用于动作识别的动作结构自注意力图卷积网络
文献发布时间:2023-06-19 10:21:15
技术领域
本发明涉及用于人体动作识别的图卷积网络(graph convolutional network,GCN),特别涉及具有自注意力模型(self-attention model)的改进的时空图卷积网络。
背景技术
近年来,由于人体动作(human action)识别在视频理解中起着重要作用,因此得到了积极的发展。通常,可以从外观、深度、光流、身体等多种模态中识别出人的动作。在这些模态中,动态的人体骨骼通常传达出重要信息,与其他模态形成互补。然而,传统的骨骼建模方法通常依赖于手工制作的特征或遍历规则,因此导致表达力有限,难以推广和/或应用。
现有的通过骨骼建模来识别人体动作的方法存在许多问题和难题,例如但不限于识别效率低、识别速度慢和/或识别精度低。
本申请描述了使用动作结构自注意力图卷积网络(GCN)来识别人体动作的方法、设备、系统和存储介质,其可以克服上述讨论的一些挑战和缺点,改善整体性能,提高识别速度,而不牺牲识别精度。
发明内容
本申请的实施例包括用于识别一个或多个动作的动作结构自注意力图卷积网络(GCN)系统的方法、设备和计算机可读介质。
本申请描述了一种使用图卷积网络(GCN)识别人体动作的方法。该方法包括通过设备获得多个关节点姿态。该设备包括存储指令的存储器和与该存储器通信的处理器。该方法还包括通过该设备对多个关节点姿态进行归一化处理以获得多个归一化的关节点姿态;通过该设备使用改进的时空图卷积网络(spatial-temporal graph convolutionalnetwork ST-GCN)从多个归一化的关节点姿态中提取多个粗略特征;通过该设备降低多个粗略特征的特征维度,以获得多个降维的特征;通过该设备基于自注意力模型对多个降维的特征进行优化,以获得多个优化特征;通过该设备基于多个优化特征识别人体动作。
本申请描述了一种使用图卷积网络(GCN)识别人体动作的设备。该设备包括存储指令的存储器,以及与存储器通信的处理器。当处理器执行指令时,处理器被配置成使设备获得多个关节点姿态;对多个关节点姿态进行归一化以获得多个归一化的关节点姿态;使用改进的时空图卷积网络(ST-GCN)从多个归一化的关节点姿态中提取多个粗略特征;降低多个粗略特征的特征维度以获得多个降维的特征;基于自注意力模型,对多个降维的特征进行优化,得到多个优化特征;基于多个优化特征来识别人体动作。
本申请描述了一种存储指令的非暂时性计算机可读存储介质。指令在由处理器执行时,使处理器执行获得多个关节点姿态;对多个关节点姿态进行归一化处理,以获得多个归一化的关节点姿态;使用改进的时空图卷积网络(ST-GCN)从多个归一化的关节点姿态中提取多个粗略特征;降低多个粗略特征的特征维度以获得多个降维的特征;基于自注意力模型,对多个降维的特征进行优化,得到多个优化特征;基于多个优化特征来识别人体动作。
在附图、说明书和权利要求书中更详细地描述了上述和其他方面及其实施。
附图说明
下面描述的系统和方法可以参考以下附图和非限制性和非穷举性实施例的描述来更好地理解。附图中的组件不一定按比例绘制。而是强调说明申请的原理。
图1显示了用于实现识别一个或多个动作的动作结构自注意力图卷积网络(GCN)系统的示例性电子通信环境。
图2显示了可用于实施图1的电子通信环境的各种组件的电子设备。
图3A显示了由动作结构自注意力GCN识别一个或多个动作的实施例的示意图。
图3B显示了由时空图卷积网络(ST-GCN)识别一个或多个动作的实施例的工作流程。
图4显示了由动作结构自注意力GCN识别一个或多个动作的实施例的流程图。
图5A显示了具有关节点姿态估计和归一化的示例性图像。
图5B显示了具有多个关节的示例性图像。
图5C显示了对多个关节点姿态进行归一化处理以获得多个归一化的关节点姿态的实施例的流程图。
图6A显示特征提取器的示意图。
图6B显示特征提取器的示例图。
图7A显示特征降维器的示意图。
图7B显示了降低多个粗略特征的特征维度以获得多个降维的特征的实施例的流程图。
