处理用户话语的电子设备及其控制方法
文献发布时间:2023-06-19 10:32:14
技术领域
在本说明书中公开的实施例涉及用于处理用户话语的技术。
背景技术
如今,除了使用键盘或鼠标的输入方案之外,电子设备还可以支持诸如语音输入等的各种输入方案。例如,诸如智能电话和平板电脑之类的电子设备可以启动与语音识别服务相关联的应用,可以通过该应用接收用户的语音输入,可以执行与语音输入相对应的操作或者提供与语音输入相对应的发现结果。
如今,语音识别服务正在支持一种用于处理自然语言的技术。用于处理自然语言的技术是指掌握用户话语意图并向用户提供与意图相匹配的结果的技术。
发明内容
技术问题
大词汇量连续语音识别(LVCSR)系统需要相对大量的计算和存储容量,因此很难在诸如智能手机或平板电脑之类的用户终端中实现LVCSR系统。当在用户终端中未实现LVCSR系统时,用户终端可能难以清楚地掌握接收到的语音输入中包括的词的含义。因此,用户终端可能难以确定接收到的语音输入中是否包括不适当的词(例如,辱骂)。
技术方案
根据本公开的各种实施例,用户终端可以确定语音输入中是否包括不适当的词以注册唤醒词,从而防止将不适当的词注册为唤醒词(或开启语音识别服务的开启话语)。
根据本说明书中公开的各种实施例,电子设备可以包括通信接口、至少一个存储器、麦克风、扬声器、显示器、主处理器以及通过识别在语音输入中包含的唤醒词而启用主处理器的副处理器。至少一个存储器可以存储指令,该指令在被执行时使主处理器:通过麦克风接收注册唤醒词的第一语音输入;确定第一语音输入是否包括指定词;当第一语音输入不包括指定词时,通过麦克风接收包括与第一语音输入相同的词的第二语音输入,基于第一语音输入和第二语音输入来生成用于识别唤醒词的唤醒词识别模型,并将生成的唤醒词识别模型存储在至少一个存储器中;以及当第一语音输入包括指定词时,通过扬声器或显示屏输出用于请求与第一语音输入不同的第三语音输入的信息。
此外,根据本说明书中公开的各种实施例,一种用于处理语音输入的方法可以包括:接收注册唤醒词的第一语音输入;确定第一语音输入是否包括指定词;当第一语音输入不包括指定词时,接收包括与第一语音输入相同的词的第二语音输入,基于第一语音输入和第二语音输入生成用于识别唤醒词的唤醒词识别模型,并将生成的唤醒词识别模型存储在至少一个存储器中;以及当第一语音输入包括指定词时,通过扬声器或显示器输出用于请求与第一语音输入不同的第三语音输入的信息。
有益效果
根据本说明书中公开的各种实施例,当接收注册用于启用主处理器的唤醒词的语音输入时,用户终端可以确定接收到的语音输入是否包括不适当的词,从而防止不适当的词被注册为唤醒词。
此外,可以提供通过说明书直接或间接理解的各种效果。
附图说明
图1是示出根据实施例的集成智能系统的框图。
图2是示出根据实施例的概念与动作之间的关系信息被存储在数据库中的形式的示图。
图3是示出根据实施例的显示用于处理通过智能应用接收到的语音输入的屏幕的用户终端的视图。
图4是示出根据各种实施例的智能系统的配置的框图。
图5是示出根据实施例的用户终端注册唤醒词的方法的流程图。
图6是示出根据实施例的用户终端注册唤醒词的屏幕的示图。
图7是示出根据实施例的在用户终端接收包括不适当词的语音输入的情况下的屏幕的视图。
图8是示出根据实施例的用户终端训练唤醒词的方法的流程图。
图9是示出根据实施例的注册用户终端的唤醒名称的方法的流程图。
图10是示出根据实施例的利用唤醒名称来生成响应的方法的流程图。
图11是示出根据实施例的智能服务器基于识别出的唤醒词来生成响应的方法的顺序图。
图12是示出根据实施例的用户终端在其上基于唤醒词来提供响应的屏幕的示图。
图13是示出根据实施例的智能服务器确定响应中包括的唤醒名称的方法的流程图。
图14是根据各种实施例的在网络环境中的电子设备的框图。
关于附图的描述,相同或相似的部件将用相同或相似的附图标识来标记。
具体实施方式
在下文中,可以参考附图描述本公开的各种实施例。然而,应当理解,这并不旨在将本公开限制为特定的实现形式,而是包括本公开的实施例的各种修改、等同形式和/或替代形式。
图1是示出根据实施例的集成智能系统的框图。
参照图1,根据实施例的集成智能系统10可以包括用户终端100、智能服务器200和服务服务器300。
根据实施例的用户终端100可以是能够连接到互联网的终端设备(或电子设备),并且可以是例如移动电话、智能电话、个人数字助理(PDA)、笔记本电脑、电视、白色家用电器、可穿戴设备、HMD或智能扬声器。
根据所示的实施例,用户终端100可以包括通信接口110、麦克风120、扬声器130、显示器140、存储器150或处理器160。所列出的组件可以可操作地或电力地彼此连接。
根据实施例的通信接口110可以连接到外部设备,并且可以被配置为向外部设备发送数据或从外部设备接收数据。根据实施例的麦克风120可以接收声音(例如,用户话语)以将声音转换为电信号。根据实施例的扬声器130可以将电信号输出为声音(例如,语音)。根据实施例的显示器140可以被配置为显示图像或视频。根据实施例的显示器140可以显示正在运行的应用(或应用程序)的图形用户界面(GUI)。
根据实施例的存储器150可以存储客户端模块151、软件开发套件(SDK)153和多个应用155。客户端模块151和SDK 153可以构成用于执行通用功能的框架(或解决方案程序)。此外,客户端模块151或SDK 153可以构成用于处理语音输入的框架。
在根据实施例的存储器150中,多个应用155可以是用于执行指定功能的程序。根据实施例,多个应用155可以包括第一应用155_1和第二应用155_3。根据实施例,多个应用155中的每一个可以包括用于执行指定功能的多个动作。例如,这些应用可以包括警报应用、消息应用和/或日程应用。根据实施例,多个应用155可以由处理器160执行以顺序地执行多个动作的至少一部分。
根据实施例,处理器160可以控制用户终端100的整体操作。例如,处理器160可以电连接到通信接口110、麦克风120、扬声器130和显示器140以执行指定操作。
此外,根据实施例的处理器160可以执行存储在存储器150中的程序以执行指定功能。例如,根据实施例,处理器160可以执行客户端模块151或SDK 153中的至少一个,以执行以下用于处理语音输入的操作。处理器160可以经由SDK 153控制多个应用155的操作。被描述为客户端模块151或SDK 153的操作的以下操作可以由处理器160执行。
根据实施例,客户端模块151可以接收语音输入。例如,客户端模块151可以接收与通过麦克风120检测到的用户话语相对应的语音信号。客户端模块151可以将接收到的语音输入发送到智能服务器200。客户端模块151可以将用户终端100的状态信息和接收到的语音输入发送到智能服务器200。例如,状态信息可以是应用的执行状态信息。
根据实施例,客户端模块151可以接收与接收到的语音输入相对应的结果。例如,当智能服务器200能够计算与接收到的语音输入相对应的结果时,客户端模块151可以接收与接收到的语音输入相对应的结果。客户端模块151可以在显示器140上显示接收到的结果。
根据实施例,客户端模块151可以接收与接收到的语音输入相对应的计划。客户端模块151可以在显示器140上显示根据计划执行应用的多个动作的结果。例如,客户端模块151可以在显示器上顺序显示执行多个动作的结果。对于另一个示例,用户终端100可以在显示器上仅显示执行多个动作的结果的一部分(例如,最后动作的结果)。
根据实施例,客户端模块151可以从智能服务器200接收用于获得计算与语音输入相对应的结果所需的信息的请求。根据实施例,客户端模块151可以响应于请求将必要的信息发送给智能服务器200。
