用于选择表达异源多肽的细胞克隆的方法
文献发布时间:2024-04-18 19:58:21
本发明属于细胞系生成领域。更准确地,本文报道了一种用于使用基于ELISA的数据选择表达大量正确组装且发挥功能的异源多肽的细胞克隆的方法。
背景技术
近年来,重组多肽(诸如抗体和基于抗体的分子)在疾病治疗领域已经得到了广泛应用。
特别是关于抗体,在包含天然存在的IgG形式的第一波基于抗体的药物之后,下一代形式现在越来越多地看到分子,该分子对经典IgG抗体形式有大量的修改和衍生。连续或同时靶向两种或甚至更多种抗原的期望带来了越来越复杂的抗体形式。随着形式复杂性的增加,可能的抗体相关副产物(诸如例如链错配)的数量随之增加。
治疗性抗体进入市场的一个步骤是开发稳定的生产细胞系,该生产细胞系的特征为高表达以及重组蛋白的高质量,即低抗体相关副产物含量。一般来说,由于在细胞系开发期间(特别是在单克隆水平上)缺乏高通量测定来以低体积评定产物质量和功能,在复杂形式抗体空间中寻找新颖药物分子陷入瓶颈。
因此,为了从转染后获得的大量细胞克隆中鉴定出能够产生正确组装的复杂抗体的那些稀有细胞克隆,需要具有低所需样品体积的高通量方法。这种方法将会提供将筛选转移到早期阶段的能力,由此可以表征并从而评估更多的单克隆细胞克隆。这增加了鉴定可以产生高质量级别复杂形式抗体的特殊细胞克隆的可能性,从而增加了技术成功的可能性并且同时最小化了商品的成本。
Sawyer,W.S.等人(Proc.Natl.Acad.Sci.USA 117(2020)9851-9856)报道了使用完整蛋白质电喷雾质谱法从复杂基质中进行高通量抗体筛选。
WO 2016/172485报道了多特异性抗原结合蛋白。
发明内容
本文报道了一种用于表征和鉴定以及选择表达具有高滴度和低水平的抗体相关副产物的复杂抗体形式的重组细胞克隆的新颖的、高通量的合适方法。根据本发明的方法使用针对抗体的相应靶标的分离结合以及同时结合的对重组细胞克隆培养上清液进行基于免疫测定的筛选的结合信号。该数据允许在500或更多个克隆的阶段首次选择具有期望的产物谱的高生产细胞克隆。
本发明的一个方面是一种用于从全部表达相同(重组)(治疗性)抗体的大量(在一个实施例中,至少500个)重组细胞克隆中鉴定和/或选择一个或多个重组细胞克隆的方法,该抗体为至少双特异性的并且与第一抗原和第二抗原(特异性地)结合,该方法包括以下步骤:
-培养每个单一存放的重组细胞克隆(至少5天)以产生培养上清液;
-确定以下各项:
i)确定上清液中的总蛋白质(在某些实施例中,抗体)浓度(使用免疫测定);
ii)在针对至少2种,在一个优选实施例中(至少)4种不同浓度的上清液的免疫测定中确定针对每种上清液的与(治疗性)抗体的第一抗原结合的结合信号;
iii)在针对至少2种,在一个优选实施例中(至少)4种与ii)中相同浓度的上清液的免疫测定中确定针对每种上清液的与(治疗性)抗体的第二抗原结合的结合信号;
iv)在针对至少2种,在一个优选实施例中(至少)4种与ii)和iii)中相同浓度的上清液的(桥接)免疫测定中针对每种上清液的与(治疗性)抗体的第一抗原和第二抗原同时结合的结合信号;
v)利用各自针对至少4种,在一个优选实施例中至少14种不同浓度的(分离的)(治疗性)抗体的如ii)、iii)和iv)中相同的免疫测定确定针对(分离的)(治疗性)抗体(在如通过质谱法确定的至少98%的纯度下)的与第一抗原和第二抗原分离结合以及与这两种抗原同时结合的结合信号;
vi)利用各自针对至少4种,在一个优选实施例中至少14种如v)中相同浓度的第一(主要/主)(治疗性)抗体相关副产物的如ii)、iii)和iv)中相同的免疫测定确定针对第一(主要/主)(分离的)(治疗性)抗体相关副产物(其也可以由所述细胞克隆表达/也由所述细胞克隆表达)(在如通过质谱法确定的至少70%的纯度下)的与第一抗原和第二抗原分离结合以及与这两种抗原同时结合的结合信号;
vii)利用各自针对至少4种,在一个优选实施例中至少14种如v)和vi)中相同浓度的第二(第二主要)(治疗性)抗体相关副产物的如ii)、iii)和iv)中相同的免疫测定确定针对第二(第二主要)(分离的)(治疗性)抗体相关副产物(其也可以由所述细胞克隆表达/也由所述细胞克隆表达)(在如通过质谱法确定的至少70%的纯度下)的与第一抗原和第二抗原分离结合以及与这两种抗原同时结合的结合信号;
-基于以下各项对大量重组细胞克隆中的重组细胞克隆进行排位:
-i)、ii)、iii)、iv),以及
-针对相同浓度在iii)中确定的结合信号与在ii)中确定的结合信号的(所有)比率的中位值,由此该中位值进一步除以(归一化至)针对相同浓度使用iii)的免疫测定在v)中确定的结合信号与使用ii)的免疫测定在v)中确定的结合信号的(所有)比率的中位值,以及
-针对相同浓度在iv)中确定的结合信号与在ii)中确定的结合信号的(所有)比率的中位值,由此该中位值进一步除以(归一化至)针对相同浓度使用iv)的免疫测定在v)中确定的结合信号与使用ii)的免疫测定在v)中确定的结合信号的(所有)比率的中位值,以及
-针对相同浓度在iii)中确定的结合信号与在ii)中确定的结合信号的(所有)比率的中位值,由此该中位值进一步除以(归一化至)针对相同浓度使用iii)的免疫测定在vi)中确定的结合信号与使用ii)的免疫测定在vi)中确定的结合信号的(所有)比率的中位值,以及
-针对相同浓度在iv)中确定的结合信号与在ii)中确定的结合信号的(所有)比率的中位值,由此该中位值进一步除以(归一化至)针对相同浓度使用iii)的免疫测定在vii)中确定的结合信号与使用ii)的免疫测定在vii)中确定的结合信号的(所有)比率的中位值,
(单一单独维度)
由此排位是按照针对每个单独细胞克隆的上述值与针对分离的(治疗性)抗体获得的值的相应差,
由此选择具有最小整体差的重组细胞克隆。
在某些实施例中,排位是按照针对每个单独细胞克隆的这些值与针对在ii)、iii)和iv)的测定中在v)中使用的分离的(治疗性)抗体获得的相应值的相应(绝对)差(距离)以及从其得出的比率。
在某些实施例中,排位(多维排位)考虑了每个单独值(维度)的单独(绝对)距离,即基于就(分离的)(治疗性)抗体的值而言的相似性(最小(绝对)差)与就第一(主要)和第二(第二主要)分离的(治疗性)抗体相关副产物而言的不相似性(最大(绝对)差)的组合。
在某些实施例中,选择基于就浓度、结合信号和(治疗性)抗体相除比率而言的最小差与就副产物相除比率而言的最大差的组合。
在某些实施例中,鉴定/选择具有最小整体(即,在所有单独维度中)(绝对)差(距离)的重组细胞克隆,即,鉴定/选择具有所有八个差的最小和的那些克隆。
在某些实施例中,一个或多个鉴定/选择的细胞克隆表达具有比大量重组细胞克隆的平均值更低的抗体相关副产物分数或百分比的所述重组(治疗性)抗体。
在某些实施例中,使用在计算机上运行的(in silico)方法确定差(距离)。
在某些实施例中,使用机器学习确定差(距离)。
在某些实施例中,使用极端梯度提升模型确定差(距离)。
在某些实施例中,结合信号为空白校正结合信号(通过相应的空白信号减少的原始结合信号)
在某些实施例中,在ii)、iii)和iv)中使用至少4种浓度。在某些实施例中,在ii)、iii)和iv)中使用4或5或6或7种浓度。
在某些实施例中,在v)、vi)和vii)中使用至少14种浓度。在某些实施例中,在v)、vi)和vii)中使用14或15或16或17或18种浓度。
在某些实施例中,双特异性(治疗性)抗体包含异二聚体Fc区,其中一个Fc区多肽包含杵突变并且相应的另一个Fc区多肽包含臼突变;第一(主要)双特异性(治疗性)抗体相关副产物为所述双特异性(治疗性)抗体的臼-臼同二聚体;第二(第二主要)双特异性(治疗性)抗体相关副产物为所述双特异性(治疗性)抗体的杵-杵同二聚体。
在某些实施例中,免疫测定为酶联免疫吸附测定。
在某些实施例中,细胞为CHO细胞。
在一个优选实施例中,(治疗性)抗体为双特异性(治疗性)抗体。在某些实施例中,双特异性(治疗性)抗体就其重链而言为异二聚体的,由此重链中的一条重链包含臼突变并且相应的另一条重链包含杵突变。在某些实施例中,第一(主要/主)(分离的)(治疗性)抗体相关副产物包含各自具有臼突变的两条重链,并且第二(第二主要)(分离的)(治疗性)抗体相关副产物包含各自具有杵突变的两条重链。
本发明的进一步方面是一种
i)在单一重组细胞克隆培养上清液中确定的总抗体浓度,其中重组细胞克隆已经用编码双特异性(治疗性)抗体的核酸进行转染,
ii)针对上清液与双特异性(治疗性)抗体的第一抗原和第二抗原的分离结合的结合信号,
iii)针对上清液与双特异性(治疗性)抗体的第一抗原和第二抗原的同时结合的结合信号
用于鉴定表达具有低双特异性抗体相关副产物的所述双特异性(治疗性)抗体的重组细胞克隆的用途。
在某些实施例中,进一步地,
iv)双特异性(治疗性)抗体与其第一抗原和第二抗原的分离结合和同时结合的结合信号,
v)第一(主要)双特异性抗体相关副产物与双特异性(治疗性)抗体的第一抗原和第二抗原的分离结合和同时结合的结合信号,
vi)第二(第二主要)双特异性抗体相关副产物与双特异性(治疗性)抗体的第一抗原和第二抗原的分离结合和同时结合的结合信号
用于鉴定表达具有低双特异性抗体相关副产物的所述双特异性(治疗性)抗体的重组细胞克隆。
在某些实施例中,进一步地,
-针对在iii)中获得的浓度中的每一者的结合信号与针对在ii)中获得的相同浓度的相应结合信号的单独比率的中位值除以针对使用iii)的免疫测定在v)中获得的浓度中的每一者的结合信号与针对使用ii)的免疫测定在v)中获得的相同浓度的相应结合信号的单独比率的中位值,
-针对在iv)中获得的浓度中的每一者的结合信号与针对在ii)中获得的相同浓度的相应结合信号的单独比率的中位值除以针对使用iv)的免疫测定在v)中获得的浓度中的每一者的结合信号与针对使用ii)的免疫测定在v)中获得的相同浓度的相应结合信号的单独比率的中位值,
-针对在iii)中获得的浓度中的每一者的结合信号与针对在ii)中获得的相同浓度的相应结合信号的单独比率的中位值除以针对使用iii)的免疫测定在vi)中获得的浓度中的每一者的结合信号与针对使用ii)的免疫测定在vi)中获得的相同浓度的相应结合信号的单独比率的中位值,以及
-针对在iv)中获得的浓度中的每一者的结合信号与针对在ii)中获得的相同浓度的相应结合信号的单独比率的中位值除以针对使用iv)的免疫测定在vii)中获得的浓度中的每一者的结合信号与针对使用ii)的免疫测定在vii)中获得的相同浓度的相应结合信号的单独比率的中位值
用于鉴定表达具有低双特异性抗体相关副产物的所述双特异性(治疗性)抗体的重组细胞克隆,
其中
iv)为双特异性(治疗性)抗体与其第一抗原和第二抗原的分离结合和同时结合的结合信号,
v)为第一(主要)双特异性抗体相关副产物与双特异性(治疗性)抗体的第一抗原和第二抗原的分离结合和同时结合的结合信号,
vi)为第二(第二主要)双特异性抗体相关副产物与双特异性(治疗性)抗体的第一抗原和第二抗原的分离结合和同时结合的结合信号。
本发明的进一步方面是一种计算机程序,其包括计算机可执行指令,该计算机可执行指令用于当程序在计算机或计算机网络上执行时进行根据本发明的方法。
本发明的进一步方面是一种计算机程序产品,其具有程序代码工具,以便当程序在计算机或计算机网络上执行时,进行根据本发明的方法。
本发明的进一步方面是一种数据载体,其具有存储在其上的数据结构,数据载体在加载到计算机或计算机网络中之后,诸如加载到计算机或计算机网络的工作存储器或主存储器中之后,能够执行根据本发明的方法。
除了所描绘和要求保护的各种实施例之外,所公开的主题还涉及具有本文所公开和要求保护的特征的其他组合的其他实施例。这样,本文所呈现的特定特征,尤其是呈现为方面或实施例,可以在所公开的主题的范围内以其他方式彼此组合,使得所公开的主题包括本文所公开的特征的任何合适的组合。出于图示和描述的目的,已经呈现了所公开主题的具体实施例的描述。其并不旨在穷举或将所公开的主题限制为所公开的那些实施例。
如本文所用的一方面涉及本发明的独立主题,如本文所用的实施例提供对一个或多个或所有独立方面的更详细实现。
具体实施方式
本发明至少部分地基于这样的发现:使用基于ELISA的滴度和结合表征可以用于在药物开发的细胞系开发阶段期间预测在至少500个克隆的阶段的单独克隆的关键质量属性。
本发明进一步至少部分地基于这样的发现:基于ELISA的滴度和结合表征与在计算机上运行的数据分析的组合可以用于在药物开发的细胞系开发阶段预测在至少500个克隆的阶段的单独克隆的关键质量属性。
因此,利用根据本发明的方法,增加可以分析的克隆的数量,减少分析时间,并且同时增加再现性和易应用性。因此,首次有可能在细胞系开发期间的早期实施产物质量筛选(特别是对于复杂的抗体形式)。
