数据血缘生成方法及装置
文献发布时间:2023-06-19 11:03:41
技术领域
本公开涉及数据分析技术领域,尤其涉及数据血缘生成方法及装置。
背景技术
目前,在数据处理过程中,可以将原始数据作为输入数据,输入数据处理管线(pipeline),由pipeline进行一系列处理操作(operator)处理后得到最终输出的数据。其中,pipeline最终输出的数据可以作为输出数据,输出数据与输入数据、经pipeline中的处理操作生成的中间数据组成数据血缘。数据血缘可以描述数据处理过程中生成的中间数据与输入/输出数据之间的依赖关系,技术人员可以根据数据血缘进行数据分析处理,如:数据回溯或影响分析等功能。因此,数据血缘在数据分析技术领域中的应用越来越广。
其中,上述各类数据,如:输入数据、中间数据以及输出数据,可以以包括一个或多个字段/列的数据表的形式呈现在数据血缘中,也可以以字段/列的形式呈现在数据血缘中,即现有技术中数据血缘的精细度可以是数据表级或者字段/列级,在根据数据血缘进行数据分析时,仅能回溯或分析到输出数据中数据来源于输入数据中的某一个或某几个字段/列,数据分析不够精确。
发明内容
本公开提供一种数据血缘生成方法及装置,可以将数据血缘的精细度提高至亚字段级。本公开的技术方案如下:
根据本公开实施例的第一方面,提供一种数据血缘生成方法,该方法包括:根据结构化查询语言SQL,得到逻辑执行计划树LOT,其中,所述SQL用于指示源输入列以及多个处理操作;所述LOT包括与所述多个处理操作对应的多个算子,具有串行关系的两个算子通过有向边连接,每个算子包括所述算子的输出列,每个算子具有表达式树或者不具有表达式树;将所述源输入列作为所述多个算子中起始算子的输入列,推导得到每个算子的输入列与输出列之间的映射关系;其中,对于所述多个算子中具有表达式树的第一算子,所述第一算子的输入列与输出列之间的映射关系包括所述第一算子的输入列包括的亚字段与所述第一算子的输出列之间的映射关系;根据所述每个算子的输入列与输出列之间的映射关系,得到所述多个算子中根算子的输出列与所述源输入列之间的映射关系。
在一种可能的实现方式中,所述表达式树包括至少一条路径,所述路径包括至少一个节点,所述路径与所述第一算子的具有映射关系的输入列与输出列对应,所述至少一个节点串行连接;所述推导得到所述第一算子的输入列与输出列之间的映射关系包括:建立亚字段关系映射表;其中,所述亚字段关系映射表包括所述至少一个节点中每个节点的标识、所述节点所处路径的输入列以及所述节点的表达式间的对应关系;对于第一节点,所述第一节点为所述至少一个节点中的任一节点,根据所述第一节点所处路径的输入列、所述第一节点的表达式以及所述第一节点所处路径中,所述第一节点的下游节点的表达式,确定所述第一节点的输出列;若所述第一节点为所述第一节点所处路径的根节点,将所述第一节点的输出列与所述第一算子的输出列之间的映射关系,确定为所述第一算子的输入列与输出列之间的映射关系。
在一种可能的实现方式中,所述至少一个节点包括相关节点,所述相关节点的输入列包括一个或多个亚字段,所述相关节点的表达式使用所述相关节点的输入列包括的亚字段执行相应操作;若所述第一节点为相关节点,所述根据所述第一节点所处路径的输入列、所述第一节点的表达式以及所述第一节点所处路径中,所述第一节点的下游节点的表达式,确定所述第一节点的输出列,包括:根据所述第一节点所处路径的输入列以及所述第一节点所处路径中,所述第一节点的下游节点的表达式,确定所述第一节点的输入列;根据所述第一节点的输入列以及所述第一节点的表达式,得到所述第一节点的输出列。
在一种可能的实现方式中,所述至少一个节点包括非相关节点,所述非相关节点的输入列包括一个或多个亚字段,所述非相关节点的表达式不使用所述非相关节点的输入列包括的亚字段执行相应操作;若所述第一节点为非相关节点,所述根据所述第一节点所处路径的输入列、所述第一节点的表达式以及所述第一节点所处路径中,所述第一节点的下游节点的表达式,确定所述第一节点的输出列,包括:根据所述第一节点所处路径的输入列以及所述第一节点所处路径中,所述第一节点的下游节点的表达式,确定所述第一节点的输入列;将所述第一节点的输入列确定为所述第一节点的输出列。
在一种可能的实现方式中,所述根据所述每个算子的输入列与输出列之间的映射关系,得到所述多个算子中根算子的输出列与所述源输入列之间的映射关系,包括:对所述多个算子中的第i+1个算子,根据所述第i+1个算子的输入列与输出列之间的映射关系以及所述第i个算子的输出列与所述源输入列之间的映射关系,得到所述第i+1个算子的输出列与所述源输入列之间的映射关系;其中,i为大于或者等于1的整数;当所述第i+1个算子为所述根算子的子算子时,根据所述第i+1个算子的输出列与所述源输入列之间的映射关系、以及所述根算子的输入列与输出列之间的映射关系,得到所述根算子的输出列与所述源输入列之间的映射关系。
根据本公开实施例的第二方面,提供一种数据血缘生成装置,包括处理模块和推导模块;所述处理模块,被配置为根据结构化查询语言SQL,得到逻辑执行计划树LOT,其中,所述SQL用于指示源输入列以及多个处理操作;所述LOT包括与所述多个处理操作对应的多个算子,具有串行关系的两个算子通过有向边连接,每个算子包括所述算子的输出列,每个算子具有表达式树或者不具有表达式树;所述推导模块,被配置为将所述源输入列作为所述多个算子中起始算子的输入列,推导得到每个算子的输入列与输出列之间的映射关系;其中,对于所述多个算子中具有表达式树的第一算子,所述第一算子的输入列与输出列之间的映射关系包括所述第一算子的输入列包括的亚字段与所述第一算子的输出列之间的映射关系;所述处理模块,还被配置为根据所述每个算子的输入列与输出列之间的映射关系,得到所述多个算子中根算子的输出列与所述源输入列之间的映射关系。
