基于并行时空注意力机制的TCN多元时间序列预测方法
文献发布时间:2023-06-19 09:38:30
技术领域
本发明属于机器学习、深度学习和时间序列预测领域,是一种基于深度模型框架的时间序列预测方法。
背景技术
使用复杂系统监控运行状况在今天的生产工厂中已经普及,要确保这些系统顺利运行,不可避免地需要对大量不同的数据流进行持续监控,从温度和压力传感器到图像和视频,再到CPU使用水平、生物数据等等。多变量时间序列预测在我们社会的平稳运行中占据着重要的位置。然而,今天的智能分析系统不仅仅是观察传感器读数是否接近某些阈值,还必须基于历史模式来预测可能发生的事件。而且,一般来说,在预测中可以考虑的历史数据越多,在不同变量中捕获相关性的机会就越高,预测也就越准确。目前,循环神经网络(RNN)是多变量时间序列预测的首选方法。然而,我们认为,RNN从根本上来说并不适合这项任务,它被梯度消失问题所困扰,而像长短时网络(LSTM)、门控循环网络(GRU)这样的技术只是减轻了这个问题,而不是解决它。即使把注意力集中在最重要的信息上,RNN仍难以捕捉足够数量的历史信息来进行高准确度的预测。此外,由于当前时间步的计算需要在开始下一个时间步之前完成,RNN往往会花费过多的时间等待结果,效率低下。
针对该问题,使用并行计算的时间卷积网络(TCN)进行研究可能是一个有效的突破口。此外,尽管存在一些不稳定性和效率问题,但它们比RNN具有更长的记忆力。
那么,如何在充分利用TCN的并行计算能力弥补RNN固有缺点的基础上进行改进,使得预测既准确又稳定成为了一个复杂而待探索的方向。目前,没有一个较为有效的解决方案。
发明内容
本发明的目的是针对现有技术的不足,提供一种基于并行时空注意力机制的TCN多元时间序列预测方法,基于并行时空注意力机制的TCN多元时间序列预测模型PSTA-TCN,充分利用TCN模型的并行性,避免了RNN更新梯度存在的问题,在TCN模型的基础上又增加了并行的时空注意力机制,分别捕捉时间序列在时间上与空间上的依赖关系。此外,在注意力模块中添加了残差连接,使得原始输入信息有选择性的被传递到下一层。我们还为在不同的历史窗口大小进行单步预测后的结果波动提供了详尽的解释。
基于并行时空注意力机制的TCN多元时间序列预测方法,具体步骤如下:
步骤1、公式定义;
多变量的时间序列,包括外生序列和目标序列;
其中,外生序列定义为X=(X
同时定义目标序列为Y=(y
通常,给出外生序列X=(X
步骤2、构建多元时间序列预测模型;
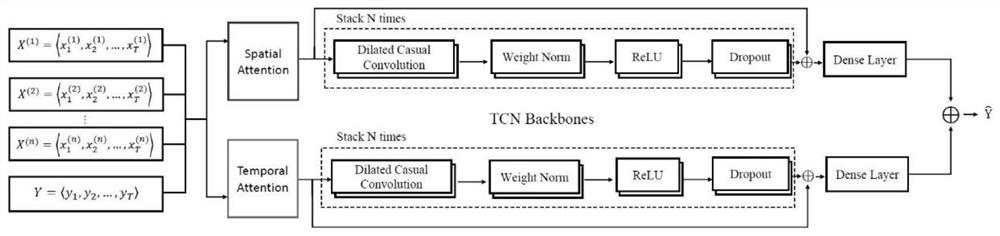
多元时间序列预测模型包括两个并行的网络主干,空间注意力分支主干通过空间注意力模块提取外生序列和目标序列之间的空间相关性,时间注意力分支主干则通过时间注意力模块来捕捉窗口中所有时间步间的时间依赖性。空间注意力模块和时间注意力模块分别连接两个相同的堆叠TCN主干和全连接层。
步骤3、将多变量的时间序列输入多元时间序列预测模型中,获得最终的预测结果;
将多变量的时间序列输入多元时间序列预测模型中,所述的多变量的时间序列包括外生序列和目标序列,多变量的时间序列分别经过两个并行的网络主干,空间注意力分支主干通过空间注意力模块提取外生序列和目标序列之间的空间相关性,时间注意力分支主干则通过时间注意力模块来捕捉窗口中所有时间步间的时间依赖性。空间注意力模块和时间注意力模块的输出通过两个相同的堆叠TCN主干进行处理,获得的输出结果分别被传送到两个全连接层,然后将两个全连接层的输出求和产生最终的预测结果。
进一步的,并行的网络主干时空注意力模块具体操作如下:
空间注意力分支主干采用空间注意力模块提取外生序列与目标序列之间的空间相关性。同时,时间注意力分支主干使用时间注意力模块来获得窗口大小T之间的长历史时间依赖关系。空间注意力分支主干输入表示为
c
其中W
使用softmax函数对生成的空间注意权重向量c
时间注意力分支主干的输入为
d
其中W
其中当前时间步t∈[1,T]。
进一步的,所述的堆叠TCN主干模块具体如下:
使用原始TCN作为基本主干,并将其堆叠N次得到N个层级。TCN中的卷积层采用因果卷积,即不存在信息泄漏,也就是在计算当前时间步输出时,只对当前时间步或之前的状态进行卷积。当处理长序列时,扩张卷积通过指数增长扩张因子实现了在较少的参数和层数的情况下得到更大的感受野。TCN各层的有效历史长度为(k-1)*d,其中k是卷积核大小,d是扩张因子。为了控制参数的数量,选择一个固定k的大小,并且每一层都以指数增加d的值,即d=2