一般定义
可用于实施本发明的方法和技术描述于:例如Ausubel,F.M.(编辑),CurrentProtocols in Molecular Biology,第I卷至第III卷(1997);Glover,N.D.和Hames,B.D.编辑,DNA Cloning:A Practical Approach,第I卷和第II卷(1985),Oxford UniversityPress;Freshney,R.I.(编辑),Animal Cell Culture-a practical approach,IRL PressLimited(1986);Watson,J.D.等人,Recombinant DNA,第二版,CHSL Press(1992);Winnacker,E.L.,From Genes to Clones;N.Y.,VCH Publishers(1987);Celis,J.编辑,Cell Biology,第二版,Academic Press(1998);Freshney,R.I.,Culture of AnimalCells:A Manual of Basic Technique,第二版,Alan R.Liss,Inc.,N.Y.(1987)。
使用重组DNA技术能够产生核酸的衍生物。此类衍生物可例如在一个或几个核苷酸位置处通过取代、改变、交换、缺失或插入来修饰。修饰或衍生化可以例如借助定点诱变来进行。此类修饰可以由本领域技术人员容易地进行(参见例如,Sambrook,J.等人,Molecular Cloning:A laboratory manual(1999)Cold Spring Harbor LaboratoryPress,New York,USA;Hames,B.D.和Higgins,S.G.,Nucleic acid hybridization-apractical approach(1985)IRL Press,Oxford,England)。
必须注意的是,如本文和所附权利要求书中所用,单数形式“一个”、“一种”和“该/所述”包括复数指代,除非上下文另外明确规定。因此,例如,提及“一个细胞”包括多个此类细胞和本领域技术人员已知的其等同物,诸如此类。同样,术语“一个/一种”、“一个或多个/一种或多种”和“至少一个/至少一种”在本文中可以互换使用。还应当注意的是,术语“包含”、“包括”和“具有”可以互换使用。
术语“约”表示其后所跟随的数值的+/-20%范围。在某些实施例中,术语“约”表示其后所跟随的数值的+/-10%的范围。在某些实施例中,术语“约”表示其后所跟随的数值的+/-5%的范围。
术语“包括”还涵盖术语“包含……”。
特定于细胞的定义
如本文所用,术语“细胞克隆”表示包含能够表达多肽的外源核苷酸序列的哺乳动物细胞(即,重组哺乳动物细胞)。此类重组哺乳动物细胞是已引入一种或多种外源核酸的细胞,包括此类细胞的后代。在某些实施例中,细胞克隆为包含编码异源多肽的核酸的哺乳动物细胞。因此,术语“包含编码异源多肽的核酸的细胞克隆”表示包含整合在哺乳动物细胞的基因组中并且能够表达异源多肽的外源核苷酸序列的重组哺乳动物细胞。在某些实施例中,细胞克隆为包含整合在细胞的基因组的基因座内的单个位点处的外源核苷酸序列的哺乳动物细胞。在一个优选实施例中,细胞克隆为包含整合在细胞的基因组的基因座内的单个位点处的外源核苷酸序列的哺乳动物细胞,其中外源核苷酸序列包含侧接至少一个第一选择标志物的第一重组识别序列和第二重组识别序列以及位于第一重组识别序列与第二重组识别序列之间的第三重组识别序列,并且所有重组识别序列都不同。
如本文所用,术语“重组细胞”表示遗传修饰后的细胞,例如表达目标异源多肽并且可以用于以任何规模生产所述目标异源多肽的细胞。例如,“细胞克隆”表示其中已将目标异源多肽的编码序列引入到基因组中的细胞。例如,已进行过重组酶介导的盒式交换(RMCE)由此目标多肽的编码序列已被引入到宿主细胞的基因组中的“包含外源核苷酸序列的重组哺乳动物细胞”为特异性“细胞克隆”。
如本文所用,“细胞克隆”表示“转化细胞”。该术语包括原代转化细胞以及由其衍生的子代,而不考虑传代次数。子代可能例如不与亲本细胞的核酸内容物完全一致,而是可能含有突变。涵盖了具有与在最初转化的细胞中筛选或选择的功能或生物活性相同的功能或生物活性的突变体子代。
“分离的细胞克隆”表示已经从其自然环境的组分中分离的细胞克隆。
“分离的核酸”表示已经从其天然环境的组分中分离的核酸分子。
“分离的多肽”或“分离的抗体”或“分离的副产物”分别表示已经从其天然环境的组分中分离的多肽分子或抗体分子。在某些实施例中,分离的多肽或分离的抗体或分离的副产物被纯化至大于70%的纯度,如通过例如质谱法确定的。在某些实施例中,分离的多肽或分离的抗体或分离的副产物被纯化至大于95%或98%的纯度,如通过例如质谱法确定的。关于用于评估例如抗体纯度的方法的综述,参见Flatman,S.等人,J.Chrom.B 848(2007)79-87。
测定
不同免疫测定的原理如例如Hage,D.S.(Anal.Chem.71(1999)294R-304R)所述。Lu,B.等人(Analyst 121(1996)29R-32R)报道了用于免疫测定的抗体的取向固定。例如,Wilchek,M.和Bayer,E.A.,在Methods Enzymol.184(1990)467-469中报道了亲和素-生物素介导的免疫测定。
术语“免疫测定”表示利用特异性结合分子(例如抗体)来捕获和/或检测用于定性或定量分析的特定靶标的任何技术。通常,免疫测定的特征在于以下步骤:1)固定或捕获分析物以及2)检测和测量分析物。分析物可以被捕获,即结合在任何固体表面,例如膜、塑料板或其他一些固体表面上。免疫测定的具体形式是ELISA(酶联免疫吸附测定)。
免疫测定通常可以采用三种不同的形式进行。一种是直接检测,一种是间接检测,或通过夹心测定。
直接检测免疫测定使用可直接测量的检测(或示踪)抗体。酶或其他分子允许产生信号,该信号将产生颜色、荧光或发光,从而使信号可视化或测量(也可以使用放射性同位素,尽管现在它并不常用)。
在间接测定中,与分析物结合的一抗用于为二抗(示踪抗体)提供确定的靶标,该二抗与由一抗(称为检测剂或示踪抗体)提供的靶标特异性结合。二抗产生可测量的信号。
夹心测定使用两种抗体,一种捕获抗体和一种示踪(检测剂)抗体。捕获抗体用于结合(固定化)溶液中的分析物或在溶液中与其结合。这允许从样品中特异性地去除分析物。示踪(检测剂)抗体在第二步中用于产生信号(如上所述直接或间接)。夹心形式需要两个抗体,每个抗体在靶标分子上都有不同的表位。此外,它们不得相互干扰,因为两种抗体必须同时与靶标结合。
单克隆抗体及其恒定结构域包含许多反应性氨基酸侧链,用于与结合对,例如多肽/蛋白质的成员、聚合物(例如PEG、纤维素或聚苯乙烯)或酶缀合。氨基酸的化学反应性基团是例如氨基(赖氨酸、α-氨基)、硫醇基(胱氨酸、半胱氨酸和甲硫氨酸)、甲酸基(天冬氨酸、谷氨酸)和糖醇基。这种方法是例如由Aslam M.和Dent,A.在“Bioconjugation”,MacMillan Ref.Ltd.1999,第50-100页中描述。
抗体最常见的反应性基团之一是氨基酸赖氨酸的脂肪族ε-胺。一般来说,几乎所有的抗体都含有丰富的赖氨酸。赖氨酸胺在pH 8.0以上(pKa=9.18)是相当好的亲核试剂,因此容易且干净地与各种试剂反应,形成稳定的键。胺反应性试剂主要与赖氨酸和蛋白质的α-氨基反应。反应性酯,特别是N-羟基-琥珀酰亚胺(NHS)酯,是最常用的胺基改性试剂。在水性环境中反应的最佳pH是pH 8.0至9.0。异硫氰酸酯是胺修饰试剂,并且与蛋白质形成硫脲键。它们与水溶液中的蛋白质胺反应(最佳pH为9.0至9.5)。醛在温和的水性条件下与脂族和芳族胺、肼和酰肼反应,形成亚胺中间体(希夫碱)。希夫碱可以用温和或强还原剂(诸如硼氢化钠或氰基硼氢化钠)选择性还原,以衍生出稳定的烷基胺键。已用于改性胺的其他试剂是酸酐。例如,二乙烯三胺五乙酸酐(DTPA)是含有两个胺反应性酸酐基团的双功能螯合剂。它可以与氨基酸的N-末端和ε-胺基反应形成酰胺键。酸酐环打开形成多价金属螯合臂,能够与配位复合物中的金属紧密结合。
抗体中另一个常见的反应性基团是来自含硫氨基酸胱氨酸及其还原产物半胱氨酸(或半胱氨酸,half cystine)的硫醇残基。半胱氨酸含有游离硫醇基团,它比胺类更具亲核性,且通常是蛋白质中反应性最强的官能团。硫醇通常在中性pH下具有反应性,因此可以在胺存在的情况下选择性地与其他分子偶联。由于游离巯基具有相对反应性,因此具有这些基团的蛋白质通常以其氧化形式作为二硫基或二硫键与其一起存在。在此类蛋白质中,需要用诸如二硫苏糖醇(DTT)等试剂还原二硫键以生成反应性游离硫醇。硫醇反应性试剂是那些将与多肽上的硫醇基团偶联,形成硫醚偶联产物的试剂。这些试剂在弱酸性至中性pH下反应迅速,因此可以在胺基团存在的情况下选择性地反应。文献报道了几种硫醇化交联试剂的诸如Traut试剂(2-亚氨基硫烷)、琥珀酰亚氨基(乙酰硫基)乙酸酯(SATA)和磺基琥珀酰亚胺6-[3-(2-吡啶基二硫基)丙酰胺]己酸酯(Sulfo-LC-SPDP)的使用提供经由反应性氨基引入多个巯基的高效方式。卤代乙酰基衍生物,例如碘乙酰胺,形成硫醚键,且也是硫醇修饰的试剂。另外有用的试剂是马来酰亚胺。马来酰亚胺与硫醇反应性试剂的反应与碘乙酰胺的反应基本相同。马来酰亚胺在弱酸性至中性pH下反应迅速。
抗体中另一个常见的反应性基团是甲酸。抗体在C-末端位置以及天冬氨酸和谷氨酸的侧链内含有甲酸基团。甲酸在水中相对较低的反应性通常使得难以使用这些基团来选择性地修饰多肽和抗体。完成此操作后,通常使用水溶性碳二亚胺将甲酸基团转化为反应性酯,并与亲核试剂诸如胺、酰肼或肼反应。含胺试剂应该是弱碱性的,以便在赖氨酸的碱性更强的ε-胺存在的情况下与活化的甲酸选择性地反应,形成稳定的酰胺键。当pH值升至8.0以上时,可能发生蛋白质交联。
高碘酸钠可用于氧化与醛的抗体连接的碳水化合物部分内的糖的醇部分。每个醛基都可以与胺、酰肼或肼反应,如针对甲酸所述。由于碳水化合物部分主要存在于抗体的可结晶片段区(Fc-区),因此可通过远离抗原结合位点的碳水化合物定点修饰实现缀合。形成希夫碱中间体,可通过用氰基硼氢化钠(温和且选择性)或硼氢化钠(强)水溶性还原剂还原该中间体,将其还原为烷基胺。
示踪和/或捕获和/或检测抗体与其缀合配偶体的缀合可以通过不同的方法,诸如化学结合,或经由结合对的结合来进行。如本文所用,术语“缀合配偶体”表示例如固体支持物、多肽、可检测标记、特异性结合对的成员。在某些实施例中,捕获和/或示踪和/或检测抗体与其缀合配偶体的缀合通过经由N末端和/或ε-氨基(赖氨酸)、不同赖氨酸的ε-氨基、抗体的氨基酸骨架的羧基-、巯基-、羟基-和/或酚官能团、和/或抗体的碳水化合物结构的糖醇基团的化学结合来进行。在某些实施例中,捕获抗体经由结合对与其缀合配偶体缀合。在一个优选实施例中,捕获抗体与生物素缀合,并且经由固体支持物固定化的亲和素或链霉亲和素进行固定至固体支持物。在某些实施例中,示踪抗体经由结合对与其缀合配偶体缀合。在一个优选的实施例中,示踪抗体通过作为可检测标记的共价键与异羟基洋地黄毒苷缀合。
术语“固相”表示非流体物质,并且包括:由诸如聚合物、金属(顺磁性颗粒、铁磁性颗粒)、玻璃和陶瓷等材料制成的颗粒(包括微粒和珠粒);凝胶物质,诸如二氧化硅凝胶、氧化铝凝胶和聚合物凝胶;毛细管,其可以由聚合物、金属、玻璃和/或陶瓷制成;沸石和其他多孔物质;电极;微量滴定板;固体条;以及比色皿、管或其他光谱仪样品容器。固相组分与惰性固体表面的区别在于,“固相”在其表面上包含至少一个部分,其旨在与样品中的物质发生相互作用。固相可以是固定组分,诸如管、条、比色皿或微量滴定板,或者可以是非固定组分,诸如珠粒和微粒。可以使用允许蛋白质和其他物质非共价连接或共价连接的多种微粒。此类颗粒包括聚合物颗粒,诸如聚苯乙烯和聚(甲基丙烯酸甲酯);金颗粒,诸如金纳米颗粒和金胶体;以及陶瓷颗粒,诸如二氧化硅颗粒、玻璃颗粒和金属氧化物颗粒。参见例如Martin,C.R.,等人,Analytical Chemistry-News&Features,70(1998)322A-327A或Butler,J.E.,Methods 22(2000)4-23。
发色体(荧光或发光基团和染料)、酶、NMR活性基团或金属颗粒、半抗原,例如异羟基洋地黄毒苷是“可检测标记”的实例。可检测标记也可以是可光活化的交联基团,例如叠氮基或吖丙啶基团。可以通过电化学发光检测的金属螯合物也是信号发射基团,特别优选钌螯合物,例如钌(双吡啶基)