在一种可能的实现方式中,所述表达式树包括至少一条路径,所述路径包括至少一个节点,所述路径与所述第一算子的具有映射关系的输入列与输出列对应,所述至少一个节点串行连接;所述推导模块,具体被配置为建立亚字段关系映射表;其中,所述亚字段关系映射表包括所述至少一个节点中每个节点的标识、所述节点所处路径的输入列以及所述节点的表达式间的对应关系;所述推导模块,还具体被配置为对于第一节点,所述第一节点为所述至少一个节点中的任一节点,根据所述第一节点所处路径的输入列、所述第一节点的表达式以及所述第一节点所处路径中,所述第一节点的下游节点的表达式,确定所述第一节点的输出列;所述推导模块,还具体被配置为若所述第一节点为所述第一节点所处路径的根节点,将所述第一节点的输出列与所述第一算子的输出列之间的映射关系,确定为所述第一算子的输入列与输出列之间的映射关系。
在一种可能的实现方式中,所述至少一个节点包括相关节点,所述相关节点的输入列包括一个或多个亚字段,所述相关节点的表达式使用所述相关节点的输入列包括的亚字段执行相应操作;若所述第一节点为相关节点,所述推导模块,还具体被配置为根据所述第一节点所处路径的输入列以及所述第一节点所处路径中,所述第一节点的下游节点的表达式,确定所述第一节点的输入列;所述推导模块,还具体被配置为根据所述第一节点的输入列以及所述第一节点的表达式,得到所述第一节点的输出列。
在一种可能的实现方式中,所述至少一个节点包括非相关节点,所述非相关节点的输入列包括一个或多个亚字段,所述非相关节点的表达式不使用所述非相关节点的输入列包括的亚字段执行相应操作;若所述第一节点为非相关节点,所述推导模块,还具体被配置为根据所述第一节点所处路径的输入列以及所述第一节点所处路径中,所述第一节点的下游节点的表达式,确定所述第一节点的输入列;所述推导模块,还具体被配置为将所述第一节点的输入列确定为所述第一节点的输出列。
在一种可能的实现方式中,所述处理模块,具体被配置为对所述多个算子中的第i+1个算子,根据所述第i+1个算子的输入列与输出列之间的映射关系以及所述第i个算子的输出列与所述源输入列之间的映射关系,得到所述第i+1个算子的输出列与所述源输入列之间的映射关系;其中,i为大于或者等于1的整数;所述处理模块,还具体被配置为当所述第i+1个算子为所述根算子的子算子时,根据所述第i+1个算子的输出列与所述源输入列之间的映射关系、以及所述根算子的输入列与输出列之间的映射关系,得到所述根算子的输出列与所述源输入列之间的映射关系。
根据本公开实施例的第三方面,提供一种数据血缘生成装置,该装置包括:处理器、用于存储所述处理器可执行指令的存储器;其中,所述处理器被配置为执行所述指令,以实现上述第一方面以及第一方面的任一种可能的实现方式中所述的数据血缘生成方法。
根据本公开实施例的第四方面,提供一种存储介质,当所述存储介质中的指令由数据血缘生成装置的处理器执行时,使得数据血缘生成装置够执行上述第一方面以及第一方面的任一种可能的实现方式中所述的数据血缘生成方法。
根据本公开实施例的第五方面,提供一种计算机程序产品,当其在计算机上运行时,以实现上述第一方面以及第一方面的任一种可能的实现方式中所述的数据血缘生成方法。
本公开的实施例提供的技术方案至少带来以下有益效果:血缘生成装置可以根据SQL得到LOT,将源输入列作为多个算子中起始算子的输入列,推导得到每个算子的输入列与输出列之间的映射关系,并根据每个算子的输入列与输出列之间的映射关系,得到多个算子中根算子的输出列与源输入列之间的映射关系,因为对于多个算子中包括表达式数的第一算子,第一算子的输入列与输出列之间的映射关系包括第一算子的输入列包括的亚字段与第一算子的输出列之间的映射关系,也就是说,第一算子的输入列与第一算子的输出列之间的映射关系是亚字段级的映射关系,所以根据每个算子的输入列和输出列之间的映射关系,得到的多个算子中根算子的输出列与源输入列之间的映射关系也是亚字段级的映射关系,提高了数据血缘的精细度。采用本公开实施例示出的数据血缘生成方法得到的数据血缘进行数据分析时,可以回溯或分析到输出数据中数据来源于输入数据中的某一个或某几个字段/列中的某个亚字段,可以得到更精确的分析结果,另外,用户还可以根据该更精确的分析结果对输入数据进行操作(例如,删除输入数据中的某一列中的某个亚字段)。
应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,并不能限制本公开。
附图说明
此处的附图被并入说明书中并构成本说明书的一部分,示出了符合本公开的实施例,并与说明书一起用于解释本公开的原理,并不构成对本公开的不当限定。
图1A是根据一示例性实施例示出的一种逻辑执行计划树的示意图。
图1B是根据一示例性实施例示出的一种表达式树的示意图一。
图1C是根据一示例性实施例示出的一种表达式树的示意图二。
图2是根据一示例性实施例示出的一种实施环境的架构示意图。
图3是根据一示例性实施例示出的一种数据血缘生成方法的流程图一。
图4是根据一示例性实施例示出的一种数据血缘生成方法的流程图二。
图5是根据一示例性实施例示出的一种数据血缘生成方法的流程图三。
图6是根据一示例性实施例示出的一种数据血缘生成装置的框图一。
