一种复杂背景下硅藻定位与识别方法
文献发布时间:2023-06-19 11:45:49
技术领域
本发明涉及深度学习领域,更具体地,涉及一种复杂背景下硅藻定位与识别方法。
背景技术
硅藻广泛分布在地球上的各种水体和湿土壤中,其种类繁多且形状各异。硅藻的生存与繁殖离不开水,对水体中富含的营养物质和理化性质如温度,pH,电导率等条件的变化极其敏感,所以在水质检测中判断水体是否受到污染的时候水中硅藻的种类与数量的重要检测指标。因为硅藻细胞壁是由含有硅元素的化合物组成,所以硅藻细胞壁结构坚固使得硅藻细胞不容易被破坏。在溺水过程中,硅藻细胞可以通过人的主动呼吸随着液体进入人的肺部组织中,通过破损的血管进入血液中并随着血液循环到达人体内部的其他器官中。而在死后抛尸入水这种情况下,由于人体已经死亡,即使硅藻通过渗透作用进入人体肺部组织,但是没有了血液循环进入肺部组织的硅藻无法随着血液循环进入人体其他内部器官。所以在法医学溺死判断中,通过对尸体的内部器官组织中硅藻种类和数量的检查可以辅助判断死者是生前溺水而亡还是死后被人抛尸入水,以及落水的地点。
目前在硅藻的实验室检查中,对硅藻目标的人工分类识别的主要方法有化学分类法,分子生物学方法和形态学方法。通过硅藻的纹理特征与形状特征的形态学方法给硅藻进行分类识别最先应用,由于提取到的硅藻样本难以使用化学试剂等清洗干净,所以硅藻在成像过程中会受到细砂石和其他细微颗粒的的干扰。在使用光学显微镜成像的结果综合硅藻形态学知识对硅藻的种类进行判别时,不仅需要操作人员具有深厚的硅藻相关知识和经验积累,而且在显微镜下连续观察,存在着工作量大,效率低下和受到观测人的主观性影响的问题。自上世纪40年代计算机诞生以来,使用计算机来辅助硅藻识别成为了可能。
自深度学习诞生以来,基于深度学习的目标检测算法开始在人脸检测和人脸识别上大放异彩。R-CNN系列模型利用卷积神经网络强大的特征提取能力,能够在背景相对复杂的情况下对物体进行定位和识别,其演进版本Fast R-CNN和Faster-RCNN通过更改算法策略实现了在算法速度上的提升,进一步提升了模型性能。R-CNN系列模型选择在原图上首先生成候选区域框之后再对这些预选框进行训练分类的策略使其在速度上远逊于不用在原图上生成候选区域框而是通过对逻辑框直接回归得到物体类别概率和位置坐标的YOLO模型,但是YOLO在精确度上稍逊Faster-RCNN模型。而SSD模型的诞生使得拥有较快的速度和较高的准确率成为了可能,SSD模型可以在速度上和精度上都超过现有的Faster-RCNN和YOLO模型。
目前国内外针对硅藻的分割与识别都是在简单背景下完成的,而且大多都是针对单一的藻类进行分割识别。在现有的机器学习的方法中,硅藻识别的过程是:首先通过图像分割技术将硅藻从其背景中提取出来,然后针对提取出来的无背景干扰的硅藻利用特征提取算法提取其形状特征,颜色和纹理特征等,最后使用提取到的特征去训练分类器,得到硅藻的种类信息。这种方法不能完全去除背景对硅藻的影响,无法达到对硅藻有效区域进行精准定位的要求,且提取的特征有限,所以难以胜任复杂背景下硅藻的定位与识别任务。
深度学习算法中,R-CNN模型是基于区域推荐的目标检测算法,吸收了传统的目标检测算法的优点。但R-CNN算法模型借助选择性搜索算法生成候选框区域,生成的候选框数目巨大达到2000个,会导致出现很多候选框重叠的情况,而在卷积神经网络中提取特征的时候采取的策略是对所有框都提取特征,这样会导致很多无效的重复计算,计算量过大导致网络训练时间过长,而且采用了对所有的候选框进行缩放到固定尺寸的策略会导致图像发生畸变,影响网络模型的性能,存在着目标检测慢,步骤繁琐等缺点。
