基于虚拟人的人脸及肢体识别状态监测主动反馈的方法
文献发布时间:2024-04-18 20:01:23
技术领域
本发明涉及虚拟人物数字数据处理技术领域,尤其涉及一种基于虚拟人的人脸及肢体识别状态监测主动反馈的方法。
背景技术
人脸和肢体识别技术是一种通过计算机对人脸图像和肢体图像进行识别和比对的技术。该类技术主要基于图像处理算法和人工神经网络模型,可以实现对人脸和肢体的检测、特征提取、匹配和识别等功能。虚拟人技术是指将计算机程序或系统与人类语言和行为进行交互的技术。在现有技术中,虚拟人技术被广泛应用于教育、娱乐、售后服务等领域。虚拟人技术可以实现语音识别和合成、自然语言处理、智能问答等功能,从而提供更加人性化的交互体验。
现有的人脸识别技术主要用于识别和验证用户身份,但对用户状态监测和主动反馈的支持较弱。例如,在家中用户可能会因为身体不适或意外摔倒而需要及时得到帮助。因此,有必要设计一种基于虚拟人的人脸识别状态监测主动反馈的方法,以提供更加全面和贴心的服务。现有技术中也有一些类似的人脸识别状态监测系统。例如,实时肢体识别技术可以通过摄像头捕捉用户的动作,并通过算法分析用户的姿态,从而判断是否需要及时给予帮助。但这种技术缺乏情感识别和语音交互功能,难以提供更加完备的服务。另外,还有一些人脸识别与情感识别结合的应用,例如企业面试系统,可以通过人脸识别和情感识别技术来评估候选人的情绪状态。但这些应用多数是单向的,即仅提供信息输出,而没有主动反馈和互动功能。
本发明就是基于上述情况作出的。
发明内容
本发明克服了现有技术的不足,提供了一种既具有用户状态监测又具有主动反馈功能的基于虚拟人的人脸识别状态监测主动反馈的方法。
本发明是通过以下技术方案实现的:
一种基于虚拟人的人脸及肢体识别状态监测主动反馈的方法,包括控制系统、云端数据库、图像处理模块以及显示设备,所述显示设备上还设有摄像模块、显示模块以及语音交互模块;
所述基于虚拟人的人脸及肢体识别状态监测主动反馈的方法包括以下步骤:
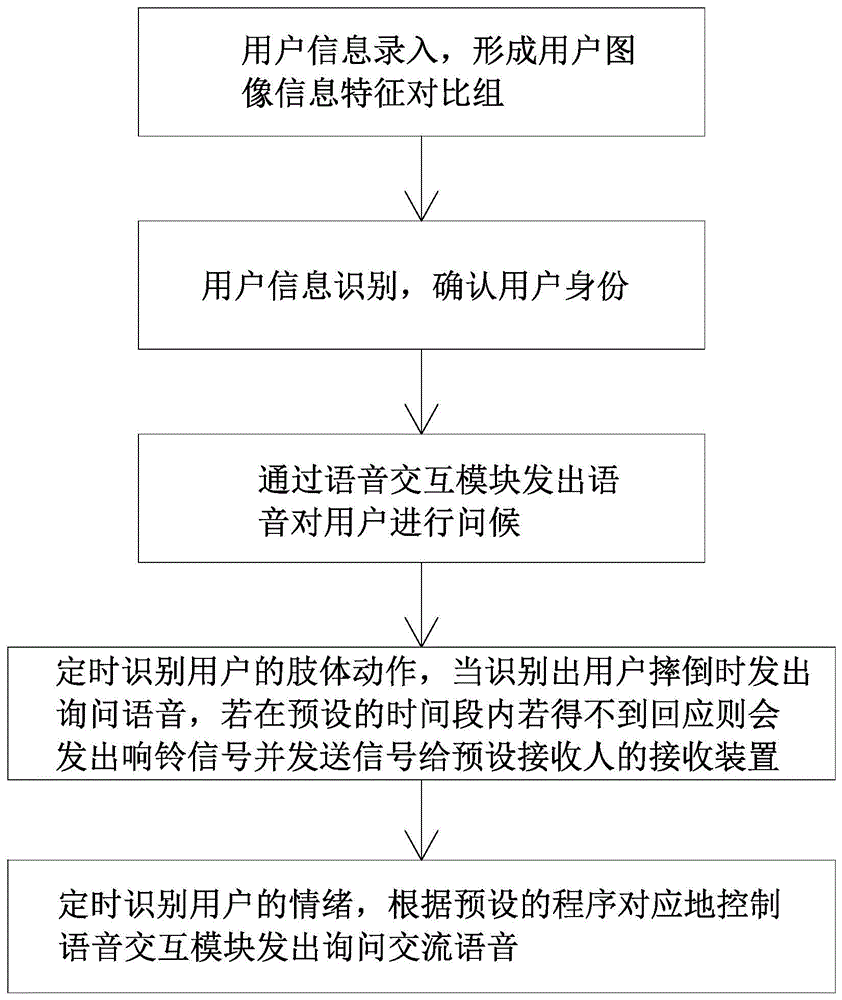
S1、用户信息录入;
通过摄像模块采集用户的图像信息并传输至图像处理模块,图像处理模块对图像信息进行预处理以及特征提取从而形成用户图像特征组,将提取后的用户图像特征组存储至云端数据库中,形成用户图像信息特征对比组;
S2、用户图像信息识别;
重新通过摄像模块采集用户的图像信息并传输至图像处理模块,图像处理模块对输入的图像信息进行预处理并进行特征提取从而形成待识别图像特征组,图像处理模块将提取后的待识别图像特征组与用户信图像息特征对比组进行匹配和比较,图像处理模块将确认用户身份的OK/NG发送给控制系统;
S3、对用户进行问候服务;
控制系统接收到图像处理模块发送的用户身份OK信息后,根据预设的问候程序,通过语音交互模块发出语音对用户进行问候;
S4、定时识别用户的肢体动作;
控制系统根据预设的程序每间隔一个时间段,控制摄像模块采集用户的图像信息并传输至图像处理模块,图像处理模块对输入的图像信息进行预处理并进行特征提取从而形成肢体识别图像特征组,图像处理模块将提取后的肢体识别图像特征组与云端数据库中预设的肢体特征组进行匹配和比较,当识别出用户摔倒时发送信号给控制系统,控制系统根据预设的程序控制语音交互模块发出询问语音,若在预设的时间段内若得不到回应则会发出响铃信号并发送信号给预设接收人的接收装置;