图7是根据一示例性实施例示出的一种数据血缘生成装置的框图二。
具体实施方式
为了使本领域普通人员更好地理解本公开的技术方案,下面将结合附图,对本公开实施例中的技术方案进行清楚、完整地描述。
需要说明的是,本公开的说明书和权利要求书及上述附图中的术语“第一”、“第二”等是用于区别类似的对象,而不必用于描述特定的顺序或先后次序。应该理解这样使用的数据在适当情况下可以互换,以便这里描述的本公开的实施例能够以除了在这里图示或描述的那些以外的顺序实施。以下示例性实施例中所描述的实施方式并不代表与本公开相一致的所有实施方式。相反,它们仅是与如所附权利要求书中所详述的、本公开的一些方面相一致的装置和方法的例子。
首先,对本公开下述实施例中的逻辑执行计划树(logical operator tree,LOT)进行介绍。
该LOT可以包括多个算子(或运算符),具有串行关系的两个算子可以通过有向边连接。LOT中,和一条有向边连接,并且该有向边未指向的算子称为叶子算子,和一条有向边连接,并且该有向边指向的算子称为根算子,叶子算子与根算子之间的算子可以称为中间算子。叶子算子的输入数据可以称为源输入列,根算子的输出数据可以称为目标输出列。被有向边连接的两个算子中,有向边指向的算子,是未指向的算子的父算子,有向边中未指向的算子,是有向边指向的算子的子算子,如图1A所示,为LOT的示意图。
图1A中,LOT可以包括以下算子:表扫描算子(TableScanOperator)、过滤算子(FilterOperator)、选择算子[S1](SelectOperator[S1])、选择算子[S2](SelectOperator[S2])和文件输出算子(FileSinkOperator)。其中,TableScanOperator和FilterOperator具有串行关系,并通过有向边连接,FilterOperator和SelectOperator[S1]具有串行关系,并通过有向边连接,SelectOperator[S1]和SelectOperator[S2]具有串行关系,并通过有向边连接,SelectOperator[S2]和FileSinkOperator具有串行关系,并通过有向边连接。LOT中,FileSinkOperator为根算子,TableScanOperator为叶子算子,FilterOperator、SelectOperator[S1]和SelectOperator[S2]为中间算子。源输入列可以通过TableScanOperator输入LOT,并经过FilterOperator、SelectOperator[S1]、SelectOperator[S2]和FileSinkOperator得到目标输出列。其中,FileSinkOperator是SelectOperator[S2]的父算子,SelectOperator[S2]是FileSinkOperator的子算子,类似的,SelectOperator[S2]是SelectOperator[S1]的父算子,SelectOperator[S1]是SelectOperator[S2]的子算子,SelectOperator[S1]是FilterOperator的父算子,FilterOperator是SelectOperator[S1]的子算子,FilterOperator是TableScanOperator的父算子,TableScanOperator是FilterOperator的子算子。
需要说明的是,图1A所示仅为LOT的示例,在实际应用中,LOT还可以是其他形式,不予限制。
其中,LOT中的每个算子可以包括该算子的输出列。该算子的输出列为该算子的父算子的输入列。算子的输出列也可以描述为算子的输出列模式(column schema)。
LOT中的每个算子可以具备表达式树或者不具备表达式树。若算子的输出列是将该算子的输入列经过表达式计算得到的,则该算子具备表达式树。若算子的输出列不是将该算子的输入列经过表达式计算得到的,则该算子不具备表达式树。表达式树可以包括多个节点。具有串行关系的两个节点通过有向边连接,表达式树中,输出列为该算子的输出列的节点称为根节点,输入列为该算子的输入列的节点称为叶子节点,叶子节点与根节点之间的节点可以称为中间节点。被有向边连接的两个节点中,有向边指向的节点,是有向边未指向的节点的父节点,有向边中未指向的节点,是有向边指向的节点的子节点。
例如,图1A中的TableScanOperator、FilterOperator和FileSinkOperator不具备表达式树,TableScanOperator的输出列可以包括TS_col0、TS_col1和TS_col2,FilterOperator的输出列可以包括F_col0和F_col1,FileSinkOperator的输出列可以包括FS_col0、FS_col1、FS_col2和FS_col3。图1A中的SelectOperator[S1]和SelectOperator[S2]具备表达式树。SelectOperator[S1]具备的表达式树如图1B所示,SelectOperator[S2]具备的表达式树如图1C所示。