公开日为2019年07月05日,公开号为CN109977780A的中国专利公开了一种基于深度学习算法的硅藻的检测与识别方法,用于解决了硅藻检验过程中因为种类过多和背景复杂而造成的识别效率低、识别不准确的问题。本发明实施例包括以下步骤:S1、获取多种硅藻种类图像,并按照Pascal VOC2007数据集格式制作数据集;S2、通过深度学习目标检测算法训练针对多种硅藻目标的目标检测模型;S3、使用训练好的Faster R-CNN网络模型来检测待检测图像中的硅藻目标,图像进入Fast R-CNN网络模型的卷积层中,把最后一个共享卷积层输出的特征图输入RPN网络模型中生成可能存在目标的候选区域,输出这些区域的中心坐标以及宽和高,再将候选区域特征输入Fast R-CNN中后续的分类及边框回归部分即可得到目标种类和精修过的位置信息。该专利使用的Faster-RCNN算法使用区域生成网络RPN(Region Proposal Network)生成候选区域的策略解决了这个问题,这种策略进一步的提升了算法的速度。Faster-RCNN模型检测目标时,需要首先产生候选框区域,之后针对候选区域进行分类,这属于目标检测领域中常见的two-stage方法,虽然Faster-RCNN改进了R-CNN在效率上的不足,并且准确率有了极大的提升,但是其速度还是不能满足实时检测中对速度的要求,而且Faster-RCNN算法选择了在卷积层的最后一层进行ROI池化,对小目标物体具有天然的劣势。
YOLO算法模型是使用基于回归的方法进行检测和分类,YOLO模型不需要像RCNN和Faster-RCNN那样真正生成目标预选框,而是采用预测候选区域的方式,以单元格为基本单位训练回归得到目标的位置和类别分数。速度上远远领先RCNN系列算法,但是YOLO采取的划分单元格且在每个单元格中只生成两个候选框策略使得其对于相互靠近的物体以及小物体的时候检测效果不好,在准确率上不及Faster-RCNN模型。
SSD(Single Shot MultiBox Detector)算法使用了一种新的预测框生成策略解决了此前one-stage方法中定位不准的问题。SSD算法利用多尺度的思想提取了不同尺度的特征图参与检测,采取空洞卷积的方式扩大了感受野,一定程度上解决了之前的特征检测算法无法检测小物体的问题,其采用不同宽高比的默认预测框(Default box)解决了YOLO模型定位不准的问题。虽然SSD提高了对小目标物体的识别效果,但是在同一图像中,如果出现极小目标和边缘目标,算法往往难以检测到它们。
综上,复杂背景下硅藻的精准分类识别具有重要的研究意义,但是传统的识别方法无法较好解决复杂背景下硅藻的定位和识别问题。深度学习方法也存在着各样的不足。因此运用深度学习技术进一步研究融合HDC的SSD模型的复杂背景下硅藻的定位与识别方法具有重要的价值。
发明内容
本发明提供一种复杂背景下硅藻定位与识别方法,解决了原SSD对极小目标与边缘目标漏检和细长的针形藻的平均准确率不高的问题,且速度能与原SSD算法媲美,且在精度上和速度上均能满足刑侦分析的需求。
为解决上述技术问题,本发明的技术方案如下:
一种复杂背景下硅藻定位与识别方法,包括以下步骤:
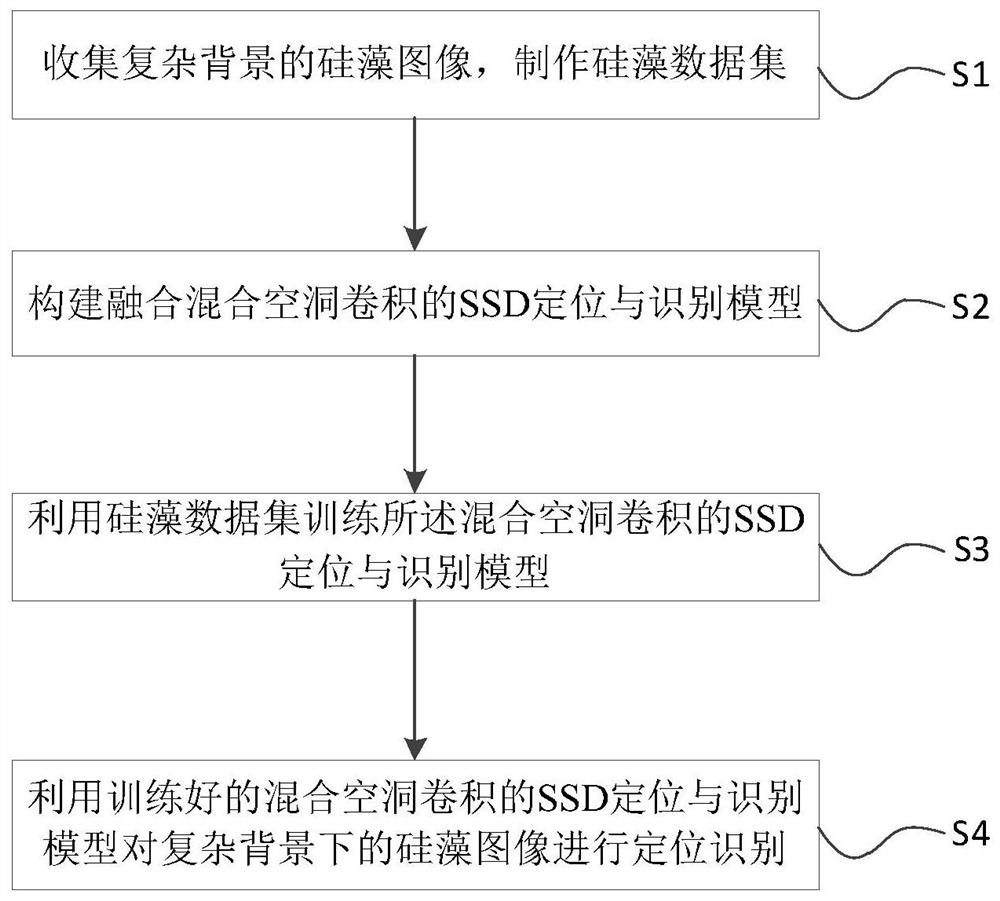
S1:收集复杂背景的硅藻图像,制作硅藻数据集;
S2:构建融合混合空洞卷积的SSD定位与识别模型;
S3:利用硅藻数据集训练所述混合空洞卷积的SSD定位与识别模型;
S4:利用训练好的混合空洞卷积的SSD定位与识别模型对复杂背景下的硅藻图像进行定位识别。
优选地,步骤S1中,所述收集复杂背景的硅藻图像,制作硅藻数据集具体为:
收集真实情况下获得的8种一共2600张高清电镜下存在复杂背景的硅藻图像数据;
按照PASCAL VOCS数据集的标准,使用LabelImage工具对收集的硅藻图像数据进行标注,得到硅藻图像数据集;
根据训练集:验证集:测试机=6:2:2的比例对所述硅藻图像数据集进行划分,写入到对应的txt文件中,得到VOC格式硅藻数据集。