根据实施例,客户端模块151可以向智能服务器200发送关于根据计划执行多个动作的结果的信息。智能服务器200可以使用结果信息来识别接收到的语音输入被正确地处理。
根据实施例,客户端模块151可以包括语音识别模块。根据实施例,客户端模块151可以经由语音识别模块来识别语音输入以执行有限功能。例如,客户端模块151可以经由指定输入(例如,唤醒!)来启动智能应用,其处理语音输入以执行有机操作。
根据实施例,智能服务器200可以通过通信网络从用户终端100接收与用户的语音输入相关联的信息。根据实施例,智能服务器200可以将与接收到的语音输入相关联的数据转换为文本数据。根据实施例,智能服务器200可以基于文本数据生成用于执行与用户的语音输入相对应的任务的计划。
根据实施例,计划可以由人工智能(AI)系统生成。AI系统可以是基于规则的系统,或者可以是基于神经网络的系统(例如,前馈神经网络(FNN)或递归神经网络(RNN))。可选地,AI系统可以是上述系统的组合或不同于上述系统的AI系统。根据实施例,计划可以从一组预定义的计划中选择或者可以响应于用户请求而实时地生成。例如,AI系统可以在多个预定义的计划中选择至少一个计划。
根据实施例,智能服务器200可以将根据生成的计划的结果发送到用户终端100,或者可以将生成的计划发送到用户终端100。根据实施例,用户终端100可以在显示器上显示根据计划的结果。根据实施例,用户终端100可以在显示器上显示根据计划执行动作的结果。
根据实施例的智能服务器200可以包括前端210、自然语言平台220、胶囊数据库(DB)230、执行引擎240、终端用户界面250、管理平台260、大数据平台270或分析平台280。
根据实施例,前端210可以接收从用户终端100接收的语音输入。前端210可以发送与语音输入相对应的响应。
根据实施例,自然语言平台220可以包括自动语音识别(ASR)模块221、自然语言理解(NLU)模块223、计划器模块225、自然语言生成器(NLG)模块227或文字转语音模块(TTS)模块229。
根据实施例,ASR模块221可以将从用户终端100接收到的语音输入转换为文本数据。根据实施例,NLU模块223可以使用语音输入的文本数据来掌握用户的意图。例如,NLU模块223可以通过执行句法分析或语义分析来掌握用户的意图。根据实施例,NLU模块223可以通过使用诸如词素(morpheme)或短语的语言特征(例如,句法元素)来掌握从语音输入中提取的词的含义,并且可以通过将所掌握的词的含义与意图进行匹配来确定用户的意图。
根据实施例,计划器模块225可以利用由NLU模块223确定的意图和参数来生成计划。根据实施例,计划器模块225可以基于确定的意图,来确定执行任务所需的多个域。计划器模块225可以确定在基于意图而确定的多个域中的每个域中包括的多个动作。根据实施例,计划器模块225可以确定执行所确定的多个动作所需的参数或通过执行多个动作而输出的结果值。参数和结果值可以定义为指定形式(或类)的概念。这样,计划可以包括由用户的意图确定的多个动作和多个概念。计划器模块225可以逐步地(或分级地)确定多个动作与多个概念之间的关系。例如,计划器模块225可以基于多个概念来确定基于用户的意图确定的多个动作的执行顺序。换句话说,计划器模块225可以基于执行多个动作所需的参数和通过执行多个动作而输出的结果来确定多个动作的执行顺序。因此,计划器模块225可以生成包括关于多个动作与多个概念之间的关系的信息(例如,本体(ontology))的计划。计划器模块225可以使用存储在胶囊DB 230中的信息来生成计划,该信息存储有概念与动作之间的一组关系。
根据实施例,NLG模块227可以将指定的信息改变为文本形式的信息。改变为文本形式的信息可以是自然语言语音的形式。根据实施例的TTS模块229可以将文本形式的信息改变为语音形式的信息。
胶囊DB 230可以存储对应于多个域的关于动作与多个概念之间的关系的信息。根据实施例,胶囊可以包括计划中包括的多个动作对象(或动作信息)和概念对象(或概念信息)。根据实施例,胶囊DB 230可以以概念动作网络(CAN)的形式存储多个胶囊。根据实施例,多个胶囊可以被存储在胶囊DB 230中包括的功能注册表中。
胶囊DB 230可以包括策略注册表,其存储确定与语音输入相对应的计划所需的策略信息。当存在与语音输入相对应的多个计划时,策略信息可以包括用于确定一个计划的参考信息。根据实施例,胶囊DB 230可以包括存储后续动作的信息的后续注册表,其用于在指定的上下文中向用户表明后续动作。例如,后续动作可以包括后续话语。根据实施例,胶囊DB 230可以包括布局注册表,其存储经由用户终端100输出的信息的布局信息。根据实施例,胶囊DB 230可以包括词汇注册表,其存储包括在胶囊信息中的词汇信息。根据实施例,胶囊DB 230可以包括对话注册表,其存储关于与用户的对话(或交互)的信息。胶囊DB 230可以更新经由开发者工具存储的对象。例如,开发者工具可以包括用于更新动作对象或概念对象的功能编辑器。开发者工具可以包括用于更新词汇表的词汇表编辑器。开发者工具可以包括生成并注册用于确定计划的策略的策略编辑器。开发者工具可以包括与用户创建对话的对话编辑器。开发者工具可以包括能够启用后续目标并编辑后续话语以提供提示的后续编辑器。可以基于当前设置的目标、用户的偏好或环境条件来确定后续目标。根据实施例的胶囊DB 230也可以实现在用户终端100中。
根据实施例,执行引擎240可以利用生成的计划来计算结果。终端用户界面250可以将计算出的结果发送给用户终端100。因此,用户终端100可以接收该结果并且可以向用户提供接收到的结果。根据实施例,管理平台260可以管理由智能服务器200使用的信息。根据实施例,大数据平台270可以收集用户的数据。根据实施例,分析平台280可以管理智能服务器200的服务质量(QoS)。例如,分析平台280可以管理智能服务器200的组件和处理速度(或效率)。
根据实施例,服务服务器300可以向用户终端100提供指定的服务(例如,点餐或旅馆预订)。根据实施例,服务服务器300可以是由第三方操作的服务器。根据实施例,服务服务器300可以向智能服务器200提供用于生成与接收到的语音输入相对应的计划的信息。所提供的信息可以被存储在胶囊DB 230中。此外,服务服务器300可以根据计划向智能服务器200提供结果信息。
在上述集成智能系统10中,用户终端100可以响应于用户输入向用户提供各种智能服务。用户输入可以包括例如通过物理按钮的输入、触摸输入或语音输入。
根据实施例,用户终端100可以经由存储在其中的智能应用(或语音识别应用)来提供语音识别服务。在这种情况下,例如,用户终端100可以识别经由麦克风接收的用户话语或语音输入,并且可以向用户提供与所识别的语音输入相对应的服务。
根据实施例,用户终端100可以基于接收到的语音输入,独立地或者与智能服务器和/或服务服务器一起执行指定动作。例如,用户终端100可以启动与接收到的语音输入相对应的应用,并且可以经由执行的应用执行指定动作。
根据实施例,当用户终端100与智能服务器200和/或服务服务器一起提供服务时,用户终端100可以利用麦克风120检测用户话语并且可以生成与检测到的用户话语相对应的信号(或者语音数据)。用户终端可以使用通信接口110将语音数据发送到智能服务器200。
