新异检测器
文献发布时间:2023-06-19 13:49:36
相关申请的交叉引用
本申请要求于2020年6月8日提交的申请号为10-2020-0068807的韩国专利申请的优先权,该韩国专利申请通过引用整体并入本文。
技术领域
各个实施例可以涉及一种新异(novelty)检测器,并且更特别地,涉及一种利用没有标签的各种样本进行训练的新异检测器。
背景技术
新异检测是指检测与先前已知数据不同的数据的技术。
当使用神经网络执行新异检测时,使用正常样本来训练神经网络。正常样本可以来自正常样本的特征空间的分布。
当完成训练后将数据输入到神经网络时,神经网络推断实际数据是正常样本(诸如来自正常样本的特征空间的分布的样本)还是异常样本(诸如并非来自正常样本的特征空间的分布的样本)。
图1是示出常规的新异检测器1的框图。
常规的新异检测器1包括生成器10和判别器20。
生成器10和判别器20中的每一个都具有诸如卷积神经网络(CNN)的神经网络结构。
具有图1所示结构的神经网络称为生成对抗网络(GAN)。
生成器10包括:编码器11和解码器12,如图2所示顺序地联接以接收实际数据x并且生成重构数据G(x)。
编码器11和解码器12还可以具有诸如CNN的神经网络结构。
判别器20接收重构数据G(x)并且输出表明实际数据x是正常样本还是异常样本的判别数据D。
例如,判别数据D可以变为0或1,其中1表明实际数据被确定为正常样本,而0表明实际数据被确定为异常样本。
常规的新异检测器1进一步包括耦合电路30。
耦合电路30提供实际数据x或重构数据G(x)作为判别器20的输入以进行训练操作。
耦合电路30提供重构数据G(x)作为判别器20的输入以进行推断操作。
图3是示出常规的新异检测器1的训练操作的流程图。训练生成器10的目的是重构与实际样本相似的样本,而训练判别器20的目的是区分由生成器10生成的样本与实际样本。
在常规的新异检测器1中,交替训练判别器20和生成器10。
当在步骤S10中训练判别器20时,在生成器10的神经网络的权重固定时,调整判别器20的神经网络的权重。
此时,将实际数据x和重构数据G(x)交替输入到判别器20。
此时,调整判别器20的权重,使得当输入实际数据x时判别数据D变为1,而当输入重构数据G(x)时判别数据D变为0。
当在步骤S20中训练生成器10时,在判别器20的权重固定时,调整生成器10的权重。
此时,将重构数据G(x)输入到判别器20。
当输入重构数据G(x)时,调整生成器10的权重,使得判别数据D变为1并且实际数据x与重构数据G(x)之间的均方误差(MSE)变为0。
在训练操作期间,可以重复执行以上两个步骤。
在训练神经网络时,可以使用标有类别的正常样本。
当使用具有标签的正常样本来训练神经网络时,可以提高新异检测性能。
然而,存在的问题是,准备工业用途所需的许多具有类别标签的正常样本需要花费大量的时间和成本。
为此,通常的做法是使用没有标签的各种类别的样本进行训练。在这种情况下,随着类别的数量增加,存在新异检测性能迅速下降的问题。
发明内容
根据本公开的实施例,新异检测器可以包括:生成器,被配置为根据实际数据输出重构数据;以及判别器,被配置为接收实际数据和重构数据并且使用实际数据和重构数据来产生表示实际数据是正常还是异常的判别数据。
附图说明
附图以及以下详细描述并入说明书中并且形成说明书的一部分,并且用于进一步说明包括所要求保护的新异检测器的概念的实施例,并且解释这些实施例的各种原理和优点,在附图的不同的视图中,类似的附图标记指代相同或功能相似的元件。
图1是示出常规的新异检测器的框图。
图2是示出常规的生成器的框图。
图3是示出常规的新异检测器的训练操作的流程图。
图4是示出根据本公开的实施例的新异检测器的框图。
图5是示出根据本公开的另一实施例的新异检测器的框图。
图6是示出根据本公开的另一实施例的新异检测器的框图。