优选地,步骤S2中,所述融合混合空洞卷积的SSD定位与识别模型,具体为:
将原始SSD模型的空洞卷积层替换为一组叠加的具有不同膨胀系数的空洞卷积核,再使用其中6层不同尺度的特征图组成多尺度目标检测层,检测到图像中不同大小的目标;
将多尺度目标检测层的结果输入到非极大值抑制筛选层,采用非极大值抑制算法去除多余的无效检测框,保留效果最好的检测框。
优选地,所述将原始SSD模型的空洞卷积层替换为一组叠加的具有不同膨胀系数的空洞卷积核,具体为:
原始SSD模型卷积层中主干网络是VGG16网络,并对VGG16网络进行了一定的修改,原始SSD模型中将VGG16网络中的两个全连接层fc6和fc7转换为卷积层的Conv6和Conv7,同时将原来网络中这两层后面的部分以及Dropout层全部去除,并在Conv7的后面额外添加了Conv8,Conv9,Conv10,Conv11四组卷积层,其中对Conv6采取空洞卷积;
融合混合空洞卷积的SSD定位与识别模型中,将Conv6替换为具有不同膨胀系数的空洞卷积层。
优选地,所述具有不同膨胀系数的空洞卷积层,膨胀系数需满足以下条件:(1)叠加的空洞卷积核的一组膨胀系数之间不能有大于1的公约数,像[2,4,8]这种组合经过混合空洞卷积依然会存在栅格效应,同样会造成信息提取不充分;
(2)叠加的空洞卷积核的一组膨胀系数的计算公式满足下式:
M
式中,r
优选地,所述使用其中6层不同尺度的特征图组成多尺度目标检测层,具体为:
将融合混合空洞卷积的SSD定位与识别模型中的Conv4_3、Conv7、Conv8_2、Conv9_2、Conv10_2、Conv11_2输出的特征图组成多尺度目标检测层,其中Conv4_3的尺度为38*38,Conv7的尺度为19*19、Conv8_2的尺度为10*10、Conv9_2的尺度为5*5、Conv10_2的尺度为3*3、Conv11_2的尺度为1*1;
在每一个特征图上,使用一个3x3的卷积核用于回归定位,即输出计算默认预测框相对真实标记框的偏移值,使用另外一个3x3的卷积核用于分类,即输出计算类别的置信度。
优选地,所述非极大值抑制筛选层中,采用非极大值抑制算法去除多余的无效检测框前,首先过滤掉IOU低于阈值的默认预测框。
优选地,所述采用非极大值抑制算法去除多余的无效检测框,具体为:
在融合混合空洞卷积的SSD定位与识别模型中设置默认预测框,在训练阶段中将默认预测框与真实标注框匹配,根据IOU结果来判断默认预测框内是否有目标物体,存在目标物体的默认预测框会被认定为是正样本,其它则为负样本;
采用best jaccard overlap算法计算出默认预测框与真实标记框的IOU,其计算公式如下式:
其中A,B分别代表两个集合,当J(A,B)=1代表两个集合完全重合;
将IOU阈值设置为0.5,筛选出阈值超过0.5的默认预测框,将这一部分默认预测框作为正样本,其它没有超过阈值0.5的默认预测框就是负样本,对负样本采取IOU从大到小排序进行选择,采用Online Hard Negative Mining方法将正样本与负样本比例设置为1:3,其他负样本进行丢弃;
正样本和负样本同时参与类别分数的选练,正样本参与位置和类别的训练进行回归得到结果。
优选地,所述默认预测框的生成具体为:
在不同的尺度的特征图上,默认预测框的尺度是不变的,通过预设一组默认的检测框来确定特征图上每一个像素单元的实际感受野的标签,在VOC格式的硅藻数据集中,一共具有8类不同的硅藻,因此每个默认预测框都需要预测其属于9个类别的分数以及4个坐标偏移量,9个类别分别为硅藻种类数加上背景;