图8A显示了特征优化器的示意图,该特征优化器包括类似变形编码器的自注意力层。
图8B显示了特征优化器的示例图,其包括类似变形编码器的自注意力层。
图9A显示了包括全连接层和softmax层的分类器的示意图。
图9B显示了基于多个优化特征来识别人体动作的实施例的流程图。
图9C显示了基于由动作结构自注意力GCN预测的人体动作来显示的示例性图像。
图9D显示了基于由动作结构自注意力GCN预测的人体动作来显示的另一示例性图像。
图10A显示了ST-GCN和动作结构自注意力GCN系统的五个评估时期的最高精度度量的图表。
图10B显示了ST-GCN和图10A中使用的动作结构自注意力GCN系统的五个评估时期的前五位精度度量的图表。
图11显示了本申请的实施例的示例性应用,显示了老人正在老人护理中心做运动。
具体实施方式
现在将参考附图来描述该方法,附图以说明的方式显示了具体的示例性实施例。然而,该方法可以以各种不同的形式体现,因此,所覆盖或要求保护的主题旨在被解释为不限于所阐述的任何示例性实施例。该方法可以体现为方法、装置、组件或系统。相应地,例如,实施例可以采取硬件、软件、固件或其任意组合的形式。
在整个说明书和权利要求书中,术语可能具有超出明确陈述的含义的在上下文中暗示或暗含的细微含义。同样,本文使用的短语“在一个实施例中”或“在一些实施例中”不一定指同一实施例。本文使用的短语“在另一实施例”或“在其他实施例中”不一定指不同的实施例。本文使用的短语“在一个实施方式中”或“在某些实施方式中”不一定指相同的实施方式,本文使用的短语“在另一实施方式”或“在其他实施方式中”不一定指不同的实施方式。例如,旨在要求保护的主题包括全部或部分示例性实施例或实施方式的组合。
通常,可以至少部分地根据上下文中的使用来理解术语。例如,本文使用的术语,诸如“和”、“或”或“和/或”,可以包括各种含义,其可以至少部分地取决于使用这些术语的上下文。通常,“或”如果用于关联一个列表,例如A、B或C,则意指A、B和C,在这里用于包容意义,以及A、B或C,在这里用于排他意义。另外,本文使用的术语“一个或多个”或“至少一个”,至少部分取决于上下文,可用于描述单数意义上的任何特征、结构或特性,或可用于描述复数意义上的特征、结构或特性的组合。类似地,诸如“一个”、“一种”或“该”之类的术语可以被理解为表达单数用法或表达复数用法,至少部分地取决于上下文。另外,术语“基于”或“由...确定”可以被理解为不一定意在表达一套排他性的因素,而是可能存在不一定明确描述的其他因素,同样,至少部分取决于上下文。
本申请描述了使用具有自注意力模型的改进的时空图卷积网络(GCN)来识别一个或多个人类动作的方法、设备、系统和存储介质。
人体骨骼的动态可以传递重要信息,用于识别各种人体动作。例如,可以有一些场景,例如但不限于,根据一个或多个视频片段对人体骨骼的动态进行建模,并根据人体骨骼的动态识别各种人体活动。人体活动可以包括但不限于行走、站立、奔跑、跳跃、转身、滑雪、打太极拳等。
从一个或多个视频片段中识别出各种人体活动可能在理解一个或多个视频片段的内容和/或监测特定环境中一个或多个对象的行为方面起着重要的作用。最近,机器学习和/或人工智能(AI)被用于识别人体活动。对于机器来说,要准确、高效地理解实时高清(HD)视频上的含义,仍然是一个巨大的挑战。
神经网络是最流行的机器学习算法之一,在精度和速度上取得了一定的成功。神经网络包括各种变体,例如但不限于卷积神经网络(CNN)、递归神经网络(RNN)、自动编码器和深度学习。
人体骨骼的动态可以由骨骼序列或多个关节点姿态来表示,其可以由一帧以上的多个人体关节的二维或三维坐标表示。每一帧可以表示在不同时间点(例如,在视频片段的一个时间段内的顺序时间点)的关节点姿态的坐标。让计算机从视频中的图像帧中获取含义是一个挑战。例如,体操比赛的视频片段,裁判可以观看体操运动员在比赛中的比赛,以便进一步评估和/或评估;而要让一台计算机达到相当的效率、准确性和可靠性是一个挑战。
一种称为时空图卷积网络(ST-GCN)的动态骨骼模型可以从数据中自动学习空间和时间模式。这种表述不仅使其具有更强的表现力,而且具有更强的泛化能力。