根据实施例,作为对从用户终端100接收的语音输入的响应,智能服务器200可以生成用于执行与语音输入相对应的任务的计划或者根据该计划执行动作的结果。例如,计划可以包括用于执行与用户的语音输入相对应的任务的多个动作以及与该多个动作相关联的多个概念。概念可以定义在执行多个动作时要输入的参数或者通过执行多个动作而输出的结果值。该计划可以包括多个动作与多个概念之间的关系信息。
根据实施例,用户终端100可以使用通信接口110来接收响应。用户终端100可以通过利用扬声器130将在用户终端100中产生的语音信号输出到外部,或者通过利用显示器140将在用户终端100中生成的图像输出到外部。
图2是示出根据各种实施例的概念与动作之间的关系信息被存储在数据库中的形式的示图。
智能服务器200的胶囊数据库(例如,胶囊DB 230)可以以概念动作网络(CAN)的形式存储胶囊。胶囊DB可以以CAN形式存储用于处理与用户的语音输入相对应的任务的动作和该动作所需的参数。
胶囊DB可以存储分别与多个域(例如,应用)相对应的多个胶囊(胶囊A 401和胶囊B 404)。根据实施例,一个胶囊(例如,胶囊A401)可以对应于一个域(例如,位置(地理)或应用)。此外,用于执行与胶囊相关联的域的功能的至少一个服务提供商(例如,CP 1 402或CP2 403)可以对应于一个胶囊。根据实施例,单个胶囊可以包括至少一个或更多个动作410和用于执行指定功能的至少一个或更多个概念420。
自然语言平台220可以使用存储在胶囊数据库中的胶囊来生成用于执行与接收到的语音输入相对应的任务的计划。例如,自然语言平台的计划器模块225可以通过使用存储在胶囊数据库中的胶囊来生成计划。例如,计划器模块225可以使用胶囊A410的动作4011和4013以及概念4012和4014以及胶囊B 404的动作4041和概念4042来生成计划407。
图3是示出根据各种实施例的用户终端处理通过智能应用接收到的语音输入的屏幕的视图。
用户终端100可以通过智能服务器200执行智能应用以处理用户输入。
根据实施例,在屏幕310上,当识别指定的语音输入(例如,唤醒!)或经由硬件键(例如,专用硬件键)接收输入时,用户终端100可以启动用于处理语音输入的智能应用。例如,用户终端100可以在执行日程应用的状态下启动智能应用。根据实施例,用户终端100可以在显示器140上显示与智能应用相对应的对象(例如,图标)311。根据实施例,用户终端100可以接收通过用户话语输入的语音。例如,用户终端100可以接收说“让我知道本周的日程!”的语音输入。根据实施例,用户终端100可以在显示器上显示智能应用的用户界面(UI)313(例如,输入窗口),其中显示了接收到的语音输入的文本数据。
根据实施例,在屏幕320上,用户终端100可以在显示器上显示与接收到的语音输入相对应的结果。例如,用户终端100可以接收与接收到的用户输入相对应的计划,并且可以根据计划在显示器上显示“本周的日程”。
图4是示出根据各种实施例的智能系统的配置的框图。
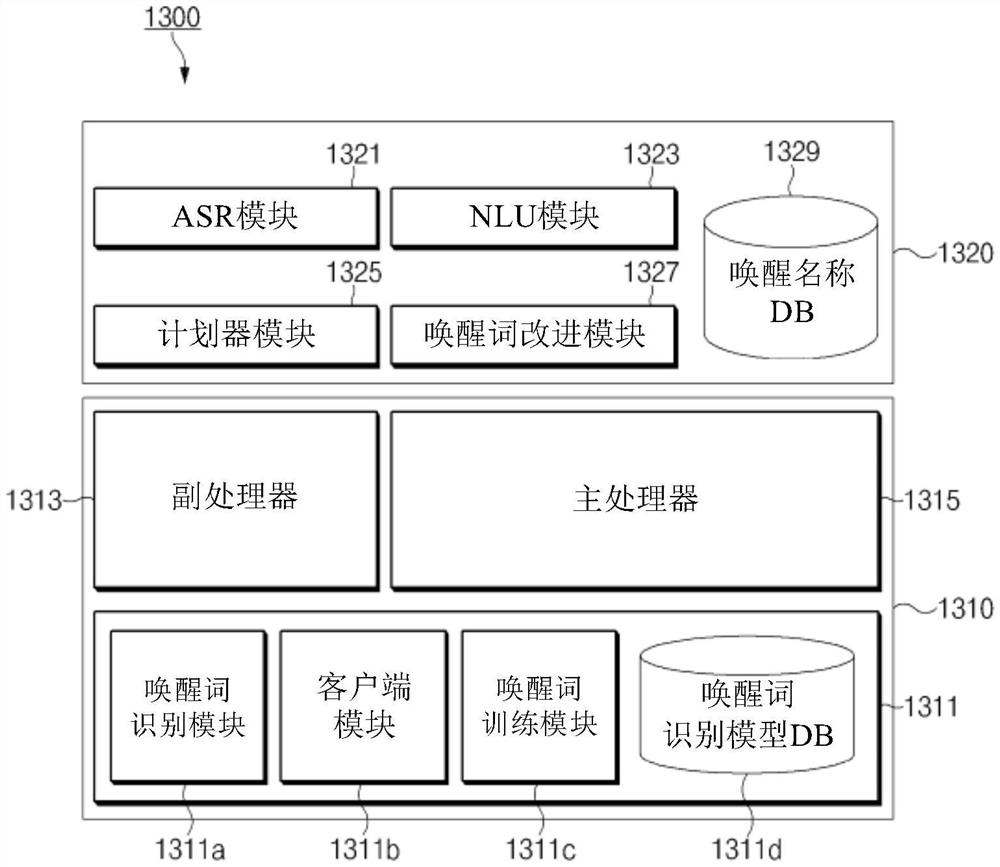
参照图4,智能系统1300可以包括用户终端1310和智能服务器1320。用户终端1310和智能服务器1320可以与图1的用户终端100和智能服务器200类似。
根据实施例,用户终端1310可以包括存储器1311(例如,图1的存储器150)、副处理器1313(例如,图1的处理器160)和主处理器1315(例如,图1的处理器160)。根据实施例,用户终端1310的配置不限于此,并且可以进一步包括图1的用户终端100的配置。
根据实施例,存储器1311可以存储唤醒词识别模块1311a、客户端模块1311b、唤醒词训练模块1311c和唤醒词识别模型数据库(DB)1311d。唤醒词识别模块1311a、客户端模块1311b和唤醒词训练模块1311c可以是用于执行通用功能的框架。根据实施例,可以由处理器(例如,副处理器1313和主处理器1315)执行唤醒词识别模块1311a、客户端模块1311b和唤醒词训练模块1311c,以实现其功能。根据实施例,唤醒词识别模块1311a、客户端模块1311b和唤醒词训练模块1311c还可以不仅由软件而且由硬件来实现。
根据实施例,由唤醒词识别模块1311a识别的唤醒词可以是调用语音识别服务的唤醒话语。例如,唤醒词可以是用于将主处理器1315改变为处于能够处理语音输入的状态的输入。
根据实施例,存储器1311可以包括用于存储唤醒词识别模型DB 1311d的单独的存储器。存储器1311可以包括:第一存储器,其存储用于控制处理器(例如,副处理器1313和主处理器1315)的操作的指令;以及第二存储器,其存储唤醒词识别模型DB 1311。例如,第一存储器可以存储唤醒词识别模块1311a、客户端模块1311b和唤醒词训练模块1311c。第二存储器可以在物理上与第一存储器分离。根据实施例,在电子设备1300被启用之前,副处理器1313可以访问第二存储器。例如,副处理器1313可以读取存储在第二存储器中的信息(例如,唤醒词识别模型信息),以识别用于启用电子设备1300的语音输入。对于另一示例,存储器1311可以包括存储唤醒词识别模块1311a、客户端模块1311b、唤醒词训练模块1311c以及唤醒词识别模型DB 1311d的一个存储器。换句话说,存储器1311可以不单独包括用于唤醒词识别模型DB 1311的存储器。
根据实施例,副处理器1313可以控制用户终端1310的有限操作。例如,副处理器160可以通过识别指定词(或唤醒词)来启用主处理器1315。换句话说,用户终端1310的状态可以从副处理器1313仅执行有限操作(例如,维持系统启动状态)的第一状态(例如,停用状态、待机状态或睡眠状态)改变为执行提供多个服务的操作(例如,消息发送/接收功能和电话呼叫功能)的第二状态(例如,启用状态)。根据实施例,副处理器1313可以是功耗比主处理器1315少的处理器。
根据实施例,副处理器1313可以执行唤醒词识别模块1311a以执行识别唤醒词的操作。被描述为唤醒词识别模块1311a的操作的以下操作可以由副处理器1313执行。
根据实施例,唤醒词识别模块1311a可以识别有限数量的词。例如,唤醒词识别模块1311a可以识别用于启用主处理器1315的唤醒词。根据实施例,唤醒词识别模块1311a可以使用唤醒词识别模型。唤醒词识别模型可以包括识别唤醒词所需的信息。例如,当基于隐马尔可夫模型(HMM)算法执行语音识别功能时,唤醒词识别模型可以包括状态初始概率、状态转变概率、观察概率等。对于另一示例,当基于神经网络算法执行语音识别功能时,唤醒词识别模块可以包括神经网络模型信息,例如层、节点的类型和结构、每个节点的权重、网络连接信息以及非线性启用函数。根据实施例,当通过唤醒词识别模块1311a识别唤醒词时,副处理器1313可以启用主处理器1315。
根据实施例,唤醒词识别模块1311a可以通过测量多个语音输入之间的相似度来确定多个语音输入是否彼此相同。例如,唤醒词识别模块1311a可以提取多个语音输入的特征向量,并且可以通过使用动态时间规整(DTW)来测量所提取的特征向量之间的相似度。对于另一示例,当基于HMM算法执行语音识别功能时,唤醒词识别模块1311a可以通过使用向前-向后概率来测量多个语音输入之间的相似度。对于另一示例,当基于神经网络算法来执行唤醒词识别模块1311a时,唤醒词识别模块1311a可以利用通过音素识别器测量的音素水平来测量多个语音输入之间的相似度。根据实施例,当所测量的相似度不小于指定值时,唤醒词识别模块1311a可以确定多个语音输入彼此相同。根据实施例,唤醒词识别模块1311a可以确定用于训练唤醒词的多个语音输入是否包括相同的词。根据实施例,可以由主处理器1315执行唤醒词识别模块1311a的用于训练唤醒词的操作。