如果一个特征图的大小为m*n,设每个像素单元存在k个默认预测框,则每个特征图都将会产生k*m*n个默认预测框以及k*m*n*(9+4)的预测值,这些预测值里面中的9*k*m*n个预测值用于默认预测框的的confidence输出,即物体的类别的概率,m*n*4*k是localization的输出,即每个默认预测框的坐标位置,其尺度的计算如下式:
其中S
模型对对每个像素单元产生了不同宽高比的默认预测框a
每一个默认预测框的宽的计算公式如下:
每一个默认预测框的高的计算公式如下:
其中当宽高比为1的时候,还增设了另外一个默认预测框,其尺度的计算公式如下:
优选地,在训练的正负样本确定之后,通过损失函数来预测模型的性能,损失函数由分类损失和回归损失组成,其中分类损失是置信度误差conf,回归损失是定位用的位置误差loc,其计算公式见式:
其中N是默认预测框中的正样本数,x是默认预测框与真实标记框的匹配情况,c是类别置信度的预测值,l是默认预测框的位置初始值,L
与现有技术相比,本发明技术方案的有益效果是:
本发明使用了SSD算法混合空洞卷积的策略,可以在保持感受野大小与原空洞卷积一样的情况下,增大了对信息的利用率,提升了对小目标的物体的检测能力。使用改进后的HDC-SSD(融合混合洞空卷积的SSD)算法能够很好的解决原SSD算法在小目标和边缘物体上漏检的问题,提升了SSD算法对边缘目标和小目标的检测能力。
附图说明
图1为本发明的方法流程示意图。
图2为实施例中融合HDC的SSD算法结构图。
图3为实施例中原始SSD算法与HDC-SSD300算法的实验结果对比图。
图4为实施例中多种算法的算法性能雷达图。
图5为实施例中硅藻数据集中各类藻类样图。
图6为实施例中LabelImage工具使用示意图。
图7为SSD300网络结构图。
图8为空洞卷积示意图。
图9为原始SSD模型空洞卷积采集图。
图10为混合空洞卷积示意图。
图11为原始SSD算法在Conv6的空洞卷积示意图。
图12为改进后的HDC-SSD算法在Conv6的混合空洞卷积示意图。
图13为实施例中NMS非极大值限制效果示意图。
图14为实施例中分类错误示意图。
图15为实施例中默认预测框的生成策略图。
具体实施方式
附图仅用于示例性说明,不能理解为对本专利的限制;
为了更好说明本实施例,附图某些部件会有省略、放大或缩小,并不代表实际产品的尺寸;
对于本领域技术人员来说,附图中某些公知结构及其说明可能省略是可以理解的。
下面结合附图和实施例对本发明的技术方案做进一步的说明。
实施例1
本实施例提供一种复杂背景下硅藻定位与识别方法,如图1所示,包括以下步骤:
S1:收集复杂背景的硅藻图像,制作硅藻数据集;
S2:构建融合混合空洞卷积的SSD定位与识别模型;
S3:利用硅藻数据集训练所述混合空洞卷积的SSD定位与识别模型;
S4:利用训练好的混合空洞卷积的SSD定位与识别模型对复杂背景下的硅藻图像进行定位识别。
步骤S1中,本实施例中,所述收集复杂背景的硅藻图像,制作硅藻数据集具体为:
对刑侦真实案例获得的8种一共2600张高清电镜下存在复杂背景的硅藻图像数据进行了标注,得到数据集A,数据集中各种藻类图片如图5,其基本组成如下表1:
表1数据集A中八种硅藻的数量分布
由于在SSD模型中会使用图像规整函数将输入图像全部调整为正方形,对于非正方形的图像,图像大小规整函数会导致图像发生畸变,会改变图像中物体原有的信息。由于原始硅藻数据库中的图像大小为512*472,为了避免图像大小规整函数导致畸变的情况发生,所以针对大小为512*472的图像采用了填充的方式,将其填充至512*512成方形之后使用标注工具标记,这样可以减小因为图像规整函数调整图像大小时候造成的影响。按照PASCAL VOCS数据集的标准,使用LabelImage工具对收集的硅藻图像数据进行标注,得到硅藻图像数据集,LabelImage工具的标记如图6所示;
根据训练集:验证集:测试机=6:2:2的比例对所述硅藻图像数据集进行划分,写入到对应的txt文件中,得到VOC格式硅藻数据集。
