基于新型血液标志物cfDNA的肝癌预测模型及其构建方法
文献发布时间:2023-06-19 18:34:06
技术领域
本发明涉及生物学研究及生物信息学研究技术领域,具体涉及基于新型血液标志物cfDNA的肝癌预测模型及其构建方法。
背景技术
肝癌是我国乃至世界范围内最常见的实体恶性肿瘤之一,目前针对肝癌的治疗手段主要包括手术切除、肝移植、射频消融、经肝动脉化疗栓塞术等,肝癌患者的生存期延长,生存质量得到一定改善。然而,由于肝癌起病及进展隐匿,发现时往往己失去手术机会,且复发及转移率仍居高不下,总体预后仍较差。因此,迫切需要寻找新的诊断和治疗方法,尤其是早期诊断,来提高患者的生存质量。
目前,传统的影像学手段与血液标志物对于微小残余病灶的检测能力十分有限,难以解决临床上继续面对的预后评估问题。近年来得到高速发展的液态活检技术能够对患者的肿瘤负荷进行动态评估,具有较高的灵敏性,为肿瘤术后微小残余病灶的检测提供了新的工具与策略。
既往针对恶性肿瘤的诊断主要是依靠病理的形态学观察和临床的影像学检测,即依据肿瘤的形态学来诊断,而随着各项生物技术的进步,如基因检测、蛋白质组学等很多技术手段应用于癌症的辅助诊断,使癌症的诊断更加趋向于功能学诊断。
血常规、血生化、肿瘤标志物中包含了大量的人体健康信息,许多项具体指标都是一些常用的敏感指标,对机体内许多病理改变都有敏感反映,患者在病因不明时可以做血液检查对其进行辅助诊断。游离DNA(Circulating free DNA or Cell free DNA,cfDNA),循环游离DNA或者细胞游离DNA,是释放到血浆中的降解的DNA片段。cfDNA存在于人体的各种体液中,随组织损伤、癌症和炎症反应等发生浓度变化。目前大量的研究证实,血液检查指标、肿瘤标志物、cfDNA与恶性肿瘤都存在关联性。如果能够联合多种检验结果综合分析,提高恶性肿瘤筛查的准确度,对于恶性肿瘤的筛查具有很高的实际应用价值。
发明内容
本发明的目的在于提供基于新型血液标志物cfDNA的肝癌预测模型及其构建方法,液体活检肝癌早筛产品的敏感性和特异性均超过90%,具有很高的临床价值,以解决上述背景技术中提出的问题。
为实现上述目的,本发明提供如下技术方案:
基于新型血液标志物cfDNA的肝癌预测模型,该模型基于miRNA在肝癌组织中下调表达,miRNA是一类短小(长度约为22个核苷酸)的非编码RNA分子,通过破坏mRNA的稳定结构或通过抑制翻译调节基因的表达而发挥作用,所述miRNA模型的检测指标为下列miRNA中的一种或几种:miRNA-10b-5p、miRNA-10b-3p、miRNA-224-5p、miRNA-183-5p、miRNA-182-5p;
所述miRNA在肝癌样本中高表达,所述肝癌样本为外周血、组织(用于获取血常规的指标以及深化指标),血浆cfDNA测序可提供大小片单分布的DNA片段和末端序列占比与肝癌相关联的诊断模型;
所述肝癌相关联的诊断模型包括内参基因检测试剂、甲基化数据、检测组合标志物中各个基因甲基化水平的引物。
其中,所述组合标志物的检测试剂可包括用于检测所述组合标志物中各个基因甲基化水平的引物和/或探针。
其中,所述内参基因检测试剂的试剂盒中包括:septin9基因甲基化检测位点对应的引物序列;septin9基因检测位点探针序列;内参基因检测位点对应引物序列;内参基因检测位点探针序列,Septin9基因检测位点为septin9基因CpG岛3的一个位点;内参基因为Actin。