间接检测系统包括,例如,检测试剂,例如检测抗体用结合对的第一配偶体标记。合适的结合对的实例是抗原/抗体、生物素或生物素类似物诸如氨基生物素、亚氨基生物素或脱硫生物素/亲和素或链霉亲和素、糖/凝集素、核酸或核酸类似物/互补核酸和受体/配体,例如类固醇激素受体/类固醇激素。在一个优选的实施例中,第一结合对成员包括半抗原、抗原和激素。在某些实施例中,半抗原选自由以下项组成的组:地高辛、异羟基洋地黄毒苷和生物素及其类似物。这种结合对的第二配偶体,例如抗体、链霉亲和素等通常被标记以允许直接检测,例如通过上述标记。
抗体
关于人免疫球蛋白轻链和重链的核苷酸序列的一般信息给出于:Kabat,E.A.等人,Sequences of Proteins of Immunological Interest,第5版,Public HealthService,National Institutes of Health,Bethesda,MD(1991)中。
如本文所用,重链和轻链的所有恒定区和结构域的氨基酸位置是根据Kabat等人,Sequences of Proteins of Immunological Interest,第5版,Public Health Service,National Institutes of Health,Bethesda,MD(1991)中描述的Kabat编号系统编号的,并且在本文中被称为“根据Kabat编号”。具体地,将Kabat编号系统(参见Kabat等人,Sequences of Proteins of Immunological Interest,第5版,Public Health Service,National Institutes of Health,Bethesda,MD(1991)的第647-660页)用于κ和λ同种型的轻链恒定结构域CL,并且将Kabat EU索引编号系统(参见Kabat等人,Sequences ofProteins of Immunological Interest,第5版,Public Health Service,NationalInstitutes of Health,Bethesda,MD(1991)的第661-723页)用于恒定重链结构域(CH1、铰链、CH2和CH3,这在本文中通过在此情况下称为“根据Kabat的EU索引编号”而进一步分类)。
本文的术语“抗体”以最广泛的含义使用,并且包括各种抗体结构,包括但不限于全长抗体、单克隆抗体、多特异性抗体(例如,双特异性抗体)和抗体-抗体片段-融合物,以及其组合物。
术语“天然抗体”表示具有不同结构的天然存在的免疫球蛋白分子。例如,天然IgG抗体为约150,000道尔顿的异四聚体糖蛋白,由经二硫键键合的两条相同轻链和两条相同重链组成。从N末端到C末端,每条重链具有重链可变区(VH),接着是三个重链恒定结构域(CH1、CH2和CH3),借此,铰链区定位在第一重链恒定结构域与第二重链恒定结构域之间。类似地,从N末端到C末端,每条轻链都有一个轻链可变区(VL),后跟一个轻链恒定结构域(CL)。抗体的轻链基于其恒定结构域的氨基酸序列,可以归属于两种类型中的一种,所述两种类型称为卡帕(κ)和兰姆达(λ)。
术语“全长抗体”表示具有与天然抗体的结构大体上相似的结构的抗体。全长抗体包含两条全长抗体轻链以及两条全长抗体重链,每条全长抗体轻链在N末端到C末端方向上包含轻链可变区和轻链恒定结构域,每条全长抗体重链在N末端到C末端方向上包含重链可变区、第一重链恒定结构域、铰链区、第二重链恒定结构域和第三重链恒定结构域。与天然抗体相反,全长抗体可包含另外的免疫球蛋白结构域,诸如例如缀合至全长抗体不同链的一个或多个末端的一个或多个额外的scFv、或重链或轻链Fab片段、或scFab,但每个末端仅缀合单个片段。这些缀合物也由术语全长抗体涵盖。
术语“抗体结合位点”表示一对重链可变结构域和轻链可变结构域。为了确保与抗原的正确结合,这些可变结构域是同源可变结构域,即属于一起。结合位点的抗体包含至少三个HVR(例如在VHH的情况下)或三到六个HVR(例如在天然存在的情况下,即具有VH/VL对的常规抗体)。通常,负责抗原结合的抗体的氨基酸残基形成结合位点。这些残基通常包含在一对抗体重链可变结构域和相应的抗体轻链可变结构域中。抗体的抗原结合位点包含来自“高变区”或“HVR”的氨基酸残基。“框架”或“FR”区是除本文定义的高变区残基以外的那些可变结构域区域。因此,抗体的轻链可变结构域和重链可变结构域包含从N末端至C末端的区域FR1、HVR1、FR2、HVR2、FR3、HVR3和FR4。尤其是,重链可变结构域的HVR3区域是最有助于抗原结合并且定义抗体结合特异性的区域。“功能性结合位点”能够与其靶标结合。术语“与……结合”表示在某些实施例中在结合测定中结合位点在体外测定中与其靶标的结合。这种结合测定可以是任何测定,只要可以检测到结合事件。“结合”可以使用例如ELISA测定来确定。
如本文所用,术语“高变区”或“HVR”是指以下项中的每一种:包含氨基酸残基延伸体的抗体可变结构域的在序列中高变(“互补决定区”或“CDR”)和/或形成结构上限定的环(“高变环”)和/或含有抗原接触残基(“抗原接触点”)的区域。通常,抗体包含六个CDR;三个在重链可变结构域VH中(H1、H2、H3),并且三个在轻链可变结构域VL中(L1、L2、L3)。
HVR包括
(a)存在于氨基酸残基26-32(L1)、50-52(L2)、91-96(L3)、26-32(H1)、53-55(H2)和96-101(H3)处的高变环(Chothia,C和Lesk,A.M.,J.Mol.Biol.196(1987)901-917);
(b)存在于氨基酸残基24-34(L1)、50-56(L2)、89-97(L3)、31-35b(H1)、50-65(H2)和95-102(H3)处的CDR(Kabat,E.A.等人,Sequences of Proteins of ImmunologicalInterest,第5版,Public Health Service,National Institutes of Health,Bethesda,MD(1991),NIH Publication 91-3242);
(c)存在于氨基酸残基27c-36(L1)、46-55(L2)、89-96(L3)、30-35b(H1)、47-58(H2)和93-101(H3)处的抗原接触点(MacCallum等人,J.Mol.Biol.262:732-745(1996));以及
(d)(a)、(b)和/或(c)的组合,包括氨基酸残基46-56(L2)、47-56(L2)、48-56(L2)、49-56(L2)、26-35(H1)、26-35b(H1)、49-65(H2)、93-102(H3)和94-102(H3)。
除非另外指明,否则可变结构域中的HVR残基和其他残基(例如,FR残基)在本文中根据Kabat等人,出处同上编号。
抗体的“类别”是指抗体的重链所具有的恒定结构域或恒定区优选地Fc区域的类型。存在五大类抗体:IgA、IgD、IgE、IgG和IgM,并且它们中的一些可以进一步分为亚类(同型),例如,IgG1、IgG2、IgG3、IgG4、IgA1和IgA2。对应于不同类别的免疫球蛋白的重链恒定结构域分别称为α、δ、ε、γ和μ。
术语“重链恒定区”表示免疫球蛋白重链中含有恒定结构域的区域,即CH1结构、铰链区、CH2结构域和CH3结构域。在一个实施例中,人IgG恒定区从Ala118延伸至重链的羧基末端(根据Kabat EU索引编号)。然而,恒定区的C末端赖氨酸(Lys447)可以存在或不存在(根据Kabat EU索引编号)。术语“恒定区”表示包含两个重链恒定区的二聚体,它们可以经由铰链区半胱氨酸残基彼此共价连接,形成链间二硫键。
术语“重链Fc区”表示免疫球蛋白重链的C末端区域,其含有铰链区(中和下铰链区)、CH2结构域和CH3结构域的至少一部分。在一个实施例中,人IgG重链Fc区从Asp221或从Cys226或从Pro230延伸至重链的羧基末端(根据Kabat EU索引编号)。因此,Fc区比恒定区小但在C末端部分与其相同。然而,重链Fc区的C末端赖氨酸(Lys447)可能存在或者可能不存在(根据Kabat EU索引编号)。术语“Fc区”表示包含两个重链Fc区的二聚体,它们可以经由铰链区半胱氨酸残基彼此共价连接,形成链间二硫键。
如在本申请中所用的术语“价”表示抗体中存在指定数目的结合位点。因此,术语“二价”“四价”和“六价”分别表示抗体中存在两个结合位点、四个结合位点和六个结合位点。
“单特异性抗体”表示具有单个结合特异性即特异性结合一个抗原的抗体。单特异性抗体可制备为全长抗体或抗体片段(例如,F(ab')
“多特异性抗体”表示具有关于同一抗原上至少两个不同表位或两个不同抗原的结合特异性。多特异性抗体可以制备为全长抗体或抗体片段(例如,Fab双特异性抗体)或它们的组合(抗体-抗体片段-融合物,例如与额外的scFv或Fab片段缀合的全长抗体)。多特异性抗体至少是二价的,即包含两个抗原结合位点。此外,多特异性抗体至少是双特异性的。因此,二价双特异性抗体是多特异性抗体的最简单形式。具有两个、三个或更多个(例如,四个)功能性抗原结合位点的工程化抗体也已有报告(参见,例如,US2002/0004587)。
在某些实施例中,一个或多个细胞克隆产生多特异性抗体。在某些实施例中,结合特异性中的一个针对第一抗原,而另一个针对不同的第二抗原。在某些实施例中,多特异性抗体与同一抗原的两个不同表位结合。在某些实施例中,同一抗原上的第二表位为非重叠表位。在某些实施方案中,抗体为双特异性抗体。在一个优选实施例中,双特异性抗体为三价双特异性抗体或二价双特异性抗体。
用于制备多特异性抗体的技术包括但不限于具有不同特异性的两个免疫球蛋白重链-轻链对的重组共表达(参见Milstein,C.和Cuello,A.C.,Nature 305(1983)537-540,WO 93/08829,以及Traunecker,A.等人,EMBO J.10(1991)3655-3659)和“杵臼结构”工程化(参见例如US 5,731,168)。多特异性抗体还可以通过以下方式来制备:工程化用于制备抗体Fc-异二聚体分子的静电操纵效应(参见例如,WO 2009/089004);使两个或更多个抗体或片段交联(参见例如,US 4,676,980,以及Brennan,M.等人,Science,229(1985)81-83);使用亮氨酸拉链来产生双特异性抗体(参见例如,Kostelny,S.A.等人,J.Immunol.148(1992)1547-1553);使用用于避免轻链错配问题的普通轻链技术(参见例如,WO 98/50431);使用用于制备双特异性抗体片段的具体技术(参见例如Holliger,P.等人,Proc.Natl.Acad.Sci.USA 90(1993)6444-6448);以及如Tutt,A.等人,J.Immunol.147(1991)60-69中所述制备三特异性抗体。
本文还包括具有三个或更多个抗原结合位点的工程化抗体,包括例如“章鱼抗体”或者DVD-Ig(参见例如,WO 2001/77342和WO 2008/024715)。具有三个或更多个抗原结合位点的多特异性抗体的其他示例可以在WO 2010/115589、WO 2010/112193、WO 2010/136172、WO 2010/145792和WO 2013/026831中找到。双特异性抗体或其抗原结合片段还包括“双作用Fab”或“DAF”(参见例如US2008/0069820和WO 2015/095539)。
多特异性抗体也可以以不对称形式提供,其中在具有相同抗原特异性的一个或多个结合臂中有结构域互换,即通过交换VH/VL结构域(参见例如,WO 2009/080252和WO2015/150447)、CH1/CL结构域(参见例如,WO 2009/080253)或完整的Fab臂(参见例如,WO2009/080251、WO 2016/016299,还参见Schaefer等人,Proc.Natl.Acad.Sci.USA 108(2011)1187-1191,以及Klein等人,MAbs 8(2016)1010-1020)。
在一个优选实施例中,多特异性抗体包含Fab片段,其中重链和轻链的可变区或恒定区被交换,即,其中在一条链中,重链VH可变结构域直接或经由肽接头与轻链CL恒定结构域缀合,并且在相应的另一条链中,轻链VL可变结构域直接或经由肽接头与重链CH1恒定结构域缀合。
因此,结构域交换Fab片段包含由轻链可变区(VL)和重链恒定区1(CH1)构成的多肽链以及由重链可变区(VH)和轻链恒定区(CL)构成的多肽链。
还可以通过将荷电或非荷电的氨基酸突变引入结构域界面以指导正确的Fab配对,以对不对称Fab臂进行工程化。参见例如WO 2016/172485。
抗体或片段也可以是多特异性抗体,如WO 2009/080254、WO 2010/112193、WO2010/115589、WO 2010/136172、WO 2010/145792、或WO 2010/145793中所述。