图1B中,SelectOperator[S1]的表达式树包括节点101-节点105。其中,节点101的表达式为ChildOperator.F_col0,该表达式可以表示节点101使用FilterOperator的输出列F_col0,节点102的表达式为ExprNodeFieldRef(ChildOperator.F_col1,‘name’),该表达式表示节点102使用FilterOperator的输出列F_col1中的name,节点103的表达式为ExprNodeFieldRef(ChildOperator.F_col1,‘workinfo’),该表达式表示节点103使用FilterOperator的输出列F_col1中的workinfo,节点104的表达式为ExprNodeFieldRef(ChildExprNode,‘adds’),该表达式表示节点104使用节点103的输出列中的adds,节点105的表达式为ExprNodeFieldRef(ChildExprNode,‘field’),该表达式表示节点105使用节点103的输出列中的field。SelectOperator[S1]的输出列包括S1_col0、S1_col1、S1_col2和S1_col3,节点101的输出列即为S1_col0,节点102的输出列即为S1_col1,节点104的输出列即为S1_col2,节点105的输出列即为S1_col3。节点103是节点104和节点105的子节点,节点104和节点105是节点103的父节点。
图1C中,SelectOperator[S2]的表达式树包括节点106-节点109。其中,节点106的表达式为ChildOperator.S1_col0,该表达式可以表示节点106使用SelectOperator[S1]的输出列S1_col0,节点107的表达式为UdfToString(ChildOperator.S1_col1),该表达式表示节点107将SelectOperator[S1]的输出列S1_col1的类型转换成字符串,节点108的表达式为ChildOperator.S1_col2,该表达式可以表示节点108使用SelectOperator[S1]的输出列S1_col2,节点109的表达式为ChildOperator.S1_col3,该表达式可以表示节点109使用SelectOperator[S1]的输出列S1_col3。SelectOperator[S2]的输出列包括S2_col0、S2_col1、S2_col2和S2_col3,节点106的输出列即为S2_col0,节点107的输出列即为S2_col1,节点108的输出列即为S2_col2,节点109的输出列即为S2_col3。
需要说明的是,图1B和图1C所示仅为表达式树的示例,在实际应用中,表达式树还可以是其他形式,不予限制。
下面介绍本公开实施例示出的数据血缘生成方法的实施环境。
图2是根据一示例性实施例示出的一种实施环境的架构图,下述数据血缘生成方法可以应用于该实施环境中。如图2所示,该实施环境包括至少一个数据血缘生成装置201。
图2中,该数据血缘生成装置201可以是具备数据处理能力的装置,可以用于执行下述数据血缘生成方法。该数据血缘生成装置201可以是笔记本电脑、个人计算机(personal computer,PC)或服务器等。
在一些实施例中,图2所示的实施环境还可以包括用户设备202。用户设备202可以是便携式计算机(如手机)、笔记本电脑、PC或平板电脑等。用户设备202可以向数据血缘生成装置201发送结构化查询语言(structured query language,SQL),以便数据血缘生成装置201在接收到SQL后,执行下述数据血缘生成方法。
在一些实施例中,用户设备202还可以接收来自数据血缘生成装置201的数据血缘信息,该数据血缘信息包括多个算子中根算子的输出列与源输入列之间的映射关系。
应注意,图2所示的实施环境仅用于举例,并非用于限制本公开的技术方案。本领域的技术人员应当明白,在具体实现过程中,该实施环境还可以包括其他装置,同时也可根据具体需要来配置数据血缘生成装置或用户设备的数量。
下面以图3为例,结合图1A、图1B、图1C和图2对本公开实施例示出的数据血缘生成方法进行具体阐述。
图3是根据一示例性实施例示出的一种数据血缘生成方法的流程图,该数据血缘生成方法可以应用于图2所示的数据血缘生成装置201中。如图3所示,该数据血缘生成方法可以包括以下步骤。
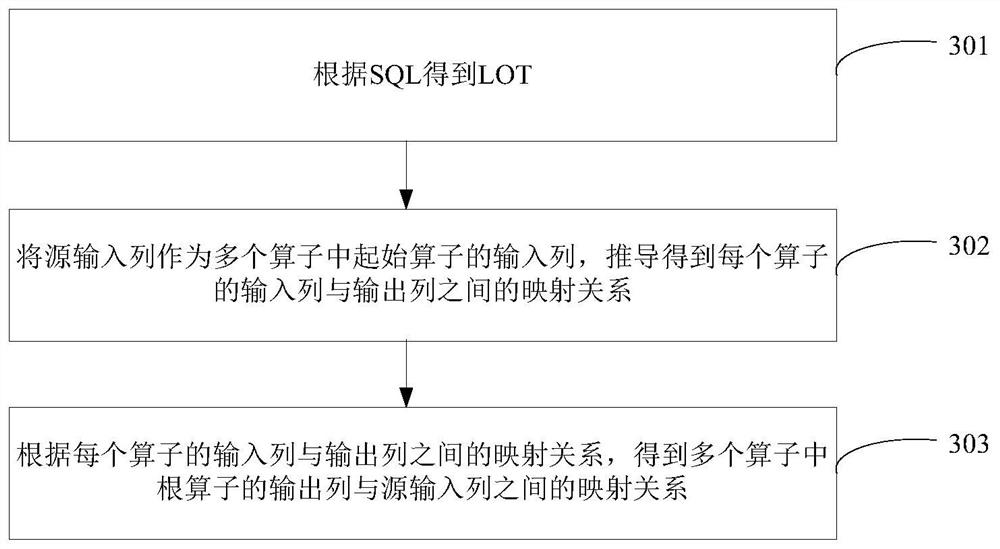
步骤301:根据SQL得到LOT。
其中,SQL可以用于指示源输入列以及多个处理操作。源输入列可以是元信息中的数据,源输入列还可以描述为源输入字段。元信息可以提供数据处理过程中的数据。多个处理操作可以用于对源输入列或者源输入列的处理结果进行处理,如:多个处理操作可以为查询或数据加工等操作。
可选的,本公开实施例中,SQL可以用于指示一组源输入列,一组源输入列包括一个或者多个输入列,一组源输入列可以包括在源输入表中。当一组源输入列可以包括在源输入表中时,可替换的,SQL可以指示该组源输入列所处的源输入表。
除包括源输入列外,SQL还可以用于指示源输入列的类型,源输入表中还可以包括源输入列的类型。需要说明的是,源输入列可以包括在同一个源输入表中,也可以包括在不同源输入表中,不予限制。
可选的,源输入列的类型包括复合字段类型(例如,结构体(struct)类型、映射(map)类型或列表(list)类型等)或非复合字段类型(例如,字符串(string)等)。其中,复合字段类型是指源输入列包括一个或多个亚字段,非复合字段是指源输入列不包括亚字段。亚字段是SQL中,粒度小于列(或字段)的单元。本公开下述实施例是以复合字段类型为struct为例,介绍数据血缘生成方法的,当复合字段类型为其他类型时,数据血缘生成方法的具体过程可以参考本公开下述实施例中,复合字段类型为struct时的描述,不予赘述。
