一种hadoop采集系统的运行方法
文献发布时间:2023-06-19 09:57:26
技术领域
本发明涉及一种采集系统的运行方法,尤其涉及一种hadoop采集系统的运行方法。
背景技术
Hadoop提供了一个高度容错的中央化分布式存储系统,其有利于集中式的数据分析和数据共享。Hadoop对存储格式没有要求。可以存储用户访问日志、产品信息以及网页数据等数据。
Hadoop分布式文件系统(HDFS)被设计成适合运行在通用硬件(commodityhardware)上的分布式文件系统。HDFS能提供高吞吐量的数据访问,非常适合大规模数据集上的应用。在大数据生态圈中,HDFS是最重要的底层分布式文件系统,它的稳定性关乎整个生态系统的健康。
在日常应用中要将各种数据采集到HDFS存储服务中去,常见的两种数据来源。一种是分散的数据源:机器产生的数据、用户访问日志以及用户购买日志。另一种是传统系统中的数据:传统关系型数据库、磁盘阵列以及磁盘。传统关系型数据库虽然可以搭建内集群但是当数据量达到一定限容度之后查询处理速度会变得很慢且对机器性能要求很高。HDFS具有高容错性,适合批处理、大数据处理,可构建在廉价机器上等优点,缺点是不适宜小文件存取,并发写入、文件随机修改。
发明内容
本发明所要解决的技术问题是提供一种hadoop采集系统的运行方法,能够提升数据采集效率,有效缩短部分流程的超长等待时间。
本发明为解决上述技术问题而采用的技术方案是提供一种hadoop采集系统的运行方法,包括S1)在数据存储层采用hadoop和关系型数据库的混搭架构,存储数据应用层和数据服务层产生的数据;S2)在数据获取层通过基于hadoop的ETL加工过程,对数据应用层和数据服务层产生的数据进行处理,并在数据存储层形成企业数据仓库和数据集市。
进一步地,所述步骤S1通过Sqoop把关系型数据库的数据导入到Hadoop系统中或把数据从Hadoop系统里抽取并导出到关系型数据库里,并利用MapReduce进行数据传输。
进一步地,所述步骤S1中应用层和数据服务层产生的数据为非结构化数据,包括过程数据和业务数据。
进一步地,所述过程数据和业务数据由日志收集工具Flume进行处理,所述Flume由Master、Collector和Agent三部分构成;Master是集群的控制器,负责通信及配置管理;Collector用于对数据进行聚合,并会产生一个更大的数据流,然后加载到HDFS上;Agent负责采集数据并将产生的数据传输到Collector。
进一步地,所述步骤S2中的数据处理包括数据校验、数据清洗、数据关联、数据汇总和数据聚合处理。
进一步地,所述步骤S2中的数据处理包括采集搜索行为的响应时间及结果,得到需要采集索引优化词集合。
进一步地,所述步骤S2中的数据处理包括数据评估分析,具体过程如下:S21、在Datanode服务器运行监视工具nmon,采用监视工具nmon监视hadoop集群系统的性能指标,并从功能性、高效性、可靠性和稳定性四个维度筛选出各评价指标;S22、从hadoop集群系统及监视工具nmon中获得相关指标数据Y=(yij)m*n,i=1,2,…,m,j=1,2,…,n,yij表示第i个待评价对象对应于第j个评价指标的原始数据值;S23、对各评价指标的原始数据进行标准化处理,得到处理后的数据X=(xij)m*n,xij表示第i个待评价对象对应于第j个评价指标经过标准化后的数据值;S24、选取s种评价方法分别按照已选择的评价指标对用电信息采集系统的性能进行评价,计算并得到基于各评价方法的指标权重wkj和评价结论值fki