其抗体或片段也可以是如WO 2012/163520中公开的多特异性抗体。
多特异性抗体的各种其他分子形式是在本领域中已知的并且包括在本文中(参见例如Spiess等人,Mol.Immunol.67(2015)95-106)。
双特异性抗体通常是与同一抗原上的两个不同的、不重叠的表位或与不同抗原上的两个表位特异性结合的抗体分子。
在某些实施例中,双特异性抗体选自由以下项组成的双特异性抗体组:
结构域交换1+1双特异性抗体(CrossMab)
(双特异性全长IgG抗体,其包含一对包含第一Fab片段的第一轻链和第一重链以及一对包含第二Fab片段的第二轻链和第二重链,
其中在第一Fab片段中
a)仅CH1结构域和CL结构域相互替换(即第一Fab片段的轻链包含VL结构域和CH1结构域,且第一Fab片段的重链包含VH结构域和CL结构域);b)仅VH结构域和VL结构域相互替换(即第一Fab片段的轻链包含VH结构域和CL结构域,且第一Fab片段的重链包含VL结构域和CH1结构域);或者
c)CH1和CL结构域以及VH和VL结构域彼此替换(即第一Fab片段的轻链包含VH和CH1结构域,并且第一Fab片段的重链包含VL和CL结构域);
其中第二Fab片段包含轻链和重链,该轻链包含VL和CL结构域,该重链包含VH和CH1结构域;
其中第一重链和第二重链均包含CH3结构域,其中两个CH3结构域通过相应的氨基酸取代以互补方式工程化,以支持第一重链和第二重链的异源二聚化(在一个优选实施例中,一个CH3结构域包含杵突变并且相应的另一个CH3结构域包含臼突变);
C末端Fab结构域融合2+1双特异性抗体(BS)
(双特异性全长IgG抗体,其包含
a)一种全长抗体,其包含各有全长抗体轻链和全长抗体重链的两个对,其中由全长重链和全长轻链对中的每个对形成的结合位点特异性结合至第一抗原,以及
b)一个额外的Fab片段,其中额外的Fab片段与全长抗体的一条重链的C末端融合,其中额外的Fab片段的结合位点与第二抗原特异性结合,
其中与第二抗原特异性结合的额外的Fab片段包含结构域交叉,使得a)轻链可变结构域(VL)和重链可变结构域(VH)彼此替换,或b)轻链恒定结构域(CL)和重链恒定结构域(CH1)彼此替换);
双特异性单臂单链抗体
(双特异性单臂单链抗体,其包含与第一表位或抗原特异性结合的第一结合位点和与第二表位或抗原特异性结合的第二结合位点,由此单独的链如下:
-轻链(包含可变轻链结构域和轻链恒定结构域);
-组合轻链/重链(按N末端到C末端的顺序包含可变轻链结构域、轻链恒定结构域、肽接头、可变重链结构域、CH1结构域、铰链区、CH2结构域和具有杵或臼突变的CH3)
-重链(按N末端到C末端的顺序包含可变重链结构域、CH1结构域、铰链区、CH2结构域、具有臼或杵突变的CH3结构域));
双特异性双臂单链抗体
(双特异性双臂单链抗体,其包含与第一表位或抗原特异性结合的第一结合位点和与第二表位或抗原特异性结合的第二结合位点,由此单独的链如下:
-组合轻链/重链1(按N末端到C末端的顺序包含可变轻链结构域1、轻链恒定结构域、肽接头、可变重链结构域1、CH1结构域、铰链区、CH2结构域、具有杵或臼突变的CH3结构域);
-组合轻链/重链2(按N末端到C末端的顺序包含可变轻链结构域2、轻链恒定结构域、肽接头、可变重链结构域2、CH1结构域、铰链区、CH2结构域、具有臼或杵突变的CH3结构域));
常见的轻链双特异性抗体
(常见的轻链双特异性抗体,其包含与第一表位或抗原特异性结合的第一结合位点和与第二表位或抗原特异性结合的第二结合位点,由此单独的链如下
-轻链(按N末端到C末端的顺序包含可变轻链结构域和轻链恒定结构域);
-重链1(按N末端到C末端的顺序包含可变重链结构域1、CH1结构域、铰链区、CH2结构域、具有臼或杵突变的CH3结构域);
-重链2(按N末端到C末端的顺序包含可变重链结构域2、CH1结构域、铰链区、CH2结构域、具有杵或臼突变的CH3结构域));
N末端Fab结构域插入2+1双特异性抗体(TCB)
(双特异性全长抗体,其具有带有结构域交换的额外的重链N末端结合位点,包括
-第一Fab片段和第二Fab片段,其中第一Fab片段和第二Fab片段的每个结合位点与第一抗原特异性结合,
-第三Fab片段,其中第三Fab片段的结合位点与第二抗原特异性结合,并且其中第三Fab片段包含结构域交叉,使得可变轻链结构域(VL)和可变重链结构域(VH)被彼此替换,以及
-包含第一Fc区多肽和第二Fc区多肽的Fc区,
其中第一Fab片段和第二Fab片段各自包含重链片段和全长轻链,
其中第一Fab片段的重链片段的C-末端与第一Fc区多肽的N-末端融合,
其中第二Fab片段的重链片段的C末端与第三Fab片段的可变轻链结构域的N末端融合,并且第三Fab片段的CH1结构域的C末端与第二Fc区多肽的N末端融合);
抗体-多聚体融合体
(融合体多肽,其包含
(a)抗体重链和抗体轻链,以及
(b)第一融合体多肽,其在N末端至C末端方向上包含非抗体多聚体多肽的第一部分、抗体重链CH1结构域或抗体轻链恒定结构域、抗体铰链区、抗体重链CH2结构域和抗体重链CH3结构域;以及第二融合体多肽,其在N末端至C末端方向上包含该非抗体多聚体多肽的第二部分以及在第一多肽包含抗体重链CH1结构域的情况下的抗体轻链恒定结构域或在第一多肽包含抗体轻链恒定结构域的情况下的抗体重链CH1结构域,
其中
(i)(a)的抗体重链和(b)的第一融合体多肽,(ii)(a)的抗体重链和(a)的抗体轻链,以及(iii)(b)的第一融合体多肽和(b)的第二融合体多肽各自独立地通过至少一个二硫键彼此共价连接,
其中
抗体重链和抗体轻链的可变结构域形成与抗原特异性结合的结合位点)。
抗体重链中的CH3结构域可通过“杵臼结构(knob-into-holes)”技术改变,这一技术在例如WO 96/027011、Ridgway,J.B.等人,Protein Eng.9(1996)617-621和Merchant,A.M.等人,Nat.Biotechnol.16(1998)677-681中以若干实例详细描述。在这一方法中,改变两个CH3结构域的相互作用表面以增加这两个CH3结构域的异源二聚化,从而增加包含它们的多肽的异源二聚化。(两个重链的)两个CH3结构域中的一个可以为“杵”,而相应的另一个为“臼”。二硫键的引入进一步稳定化异二聚体(Merchant,A.M.等人,Nature Biotech.16(1998)677-681;Atwell,S.等人,J.Mol.Biol.270(1997)26-35)并增加产率。
(抗体重链的)CH3结构域中的突变T366W表示为“杵突变”,并且(抗体重链的)CH3结构域中的突变T366S、L368A、Y407V表示为“臼突变”(根据Kabat EU索引编号)。例如通过将S354C突变引入到具有“杵突变”(表示为“杵-cys-突变”)的重链的CH3结构域中或通过将Y349C突变引入到具有“臼突变”(表示为“臼-cys-突变”)的重链的CH3结构域(根据KabatEU索引编号)中,也可以使用CH3结构域之间的额外的链间二硫桥(Merchant,A.M.等人,Nature Biotech.16(1998)677-681)。
如本文所用,术语“结构域交换”表示在抗体重链VH-CH1片段及其相应的同源抗体轻链对中,即在抗体Fab(片段抗原结合)中,结构域序列偏离天然抗体序列是因为至少一个重链结构域由其相应的轻链结构域取代,反之亦然。结构域交换有三种常见类型:(i)CH1和CL结构域的交叉,其由轻链结构域交换轻链导致VL-CH1结构域序列,由重链片段结构域交换导致VH-CL结构域序列的(或具有VH-CL-铰链-CH2-CH3结构域序列的全长抗体重链);(ii)VH和VL结构域的结构域交换,其由轻链结构域交换导致VH-CL结构域序列,由重链片段结构域交换导致VL-CH1结构域序列;以及(iii)完整轻链(VL-CL)和完整VH-CH1重链片段的结构域交换(“Fab交叉”),其通过结构域交换导致具有VH-CH1结构域序列的轻链并通过结构域交换导致具有VL-CL结构域序列的重链片段(所有上述结构域序列均以N末端至C末端方向表示)。
如本文所用,关于相应重链结构域和轻链结构域的术语“彼此替换”是指前述结构域交换。因此,当CH1结构域和CL结构域“彼此替换”时,是指项目(i)下提及的结构域交换以及所得重链和轻链结构域序列。因此,当VH和VL“彼此替换”时,是指在第(ii)项中提到的结构域交叉;以及当CH1和CL结构域“彼此替换”并且VH和VL结构域“彼此替换”时,是指在第(iii)项中提到的结构域交叉。例如,在WO 2009/080251、WO 2009/080252、WO 2009/080253、WO 2009/080254和Schaefer、W.等人,Proc.Natl.Acad.Sci USA 108(2011)11187-11192中报告了包括结构域交换的双特异性抗体。此类抗体通常称为CrossMab。
在某些实施例中,多特异性抗体还包含至少一个Fab片段,其包括如上文第(i)项所提到的CH1和CL结构域的结构域交叉,或者如上文第(ii)项所提到的VH和VL结构域的结构域交叉,或如上文第(iii)项所提到的VH-CH1和VL-VL结构域的结构域交叉。在具有结构域交叉的多特异性抗体的情况下,与相同抗原特异性结合的Fab在某些实施例中被构建为具有相同结构域序列。因此,在多特异性抗体中包含多个具有结构域交换的Fab的情况下,所述Fab与相同抗原特异性结合。
如本文所用,术语“重组抗体”表示所有通过重组手段诸如重组细胞制备、表达、创造或分离的抗体(嵌合抗体、人源化抗体和人类抗体)。这包括从重组细胞(诸如NS0、HEK、BHK、羊水细胞或CHO细胞)中分离的抗体。
如本文所用,术语“抗体片段”是指除了完整抗体以外的分子,其包括完整抗体的部分,该部分结合完整抗体结合的抗原,即它是功能性片段。抗体片段的实例包括但不限于Fv、Fab、Fab'、Fab'-SH、F(ab')2、双特异性Fab、双体抗体、线性抗体、单链抗体分子(例如scFv或scFab)。
术语“正确组装的抗体”及其语法等同物是指由重链和轻链的同源对组装的抗体。即,正确组装的抗体包含每条链各自的配对配偶体。例如,每个重链与其同源轻链配对,每个重链Fab片段与其同源轻链配对和/或每个scFab片段与其自身配对而不是与重链Fab片段的不同轻链配对。
术语“抗体相关副产物”是指在重组抗体的表达期间或伴随表达而获得的分子,该分子不是正确组装的抗体,但包含比正确组装的抗体更少或更多的抗体链(多肽)。抗体相关副产物涵盖例如抗体分子,其中一条或多条链(诸如轻链)缺失,或者其中一条或多条重链或重链Fab片段与不是同源轻链的轻链配对,或其中抗体包含额外的轻链。抗体重链或重链Fab片段和轻链的“同源对”表示已经旨在/选择/设计成配对以形成相对于靶标具有正确结合特性的结合位点的那些链。
重组方法和组合物
可以使用重组方法和组合物来产生抗体,例如,如在US 4,816,567中所述。对于这些方法,提供了编码抗体的一种或多种分离的一种或多种核酸。
在本发明的一个方面,提供了一种产生抗体的方法,其中该方法包括在适于表达抗体的条件下培养包含编码抗体的核酸的细胞克隆以及任选地从宿主细胞(或宿主细胞培养基)中回收抗体,其中已经利用根据本发明的方法选择了细胞克隆。
对于抗体的重组产生,将编码抗体的核酸生成设计/合成并插入到一个或多个载体中以用于在细胞中进一步克隆和/或表达。可以使用常规程序来容易地对此类核酸进行分离和测序(例如,通过使用能够与编码抗体的重链和轻链的基因特异性结合的寡核苷酸探针),或通过重组方法产生或通过化学合成获得此类核酸。
一般来讲,对于目标多肽(诸如例如治疗性抗体)的重组大规模生产,需要稳定地表达和分泌所述多肽的细胞克隆。该细胞克隆被称为“重组细胞克隆”或“重组生产细胞克隆”,并且用于生成这种细胞的整体过程被称为“细胞系开发”。在细胞系开发过程的第一步骤中,合适的宿主细胞(诸如例如在某些实施例中,CHO细胞)用适于表达所述目标多肽的一个或多个核酸序列转染。在第二步骤中,基于已经用编码目标多肽的核酸共转染的选择标志物的共表达来选择稳定地表达目标多肽的细胞克隆。
编码多肽的核酸(即编码序列)表示为结构基因。这样的结构基因为纯编码信息。因此,需要额外的调控元件用于其表达。因此,结构基因通常整合在所谓的表达盒中。表达盒在哺乳动物细胞中起作用所需的最少调控元件是在所述哺乳动物细胞中起作用的启动子,其位于结构基因的上游,即5',以及在所述哺乳动物细胞中起作用的多聚腺苷酸化信号序列,其位于结构基因的下游,即3'。启动子、结构基因和多聚腺苷酸化信号序列以可操作连接的形式排列。
