基于卷积神经网络的单幅图像三维人脸重建方法及系统
文献发布时间:2023-06-19 10:48:02
技术领域
本发明属于图像处理领域,尤其是涉及一种基于卷积神经网络的单幅图像三维人脸重建方法及系统。
背景技术
近年来,三维人脸重建成为计算机视觉、图像识别等研究领域中的热点问题。三维人脸重建技术可以分为基于不同视角的多幅图像的重建和基于单幅图像的三维人脸重建。现实生活中很多场合下,往往只有一张人脸图片可用,因此,基于单幅图像的三维人脸重建受到了国内学者的重点关注。
目前,针对单幅图像的三维人脸重建国内外学者已经给出了多种方法,例如传统方法有基于模型的方法、基于明暗形状恢复的方法等。随着深度学习的兴起,基于深度学习的方法也被引入到三维人脸重建领域,并且取得了比传统方法更优异的效果,逐渐成为主流的重建方法。Aaron S.Jackson等提出使用Volumetric Regression Networks(VRN)从单个二维图像直接进行三维面部重建的方法。该方法提高了面部大姿势和面部表情变化的重建质量。Yao Feng等设计了一个名为UV位置图的二维表示方法,记录UV空间中完整面部的三维形状,然后训练一个简单的卷积神经网络,从单个二维图像中回归。该方法不依赖于任何先前的面部模型,并且可以重建完整的面部几何以及语义。Feng-Ju Chang等提出了直接应用于人脸图像强度,回归3D表情系数的29D向量的ExpNet CNN模型。该模型不需要使用面部特征检测器作为模型训练的先验步骤,对人脸表情重建有较好的鲁棒性。Xiaoguang Tu等针对3D标注训练数据短缺问题,提出一种2D辅助自监督学习方法。该方法利用带嘈杂地标信息的无约束二维人脸图像改善三维人脸模型的学习,在密集人脸对齐和三维人脸重建方面取得了突出的效果。刘成攀等提出一种基于自监督深度学习的人脸表征及三维重建方法,将二维人脸的特征点信息映射到三维空间实现三维人脸重建,增强了三维人脸重构的准确性。
在无约束条件下,人脸的表情、姿势、纹理和内在几何存在很大差异,以上三维人脸重建方法仍然不够稳定,重建的结果出现脸部不完整、重建脸型偏向平均脸型、表情不够逼真等问题。
发明内容
本发明要解决的技术问题是怎样基于单幅图像重建完整、逼真且稳定的三维人脸,提出了一种基于卷积神经网络的单幅图像三维人脸重建方法及系统。
为解决该问题,本发明所采用的技术方案是:
一种基于卷积神经网络的单幅图像三维人脸重建方法,包括以下步骤:
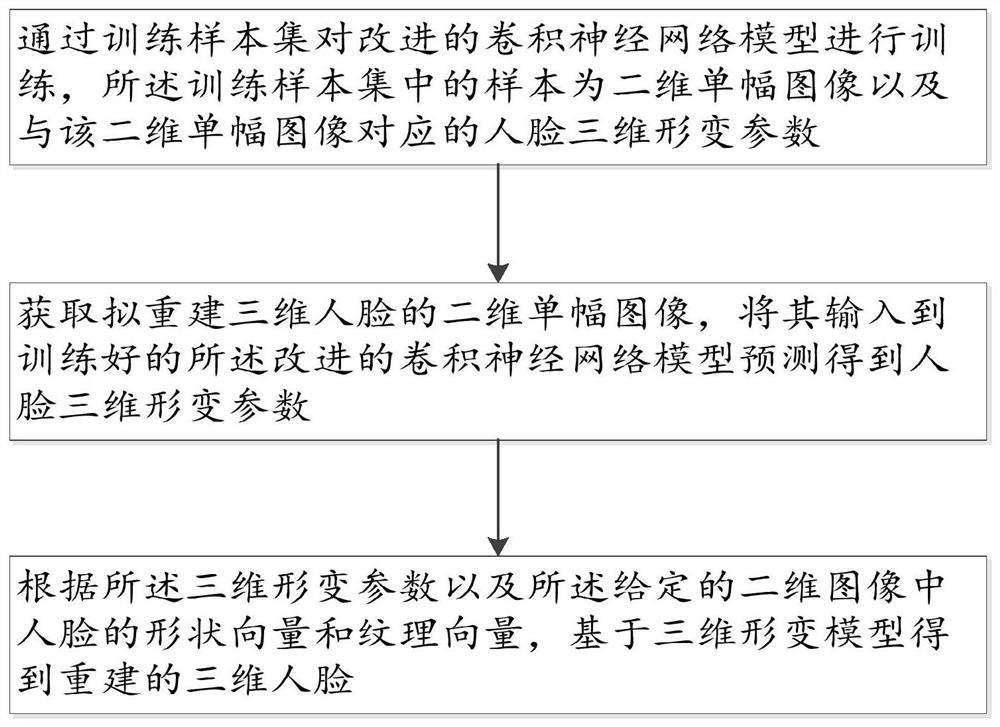
步骤1:通过训练样本集对改进的卷积神经网络模型进行训练,所述训练样本集中的样本为二维单幅图像以及与该二维单幅图像对应的人脸三维形变参数;
步骤2:获取拟重建三维人脸的二维单幅图像,将其输入到训练好的所述改进的卷积神经网络模型预测得到人脸三维形变参数;
步骤3:根据所述三维形变参数以及所述给定的二维图像中人脸的形状向量和纹理向量,基于三维形变模型得到重建的三维人脸。
进一步地,所述改进的卷积神经网络模型为:以VGG-16网络为骨架,网络模型包含13个卷积层、5个最大池化层、3个全连接层,在每个卷积层之后紧跟一个批归一化层,在批归一化层之后紧跟一个激活函数ReLU,在前两个所述全连接层之后紧跟ReLU激活函数和Dropout函数,在卷积层中,每个卷积核的大小为3x3,步长为1,填充为1,在池化层中,每个卷积核的大小为2x2,所述批归一化层是指将前一个卷积层输出的数据进行批量标准化处理。
进一步地,所述改进的卷积神经网络模型在训练过程中,采用迁移学习方法,引入预训练好的VGG-16模型参数,在此基础上对所述改进的卷积神经网络模型使用训练样本进行训练,所述预训练好的VGG-16模型是通过ImageNet数据库中的100万幅图像训练而成。
进一步地,所述改进的卷积神经网络模型使用300W-LP数据集上的样本数据作为训练集和验证集对所述改进的卷积神经网络模型进行训练,所述300W-LP数据集上的样本数据包括二维人脸图像和对应的人脸三维形变参数。