示例性的,可以由用户通过数据血缘生成装置的人机交互界面将SQL输入到数据血缘生成装置;或者,数据血缘生成装置可以通过数据血缘生成装置与用户设备间的通信链路,接收来自用户设备的SQL。例如,可以接收来自图2所示用户设备202的SQL。
例如,SQL可以如下所示:
其中,SQL中的struct_field_demo_src_table为源输入表,demo_dest_table为目标输出表,where id>100表示选择表的标识大于100的表作为源输入表,select…from表示从struct_field_demo_src_table中选择user_id、user_info.name、user_info.workinfo.adds、user_info.workinfo.field,insert overwrite表示将选择出的user_id、user_info.name、user_info.workinfo.adds、user_info.workinfo.field插入并覆盖目标输出表中的user_id、work_name、work_adds、work_field。
如表1所示,为源输入表(struct_field_demo_src_table)的表结构。表1中,源输入表包括3个源输入列,该3个源输入列分别为表的标识(id)、用户标识(user_id)和用户信息(user_info)。id的类型为bigint,user_id的类型为string,user_info的类型为struct。其中,user_info包括多个亚字段,该多个亚字段分别为姓名(name)、年龄(age)、地址(addr)和工作信息(workinfo),name的类型为string,age的类型为bigint,addr的类型为string,workinfo的类型为struct。其中,workinfo包括多个亚字段,该多个亚字段分别为公司(corp)、领域(field)、经理(owner)和附加信息(adds),corp、field、owner和adds的类型都是string。
表1
目标输出表(demo_dest_table)的表结构可以如表2所示。表2中,目标输出表包括4个目标输出列,该四个目标输出列分别为用户标识(user_id)、用户姓名(user_name)、工作附加信息(work_adds)和工作领域(work_field),user_id、user_name、work_adds和work_field的类型都为string。
表2
上述SQL指示的处理操作是1、扫描源输入表;2、过滤出源输入表中,标识大于100的源输入表;3、选择标识大于100的源输入表中的user_id、user_info.name、user_info.workinfo.adds、user_info.workinfo.field;4、用选择出的user_id、user_info.name、user_info.workinfo.adds、user_info.workinfo.field插入并覆盖目标输出表中的user_id、work_name、work_adds、work_field。
示例性的,可以将SQL进行解析得到LOT。例如,采用现有的SQL编译器,如:Hive编译器(Hive Parser)或Calcite等,对SQL进行解析得到LOT。又例如,可以自行开发SQL编译器,对SQL进行词法分析、语法分析和元数据(meta)关联,进而得到LOT。
其中,LOT可以包括与SQL指示的多个处理操作对应的多个算子。一个处理操作可以对应一个或多个算子。例如,上述SQL指示的处理操作1可以对应图1A中的TableScanOperator,上述SQL指示的处理操作2可以对应图1A中的FilterOperator,上述SQL指示的处理操作3可以对应图1A中的SelectOperator[S1]和SelectOperator[S2],上述SQL指示的处理操作4可以对应图1A中的FileSinkOperator。LOT的具体介绍可以参考上述图1A、图1B和图1C中对应的介绍,不予赘述。
可选的,该多个算子包括以下算子中的一个或多个:文件输出算子(FileSinkOperator)、表输出算子(TableSinkOperator)、过滤算子(FilterOperator)、向前算子(ForwardOperator)、分组算子(GroupByOperator)、连接算子(JoinOperator)、侧视向前(传导)算子(LateralViewForwardOperator)、侧视连接算子(LateralViewJoinOperator)、极限算子(LimitOperator)、分区表函数算子(PartitionTableFunctionOperator)、脚本算子(ScriptOperator)、选择算子(SelectOperator)、表扫描算子(TableScanOperator)、表函数算子(UDTFOperator)或合并算子(UnionOperator)。
步骤302:将源输入列作为多个算子中起始算子的输入列,推导得到每个算子的输入列与输出列之间的映射关系。
其中,起始算子也可以描述为叶子算子。例如,图1A中的TableScanOperator可以称为起始算子,也可以称为叶子算子。
