一种分布式电源高渗透率地区电网综合优化方法
文献发布时间:2023-06-19 10:16:30
技术领域
本发明涉及智能电网领域,更具体地,涉及一种分布式电源高渗透率地区电网综合优化方法。
背景技术
为了缓解能源紧缺和环境污染的双重压力,建设以风电、光伏为代表的分布式新能源发电机组,是我国能源结构变革的重点方向。2019年度全国可再生能源电力发展监测评价报告中指出,全国可再生能源装机容量已接近8亿千瓦,占总装机容量的近四成。受自然资源分布影响,分布式新能源发电具有较强的随机性,难以实现对发电机组出力的精确控制,不同时段出力差异显著,出力高峰和用电高峰往往并不重合。此外分布式新能源发电容易受到气象因素干扰,不具备常规机组出力平滑稳定的特点。大量分布式电源的渗透为系统运行增加了不确定性,增加了系统的调节负担,在分布式电源高渗透率地区,系统调控能力不足的问题日益突出。当分布式电源出力波动超出系统调节范围时,只能采取弃光弃风手段,造成了大量的资源浪费。以网络结构优化和功率分布优化为主要手段的电网综合优化可以充分挖掘系统调控潜力,是提高输电网经济性和安全性的有效手段,可实现单一优化手段无法达到的效果。
公开日为2015年10月07日,公开号为CN104967149A的中国专利公开了一种一种微电网风光储模型预测控制方法,包括以下步骤:建立预测模型,通过预测模型预测未来设定时段内微电网中风电机组和光伏发电的最大出力;以预测到的风电和光伏最大出力作为约束条件,对微电网中风电机组、光伏发电以及储能电池三者出力进行在线优化,给出三者的参考出力;根据风电机组和光伏发电的实时可调容量,对风电机组、光伏发电以及储能电池三者参考出力进行反馈调整。
然而,考虑网络结构切换的输电网综合优化是一个具有高度非凸性的混合整数非线性规划问题,其非凸性来源于潮流方程的非凸性和整数变量引入的非凸项,现有方法无法对该问题进行有效求解。传统的线性化直流潮流模型在近似过程中忽略了输电线路的电阻和两端的相角差,并且认为所有节点电压的标幺值都为1,不能对电压和无功的进行精确近似,难以保证解的可行性和最优性。
发明内容
本发明提供一种分布式电源高渗透率地区电网综合优化方法,结合电网优化运行规律,求解具有非凸和非线性性质的电网综合优化问题,满足电力系统安全稳定运行的基本要求。
为解决上述技术问题,本发明的技术方案如下:
一种分布式电源高渗透率地区电网综合优化方法,包括以下步骤:
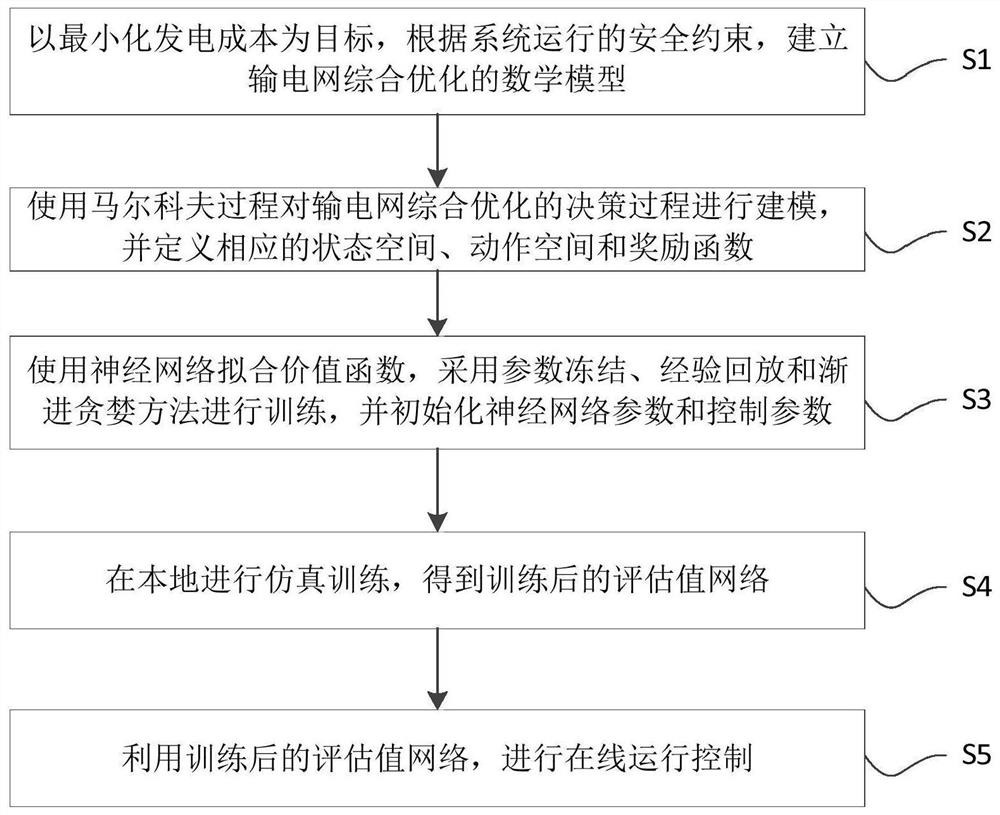
S1:以最小化发电成本为目标,根据系统运行的安全约束,建立输电网综合优化的数学模型;
S2:使用马尔科夫过程对输电网综合优化的决策过程进行建模,并定义相应的状态空间、动作空间和奖励函数;
S3:使用神经网络拟合价值函数,采用参数冻结、经验回放和渐进贪婪方法进行训练,并初始化神经网络参数和控制参数;
S4:在本地进行仿真训练,得到训练后的评估值网络;
S5:利用训练后的评估值网络,进行在线运行控制。
优选地,步骤S1中输电网综合优化的数学模型,具体为:
V
上式中,C
优选地,步骤S2中定义相应的状态空间,具体为:
根据实际情况中可采集到的系统运行数据,选取部分观测量组成马尔科夫过程的状态空间,用以描述当前系统状态:
s=(P
其中P
优选地,步骤S2中动作空间,具体为:
可选择的控制动作组成的动作空间定义下式所示,实际控制时采取的控制动作从定义的动作空间中选取:
A=(ΔP
其中,ΔP
优选地,步骤S2中奖励函数,具体为:
根据在不违背安全约束的情况下降低发电成本的控制目标
上式由两部分组成,前一项为和系统发电成本相关的经济性指标,后一项为和系统电压分布相关的安全性指标,其中,p
优选地,步骤S2中首先需要获取系统的状态,即获取状态空间中的状态量,然后根据当前状态从动作空间中选择最优控制动作执行,系统转移到下一个状态后,算法再次获得系统的观测用来计算奖励并评价刚才采取的动作,以便于优化策略。
优选地,步骤S2中决策过程定义为在系统状态s下采取的动作a,基于值函数的贪婪策略,即选择当前状态下值函数最大的动作,其中值函数定义如下:
Q(s
式中,Q(s
优选地,步骤S3中构建神经网络用于拟合价值函数,采用参数冻结、经验回放和渐进贪婪方法进行训练,并初始化神经网络参数和控制参数,具体为:
S3.1:初始化拟合价值函数的神经网络,包括:1)评估值网络Q
S3.2:初始化学习率α;
S3.3:初始化远期回报衰减率γ;
S3.4:清空本地经验池D,所述本地经验池D用以在训练过程中存储收集到的训练样本,设置经验池容量为N;
S3.5:初始化控制参数,最大训练步数max_iter;
S3.6:初始化选择动作时的贪婪值ε,并设置贪婪值递增步长Δε;
S3.7:初始化训练步数i=0。
优选地,步骤S4中在本地进行仿真训练,得到训练后的评估值网络,具体为:
S4.1:从仿真环境获得观测信号,得到系统状态变量s
S4.2:生成随机数σ∈(0,1),若σ>ε,则从动作空间A中随机选择一个动作作为第i步执行的动作a
S4.3:执行步骤4.2选择的动作,系统状态发生改变,获得系统的新的状态变量s
S4.4:将数据元组(s
S4.5:从经验池D中进行抽取训练样本D
S4.6:对于每一个抽取到的数据元组,计算对应的实际价值函数
否则,计算公司如下所示:
其中,s
S4.7:计算该数据元组上的误差函数值,如下式所示:
S4.8:对样本中的所有元组的误差函数进行求和:
S4.9:使用梯度下降法更新评估值网络Q
S4.10:更新目标值网络Q
式中,ρ是更新权重系数;
S4.11:i=i+1,ε=ε+Δε,判断i是否达到max_iter,若是返回步骤4.1,否则执行步骤4.12;
S4.12:判断收敛性条件,如果收敛执行步骤5,否则继续训练。
优选地,步骤S5中利用训练后的评估值网络,进行在线运行控制,具体为:
S5.1:建立运行控制值网络Q
S5.2:从系统测量装置获得状态观测信息,得到系统状态变量s=(P
S5.3:将s输入运行控制值网络Q
S5.4:返回步骤5.2,更新系统状态。
与现有技术相比,本发明技术方案的有益效果是:
本发明采用马尔科夫过程对决策过程进行建模,提出了一种基于DDQN(DoubleDeep Q-learning)算法的电网综合优化方法,通过高效的深度强化学习算法,在与仿真模型的交互中学习最优控制策略,缩短在线决策时间,快速获得电网综合优化方案。本发明一方面发挥深度学习的强大的泛化能力,处理复杂多变的实际运行场景,另一方面增加了越线惩罚预防机制和模型引导运行策略,增强了算法的容错率和安全性。本发明在算法训练过程中采取渐进收敛的技巧,提升了对动作空间的搜索能力,加速算法收敛。本发明运用深度强化学习实现了对混合整数非线性电网综合优化问题的求解,所提算法具有良好的收敛性和泛化能力,同时保证了结果的最优性和控制的安全性,特别适合分布式电源高渗透率地区的电网使用,可以增强电网应对分布式电源冲击的能力,充分发挥系统调控潜力,降低系统运行成本,避免出现违背安全约束的情况