对于标准的ST-GCN模型,可以对视频进行姿态估计,并在骨骼序列上构建空间时间图。多层时空图卷积网络(ST-GCN)在图上生成更高级别的特征图,然后可以将其分类为相应的动作类别。ST-GCN模型可以高精度地进行动作识别,而其速度可能会被限制为较低的帧率,即使是在相对强大的计算机上,例如,配备GTX-1080Ti图形处理单元(GPU)的计算机的帧率约为10帧/秒(FPS)。这可能会妨碍实时应用,因为实时应用可能需要大约或超过25FPS。
可能期望设计一种简化的ST-GCN,其可以达到更高的速度(例如,达到大约或超过25FPS),而不会影响动作识别的准确性。本申请描述了使用简化的ST-GCN来识别人体动作而不会牺牲动作识别的准确性的各种实施例,解决了上面讨论的一些问题。各种实施例可以包括用于识别一个或多个动作的动作结构自注意力GCN。
图1显示了示例性电子通信环境100,其中可以实施动作结构自注意力GCN系统(actional-structural self-attention GCN system)。电子通信环境100可以包括动作结构自注意力GCN系统110。在其他实施中,动作结构自注意力GCN系统110可以被实施为中央服务器或分布在通信网络中的多个服务器。
电子通信环境100还可以包括以下一部分或全部:一个或多个数据库120、一个或多个二维图像/视频采集服务器130、与一个或多个用户(142、172和182)相关联的一个或多个用户设备(或终端140、170和180)、一个或多个应用服务器150、一个或多个三维图像/视频采集服务器160。
上述组件中的任何一个都可以经由公共或专用通信网络(如本地网络或因特网)彼此直接通信,或者也可以经由第三方彼此间接通信。例如但不限于,数据库120与二维图像/视频采集服务器130(或三维图像/视频采集服务器160)之间可以无需经由动作结构自注意力GCN系统110而进行通信。例如,获取的二维视频可以经由123直接从二维图像/视频采集服务器130发送到数据库120,以便数据库120可以将获取的二维视频存储在其数据库中。
在一个实施中,参照图1,动作结构自注意力GCN系统可以在与数据库、二维图像/视频采集服务器、三维图像/视频采集服务器或应用服务器上的不同的服务器上实施。在其他实施中,动作结构自注意力GCN系统、一个或多个数据库、一个或多个二维图像/视频采集服务器、一个或多个三维图像/视频采集服务器和/或一个或多个应用服务器可以实施或安装在单个计算机系统上、或包括多个计算机系统的一个服务器上、或包括多个计算机系统的多个分布式服务器上、或一个或多个基于云的服务器或计算机系统上。
用户设备/终端(140、170和180)可以是任何形式的移动或固定电子设备,包括但不限于台式个人计算机、膝上型计算机、平板电脑、移动电话、个人数字助理等。用户设备/终端可以安装有用于访问动作结构自注意力GCN系统的用户界面。
数据库可以托管在中央数据库服务器、多个分布式数据库服务器或基于云的数据库主机中。数据库120可被配置成存储一个或多个对象执行某些动作的图像/视频数据、中间数据和/或最终结果,以用于实施动作结构自注意力GCN系统。
图2显示了一个示例性设备,例如计算机系统200,用于实施动作结构自注意力GCN系统110、应用服务器150或用户设备(140、170和180)。计算机系统200可以包括通信接口202、系统电路204、输入/输出(I/O)接口206、存储器209和显示电路208,显示电路208例如在本地或远程机器上运行的网络浏览器中生成在本地或用于远程显示的机器接口210。机器接口210和I/O接口206可以包括GUI、触敏显示器、语音输入、按钮、开关、扬声器和其他用户接口元件。I/O接口206的其他示例包括麦克风、视频和静态图像相机、耳机和麦克风输入/输出插孔、通用串行总线(USB)连接器、存储卡插槽以及其他类型的输入。I/O接口206还可以包括键盘和鼠标接口。