其中,算子的输入列可以是一组输入列,一组输入列可以包括一个或多个输入列。算子的输出列可以是一组输出列,一组输出列可以包括一个或多个输出列,例如,图1A中的FilterOperator的输出列包括两个输出列,分别是F_col0和F_col1。该一组输入列和该一组输出列存在对应关系。算子的输入列或输出列中的每一列可以包括一个或多个亚字段。例如,表1所示的源输入列包括3个输入列,分别为id、user_id和user_info,其中,user_info包括多个亚字段,该多个亚字段分别为name、age、addr和workinfo。
可选的,对于多个算子中具有表达式树的第一算子(例如,图1A中的SelectOperator[S1]或SelectOperator[S2]),该第一算子的输入列与输出列之间的映射关系包括该第一算子的输入列包括的亚字段与该第一算子的输出列之间的映射关系。
其中,该表达式树可以包括至少一条路径,该路径可以包括至少一个节点。该路径与第一算子的具有映射关系的输入列与输出列对应,该至少一个节点串行连接。该至少一个节点可以包括相关节点和/或非相关节点。
其中,相关节点和/或非相关节点的输入列可以包括一个或多个亚字段。相关节点的表达式可以使用该相关节点的输入列包括的亚字段执行相应操作。非相关节点的表达式不使用该非相关节点的输入列包括的亚字段执行相应操作。
示例性的,以图1B所示的表达式树为例,图1B所示的表达式树包括4条路径,第一条路径包括节点101,第二条路径包括节点102,第三条路径包括节点103和节点104,第四条路径包括节点103和节点105。其中,第一条路径的输入列为F_col0,第一条路径的输出列为S1_col0;第二条路径的输入列为F_col1,第二条路径的输出列为S1_col1;第三条路径的输入列为F_col1,第三条路径的输出列为S1_col2;第四条路径的输入列为F_col1,第四条路径的输出列为S1_col3。其中,节点101为非相关节点,节点102-节点105为相关节点。
示例性的,对于将源输入列作为多个算子中起始算子的输入列,推导得到第一算子的输入列与输出列之间的映射关系的具体过程,可参考下述图4所示方法中的介绍。
可选的,对于多个算子中不具有表达式树的第二算子(例如,图1A中的TableScanOperator、FilterOperator或FileSinkOperator),该第二算子的输出列依赖于该第二算子的输入列。例如,若第二算子的一组输入列包括一个输入列,则第二算子的一组输出列包括一个输出列,且该一个输出列依赖于该一个输入列。若第二算子的一组输入列包括多个输入列,则第二算子的一组输出列包括一个或多个输出列,且该一个或多个输出列依赖于该多个输入列中的一个输入列或多个输入列。
示例性的,以第二算子为TableScanOperator为例,第二算子的输入列为表1所示的源输入列,第二算子的输出列为TS_col0、TS_col1和TS_col2。第二算子的输出列与第二算子的输入列之间的映射关系可以如表3所示。表3中,TS_col0依赖于源输入列中的user_id,TS_col1依赖于源输入列中的user_info,TS_col2依赖于源输入列中的id。
表3
示例性的,以第二算子为FilterOperator为例,第二算子的输入列为TableScanOperator的输出列,第二算子的输出列为F_col0和F_col1。第二算子的输出列与第二算子的输入列之间的映射关系可以如表4所示。表4中,F_col0依赖于TableScanOperator的输出列中的TS_col0,F_col1依赖于TableScanOperator的输出列中的TS_col1。
表4
示例性的,以第二算子为FileSinkOperator为例,第二算子的输入列为SelectOperator[S2]的输出列,第二算子的输出列为FS_col0、FS_col1、FS_col2和FS_col3。第二算子的输出列与第二算子的输入列之间的映射关系可以如表5所示。表5中,FS_col0依赖于SelectOperator[S2]的输出列中的S2_col0,FS_col1依赖于SelectOperator[S2]的输出列中的S2_col1,FS_col2依赖于SelectOperator[S2]的输出列中的S2_col2,FS_col3依赖于SelectOperator[S2]的输出列中的S2_col3。
表5
步骤303:根据每个算子的输入列与输出列之间的映射关系,得到多个算子中根算子的输出列与源输入列之间的映射关系。
可选的,根据每个算子的输入列与输出列之间的映射关系,得到多个算子中根算子的输出列与源输入列之间的映射关系,包括:对多个算子中的第i+1个算子,根据第i+1个算子的输入列与输出列之间的映射关系以及第i个算子的输出列与源输入列之间的映射关系,得到第i+1个算子的输出列与源输入列之间的映射关系;其中,i为大于或者等于1的整数;当第i+1个算子为根算子的子算子时,根据第i+1个算子的输出列与源输入列之间的映射关系、以及根算子的输入列与输出列之间的映射关系,得到根算子的输出列与源输入列之间的映射关系。这一过程的具体描述可以参考下述图5所示方法中的介绍。
在一些实施例中,步骤303后,数据血缘生成装置还可以将数据血缘通过数据血缘生成装置的输出设备呈现给用户,以使得用户了解目标输出表与源输入表的映射关系。
在一些实施例中,步骤303后,数据血缘生成装置还可以为用户提供血缘关系查询服务、历史版本查询服务、任务粒度的血缘关系查询、输入/输出表粒度的血缘关系查询或血缘关系树查询服务。需要说明的是,上述血缘关系的粒度可以是亚字段级的。