步骤S2中,所述融合混合空洞卷积的SSD定位与识别模型,具体为:
将原始SSD模型的空洞卷积层替换为一组叠加的具有不同膨胀系数的空洞卷积核,再使用其中6层不同尺度的特征图组成多尺度目标检测层,检测到图像中不同大小的目标;
将多尺度目标检测层的结果输入到非极大值抑制筛选层,采用非极大值抑制算法去除多余的无效检测框,保留效果最好的检测框。
所述将原始SSD模型的空洞卷积层替换为一组叠加的具有不同膨胀系数的空洞卷积核,具体为:
原始SSD模型卷积层中主干网络是VGG16网络,并对VGG16网络进行了一定的修改,原始SSD模型中将VGG16网络中的两个全连接层fc6和fc7转换为卷积层的Conv6和Conv7,同时将原来网络中这两层后面的部分以及Dropout层全部去除,并在Conv7的后面额外添加了Conv8,Conv9,Conv10,Conv11四组卷积层,其中对Conv6采取空洞卷积;在这添加的四层中首先采用了1x1的卷积核对输入的图像进行降维,降维可以降低了计算的复杂程度,减少运算量的同时减少冗余信息,可以一定程度上减少误差,提升精度,然后采用3x3的卷积核提取特征,原始SSD模型为了更加有利于检测小物体,采取的策略是在第五个池化层pool5中将其参数2x2-s2更改为3x3-s1-p1,即卷积核大小为3x3,步长为1,padding为1。这种将池化层改成卷积层策略可以不改变特征图像的大小,这样经过第五个池化层pool5之后的图像大小还是保持了输入之前的大小,但会使得后面卷积层的感受野发生变化。而原来的第五个池化层pool5采取了下采样减少了图像大小,增大了感受野。因此SSD中采取了一种方法来弥补上面的池化改动,即采用了一种空洞卷积算法,对Conv6采取空洞卷积,空洞卷积可以扩大感受野,感受野扩大由膨胀系数决定。对原始的卷积核内部填充0实现膨胀,假设原始卷积核大小为3x3,当膨胀系数为6时,则膨胀后的卷积核大小计算见下式:
NewK=dialation*(K-1)+1
其中dialation是膨胀系数,NewK是膨胀后的卷积核大小,K是原始卷积核大小;
使用上式计算之后得到膨胀后卷积核大小为13,为了不改变图像大小,需要对输入图像进行padding操作,其padding数值计算见下式:
即padding为6,根据公式可以计算到输出Conv6的结果仍然为19*19,与Conv6的输入结果一致,没有改变图像的大小。
融合混合空洞卷积的SSD定位与识别模型中,将Conv6替换为具有不同膨胀系数的空洞卷积层;
图像分割领域里使用卷积神经网络进行分割的方法中,卷积层提取图像特征,池化层降低图像尺度。在这些方法里,采用池化的方法增大感受野的同时减小图像尺度,但是在分割任务中最终要输出原始图像大小的分割结果图,所以需要使用反卷积进行上采样的方式扩大图像,而在池化的过程中会导致细节的丢失,而采用空洞卷积的方法可以既不减小图像又能增大感受野。原始SSD采用空洞卷积提取图像特征。
空洞卷积中,采用的超参数是膨胀系数(dilation rate),膨胀系数即卷积核中各个单元的距离,传统的卷积核中各单元的距离为1,而在空洞卷积中,如果膨胀系数为dilation,那么卷积核的各个单元之间的距离即为dilation-1,如图8,图8是无padding操作的膨胀系数dilation rate=2的空洞卷积,使用padding操作之后即可获得原始图像大小的特征图;
空洞卷积可以扩大感受野,空洞卷积后的特征图像的像素单元感受野扩大的同时拥有更大尺度的信息。原始的卷积核大小为k*k,膨胀系数为r的空洞卷积核的大小计算见下式:
K=k+(k-1)(r-1)
其中K是空洞卷积的卷积核大小,r是膨胀系数,k是原始卷积核大小。当膨胀系数越大的时候,感受野范围内贡献的像素单元比例越小,其信息丢失的也越多,信息之间的相关性损失越大,对小目标漏检的可能性也越大。