根据实施例,主处理器1315可以执行客户端模块1311b以执行处理语音输入的操作。语音输入可以是用于执行指定任务的命令的用户输入。被描述为客户端模块1311b的操作的以下操作可以由主处理器1315执行。
根据实施例,客户端模块1311b可以将用于执行指定任务的语音输入发送到智能服务器1320。根据实施例,客户端模块1311b可以通过智能服务器1320接收与语音输入相对应的计划。该计划可以包括用于执行指定任务的动作信息。根据实施例,客户端模块1311b可以根据接收到的计划来执行应用的操作以执行指定任务,并且因此可以向用户提供执行指定任务的结果。
根据实施例,当接收到注册唤醒词的语音输入时,客户端模块1311b可以将语音输入发送到智能服务器1320。例如,客户端模块1311b可以通过通信接口(例如,图1的通信接口110)将语音输入发送到智能服务器1320。根据实施例,客户端模块1311b可以从智能服务器1320接收确定语音输入是否包括指定词的结果。例如,客户端模块1311b可以通过通信接口接收确定结果。根据实施例,客户端模块1311b可以基于确定结果来确定唤醒词是否能够被注册。因此,当接收到的语音输入能够被注册为唤醒词时,客户端模块1311b可以通过唤醒词训练模块1311c基于接收到的语音输入来注册唤醒词。
根据实施例,主处理器1315可以执行唤醒词训练模块1311c以执行注册(或生成)唤醒词的操作。用户可以将用户期望的词注册为用于启用主处理器1315的唤醒词。被描述为唤醒词训练模块1311c的操作的以下操作可以由主处理器1315执行。
根据实施例,唤醒词训练模块1311c可以执行用于注册唤醒词的唤醒词识别训练。唤醒词训练模块1311c可以基于重复接收到的语音输入来执行唤醒词识别训练。例如,当基于HMM算法执行语音识别功能时,唤醒词训练模块1311c可以通过使用期望最大化(EM)算法执行模型训练或通过使用最大似然线性回归(MLLR)和最大后验估计(MAP)执行自适应训练来生成唤醒词识别模型。对于另一示例,当基于神经网络算法执行语音识别功能时,唤醒词训练模块1311c可以使用前馈或反向传播算法来执行模型训练,或者可以使用线性变换来执行自适应训练。根据实施例,唤醒词训练模块1311c可以确定在通过唤醒词识别模块1311a重复接收到的语音输入中是否包括相同的唤醒词。因此,唤醒词训练模块1311c可以基于包括相同唤醒词的语音输入来执行唤醒词识别训练。根据实施例,唤醒词训练模块1311c可以通过唤醒词识别训练来生成唤醒词识别模型。
根据实施例,唤醒词识别模型DB 1311d可以存储所生成的唤醒词识别模型。根据实施例,唤醒词识别模块1311a可以通过使用存储在唤醒词识别模型DB 1311d中的唤醒词识别模型信息来识别唤醒词。
根据实施例,智能服务器1320可以包括ASR模块1321(例如,图1的ASR模块221)、NLU模块1323(例如,图1的NLU模块223)、计划器模块1325(例如,图1的计划器模块225)、唤醒词改进模块1327和唤醒词DB1329。根据实施例,智能服务器1320的配置不限于此,可以进一步包括图1的智能服务器200的配置。
根据实施例,ASR模块1321可以将语音输入改变为文本数据。根据实施例,可以利用HMM算法、加权有限状态换能器(wFST)算法、神经网络算法等来实现ASR模块1321。例如,ASR模块1321可以通过使用距离测量方法将指定词与语音输入进行比较来将语音输入改变为文本数据。例如,距离测量方法可以包括诸如Levenshtein距离、Jaro-Winkler距离等的测量方法。对于另一个示例,距离测量方法可以包括以下方法:通过字素到音素(G2P)将文本转换为发音字符串,然后在音素级别测量文本之间的距离。
根据实施例,ASR模块1321可以包括LVCSR系统。因此,ASR模块1321可以使用比用户终端1310的唤醒词识别模块1311a更复杂的计算过程,并且可以识别很多词。
根据实施例,NLU模块1323可以通过使用从ASR模块1321传递的文本数据来确定与语音输入相对应的参数和意图。
根据实施例,计划器模块1325可以基于由NLU模块1323确定的参数和意图来生成与语音输入相对应的计划。该计划可以包括用于执行与语音输入相对应的任务的动作信息。根据实施例,计划器模块1325可以布置用于逐步执行任务的动作,并且可以确定定义用于执行布置的动作的参数输入或通过执行而输出的结果值的概念。因此,计划器模块1325可以生成计划。
根据实施例,唤醒词改进模块1327可以基于在指定条件下接收到的语音输入来确定唤醒词是否能够被注册。例如,唤醒词改进模块1327可以基于接收到的语音输入,通过确定语音输入是否包括指定词来确定唤醒词是否能够被注册。唤醒词改进模块1327可以获得通过ASR模块1321接收的语音输入的文本数据,并且可以确定指定词是否包括在文本数据中。例如,指定词可能不适合被设置为唤醒词,并且可能包括贬低制造商的词(例如,竞争对手的产品名称)、辱骂等。根据实施例,当语音输入包括指定词时,唤醒词改进模块1327可以基于接收到的语音输入来确定唤醒词不能被注册。此外,当语音输入不包括指定词时,唤醒词改进模块1327可以使用接收到的语音输入来确定唤醒词能够被注册。根据实施例,唤醒词改进模块1327可以将确定结果发送到用户终端1310。
根据实施例,唤醒词改进模块1327可以通过改进注册的唤醒词来生成用户终端1310的唤醒名称。根据实施例,智能服务器1320可以通过使用唤醒名称来生成与语音输入相对应的响应。换句话说,智能服务器1320可以将包括唤醒名称的响应提供给用户终端1310。例如,唤醒名称可以用作语音助手的名称。根据实施例,唤醒词改进模块1327可以将所确定的唤醒名称存储在唤醒名称DB 1329中。
根据实施例,智能服务器1320可以生成用于从用户接收指定语音输入的指导信息。例如,智能服务器1320可以生成用于接收唤醒词训练的语音输入的指导信息。当接收到包括不适当词的语音输入时,智能服务器3120可以生成用于接收与不适当词不同的语音输入的指导信息。根据实施例,智能服务器1320可以将所生成的指导信息发送到用户终端1310。用户终端1310可以输出指导信息。
用户终端1310可以通过确定不适当的词是否被包括在用于注册唤醒词的语音输入中来防止不适当的词被注册为唤醒词。
图5是示出根据实施例的用户终端注册唤醒词的方法的流程图1400。
参照图5,用户终端(例如,图4的用户终端1310)可以通过智能服务器(例如,图4的智能服务器1320)确定语音输入中是否包括不适当的词,并且可以注册唤醒词。
根据实施例,在操作1410中,用户终端可以接收注册唤醒词的第一语音输入。例如,用户终端可以接收“Galaxy”。根据实施例,用户终端可以将接收到的第一语音输入发送到智能服务器。
根据实施例,在操作1420中,智能服务器可以识别接收到的第一语音输入。例如,智能服务器可以通过ASR模块(例如,图4的ASR模块1321)将第一语音输入转换为文本数据(例如,Galaxy)。
根据实施例,在操作1430中,智能服务器可以确定所识别的第一语音输入是否包括指定词。例如,指定词可以是不适当的词(或禁止被注册为唤醒词的词)。根据实施例,智能服务器可以将确定结果发送到用户终端。根据实施例,用户终端可以基于确定结果执行以下注册唤醒词的操作。
根据实施例,当第一语音输入包括指定词(是)时,在操作1441中,用户终端可以请求重发话语以接收不同于指定词的语音输入。用户终端可以通过扬声器(例如,图1的扬声器130)或显示器(例如,图1的显示器140)输出重发话语请求(例如,“请尝试另一个唤醒词!”)。