图7是示出根据实施例的图4的新异检测器的训练过程的流程图。
图8是示出根据实施例的图5的新异检测器的训练过程的流程图。
图9是示出本公开的实施例的效果的曲线图。
具体实施方式
下面将参照附图描述各个实施例。出于说明目的提供这些实施例并且也可以存在未明确示出或描述的其他实施例。进一步,可以对将在下面详细描述的本公开的实施例进行修改。
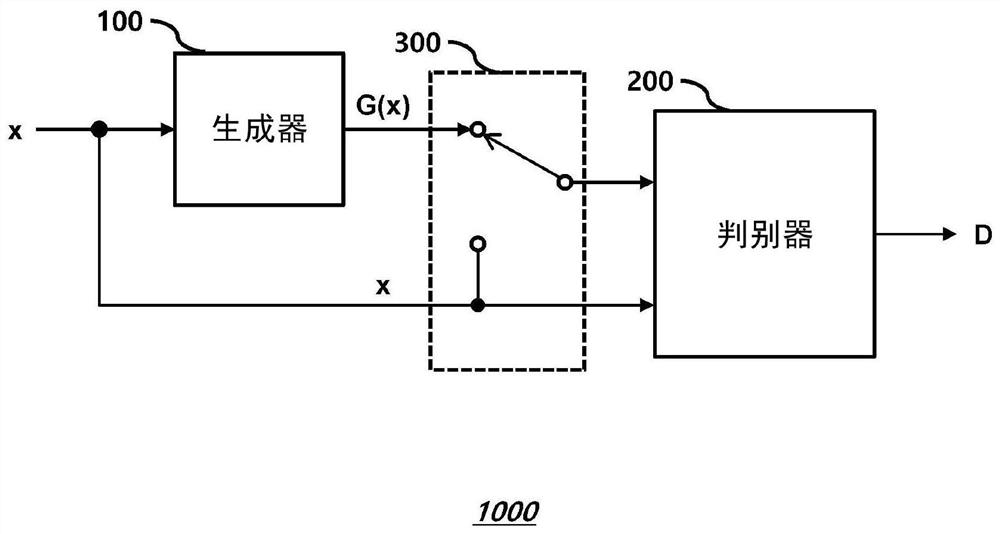
图4是示出根据本公开的实施例的新异检测器1000的框图。
新异检测器1000包括生成器100和判别器200。
生成器100和判别器200中的每一个可以包括诸如卷积神经网络(CNN)神经网络。
生成器100接收实际数据x并且生成重构数据G(x),并且在生成器100中可以包括诸如图2所示的编码器和解码器,其中编码器和解码器中的每一个可以具有诸如CNN的神经网络结构。
在下文中,实际数据x可以称为输入数据x。
与现有技术不同,判别器200在推断过程期间同时接收重构数据G(x)和实际数据x并且输出判别数据D。
在本实施例中,判别数据D具有从0到1的值,并且当实际数据x是正常样本时,判别数据D具有比对应于异常样本的值更大的值。在实施例中,判别数据D的值更高可以对应于实际数据x是正常样本的似然性或置信度增加。
新异检测器1000可以进一步包括耦合电路300。
在训练操作期间,耦合电路300提供第一对实际数据x和实际数据x或者第二对实际数据x和重构数据G(x)作为判别器200的输入。
例如,在训练操作期间,可以交替提供第一对(x,x)和第二对(x,G(x))作为判别器200的输入。
在推断过程期间,耦合电路300同时提供实际数据x和重构数据G(x)作为判别器200的输入。
图7是示出新异检测器1000的训练操作700的流程图。
在本实施例中,交替训练判别器200和生成器100。
在步骤S100中的判别器200的训练操作期间,在生成器100的权重固定时,调整判别器200的权重。
在判别器200的训练操作期间,将第一对(x,x)或第二对(x,G(x))交替输入到判别器200。
在步骤S100的实施例中,在步骤S102中,将第一对(x,x)输入到判别器200以产生判别数据D。在步骤S104中,调整判别器200的权重,使得当输入第一对(x,x)时判别数据D趋向1。在步骤S106中,将实际数据x输入到生成器100以产生所生成的重构数据G(x)并且将第二对(x,G(x))输入到判别器200以产生判别数据D。在步骤S108中,调整判别器200的权重,使得当输入第二对(x,G(x))时判别数据D趋向0。也就是说,为了调整判别器200的权重,会考虑对应于第一对(x,x)的判别数据D的第一值和对应于第二对(x,G(x)的判别数据D的第二值两者。
在步骤S200中的生成器100的训练操作700期间,在判别器200的权重固定时,调整生成器100的权重。
在步骤S200中,在步骤S202中,向生成器100提供实际数据x以产生重构数据G(x),并且将实际数据x和重构数据G(x)同时输入到判别器200。也就是说,仅将第二对(x,G(x))输入到判别器200。
在步骤S204中,基于输入的实际数据x和重构数据G(x),调整生成器100的权重以使判别数据D趋于1。在本实施例中,对于训练生成器100,不会考虑实际数据x与重构数据G(x)之间的均方误差。
在训练操作700中,可以通过交替重复步骤S100和S200来训练判别器200和生成器100。
在常规的新异检测器1中,判别器20仅接收重构数据G(x)而不接收实际数据x,并且区分正常样本和异常样本。
相反,在根据本实施例的新异检测器1000中,判别器200同时接收实际数据x和重构数据(G(x))。
可以用泛化误差来表示当在推断过程期间输入在训练操作期间未使用的测试样本时的新异检测性能。
