一种基于深度度量学习的中医舌图像腐腻特征分类方法
文献发布时间:2023-06-19 10:32:14
技术领域
本发明涉及图像分类方法,特别涉及一种基于深度度量学习的中医舌图像腐腻特征分类方法。
背景技术
中医是我国文化的重要组成部分,是我国人民长期同疾病作斗争的经验总结和理论概括。它以独特的理论体系屹立于世界医学之林,是人类医学的宝贵财富。中医舌诊是中医四诊中望诊的重要内容,医生通过观察舌色、舌体形态、苔色、苔质等各种舌象特征来诊断病症,是中医医治原则辨证施治中的重要环节。长期以来,舌诊结果主要是通过医生目测观察,根据个人经验判断,受到医生知识水平和经验等主观因素影响。舌诊结果主观性强,缺少统一的标准,严重的阻碍了中医的现代化。因此,实现中医舌诊信息客观化已经成为了中医现代化发展过程中亟待解决的一个问题。
舌象腐腻特征是中医舌诊的重要指标,医生可以通过腐腻特征推断病人是否痰湿或食滞。其中腻苔是指舌苔细腻紧密、光滑,白腻,原因多为湿寒,黄腻原因多为湿热;腐苔是指苔如腐渣、疏松,原因多为食积、痰浊。通过计算机对舌图像的腐腻特征进行分析、使舌图像腐腻特征信息客观化有利于诊断病症,具有重要的应用价值。
对舌图像特征进行分类主要可以分为两大类:基于传统方法的舌图像分类和基于深度学习的舌图像分类。传统的舌图像分类方法需要针对舌图像人工精心设计特征,因此提取出来的特征会有具体的物理含义,但是这通常需要丰富的专业经验,提取的特征往往是一些底层特征,比如纹理、颜色、形状、梯度等。手工设计的特征存在泛化能力有限,从而导致舌图像分类准确率不高的局限性。近年来深度学习由于其强大的特征提取和表达能力,为许多行业带来了变革。将深度学习知识理论应用于中医舌图像腐腻特征分类,有望提供更准确的中医舌象分析结果。
在利用深度学习模型进行舌图象腐腻特征分类时主要有两个待解决的问题:1)高质量有标签的舌图像样本获取代价高:舌图像训练样本需要依靠有丰富舌诊经验医生标注,其花费代价往往是比较高,往往比较难以获取。因此,通常中医舌象训练数据集规模较小。如果直接应用深度学习算法时可能会由于训练样本数量不足,造成模型难以训练或过拟合等现象。2)对在医院的真实场景下采集的舌图像数据进行分析时,会发现获取的腐腻特征各类别的样本数量比例存在明显差异,即样本类别不均衡。类别样本数量相对较多的被称为多数类别,类别样本数量相对较少的被称为少数类别。类别比例不均衡的训练样本数据集直接应用深度学习的网络训练时可能会得到泛化能力较差的模型,会导致分类结果会偏向多数类别,使模型对少数类别的样本识别率较低。
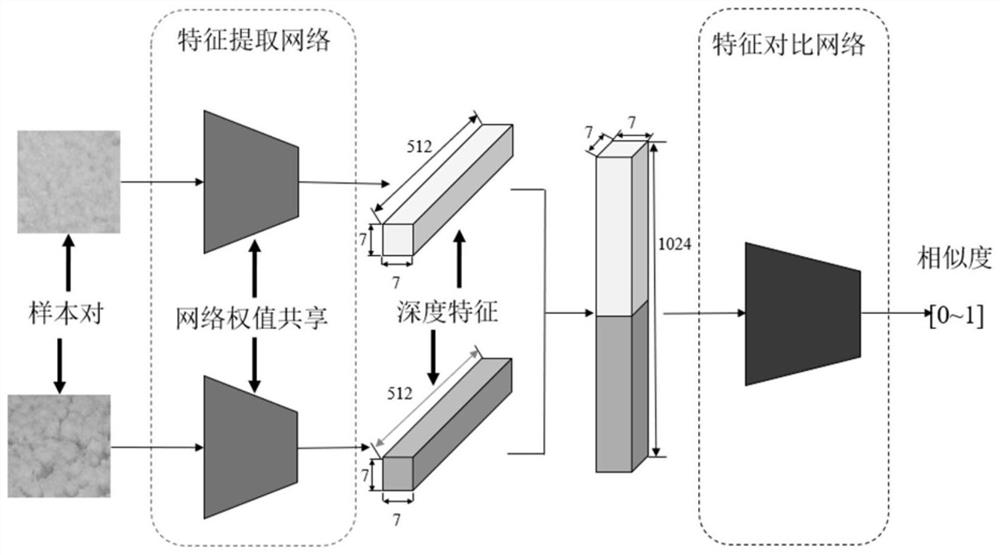
本发明提出了一种基于深度度量学习的中医舌图像腐腻特征分类方法。设计了一个结合自适应度量准则的深度度量学习网络。其可以分为两部分,一部分为特征提取网络,采用孪生网络提取具有区分度的特征;第二部分为特征对比网络,根据输入的样本自适应的学习度量准则,判断特征之间的相似度;本发明可以有效的提高舌图像腐腻分类的准确性。该技术在中医舌图像自动分析中具有重要的应用价值。
发明内容
本发明的目的在于解决中医舌图像腐腻特征分类时,由于获取的舌图像样本量不足时出现的过拟合现象,和真实场景下采集的舌图像样本的腐腻特征存在类别不均衡所导致训练的模型对少数类别识别率较低的问题。针对以上问题,提出一种基于度量学习的中医舌图像腐腻特征分类方法,该方法可以通过设定训练数据的读取机制和从数据中自适应学习度量准则,实现准确的舌图像腐腻特征自动分类。