通信接口202可以包括无线发射器和接收器(“收发器”)212以及由收发器212的发射和接收电路使用的任何天线214。收发器212和天线214可以支持Wi-Fi网络通信,例如,在IEEE 802.11的任何版本(如802.11n或802.11ac)下。收发器212和天线214可以支持移动网络通信,例如3G、4G和5G通信。通信接口202还可以包括有线收发器216,例如以太网通信。
存储器209可用于存储各种初始、中间或最终数据或模型,以用于实施动作结构自注意力GCN系统。这些数据语料库可以备选地存储在图1的数据库120中。在一个实施方式中,计算机系统200的存储器209可以与图1的数据库120集成在一起。存储器209可以是集中式的或分布式的,并且可以位于计算机系统200的本地或远程。例如,存储器209可以由云计算服务提供商远程托管。
系统电路系统204可以包括硬件、软件、固件或其他电路系统的任何组合。例如,系统电路204可以用一个或多个片上系统(SoC)、专用集成电路(ASIC)、微处理器、离散模拟和数字电路以及其他电路来实现。
例如,系统电路204可以实现为图1中的动作结构自注意力GCN系统110的系统电路220。动作结构自注意力GCN系统的系统电路220可以包括一个或多个处理器221和存储器222。存储器222存储例如控制指令226和操作系统224。例如,控制指令226可以包括用于实施动作结构自注意力GCN系统的组件228的指令。在一个实施方式中,指令处理器221执行控制指令226和操作系统224,以执行与动作结构自注意力GCN系统有关的任何所需功能。
同样,系统电路204可以实施为图1的用户设备140、170和180的系统电路240。用户设备的系统电路240可以包括一个或多个指令处理器241和存储器242。存储器242存储例如控制指令246和操作系统244。用于用户设备的控制指令246可以包括用于实施与动作结构自注意力GCN系统的通信接口的指令。在一个实施中,指令处理器241执行控制指令246和操作系统244以执行与用户设备有关的任何所需功能。
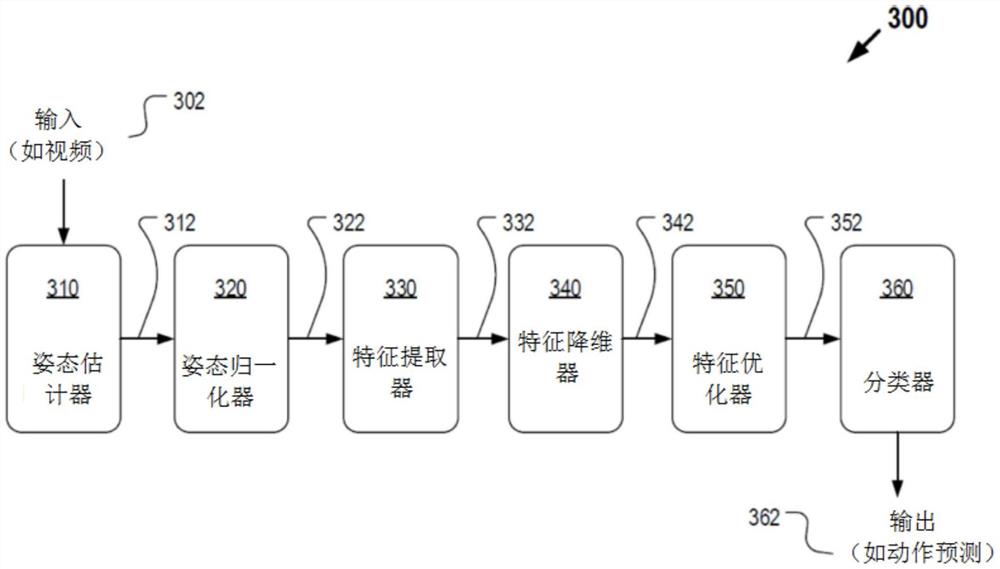
参照图3A,本申请描述了动作结构自注意力图卷积网络(GCN)300基于一个或多个视频片段来识别人的动作的实施例。动作结构自注意力GCN 300可以包括以下功能组件的一部分或全部:姿态估计器310、姿态归一化器320、特征提取器330、特征降维器340、特征优化器350和分类器360。图3A中动作结构自注意力GCN 300中的一个或多个功能组件可以由图2所示的一个设备来实现,或者备选地,动作结构自注意力GCN中的一个或多个功能组件可以由图2所示的多个设备来实现,这些设备之间进行通信以协调地充当动作结构自注意力GCN。
动作结构自注意力GCN 300可以接收输入302,并且可以生成输出362。输入302可以包括视频数据,输出362可以包括基于视频数据的一个或多个动作预测。姿态估计器310可以接收输入302并执行姿态估计以获得并输出多个关节点姿态312。姿态归一化器320可以接收多个关节点姿态312并执行姿态归一化以获得并输出多个归一化的关节点姿态322。特征提取器330可以接收多个归一化的关节点姿态322,并执行特征提取以获得并输出多个粗略特征332。特征降维器340可以对多个粗略特征332进行特征降维以获得并输出多个降维的特征342。特征提炼器350可接收多个降维的特征342,并执行特征优化以获得并输出多个优化特征352。分类器360可接收多个优化特征352,并执行分类和预测以获得和输出包括一个或多个动作预测的输出362。
图3B显示了基于骨骼的人体动作识别的工作流程。与之前传统方法相比,骨骼图网络在动作识别方面显示出显著优势,例如但不限于,基于骨骼的动作识别方法可以避免由于背景和/或身体纹理干扰而引起的变化。深度传感器372和/或图像传感器374可以捕获真实世界动作370(如跑步)。从图像传感器获取的图像数据可以由骨骼提取算法376处理。提取的骨骼数据和/或深度传感器数据可以用于生成以时间流逝方式的骨骼序列380。骨骼序列可以由基于骨骼的人类动作识别(human action recognition,HAR)系统385处理,以获得动作类别390作为对真实世界动作370的预测。