根据实施例,当第一语音输入不包括指定词(否)时,在操作1443中,用户终端可以请求用于唤醒词识别训练的另外的话语。例如,用户终端可以输出第一指导信息(例如,“请再次说“Galaxy””),以通过扬声器或显示器接收与第一语音输入(例如,Galaxy)相同的第二语音输入。例如,可以通过使用第一语音输入来生成第一指导信息。根据实施例,用户终端可以从智能服务器接收第一指导信息。智能服务器可以通过使用从用户终端接收的第一语音输入来生成第一指导信息。
根据实施例,在操作1450中,用户终端可以接收包括与第一语音输入相同的信息的第二语音输入。例如,用户终端可以再次接收“Galaxy”。
根据实施例,在操作1460中,用户终端可以基于第一语音输入和第二语音输入来注册唤醒词。例如,用户终端可以基于第一语音输入和第二语音输入来生成用于识别唤醒词的唤醒词识别模型,并且可以将所生成的唤醒词识别模型存储在存储器中。例如,可以通过使用基于HMM算法或神经网络算法中的至少一种的模型训练或自适应训练算法来生成唤醒词识别模块。
根据实施例,用户终端可以在操作1441中接收与重发话语请求相对应的第三语音输入,并且可以接收用于唤醒词训练的第四语音输入。用户终端可以执行操作1420和操作1430以处理第三语音输入,并且可以执行操作1443、操作1450和操作1460以处理第四语音输入。因此,用户终端可以注册唤醒词。例如,用户终端可以通过智能服务器接收第三语音输入并且可以确定第三语音输入是否包括指定词。当第三语音输入不包括指定词时,用户终端可以接收包括与第三语音输入相同的词的第四语音输入,并且可以基于第三语音输入和第四语音输入来注册唤醒词。
因此,当在待机状态下接收包括注册的唤醒词的语音输入时,用户终端可以识别唤醒词,然后用户终端的状态可以改变为启用状态。
图6是示出根据实施例的用户终端注册唤醒词的屏幕的示图。
参照图6,用户终端1310可以通过显示器(例如,图1的显示器140)输出用于注册唤醒词的用户界面(UI)。
根据实施例,在屏幕1510上,用户终端1310可以输出用于开始唤醒词的注册的UI。用户终端1310可以在UI上显示用于注册唤醒词的用户话语的指导信息1511。根据实施例,用户终端1310可以通过对象1513(例如,虚拟按钮)接收用户输入以开始唤醒词的注册。
根据实施例,在执行图5的操作1410的步骤中,用户终端1310可以在屏幕1520上输出用于接收第一语音输入的UI,以注册唤醒词。用户终端1310可以在UI上显示用于接收第一语音输入的第一指导信息1521和用于显示注册唤醒词的步骤的指示符1523。指示符1523可以指示接收第一语音输入的步骤。根据实施例,用户终端1310可以接收第一语音输入。例如,用户终端1310可以接收“你好,Bixby!”。根据实施例,用户终端1310可以通过智能服务器(例如,图4的智能服务器1320)来确定第一语音输入是否包括指定词。
根据实施例,在执行图5的操作1450的步骤中,用户终端1310可以在屏幕1530上输出用于接收包括与第一语音输入相同的词的第二语音输入的UI。用户终端1310可以在UI上显示用于接收第二语音输入的第二指导信息1531以及指示接收第二语音输入的步骤的指示符1533。例如,第二指导信息1531可以包括与第一语音输入相对应的文本数据(例如,你好,Bixby)。根据实施例,用户终端1310可以接收第二语音输入。例如,用户终端1310可以再次接收“你好,Bixby!”。
根据实施例,在执行图5的操作1460的步骤中,用户终端1310可以在屏幕1540上输出指示执行唤醒词识别训练的过程的UI。用户终端1310可以在UI上显示指示训练正在进行中的第三指导信息1541和指示训练步骤的指示符1543。根据实施例,用户终端1310可以基于第一语音输入和第二语音输入来注册唤醒词。例如,用户终端1310可以基于第一语音输入和第二语音输入来生成唤醒词识别模型。用户终端1310可以将所生成的唤醒词识别模型存储在存储器(例如,图4的存储器1311)中。
根据实施例,用户终端1310可以在屏幕1550上输出指示注册唤醒词的结果的UI。用户终端1310可以在UI上显示包括注册唤醒词的结果的第三指导信息1551,以及执行指定功能的语音输入的示例1553。根据实施例,用户终端1310可以通过对象1555(例如,虚拟按钮)接收用户输入以完成对唤醒词的注册。
因此,当用户终端1310识别出所注册的唤醒词时,用户终端1310的状态可以从待机状态改变为启用状态。
图7是示出根据实施例的在用户终端接收包括不适当词的语音输入的情况下的屏幕的视图。
参照图7,当用于注册唤醒词的语音输入包括不适当的词(或被禁止注册为唤醒词的词)时,用户终端1310可以在显示器(例如,图1的显示器140)上输出用于指导重发话语的UI。
根据实施例,类似于图6的屏幕1510,用户终端1310可以在屏幕1610上输出用于开始唤醒词的注册的UI。根据实施例,用户终端1310可以接收包括指定词的第一语音输入。例如,指定词可能是不适当的词。根据实施例,用户终端1310可以通过智能服务器(例如,图4的智能服务器1320)确定第一语音输入中是否包括指定词。
根据实施例,类似于图5的操作1443,用户终端1310可以在屏幕1620上输出指示接收包括不适当的唤醒词的语音输入的结果的UI。用户终端1310可以在UI上显示用于接收不同的语音输入的指导信息1621,以及指示未注册结果的状态的指示符1623。
因此,用户终端1310可以防止将不适当的词注册为唤醒词,并且可以再次接收语音输入以注册唤醒词。
图8是示出根据实施例的用户终端训练唤醒词的方法的流程图1700。
参照图8,用户终端(例如,图4的用户终端1310)可以确定是否接收到与第一语音输入相同的第二语音输入,并且可以执行用于识别唤醒词的训练。
根据实施例,在操作1710中,类似于图5的操作1410,用户终端可以接收注册唤醒词的第一语音输入。根据实施例,用户终端可以将第一语音输入发送到智能服务器(例如,图4的智能服务器1320)。
根据实施例,在操作1720中,类似于图5的操作1420和操作1430,智能服务器可以识别第一语音输入并且可以确定所识别的第一语音输入是否适合被注册为唤醒词(或注册适合性)。例如,智能服务器可以确定在第一语音输入是否包括指定词。根据实施例,智能服务器可以将确定结果发送到用户终端。根据实施例,用户终端可以基于确定结果执行以下用于注册唤醒词的操作。
根据实施例,当第一语音输入适合于被注册为唤醒词时,在操作1730中,类似于图5的操作1441,用户终端可以请求重发话语以执行唤醒词训练。例如,当第一语音输入不包括指定词时,用户终端可以请求重发话语。
根据实施例,在操作1740中,类似于图5的操作1450,用户终端可以接收第二语音输入。
根据实施例,在操作1750中,用户终端可以确定接收到的第二语音输入是否与第一语音输入相同。例如,用户终端可以通过测量第一语音输入与第二语音输入之间的相似度来确定接收到的第二语音输入是否与第一语音输入相同。换句话说,当所确定的相似度在指定范围内时,用户终端可以确定第一语音输入与第二语音输入相同。
根据实施例,当第一语音输入与第二语音输入不同(否)时,在操作1761中,用户终端可以请求重发话语以接收与第一语音输入相同的语音输入。例如,第一语音输入可以是“Galaxy”,第二语音输入可以是“Note”。用户终端可以通过扬声器(例如,图1的扬声器130)或显示器(例如,图1的显示器140)输出“请再次说“Galaxy”。”。
根据实施例,当第一语音输入与第二语音输入相同(是)时,在操作1763中,用户终端可以基于第一语音输入和第二语音输入来注册唤醒词。例如,用户终端可以基于第一语音输入和第二语音输入来生成唤醒词识别模型,并且可以将所生成的模型存储在存储器中。例如,第一语音输入可以是“Galaxy”,第二语音输入也可以是“Galaxy”。
