层和目标层的权值被固化在静态内存中,神经网络除首层和目标层以外的神经网络层被缓存在循环缓存中;目标层是根据循环缓存中神经网络各层的权值累积长度确定的。
再一个实施例中,处理器1001执行在系统运行时从静态随机存取存储器的静态内存或循环缓存中读取神经网络各层的权值,包括:
在当前待读取的神经网络层为首层或目标层的情况下,从静态内存中读取首层或目标层的权值;
或者,
在当前待读取的神经网络层为首层和目标层以外的神经网络层的情况下,确定循环缓存已经预取完成当前待读取的神经网络层的权值;
在循环缓存已经预取完成当前待读取的神经网络层的权值的情况下,从循环缓存中读取当前待读取的神经网络层的权值。
再一个实施例中,在从循环缓存中读取当前待读取的神经网络层的权值之后,处理器1001进一步用于:
对从循环缓存中读取到的神经网络权值进行处理;
在该读取到的神经网络权值处理完成的情况下,将该已读取到的神经网络权值从循环缓存中释放。
再一个实施例中,处理器1001进一步用于:
在循环缓存未预取完成当前待读取的神经网络层的权值的情况下,等待循环缓存预取完成当前待读取的神经网络层的权值。
再一个实施例中,权值累积长度在系统未运行的情况下是根据权值累积长度曲线得到的,权值累积长度曲线由直接存储器访问控制器对循环缓存中各层的累积权值进行曲线拟合得到;权值累积长度在系统运行的情况下由直接存储器访问控制器对循环缓存的缓存空间的大小进行实时监测得到。
再一个实施例中,权值累积长度曲线进一步是根据处理器的计算能力、双倍速率同步动态随机存储器的传输带宽、循环缓存中各层的权值长度以及预设参数对循环缓存中各层的累积权值进行曲线拟合得到的。
再一个实施例中,权值累积长度曲线的公式如下:
其中,D(N)表示循环缓存中第n层的所述权值累积长度,t
再一个实施例中,若第n层的权值固化在静态内存中,则s
再一个实施例中,静态随机存取存储器被划分为静态内存和循环缓存,循环缓存采用环形缓冲区或环形队列实现。
再一个实施例中,目标层为权值累积长度为0的神经网络层,权值累积长度为0表示循环缓存出现下溢。
示例性的,上述电子设备可以是电脑、笔记本电脑、平板电脑、服务器等设备。电子设备可包括但不仅限于处理器1001、输入设备1002、输出设备 1003以及计算机可读存储介质1004。还可以包括内存、电源、应用客户端模块等。输入设备1002可以是键盘、触摸屏、射频接收器等,输出设备1003 可以是扬声器、显示器、射频发送器等。本领域技术人员可以理解,所述示意图仅仅是电子设备的示例,并不构成对电子设备的限定,可以包括比图示更多或更少的部件,或者组合某些部件,或者不同的部件。
需要说明的是,由于电子设备的处理器1001执行计算机程序时实现上述的神经网络权值存储方法或神经网络权值读取方法中的步骤,因此上述神经网络权值存储方法或神经网络权值读取方法的实施例均适用于该电子设备,且均能达到相同或相似的有益效果。
本申请实施例还提供了一种计算机可读存储介质(Memory),所述计算机可读存储介质是信息处理设备或信息发送设备或信息接收设备中的记忆设备,用于存放程序和数据。可以理解的是,此处的计算机可读存储介质既可以包括终端中的内置存储介质,当然也可以包括终端所支持的扩展存储介质。计算机可读存储介质提供存储空间,该存储空间存储了终端的操作系统。并且,在该存储空间中还存放了适于被处理器加载并执行的一条或多条的指令,这些指令可以是一个或一个以上的计算机程序(包括程序代码)。需要说明的是,此处的计算机可读存储介质可以是高速RAM存储器,也可以是非不稳定的存储器(non-volatile memory),例如至少一个磁盘存储器;可选的,还可以是至少一个位于远离前述处理器的计算机可读存储介质。在一个实施例中,可由处理器加载并执行计算机可读存储介质中存放的一条或多条指令,以实现上述有关神经网络权值存储方法或神经网络权值读取方法中的相应步骤。
本申请实施例还提供了一种计算机程序产品,其中,该计算机程序产品包括存储了计算机程序的非瞬时性计算机可读存储介质,该计算机程序可操作来使计算机执行如上述神经网络权值存储方法或神经网络权值读取方法中步骤。该计算机程序产品可以为一个软件安装包。
以上对本申请实施例进行了详细介绍,本文中应用了具体个例对本申请的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本申请的方法及其核心思想;同时,对于本领域的一般技术人员,依据本申请的思想,在具体实施方式及应用范围上均会有改变之处,综上所述,本说明书内容不应理解为对本申请的限制。
- 神经网络权值存储方法、读取方法及相关设备
- 神经网络计算装置和数据读取、数据存储方法及相关设备