在目标多肽是由不同多肽构成的异源多聚体多肽(诸如例如抗体或复杂抗体形式)的情况下,需要的不仅是单个表达盒,而是在各自含有的结构基因上不同的大量表达盒,即,对于异源多聚体多肽(异源多聚体抗体)的不同多肽(链)中的每一者需要至少一个表达盒。例如,全长抗体是包含轻链的两个拷贝以及重链的两个拷贝的异源多聚体多肽。因此,全长抗体由两种不同的多肽构成。因此,全长抗体的表达需要两个表达盒,一个用于轻链,另一个用于重链。例如,如果全长抗体是双特异性抗体,即抗体包含与两种不同抗原/同一抗原上的两个表位特异性结合的两个不同结合位点,则两个轻链和两个重链也彼此不同。因此,这种双特异性全长抗体由四种不同的多肽构成,并且因此需要四个表达盒。
目标多肽的表达盒进而整合到一个或多个所谓的“表达载体”中。“表达载体”是提供用于在细菌细胞中扩增所述载体以及在哺乳动物细胞中表达所包含的结构基因的所有必需元件的核酸。通常,表达载体包含原核质粒增殖单元,例如用于大肠杆菌的原核质粒增殖单元,其包含复制起点和原核选择标志物,以及真核选择标志物,以及表达目标结构基因所需的表达盒。“表达载体”是用于将表达盒引入到哺乳动物宿主细胞中以生成表达多肽的细胞克隆的转运工具。
如前面的段落中所概述,待表达的多肽越复杂,所需的不同表达盒的数量也将越高。固有地随着表达盒的数量增加,整合到宿主细胞基因组中的核酸的大小也增加。表达载体的大小也随之增加。然而,载体大小的实际上限在约15kbp的范围内,超过该范围,处理和加工效率显著下降。该问题可以通过使用两个或更多个表达载体来解决。因此,表达盒可以在不同的表达载体之间拆分,每个表达载体仅包含其中一些表达盒,导致尺寸减小。
用于产生表达异源多肽(诸如例如多特异性抗体)的重组细胞的细胞系开发(CLD),采用随机整合(RI)或靶向整合(TI)的核酸,该核酸包含表达和生产目的异源多肽所需的相应表达盒。
使用RI,一般来说,若干个载体或其片段在相同或不同的基因座处整合到细胞的基因组中。
通常,使用TI,将包含不同表达盒的转基因的单拷贝整合到宿主细胞基因组中的预定“热点”。
用于生成用于表达(糖基化)抗体的细胞克隆的合适宿主细胞通常来源于多细胞生物(诸如例如脊椎动物)。
宿主细胞
适合悬浮生长的任何哺乳动物细胞系均可以用于生成可以在根据本发明的方法中处理的重组细胞克隆。此外,独立于整合方法,即对于RI和TI,可以使用任何哺乳动物宿主细胞。
有用的哺乳动物宿主细胞系的实例是人羊水细胞(例如,如在Woelfel,J.等人,BMC Proc.5(2011)P133中所述的CAP-T细胞);由SV40转化的猴肾CV1系(COS-7);人胚肾细胞系(如在例如Graham,F.L.等人,J.Gen Virol.36(1977)59-74中所述的HEK293或HEK293T细胞);小仓鼠肾细胞(BHK);小鼠塞尔托利氏细胞(例如在Mather,J.P.,Biol.Reprod.23(1980)243-252中描述的TM4细胞);猴肾细胞(CV1);非洲绿猴肾细胞(VERO-76);人宫颈癌细胞(HELA);犬肾细胞(MDCK);布法罗大鼠肝细胞(BRL 3A);人肺细胞(W138);人肝细胞(Hep G2);小鼠乳腺肿瘤(MMT 060562);TRI细胞(如例如在Mather,J.P.等人,AnnalsN.Y.Acad.Sci.383(1982)44-68中所述);MRC 5细胞;以及FS4细胞。其他有用的哺乳动物宿主细胞系包括中国仓鼠卵巢(CHO)细胞,包括DHFR-CHO细胞(Urlaub,G.等人,Proc.Natl.Acad.Sci.USA 77(1980)4216-4220);以及骨髓瘤细胞系,诸如Y0、NS0和Sp2/0。关于适用于抗体产生的某些哺乳动物宿主细胞系的综述,参见例如Yazaki,P.和Wu,A.M.,Methods in Molecular Biology,第248卷,Lo,B.K.C.(编辑),Humana Press,Totowa,NJ(2004),第255-268页。
在某些实施例中,哺乳动物宿主细胞是例如中国仓鼠卵巢(CHO)细胞(例如CHOK1、CHO DG44等)、人胚肾(HEK)细胞、淋巴样细胞(例如Y0、NS0、Sp2/0细胞)或人类羊水细胞(例如CAP-T等)。在一个优选实施例中,所述哺乳动物(宿主)细胞为CHO细胞。因此,同样地,细胞克隆是CHO细胞。
关于TI,包含整合在基因组基因座内的单个位点上的如本文所述的着陆位点的任何已知的或未来的适用于TI的哺乳动物宿主细胞均可用于本发明。这种细胞被称为哺乳动物TI宿主细胞。在某些实施例中,哺乳动物TI宿主细胞为包含如本文所述的着陆位点的仓鼠细胞、人细胞、大鼠细胞或小鼠细胞。在一个优选实施例中,哺乳动物TI宿主细胞为CHO细胞。在某些实施例中,哺乳动物TI宿主细胞为包含整合在基因组基因座内的单个位点上的如本文所述的着陆位点的中国仓鼠卵巢(CHO)细胞、CHO K1细胞、CHO K1SV细胞、CHO DG44细胞、CHO DUKXB-11细胞、CHO K1S细胞或CHO K1M细胞。
在某些实施例中,哺乳动物TI宿主细胞包含整合的着陆位点,其中着陆位点包含一个或多个重组识别序列(RRS)。RRS可以由重组酶(例如,Cre重组酶、FLP重组酶、Bxb1整合酶或
尽管在下文中以CHO细胞举例说明本发明,但这仅是为了举例说明本发明而不应以任何方式解释为限制。本发明的真实范畴在权利要求书中阐述。
靶向整合
用于生成待在根据本发明的方法中处理的重组哺乳动物细胞克隆的一种方法是通过使用用于引入编码核酸的靶向整合(TI)来生成重组细胞克隆。
在靶向整合中,将位点特异性重组用于将外源核酸引入到哺乳动物TI宿主细胞的基因组中的特定基因座中以生成重组细胞克隆。这是一种酶促过程,其中基因组中整合位点处的序列被交换为外源核酸。用于实现此类核酸交换的一种系统是Cre-lox系统。催化交换的酶是Cre重组酶。要交换的序列由基因组和外源核酸中两个lox(P)位点的位置定义。这些lox(P)位点被Cre重组酶识别。不需要更多,即不需要ATP等。最初在噬菌体P1中发现了Cre-lox系统。
Cre-lox系统在不同的细胞类型中运行,如哺乳动物、植物、细菌和酵母。
在某些实施例中,编码异源多肽的外源核酸已通过单重组酶或双重组酶介导的盒交换(RMCE)整合到哺乳动物TI宿主细胞中。因此,获得重组哺乳动物细胞克隆(诸如重组CHO细胞克隆),其中确定的和特定的表达盒序列已经整合到基因组中的单个基因座处。
Cre-LoxP位点特异性重组系统已广泛应用于许多生物实验系统中。Cre重组酶为38-kDa位点特异性DNA重组酶,其识别34bp LoxP序列。Cre重组酶来源于噬菌体P1并且属于酪氨酸家族位点特异性重组酶。Cre重组酶可介导LoxP序列之间的分子内和分子间重组。LoxP序列由8bp非回文核心区及其侧接的两个13bp反向重复序列构成。Cre重组酶与13bp重复序列结合,从而介导8bp核心区内的重组。Cre-LoxP介导的重组以高效率发生,并且无需任何其他宿主因子。如果两个LoxP序列以相同的取向被置于同一核苷酸序列中,则Cre重组酶介导的重组将切除位于两个LoxP序列之间的DNA序列,成为共价闭环。如果两个LoxP序列以颠倒的位置被置于同一核苷酸序列中,则Cre重组酶介导的重组将反转位于这两个序列之间的DNA序列的取向。如果两个LoxP序列在两个不同的DNA分子上,并且如果一个DNA分子为环状分子,则Cre重组酶介导的重组将导致环状DNA序列的整合。
“重组识别序列”(RRS)是由重组酶识别的核苷酸序列,并且是重组酶介导的重组事件所必需和充足的。RRS可用于定义核苷酸序列中将发生重组事件的位置。
术语“匹配RRS”表示在两个RRS之间发生了重组。在某些实施例中,两个匹配RRS相同。
在某些实施例中,RRS可由Cre重组酶识别。在某些实施例中,RRS可由FLP重组酶识别。在某些实施例中,RRS可由Bxb1整合酶识别。在某些实施例中,RRS可由
在某些实施例中,两个RRS均为野生型LoxP序列。在某些实施例中,两个RRS均为突变体LoxP序列。在某些实施例中,两个RRS均为野生型FRT序列。在某些实施例中,两个RRS均为突变体FRT序列。在某些实施例中,两个RRS为不同的序列,但是可由同一重组酶识别。在某些实施例中,第一匹配RRS为Bxb1 attP序列,并且第二匹配RRS为Bxb1 attB序列。在某些实施例中,第一匹配RRS为
当使用双载体组合时,在根据本发明的方法中采用“双质粒RMCE”策略或“双RMCE”。例如,但不作为限制,整合的着陆位点可以包含三个RRS,例如以下排列:其中第三RRS(“RRS3”)存在于第一RRS(“RRS1”)与第二RRS(“RRS2”)之间,而第一载体包含与该整合的外源核苷酸序列上的第一RRS和第三RRS相匹配的两个RRS,并且第二载体包含与该整合的外源核苷酸序列上的第三RRS和第二RRS相匹配的两个RRS。
双质粒RMCE策略涉及使用三个RRS位点来同时实施两个独立的RMCE。因此,在使用双质粒RMCE策略的哺乳动物TI宿主细胞中的着陆位点包括第三RRS位点(RRS3),其与第一RRS位点(RRS1)或第二RRS位点(RRS2)没有交叉活性。两个待靶向的质粒需要相同的侧接RRS位点才能高效靶向,其中一个质粒(前)侧接有RRS1和RRS3,另一个表达质粒(后)侧接有RRS3和RRS2。在该双质粒RMCE中还需要两个选择标志物。一个选择标志物表达盒被分成两部分。前质粒将包含启动子,随后是起始密码子和RRS3序列。后质粒将具有与选择标志物编码区的减去了起始密码子(ATG)的N末端融合的RRS3序列。可能需要在RRS3位点与选择标志物序列之间插入额外的核苷酸,以确保融合体蛋白质发生框架内翻译(即可操作的连接)。仅当两个质粒均正确插入时,选择标志物的完整表达盒才将被组装,并因此使细胞对相应的选择剂具有抗性。
双质粒RMCE涉及靶标基因组基因座内的两个异种特异性RRS与供体DNA分子之间的双重组交叉事件,该事件由重组酶催化。双质粒RMCE被设计成将来自组合的前载体和后载体的DNA序列的拷贝引入哺乳动物TI宿主细胞基因组的预定基因座中。RMCE可以实现为使得原核载体序列不被引入哺乳动物TI宿主细胞的基因组中,从而减少和/或防止不必要的触发宿主免疫或防御机制。RMCE过程可以用多个DNA序列重复。
在某些实施例中,靶向整合通过两次RMCE实现,其中两种不同的DNA序列均整合到RRS匹配的哺乳动物TI宿主细胞的基因组的预定位点中,其中每种DNA序列均包含至少一个编码异源多聚体多肽的一部分的表达盒和/或至少一个侧接两个异种特异性RRS的选择标志物或其部分。在某些实施例中,靶向整合通过多次RMCE实现,其中来自多个载体的DNA序列全部整合到哺乳动物TI宿主细胞的基因组的预定位点中,其中每种DNA序列均包含至少一个编码异源多聚体多肽的一部分的表达盒和/或至少一个侧接两个异种特异性RRS的选择标志物或其部分。在某些实施例中,该选择标志物可以在第一载体上部分编码并且在第二载体上部分编码,使得只有通过双RMCE正确整合两者才能够表达该选择标志物。
在某些实施例中,经由重组酶介导的重组进行的靶向整合导致多聚体多肽的选择标志物和/或不同的表达盒整合到不含来自原核载体的序列的宿主细胞基因组的一个或多个预定整合位点中。
适用于根据本发明的方法的示例性哺乳动物TI宿主细胞是CHO细胞,其具有整合在其基因组基因座内的单个位点的着陆位点,其中该着陆位点包含三个用于Cre重组酶介导的DNA重组的异种特异性loxP位点。
在该实例中,该异种特异性loxP位点为L3、LoxFas和2L(参见例如,Lanza等人,Biotechnol.J.7(2012)898-908;Wong等人,Nucleic Acids Res.33(2005)e147),由此L3和2L分别在5’端和3’端处侧接着陆位点,并且LoxFas位于L3位点与2L位点之间。
如前一段中所概述的着陆位点的这种配置允许同时整合两个载体,例如携带L3和LoxFas位点的所谓前载体,以及包含LoxFas和2L位点的后载体。与着陆位点中存在的选择标志物基因不同的选择标志物基因的功能性元件可以分布在两个载体之间:启动子和起始密码子可以位于前载体上,而编码区和多聚A信号位于后载体上。只有来自两个载体的所述核酸的正确的重组酶介导整合才诱导针对相应选择剂的抗性。
一般来讲,哺乳动物TI宿主细胞为包含整合在哺乳动物细胞的基因组的基因座内的着陆位点的哺乳动物细胞,其中着陆位点包含侧接至少一个第一选择标志物的第一重组识别序列和第二重组识别序列以及位于第一重组识别序列与第二重组识别序列之间的第三重组识别序列,并且所有重组识别序列都不同。
外源核苷酸序列是并非来源于特异性细胞,而是可以通过DNA递送方法(诸如,通过转染方法、电穿孔方法或转化方法)引入所述细胞中的核苷酸序列。在某些实施例中,哺乳动物TI宿主细胞包含整合在哺乳动物细胞基因组中的一个或多个整合位点处的至少一种着陆位点。在某些实施例中,着陆位点整合在哺乳动物细胞基因组的特异性基因座内的一个或多个整合位点处。