其中,所述血常规指标包括白细胞计数(WBC),红细胞计数(RBC),血红蛋白(Hb),红细胞比容(Hct),平均红细胞体积(MCV),平均红细胞血红蛋白含量(MCH),平均红细胞血红蛋白浓度(MCHC),血小板计数(PLT),淋巴细胞百分比(Lymph%),单核细胞百分比(Mono%),中性粒细胞百分比(Neut%),嗜酸性粒细胞百分比(Eos%),嗜碱性粒细胞百分比(Baso%),淋巴细胞计数(Lymph),单核细胞计数(Mono),中性粒细胞计数(Neut),嗜酸性粒细胞计数(Eos),嗜碱性粒细胞计数(Baso),红细胞体积分布宽度CV(RDW-CV),红细胞体积分布宽度SD(RDW-SD),血小板分布宽度(PDW),平均血小板体积(MPV),大血小板百分比(P-LCR%),血小板比容(PCT)。
其中,所述血生化指标包括谷草转氨酶(AST),谷丙转氨酶(ALT),谷草转氨酶/谷丙转氨酶(S/L),谷氨酰转肽酶(GGT),碱性磷酸酶(ALP),总蛋白(TP),白蛋白(ALB),球蛋白(GLO),白蛋白/球蛋白(A/G),总胆红素(TBIL),直接胆红素(DBIL),间接胆红素(IBIL),总胆固醇(CHOL),高密度脂蛋白(HDL-C),低密度脂蛋白(LDL/C),甘油三酯(TG),葡萄糖(GLU),尿素氮(BUN),肌酐(CREA),尿素氮/肌酐(BUN/CREA),尿酸(URIC)。
其中,所述组合标志物中各个基因甲基化水平的引物包括dNTPs、缓冲液、热启动DNA聚合酶(Hotstart Taq)、ddH
其中,对用于所述cfDNA甲基化水平的参考基因组数据和原始的测序样本数据进行对比处理,调用YFPGA-808用于实现比对器将预处理后的测序样本数据和参考基因组进行比对。
本发明还提供一种基于新型血液标志物cfDNA的肝癌预测模型的构建方法,包括如下步骤:
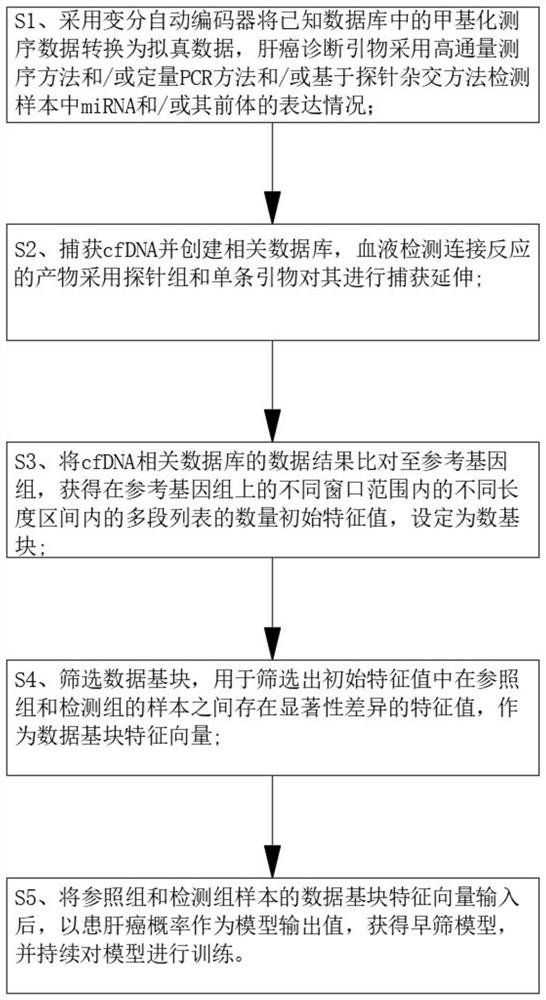
S1、采用变分自动编码器将已知数据库中的甲基化测序数据转换为拟真数据,肝癌诊断引物采用高通量测序方法和/或定量PCR方法和/或基于探针杂交方法检测样本中miRNA和/或其前体的表达情况;
S2、捕获cfDNA并创建相关数据库,血液检测连接反应的产物采用探针组和单条引物对其进行捕获延伸;
S3、将cfDNA相关数据库的数据结果比对至参考基因组,获得在参考基因组上的不同窗口范围内的不同长度区间内的多段列表的数量初始特征值,设定为数据基块;
S4、筛选数据基块,用于筛选出初始特征值中在参照组和检测组的样本之间存在显著性差异的特征值,作为数据基块特征向量;
S5、将参照组和检测组样本的数据基块特征向量输入后,以患肝癌概率作为模型输出值,获得早筛模型,并持续对模型进行训练。
其中,所述步骤S2中的探针组包括16个探针,分别是核苷酸序列如SIQ ID No.5所示的探针
综上所述,由于采用了上述技术,本发明的有益效果是:
本发明中,基于cfDNA血浆测序提供了大小片单分布的DNA片段和末端序列占比与肝癌关系的诊断模型,该模型不仅能够诊断早期肝癌还能够区分肝硬化,具有无创检测,通量低,检测特异性和敏感性高的优势,能够联合多种检验结果综合分析,提高恶性肿瘤筛查的准确度;