因此,用户终端可以通过接收正确的语音输入以执行唤醒词训练来注册唤醒词。
图9是示出根据实施例的注册用户终端的唤醒名称的方法的流程图1800。
参照图9,用户终端(例如,图4的用户终端1310)可以通过改进注册的唤醒词来生成用户终端的唤醒名称。
根据实施例,在操作1810中,类似于图8的操作1710,用户终端可以接收注册唤醒词的第一语音输入。根据实施例,用户终端可以将第一语音输入发送到智能服务器(例如,图4的智能服务器1320)。
根据实施例,在操作1820中,类似于图8的操作1720,用户终端可以识别第一语音输入并且可以确定识别出的第一语音输入是否适合被注册为唤醒词。例如,智能服务器可以确定在第一语音输入是否包括指定词。根据实施例,智能服务器可以将确定结果发送到用户终端。根据实施例,用户终端可以基于确定结果执行以下用于注册唤醒词的操作。
根据实施例,在操作1830中,类似于图8的操作1730,当第一语音输入适合被注册为唤醒词时,用户终端可以请求重发话语以执行唤醒词训练。例如,当第一语音不包括指定词时,用户终端可以请求重发话语以执行唤醒词训练。根据实施例,类似于图9的操作1840,用户终端可以接收第二语音输入。
根据实施例,在操作1850中,类似于图8的操作1770,用户终端可以基于第一语音输入和第二语音输入来注册唤醒词。例如,用户终端可以基于第一语音输入和第二语音输入来生成唤醒词识别模型,并且可以将所生成的模型存储在存储器中。根据实施例,在操作1860中,用户终端可以通过扬声器(例如,图1的扬声器130)或显示器(例如,图1的显示器140)输出唤醒词注册完成消息。
根据实施例,在操作1870中,智能服务器可以通过改进所注册的唤醒词来确定用户终端的唤醒名称。例如,当注册的唤醒词为指定格式时,智能服务器可以确定注册的唤醒词的至少一部分是用户终端的唤醒名称。例如,当注册的唤醒词是“嗨!Galaxy!”时,注册的唤醒词可以对应于“嗨!<名称>”的指定格式,因此智能服务器可以确定“Galaxy”是用户终端的唤醒名称。对于另一示例,当注册的唤醒词是“Bixby!你在吗?”,注册的唤醒词可以对应于“
根据另一实施例,操作1870和操作1880可以由用户终端执行。换句话说,用户终端可以执行改进所注册的唤醒词的操作。
因此,用户终端可以通过使用注册的唤醒名称来生成与语音输入相对应的响应。将在图12中描述利用唤醒名称来生成响应的操作。
图10是示出根据实施例的利用唤醒名称来生成响应的方法的流程图。
参照图10,用户终端(例如,图4的用户终端1310)可以通过智能服务器(例如,图4的智能服务器1320)来处理语音输入以执行指定任务。
根据实施例,在操作1910中,用户终端可以通过识别注册的唤醒词来被改变为启用状态。
根据实施例,在操作1920中,用户终端可以接收语音输入以做出对执行指定任务的请求。例如,用户终端可以接收说“让我知道今天首尔的天气!”的语音输入。
根据实施例,在操作1930中,用户终端可以将接收到的语音输入发送到智能服务器。另外,用户终端可以将唤醒词与语音输入一起发送到智能服务器。
根据实施例,在操作1940中,用户终端可以生成与语音输入相对应的计划。例如,用户终端可以通过ASR模块(例如,图4的ASR模块1321)、NLU模块(例如,图4的NLU模块1323)、计划器模块(例如,图4的计划器模块1325)生成与语音输入相对应的计划。例如,智能服务器可以使用语音输入来确定语音输入的用于接收天气信息的意图(例如,intent=WEATHER_MESSAGE)和用于获得天气信息的参数(例如,param.weather.date=2018.02.28,param.weather.location=seoul)。智能服务器可以通过根据所确定的意图逐步地安排获得天气信息的动作(例如,WEATHERMESSAGE)来生成计划和定义用于执行动作的输入/输出值的概念。所获得的参数(例如,2018.02.28,首尔)可以位于相应的概念处。
根据实施例,在操作1950中,智能服务器可以生成与语音输入相对应的响应。根据实施例,智能服务器可以获得执行所生成的计划的结果。例如,智能服务器可以获得“今天的天气信息的页面”。根据实施例,智能服务器可以利用注册的用户终端的唤醒名称来生成指导信息。例如,用户终端可以生成指导信息,说“Galaxy将让你知道天气”。根据实施例,响应不仅可以包括获得的结果,而且还可以包括使用用户终端的唤醒名称的指导信息。根据实施例,智能服务器可以将所生成的响应发送到用户终端。
根据实施例,在操作1960中,用户终端可以输出响应。换句话说,用户终端可以输出通过执行任务而获得结果和使用唤醒名称的指导信息。例如,用户终端可以在显示器上显示“用于显示今天的天气信息的页面”,并且可以通过显示器或扬声器中的至少一个输出说“Galaxy将让你知道天气”的指导信息。
图11是示出根据实施例的智能服务器基于识别出的唤醒词来生成响应的方法的顺序图2000。
根据实施例,在操作2011中,用户终端(例如,图4的用户终端1310)的副处理器1313可以识别注册的唤醒词(例如,Galaxy)。根据实施例,在操作2013中,副处理器1313可以将启用信号传递给用户终端的主处理器1315。因此,可以启用用户终端。
根据实施例,在操作2021中,主处理器1315可以通过麦克风(例如,图1中的麦克风120)接收语音输入。例如,语音输入可以包括对执行指定任务的请求。根据实施例,在操作2023中,主处理器1315可以将接收到的语音输入发送给智能服务器1320。根据实施例,在操作2025中,主处理器1315可以将唤醒词与语音输入一起发送给智能服务器1320。
根据实施例,在操作2031中,智能服务器1320可以生成与语音输入相对应的计划。根据实施例,在操作2033中,智能服务器1320可以生成与语音输入相对应的响应。智能服务器1320可以根据所生成的计划来获得执行动作的结果。此外,智能服务器1320可以通过使用与接收到的唤醒词相对应的唤醒名称来生成指导消息。可以通过改进唤醒词来确定唤醒名称。根据实施例,响应可以包括所生成的指导信息以及所获得的结果。根据实施例,在操作2035中,智能服务器1320可以将所生成的响应发送到用户终端。
根据实施例,在操作2040中,用户终端的主处理器1315可以使用响应来输出使用唤醒名称的指导信息以及执行任务的结果。
图12是示出根据实施例的用户终端在其上基于唤醒词来提供响应的屏幕的示图。
根据实施例,在屏幕2110上,用户终端1310可以从智能服务器(例如,图4的智能服务器1320)接收与语音输入相对应的响应,并且使用响应可以显示通过处理语音输入而获得的结果UI。用户终端1310可以在UI上显示通过执行与语音输入相对应的任务而获得的结果2111(例如,今天的天气信息的页面)。用户终端1310可以通过在UI上使用唤醒名称(例如,Galaxy)来显示指导信息2113(例如,“Galaxy将让你知道天气”)。此外,用户终端1310可以在UI上显示接收到的语音输入的文本数据2115(例如,“让我知道今天首尔的天气!”)。可以从智能服务器接收文本数据。
图13是示出根据实施例的智能服务器确定响应中包括的唤醒名称的方法的流程图2200。
参照图13,用户终端(例如,图4的用户终端1310)可以通过智能服务器(例如,图4的智能服务器1320)确定唤醒词是否包括不适当的词(或被禁止注册为唤醒词的词)(例如,笨蛋),可以根据确定结果来确定唤醒词,并且可以提供指导信息。