进一步地,所述训练集和验证集中的样本数据,根据样本中图像对应的三维信息文件中人脸区域的二维坐标,将图像中人脸区域裁剪并调整大小为150*150像素,然后将训练集和测试集中的样本数据进行均值方差归一化后输入到所述改进的卷积神经网络模型,对所述训练集和测试集中的目标参数进行均值方差归一化。
进一步地,所述改进的卷积神经网络模型损失函数为
其中,
进一步地,所述池化层为最大值池化层。
进一步地,所述第三个全连接层的通道数与预测的人脸三维形变参数数量一致。
进一步地,根据步骤2中所述给定的二维单幅图像中对应的三维信息文件中人脸区域的二维坐标,将所述给定的二维单幅图像中人脸区域裁剪并调整大小为150*150像素,然后将调整大小后的图像数据进行均值方差归一化后输入到所述改进的卷积神经网络模型中。
本发明还提供了一种基于卷积神经网络的单幅图像三维人脸重建系统,包括以下模块:
模型训练模块:用于通过训练样本集对改进的卷积神经网络模型进行训练,所述训练样本集中的样本为二维单幅图像以及与该二维单幅图像对应的人脸三维形变参数;
图像获取及参数预测单元:获取拟重建三维人脸的二维单幅图像,将其输入到训练好的所述改进的卷积神经网络模型预测得到人脸三维形变参数;
三维人脸重建单元:根据所述三维形变参数以及所述给定的二维图像中人脸的形状向量和纹理向量,基于三维形变模型得到重建的三维人脸。
采用上述技术方案,本发明具有如下有益效果:
本发明提供的一种基于卷积神经网络的单幅图像三维人脸重建方法及系统,通过对VGG-16网络模型进行改进,在每一个卷积层和全连接层输出后加入批归一化层,批归一化层利用小批量上的均值和标准差,不断调整神经网络的输出,从而使整个神经网络在各层的中间输出的值更加稳定,最后使得整个网络的输出更加稳定,避免了在训练过程中模型参数的更新造成靠近输出层输出的剧烈变化。在卷积神经网络模型的训练过程中,通过采用迁移学习方法,引入预训练好的VGG-16网络模型,由于该训练好的VGG-16网络模型,其拥有大量已经完成的参数和权重,在此基础上进行改进的卷积神经网络模型的训练,减少了网络训练时间和提高了网络训练效率。通过在AFLW2000-3D数据集上进行实验和比较,验证了本发明方法进行三维人脸重建的稳定性和逼真性。
附图说明
图1为本发明卷积神经网络结构示意图;
图2为最大值池化示意图;
图3为改进的卷积神经网络训练过程中在验证集上的损失对比示意图;
图4为本发明方法与其他方法对比结果示意图;
图5为在AFLW2000-3D上的累积误差分布(CED)曲线;
图6为本发明系统流程图。
具体实施方式
下面将结合附图对本发明的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
三维形变模型(3D Morphable Model,3DMM)是Volker Blanz等提出的一种人脸线性表示模型。该模型使用形状向量S表示人脸的几何形状,S=(X
首先,计算所有样本的平均形状向量
其次,计算每个样本的形状向量和平均形状向量的差值
最后,分别计算协方差矩阵的特征值和特征向量,按特征值降序选取前m个最大的特征值γ=(γ
其中,
当模型具有纹理部分时,上述三维形变模型往往拟合效果不够好。因此,重建人脸时通常只考虑人脸的形状部分,当需要纹理时,一般直接从照片中提取纹理进行贴合。针对3DMM对人脸表情处理的不足,Chen Cao等提出了FaceWarehouse人脸表情数据库,并将其引入到3DMM中。人脸线性模型可以扩充为:
其中,e
在获得三维面部形状S
V=f*Pr*R*(S
其中,V存储投影到二维平面上的三维顶点的二维坐标,f是比例因子,Pr是正交投影矩阵
图1至图6示出了本发明一种基于卷积神经网络的单幅图像三维人脸重建方法的具体实施例,包括以下步骤,如图6所示:
步骤1:通过训练样本集对改进的卷积神经网络模型进行训练,所述训练样本集中的样本为二维单幅图像以及与该二维单幅图像对应的人脸三维形变参数;
本实施例中,所述改进的卷积神经网络模型为:以VGG-16网络为骨架,网络模型包含13个卷积层、5个最大池化层、3个全连接层,在每个卷积层之后紧跟一个批归一化层,在批归一化层之后紧跟一个激活函数ReLU,在前两个所述全连接层之后紧跟ReLU激活函数和Dropout函数,在卷积层中,每个卷积核的大小为3x3,步长为1,填充为1,在池化层中,每个卷积核的大小为2x2,所述批归一化层是指将前一个卷积层输出的数据进行批量标准化处理。本实施例中池化层为最大值池化层,如图2所示。网络结构如图1所示,网络结构参数如表1所示。
表1卷积层网络参数
在VGG-16网络结构中,每个卷积层之后紧跟一个激活函数ReLU,其计算公式为
R=max(0,y) (11)
式中,R为激活函数的输出值,y为卷积层的输出值。ReLU函数的优点在于:当输入值y大于0时,它的导数恒为1,保持梯度不衰减,有效缓解了梯度消失问题,加快了网路收敛速度。
本实施例中,对于VGG-16网络结构的改进在于,在激活函数ReLU之前加入批归一化BN层,优化了网络结构模型。即对输入激活函数的数据进行批量标准化处理,使输入数据的均值为0,方差为1。假设批归一化BN层输入数据为β={x
式中,ε是为避免分母为0,设置的极小正数,取值为1e-5,γ是尺度因子,
本实施例中,在池化层中,每个卷积核的大小为2x2。池化层的作用是从小区域的特征中剔除不重要的特征,提取新的特征信息。池化方式常用的有最大值池化和平均值池化,本发明方法结构采用的是最大值池化方式。最大值池化的实现过程见图2所示。
原VGG-16网络模型包含3个全连接层,前两个全连接层都是4096个通道,第三个全连接层通道原本是1000,代表1000个类别。本实施例中,因为本文预测目标是62个参数,此处将其改为62。因此所述第三个全连接层的通道数与预测的人脸三维形变参数数量一致。前两个全连接层之后都紧跟ReLU激活函数和Dropout函数。Dropout函数的作用是在网络训练过程中,按照一定的概率p将神经元从网络中丢去,这样使网络模型的泛化能力更强,让网络不会太依赖于某些局部特征。改进模型Dropout函数的失活概率p=0.5。
本实施例中,所述改进的卷积神经网络模型在训练过程中,采用迁移学习方法,引入预训练好的VGG-16模型参数,在此基础上对所述改进的卷积神经网络模型使用训练样本进行训练,所述预训练好的VGG-16模型是通过ImageNet数据库中的100万幅图像训练而成,具有较强的深度特征学习能力,其拥有大量已经训练完成的参数和权重,特别是卷积层关于图像的曲线、边缘、轮廓的特征提取具备较强的能力。
本实施例中,所述改进的卷积神经网络模型使用300W-LP数据集上的样本数据作为训练集对所述改进的卷积神经网络模型进行训练,所述300W-LP数据集上的样本数据包括二维人脸图像和对应的人脸三维形变参数,使用AFLW2000-3D数据集上的样本数据作为测试集对所述改进的卷积神经网络模型进行测试。目前300W-LP和AFLW2000-3D数据集被广泛用于人脸对齐和人脸重建领域。300W-LP是由Zhu Xiangyu等采用其提出的方法生成61,225个大型样品,其进一步通过翻转将其扩展到122,450个样品。每个样品包括二维人脸图像和对应3DMM系数。采用其中636252张图片和对应的3DMM系数作为训练集,51602张图片和对应的3DMM系数作为训练时的验证集。
本实施例中,所述训练集和测试集中的样本数据,根据样本中图像对应的三维信息文件中人脸区域的二维坐标,将图像中人脸区域裁剪并调整大小为150*150像素,然后将训练集和测试集中的样本数据进行均值方差归一化后输入到所述改进的卷积神经网络模型,对所述训练集和测试集中的目标参数进行均值方差归一化。本实施例中,对训练数据和验证数据集进行归一化,归一化是指将所有数据都映射成均值为0,方差为1的数据的过程,这样可以避免异常值的影响,有助于加速网络收敛并达到更高性能。这里使用均值方差归一化方法,即