附图说明
图1为本发明的方法流程示意图。
图2为本发明的方法的实际运行架构示意图。
图3为IEEE-9节点系统示意图。
图4为本发明的训练过程中,发电成本变化示意图。
图5为本发明所提方法在随机场景下的控制效果示意图。
具体实施方式
附图仅用于示例性说明,不能理解为对本专利的限制;
为了更好说明本实施例,附图某些部件会有省略、放大或缩小,并不代表实际产品的尺寸;
对于本领域技术人员来说,附图中某些公知结构及其说明可能省略是可以理解的。
下面结合附图和实施例对本发明的技术方案做进一步的说明。
实施例1
本实施例提供一种分布式电源高渗透率地区电网综合优化方法,如图1和图2,包括以下步骤:
S1:以最小化发电成本为目标,根据系统运行的安全约束,建立输电网综合优化的数学模型;
S2:使用马尔科夫过程对输电网综合优化的决策过程进行建模,并定义相应的状态空间、动作空间和奖励函数;
S3:使用神经网络拟合价值函数,采用参数冻结、经验回放和渐进贪婪方法进行训练,并初始化神经网络参数和控制参数;
S4:在本地进行仿真训练,得到训练后的评估值网络;
S5:利用训练后的评估值网络,进行在线运行控制。
步骤S1中输电网综合优化的数学模型,具体为:
V
上式中,C
步骤S2中定义相应的状态空间,具体为:
根据实际情况中可采集到的系统运行数据,选取部分观测量组成马尔科夫过程的状态空间,用以描述当前系统状态:
s=(P
其中P
步骤S2中动作空间,具体为:
可选择的控制动作组成的动作空间定义下式所示,实际控制时采取的控制动作从定义的动作空间中选取:
A=(ΔP
其中,ΔP
步骤S2中奖励函数,具体为:
根据在不违背安全约束的情况下降低发电成本的控制目标
上式由两部分组成,前一项为和系统发电成本相关的经济性指标,后一项为和系统电压分布相关的安全性指标,其中,p
步骤S2中首先需要获取系统的状态,即获取状态空间中的状态量,然后根据当前状态从动作空间中选择最优控制动作执行,系统转移到下一个状态后,算法再次获得系统的观测用来计算奖励并评价刚才采取的动作,以便于优化策略。
步骤S2中决策过程定义为在系统状态s下采取的动作a,基于值函数的贪婪策略,即选择当前状态下值函数最大的动作,其中值函数定义如下:
Q(s
式中,Q(s
步骤S3中构建神经网络用于拟合价值函数,采用参数冻结、经验回放和渐进贪婪方法进行训练,并初始化神经网络参数和控制参数,具体为:
S3.1:初始化拟合价值函数的神经网络,包括:1)评估值网络Q
S3.2:初始化学习率α,该参数控制神经网络的学习速率,为一标量值,过高的学习率会导致震荡,过低的学习率会导致收敛变慢,学习率的典型值为1×10
S3.3:初始化远期回报衰减率γ,为一标量值,典型值为0.95;
S3.4:清空本地经验池D,所述本地经验池D用以在训练过程中存储收集到的训练样本,设置经验池容量为N,典型值为100000;
S3.5:初始化控制参数,最大训练步数max_iter,典型值为100000;
S3.6:初始化选择动作时的贪婪值ε,典型值为0.5,并设置贪婪值递增步长Δε,典型值为5×10
S3.7:初始化训练步数i=0。