根据实施例,在操作2210中,类似于图10中的操作1910,用户终端可以通过识别注册的唤醒词来被改变为启用状态。
根据实施例,在操作2220中,类似于图10中的操作1920,用户终端可以接收语音输入以做出对执行指定任务的请求。
根据实施例,在操作2230中,类似于图10中的操作1930,用户终端可以将唤醒词与接收到的语音输入一起发送到智能服务器。
根据实施例,在操作2240中,类似于图10中的操作1940,用户终端可以生成与语音相对应的计划。
根据实施例,在操作2250中,用户终端可以确定唤醒词是否适合于产生指导信息。例如,用户终端可以确定唤醒词是否包括指定词。例如,指定词可能不适合注册为唤醒词。
根据实施例,当唤醒词不包括指定词(否)时,在操作2261中,用户终端可以使用唤醒词和执行任务的结果来生成包括指导信息的响应。用户终端可以使用唤醒词来生成说“Galaxy将让你知道今天的天气。”的指导信息。
根据实施例,当唤醒词包括指定词(是)时,在操作2263中,用户终端可以使用与唤醒词不同的名称和执行任务的结果生成包括指导信息的响应。例如,可以默认设置名称(例如,Bixby)。用户终端可以生成说“Bixby将让你知道今天的天气”的指导信息,而不是不适当的唤醒词“笨蛋”。
根据实施例,在操作2270中,用户终端可以输出从智能服务器生成的响应。例如,用户终端可以使用唤醒名称以及通过执行任务而获得的结果来输出指导信息。例如,用户终端可以在显示器上显示“用于显示今天的天气信息的页面”,并且可以通过显示屏或扬声器中的至少一个来输出说“Galaxy将让你知道天气。”的指导信息或“Bixby将让你知道天气。”的指导信息。
因此,可以防止用户终端通过使用不适当的词来提供与语音输入相对应的响应。
根据参照图4至图13描述的本公开的各种实施例,当接收注册唤醒词的语音输入以启用主处理器时,用户终端1310可以确定接收到的语音输入是否包括不适当的词,从而防止将不适当的词注册为唤醒词。
图14是示出根据各种实施例的网络环境2300中的电子设备2301的框图。
参照图14,网络环境2300中的电子设备2301可通过第一网络2398(例如,短程无线通信网络)与电子设备2302进行通信,或者可以通过第二网络2399(例如,远程无线通信网络)与电子设备2304或服务器2308进行通信。根据实施例,电子设备2301可通过服务器2308与电子设备2304进行通信。根据实施例,电子设备2301可包括处理器2320、存储器2330、输入设备2350、声音输出设备2355、显示设备2360、音频模块2370、传感器模块2376、接口2377、触觉模块2379、相机模块2380、电力管理模块2388、电池2389、通信模块2390、用户识别模块(SIM)2396或天线模块2397。在任一实施例中,可从电子设备2301中省略所述部件中的至少一个(例如,显示设备2360或相机模块2380),或者可进一步将一个或更多个其它部件纳入到电子设备2301中。在任一实施例中,可将所述部件中的一些部件与单个集成电路一起实现。例如,可将传感器模块2376(例如,指纹传感器、虹膜传感器、或照度传感器)嵌入在显示设备2360(例如,显示器)中。
处理器2320可运行例如软件(例如,程序2340)来控制电子设备2301的与处理器2320连接的至少一个其它部件(例如,硬件部件或软件部件),并可执行各种数据处理或运算。根据实施例,作为所述数据处理或运算的至少一部分,处理器2320可将从任意其他部件(例如,传感器模块2376或通信模块2390)接收到的命令或数据加载到易失性存储器2332中,可以对存储在易失性存储器2332中的命令或数据进行处理,并可以将处理后的数据存储在非易失性存储器2334中。根据实施例,处理器2320可包括主处理器2321(例如,中央处理器或应用处理器)以及可与主处理器2321独立的或者一起操作的辅助处理器2323(例如,图形处理设备、图像信号处理器、传感器中枢处理器或通信处理器)。另外地或者可选择地,辅助处理器2323可被配置为比主处理器2321耗电更少,或者被配置为专用于指定的功能。辅助处理器2323可以与主处理器2321分离实现,或者可以实现为主处理器2321的部分。
在主处理器2321处于停用(例如,睡眠)状态时,辅助处理器2323(例如,而非主处理器2321)可控制与电子设备2301的至少一个部件(例如,显示设备2360、传感器模块2376或通信模块2390)相关联的功能或状态中的至少部分,或者在主处理器2321处于启用状态(例如,应用运行)时,辅助处理器2323可与主处理器2321一起来控制与电子设备2301的至少一个部件(例如,显示设备2360、传感器模块2376或通信模块2390)相关联的功能或状态中的至少部分。根据实施例,可将辅助处理器2323(例如,图像信号处理器或通信处理器)实现为在功能上(或可操作地)与辅助处理器2323相关联的任意其他部件(例如,相机模块2380或通信模块2390)的部分。
存储器2330可存储由电子设备2301的至少一个部件(例如,处理器2320或传感器模块2376)使用的各种数据。所述数据可包括例如软件(例如,程序2340),或与软件的命令相关联的输入数据或输出数据。存储器2330可包括易失性存储器2332或非易失性存储器2334。
可将程序2340作为软件存储在存储器2330中,并且程序2340可包括例如操作系统2342、中间件2344或应用2346。
输入设备2350可从电子设备2301的外部(例如,用户)接收将由电子设备2301的部件(例如,处理器2320)使用的命令或数据。输入设备2350可包括例如麦克风、鼠标或键盘。
声音输出设备2355可将声音信号输出到电子设备2301的外部。声音输出设备2355可包括例如扬声器或接收器。扬声器可用于诸如多媒体播放或唱片播放的通用目的,接收器可用于接收呼入呼叫。根据实施例,接收器可与扬声器分离实现,或可实现为扬声器的部分。
显示设备2360可向电子设备2301的外部(例如,用户)视觉地提供信息。显示设备2360可包括例如显示器、全息设备或用于控制投影仪以及相应设备的控制电路。根据实施例,显示设备2360可包括被配置为感测触摸的触摸电路或被配置为测量由触摸产生的力的强度的传感器电路(例如,压力传感器)。
音频模块2370可将声音转换为电信号,或相反地可将电信号转换为声音。根据实施例,音频模块2370可通过输入设备2350获得声音,或者可通过声音输出设备2355,或通过与电子设备2301直接连接或无线连接的外部电子设备(例如,电子设备2302)(例如,扬声器或耳机)输出声音。
传感器模块2376可检测电子设备2301的操作状态(例如,功率或温度)或外部环境状态(例如,用户状态),并且可以产生与感测到的状态相应的电信号或数据值。根据实施例,传感器模块2376可包括例如手势传感器、握持传感器、气压传感器、磁性传感器、加速度传感器、握持传感器、接近传感器、颜色传感器、红外(IR)传感器、生物特征传感器、温度传感器、湿度传感器或照度传感器。
接口2377可支持可用来使电子设备2301与外部电子设备(例如,电子设备2302)直接或无线连接的一个或更多个特定协议。根据实施例,接口2377可包括例如高清晰度多媒体接口(HDMI)、通用串行总线(USB)接口、安全数字(SD)卡接口或音频接口。
连接端2378可包括连接器,其可使电子设备2301与外部电子设备(例如,电子设备2302)物理连接。根据实施例,连接端2378可包括例如HDMI连接器、USB连接器、SD卡连接器或音频连接器(例如,耳机连接器)。