空洞卷积在不减少图像尺度的情况下可以扩大感受野,得到更多的信息,但是空洞卷积中膨胀系数如果设置过大会造成栅格效应,空洞卷积核中的各个单元之间不连续,这样导致参加空洞卷积的特征图上感受野范围内的图像的像素单元不是都参加了计算,会造成信息的丢失。如图7所示,原始的SSD中Conv6输出特征图中的一个像素单元在Conv6输入(或者POOL5输出)的特征图上的感受野如图9所示,其感受野大小为13*13,感受野范围内参与运算的单元仅为9个且每个像素单元之间间隔较大,导致了很多信息的丢失,且贡献的像素单元之间缺乏联系,导致像素单元之间的相关性也出现丢失。
为了解决膨胀系数过大的空洞卷积会导致极小目标漏检这个问题,在分析空洞卷积存在的缺点之后,本实施例明提出了一种使用混合空洞卷积替换原始SSD空洞卷积的方法,即使用一组叠加的空洞卷积核取代原来的单一卷积核,并且将叠加的卷积核的膨胀系数设置拥有一定的规则:
(1)叠加的空洞卷积核的一组膨胀系数之间不能有大于1的公约数,像[2,4,8]这种组合经过混合空洞卷积依然会存在栅格效应,同样会造成信息提取不充分;
(2)叠加的空洞卷积核的一组膨胀系数的计算公式满足下式:
M
式中,r
这样的设置保证了至少叠加的第一层就可以使用膨胀系数为1的空洞卷积覆盖所有像素。Dilation rate[1,2,3]就是一个符合的例子。这样一组膨胀系数中,较小的膨胀信息用于提取小目标信息,较大的膨胀系数用于提取大目标的信息。
混合空洞卷积的感受野的计算见式:
Rf
其中Rf
如图2所示,在HDC-SSD算法中,Conv6_1,Conv6_2,Conv6_3这三层的卷积核的膨胀系数分别设置为1,2,3。所以Conv6_3输出的特征图中的一个像素单元在Conv6_2输出的特征图的感受野大小为9*9,感受野中参与运算的像素单元个数为9个,如图10(c);在Conv6_1输出的特征图上的感受野大小为11*11,感受野中参与运算的像素单元个数为81个,如图10(b);在Conv6_1输入(或者POOL5输出)的特征图上的感受野大小为13*13,以及感受野中参与运算的像素单元个数为169个,如图10(a)。
在空洞卷积中,以填充0的方式膨胀卷积核,但是实际参与计算的卷积核中的参数任然和原卷积核的参数个数相同,即空洞卷积实现了不增加参数扩大感受野的效果。在混合空洞卷积中,设置一组[1,2,3]的膨胀系数一共需要进行三层卷积,而原来的空洞卷积中膨胀系数为6的时候只需要进行一层卷积,如图11,混合空洞卷积中实际参与计算的参数比之前多了18个,但是相对可以获得到了更多的采集信息,如图12所示。
所述使用其中6层不同尺度的特征图组成多尺度目标检测层,具体为:
传统的目标检测中,为了检测到图像中不同大小的目标时,通过将图像下采样至不同的大小进行分别检测。为了提高算法在不同尺度上的检测能力,在SSD模型中采用的是提取不同尺度的特征图来进行目标检测,而且达到了相同的效果;将融合混合空洞卷积的SSD定位与识别模型中的Conv4_3、Conv7、Conv8_2、Conv9_2、Conv10_2、Conv11_2输出的特征图组成多尺度目标检测层,其中Conv4_3的尺度为38*38,Conv7的尺度为19*19、Conv8_2的尺度为10*10、Conv9_2的尺度为5*5、Conv10_2的尺度为3*3、Conv11_2的尺度为1*1,如表2所示:
表2组特征图信息
在每一个特征图上,使用一个3x3的卷积核用于回归定位,即输出计算默认预测框相对真实标记框的偏移值,使用另外一个3x3的卷积核用于分类,即输出计算类别的置信度。
所述非极大值抑制筛选层中,采用非极大值抑制算法去除多余的无效检测框前,首先过滤掉IOU低于阈值的默认预测框。
所述采用非极大值抑制算法去除多余的无效检测框,具体为:
非极大值抑制是为了选出局部的极大值,其常被用在目标检测算法中筛选信息。在目标检测算法中,多预选框策略往往导致经过分类层后的目标结果可能会存在多个检测框以及预测值。在HDC-SSD模型中,目标检测层产生了众多的默认预测框,其中拥有与真实框匹配程度各不同的默认预测框,为了在众多的框中需要去除掉那些冗余的框,因此算法采用了非极大值抑制算法来去除冗余的框确定最终的框,如图13。硅藻中产生了众多与目标物相匹配的默认预测框,要删除冗余的检测框只保留最好的那个一个。在对多类任务进行目标定位和检测时,对每个类别都进行非极大值抑制。那么检测结果中就会出现一个目标物会被分给两个不同的类别,且目标的IOU极大,这种情况是无法接受的,如图14所示。
在融合混合空洞卷积的SSD定位与识别模型中设置默认预测框,在训练阶段中将默认预测框与真实标注框匹配,根据IOU结果来判断默认预测框内是否有目标物体,存在目标物体的默认预测框会被认定为是正样本,其它则为负样本,但是实际上匹配成功的默认框可能具有多个且和真实的标注框存在差别,通过训练将默认框尽可能的回归到真实框的位置。算法使用训练损失来衡量整个模型的性能,其中训练损失包括位置回归损失和分类损失;
特征图上生成的不同尺度的默认预测框(Default box)映射到原图后会与原图像中的真实标记框(ground truth box)存在差距,为了在众多的默认预测框中匹配到与真实目标框相一致的默认预测框,SSD中采取的措施是首先对于每个真实目标框寻找到与其匹配程度最高的默认预测框,这样可以保证每个真实目标框都能够至少有一个默认预测框与它匹配。并将此默认预选框设为正样本,如果只把这个当作正样本,那么正样本和负样本会极度不平衡,这就需要增加正样本的数量,在得到了至少一个默认框的情况下,采用bestjaccard overlap算法计算出默认预测框与真实标记框的IOU,其计算公式如下式:
其中A,B分别代表两个集合,当J(A,B)=1代表两个集合完全重合;
将IOU阈值设置为0.5,筛选出阈值超过0.5的默认预测框,将这一部分默认预测框作为正样本,其它没有超过阈值0.5的默认预测框就是负样本,一般得到的负样本数会远远大于正样本,这使得正负样本之间不平衡,会使得网络在训练的时候收敛困难,为了加快模型收敛,对负样本采取IOU从大到小排序进行选择,采用Online Hard Negative Mining方法将正样本与负样本比例设置为1:3,其他负样本进行丢弃,这样即保证了在训练过程中模型能够加快收敛,同时也能保证模型的准确率。正样本和负样本同时参与类别分数的选练,正样本参与位置和类别的训练进行回归得到结果。当然一个真实目标框可能存在多个默认预测框与它匹配,这就需要在的NMS筛选层来解决这个问题,去掉冗余的默认预测框;
正样本和负样本同时参与类别分数的选练,正样本参与位置和类别的训练进行回归得到结果。
所述默认预测框的生成具体为:
默认预测框如图15(a)所示,它和Faster-RCNN模型中提出的anchor机制相似,在不同的尺度的特征图上,默认预测框的尺度是不变的,通过预设一组默认的检测框来确定特征图上每一个像素单元的实际感受野的标签,在VOC格式的硅藻数据集中,一共具有8类不同的硅藻,因此每个默认预测框都需要预测其属于9个类别的分数以及4个坐标偏移量,9个类别分别为硅藻种类数加上背景;
如果一个特征图的大小为m*n,设每个像素单元存在k个默认预测框,则每个特征图都将会产生k*m*n个默认预测框以及k*m*n*(9+4)的预测值,这些预测值里面中的9*k*m*n个预测值用于默认预测框的的confidence输出,即物体的类别的概率,m*n*4*k是localization的输出,即每个默认预测框的坐标位置,其尺度的计算如下式:
其中S
表3各特征图默认预选框