当使用GAN结构时,我们希望当正常样本进入时生成器重构良好,而当异常样本进入时生成器重构不佳。这意味着生成器没有被泛化或生成器的泛化能力不佳。另一方面,我们希望判别器很好地判别样本,而不管样本是正常还是异常,这意味着判别器的泛化能力良好。
在常规的GAN中,难以使判别器和生成器的泛化误差不同。例如,判别器的泛化能力良好将导致生成器的泛化能力良好,反之亦然。
然而,在实施例中,可以通过使用两个判别器来不同地设置生成器和判别器的泛化性能。在本实施例中,生成器的泛化误差可以被认为与重构误差相同并且生成器的泛化性能可以被认为与重构性能相同。泛化性能随着泛化误差变小而提高。
生成器100应当对正常样本具有良好重构性能即小的重构误差,以及对异常样本具有不良的重构性能即大的重构误差,以提高整体新异检测性能。随着判别器200的泛化性能的提高,生成器100对异常样本的泛化性能也得到提高,因此整体新异检测性能可能受到限制。
在图5的实施例中,在提高判别器的泛化性能的同时,可以抑制生成器的泛化性能的提高。因此,可以不同地设置判别器的泛化性能和生成器的泛化性能。
图5是示出根据本公开的另一实施例的新异检测器2000的框图。
新异检测器2000包括生成器400和判别器500。
生成器400包括第一编码器411、第二编码器412、运算电路430和解码器420。
第一编码器411和第二编码器412分别编码实际数据x。
第一编码器411对应于图4的生成器100中包括的编码器,而第二编码器412对应于图1的生成器10中包括的编码器。
这将在解释训练操作时详细公开。
运算电路430将第一编码器411和第二编码器412的输出进行组合。例如,运算电路430可以将来自第一编码器411和第二编码器412的输出通过规范化进行线性组合。
解码器420对运算电路430的输出进行解码并且输出重构数据G(x)。
第一编码器411、第二编码器412和解码器420中的每一个可以包括诸如CNN的神经网络。
判别器500接收实际数据x和重构数据G(x)并且输出判别数据D。
例如,判别数据D具有从0到1的值。当实际数据x是正常样本时,判别数据D具有较大的值。
判别器500包括第一判别器510和第二判别器520。
第一判别器510与图4的判别器200基本相同,而第二判别器520与图1的判别器20基本相同。
第一判别器510在推断操作期间同时接收实际数据x和重构数据G(x),并且输出判别数据D。
从第一判别器510输出的判别数据D可以被称为第一判别数据。
从第二判别器520输出的判别数据SD仅在训练操作中使用,而不在推断操作中使用。
从第二判别器520输出的判别数据SD可以被称为第二判别数据SD。
因此,在推断操作期间可以关闭第二判别器520以减少功耗。
新异检测器2000进一步包括耦合电路600。
耦合电路600包括第一耦合电路610和第二耦合电路620。
第一耦合电路610对应于图4的耦合电路300,而第二耦合电路620对应于图1的耦合电路30。
第一耦合电路610在推断操作中同时向第一判别器510提供实际数据x和重构数据G(x)。
第一耦合电路610在第一判别器510的训练操作中交替地向第一判别器510提供第一对(x,x)或第二对(x,G(x)),并且在第一编码器411或解码器420的训练操作中向第一判别器510提供第二对(x,G(x))。
第二耦合电路620在第二判别器520的训练操作中交替地向第二判别器520提供实际数据x或重构数据G(x),并且在第二编码器412或解码器420的训练操作中向第二判别器520提供重构数据G(x)。
由于第二判别器520在推断操作期间不工作,因此第二耦合电路610可以在推断操作期间具有任意状态。
图8是示出新异检测器2000的训练过程800的流程图。
首先,在步骤S300中顺序地地训练第一判别器510、第一编码器411和解码器420。
在步骤S300中,在步骤S302处第一耦合电路610进行操作以在第一判别器510的训练操作中交替地向第一判别器510提供第一对(x,x)和第二对(x,G(x)),并且在步骤S304处第一耦合电路610进行操作以在第一编码器411和解码器420的训练操作中向第一判别器510提供第二对(x,G(x))。