S5、定时识别用户的情绪;
控制系统根据预设的程序每间隔一个时间段,控制摄像模块采集用户的图像信息并传输至图像处理模块,图像处理模块对输入的图像信息进行预处理并进行特征提取从而形成情绪识别图像特征组以及肢体识别图像特征组,图像处理模块将提取后的情绪识别图像特征组与云端数据库中预设的情绪特征组进行匹配和比较,并将识别出的用户情绪信息发送给控制系统,控制系统根据预设的程序对应地控制语音交互模块发出询问交流语音。
如上所述的基于虚拟人的人脸及肢体识别状态监测主动反馈的方法,其特征在于:所述步骤S1、S2、S4以及S5中图像处理模块对输入的图像信息进行预处理的步骤为:
S100、通过加权法,将图像信息灰度化,从而减少光照因素对于图像特征的影响;
S101、使用直方图均衡化对图像信息进行亮度和对比度归一化,从而将图像信息的亮度和对比度调整到相同的水平;
S102、对图像信息进行平滑处理,从而减少噪声和细节信息。
如上所述的基于虚拟人的人脸及肢体识别状态监测主动反馈的方法,其特征在于:所述步骤S1、S2、S4以及S5中图像处理模块对输入的图像信息进行特征提取的步骤为:
S200、使用高斯滤波对图像信息进行消除噪声,然后通过Sobel算子计算图像中每个像素点的水平和垂直方向的梯度;
S201、将图像分成若干个大小相等的cell,对每个cell内的梯度方向进行统计,并生成一个直方图;
S202、对于每个cell的直方图,将其与周围的2×2个cell的直方图进行块归一化;
S203、将所有cell内的直方图拼接成一个大的特征向量。
如上所述的基于虚拟人的人脸及肢体识别状态监测主动反馈的方法,其特征在于:所述步骤S4中,通过YOLO目标检测算法对用户的肢体动作进行识别。
如上所述的基于虚拟人的人脸及肢体识别状态监测主动反馈的方法,其特征在于:所述YOLO目标检测算法的步骤为:
S300、对预设的多组图像进行大小缩放、裁剪以及归一化处理,从而网络的稳定性;
S301、使用TensorFlow深度学习框架,搭建能用于肢体识别的YOLO网络结构;
S302、通过将标注好的图像数据输入到YOLO网络中,进行反向传播更新权值,得到训练好的模型;
S303、用训练好的模型对输入的图像信息进行测试,获取检测出的人体位置和姿态信息;
S304、对检测出的结果采用NMS算法排除重复的检测结果和低置信度的预测框,得到最终的肢体检测和识别结果。
如上所述的基于虚拟人的人脸及肢体识别状态监测主动反馈的方法,其特征在于:所述步骤S5中,通过关键点选择算法对用户的面部表情进行识别。
如上所述的基于虚拟人的人脸及肢体识别状态监测主动反馈的方法,其特征在于:所述语音交互模块包含语音识别ASR模块、自然语言处理NLP模块以及语音合成TTS模块。
如上所述的基于虚拟人的人脸及肢体识别状态监测主动反馈的方法,其特征在于:所述显示模块包括LED显示屏。
与现有技术相比,本发明有如下优点:
本案能通过对用户进行身份识别,识别通过后能对用户发出打招呼问好,并定时检测用户的肢体动作,从而判断用户是否跌倒,从而发出信息给预设的接收者,进而使用户能及时得到帮助,减少一些事故的发生,同时,其还就有情绪识别功能,能对应地控制语音交互模块与用户进行交流,从而提供更加人性化和贴心的服务。
附图说明
下面结合附图对本发明的具体实施方式作进一步详细说明,其中:
图1是本发明的流程示意图。