,k=1,2,…,s,i=1,2,…,m,j=1,2,…,n;S25、根据所述评价结论值fki,计算各单一评价方法的变异系数,并进行归一化处理,得到各评价方法的事前权重λk,k=1,2,…,s;S26、基于整体方差最大方法,运用合作博弈的分析方法,计算各单一评价方法的特征函数,即计算多种单一评价方法组成的联盟S进行组合评价时的方差;S27、基于S25求出的各评价方法的事前权重,计算各单一评价方法的变权Shapley值,对其进行归一化处理,得到各评价方法的权重系数μk,k=1,2,…,s;S28、根据得到的各评价方法的权重系数,计算各评价指标的最终权重系数及组合评价值,作为hadooop集群运行性能的综合评价值。
本发明对比现有技术有如下的有益效果:本发明提供的hadoop采集系统的运行方法,通过利用HADOOP的计算和存储优势,对海量数据、非结构化数据进行采集预处理整合,提升海量数据采集效率,有效缩短部分流程的超长等待时间;并可提升数据分析及展示,提高数据展示效率。
附图说明
图1为现有数据采集系统响应耗时示意图;
图2为本发明的hadoop采集系统的架构示意图;
图3为本发明hadoop采集系统的数据安全管理示意图。
具体实施方式
下面结合附图和实施例对本发明作进一步的描述。
图1为现有数据采集系统响应耗时示意图。
请参见图1,在长时间的系统运维实践中,从(数据生存)六个方面对“采集响应耗时长”的原因进行归纳总结,列出了15个末端原因。其中“海量数据采集耗时长”“流程等待时间长”两个原因,是影响“采集响应及时率”的关键因素。
考虑到Hadoop计算框架具有高性能集群计算的存储能力,且易扩展,选择采用hadoop与传统关系型数据库混搭模式,优势互补,即可提升数据采集时效性,又可确保核心数据服务能力的稳定。
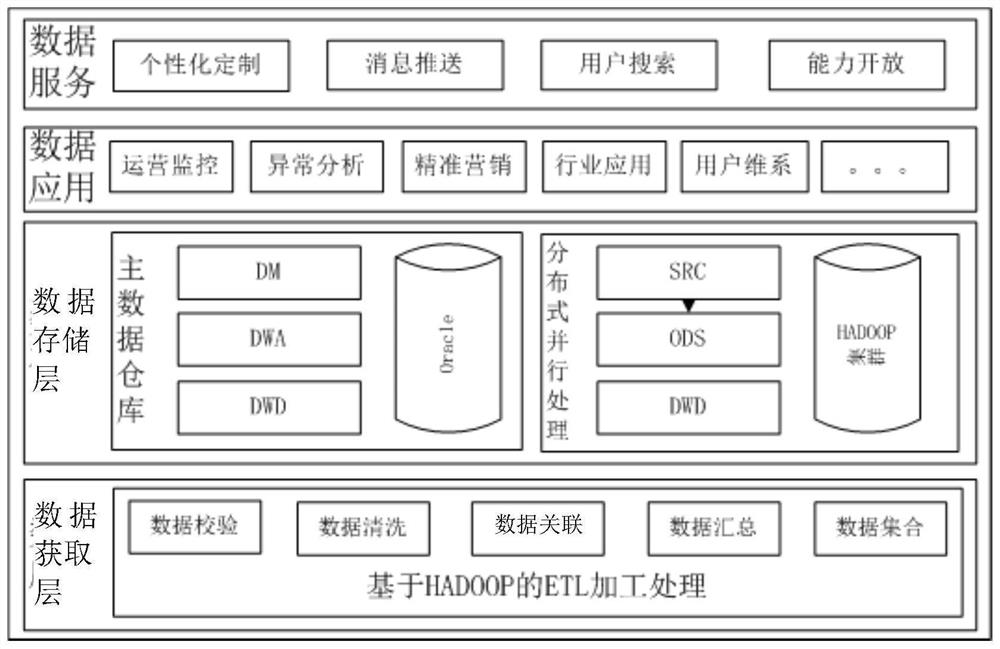
图2为本发明的hadoop采集系统的架构示意图。
请参见图2,本发明提供的hadoop采集系统的运行方法,包括如下步骤:
S1)在数据存储层采用hadoop和关系型数据库的混搭架构,存储数据应用层和数据服务层产生的数据;
S2)在数据获取层通过基于hadoop的ETL加工过程,对数据应用层和数据服务层产生的数据进行处理,并在数据存储层形成企业数据仓库和数据集市。
本发明采用hadoop、传统关系型数据库混搭架构,扬长避短,对大数据平台数据进行分层管理。采用混搭架构的大数据支撑平台,其逻辑架构、数据获取层、数据存储层、数据应用层和数据服务层,采集的数据涵盖了运营商拥有的过程数据和业务数据,数据资源的真实性、丰富性、完整性、连续性,集中体现运营商大数据优势。
数据获取层通过基于hadoop的ETL加工过程,包括数据校验、数据清洗、数据关联、数据汇总、数据聚合等系列加工流程,进行深度分析和信息挖掘,在数据存储层形成企业数据仓库和数据集市。
数据应用层通过业务应用产生的业务数据或者业务日志等数据。
数据服务层则是业务提供的应用服务所产生的数据。
数据存储层是HDFS及关系型数据库层,用于存放各个层的数据等。
本发明在整个数据加工处理,通过以上数据流程图实现流转服务过程,数据质量、数据标准、元数据、生命周期等数据管理措施贯穿始终;通过安全制度、安全技术、安全运营、安全教育等运营机制确保数据安全,如图3所示。