模型对对每个像素单元产生了不同宽高比的默认预测框a
每一个默认预测框的宽的计算公式如下:
每一个默认预测框的高的计算公式如下:
其中当宽高比为1的时候,还增设了另外一个默认预测框,其尺度的计算公式如下:
因此,对于每个像素单元而言,一共可以有6种默认预测框。其中每一个默认框的计算公式见下式:
其中f
对于每一层中的特征图上获得的默认预选框(Default box)个数,模型是从上面六种情况中进行选择。SSD中一共最后得到的默认预选框的个数为8732个(38*38*4+19*19*6+10*10*6+5*5*6+3*3*4+1*1*4=8732),各层特征图中的默认预测框信息如表4所示:
表4各层特征图的Default box信息
在各个尺度的特征上生成不同宽高比的默认预测框,在预测的时候,会出现很多的默认预选框,这其中只有一个默认预选框和初始标记框吻合,如图15中只有红色的默认预测框与狗的标记框符合,其他框都将是负样本,至于默认预测框与初始标记框如何匹配,则由默认预测框的选择和匹配决定。
在训练的正负样本确定之后,通过损失函数来预测模型的性能,损失函数由分类损失和回归损失组成,其中分类损失是置信度误差conf,回归损失是定位用的位置误差loc,其计算公式见式:
其中N是默认预测框中的正样本数,x是默认预测框与真实标记框的匹配情况,c是类别置信度的预测值,l是默认预测框的位置初始值,L
为了验证HDC-SSD算法的性能,采取VOC格式硅藻数据集,即2800张8类的硅藻数据集,以SSD300为原型实现了HDC-SSD算法,图7为SSD300网络结构图。以原始SSD300,SSD512,Faster-RCNN算法作为参照,以单个类别的平均精准率AP,整个数据集的平均精准率均值mAP,速度指标fps,以及识别正确率指标accuracy来衡量算法性能。从表1的多种算法对比结果中可以看到使用混合空洞卷积(HDC)改进后的SSD算法的平均准确率优于其他算法,与原始的SSD算法相比在针形藻上也有一定提升。
表5多算法对比测试结果
另外针对测试集中图片的测试结果进行分析可以得到,改进的空洞卷积能够有效的提升对于边缘目标以及极小目标的检测能力,如图3所示。
原始的SSD算法对于边缘物体和极小物体的检测会存在漏检的情况。如图3(a)中原始的SSD算法中第一幅图左上角边缘较小的直链藻被漏检,第二幅图左上角边缘的较小的小环藻被漏检,第三幅图直链藻上方极小的小环藻被漏检,第四幅图桥湾藻右下方极小的小环藻被漏检。因为原始的SSD算法采用的空洞卷积膨胀系数过大,空洞卷积后生成的特征图丢失了细节信息,而通过使用混合空洞卷积改进原始空洞卷积的策略提升了信息的利用度和获得了更多的采集信息,改进后的算法能够解决这种问题。如图中2(b)中可以看到,改进后的SSD算法能够将被漏检的硅藻都能够检测出来,没有出现小目标和边缘目标被漏检的情况。
另外通过对图片中主体目标的整体识别率以及实验检测速度的对比上发现改进后的算法在整体识别率上以及检测速度上由于其他算法,证实了HDC-SSD减少了参数数量,加快检测速度的论断,具体如表2。
表6多种算法效率对比
从图4的性能雷达图中可以看出,采用混合空洞卷积改进后的算法HDC-SSD在平均准确率均值mAP和分类准确率accuracy上优于其他算法,且算法检测速度和训练时间上极其接近原始SSD算法,领先其他算法。HDC-SSD算法整体识别正确率和检测速度均能满足实验室对硅藻检测算法的要求,实验验证了算法的优越性。
相同或相似的标号对应相同或相似的部件;
附图中描述位置关系的用语仅用于示例性说明,不能理解为对本专利的限制;
显然,本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。
- 一种复杂背景下硅藻定位与识别方法
- 一种复杂背景下大区域多目标硅藻提取与识别方法