触觉模块2379可将电信号转换为用户可通过感测触摸或感测运动来感知到的机械刺激(例如,振动或运动)或电刺激。根据实施例,触觉模块2379可包括例如电机、压电传感器或电刺激设备。
相机模块2380可拍摄静止图像或视频。根据实施例,相机模块2380可包括一个或更多个透镜、图像传感器、图像信号处理器或闪光灯(或电闪光灯)。
电力管理模块2388可管理对电子设备2301的供电。根据实施例,可将电力管理模块2388实现为例如电力管理集成电路(PMIC)的至少部分。
电池2389可对电子设备2301的至少一个部件供电。根据实施例,电池2389可包括例如不可再充电的原电池、可再充电的蓄电池、或燃料电池。
通信模块2390可在电子设备2301与外部电子设备(例如,电子设备2302、电子设备2304或服务器2308)之间建立直接(例如,有线)通信信道或无线通信信道,或可通过建立的通信信道执行通信。通信模块2390可包括与处理器2320(例如,应用处理器)独立操作的一个或更多个通信处理器,并支持直接(或有线)通信或无线通信。根据实施例,通信模块2390可包括无线通信模块2392(例如,蜂窝通信模块、短程无线通信模块或全球导航卫星系统(GNSS)通信模块)或有线通信模块2394(例如,局域网(LAN)通信模块或电力线通信模块)。这些通信模块中的相应一个通信模块可通过第一网络2398(例如,短程通信网络,诸如蓝牙、Wi-Fi直连或红外数据协会(IrDA))或第二网络2399(例如,远程通信网络,诸如蜂窝网络、互联网、或计算机网络(例如,LAN或WAN))与外部电子设备进行通信。上述多种通信模块可以集成在一个部件(例如,单个芯片)中,或可与彼此独立的多个部件(例如,多个芯片)一起实现。无线通信模块2392可利用存储在用户识别模块2396中的用户信息(例如,国际移动用户识别码(IMSI))来验证和认证通信网络(诸如第一网络2398或第二网络2399)中的电子设备2301。
天线模块2397可将信号或电力发送到外部(例如,外部电子设备)或者可从外部接收信号或电力。根据实施例,天线模块2397可包括一个或更多个天线,可例如由通信模块2390从所述一个或更多个天线中选择适合于在计算机网络(诸如第一网络2398或第二网络2399)中使用的通信方案的至少一个天线。可通过所选择的至少一个天线在通信模块2390与外部电子设备之间交换信号或电力,可通过所选择的至少一个天线和通信模块2390从外部电子设备接收信号或电力。
部件中的至少一些可通过外围设备之间的通信方案(例如,总线、通用输入输出(GPIO)、串行外设接口(SPI)或移动工业处理器接口(MIPI))相互连接并在它们之间交换信号(例如,命令或数据)。
根据实施例,可通过与第二网络2399连接的服务器2308在电子设备2301与外部电子设备2304之间发送或接收(或交换)命令或数据。电子设备2302和电子设备2304中的每一个可以是与电子设备2301相同类型的设备,或者是与电子设备2301不同类型的设备。根据实施例,将在电子设备2301运行的全部操作或部分操作可在外部电子设备2302,2304或2308中的一个或更多个外部设备中运行。例如,在电子设备2301应该自动执行任意功能或服务或者应该响应于来自用户或任意其他设备的请求执行任意功能或服务的情况下,电子设备2301可请求所述一个或更多个外部电子设备执行所述功能或服务中的至少部分,而不是内部地运行所述功能或服务,或者电子设备2301除了运行所述功能或服务以外,还可请求所述一个或更多个外部电子设备执行所述功能或服务中的至少部分。接收到所述请求的所述一个或更多个外部电子设备可执行所述功能或服务中的所请求的所述至少部分,或者可执行与所述请求相关联的另外功能或服务,并可将执行的结果提供给电子设备2301。电子设备2301可原样或另外处理接收到的结果,并可将处理的结果提供作为对所述请求的至少部分响应。为此,例如,可使用云计算、分布式计算或客户机-服务器计算技术。
根据本公开中公开的各种实施例的电子设备可以是各种类型的设备。电子设备可包括例如便携式通信设备(例如,智能电话)、计算机设备、便携式多媒体设备、移动医疗器械、相机、可穿戴设备或家用电器。根据本公开的实施例的电子设备不应当限于上述设备。
应该理解的是,本公开的各种实施例以及其中使用的术语并不意图将在本公开中公开的技术特征限制于本文中公开的具体实施例,而是本公开应解释为覆盖本公开的实施例的各种改变、等同形式或替换形式。对于附图的描述,相似或相关的部件可以赋予相似的附图标记。如本文中所述,与术语相应的单数形式的名词可包括一个或更多个术语,除非上下文另有明确指示。如在本文中公开的本公开中,本文中使用的表述“A或B”、“A和B中的至少一个”、“A或B中的至少一个”、“A、B或C”、“A、B和C中的一个或更多个”以及“A、B或C中的一个或更多个”等中的每一个可包括与所列出的项目相关联的一个或更多个的任意或所有组合。诸如“第1”和“第2”或者“第一”和“第二”的术语可仅用于将部件与另一部件进行区分,而不在其它方面(例如,重要性或顺序)限制对应部件。将理解的是,在使用了术语“可操作地”或“通信地”的情况下或者在不使用术语“可操作地”或“通信地”的情况下,如果一元件(例如,第一元件)被称为“与另一元件(例如,第二元件)结合”、“结合到另一元件(例如,第二元件)”、“与另一元件(例如,第二元件)连接”或“连接到另一元件(例如,第二元件)”,则意味着该元件可与该另一元件直接(例如,有线地)连接、与该另一元件无线连接、或经由第三元件与该另一元件连接。
本公开中使用的术语“模块”可以包括以硬件、软件或固件实现的单元,并且可以与术语“逻辑”、“逻辑块”、“部件”和“电路”互换使用。“模块”可以是集成部件的最小单元或者可以是其部分。“模块”可以是用于执行一个或更多个功能的最小单元或其部分。例如,根据实施例,“模块”可以包括专用集成电路(ASIC)。
本公开的各种实施例可以通过包括存储在机器可读存储介质(例如,内部存储器2336或外部存储器2338)中的可由机器(例如,电子设备2301)读取的指令的软件(例如,程序2340)来实现。例如,机器(例如,电子设备2301)的处理器(例如,处理器2320)可从机器可读存储介质中调用指令并运行所调用的指令。这意味着所述机器可以基于所调用的至少一个指令执行至少一个功能。所述一个或更多个指令可包括由编译器产生或可由解释器运行的代码。可以以非暂时性存储介质的形式来提供机器可读存储介质。这里,如本文中所使用的术语“非暂时性”意味着所述存储介质是有形的,并且不包括信号(例如,电磁波)。术语“非暂时性”并不在数据被永久性地存储在存储介质中的情况与数据被临时存储在存储介质中的情况之间进行区分。
根据实施例,根据本公开中公开的各种实施例的方法可被提供为计算机程序产品的一部分。计算机程序产品可作为产品在销售者与购买者之间进行交易。可以以机器可读存储介质(例如,紧凑盘只读存储器(CD-ROM))的形式来发布计算机程序产品,或者可通过应用商店(例如,Play Store
根据各种实施例,上述部件中的每个部件(例如,模块或程序)可包括单个实体或多个实体。根据各种实施例,可省略上述部件或操作中的至少一个或更多个部件,或者可添加一个或更多个部件或操作。可选择地或者另外地,可将一些部件(例如,模块或程序)集成为单个部件。在这种情况下,该集成部件可执行每个对应部件在集成之前所执行相同或相似的功能。根据各种实施例,由模块、程序或另一部件所执行的操作可顺序地、并行地、重复地或以启发式方式来执行,或者至少一些操作可按照不同的顺序来运行或被省略,或者可添加其它操作。
- 处理用户话语的电子设备及其控制方法
- 用于处理用户话语的电子装置及其控制方法