本申请还描述了图4的使用图卷积网络,例如动作结构自注意力图卷积网络,来识别人体动作的方法400的实施例。方法400可以由图2所示的一个或多个电子设备来实现。方法400可以包括以下步骤的一部分或全部:步骤410:获得多个关节点姿态;步骤420:对多个关节点姿态进行归一化处理,以获得多个归一化的关节点姿态;步骤430:使用改进的时空图卷积网络(ST-GCN)从多个归一化的关节点姿态中提取多个粗略特征;步骤440:降低多个粗略特征的特征维度,以获得多个降维的特征;步骤450:基于自注意力模型对多个降维的特征进行优化,得到多个优化特征;步骤460:基于多个优化特征,识别人体动作。
参照步骤410,可以由图3A中的姿态估计器310执行获得多个关节点姿态。姿态估计器可以接收包括视频数据的输入。视频数据可以包括一段时间内的若干帧。姿态估计器310可基于一种或多种姿态估计算法来处理视频数据以获得并输出多个关节点姿态312。姿态估计器310可以利用一种或多种基于手工特征的方法和/或一种或多种深度学习方法来基于视频数据生成多个关节点姿态。在一个实施中,视频数据可以包括基于深度传感器获取的数据,因此可以获得多个关节的三维坐标。
在一个实施方式中,可以从一个或多个运动捕捉图像传感器获得多个关节点姿态,例如但不限于深度传感器、照相机、视频记录器等。在一些其他实施方式中,可以根据姿态估计算法从视频获得多个关节点姿态。来自运动捕捉设备或视频的输出可以包括帧序列。每一帧可以对应于序列中的一个特定时间点,并且每一帧可以用于生成关节坐标,形成多个关节点姿态。
在一个实施方式中,多个关节点姿态可以包括二维坐标形式的关节坐标,如(x,y),其中x是沿x轴的坐标,y是沿y轴的坐标。每个关节的置信度得分可以添加到二维坐标中,因此每个关节可以用(x,y,c)元组表示,其中c是该关节的坐标的置信度得分。
在另一个实施中,多个关节点姿态可以包括三维坐标形式的关节坐标,如(x,y,z),其中x是沿x轴的坐标,y是沿y的坐标,z是沿z轴的坐标。每个关节的置信度得分可以添加到三维坐标中,因此每个关节可以用(x,y,z,c)元组表示,其中c是该关节的坐标的置信度得分。
参照步骤420,可以由图3A中的姿态归一化器320对多个关节点姿态进行归一化,以获得多个归一化的关节点姿态。
图5A显示了视频片段中一个图像帧的例子,该图像帧中的一个或多个对象(510、512、514、516及其他)具有一组或多组关节坐标。对于每个对象,可以识别出多个关节并获得其坐标。关节的数量可以是任何正整数,例如但不限于10、18、20、25和32。可以画出一个相对边界框来包围一个对象。
图5B显示了一个对象的25个关节(从第0关节到第24关节)的一个例子。对于每个对象,可以获得躯干长度。躯干长度可以是第1关节与第8关节之间的距离520。第8关节可以作为包围对象的边界框522的中心。
参照图5C,步骤420可以包括以下步骤的一部分或全部:步骤422:获取多个关节点姿态中的每个关节点姿态的躯干长度;步骤424:根据获取的躯干长度对多个关节点姿态中的每个关节点姿态进行归一化处理,得到多个归一化的关节点姿态。
步骤420可以包括固定的躯干长度归一化,其中所有姿态坐标可以相对于躯干长度进行归一化。可选地和备选地,如果在该图像帧中未检测到一个对象的躯干长度,则该方法可以丢弃该对象,并且不分析该对象的姿态坐标,例如,当该对象的第1和第8关节中的至少一个不在图像帧中,或者由于被其他对象或物体遮挡而看不见时。
参照步骤430,可通过特征提取器330从多个归一化的关节点姿态中使用改进的时空图卷积网络(ST-GCN)提取多个粗略特征。特征提取器可以包括一个改进的时空图卷积网络(ST-GCN)。
图6A显示了包括一个或多个GCN模块的特征提取器600。特征提取器可以包括两个功能单元(610和620)。第一功能单元610可以包括用于骨骼数据的图网络;第二功能单元620可以包括一个或多个卷积层。
在参考图6A的一个实施方式中,每个ST-GCN模块可以包括卷积层622和池化层624中的至少一个。在另一实施方式中,每个GCN模块可以包括卷积层622和池化层624之间的非线性层。非线性层可以包括以下中的至少之一:批量归一化、整流线性单元层和/或非线性激活函数层(如sigmoid函数)。