步骤S4中在本地进行仿真训练,得到训练后的评估值网络,具体为:
S4.1:从仿真环境获得观测信号,得到系统状态变量s
S4.2:生成随机数σ∈(0,1),若σ>ε,则从动作空间A中随机选择一个动作作为第i步执行的动作a
S4.3:执行步骤4.2选择的动作,系统状态发生改变,获得系统的新的状态变量s
S4.4:将数据元组(s
S4.5:从经验池D中进行抽取训练样本D
S4.6:对于每一个抽取到的数据元组,计算对应的实际价值函数
否则,计算公司如下所示:
其中,s
S4.7:计算该数据元组上的误差函数值,如下式所示:
S4.8:对样本中的所有元组的误差函数进行求和:
S4.9:使用梯度下降法更新评估值网络Q
S4.10:更新目标值网络Q
式中,ρ是更新权重系数;
S4.11:i=i+1,ε=ε+Δε,判断i是否达到max_iter,若是返回步骤4.1,否则执行步骤4.12;
S4.12:判断收敛性条件,如果收敛执行步骤5,否则继续训练。
步骤S5中利用训练后的评估值网络,进行在线运行控制,具体为:
S5.1:建立运行控制值网络Q
S5.2:从系统测量装置获得状态观测信息,得到系统状态变量s=(P
S5.3:将s输入运行控制值网络Q
S5.4:返回步骤5.2,更新系统状态。
本实施例通过一算例验证本发明有效求解了传统方法不能处理的混合整数非线性规划模型。
算例在Python环境下进行神经网络搭建和训练,训练使用的电网仿真环境为基于Python的仿真工具包Pypower,算例测试硬件条件为
本算例以IEEE-9节点系统为基础,如图3,对其进行改进,将节点3电源改造为分布式新能源。节点1为平衡节点,电压设定为1.0p.u.,其他节点的电压上下限分别为1.05p.u.和0.95p.u.。机组参数见表1,负荷与线路参数见表2。在原系统中,节点5和节点6之间的线路对地电纳较大,线路5-6的充电功率可以使节点5和节点6的电压大幅升高甚至越限。因此选择线路5-6作为备选的可开断线路。
表1含分布式电源的IEEE9节点系统机组参数
表2原始IEEE9节点系统负荷与线路参数
表3 IEEE-9节点系统训练参数
表4 IEEE-9节点系统发电机成本系数
算法的训练过程见图4,在训练的初始阶段,得到的发电成本非常高,这是由于强化学习算法尚处于探索阶段,尚未学习到正确的策略,不能对发电成本和节点电压进行有效的控制,随着训练的进行,智能体的策略逐渐收敛到最优策略,得到的发电成本降至最低水平并且趋于稳定。将算法训练后的值神经网络提取出来,采用基于值函数的贪婪策略进行控制,提取的神经网络基本复现了训练时的效果。
为测试智能体的实际控制效果,提取训练得到的Q网络参数,随机选取出力-负荷模式测试控制效果,采用基于值函数的贪婪策略进行控制,运行效果见图5。在测试场景中,智能体通过一系列电网操作,在可接受的计算时间内,有效降低系统的发电成本,说明算法的适应能力较强。所选随机算例的出力和负荷数据以及控制效果见表5。
表5算例数据和控制效果
相同或相似的标号对应相同或相似的部件;
附图中描述位置关系的用语仅用于示例性说明,不能理解为对本专利的限制;
显然,本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。
- 一种分布式电源高渗透率地区电网综合优化方法
- 一种含分布式电源的配电网扩展规划综合优化方法