在多个步长间迁移Transformer时空模型的水质污染预测方法
文献发布时间:2023-06-19 18:30:43
技术领域
本发明涉及水质污染预测技术领域,更具体地说,本发明涉及在多个步长间迁移Transformer时空模型的水质污染预测方法。
背景技术
水作为人类生命、医疗保健、工业需求和农业部分的宝贵资源,其相关问题往往收到重点关注。受污染的水不仅是国家发展的障碍,而且会产生许多疾病,如心脏、肾脏疾病和其他慢性疾病。
近年来,由于人类活动频繁、河流环境污染频发、极端天气条件等原因,地表水水质恶化日益严重。提供合理的水质预测和预警,提前保障应急响应能力,防止负面影响大规模分散,对地表水可持续管理至关重要。然而,由于不可预测的污染源、快速变化的环境条件和不充分的历史数据记录等固有的不确定性,预测地表河流系统水质参数的时间序列变化趋势可能是一项艰巨的任务。
传统方法预测水质污染数据常常具有较高的误差,较差的精度。近年来深度学习的方法被广泛应用于水质污染数据的预测,结果大都由于传统的浅层机器学习方法和物理模型。但是现存的深度学习模型在预测水质污染仍存在一些问题:(1)在预测长期序列时精度较低;(2)没有考虑到多站点情况下的空间关联性。
发明内容
为了克服现有技术的上述缺陷,本发明的实施例提供在多个步长间迁移Transformer时空模型的水质污染预测方法,本发明所要解决的技术问题是:如何解决现有预测水质污染数据时精度较低和多站点情况下的空间无关联性的问题。
为实现上述目的,本发明提供如下技术方案:在多个步长间迁移 Transformer时空模型的水质污染预测方法,具体包括以下步骤:
步骤S1:建立数据集;
S1.1:从同一断面上的多个邻近水质污染监测微站采集连续的污染数据,接着对采集的数据进行清洗和预处理操作;
S1.2:用滑动窗口的方式将步骤S1.1中处理后的数据构建成数据集;
S1.3:步骤S1.2中得到的数据集每个样本中包含24个输入数据,8个输出数据,每个数据由同一时刻的全部站点数据构成;
步骤S2、构建水质污染单步长预测模型:将多步长的预测任务拆分为多个子任务,每个子任务用于预测一个步长的序列数据;在每个子任务中构建 Transformer模型;
步骤S3、构建水质污染多步长预测模型:使用迁移学习在步骤S2构建好的多个单步长预测模型中加速训练,强化模型泛化能;
步骤S4:训练完成后,分别使用每个模型预测对应步长的污染数据,组合在一起后得到多步长结果。
在一个优选的实施方式中,所述步骤S1.1中清洗数据的过程包括剔除不符合常识、经验的数据,并标记为缺失值;对缺失值使用线性插值法。
在一个优选的实施方式中,所述步骤S2中构建的单步长预测模型步骤如下:
S2.1、调整:Transformer模型的超参数:调整超参数N=2,d
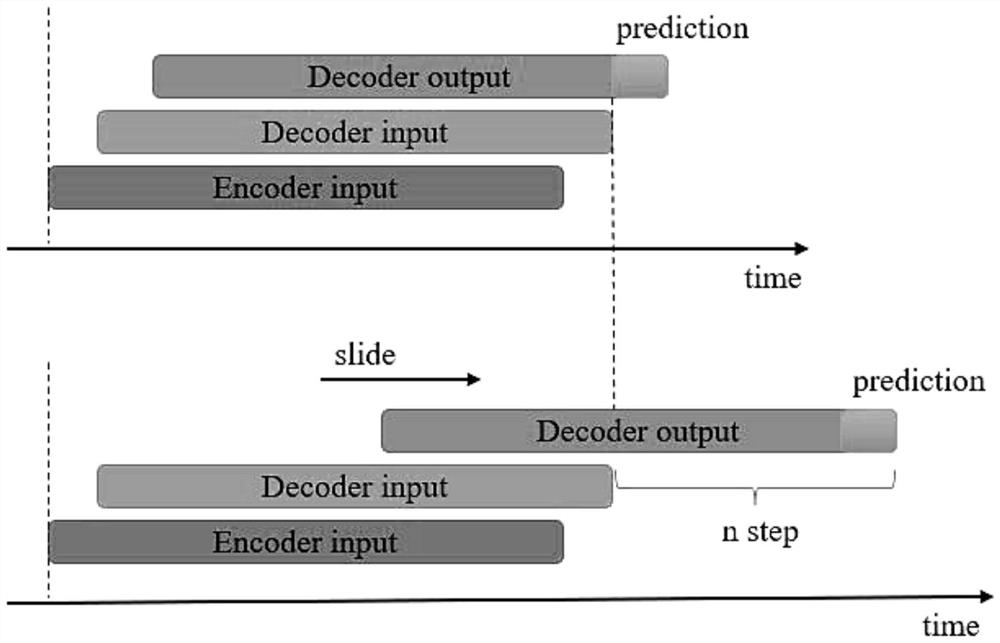
S2.2、模型的输入输出策略:解码器的输入序列由编码器的输入序列右移一位得到;在预测第n个步长的数据时,期望解码器输出的序列是输入序列右移n位得到;每次得到的编码器输出取时间维最后一个数据作为当前步长的结果。
在一个优选的实施方式中,所述步骤S3中的多步长训练策略有如下步骤:
在一个优选的实施方式中,所述步骤S4中的模型预测具体过程如下步骤:
S4.1:分别载入步骤S3中训练好的模型参数,接着将输入数据输入模型;得到每个步长的预测结果;
S4.2:将多个单步长的预测结果组合在一起。
本发明的技术效果和优点:
本发明通过将Transformer模型与迁移学习结合,应用于水质污染数据的预测,取得很好的预测性能;不仅考虑到了多站点间的空间依赖,而且在长期序列预测上提升了预测精度。
附图说明
图1为本发明的模型输入输出策略示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明提供了在多个步长间迁移Transformer时空模型的水质污染预测方法,具体包括以下步骤:
步骤S1:建立数据集;
S1.1:从同一断面上的多个邻近水质污染监测微站采集连续的污染数据,接着对采集的数据进行清洗和预处理操作;
清洗数据的过程包括剔除不符合常识、经验的数据,并标记为缺失值,从而有效避免因数据过度异常的数据引入造成后续模型数据输出的异常,从而干扰得出数据的准确度;对缺失值使用线性插值法;线性插值是指插值函数为一次多项式的插值方式,其在插值节点上的插值误差为零。线性插值相比其他插值方式,如抛物线插值,具有简单、方便的特点。线性插值的几何意义即为概述图中利用过A点和B点的直线来近似表示原函数。线性插值可以用来近似代替原函数,也可以用来计算得到查表过程中表中没有的数值;
S1.2:用滑动窗口的方式将步骤S1.1中处理后的数据构建成数据集(滑动窗口(Sliding window)是一种流量控制技术。早期的网络通信中,通信双方不会考虑网络的拥挤情况直接发送数据。由于大家不知道网络拥塞状况,同时发送数据,导致中间节点阻塞掉包,谁也发不了数据,所以就有了滑动窗口机制来解决此问题);
S1.3:步骤S1.2中得到的数据集每个样本中包含24个输入数据,8个输出数据,每个数据由同一时刻的全部站点数据构成;
步骤S2、构建水质污染单步长预测模型:将多步长的预测任务拆分为多个子任务,每个子任务用于预测一个步长的序列数据;在每个子任务中构建 Transformer模型;构建的单步长预测模型步骤如下:
S2.1、调整:Transformer模型的超参数:调整超参数N=2,d
S2.2、模型的输入输出策略如图1所示:解码器的输入序列由编码器的输入序列右移一位得到;在预测第n个步长的数据时,期望解码器输出的序列是输入序列右移n位得到;每次得到的编码器输出取时间维最后一个数据作为当前步长的结果
步骤S3、构建水质污染多步长预测模型:使用迁移学习(迁移学习:深度学习中在计算机视觉任务和自然语言处理任务中将预训练的模型作为新模型的起点是一种常用的方法,通常这些预训练的模型在开发神经网络的时候已经消耗了巨大的时间资源和计算资源,迁移学习可以将已习得的强大技能迁移到相关的的问题上)在步骤S2构建好的多个单步长预测模型中加速训练,强化模型泛化能;多步长训练策略有如下步骤:
步骤S4:训练完成后,分别使用每个模型预测对应步长的污染数据,组合在一起后得到多步长结果;型预测具体过程如下步骤:
S4.1:分别载入步骤S3中训练好的模型参数,接着将输入数据输入模型;得到每个步长的预测结果;
S4.2:将多个单步长的预测结果组合在一起。
实施方式具体为:通过对相同断面的多个监测站的数据统计,去除异常数据后建立数据集,并利用Transformer模型将建立的数据集进行任务的拆分,并针对拆分后的任务分别构建Transformer模型,对各个Transformer 模型进行加速训练,从而确保该模型构建的准确性及输出数值的正确性,利用该模型对数据进行检测,将多个拆分后的任务分别进行结果的预测,并对多个拆分任务的预测结果进行组合,从而实现对多站点情况下的空间关联性,使得预测结果的精度提升。
最后应说明的几点是:首先,在本申请的描述中,需要说明的是,除非另有规定和限定,术语“安装”、“相连”、“连接”应做广义理解,可以是机械连接或电连接,也可以是两个元件内部的连通,可以是直接相连,“上”、“下”、“左”、“右”等仅用于表示相对位置关系,当被描述对象的绝对位置改变,则相对位置关系可能发生改变;
其次:本发明公开实施例附图中,只涉及到与本公开实施例涉及到的结构,其他结构可参考通常设计,在不冲突情况下,本发明同一实施例及不同实施例可以相互组合;
最后:以上所述仅为本发明的优选实施例而已,并不用于限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 一种基于深度时空修正模型的城市区域尾气污染预测方法
- 双阶段时空注意力机制的污染源-水质预测模型权重影响计算方法
- 基于考虑人类流动性的图时空Transformer模型的交通流预测方法