每个ST-GCN模块包含一个空间图卷积,然后是一个时间图卷积,其交替提取空间和时间特征。空间图卷积是ST-GCN模块中的关键部分,空间图卷积为每个关节引入了相邻特征的加权平均。ST-GCN模块的主要优点可能是提取空间特征,和/或其缺点可能是它只使用权重矩阵来衡量帧间注意(相关性),效果相对较差。
特征提取器模型中的ST-GCN模块的数量可以是,例如但不限于3、5、7、10或13。特征提取器包含的时空图卷积模块越多,则模型中总参数的数量就越多,计算复杂度就越高,完成计算所需的计算时间就越长。由于总参数的数量较大,因此包括10个ST-GCN模块的ST-GCN可能比包括7个ST-GCN模块的ST-GCN慢。例如,标准ST-GCN可以包括10个ST-GCN模块,每个对应的ST-GCN模块的参数可以包括3×64(1)、64×64(1)、64×64(1)、64×64(1)、64×128(2)、128×128(1)、128×128(1)、128×256(2)、256×256(1)和256×256(1)。一个包括10个ST-GCN模块的标准ST-GCN可以包括的总参数数量为3,098,832。
对于参考图6B的一个示例性实施例,特征提取器可以包括轻量级的ST-GCN模型,其包括7个ST-GCN模块(631、632、633、634、635、636和637),每个对应的ST-GCN模块的参数可以包括3×32(1)、32×32(1)、32×32(1)、32×32(1)、32×64(2)、64×64(1)和64×128(1)。包括7个ST-GCN模块的轻量级ST-GCN模型可以包括的总参数数量是2,480,359,与包括10个ST-GCN模块的标准ST-GCN相比,减少了约20%。包括7个ST-GCN模块的轻量级ST-GCN模型可以比包括10个ST-GCN模块的标准ST-GCN运行得快得多。
特征提取器可以包括:基于多个归一化的关节点姿态,构建以关节为图节点(graph nodes)、以人体结构的自然连接性和时间为图边缘(graph edges)的时空图。
在一个实施方式中,可以基于多个归一化的关节点姿态来构建无向(undirected)的时空图G=(V,E)。
V可以是包括N个关节和T帧的节点集,例如V包括v
E可以是包括两个边缘子集的边缘集。第一边缘子集可以表示每一帧的骨骼内连接,例如,第一边缘子集E
第二边缘子集可以表示连续帧中连接同一关节的帧间边缘,例如,第二边缘子集E
参考步骤440,可以通过特征降维器对多个粗略特征的特征维度进行降低,以获得多个降维的特征。步骤440可以在关节上增加卷积,以获得关键关节,降低特征维度,以便进一步处理。
如图7A所示,特征降维器700可以减少关节的数量,例如但不限于,将关节的数量从25减少到12,相当于减少约52%(以13除以25计算)。
在一个实施中,特征提取器输出的序列长度是75×25×256,特征降维器可以将序列长度减小到18×12×128,其中18×12=216是序列的长度,128是向量维度。
参照图7B,步骤440可以包括以下步骤:步骤442:对多个粗略特征进行卷积,以减少多个粗略特征的特征维度,获得与多个关键关节相关联的多个降维的特征。
参照步骤450,可以由图3A中的特征优化器350基于自注意力模型对多个降维的特征进行优化,以获得多个优化特征。步骤450可以在关键帧之间用自注意力方案来优化特征。
参照图8A,特征优化器可以包括类似变形编码器(Transformer encoder)的自注意力模型810,其包括用于提取优化特征的自注意力层(self-attention layer)。变形编码器可包括一个或多个多头注意层(multi-head attention layer)、一个或多个位置前馈层(position-wise feed-forward layer)、一个或多个残余连接层(residual connectionlayer)和/或一个或多个层归一化(layer normalization)。自注意力层可以包括一个或多个输入(如812)和一个或多个输出(如822)。变形模型(Transformer models)广泛用于自然语言处理(NLP)应用的序列-到-序列任务中,例如翻译、总结和/或语音识别。变型模型可用于学习帧间注意力(例如,相关性)和完善基于计算机视觉(CV)的动作识别中的特征。