Output=ReLU(X+G(X))
其中X表示原始输入,G(·)表示一个TCN骨干网络的处理过程。
本发明有益效果如下:
本发明方法创新性地提出并行TCN机制提高了传统TCN在长期预测上的稳定性,将时空注意力机制与TCN相结合相较于传统TCN取得了更高的准确率,同时提高网络计算效率相较于基于RNN的模型大大缩减了模型训练所需要的时间。
附图说明
图1:PSTA-TCN模型架构图;
图2:时空注意力模块中的层间转换图;
图3:可穿戴式微型传感器测试图;
图4:单步预测与多步预测的性能折线图;
图5:单步预测的模型训练时间比较图;
具体实施方式
以下结合附图与实施例对本发明方法进行进一步描述。
本发明在现有TCN的局限性的基础上,设计了一种基于并行时空注意力机制的TCN多元时间序列预测模型PSTA-TCN。
基于并行时空注意力机制的TCN多元时间序列预测方法,具体步骤如下:
步骤1、公式定义;
多变量的时间序列,包括外生序列和目标序列;
其中,外生序列定义为X=(X
同时定义目标序列为Y=(y
通常,给出外生序列X=(X
步骤2、构建多元时间序列预测模型;
如图1所示,多元时间序列预测模型包括两个并行的网络主干,空间注意力分支主干通过空间注意力模块提取外生序列和目标序列之间的空间相关性,时间注意力分支主干则通过时间注意力模块来捕捉窗口中所有时间步间的时间依赖性。空间注意力模块和时间注意力模块分别连接两个相同的堆叠TCN主干和全连接层。
步骤3、将多变量的时间序列输入多元时间序列预测模型中,获得最终的预测结果;
将多变量的时间序列输入多元时间序列预测模型中,所述的多变量的时间序列包括外生序列和目标序列,多变量的时间序列分别经过两个并行的网络主干,空间注意力分支主干通过空间注意力模块提取外生序列和目标序列之间的空间相关性,时间注意力分支主干则通过时间注意力模块来捕捉窗口中所有时间步间的时间依赖性。空间注意力模块和时间注意力模块的输出通过两个相同的堆叠TCN主干进行处理,获得的输出结果分别被传送到两个全连接层,然后将两个全连接层的输出求和产生最终的预测结果。
进一步的,并行的网络主干时空注意力模块具体操作如下:
空间注意力分支主干采用空间注意力模块提取外生序列与目标序列之间的空间相关性。同时,时间注意力分支主干使用时间注意力模块来获得窗口大小T之间的长历史时间依赖关系。图2分别显示了时间注意力模块和空间注意力模块的层间转换过程。为了简洁起见,我们省略了对输入Y处理过程的描述。图2(a)显示了空间注意力模块的工作流程。空间注意力分支主干输入表示为
c
其中W
使用softmax函数对生成的空间注意权重向量c
图2(b)显示了计算时间注意力的过程。时间注意力分支主干的输入为
d
其中W
其中当前时间步t∈[1,T]。
进一步的,所述的堆叠TCN主干模块具体如下:
TCN作为序列建模的一种新探索,得益于卷积神经网络(CNN)比RNN具有更强的并行性和更灵活的感受野,面对长序列时需要更少的内存。如图1所示,我们使用原始TCN作为基本主干,并将其堆叠N次得到N个层级。TCN中的卷积层采用因果卷积,即不存在信息泄漏,也就是在计算当前时间步输出时,只对当前时间步或之前的状态进行卷积。当处理长序列时,扩张卷积通过指数增长扩张因子实现了在较少的参数和层数的情况下得到更大的感受野。TCN各层的有效历史长度为(k-1)*d,其中k是卷积核大小,d是扩张因子。为了控制参数的数量,选择一个固定k的大小,并且每一层都以指数增加d的值,即d=2
Output=ReLU(X+G(X))
其中X表示原始输入,G(·)表示一个TCN骨干网络的处理过程。