在某些实施例中,整合的着陆位点包含至少一个选择标志物。在某些实施例中,整合的着陆位点包含第一RRS、第二RRS和第三RRS,以及至少一个选择标志物。在某些实施例中,选择标志物位于第一RRS与第二RRS之间。在某些实施例中,两个RRS侧接至少一个选择标志物,即,第一RRS位于该选择标志物的5'(上游)并且第二RRS位于该选择标志物的3'(下游)。在某些实施例中,第一RRS与该选择标志物的5'端相邻,并且第二RRS与该选择标志物的3'端相邻。在某些实施例中,着陆位点包含第一RRS、第二RRS和第三RRS,以及位于第一RRS与第三RRS之间的至少一个选择标志物。
在某些实施例中,选择标志物位于第一RRS与第二RRS之间,并且这两个侧接RRS是不同的。在某些优选的实施例中,第一侧接RRS为LoxP L3序列,并且第二侧接RRS为LoxP 2L序列。在某些实施例中,LoxP L3序列位于选择标志物的5'端,并且LoxP 2L序列位于选择标志物的3'端。在某些实施例中,第一侧接RRS为野生型FRT序列,并且第二侧接RRS为突变体FRT序列。在某些实施例中,第一侧接RRS为Bxb1 attP序列,并且第二侧接RRS为Bxb1 attB序列。在某些实施例中,第一侧接RRS为
本发明方法的具体实施例的说明
下面使用一组四种基于ELISA的测定(一种用于确定表达所述双特异性抗体的一个细胞克隆的培养物上清液中的抗体滴度,两种用于确定双特异性抗体分别与抗原1和抗原2的分离结合,以及一种用于确定与抗原1和抗原2的同时结合)针对双特异性抗体形式举例说明了根据本发明的方法。其读数是基于根据本发明的方法来处理的。因此,一方面,可以基于抗体主产物与抗体副产物的比率来区分细胞克隆,并且另一方面,可以相对于其产物(抗体)相关副产物谱对细胞克隆进行正确分类。两者都为根据本发明的方法的经过改进的克隆选择过程提供了基础。该实例仅作为根据本发明的方法的示例呈现,且不应被解释为对其的限制。本发明的真实范畴在所附权利要求书中阐述。
在此实例中,对产生双特异性抗体的单独细胞克隆的评定基于四种测定的结果,其中确定并量化了上清液中的抗体滴度、分别与抗原1和2的单独结合以及与两种抗原的同时结合。
因此,对于细胞系开发(CLD)期间的细胞克隆选择,通过用编码双特异性抗体的一种或多种核酸转染宿主细胞获得的不同细胞克隆通过如上所述的三种结合ELISA来进行分析并且考虑到表达产量根据期望的抗体主产物与不期望的抗体副产物量(=抗体主产物质量)来进行评定。这些测定的组合读数允许将表达高百分比的期望的抗体主产物(=先导物)的克隆与仅表达低百分比的期望的主产物的克隆区分开。
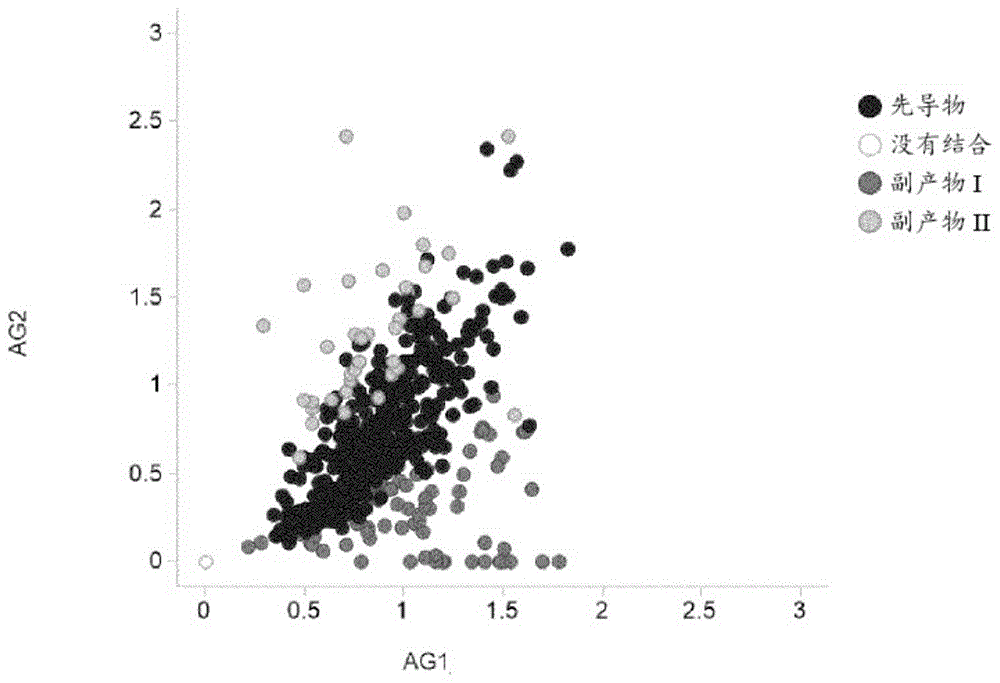
许多双特异性抗体形式基于杵臼异源二聚化技术。这种形式可以形成特征性产物相关副产物,例如由于链错配,诸如例如臼链-臼链二聚体、杵链-杵链二聚体或缺失一条轻链的3/4抗体。不同的细胞克隆通常表达抗体主产物(=先导物,即正确组装的双特异性抗体)和产物相关抗体副产物(例如,臼链-臼链二聚体(=副产物I)和杵链-杵链二聚体(=副产物II))的不同混合物。重组细胞克隆的这些分子的表达模式的差异需要早期且适合高通量的筛选方法来取消选择具有不合适的产物谱的细胞克隆,诸如具有例如低抗体主产物产量的细胞克隆。该实例中使用的抗体形式及其一些副产物描绘于图15中。
根据本发明的方法的该实例中采用的测定利用不同的测定原理。这导致不同的表达产物给出不同的ELISA信号这一效果。纯化的主产物(即正确组装的杵到臼异二聚体)和最常见的副产物(即臼-臼同二聚体和杵-杵同二聚体)用作标准品。它们基于a)因形式本身和b)由于所采用的检测抗体的亲合力效应在测定中产生特定信号。
为了确定抗原结合,该实例中使用了以下酶联免疫吸附测定(ELISA):
-将生物素化抗原1或2分别固定在链霉亲和素包被的微量滴定板上;在洗涤板之后,应用培养上清液和检测抗体(与POD(辣根过氧化物酶)缀合的抗人Fab抗体)的混合物;将3,3',5,5'-四甲基联苯胺(TMB)用于读数;
-在桥接ELISA中确定与抗原1和抗原2的同时结合;将抗原1或抗原2直接包被在微量滴定板上;在洗涤板之后,应用培养上清液、各自相应的另一个生物素化抗原2或1以及链霉亲和素-POD缀合物的混合物;将TMB用于读数。
按照根据本发明的方法将这些ELISA读数组合以区分抗体主产物(即单体和正确组装的双特异性抗体)与抗体副产物。因此,已经实现了关于相应克隆的特性对其进行分类,作为克隆选择的基础。例如,如果基于根据本发明的方法的应用预测克隆主要表达主产物,则克隆被分类为“先导物”。这种克隆适合作为用于表达/产生具有低抗体相关副产物含量的双特异性抗体的克隆。需要坚定这些克隆。
作为参考,对三种不同双特异性抗体形式-结构域交换1+1双特异性抗体(CrossMab)、N末端Fab结构域插入2+1双特异性抗体(TCB)和C末端Fab结构域融合2+1双特异性抗体(BS)-的ELISA结果的分类在图1至3中可视化。为清楚起见,仅示出三分之二ELISA和仅四分之一分析浓度的ELISA结果。在图中,针对与抗原1(AG 1)的结合绘制与抗原2(AG2)的结合。不同的阴影指示细胞克隆质量分类。这表明根据抗体形式以及靶标和/或靶标组合(=项目)存在差异并因此展示了分析的复杂性。
在稀释系列(14种不同浓度)的所有测定中使用纯化的抗体主产物(表示为“主产物标准品”;例如,与正确缔合的所有轻链配对的正确组装的杵臼异二聚体重链)和最常见的不期望的副产物(分别表示为“副产物I标准品”和“副产物II标准品”;例如,分别为臼-臼同二聚体和杵-杵同二聚体)作为标准品。以4种不同浓度对培养5天后的相应单一细胞克隆培养上清液进行分析。根据本发明的方法可以独立于绝对信号差来执行,只要这些差在统计上是显著的。这与信号是否在测定的线性信号范围内无关。在某些实施例中,所有标准品、培养上清液、包被的抗原、检测抗体和检测试剂均以导致用抗体主产物标准品获得的信号与用抗体副产物标准品获得的信号之间的最大信号差的浓度使用。本领域技术人员可以基于其在本领域中的知识容易地执行信号差的这种优化,而没有过多的负担。
本发明至少部分地基于这样的发现:表达双特异性抗体的重组细胞克隆的选择可以基于单一细胞克隆培养上清液中双特异性抗体的浓度和确定双特异性抗体与分离的抗原的结合以及与两种抗原的同时结合的免疫测定的结果来高效地完成。已经进一步发现,有目的的数据处理是有利的。
本发明至少部分地基于这样的发现:单一细胞克隆培养上清液中双特异性抗体的浓度(培养至少5天后)与
-在用于与每种抗原的分离结合和与两种抗原的同时结合的结合免疫测定中四种测量浓度的培养上清液的中位值空白校正数据(结合信号),
-在每个结合免疫测定中至少五种测量浓度的分离的双特异性抗体和两种主副产物的中位值空白校正数据,
的组合可以用于选择产生具有最低抗体相关副产物含量的双特异性抗体的重组细胞克隆。
在本文中可互换使用的术语“空白校正数据”或“空白校正结合信号”表示,从在用于测试或标准样品的免疫测定中确定的结合信号(即从为测试或标准样品确定的原始结合信号)中减去/已经减去在用于空白样品(即没有标准品、培养上清液、(治疗性)抗体和任何副产物但在其他方面与测试样品相同的样品)的相同免疫测定中确定的背景信号。
已经发现,通过使用九种可能的标准品归一化结合比率中的全部九种或四种以及任选地吸光度校正ELISA信号的比率,可以进一步改进根据本发明的方法。
本发明至少部分地基于这样的发现:结合信号的某些比率是特异性的,并且当组合使用并用为标准品(100%纯化的抗体主产物、抗体副产物I和抗体副产物II)计算的比率归一化/归一化至该比率时,允许区分单独的培养上清液(=样品)并且从而区分具有良好产物质量的克隆(主要产生/表达抗体主产物)与具有较差产物质量的克隆(主要产生/表达抗体副产物)。
标准品的比率被计算为针对浓度(在一个优选实施例中,针对4种浓度的培养上清液和针对14种浓度的标准品)获得的信号的中位值并且然后除以彼此(“归一化”)。这产生了总共九种可能的比率。
本发明至少部分地基于这样的发现:选择表达正确组装的双特异性抗体的细胞克隆仅需要以下四个中位值:
-针对相同(四种)浓度的细胞克隆培养上清液获得的用于与抗原2结合的空白校正结合信号与针对相同(四种)浓度的细胞克隆培养上清液获得的用于与抗原1结合的空白校正结合信号的比率的中位值,该中位值被归一化至(即除以)针对至少5种浓度的抗体主产物(主产物标准品)获得的用于与抗原2结合的空白校正结合信号与在相同的测定中确定的针对相同的至少5种浓度的主产物标准品获得的用于与抗原1结合的空白校正结合信号的比率的中位值,
-针对相同(四种)浓度的细胞克隆培养上清液获得的用于与抗原1和2同时结合的空白校正结合信号与针对相同(四种)浓度的细胞克隆培养上清液获得的用于与抗原1结合的空白校正结合信号的比率的中位值,该中位值被归一化至针对至少5种浓度的抗体主产物(主产物标准品)获得的用于与抗原1和2同时结合的空白校正结合信号与在相同的测定中确定的针对相同的至少5种浓度的主产物标准品获得的用于与抗原1结合的空白校正结合信号的比率的中位值,
-针对相同(四种)浓度的细胞克隆培养上清液获得的用于与抗原2结合的空白校正结合信号与针对相同(四种)浓度的细胞克隆培养上清液获得的用于与抗原1结合的空白校正结合信号的比率的中位值,该中位值被归一化至针对至少5种浓度的抗体相关副产物I(副产物I标准品)获得的用于与抗原2结合的空白校正结合信号与在相同的测定中确定的针对相同的至少5种浓度的副产物I标准品获得的用于与抗原1结合的空白校正结合信号的比率的中位值,以及
-针对相同(四种)浓度的细胞克隆培养上清液获得的用于与抗原1和2同时结合的空白校正结合信号与针对相同(四种)浓度的细胞克隆培养上清液获得的用于与抗原1结合的空白校正结合信号的比率的中位值,该中位值被归一化至针对至少5种浓度的抗体相关副产物II(副产物II标准品)获得的用于与抗原1和2同时结合的空白校正结合信号与在相同的测定中确定的针对相同的至少5种浓度的副产物II标准品获得的用于与抗原1结合的空白校正结合信号的比率的中位值。
在某些实施例中,使用至少10种浓度的相应标准品。在一个优选实施例中,使用至少14种浓度的相应标准品。
当至少使用这些参数时,可以降低细胞克隆表征的复杂性。因此,根据本发明的所得方法涵盖该改进的数据处理和评估。
已经发现,通过与在计算机上运行的分析组合地使用上述参数选择,已经获得了独立于抗体形式以及独立于靶标的方法。
为了示出根据本发明的方法的有利特性,已经比较了八种不同的示例性数据处理变体。这些汇总于下表中。
这八种不同处理变体针对不同形式的五种不同的靶标组合在利用关于质量类别预测的极端梯度提升(XGB)模型的在计算机上运行的处理中的相应性能在图4中可视化(TCB-1、2+1头到尾、TCB-2、TCB-3和CrossMab)。通过未用于模型训练的整个项目上的交叉熵损失来评定XGB模型的预测质量。使用如上表所示的不同处理方法作为实验条件。
在图5中,示出了不同处理变体的假阴性率和假阳性率。可以清楚地看到输入参数和工程化特征的不同组合的效果,由此处理变体6、7和8表现得最佳。
因此,利用根据本发明的方法,可以实现独立于靶标和形式的重组细胞克隆分类。
在图6至10中,示出了根据本发明的方法的质量。在这些图中,将使用仅手动方法评估的数据集与利用根据本发明的方法评估的相同数据集进行比较。用于展示根据本发明的方法与仅手动评估方法相比的改进的性能的项目尚未用于算法的训练中。因此,可以排除偏差。
在图6中,针对与抗原1(AG1)的结合绘制了与抗原2(AG2)的结合。仅手动分析示出在顶部,并且利用根据本发明的方法获得的结果示出在底部。图7至10以相同的布置描绘了以下比率的中位值:归一化至主产物标准品的AG2:AG1、归一化至主产物标准品的AG12:AG1、归一化至副产物I标准品的AG2:AG1以及归一化至副产物II标准品的AG12:AG2,标准品各自针对克隆数绘制。由于针对标准品归一化,属于相应分类的克隆应当具有接近1的值。在这些图中令人印象深刻地示出了利用根据本发明的方法获得的结果的改进的精度。阴影指示不同的质量类别,而底部数据集中的大小与预测精度成比例并且因此非常容易且快速地示出哪个克隆最有可能产生优异的产物质量。
根据本发明的方法可以用于克隆质量评定,以选择具有用于放大的最佳特性的克隆,如下一个实例所示。
在图11至14中,示出了利用根据本发明的方法的克隆选择的实例。利用根据本发明的方法确定的克隆质量类别在图11和图12中通过不同的阴影示出。在图13和图14中,展示了选择过程。基于根据本发明的方法的结果从610个克隆中选择160个以具有期望的产物质量,即抗体主产物产量。
