融合实体上下文和逻辑规则的知识推理方法
文献发布时间:2023-06-19 19:28:50
技术领域
本发明属于知识推理领域,尤其是涉及一种融合实体上下文和逻辑规则的知识推理方法。
背景技术
知识图谱是谷歌公司于2012年提出的概念,被看作是一种反映客观世界的语义网络,其中蕴含丰富的关系模式,最初用来完善谷歌自身的搜索引擎。知识图谱往往被表述为<实体-关系-实体>或<实体-属性-属性值>的三元组形式,以<16舰-搭载-歼15>和<16舰-完工时间-2011年>为例,在第1个三元组中,头实体是“16舰”,尾实体是“歼15”,他们之间关系是“搭载”;第2个三元组中,实体是“16舰”,属性是“完工时间”,属性值为“2011年”。传统依赖人工的知识图谱构建方法不能很好地包含所有知识,同时存在噪声信息,导致图谱稀疏,并且可能存在错误三元组,大规模知识图谱YAGO通过抽样宣布其存在大约5%的错误三元组,因此需要对知识推理进行研究,从而识别知识图谱中的错误三元组,并挖掘潜在隐含三元组。
目前知识推理任务较为流行的模型可分为两大类。一类是基于表示学习的模型,其中比较有代表性的是TransE、DistMult等,这些模型往往先对知识图谱中的实体和关系进行特征表示,再利用表示后的结果进行知识推理。然而其也存在先天劣势,由于基于表示学习的推理方法往往是一个“黑盒”模型,获得推理后的结果但并不清楚具体的推理过程,导致可解释性较弱。另一类是基于逻辑规则的方法,其中比较有代表性的RuleN、Neural LP等,这些模型先从知识图谱中学习逻辑规则,然后利用学习到的逻辑规则进行推理。现有的基于逻辑规则的模型相比基于表示学习的模型具有可解释性,但仍然有以下不足:
(1)规则编码方式较简单,不利于逻辑规则的充分利用。
(2)只考虑规则特征未考虑三元组周围其他结构特征如实体上下文等。
发明内容
有鉴于此,本发明旨在提出一种融合实体上下文和逻辑规则的知识推理方法,以解决规则编码方式简单、未考虑实体上下文特征的问题,更好地建模结构特征,提升模型的整体效果。
为达到上述目的,本发明的技术方案是这样实现的:
一种融合实体上下文和逻辑规则的知识推理方法,是一种融合实体上下文和逻辑规则等三元组周围的结构特征进行知识推理的方法,包括:
实体上下文模块:该模块首先抽取目标头尾实体的实体上下文,然后使用消息传递编码实体上下文。
逻辑规则模块:该模块首先搜索目标头尾实体之间的所有路径,从路径中抽象出逻辑规则,接着把规则的关系向量输入BiLSTM,得到保存了顺序信息的关系向量,然后使用规则感知注意力聚合关系向量,最后基于置信度聚合逻辑规则。
评分模块:该模块聚合实体上下文向量、逻辑规则向量和目标关系向量对目标三元组评分。
进一步的,所述实体上下文模块中实体上下文指目标头尾实体n阶邻域内的关系类型和关系拓扑结构。首先抽取目标头尾实体的实体上下文,然后采用PathCon提出的消息传递方案进行实体上下文编码。边e的初始特征用e所属关系的特征向量表示为
如公式(1)所示,对于每个节点v,将v连接的边的隐藏状态相加,得到消息
其中[·]表示连接操作,W
使用上述消息传递方案计算目标头实体h
其中,
进一步的,所述逻辑规则模块中,考虑的逻辑路径规则形式为封闭路径规则。一条封闭路径规则r的形式为:
P
其中x,y和z是变量,P是关系,每个P(u,v)称为一个原子,u和v分别是P的头实体参数和尾实体参数。
实体对(h
P
则该路径可看做规则P
主要从两个方面考虑建模规则,即规则体中关系的顺序和不同关系对规则的重要程度。首先把规则的关系向量输入BiLSTM,得到保存了顺序信息的关系向量,然后使用规则感知注意力
其中|r
使用目标关系向量P
其中,
进一步的,所述评分模块首先把规则的关系向量输入BiLSTM,得到保存了顺序信息的关系向量,首先拼接实体上下文向量
其中,W
最后结合嵌入模型的评分函数与上述评分函数:
score(h
其中,η为控制知识图谱嵌入得分的权重。
相对于现有技术,本发明所述的知识推理方法具有以下优势:
(1)本发明所述的知识推理方法采用基于注意力和双向BiLSTM的方法进行规则编码,克服了现有规则编码方法效率低下的问题。