参照图8B,类似变形编码器的自注意力模型可以包括一个或多个模块840。在一个实施方式中,类似变形编码器的自注意力模型可以包括(N×)个模块840,其中后续模块可以叠加在前一个模块之上。每个模块840可以包括一个多头注意层和一个前馈层。在一个实施方式中,这些叠加的模块可以并行执行以优化速度。N可以是正整数,例如但不限于1、3、5、6、8和10。在一个实施方式中,N可以优选在3和6之间的范围内(包括3和6)。
动作结构自注意力GCN可以使用类似变形编码器的自注意力模型,而不是单纯的权重矩阵,来明确学习帧间注意力(相关性)。类似变形编码器的自注意力机制也可以用来优化特征,因此与原始ST-GCN模型相比可以保持准确性。本申请中的动作结构自注意力GCN可以使用类似变形编码器的自注意力模型,以至少两倍的动作识别速度实现与标准ST-GCN至少相同的准确度水平。
参照步骤460,可以由图3A中的分类器360进行基于多个优化特征来识别人体动作。分类器基于多个优化特征输出一个或多个人体动作预测。
参照图9A,分类器900可以包括全连接层910和softmax层920。全连接层910可以将分类器的输入扁平化为单个值向量,每个值表示某个特征属于某个类别的概率。softmax层920可以将来自全连接层910的未归一化的输出转化为概率分布,该概率分布是归一化的输出。当具有最高概率的类别达到或高于预设阈值时,分类器输出该类别作为预测的人体动作。
参照图9B,步骤460可以包括以下步骤:步骤462:基于多个优化特征从softmax函数生成多个概率值;步骤464:根据多个概率值,预测人体动作。
可选地,该方法还可以包括将预测的人体动作覆盖在一个或多个图像帧上,并显示覆盖的图像帧。在一个实施方式中,可以将预测的人体动作覆盖为具有突出的字体类型、大小或颜色的文本。可选地和/或备选地,在另一个实施方式中,也可以显示覆盖图像帧中的关节点姿态。
例如,图9C是一个具有预测人体动作为“越野滑雪”的显示。另一个例子,图9D是一个具有预测人体动作为“太极拳”的显示。
本申请描述的实施例可以根据一般的ST-GCN进行训练和/或使用标准参考数据集进行测试,例如但不限于动作识别NTU RGB+D数据集(http://rose1.ntu.edu.sg/datasets/actionrecognition.asp)和Kinetics数据集(https://deepmind.com/research/open-source/kinetics)。
NTU-RGB+D数据集包含由一个或两个表演者完成的56,880个骨骼运动序列,这些序列被分为60个类别(即60个人体动作类别)。NTU-RGB+D数据集是基于骨骼的动作识别的最大数据集之一。NTU-RGB+D数据集提供了每个人一个动作中25个关节的三维空间坐标。为了评估模型,可以使用两种协议:第一种协议是跨主体(cross-subject),第二种协议是跨视角(cross-view)。在“跨主体”中,由20个对象执行的40个样本,320个样本可以划分为训练集,其余的属于测试集。跨视角可以根据相机视图分配数据,其中训练集和测试集可以分别包括37,920和18,960个样本。
Kinetics数据集是一个用于人类行为分析的大型数据集,包含超过240,000个视频片段,有400个动作。由于仅提供红绿蓝(RGB)视频,因此可以使用OpenPose工具箱通过估计某些像素上的关节位置来获取骨骼数据。该工具箱将从分辨率为340像素×256像素的调整视频中生成总共25个关节的二维像素坐标(x,y)和置信度c。每个关节可以表示为三元素特征向量:[x,y,c]。对于多帧情况,可以选择每个序列中具有最高平均关节置信度的主体。因此,一个具有T帧的片段被转换为一个大小为25×3×T的骨骼序列。