其中,x
并将均值P
其中,P
损失函数是神经网络学习的动力,即使是相同的网络模型和网络超参数,不同的损失函数有可能导致截然不同的结果,选对正确的损失函数对网络的性能至关重要。对于网络回归问题,常用的损失函数是回归参数之间的欧式距离(Parameter Distance Cost,PDC),即
式中,
其中,
步骤2:获取拟重建三维人脸的二维单幅图像,将其输入到训练好的所述改进的卷积神经网络模型预测得到人脸三维形变参数;
本实施例中,将所获取的拟重建三维人脸的二维图像,根据所述拟重建三维人脸的二维单幅图像中对应的三维信息文件中人脸区域的二维坐标,将所述给定的二维单幅图像中人脸区域裁剪并调整大小为150*150像素,然后将调整大小后的图像数据进行均值方差归一化后输入到所述改进的卷积神经网络模型中。
步骤3:根据所述三维形变参数以及所述给定的二维图像中人脸的形状向量和纹理向量,基于三维形变模型得到重建的三维人脸。
为了评价所重建的三维人脸形状和表情,本发明采用定性评价和定量评价两种评价指标,其中定性评价是对重建的三维人脸形状和表情的直观观察,定量评价是参考文献1“Chang F J,Tran A T,Hassner T,et al.ExpNet:Landmark-free,deep,3D facialexpressions[C]//2018 13th IEEE International Conference on Automatic Face&Gesture Recognition(FG 2018).IEEE,2018:122-129.”中评价方法,首先使用迭代最近点(Iterative Closest Points,ICP)算法来找到重建的3D人脸顶点和真实3D人脸顶点之间相应最近点,然后计算相应最近点之间的归一化均值误差(Normalized Mean Error,NME),人脸区域的边界框大小用作归一化因子,NME值越小,说明重建效果越精确。
ICP算法步骤:
(1)在模型重建的顶点集
(2)在真实顶点集V
(3)对v
(4)求距离
式中,n为顶点集中顶点个数。若d小于给定阈值,则停止迭代,否则返回第(2)步,直到满足收敛条件。
当ICP算法执行完毕后,求得预测顶点集
式中,
下面通过实验来说明评价本发明方法的有效性,将改进的VGG-16网络以及使用迁移学习和使用式(22)作为损失函数的模型集记为VGG-BN,将未改进的VGG-16网络以及使用迁移学习和使用式(22)作为损失函数的模型集记为VGG-preVDC,将未改进的VGG-16网络以及使用迁移学习和使用式(21)作为损失函数的模型集记为VGG-prePDC,将未改进的VGG-16网络以及未使用迁移学习和使用式(21)作为损失函数的模型记为VGG-PDC。
首先对比VGG-BN和未改进网络结构的模型在训练过程中在验证集上的损失。验证集上损失对比如图3所示。可以很明显地看出改进后的网络VGG-BN在验证集上的损失比未改进网络结构的VGG-preVDC低的多,验证了改进方法的可行性。
为了进一步验证本发明方法的有效性,将本发明的方法VGG-BN和文献1、文献2“Zhu X,Lei Z,Liu X,et al.Face alignment across large poses:A 3d solution[C]//Proceedings of the IEEE conference on computer vision and patternrecognition.2016:146-155.”在测试集AFLW2000-3D上的三维人脸重建结果进行了定性比较。首先给出这几种方法的可视化重建结果,如图4所示。