在一些实施例中,在做数据分析时,可以将多个算子中根算子的输出列与源输入列之间的映射关系与附加信息结合后,提供数据回溯或数据分析等服务。
其中,附加信息可以是源输入列的相关信息,例如,附加信息可以包括以下信息中的一种或多种:源输入列(或源输入列中亚字段)的创建时间、源输入列(或源输入列中亚字段)的被引用次数、创建源输入列(或源输入列中亚字段)的对象或源输入列(或源输入列中亚字段)的安全等级等。
示例性的,以附加信息包括源输入列中亚字段的被引用次数和源输入列中亚字段的创建时间,源输入列如表1所示为例,若在进行数据回溯的过程中,发现根算子的输出列来源于源输入列中的struct_field_demo_src_table.user_info.workinfo.adds,但struct_field_demo_src_table.user_info.workinfo.adds被引用次数为1,创建时间为2018.9.1,因为struct_field_demo_src_table.user_info.workinfo.adds在创建的一年多的时间中被引用了一次,所以可以将struct_field_demo_src_table.user_info.workinfo.adds从源输入列中删除,从而可以减轻维护后台数据的负担。
基于图3所示方法,可以根据SQL得到LOT,将源输入列作为多个算子中起始算子的输入列,推导得到每个算子的输入列与输出列之间的映射关系,并根据每个算子的输入列与输出列之间的映射关系,得到多个算子中根算子的输出列与源输入列之间的映射关系,因为对于多个算子中包括表达式数的第一算子,第一算子的输入列与输出列之间的映射关系包括第一算子的输入列包括的亚字段与第一算子的输出列之间的映射关系,也就是说,第一算子的输入列与第一算子的输出列之间的映射关系是亚字段级的映射关系,所以根据每个算子的输入列和输出列之间的映射关系,得到的多个算子中根算子的输出列与源输入列之间的映射关系也是亚字段级的映射关系,提高了数据血缘的精细度。采用本公开实施例示出的数据血缘生成方法得到的数据血缘进行数据分析时,可以回溯或分析到输出数据中数据来源于输入数据中的某一个或某几个字段/列中的某个亚字段,可以得到更精确的分析结果,另外,用户还可以根据该更精确的分析结果对输入数据进行操作(例如,删除输入数据中的某一列中的某个亚字段)。
进一步可选的,若多个算子中包括具有表达式树的第一算子,如图4所示,步骤302用步骤3021-步骤3023代替。
步骤3021:建立亚字段关系映射表。
一种可能的实现方式,该亚字段关系映射表可以包括该至少一个节点中每个节点的标识、该节点所处路径的输入列以及该节点的表达式间的对应关系。
另一种可能的实现方式,亚字段关系映射表可以包括该至少一个节点中每个节点的标识、该节点所处路径的输入列、该节点的表达式以及该节点的输出列的类型间的对应关系。
需要说明的是,当至少一个节点的输入列的类型、输出列的类型相同时,亚字段关系映射表可以包括该至少一个节点中每个节点的标识、该节点所处路径的输入列以及该节点的表达式间的对应关系。当至少一个节点的输入列的类型、输出列的类型不相同时,亚字段关系映射表可以包括该至少一个节点中每个节点的标识、该节点所处路径的输入列、该节点的表达式以及该节点的输出列的类型间的对应关系。
可选的,建立亚字段关系映射表,包括:根据表达式树中的节点的表达式建立亚字段关系映射表。例如,对于图1B中的节点101,节点101的表达式为ChildOperator.F_col0,因此,节点101所处路径的输入列为F_col0,对于图1B中的节点102,节点102的表达式为ExprNodeFieldRef(ChildOperator.F_col1,‘name’),因此,节点102所处路径的输入列为F_col1。
示例性的,以表达式如图1B所示,亚字段关系映射表包括该至少一个节点中每个节点的标识、该节点所处路径的输入列以及该节点的表达式间的对应关系为例,亚字段关系映射表可以如表6所示。表6中,节点101所处路径的输入列为F_col0,节点101的节点表达式为ChildOperator.F_col0;节点102所处路径的输入列为F_col1,节点102的节点表达式为ExprNodeFieldRef(ChildOperator.F_col1,‘name’);节点103所处路径的输入列为F_col1,节点103的节点表达式为ExprNodeFieldRef(ChildOperator.F_col1,‘workinfo’);节点104所处路径的输入列为F_col1,节点104的节点表达式为ExprNodeFieldRef(ChildExprNode,‘adds’);节点105所处路径的输入列为F_col1,节点105的节点表达式为ExprNodeFieldRef(ChildExprNode,‘field’)。
表6
步骤3022:根据第一节点所处路径的输入列、第一节点的表达式以及第一节点所处路径中,第一节点的下游节点的表达式,确定第一节点的输出列。
其中,第一节点可以是该至少一个节点中的任一节点。
其中,第一节点所处路径中,第一节点的下游节点可以包括第一节点所处路径的叶子节点,以及第一节点所处路径的叶子节点与第一节点之间的节点。例如,若第一节点为图1B中的节点104,则第一节点的下游节点包括节点103。
上文已经介绍该至少一个节点可以包括非相关节点和/或相关节点,步骤3022对不同类型的节点的处理方式不同。