本发明中,通过对从甲基化引物中获取的样本数据进行预处理,再对预处理结果进行对照,最后根据检验结果从比对处理结果中筛选出肿瘤甲基化标记物,完成了基于DNA甲基化芯片数据筛选肿瘤甲基化标志物,提高了肿瘤甲基化标记物筛选的可靠性与有效性,筛选方法简便可行,可广泛应用于医学计算机应用领域。
附图说明
图1为本发明基于新型血液标志物cfDNA的肝癌预测模型的创建流程图。
具体实施方式
为使本发明实施方式的目的、技术方案和优点更加清楚,下面将结合本发明实施方式中的附图,对本发明实施方式中的技术方案进行清楚、完整地描述,显然,所描述的实施方式是本发明一部分实施方式,而不是全部的实施方式。基于本发明中的实施方式,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施方式,都属于本发明保护的范围。因此,以下对在附图中提供的本发明的实施方式的详细描述并非旨在限制要求保护的本发明的范围,而是仅仅表示本发明的选定实施方式。基于本发明中的实施方式,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施方式,都属于本发明保护的范围。
在本发明的描述中,需要理解的是,指示方位或位置关系的术语为基于附图所示的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的设备或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。
本发明提供了基于新型血液标志物cfDNA的肝癌预测模型,该模型基于miRNA在肝癌组织中下调表达,miRNA是一类短小(长度约为22个核苷酸)的非编码RNA分子,通过破坏mRNA的稳定结构或通过抑制翻译调节基因的表达而发挥作用,所述miRNA模型的检测指标为下列miRNA中的一种或几种:miRNA-10b-5p、miRNA-10b-3p、miRNA-224-5p、miRNA-183-5p、miRNA-182-5p;
所述miRNA在肝癌样本中高表达,所述肝癌样本为外周血、组织(用于获取血常规的指标以及深化指标),血浆cfDNA测序可提供大小片单分布的DNA片段和末端序列占比与肝癌相关联的诊断模型;
所述肝癌相关联的诊断模型包括内参基因检测试剂、甲基化数据、检测组合标志物中各个基因甲基化水平的引物。
具体的,所述组合标志物的检测试剂可包括用于检测所述组合标志物中各个基因甲基化水平的引物和/或探针。
具体的,所述内参基因检测试剂的试剂盒中包括:septin9基因甲基化检测位点对应的引物序列;septin9基因检测位点探针序列;内参基因检测位点对应引物序列;内参基因检测位点探针序列,Septin9基因检测位点为septin9基因CpG岛3的一个位点;内参基因为Actin。
具体的,所述血常规指标包括白细胞计数(WBC),红细胞计数(RBC),血红蛋白(Hb),红细胞比容(Hct),平均红细胞体积(MCV),平均红细胞血红蛋白含量(MCH),平均红细胞血红蛋白浓度(MCHC),血小板计数(PLT),淋巴细胞百分比(Lymph%),单核细胞百分比(Mono%),中性粒细胞百分比(Neut%),嗜酸性粒细胞百分比(Eos%),嗜碱性粒细胞百分比(Baso%),淋巴细胞计数(Lymph),单核细胞计数(Mono),中性粒细胞计数(Neut),嗜酸性粒细胞计数(Eos),嗜碱性粒细胞计数(Baso),红细胞体积分布宽度CV(RDW-CV),红细胞体积分布宽度SD(RDW-SD),血小板分布宽度(PDW),平均血小板体积(MPV),大血小板百分比(P-LCR%),血小板比容(PCT)。