图10A和10B显示了使用NTU-RGB+D数据集时,两个比较系统的五个评估时期的一些实验结果。第一个系统包括具有10个ST-GCN模块的标准ST-GCN系统,第二个系统是具有7个ST-GCN模块的动作结构自注意力GCN系统。
图10A中的图表1010显示了ST-GCN 1014和动作结构自注意力GCN系统1012的五个评估时期的最高(top-1)精度度量。显然,在前两个时期期间,动作结构自注意力GCN系统1012的精度比ST-GCN1014高得多;而在第3至第5个时期,动作结构自注意力GCN系统1012的精度与ST-GCN 1014大致相同或更好一些。
图10B中的图表1030显示了ST-GCN 1034和动作结构自注意力GCN系统1032的五个评估时期的前5位(top-5)精度度量。显然,在前两个时期期间,动作结构自注意力GCN系统1032的精度比ST-GCN1034高得多;而在第3至第5个时期,动作结构自注意力GCN系统1032的精度与ST-GCN 1034大致相同或更好一些。
本申请还描述了上述实施例的各种应用。对于各种应用的一个示例,本申请的实施例可以应用于老年人护理中心。在本申请实施例提供的动作识别技术的帮助下,老年人护理中心的服务人员可以更准确地记录一组老年人的主要活动,然后分析这些数据以改善老年人的生活。例如,在老年人护理中心锻炼时(见图11)。另外,在动作识别技术的帮助下,可以进一步减少提供护理所需的中心服务人员的数量,同时,可以更准确和/或迅速地检测到老年人可能发生的伤害行为,例如跌倒。
对于各种应用的另一示例,本申请的实施例可以用于自动检测。在某些场合,人们可能需要进行大量重复性的工作,例如,汽车制造厂的工人需要对即将出厂的汽车进行多次出厂检查。此类工作往往需要高度的责任心和专业的职业道德。如果工人未能履行这些职责,可能很难发现。通过动作识别技术,汽车制造厂的人员可以更好地评估此类人员的绩效。本申请中的实施例可以用来检测工作人员是否完全完成了主要工作步骤,这可以帮助确保工作人员履行其所有必需的职责,以确保对产品得到正确的检测并保证质量。
对于各种应用的另一示例,本申请中的实施例可用于智慧学校。本申请中的实施例可以安装在中小学校园等公共场所,以帮助学校管理者识别并解决少数中小学学生可能存在的某些问题。例如,某些中小学可能发生校园欺凌和校园斗殴事件。此类事件可能在老师不在场的情况下发生,或者发生在校园的僻静角落。如果不及时发现和处理这些问题,可能会使事态升级,事件发生后也很难追查到肇事者。动作识别和行为分析可以立即提醒教师和/或管理员注意这些情况,以便及时处理。
对于各种应用的另一示例,本申请中的实施例可用于智能监狱和拘留所。本申请中的实施例可用于提供被拘留者的动作分析,通过其可以更准确地测量被拘留者的情绪状态。本申请中的实施例还可以用于帮助监狱管理部门检测囚犯的可疑行为。本申请中的实施例可以用于拘留室和监狱,用于寻找打架和自杀企图,这可以使城市矫正设施现代化,提供智能化的监狱和拘留。
通过前述实施例的描述,本领域技术人员可以理解,根据前述实施例的方法可以仅由硬件实现,也可以由软件和必要的通用硬件平台实现。但是,在大多数情况下,使用软件和必要的通用硬件平台是优选的。基于这种理解,本质上,本申请的技术方案或者对现有技术有贡献的部分可以以软件产品的形式实现。该计算机软件产品存储在存储介质(例如ROM/RAM、磁盘或光盘)中,并包含若干指令,用于指示终端设备(可以是移动电话、计算机、服务器、网络设备等)以执行本申请的实施例中描述的方法。
尽管已经参照说明性实施例描述了特定发明,但是本描述并不意味着是限制性的。对本领域普通技术人员来说,从本描述中可以明显看出对说明性实施例和附加实施例的各种修改。本领域技术人员将容易认识到,在不脱离本发明的精神和范围的情况下,可以对在此说明和描述的示例性实施例进行这些和各种其它修改。因此,设想所附权利要求书将覆盖任何这样的修改和替代实施例。附图中的某些比例可能被夸大,而其他比例可能被最小化。因此,本申请和附图应被认为是说明性的而非限制性的。
- 用于动作识别的动作结构自注意力图卷积网络模型
- 用于动作识别的动作结构自注意力图卷积网络