本发明是采用以下技术手段实现的:
一种基于深度度量学习的中医舌图像腐腻特征分类方法。该方法利用根据舌图像腐腻特征数据集特点所设计的数据读取机制和采用孪生网络框架来实现。
1)本发明通过每次训练时进行数据重组的方式,从数据集中每个类别随机选取数量相同的样本,构成本次训练所使用的数据集,并对随机选取的样本进行两两排列组合组成形成训练数据,其中一对样本为一个训练数据。
2)一种基于深度度量学习的中医舌图像腐腻特征分类方法。该方法采用孪生网络框架。首先,把组合后的训练数据样本对送入特征提取网络,提取到对于当前中医舌图像腐腻特征分类任务具有区分度的深度特征,然后,将提取的两个深度特征进行维度拼接,并把拼接后的合并特征送入特征对比网络,自适应的学习出适合当前中医舌图像腐腻特征分类的度量准则。该方法的整体网络如附图1所示,分为两部分:特征提取网络和特征对比网络,如附图2、3所示。以下是分别对特征提取网络和特征对比网络的详细介绍。
特征提取网络的结构:采用孪生网络结构,即两个神经网络建立的组合结构。孪生神经网络以两个样本为输入,输出为提取的样本深度特征,以比较两个样本之间的相似程度。其中两个神经网络权值共享,即网络权重一样,保证提取输入的两幅舌图像相同的深度特征。特征提取网络采用的是残差网络,主要由残差模块组成。残差模块在网络结构中加入恒等映射,允许前一层的信息可以直接传递到后面的层中。因为舌图像的底层特征,比如颜色、纹理等对腐腻特征分类有帮助,残差网络可以使的对腐腻特征分类有用的底层特征更好的传递到高层特征中,从而可以提升舌图像分类准确性。
特征提取网络由一个卷积层和4个残差模块组成。卷积层包括一个卷积操作和一个最大池化,对图像进行降维,其中卷积核大小为7×7。特征提取网络中的每个残差模块都是由两个残差单元组成,一个残差单元包含一个恒等映射。第一个残差模块的残差单元,由两个3×3的卷积操作,两个卷积之间依次有批归一化和非线性激活函数(ReLU),残差单元之后还有一个ReLU函数。后三个残差模块与第一个残差模块设计上稍有不同,因为后3个残差模块的第一个残差单元输入输出特征维度改变,所以需要额外在跳层连接加入1×1的卷积对跳层连接的输出进行调整。
特征对比网络的结构:采用卷积层和线性层组成,输入为特征特提取网络提取到的深度特征,首先经过128个3×3卷积核对深度特征进行特征降维,之后进过批归一化和非线性激活函数ReLU,增加模型的鲁棒性和表达能力。在经过两个线性层,线性层神经元个数分别为10和1,最后经过sigmoid函数,使输出的相似度的值在0到1之间。
该方法分为两个阶段:训练阶段和测试阶段;
训练阶段具体步骤如下:
第一步,建立训练数据队列;舌图像数据集中腐腻特征分为腻,稍腻,非腐腻3类,每个类别分别有c
第二步,利用特征提取网络对样本对提取特征;输入为第一步建立的数据队列中的样本对,输出为对应的舌图像提取到的两个深度特征;为了防止出现过拟合现象,采取对整个网络参数进行微调的方式训练网络,即采用预训练模型的参数作为训练时特征提取网络的初始参数,并使用训练数据进行整个网络参数的训练这样可以有效提高训练效率和准确性。
第三步,特征对比网络对深度特征计算相似度;输入为特征提取网络输出的两个深度特征的拼接特征,具体为在空间维度上对特征提取网络输出的两个深度特征进行拼接,提取到的深度特征维度为[c×h×w],其中c、h、w分别代表特征图的通道数、高、宽。拼接后的维度为[2c×h×w]。输出为特征对比网络计算的相似度大小的值。同一类别的样本应该具有较高的相似度,不同类别的样本之间的相似度较低;在本发明中设置相似度的值越接近1则代表两个深度特征越相似;同理相似度的值越接近0,则代表两个深度特征相似度越低。