(2)本发明所述的知识推理方法同时使用逻辑规则和实体上下文等结构特征进行推理,相比现有方法在推理过程中利用了更多的结构信息,且不同于PathCon只适用于用于关系预测,本发明可用于实体预测。
附图说明
构成本发明的一部分的附图用来提供对本发明的进一步理解,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。在附图中:
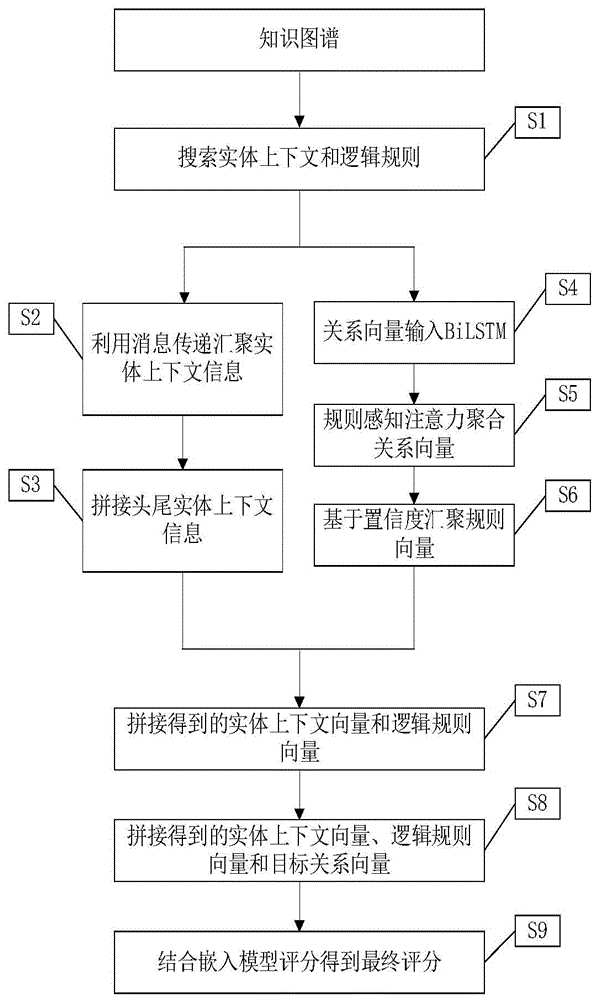
图1为本发明实施例所述的融合逻辑规则和实体上下文的知识推理方法流程示意图;
图2为本发明实施例所述的融合逻辑规则和实体上下文的知识推理方法结构示意图。
具体实施方式
下面将参考附图并结合实施例来详细说明本发明。
如图1和图2所示,本发明提出的融合实体上下文和逻辑规则的知识推理方法同时使用实体上下文和逻辑规则进行推理,显著提高了知识推理的效果,同时还使用基于注意力的方法更好地对规则编码。具体步骤如下:
S1搜索实体上下文和逻辑规则,搜索目标三元组(h
在本实施例中,以三元组(拉里·埃里森,领导,甲骨文)为例,其中,目标头实体h
S2利用消息传递汇聚实体上下文消息;
S2.1边e的初始特征用e所属关系的特征向量表示为
S2.2给定边的初始特征,通过迭代聚合来自其多跳邻居边的消息学习每个边的表示。在第i次迭代中,边的隐藏状态
如公式(1)所示,对于每个节点v,将v连接的边的隐藏状态相加,得到消息
其中[·]表示连接操作,W
S2.3使用S2.2计算目标头实体h
S3拼接头尾实体上下文信息,把
其中,
S4关系向量输入BiLSTM,把规则的关系向量输入BiLSTM,得到保存了顺序信息的关系向量;
S5利用规则感知注意力聚合关系向量;
S5.1使用规则感知注意力
其中|r
S5.2计算规则r
S6基于注意力汇聚规则向量;
S6.1使用目标关系向量P
其中,
S6.2使用置信度计算目标三元组P
S7拼接得到的实体上下文向量、逻辑规则向量和目标关系向量;
S8利用多层感知机评分三元组:
其中,W
在本实施例中,利用MLP对三元组(拉里·埃里森,领导,甲骨文)评分,得到score
S9结合嵌入模型评分得到最终评分:
score(h
其中,η为控制知识图谱嵌入得分的权重。
在本实施例中,η取值为0.4,嵌入模型使用RotatE,结合RotatE评分,得到三元组(拉里·埃里森,领导,甲骨文)最终评分score(拉里·埃里森,领导,甲骨文)=score
为了进一步验证本发明在知识推理任务上的优势,本实施例在3个常用公开数据集WN18RR,NELL-995和UMLS上进行了链接预测实验。在所有数据集上嵌入模型使用RotatE,逻辑规则最大长度K在NELL-995和UMLS数据集上取值为3,在WN18RR数据集上取值为4,在所有数据集上η取值为0.4。对比了表示学习方法ComplEx、RotatE和QuatE,规则学习方法NeuralLP、DRUM和RNNLogic。使用过滤后的排序指标:平均倒数排名MRR、Hit@1、Hit@3和Hit@10作为评价指标。所有实验都使用PyTorch框架用Python编写,在具有8GB显存的RTX3070Ti GPU上运行。
表1、表2和表3展示的是本发明在3个公开数据集上与其他模型的对比结果,最佳结果由粗体的数字表示,“-”表示不可得到的结果。
表1与其他模型在WN18RR数据集上的性能对比结果
表2与其他模型在NELL-995数据集上的性能对比结果
表3与其他模型在UMLS数据集上的性能对比结果
/>
首先将本发明与表示学习方法进行了比较,本发明比ComplEX、RotatE和QuatE取得了更好的结果,这是因为本发明可以同时结合规则和嵌入模型的预测结果。之后将本发明与规则学习方法进行了比较,本发明比Neural LP、DRUM和RNNLogic取得了更好的结果,这是因为本发明同时利用实体上下文和逻辑规则进行推理,并且利用规则注意力可以更高效编码规则。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。