一种基于算力网络的分布式机器学习调度方法和系统
文献发布时间:2024-04-18 19:58:30
技术领域
本发明属于算力网络和分布式机器学习调度技术领域,更具体地,涉及一种基于算力网络的分布式机器学习调度方法和系统。
背景技术
随着云计算、大数据等新兴信息技术业务应用的规模落地,新业务对算力需求越来越高,灵活性、易扩展和简单易用成为未来算力网络必须具备的基本能力。其中分布式计算技术与异构计算技术因其能够有效的获取高性能计算能力、灵活易扩展、开发潜力巨大,成为了当前领域的研究热点之一;其中机器学习训练任务需要大量算力提供支撑,所以分布式机器学习调度技术应运而生,分布式机器学习调度是将机器学习算法与分布式计算相结合,通过将大规模数据和计算任务分发到多个计算节点上进行并行处理。
现存的分布式机器学习调度方法基于两种架构,分别是迭代式架构和参数服务器架构;迭代式架构是基于MapReduce开发,主要适用于同步以及数据并行的应用场景,目前已经存在许多成熟的迭代式架构系统,如Hadoop以及Spark等;参数服务器架构的设计是为了解决迭代式架构同步效率差、鲁棒性欠佳的问题,并且表现出优秀的性能。
然而,上述两种分布式机器学习调度方法仍存在一些问题。第一、对于迭代式架构而言,在每次迭代中需要等待所有节点的计算完成才能进行下一轮迭代,这会导致较高的同步开销和额外的等待时间;第二、对于参数服务器结构而言,服务器需要与各个计算节点之间进行频繁的通信,特别是在算力网络场景中,会产生较高的通信开销,成为性能瓶颈;第三、这两种分布式机器学习调度方法对于节点故障问题缺少简单易用的解决方式,鲁棒性较差。
发明内容
针对现有技术的以上缺陷或改进需求,本发明提供了一种基于算力网络的分布式机器学习调度方法和系统,其目的在于,解决现有迭代式架构在每次迭代中需要等待所有节点的计算完成才能进行下一轮迭代,从而导致较高的同步开销和额外的等待时间的技术问题,以及现有参数服务器结构,由于服务器需要与各个计算节点之间进行频繁的通信,导致会产生较高的通信开销的技术问题,以及上述两种分布式机器学习调度方法对于节点故障问题缺少简单易用的解决方式,鲁棒性较差的技术问题。
为实现上述目的,按照本发明的一个方面,提供了一种基于算力网络的分布式机器学习调度方法,包括以下步骤:
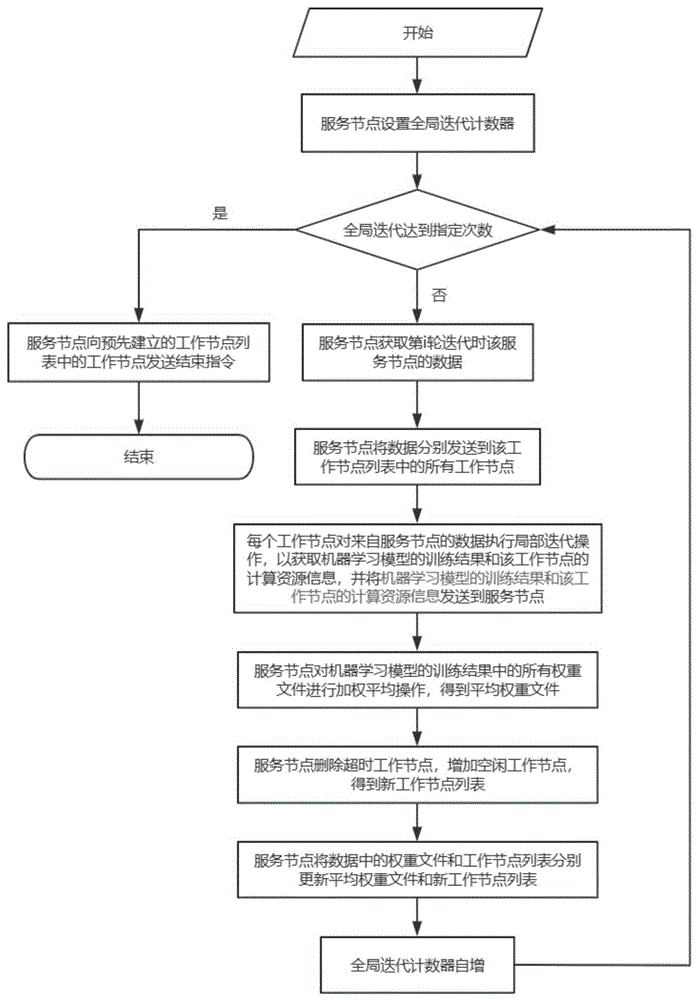
(1)服务节点设置全局迭代计数器i=1;
(2)服务节点判断i是否等于预先设定的阈值,如果是则服务节点向预先建立的工作节点列表中的工作节点发送结束指令,并且过程结束,否则进入步骤(3);
(3)服务节点获取第i轮迭代时该服务节点的数据Q
(4)服务节点读取步骤(3)得到的服务节点的数据Q
(5)每个工作节点对来自服务节点的数据Q
(6)服务节点对步骤(5)得到的机器学习模型的训练结果中的所有权重文件进行加权平均操作,以得到平均权重文件;
(7)服务节点对步骤(3)得到的第i轮迭代时服务节点的数据中的工作节点列表,服务节点删除超时工作节点,增加空闲工作节点,以得到新工作节点列表。
(8)服务节点将步骤(3)得到的第i轮迭代时服务节点的数据中的权重文件和工作节点列表分别更新为步骤(6)得到的平均权重文件和步骤(7)得到的新工作节点列表,以获得第i+1轮迭代时服务节点的数据;
(9)设置全局迭代计数器i=i+1,并返回步骤(2)。
优选地,步骤(5)包括以下子步骤:
(5-1)每个工作节点设置局部迭代计数器j=1;
(5-2)每个工作节点判断j是否等于预先设定的阈值(该阈值的取值与步骤(2)中的阈值完全相同),如果是则进入步骤(5-6),否则进入步骤(5-3);
(5-3)每个工作节点获取其权重文件和步骤(3)得到的数据Q
(5-4)每个工作节点获取步骤(5-3)处理后的梯度数据,并根据处理后的梯度数据和步骤(3)得到的服务节点的数据Q
(5-5)每个工作节点设置局部迭代计数器j=j+1,并返回步骤(5-2);