交叉熵损失函数(对数损失、log损失或逻辑损失)是对模型中的数据进行排位的函数。将每个预测类别概率与实际类别期望的输出0或1进行比较,并且计算基于概率与实际预期值的差距对概率进行惩罚的分数/损失。惩罚本质上是对数的,从而对于接近1的大差产生大分数并且对于趋向于0的小差产生小分数。当在训练期间调整模型权重时,使用交叉熵损失。目的是最小化损失,即损失越小,模型越好。完美模型具有交叉熵损失0。交叉熵被定义为
对于n个类别,其中t
中位值是一系列项中处于所述系列中间的项。对于具有N项的系列(其中N为奇数),中位值为
通过使用根据本发明的方法,减少了在克隆选择的早期步骤期间选择的产生具有较差产物质量的产物的克隆的数量(即减少了假阳性的数量),并且同时此外还减少了产生具有良好产物质量的产物的克隆的损失即取消选择(即减少了假阴性的数量)。
当在克隆选择中使用不包括产物质量属性的现有技术筛选方法时,将仅在筛选过程的后期识别产生具有较差产物质量的产物的克隆(例如,一旦有足够的产物可用使得可以通过分析色谱法来分析质量)。
因此,通过减少假阳性克隆的数量,在选择过程中进一步携带更多良好产生的克隆(即真阳性克隆)。因此,减少了产生高质量产物的克隆的潜在损失。
这很好地示出在图16至20中。
在图16中,每个条代表一个克隆。克隆按滴度(即产物浓度、条的大小)排位。此外,已经用根据本发明的方法表征了克隆。将已经用根据本发明的方法选择的克隆以黑色示出。
使用现有技术的基于滴度的选择,将已经选择浅条和暗条的组合,而利用根据本发明的方法,将已经选择仅由暗条代表的克隆。
因此,使用现有技术的基于滴度的选择,将包括不产生高质量产物的克隆(浅条)(即假阳性克隆),并且因此,减少了所选择的真阳性克隆的数量。
所有克隆(即由其产生的产物)均已经通过尺寸排阻色谱法(SEC)进行分析以确定单体含量,并且通过毛细管电泳(CE-SDS)和疏水相互作用色谱法(HIC)进行分析以用于确定主产物峰。
在图17中,针对图16的克隆示出了SEC确定的单体含量(x轴)与通过CE-SDS确定的主产物量(y轴)之间的关系。这就是在早期克隆选择中分析的内容。将已经用根据本发明的方法取消选择的克隆(即图16的浅条)以粗体示出。可以看出,大约一半的粗体取消选择的克隆可以在右上象限中找到,即基于CE-SDS和SEC具有据称具有良好的产物质量(图17中的圆圈)。然而,这些都是按照根据本发明的方法的假阳性克隆。
这已经通过使用HIC重新分析图17的圆圈中的克隆得到了证实。结果示出在图18中。图17的右上象限圈出的粗体克隆现在发现于图18中的右下象限(圆圈)中,即具有低主产物峰并且因此是假阳性克隆。
为了进一步证实根据本发明的方法的有利特性,对通过根据本发明的方法选择的克隆已经完成了相同的分析。SEC与CE-SDS组合以及SEC与HIC组合的对应结果分别示出在图19中和图20中。
可以看出,用根据本发明的方法选择的克隆位于两个图中的右上象限中并且因此是真阳性克隆。
这表明,利用根据本发明的方法,可以减少选择的假阳性克隆的数量,并且同时可以增加取消选择的真阳性克隆的数量。
本发明的具体计算机实现的实施例的描述
本发明的一个方面是一种计算机程序产品,其包括指令,当指令在包括计算机、免疫测定测量装置的合适系统上执行时,该指令使至少以下步骤得以执行
i)对于不同浓度的单一细胞克隆培养上清液,确定与单一细胞克隆培养上清液中的抗体浓度成比例的信号;
ii)对于不同浓度的单一细胞克隆培养上清液,确定与单一细胞培养上清液中含有的抗体与其第一靶标的分离结合成比例的信号;
iii)对于不同浓度的单一细胞克隆培养上清液,确定与单一细胞培养上清液中含有的抗体与其第二靶标的分离结合成比例的信号;
iv)对于不同浓度的单一细胞克隆培养上清液,确定与单一细胞培养上清液中含有的抗体与其第一靶标和第二靶标的同时结合成比例的信号;
v)对于不同浓度的相应标准品,确定与抗体参考标准品、抗体相关副产物I标准品和抗体相关副产物II标准品与抗体的第一靶标的分离结合成比例的信号;
vi)对于不同浓度的相应标准品,确定与抗体参考标准品、抗体相关副产物I标准品和抗体相关副产物II标准品与抗体的第二靶标的分离结合成比例的信号;
vii)对于不同浓度的相应标准品,确定与抗体参考标准品、抗体相关副产物I标准品和抗体相关副产物II标准品与抗体的第一靶标和第二靶标的同时结合成比例的信号。
在某些实施例中,指令在步骤vii)之后进一步包括以下步骤
a)计算针对相同四种浓度的细胞克隆培养上清液获得的用于与抗原2结合的信号与针对相同四种浓度的细胞克隆培养上清液获得的用于与抗原1结合的信号的比率的中位值,该中位值归一化至针对至少5种浓度的抗体主产物(主产物标准品)获得的相应比率的中位值信号,
b)计算针对相同四种浓度的细胞克隆培养上清液获得的用于与抗原1和2同时结合的信号与针对相同四种浓度的细胞克隆培养上清液获得的用于与抗原1结合的信号的比率的中位值,该中位值归一化至针对至少5种浓度的抗体主产物(主产物标准品)获得的相应比率的中位值信号,
c)计算针对相同四种浓度的细胞克隆培养上清液获得的用于与抗原2结合的信号与针对相同四种浓度的细胞克隆培养上清液获得的用于与抗原1结合的信号的比率的中位值,该中位值归一化至针对至少5种浓度的抗体相关副产物I(副产物I标准品)获得的相应比率的中位值信号,以及
d)计算针对相同四种浓度的细胞克隆培养上清液获得的用于与抗原1和2同时结合的信号与针对相同四种浓度的细胞克隆培养上清液获得的用于与抗原1结合的信号的比率的中位值,该中位值归一化至针对至少5种浓度的抗体相关副产物II(副产物II标准品)获得的相应比率的中位值信号。
在某些实施例中,指令进一步包括:将i)的计算的中位值和确定的滴度值拟合至用于表达双特异性抗体的重组细胞克隆的质量类别预测的模型。在一个优选实施例中,模型为XGB模型。
在某些实施例中,系统进一步包括克隆挑取装置和最后步骤viii):基于就浓度、结合信号和双特异性抗体相除比率而言的最小差与就副产物相除比率而言的最大差的组合选择克隆的步骤。
本发明的进一步方面是一种计算机程序,其包括计算机可执行指令,该计算机可执行指令用于当程序在计算机或计算机网络上执行时在本文所附的一个或多个实施例中进行根据本发明的方法。具体地,计算机程序可以存储在计算机可读数据载体上。因此,具体地,如上文指示的方法步骤i)至vii)中的一项、多于一项或甚至全部和任选地方法步骤a)至d)中的一项、多于一项或甚至全部以及进一步任选地步骤viii)可以通过使用计算机或计算机网络、优选地通过使用计算机程序来执行。
本发明的进一步方面是一种计算机程序产品,其具有程序代码工具,以便当程序在计算机或计算机网络上执行时,在本文所附的一个或多个实施例中进行根据本发明的方法。具体地,程序代码工具可存储在计算机可读数据载体上。
本发明的进一步方面是一种数据载体,其具有存储在其上的数据结构,数据载体在加载到计算机或计算机网络中之后,诸如加载到计算机或计算机网络的工作存储器或主存储器中之后,能够在本发明的一个或多个实施例中执行根据本发明的方法。
本发明的进一步方面是一种计算机程序产品,其具有存储在机器可读载体上的程序代码工具,以便当程序在计算机或计算机网络上执行时,在本发明的一个或多个实施例中进行根据本发明的方法。
如本文所用,“计算机程序产品”是指作为可交易产品的程序。该产品通常能够以任意格式(诸如以纸质格式)存在,或在计算机可读数据载体上存在。具体地讲,计算机程序产品可以分布在数据网络上。
最后,根据本发明的进一步方面是一种调制数据信号,其包含计算机系统或计算机网络可读的指令,用于在本发明的一个或多个实施例中执行根据本发明的方法。
参考本发明的计算机实现的方面,可以通过使用计算机或计算机网络来执行根据本文所公开的一个或多个实施例的方法的一个或多个方法步骤或甚至所有方法步骤。因此,一般来讲,可以通过使用计算机或计算机网络来执行包括提供和/或操纵数据的任何方法步骤。一般来讲,这些方法步骤可以包括通常除需要手动操作(诸如提供样品和/或执行实际测量的某些方面)的方法步骤之外的任何方法步骤。
具体地,本文进一步公开以下内容:
-计算机或计算机网络,其包括至少一个处理器,其中处理器被适配成在本发明的实施例之一中执行根据本发明的方法,
-计算机可加载数据结构,其被适配成当数据结构在计算机上执行时在本发明的实施例之一中执行根据本发明的方法,
-计算机程序,其中计算机程序被适配成当程序在计算机上执行时在本发明的实施例之一中执行根据本发明的方法,
-计算机程序,其包括程序器件,该程序器件用于当计算机程序在计算机上或计算机网络上执行时在本发明的实施例之一中执行根据本发明的方法,
-计算机程序,其包括根据本文所呈现的实施例中的任何实施例的程序器件,其中程序器件存储在计算机可读的存储介质上,
-存储介质,其中数据结构存储在存储介质上并且其中数据结构被适配成在已经加载到计算机或计算机网络的主存储和/或工作存储中之后在本发明的实施例之一中执行根据本发明的方法,以及
-计算机程序产品,其具有程序代码工具,其中程序代码工具可以存储或被存储在存储介质上,以用于在程序代码工具在计算机上或计算机网络上执行的情况下在本发明的实施例之一中进行根据本发明的方法。
***
提供以下实例和附图以帮助理解本发明,本发明的真正范围在所附权利要求中阐明。
应当理解,在不脱离本发明的精神的情况下,可对所阐述的程序进行修改。
附图说明
图1单种浓度的CrossMab形式双特异性抗体的抗原结合ELISA读数(AG2与AG1)的示例性分类。
图2单种浓度的TCB形式双特异性抗体的抗原结合ELISA读数(AG 2与AG 1)的示例性分类。
图3单种浓度的BS形式双特异性抗体的抗原结合ELISA读数(AG2与AG1)的示例性分类。
图4如通过未用于模型训练的整个项目上的交叉熵损失(y轴)评定的模型预测质量。对于TCB-1、2+1头到尾、TCB-2、TCB-3、CrossMab的从左到右的每个预处理变体1到8。
图5用于跨所有五个分析项目被分类为“正确组装的双特异性抗体”的假阳性预测和假阴性预测[%]。
图6仅手动分析(顶部)与根据本发明的方法(底部)的比较。在顶部图中针对与抗原1(AG1)的结合绘制与抗原2(AG2)的结合。该图示出了来自单个项目的610个单克隆细胞系的数据,该数据尚未用于训练算法。大小指示预测精度。
图7仅手动分析(顶部)与根据本发明的方法(底部)的比较。针对克隆数绘制的、归一化至AG2:AG1结合信号主产物标准品比率中位值的AG2:AG1结合信号比率中位值。
图8仅手动分析(顶部)与根据本发明的方法(底部)的比较。针对克隆数绘制的、归一化至AG12:AG1结合信号主产物标准品比率中位值的AG12:AG1结合信号比率中位值。
图9仅手动分析(顶部)与根据本发明的方法(底部)的比较。针对克隆数绘制的、归一化至AG2:AG1结合信号副产物I标准品比率中位值的AG2:AG1结合信号比率中位值。
图10仅手动分析(顶部)与根据本发明的方法(底部)的比较。针对克隆数绘制的、归一化至AG2:AG1结合信号副产物II标准品比率中位值的AG12:AG1结合信号比率中位值。
图11根据本发明的方法用于基于产物质量选择克隆的用途(第1部分)。示出了用于两种分析抗体浓度(50ng/mL、1.95ng/mL)的分类。显示了产生不同抗体质量的总共610个克隆(图11和图12一起)。
图12根据本发明的方法用于基于产物质量选择克隆的用途(第2部分)。示出了用于两种分析抗体浓度(9.9ng/mL、0.39ng/mL)的分类。显示了产生不同抗体质量的总共610个克隆(图11和图12一起)。
图13根据本发明的方法用于基于产物质量选择克隆的用途(第3部分)。示出了用于两种分析抗体浓度(50ng/mL、1.95ng/mL)的结果。显示了基于抗体质量用根据本发明的方法选择的总共160个克隆(图13和图14一起)。
图14根据本发明的方法用于基于产物质量选择克隆的用途(第4部分)。示出了用于两种分析抗体浓度(9.9ng/mL、0.39ng/mL)的结果。显示了基于抗体质量用根据本发明的方法选择的总共160个克隆(图13和图14一起)。
图15双特异性抗体形式及其常见副产物。
图16基于克隆的产物滴度。
图17SEC确定的单体含量(x轴)与通过图16的克隆的CE-SDS(y轴)确定的主产物量的关系;用根据本发明的方法
图18SEC确定的单体含量(x轴)与通过图16的克隆的HIC(y轴)确定的主产物量的关系;用根据本发明的方法
图19SEC确定的单体含量(x轴)与通过图16的克隆的CE-SDS(y轴)确定的主产物量的关系;用根据本发明的方法选择的克隆以粗体示出。
图20SEC确定的单体含量(x轴)与通过图16的克隆的HIC(y轴)确定的主产物量的关系;用根据本发明的方法选择的克隆以粗体示出。
实例
实例1
一般技术
1)重组DNA技术