为了测试PSTA-TCN的性能,我们将在定制的预测任务中测试其性能并与其他5种方法进行比较:2个RNN变种模型,2个使用了注意力的RNN变种模型,以及1个普通TCN模型作为基准。实验场景是人类活动,任务是进行长期运动预测。为了收集数据,我们将四个可穿戴微型传感器安装到10名参与者身上,并要求他们进行5组深蹲,每组深蹲10次。这些传感器(主传感器在左臂,从传感器在右臂和两个膝盖)沿着三个轴(X,Y,Z)测量加速度和角速度数据,并在一个通过蓝牙连接的移动手机应用中显示出来。图3显示了可穿戴微传感器,一个参与者穿戴着传感器设备以及移动应用程序界面。在整个数据收集过程中,我们以50HZ的频率进行采样(即每0.02秒采样一次),在24维数据序列中,我们收集了81536个数据点,即,4个传感器*3个轴*2个维度(加速度和角速度),构成了一个196万数据量的多变量时间序列。在我们的实验中,数据集依照时间顺序按4:1的比例分割为训练集和测试集。此外,我们使用滑动窗口方法将数据集分割成窗口大小的样本,为了避免过拟合,我们随机打乱了所有样本。
我们进行了两组主要的实验,首先是单步预测,然后是多步预测。在训练过程中,我们将批量大小设置为64,初始学习率设置为0.001。
通过单步预测,我们测试了不同窗口大小T∈{32,64,128,256}的每个模型的性能,即不同数量的历史信息。
在多步预测中,我们固定窗口大小T=32,并改变预测步数τ∈{2,4,8,16,32}来验证不同预测步骤的影响。
为了公平起见,我们对所有模型进行了网格搜索,以找到最佳的超参数设置。具体来说,我们为DARNN设置超参数m=p=128,为DSTP设置超参数为m=p=q=128。对于普通TCN和我们的模型PSTA-TCN,我们将卷积核大小设置为7,层数为8。为了保证实验结果的可复现性,我们在所有实验中都设置随机种子为1111。
我们选择了时间序列预测领域中最常用的两个评估指标来对所有模型的性能进行评价:均方根误差(RMSE)和平均绝对误差(MAE)。
它们的表达式为:
其中y
TABLE I
SINGLE-STEP PREDICTION AMONG DIFFERENT WINDOW SIZE
TABLE II
MULTI-STEP PREDICTION AMONG DIFFERENT PREDICTING STEPS
单步预测和多步预测的实验结果分别显示在表1和表2中。我们还将表格数据可视化为折线图,如图4所示。在所有的测试中,PSTA-TCN始终以显著的优势获得最低的RMSE和MAE(最优性能)。在表1中,我们列出了单步预测在不同窗口大小T下的性能。针对不同数量的历史信息,我们的模型可以轻松处理。其中,LSTM和GRU是比较老的模型,没有注意力机制,这意味着没有对过去的信息进行有效的筛选,所以性能不够好。如图4(a)所示,DARNN和DSTP在单步预测方面的性能基本相同,且都优于LSTM和GRU。但我们在图5中比较了在不同的窗口大小T下训练每个模型直至收敛所需的时间。虽然有多个注意力机制的帮助,但是当历史信息变长后,模型训练时间显著增加,而TCN和我们提出的模型由于采用并行计算没有受到太大影响且准确率上升更为顺利。其中,TCN以其强大的表达能力在性能上超过了DARNN和DSTP。对于多步预测,我们可以从表2和图4(b)中观察到,随着预测步长增加,基于RNN的模型性能相对于TCN下降趋势更显著,而我们提出的模型下降最小,即使在预测较长的序列时也是如此。与基于RNN的模型相比,我们提出的PSTA-TCN更加稳定,能够更好地从历史信息中提取时空相关性。将TCN与我们提出的模型进行比较,在预测32步时,TCN已经开始显示出显著的性能下降,但我们提出的模型仍然可以保持与之前相当的性能。因此,PSTA-TCN确实提高了TCN在长期预测中的稳定性。
图5比较了在不同窗口大小T下,每个模型训练到收敛为止所消耗的时间。为了保证公平,我们设置了相同的批量大小。我们可以从中发现,随着窗口大小T的增大,DARNN和DSTP由于RNN本身的串行性和其复杂的注意力机制,运算时间大幅增加,当T=256时从数值上看DSTP的时间复杂度已经达到了普通TCN模型的46倍,PSTA-TCN的13倍。由此单步预测的时间分析可知,当面对较多历史信息时,基于RNN的模型已经开始乏力,从原理上来说,RNN在等待前一步计算结果的过程中耗费了大量时间,且时间随着输入长度呈指数级增长,而TCN并行计算所带来的收益是显而易见的。我们提出的模型相对于普通TCN牺牲了一小部分训练时间,得到了更好的性能。当面对大样本时,我们的模型具有更强的适应性和性能。
- 基于并行时空注意力机制的TCN多元时间序列预测方法
- 一种基于神经网络时空注意力机制的实时站点流量预测方法