本发明提供的hadoop采集系统的运行方法,所述步骤S1通过Sqoop把关系型数据库的数据导入到Hadoop系统中或把数据从Hadoop系统里抽取并导出到关系型数据库里,并利用MapReduce进行数据传输。Sqoop优势是高效、可控地利用资源、任务并行度、超时时间等、数据类型映射与转换可自动进行或用户也可自定义。MapReduce是一种线性可伸展的编程模型,它建立了清晰的抽象层,采用“分而治之”思想,为用户提供逻辑简单、底层透明的并处理框架。
本发明步骤S1中应用层和数据服务层产生的数据为非结构化数据,包括过程数据和业务数据。所述过程数据和业务数据由日志收集工具Flume进行处理,所述Flume由Master、Collector和Agent三部分构成;Master是集群的控制器,负责通信及配置管理;Collector用于对数据进行聚合,并会产生一个更大的数据流,然后加载到HDFS上;Agent负责采集数据并将产生的数据传输到Collector。
本发明步骤S2中的数据处理包括数据校验、数据清洗、数据关联、数据汇总和数据聚合等系列加工流程,进行深度分析和信息挖掘,在数据存储层形成企业数据仓库和数据集市,从而提升采集效率,提升数据分析及展示,提高数据展示效率。所述步骤S2中的数据处理包括采集搜索行为的响应时间及结果,得到需要采集索引优化词集合;从而优化采集数据流程调度,缩短流程超长时间等待。
本发明步骤S2中的数据处理包括数据评估分析,具体过程如下:
S21、在Datanode服务器运行监视工具nmon,采用监视工具nmon监视hadoop集群系统的性能指标,并从功能性、高效性、可靠性和稳定性四个维度筛选出各评价指标,以构建综合评价指标体系;
S22、从hadoop集群系统及监视工具nmon中获得相关指标数据Y=(yij)m*n,i=1,2,…,m,j=1,2,…,n,yij表示第i个待评价对象对应于第j个评价指标的原始数据值;
S23、对各评价指标的原始数据进行标准化处理,得到处理后的数据X=(xij)m*n,xij表示第i个待评价对象对应于第j个评价指标经过标准化后的数据值;
S24、选取s种评价方法分别按照已选择的评价指标对用电信息采集系统的性能进行评价,计算并得到基于各评价方法的指标权重wkj和评价结论值fki,k=1,2,…,s,i=1,2,…,m,j=1,2,…,n;
S25、根据所述评价结论值fki,计算各单一评价方法的变异系数,并进行归一化处理,得到各评价方法的事前权重λk,k=1,2,…,s;
S26、基于整体方差最大方法,运用合作博弈的分析方法,计算各单一评价方法的特征函数,即计算多种单一评价方法组成的联盟S进行组合评价时的方差;
S27、基于S25求出的各评价方法的事前权重,计算各单一评价方法的变权Shapley值,对其进行归一化处理,得到各评价方法的权重系数μk,k=1,2,…,s;
S28、根据得到的各评价方法的权重系数,计算各评价指标的最终权重系数及组合评价值,作为hadooop集群运行性能的综合评价值。
本发明提供的hadoop采集系统的运行方法,具有如下优点:
1)通过利用HADOOP的计算和存储优势,对海量数据、非结构化数据进行采集预处理整合,提升海量数据采集效率,有效缩短部分流程的超长等待时间。
2)通过平台建设实践过程中,获得了分析数据的及时展现,提高数据展示效率,提升了数据服务支撑的时间窗口。
3)通过采集搜索行为的响应时间及结果,得到需要采集索引优化词集合的方案;减少资源浪费,节省资源拥堵现象。
虽然本发明已以较佳实施例揭示如上,然其并非用以限定本发明,任何本领域技术人员,在不脱离本发明的精神和范围内,当可作些许的修改和完善,因此本发明的保护范围当以权利要求书所界定的为准。
- 一种hadoop采集系统的运行方法
- 一种基于Hadoop的学校教室视频采集监控系统