这是对应于图7的流程图的操作。
也就是说,步骤S302中的第一判别器510的训练操作对应于图7中的步骤S100,并且步骤S304中的第一编码器411和解码器420的训练操作对应于图7中的步骤S200。
然后,在步骤S400中顺序地训练第二判别器520、第二编码器412和解码器420。
在步骤S400中,在步骤S402处第二耦合电路620进行操作以便在第二判别器520的训练操作中交替地向第二判别器520提供实际数据x和重构数据G(x)并且使用第二判别器的输出SD对第二判别器520进行训练,在步骤S404处第二耦合电路620进行操作以便使用第二判别器的输出SD在第二编码器412和解码器420的训练操作中向第二判别器520提供重构数据G(x)。
这是对应于图3的流程图的操作。
也就是说,步骤S402中的第二判别器520的训练操作对应于图3中的步骤S10,并且步骤S404中的第二编码器412和解码器420的训练操作对应于图3中的步骤S20。
如上所述,由于使用根据本实施例的第一判别器510来训练第一编码器411,因此第一编码器411的泛化误差相对小于第二编码器412的泛化误差。由于使用根据现有技术的第二判别器520来训练第二编码器412,因此第二编码器412的泛化误差将倾向于大于第一编码器411的泛化误差。
在图5的实施例中,生成器400通过一起使用第一编码器411和第二编码器412的输出来进行操作,使得生成器400的总体泛化误差大于图4的生成器100的泛化误差。
由于图5的新异检测器2000在推断操作期间使用生成器400和第一判别器510进行操作,因此第一判别器510的泛化误差可以保持在对应于图4的判别器200的泛化误差的水平,并且生成器400的泛化误差可以增加到大于图4的生成器100的泛化误差的水平,从而提高整体新异检测性能。
也就是说,与图4中的实施例不同,在图5的新异检测器2000中,可以不同地设置生成器400的泛化误差和判别器500的泛化误差,从而进一步提高新异检测性能。
图9是示出本实施例的效果的曲线图。
该曲线图示出当将5个正常样本和5个异常样本输入到作比较的新异检测器时每个作比较的新异检测器的准确度。利用修改后的国家标准技术研究院(Modified NationalInstitute of Standards and Technology,MNIST)数据集来训练图9中的新异检测器,该数据集是手写数据集。
水平轴表示在训练操作期间执行的训练阶段的数量。
如曲线图所示,当在训练操作期间执行足够数量的或更多的训练阶段时(例如,当执行600或更多个训练阶段时),在本实施例中测量出整体准确度较高。
图6是示出根据本公开的另一实施例的新异检测器3000的框图。
在图6中,新异检测器3000与新异检测器1000的不同之处在于:新异检测器3000进一步包括对象检测器30。在图6所示的实施例中,使用了图4的生成器100、判别器200和耦合电路300,但是实施例不限于此;例如,在另一实施例中,可以使用图5的生成器400、判别器500和耦合电路600来进行替代。
对象检测器30的输出数据对应于实际数据x。
例如,对象检测器30可以从输入图像Y提取特征数据。
对象检测器30可以包括预先训练的、在现有技术中众所周知的神经网络,因此将省略其详细描述。
可以使用电子电路、光学电路、运行在非暂时性计算机可读介质中存储的软件或固件的一个或多个处理器或它们的组合来实现本公开的实施例。电子电路或光学电路可以包括被配置为执行神经网络处理的电路。一个或多个处理器可以包括中央处理单元(CPU)、图形处理单元(GPU)或它们的组合。
尽管出于说明目的已描述各个实施例,但是可以进行各种改变和修改。
- 新异检测器
- 一种适用于不均匀破碎岩体的新异的光面爆破方法