(5-6)每个工作节点向服务节点发送机器学习模型的训练结果Q
优选地,机器学习模型的训练结果Q
优选地,工作节点列表中第n个工作节点的计算资源信息C
其中a
优选地,步骤(7)包括以下子步骤:
(7-1)服务节点根据步骤(3)得到的延迟迭代阈值d,获取工作节点列表中未在延迟迭代阈值内向服务节点发送机器学习模型的训练结果和工作节点的计算资源信息的所有工作节点所构成的超时工作节点列表。
(7-2)服务节点根据步骤(5)得到的所有工作节点的计算资源信息获取未处于其工作节点列表中的所有空闲工作节点,以获取空闲工作节点列表。
(7-3)服务节点从步骤(3)得到的第i轮迭代时服务节点的数据中的工作节点列表中删除步骤(7-1)得到的超时工作节点列表中的工作节点,并将删除工作节点后的工作节点列表与步骤(7-2)获得的空闲工作节点列表进行合并,以得到新工作节点列表。
优选地,当工作节点的计算资源信息C
按照本发明的另一方面,提供了一种基于算力网络的分布式机器学习调度系统,包括:
第一模块,其设置于服务节点,用于设置全局迭代计数器i=1;
第二模块,其设置于服务节点,用于判断i是否等于预先设定的阈值,如果是则服务节点向预先建立的工作节点列表中的工作节点发送结束指令,并且过程结束,否则进入第三模块;
第三模块,其设置于服务节点,用于获取第i轮迭代时该服务节点的数据Q
第四模块,其设置于服务节点,用于读取第三模块得到的服务节点的数据Q
第五模块,其设置于每个工作节点,用于读取第三模块得到的服务节点的数据Q
第六模块,其设置于服务节点,用于对第五模块得到的机器学习模型的训练结果中的所有权重文件进行加权平均操作,以得到平均权重文件;
第七模块,其设置于服务节点,用于对第三模块得到的第i轮迭代时服务节点的数据中的工作节点列表,服务节点删除超时工作节点,增加空闲工作节点,以得到新工作节点列表。
第八模块,其设置于服务节点,用于将第三模块得到的第i轮迭代时服务节点的数据中的权重文件和工作节点列表分别更新为第六模块得到的平均权重文件和第七模块得到的新工作节点列表,以获得第i+1轮迭代时服务节点的数据;
第九模块,用于设置全局迭代计数器i=i+1,并返回第二模块。
总体而言,通过本发明所构思的以上技术方案与现有技术相比,能够取得下列有益效果:
1、本发明由于采用了步骤(5),其使用的局部迭代方式中,每一次局部迭代过程中工作节点都完成了多次随机梯度下降计算,因此能够解决现有迭代式架构方法存在的较高同步开销和额外等待时间的技术问题。
2、本发明由于采用了步骤(5),其使用的局部迭代方式中,每一次局部迭代过程中工作节点完成多次迭代计算后再与服务节点进行一次通信,因此能够解决现有参数服务器架构方法存在的较高通信开销的技术问题。
3、本发明由于采用了步骤(7),其使用的全局迭代方式中,每一次全局迭代都删除了超时工作节点,并新增了空闲工作节点,因此能够解决现有分布式机器学习调度方法缺少节点故障处理方法的技术问题,提高了系统的鲁棒性。
附图说明
图1是本发明基于算力网络的分布式机器学习调度方法流程图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。此外,下面所描述的本发明各个实施方式中所涉及到的技术特征只要彼此之间未构成冲突就可以相互组合。
本发明的基本思路在于,将机器学习的迭代训练过程拆分为全局迭代和局部迭代两部分。一方面,每一轮全局迭代中,服务节点收集局部迭代过程中各节点的使用情况,并重新分配参与局部迭代的工作节点列表,避免了因为个别节点性能问题产生的长时间等待,提供了平滑的节点变更方式。另一方面,在局部迭代中工作节点统计资源使用情况,然后将资源使用情况发送给服务节点,使本方法中的算力网络能够对各节点进行感知,完成负载均衡与任务分配操作。
如图1所示,本发明提供了一种基于算力网络的分布式机器学习调度方法,包括以下步骤:
(1)服务节点设置全局迭代计数器i=1;