具体的,所述血生化指标包括谷草转氨酶(AST),谷丙转氨酶(ALT),谷草转氨酶/谷丙转氨酶(S/L),谷氨酰转肽酶(GGT),碱性磷酸酶(ALP),总蛋白(TP),白蛋白(ALB),球蛋白(GLO),白蛋白/球蛋白(A/G),总胆红素(TBIL),直接胆红素(DBIL),间接胆红素(IBIL),总胆固醇(CHOL),高密度脂蛋白(HDL-C),低密度脂蛋白(LDL/C),甘油三酯(TG),葡萄糖(GLU),尿素氮(BUN),肌酐(CREA),尿素氮/肌酐(BUN/CREA),尿酸(URIC)。
具体的,所述组合标志物中各个基因甲基化水平的引物包括dNTPs、缓冲液、热启动DNA聚合酶(Hotstart Taq)、ddH
具体的,对用于所述cfDNA甲基化水平的参考基因组数据和原始的测序样本数据进行对比处理,调用YFPGA-808用于实现比对器将预处理后的测序样本数据和参考基因组进行比对。
基于cfDNA血浆测序提供了大小片单分布的DNA片段和末端序列占比与肝癌关系的诊断模型,该模型不仅能够诊断早期肝癌还能够区分肝硬化,具有无创检测,通量低,检测特异性和敏感性高的优势。
本发明还提供一种基于新型血液标志物cfDNA的肝癌预测模型的构建方法,包括如下步骤:
S1、采用变分自动编码器将已知数据库中的甲基化测序数据转换为拟真数据,肝癌诊断引物采用高通量测序方法和/或定量PCR方法和/或基于探针杂交方法检测样本中miRNA和/或其前体的表达情况;
S2、捕获cfDNA并创建相关数据库,血液检测连接反应的产物采用探针组和单条引物对其进行捕获延伸;
S3、将cfDNA相关数据库的数据结果比对至参考基因组,获得在参考基因组上的不同窗口范围内的不同长度区间内的多段列表的数量初始特征值,设定为数据基块;
S4、筛选数据基块,用于筛选出初始特征值中在参照组和检测组的样本之间存在显著性差异的特征值,作为数据基块特征向量;
S5、将参照组和检测组样本的数据基块特征向量输入后,以患肝癌概率作为模型输出值,获得早筛模型,并持续对模型进行训练。
具体的,所述步骤S2中的探针组包括16个探针,分别是核苷酸序列如SIQ ID No.5所示的探针
综上所述,本发明通过对从甲基化引物中获取的样本数据进行预处理,再对预处理结果进行对照,最后根据检验结果从比对处理结果中筛选出肿瘤甲基化标记物,完成了基于DNA甲基化芯片数据筛选肿瘤甲基化标志物,提高了肿瘤甲基化标记物筛选的可靠性与有效性,筛选方法简便可行,可广泛应用于医学计算机应用领域。
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,根据本发明的技术方案及其发明构思加以等同替换或改变,都应涵盖在本发明的保护范围之内。
需要说明的是,在本文中,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。
- 帕金森病认知障碍标志物及基于该标志物的疾病预测模型的构建方法与应用
- 基于细胞死亡相关基因的肝癌患者生存预测模型构建方法