图4中第一列为从测试集AFLW2000-3D抽取的二维图像,第二列、第三列为本发明的重建方法VGG-BN重建三维人脸的正面图和侧面图,第三列、第四列为文献2中的方法重建三维人脸的正面图和侧面图,第五列、第六列为文献1方法重建三维人脸的正面图和侧面图。为保证对比的公平性,文献2和文献2的重建结果均由对应文献公布的测试程序生成。由图4中可以看出,改进方法重建的人脸形状比文献1的重建结果更加平滑,重建的人耳部分更加完整,同时文献1重建的人脸具有明显条纹;对比文献2,本发明的重建方法VGG-BN和文献2的部分重建结果相差不够明显,但图4第一行中本发明的重建方法重建的人脸的嘴张开的大小更加合理,同时改进方法重建结果的面部细节相对更加丰富,尤其在眼部位置。
为了准确分析重建结果的差异,将本发明重建方法和文献2方法在测试集AFLW2000-3D数据集上使用评价标准NME进行了定量对比。对比结果如图5所示。
由于本发明的重建方法和文献2方法在测试时均使用dlib人脸检测器进行人脸特征检测,同时AFLW2000-3D数据集中存在人脸角度偏转较大的图片,该部分图片无法检测到人脸,除去无法检测到人脸的图片,共使用AFLW2000-3D数据集中的1496张图片进行测试评估。从图5中可以看出:在使用同样数量单幅图像进行重建时,VGG-prePDC的NME值远低于VGG-PDC的NME值,这说明本发明的重建方法使用迁移学习提高了模型训练效率;VGG-preVDC的NME值远低于VGG-prePDC,这说明本发明的重建方法提出的损失函数促进了模型的学习效率;同时VGG-BN、VGG-preVDC的NME值都低于文献2的NME值,并且本发明的重建方法VGG-BN的NME是最低的,表明对模型的改进是可行的。图5中每种方法的平均NME值在表2中列出。
表2在AFLW2000-3D上的平均NME
从表2中可以看出,在测试数据集上,本发明重建方法的改进模型VGG-BN的平均NME值最低,比VGG-preVDC的平均NME值低0.12,比文献2的平均NME值低0.15,重建的效果明显改善。通过实验和比较分析,可以看出,相对于原来的VGG-16网络,改进后的VGG-BN网络对单幅图像的图像特征学习能力更强,泛化能力更好。
通过对VGG-16网络模型进行改进,在每一个卷积层和全连接层输出后加入批归一化层,批归一化层利用小批量上的均值和标准差,不断调整神经网络的输出,从而使整个神经网络在各层的中间输出的值更加稳定,最后使得整个网络的输出更加稳定,避免了在训练过程中模型参数的更新造成靠近输出层输出的剧烈变化。在卷积神经网络模型的训练过程中,通过采用迁移学习方法,引入预训练好的VGG-16网络模型,由于该训练好的VGG-16网络模型,其拥有大量已经完成的参数和权重,在此基础上进行改进的卷积神经网络模型的训练,减少了网络训练时间和提高了网络训练效率。通过在AFLW2000-3D数据集上进行实验和比较,验证了本发明方法进行三维人脸重建的稳定性和逼真性。
本发明还提供了一种基于卷积神经网络的单幅图像三维人脸重建系统,包括以下模块:
模型训练模块:用于通过训练样本集对改进的卷积神经网络模型进行训练,所述训练样本集中的样本为二维单幅图像以及与该二维单幅图像对应的人脸三维形变参数;
图像获取及参数预测单元:获取拟重建三维人脸的二维单幅图像,将其输入到训练好的所述改进的卷积神经网络模型预测得到人脸三维形变参数;
三维人脸重建单元:根据所述三维形变参数以及所述给定的二维图像中人脸的形状向量和纹理向量,基于三维形变模型得到重建的三维人脸。
最后应说明的是:以上各实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述各实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的范围。
- 基于卷积神经网络的单幅图像三维人脸重建方法及系统
- 基于注意力机制的单幅图像到三维点云模型重建方法及系统