具体实施方式
下面结合附图对本发明作进一步描述:
如图1所示的一种基于虚拟人的人脸识别状态监测主动反馈的方法,包括控制系统、云端数据库、图像处理模块以及显示设备,所述显示设备上还设有摄像模块、显示模块以及语音交互模块;所述的显示设备可以是机器人,机器人与通讯网络和数据网络连接。所述语音交互模块包含语音识别ASR模块、自然语言处理NLP模块以及语音合成TTS模块,所述显示模块包括LED显示屏。
所述基于虚拟人的人脸及肢体识别状态监测主动反馈的方法包括以下步骤:
S1、用户信息录入;
通过摄像模块采集用户的图像信息并传输至图像处理模块,图像处理模块对图像信息进行预处理以及特征提取从而形成用户图像特征组,将提取后的用户图像特征组存储至云端数据库中,形成用户图像信息特征对比组;
S2、用户图像信息识别;
用户在身份识别时,通过摄像模块采集用户的图像信息并传输至图像处理模块,图像处理模块对输入的图像信息进行预处理并进行特征提取从而形成待识别图像特征组,图像处理模块将提取后的待识别图像特征组与用户信图像息特征对比组进行匹配和比较,图像处理模块将确认用户身份的OK/NG发送给控制系统;
S3、对用户进行问候服务;
控制系统接收到图像处理模块发送的用户身份OK信息后,根据预设的问候程序,通过语音交互模块发出语音对用户进行问候;例如,当会对用户发出“欢迎使用…虚拟人助手”、“请问有啥能帮到您?主人!”,根据时间发出“早上好!/中午好!/晚上好!”等问候。
S4、定时识别用户的肢体动作;
控制系统根据预设的程序每间隔一个时间段,控制摄像模块采集用户的图像信息并传输至图像处理模块,图像处理模块对输入的图像信息进行预处理并进行特征提取从而形成肢体识别图像特征组,图像处理模块将提取后的肢体识别图像特征组与云端数据库中预设的肢体特征组进行匹配和比较,当识别出用户摔倒时发送信号给控制系统,控制系统根据预设的程序控制语音交互模块发出询问语音,若在预设的时间段内若得不到回应则会发出响铃信号并发送信号给预设接收人的接收装置;例如,当识别出用户跌倒在地后,虚拟人发出“主人您怎么了?需要我帮您联系…进行救助吗?”这时用户可以说出不需要或帮我联系某某,虚拟人根据用户的指令进行下一步操作,或者预先设定10分钟、15分钟等时间点,到达时间点后,虚拟人没有得到用户回应则主动发出响铃信号并发送信号给预设接收人的接收装置,所述的接收装置可以是手机或电脑等,从而使用户得到及时的帮助。
S5、定时识别用户的情绪;
控制系统根据预设的程序每间隔一个时间段,控制摄像模块采集用户的图像信息并传输至图像处理模块,图像处理模块对输入的图像信息进行预处理并进行特征提取从而形成情绪识别图像特征组以及肢体识别图像特征组,图像处理模块将提取后的情绪识别图像特征组与云端数据库中预设的情绪特征组进行匹配和比较,并将识别出的用户情绪信息发送给控制系统,控制系统根据预设的程序对应地控制语音交互模块发出询问交流语音。例如,当识别到用户处于高兴的情绪时,虚拟人会发出“主人!您看起来很高兴呢,能跟我分享下喜悦的事情吗?”,当识别到用户处于低落的情绪时,虚拟人会发出“主人!您看起来有心事,能跟我说说吗?我或许能帮助到您”等,从而提供更加人性化和贴心的服务。
上述步骤S1、S2、S4以及S5中图像处理模块对输入的图像信息进行预处理的步骤为:
S100、通过加权法,将图像信息灰度化,从而减少光照因素对于图像特征的影响,使得算法更加的稳健;由于人眼对于不同颜色通道的敏感度不同,我们可以根据通道的重要性对彩色图像进行加权转换。在一般情况下,可以使用下列的加权系数:灰度值=0.299R+0.587G+0.114B。
S101、使用直方图均衡化对图像信息进行亮度和对比度归一化,从而将图像信息的亮度和对比度调整到相同的水平;这样可以将不同图像的亮度和对比度调整到相同的水平,从而进一步减少图像特征受光照等因素的影响,并且这个方法可以使图像的像素值分布更加均匀,从而提高图像的视觉质量,直方图均衡化可以通过将图像的像素值映射到一个新的像素值范围来实现。
S102、对图像信息进行平滑处理,从而减少噪声和细节信息。可以通常使用高斯平滑算法或其他滤波器来实现。这样可以保持图像结构的统一性,有利于特征提取算法的稳健性和准确性。
上述步骤S1、S2、S4以及S5中图像处理模块对输入的图像信息进行特征提取的步骤为:
S200、使用高斯滤波对图像信息进行消除噪声,然后通过Sobel算子计算图像中每个像素点的水平和垂直方向的梯度;通过计算图像的横向和纵向的导数值,然后再通过求平方和开根号得到每个像素点的梯度强度和梯度方向。梯度强度和方向可以反映图像的纹理和结构信息。
S201、将图像分成若干个大小相等的cell,对每个cell内的梯度方向进行统计,并生成一个直方图;每个cell内含有多个像素点,将它们的梯度方向分成9个bins进行统计。
S202、对于每个cell的直方图,将其与周围的2×2个cell的直方图进行块归一化;从而可以保持光照不变性,并减少因窗口大小不同而导致的精度差异。
S203、将所有cell内的直方图拼接成一个大的特征向量。通常,一个图像会被分成多个block,每个block内包含多个cell,拼接后的特征向量大小为所有cell内bins数量的总和。
上述步骤S4中,通过YOLO目标检测算法对用户的肢体动作进行识别。本案中该算法在建立训练模型之前所用到的图像为预先输入的图像以及从网络获取的相关图像。
所述YOLO目标检测算法的步骤为:
S300、对预设的多组图像进行大小缩放、裁剪以及归一化处理,从而网络的稳定性;将归一化后的图像调整为模型输入所需的尺寸,在YOLOv3中,模型输入大小默认为416×416。
S301、使用TensorFlow深度学习框架,搭建能用于肢体识别的YOLO网络结构;在YOLOv3网络中,为了增强特征层和检测结果的多样性,使用不同尺度和横跨不同层级的特征进行融合。
S302、通过将标注好的图像数据输入到YOLO网络中,进行反向传播更新权值,得到训练好的模型;
S303、用训练好的模型对输入的图像信息进行测试,获取检测出的人体位置和姿态信息;该步所输入的图像信息为通过摄像模块定时拍的图像。
S304、对检测出的结果采用NMS算法排除重复的检测结果和低置信度的预测框,得到最终的肢体检测和识别结果。
上述步骤S5中,预先输入建立情绪识别训练模型所需的图像。通过关键点选择算法对这些图像中的面部表情进行识别。选择眉毛、眼睛、鼻子、嘴巴为关键点并进行定义;选择关键点后,标注人脸的特征点位置,使用随机森林算法对标注好的训练数据进行训练,以学习人脸关键点的位置信息;并建立人脸关键点的坐标信息;通过关键点连通算法将关键点进行连通,构成人脸部位的轮廓线,并与摄像模块定时抓拍输入的图像信息进行对比得到最终的用户面部情绪检测和识别结果。