整个训练过程的代价损失函数loss被分为两部分。第一部分为输入的样本对否为同类样本,训练时约束网络计算出的同类样本之间的相似度的值接近于1,不同类样本之间的相似度的值接近于0。可表示为:
loss1=-(y*log
其中p代表特征对比网络计算出的相似度的值,y代表两个样本类别决定的样本对标签,如果样本对的类别一样则为1,反之为0。第二部分为两个深度特征计算相似度的值时,应该没有拼接顺序的区别。假设特征提取网络的输出的两个深度特征为a和b。假设a&b代表a拼接b后的特征。F_R(a&b)代表计算出的a和b之间的相似度,则F_R(a&b)=F_R(b&a),相同样本对计算出的相似度的值应该相同。同时为了使loss2与loss1之间有相同的数量级,所以同样用交叉熵来计算其损失函数,所以其可以表示为:
loss2=-(y*log
在计算loss2时,可以推出y=0,所以最后loss2可化简为:
loss2=log
所以总损失为loss=loss1+loss2。
测试阶段步骤如下:
第一步,利用训练好的特征提取网络对训练集中所有样本提取对应的深度特征,之后计算出每个类别的中心深度特征,即
使用类别中心深度特征代表该类在度量空间中的位置,所以可以得到类别数量的类别中心深度特征;测试样本同样经过特征提取网络提取其深度特征;
第二步,利用学习到的度量准则即对比网络,计算测试样本的深度特征与每个类别中心深度特征之间的相似度的值,之后采用最近邻的思想,把测试样本归为与之计算出相似度的值最大的类别。本发明中没有直接采用把测试样本类别归为和每一个训练样本的相似度的值最大的类别,因为舌图像样本数据不足,构建的度量空间会受到一定的影响,直接使用最近邻分类可能会由于异常点、样本数据较少等原因导致测试样本错误分类,所以应当从全局考虑,从而采用平均相似度进行归类。并且提前机算出类别中心深度特征的方法速度明显快于直接使用最近邻思想分类。
本发明与现有技术相比,具有以下明显的优势和有益效果:
本发明首先每轮训练时采用数据重组的方式形成新的数据队列,可以一定程度减少舌图像腐腻特征存在的类别不均衡情况;并采用孪生网络思想,在特征提取网络的学习时利用特征对比网络学习度量准则,使学习出的度量准则比提前设定的欧式距离、余弦相似度、皮尔逊系数等人为提前设定的度量方式更加适合于舌图像腐腻特征分析;最后,计算训练数据集的类别中心深度特征,并采用测试样本的深度特征与各类别的中心深度特征计算出测试样本的类别,这样一定程度上可以提高算法的鲁棒性。
1.利用数据重组的方式,每次训练前从数据集选取出舌图像腐腻特征类别相对均衡的部分数据,并排列组合形成数据队列,一定程度上缓解采集到的舌图像样本数量较少和腐腻特征存在的类别不均衡的情况;
2.提出利用网络学习度量准则代替人为提前设定的度量准则方式,使得学习出的度量准则更加适用于当前舌图像腐腻特征分类任务,从而提高分类的准确性;
3.测试时,利用训练好的特征提取网络计算出每个类别的中心深度特征,利用每个类别中心深度特征计算其与测试样本的相似度,并计算出测试样本的类别。采用平均相似度可以提升分类模型的性能,同时算法更加地鲁棒。
下面结合实例参照附图进行详细说明,以求对本发明的目的、特征和优点得到更深入的理解。
附图说明:
图1、发明方法网络结构;
图2、特征提取网络结构;
图3、特征对比网络结构;
图4、方法测试阶段分类方法示意图;
图5、舌图像腐腻特征数据集示意图;
具体实施方式:
以下结合说明书附图,对本发明的实施实例加以详细说明:
(1)从医院现场采集的舌图像分辨率为5184×3456,舌图像分辨率太大,不能直接作为训练数据集,并且为了减少所采集的舌图像中存在的无关信息对舌图像腐腻特征分类造成干扰,先对采集的舌图像数据进行舌苔关键位置图像块的选取,选取的图像块分辨率大小为224×224,并且选取的图像块之间无重复区域,并以此分辨率为标准制作舌图像腐腻特征数据集,其特征类别分为非腐腻,稍腻和腻。最终经过数据清洗,筛除一些明显错误数据、缺失值处理、重复值处等操作,最终构建实验所用的舌图像腐腻特征数据集,如附图5所示;其详细信息为训练集共1500张,测试集443张。
(2)训练的具体实现步骤如下:
a)数据队列的构造;网络的整体训练轮数设置为10000轮,每轮训练时都重新从每一类数据中随机选出30个样本,腐腻特征一共有三类,即共选出90个样本。进行排列组合后形成的数据队列中共90×90=8100个样本对,每个样本对的标签取决于样本对中两个舌图图像样本的类别,相同类别时样本对的标签设置为1,反之设置为0。在训练时每轮都需要重新构造数据队列,从而可以更加充分利用整个数据集的信息。
b)特征提取网络;网络结构如图2所示,采用预训练18层残差网络模型作为特征提取网络的主干,因为舌图像腐腻特征分类与自然图像分类任务存在一定的差异,相对于自然图像,舌图像腐腻特征不同类别之间的差异较小,很多细小的纹理可能都是重要信息,所以把预训练模型参数作为主干网络的初始参数,使用随机梯度下降(SGD)优化器训练模型,采用固定步长衰减学习率,起始学习率设置为0.005,之后每隔500个epoch学习率就减少为原来80%,为了防止过拟合采用权值衰减(weight decay)设置为1e-5。训练时对特征网络进行微调。特征提取网络的输入两幅大小为3×224×22像素的舌图像,经过特征提取网络提取出更具有判别性的深度特征,深度特征输出维度为512×7×7。
c)特征对比网络:网络结构如图3所示,对提取到的两个特征提取进行空间维度上拼接,形成1024×7×7的特征送入特征对比网络。特征对比网络结构如图3所示,拼接的深度特征首先经过128个3×3的卷积核,输出维度为128×7×7,其后跟一个归一化操作和一个ReLU激活函数,再经过全局平局池化输出维度为128×1×1,维度变为再经过两个线性层,线性层神经元个数分别为10和1,最后经过sigmoid函数,使输出的相似度的值在0到1之间。代表拼接的特征之间计算出的相似度值。值越接近1则代表两个特征越相似,则很大可能两个舌图像样本为同类样本。反之接近0,很大可能两个舌图像样本为不同类样本。特征对比网络的训练方式和参数和特征对比网络保持一致,但是网络参数采取随机初始化。
(d)同时对特征对比网络和特征对比网络进行训练。最终使得网络收敛,损失loss保持基本不变。
(3)测试阶段的具体实现步骤如下:
a)测试方法如图4所示,利用训练好的特征提取网络对训练集中所有样本提取深度特征,之后计算出每个类别的中心深度特征类别a
其中n代表当前计算的类别中的所有样本数量,a
b)对测试样本进行分类:对测试样本同样提取特征a
Max(F_R(a
- 一种基于深度度量学习的中医舌图像腐腻特征分类方法
- 基于深度元度量模型互学习的小样本图像分类方法