使用标准方法来操纵DNA,如描述于Sambrook等人,Molecular Cloning:ALaboratory Manual,Second Edition,Cold Spring Harbor Laboratory Press,ColdSpring Harbor,N.Y,(1989)。根据制造商的说明来使用分子生物学试剂。
2)DNA序列测定
DNA测序在SequiServe GmbH(Vaterstetten,Germany)进行
3)DNA和蛋白质序列分析及序列数据管理
EMBOSS(欧洲分子生物学开放软件套件)软件包和Invitrogen的Vector NTI 11.5版用于序列创建、映射、分析、注释和图示。
4)基因和寡核苷酸合成
在Geneart GmbH(Regensburg,德国)通过化学合成制备期望的基因片段。将合成的基因片段克隆到大肠杆菌质粒中进行繁殖/扩增。通过DNA测序来验证亚克隆基因片段的DNA序列。可替代地,通过对化学合成的寡核苷酸进行退火或经由PCR来组装短的合成DNA片段。各个寡核苷酸由metabion Gmb H(Planegg-Martinsried,德国)制备。
5)试剂
如果没有另外说明,所有商业化学品、抗体和试剂盒均按照制造商的方案使用。
6)宿主细胞系的培养
CHO宿主细胞在37℃下在湿度为85%和5% CO
7)克隆
核酸的克隆已经基于本领域技术人员已知的程序或根据制造商的方案完成。
一般来说,利用R位点进行克隆取决于目标基因(GOI)旁边的DNA序列,该序列等同于位于以下片段中的序列。类似地,通过等同序列的重叠和随后由DNA连接酶密封组装的DNA中的切口,片段的组装是可能的。在成功克隆这些初步载体后,通过直接在R位点旁边酶切,经由限制性消化切掉侧翼为R位点的目的基因。为了在一个步骤中组装所有DNA片段,5'-核酸外切酶去除重叠区域(R位点)的5'端。之后,可以进行R位点的退火,DNA聚合酶延伸3'端以填补序列中的空白。最后,DNA连接酶密封核苷酸之间的缺口。添加包含不同酶(如外切核酸酶、DNA聚合酶和连接酶)的组装主混合物,随后在50℃下孵育反应混合物,将单个片段组装成一个质粒。之后,用质粒转化感受态大肠杆菌细胞。
对于某些载体,使用了经由限制酶的克隆策略。通过选择合适的限制性内切酶,可以切下目标基因,然后通过连接将其插入不同的载体中。因此,优选地使用并以巧妙的方式选择在多克隆位点(MCS)中切割的酶,使得可以在正确的阵列中进行片段的连接。如果载体和片段之前用相同的限制酶切割,则片段和载体的粘性末端契合在一起并且随后可以通过DNA连接酶连接。连接后,用新产生的质粒转化感受态大肠杆菌细胞。
为了转化,根据制造商的方案使用了10-β感受态大肠杆菌细胞。只有已经成功掺入质粒从而携带针对氨苄青霉素的抗性基因的细菌才能在相应的板上生长。挑取单菌落并在LB-Amp培养基中培养,以用于随后的质粒制备。
细菌培养
大肠杆菌的培养在LB培养基(Luria Bertani的缩写)中进行,该培养基中刺入1ml/L的100mg/ml的氨苄青霉素,使得氨苄青霉素浓度为0.1mg/ml。
在15ml管(带通风盖)中填充3.6ml的LB-Amp培养基并等同地接种细菌菌落。在孵育过程中,牙签没有被移除,而是留在管中。管在37℃、200rpm下孵育23小时。从孵育器中取出15ml的管,并将3.6ml的细菌培养物分装到两个2ml的Eppendorf管中。在室温,在台式微量离心机中以6,800xg将管离心3分钟。之后,根据制造商的说明使用Qiagen QIAprep SpinMiniprep Kit进行Mini-Prep。用Nanodrop测量质粒DNA浓度。
乙醇沉淀
将一定体积的DNA溶液与2.5倍体积的100%乙醇混合。混合物在-20℃孵育10min。然后以14,000rpm,4℃将DNA离心30min。小心去除上清液,用70%乙醇洗涤沉淀。再次以14,000rpm,4℃将管离心5min。通过移液小心除去上清液并干燥沉淀。待乙醇蒸发后,加入适量的无内毒素水。给予DNA时间在4℃下重新溶解在水中过夜。取一小部分并用Nanodrop装置测量DNA浓度。
实例2
质粒产生
表达盒组成
为了表达抗体链,使用了包含以下功能性元件的转录单位:
-来自人类巨细胞病毒的即刻早期增强子和启动子,包括内含子A,
-人重链免疫球蛋白5'-非翻译区(5'UTR),
-鼠免疫球蛋白重链信号序列,
-编码相应抗体链的核酸,
-牛生长激素多腺苷酸化序列(BGH pA),和
-任选地,人胃泌素终止子(hGT)。
除了包括所期望的待表达基因的表达单元/盒外,基础/标准哺乳动物表达质粒还包含
-来自载体pUC18的复制起点,其允许在大肠杆菌中进行该质粒的复制,以及
-β-内酰胺酶基因,其赋予大肠杆菌中的氨苄青霉素抗性。
正向和反向载体克隆
为构建双质粒抗体构建体,将抗体HC和LC克隆到包含L3和LoxFAS序列的前载体骨架以及包含LoxFAS和2L序列与可选择标志物的后载体中。将Cre重组酶质粒pOG231(Wong、E.T.、等人,Nucl.Acids Res.33(2005)e147;O'Gorman、S.、等人,Proc.Natl.Acad.Sci.USA94(1997)14602-14607)用于所有RMCE过程。
通过基因合成(Geneart,Life Technologies Inc.)产生编码各个抗体链的cDNA。在37℃下用HindIII-HF和EcoRI-HF(NEB)将基因合成载体和骨架载体消化1小时,并且通过琼脂糖凝胶电泳分离。从琼脂糖凝胶切下插入物和骨架的DNA片段,并且通过QIAquick凝胶提取试剂盒(Qiagen)提取。经纯化的插入片段和骨架片段经由快速连接试剂盒(Roche),按照制造商的方案以3:1的插入片段/骨架比连接。然后经由在42℃下热激30秒将连接方法转化到感受态大肠杆菌DH5α中,并且在37℃下温育1小时,之后将它们铺板在含有氨苄青霉素的琼脂平板上以供选择。在37℃下将平板温育过夜。
第二天,挑取克隆并且在37℃下振荡孵育过夜,以进行制备,该制备是分别用
在第二个克隆步骤中,用KpnI-HF/SalI-HF和SalI-HF/MfeI-HF消化先前克隆的载体,条件与第一次克隆相同。用KpnI-HF和MfeI-HF消化骨架载体。如上进行分离和提取。按照制造方案,使用T4 DNA连接酶(NEB)以1:1:1的插入物/插入物/骨架比在4℃下过夜,来将经纯化的插入物和骨架连接,并且在65℃下灭活10min。如上进行以下克隆步骤。
实例3
培养、转染、选择和单细胞克隆
宿主细胞在标准加湿条件(95%rH、37℃和5% CO
为了稳定转染,将等摩尔量的正向和反向载体混合。将1μg Cre表达质粒加入5μg混合物中。
转染前两天将宿主细胞以4x10E5个细胞/ml的密度接种在新鲜培养基中。根据制造商的方案,使用Nucleofector Kit V(Lonza,Switzerland)通过Nucle ofector装置进行转染。3x10E7细胞用30μg质粒转染。转染后将细胞接种在不含选择剂的30ml的培养基中。
接种后第5天,将细胞离心并以6x10E5个细胞/ml转移到80mL化学成分确定的培养基中,该培养基含有有效浓度的选择剂1和选择剂2,用于选择重组细胞。从这一天起,将细胞在37℃、150rpm、5% CO2和85%湿度孵育,不分裂传代。定期监测培养物的细胞密度和活力。当培养物的活力再次开始增加时,选择剂1和2的浓度减少到之前使用量的大约一半。
开始选择后十天,通过测量细胞内标志物和与细胞表面结合的双特异性抗体的表达的流式细胞术,检查Cre介导的盒交换的成功。针对人抗体轻链和重链的APC抗体(别藻蓝蛋白标记的F(ab’)2片段山羊抗人IgG)用于FACS染色。使用BD FACS Canto II流式细胞仪(BD,Heidelberg,德国)进行流式细胞术。测量了每个样品的一万个事件。在前向散射(FSC)对侧向散射(SSC)图中对活细胞进行门控。活细胞门由未转染的宿主细胞定义并通过采用FlowJo 7.6.5EN软件(TreeStar,Olten,Switzerland)应用于所有样品。在FITC通道中量化细胞内标志物的荧光(在488nm处激发,在530nm处检测)。在APC通道中测量双特异性抗体(在645nm处激发,在660nm处检测)。亲本CHO细胞,即用于生成宿主细胞的那些细胞,用作关于细胞内标志物和双特异性抗体表达的阴性对照。选择开始后十四天,活力超过90%,视为选择完成。
实例4
FACS 筛选
进行FACS分析以检查转染效率。将转染方法的4×10E5个细胞离心(1200rpm,4min),并且用1mL PBS洗涤两次。在用PBS进行的洗涤步骤之后,将沉淀物再悬浮于400μLPBS中并且转移到FACS管(带细胞滤网帽的
实例5
单细胞克隆
通过在384孔板中以0.6个细胞/孔进行有限稀释,对抗性池进行单细胞克隆。在接种之前,用5-氯甲基荧光素二乙酸酯(CMFDA)(活细胞荧光染料)对池进行染色。接种后,将板离心,并且在荧光和明场两种模式下从每个孔获取图像。荧光成像允许检测活细胞并区分细胞样伪影,如在明场图像中观察到的。播种后大约两周,通过明场成像来确定汇合。将已经被鉴定为源自单细胞的菌落扩增至96孔板并通过ELISA分析滴度和与靶抗原的结合。
实例6
基于ELISA的滴度确定
将0.25μg/mL生物素化F(ab')2山羊抗人IgG(Fcy规格;JacksonImmunoResearch,#109-066-098)和检测抗体POD缀合的F(ab')2山羊抗人IgG(Fcy规格;Jackson ImmunoResearch,#109-036-098)在稀释缓冲液(=1xPBS(0.01M KH
实例7
基于ELISA的结合测定
将0.03μg/mL生物素化抗原1-人Fc区(huFc)缀合物或0.25μg/mL生物素化抗原2-人Fc区缀合物和检测抗体抗人F(ab)2-HRP(Jackson ImmunoResearch,#109-036-006;1:5000i.A.)在稀释缓冲液(=1xPBS(0.01M KH
实例8
桥接ELISA AG12
将非生物素化抗原2-huFc缀合物以0.5μg/mL的浓度在稀释缓冲液中直接包被到微量滴定板(Nunc,MaxiSorp,#464718)并在4℃下孵育过夜,无需搅拌。在洗涤板(3x90μL/孔,各自使用洗涤缓冲液;1xPBS(0.01M KH
实例9
机器学习
输入数据
对于每个细胞克隆,将来自抗体滴度、与抗原1的结合、与抗原2的结合以及与抗原1和2的同时结合的ELISA测定的空白校正读数用作输入数据。
作为目标变量(在机器学习中称为标记),利用由来自历史项目的人类专家将细胞克隆上清液分类为五种不同的产品类别(先导物、副产物I、副产物II、无结合和不确定的)。
除了输入数据之外,还执行对数据的进一步操纵(特征工程)并将其输入到模型中。
特征工程
已经将八种不同的数据处理变体用于构建预测模型。因此,以不同方式转化来自ELISA测定的空白校正读数,如下表所示。
详细地,处理变体如下:
处理变体编号1:仅使用上清液的结合和桥连ELISA测定数据(候选克隆的上清液的吸光度校正ELISA信号)和确定的总抗体滴度;这是基线实验;利用的数据是所有连续实验的一部分。
处理变体编号2-8:将三种标准品先导物(100%纯化的主产物)、副产物I(100%纯化的副产物I,臼-臼同二聚体)和副产物II(100%纯化的副产物II,杵-杵同二聚体)的测定读数添加到数据集(变体2)或以修改形式使用(变体3-8);每种标准品以14种不同浓度确定(标准曲线);对于变体2-5,选择线性测定中的这些浓度中的四种进行计算。
对于变体6-8,使用所有14种分析浓度的中位值,因此不需要选择步骤。
变体编号3-8包含数据,该数据针对来自一种或所有三种标准品的数据归一化。变体3利用针对先导物标准品归一化的样品值,而变体4用针对所有三种标准品归一化的值进行工作。
变体编号5-8包含比率而不是简单的值,该值被用作针对所有三种标准归一化的值。在9个可能的归一化比率中,变体7包含所有9个比率,而变体8利用仅4个选择的比率。
训练
为了进行训练,将三个项目汇集,并且将第四个项目保留以用于最终模型评估(未见过的测试数据集)。然后将训练数据用于模型构建和超参数优化。使用来自H2O.ai的无人驾驶AI来自动生成机器学习模型。使用每个处理变体(参见上表)来生成数据集,在该数据集上执行训练和评估。
测试
然后,通过将交叉熵损失函数应用于未见过的测试数据集(项目四),仅对最终模型(具有最佳超参数集)进行评分。
参考文献
Scikit-learn:Machine Learning in Python,Pedregosa等人,JMLR 12,pp.2825-2830,2011。
- 表达载体、异源基因产物的制备方法以及高产重组细胞的选择方法
- 选择表达异源蛋白质的真核细胞的方法