(2)服务节点判断i是否等于预先设定的阈值,如果是则服务节点向预先建立的工作节点列表中的工作节点发送结束指令,并且过程结束,否则进入步骤(3);
具体而言,i=1时,工作节点列表需手动初始化,加入参与第一次迭代的工作节点,当i>1时,工作节点列表在迭代过程中自动更新。
具体而言,阈值的取值范围与机器学习模型的复杂性和数据集的大小相关。建议从一个相对较小的阈值开始,随着训练的进行,可以逐步增加阈值并监控机器学习模型的性能变化。当机器学习模型在验证集上的性能不再提升,或者出现过拟合迹象时,可以选择停止过程,以确定阈值的准确值。
(3)服务节点获取第i轮迭代时该服务节点的数据Q
具体而言,延迟迭代阈值与工作节点的并行度和资源利用率相关,较高的并行度意味着更多的计算资源可以同时执行任务,可能需要更低的延迟迭代阈值以保持进度一致。但是,如果资源利用率较低,例如某些任务的计算时间较长,那么可以适当增加延迟迭代阈值,以减少同步开销并提高整体效率。
(4)服务节点读取步骤(3)得到的服务节点的数据Q
(5)每个工作节点对来自服务节点的数据Q
具体而言,步骤(5)包括以下子步骤:
(5-1)每个工作节点设置局部迭代计数器j=1;
(5-2)每个工作节点判断j是否等于预先设定的阈值(该阈值的取值与步骤(2)中的阈值完全相同),如果是则进入步骤(5-6),否则进入步骤(5-3);
(5-3)每个工作节点获取其权重文件和步骤(3)得到的数据Q
(5-4)每个工作节点获取步骤(5-3)处理后的梯度数据,并根据处理后的梯度数据和步骤(3)得到的服务节点的数据Q
(5-5)每个工作节点设置局部迭代计数器j=j+1,并返回步骤(5-2);
(5-6)每个工作节点向服务节点发送机器学习模型的训练结果Q
具体而言,Q
工作节点列表中第n个工作节点的计算资源信息C
上式中,a
本步骤的优点在于,其使用的局部迭代方式中,每一次局部迭代过程中工作节点都完成了多次随机梯度下降计算,因此能够解决现有迭代式架构方法存在的较高同步开销和额外等待时间的技术问题;并且,在其使用的局部迭代方式中,每一次局部迭代过程中工作节点完成多次迭代计算后再与服务节点进行一次通信,因此能够解决现有参数服务器架构方法存在的较高通信开销的技术问题。
(6)服务节点对步骤(5)得到的机器学习模型的训练结果中的所有权重文件进行加权平均操作,以得到平均权重文件;
(7)服务节点对步骤(3)得到的第i轮迭代时服务节点的数据中的工作节点列表,服务节点删除超时工作节点,增加空闲工作节点,以得到新工作节点列表。
具体而言,本步骤包括以下子步骤:
(7-1)服务节点根据步骤(3)得到的延迟迭代阈值d,获取工作节点列表中未在延迟迭代阈值内向服务节点发送机器学习模型的训练结果和工作节点的计算资源信息的所有工作节点所构成的超时工作节点列表。
(7-2)服务节点根据步骤(5)得到的所有工作节点的计算资源信息获取未处于其工作节点列表中的所有空闲工作节点,以获取空闲工作节点列表。
具体而言,工作节点是否为空闲工作节点的判断方式与工作节点的计算资源信息C
(7-3)服务节点从步骤(3)得到的第i轮迭代时服务节点的数据中的工作节点列表中删除步骤(7-1)得到的超时工作节点列表中的工作节点,并将删除工作节点后的工作节点列表与步骤(7-2)获得的空闲工作节点列表进行合并,以得到新工作节点列表。
本步骤的优点在于,其使用的全局迭代方式中,每一次全局迭代都删除了超时工作节点,并新增了空闲工作节点,因此能够解决现有分布式机器学习调度方法缺少节点故障处理方法的技术问题,提高了系统的鲁棒性。
(8)服务节点将步骤(3)得到的第i轮迭代时服务节点的数据中的权重文件和工作节点列表分别更新为步骤(6)得到的平均权重文件和步骤(7)得到的新工作节点列表,以获得第i+1轮迭代时服务节点的数据;
(9)设置全局迭代计数器i=i+1,并返回步骤(2)。
本领域的技术人员容易理解,以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。