可选的,若第一节点为相关节点,步骤3022包括以下步骤:
步骤1a:根据第一节点所处路径的输入列以及第一节点所处路径中,第一节点的下游节点的表达式,确定第一节点的输入列。
可以从第一节点所在路径的叶子节点开始,遍历第一节点所处路径中,第一节点的每一个下游节点,根据下游节点的输入列与该下游节点的表达式,得到该下游节点的输出列,将第一节点的子节点的输出列确定为第一节点的输入列。
需要说明的是,若第一节点为第一节点所处路径的叶子节点,可以将第一节点所处路径的输入列确定为第一节点的输入列。
下面以图1B所示的表达式树为例介绍步骤1a。
上文已经说明节点101为非相关节点,节点102-节点105为相关节点。对于节点102,该节点为第二条路径上的叶子节点,根据表5得到第二条路径的输入列为F_col1,因此,节点102的输入列为F_col1。对于节点103,该节点为第三条路径上的叶子节点,根据表5得到第三条路径的输入列为F_col1,因此,节点103的输入列为F_col1。对于节点104,节点104的下游节点包括节点103,可以根据节点103的输入列以及节点103的表达式得到节点103的输出列为F_col1.workinfo,因此,节点104的输入列为F_col1.workinfo。对于节点105,节点105的下游节点包括节点103,可以根据节点103的输入列以及节点103的表达式得到节点103的输出列为F_col1.workinfo,因此,节点105的输入列为F_col1.workinfo。经过步骤1a,第一节点的输入列可以如表7所示。节点101为非相关节点,非相关节点的输入列的确定过程在下述步骤1b中介绍。
表7
步骤1b:根据第一节点的输入列以及第一节点的表达式,得到第一节点的输出列。
可选的,根据第一节点的输入列以及第一节点的表达式,得到第一节点的输出列,包括:根据第一节点的表达式,得到第一节点的输入列中的亚字段;将第一节点的输入列和第一节点的输入列中的亚字段结合,得到第一节点的输出列。
下面以图1B所示的表达式树为例介绍步骤1b。
图1B所示的表达式树中的相关节点有节点102-节点105。对于节点102,该节点的输入列为F_col1,该节点的表达式为ExprNodeFieldRef(ChildOperator.F_col1,‘name’),因此,该节点的输出列为F_col1.name。对于节点103,该节点的输入列为F_col1,该节点的表达式为ExprNodeFieldRef(ChildOperator.F_col1,‘workinfo’),因此,该节点的输出列为F_col1.workinfo。对于节点104,该节点的输入列为F_col1.workinfo,该节点的表达式为ExprNodeFieldRef(ChildExprNode,‘adds’),因此,该节点的输出列为F_col1.workinfo.adds。对于节点105,该节点的输入列为F_col1.workinfo,该节点的表达式为ExprNodeFieldRef(ChildExprNode,‘field’),因此,该节点的输出列为F_col1.workinfo.field。经过步骤1b,第一节点的输出列可以如表8所示。节点101为非相关节点,非相关节点的输出列的确定过程在下述步骤2b中介绍。
表8
基于上述步骤1a和步骤1b,可以根据第一节点所处路径的输入列以及第一节点所处路径中,第一节点的下游节点的表达式,确定第一节点的输入列,并根据第一节点的输入列以及第一节点的表达式,得到第一节点的输出列,从而可以得到第一算子中,每个相关节点的输出列,以便后续推导第一算子的输入列与输出列之间的映射关系。
可选的,若第一节点为非相关节点,步骤3022包括以下步骤:
步骤2a:根据第一节点所处路径的输入列以及第一节点所处路径中,第一节点的下游节点的表达式,确定第一节点的输入列。
步骤2a的具体过程可以参考步骤1a中的介绍,不予赘述。
下面以图1B所示的表达式树为例介绍步骤2a。
图1B所示的表达式树中,节点101为非相关节点。对于节点101,该节点的为第二条路径上的叶子节点,根据表5得到第二条路径的输入列为F_col0,因此,节点102的输入列为F_col0。经过步骤2a,第一节点的输入列可以如表9所示。
表9
步骤2b:将第一节点的输入列确定为第一节点的输出列。
下面以图1B所示的表达式树为例介绍步骤2b。
图1B所示的表达式树中,节点101为非相关节点。对于节点101,该节点的输入列为F_col0,因此该节点的输出列为F_col0。经过步骤2b,第一节点的输出列可以如表10所示。
表10
基于上述步骤1a和步骤1b,可以根据第一节点所处路径的输入列以及第一节点所处路径中,第一节点的下游节点的表达式,确定第一节点的输入列,并将第一节点的输入列确定为第一节点的输出列,从而可以得到第一算子中,每个非相关节点的输出列,以便后续推导第一算子的输入列与输出列之间的映射关系。
需要说明的是,亚字段关系映射表包括该至少一个节点中每个节点的标识、该节点所处路径的输入列、该节点的表达式以及该节点的输出列的类型间的对应关系的介绍,可以参考上述亚字段关系映射表包括该至少一个节点中每个节点的标识、该节点所处路径的输入列以及该节点的表达式的对应关系的情况,不予赘述。
步骤3023:若第一节点为第一节点所处路径的根节点,将第一节点的输出列与第一算子的输出列之间的映射关系,确定为第一算子的输入列与输出列之间的映射关系。
示例性的,以图1B所示的表达式树为例,SelectOperator[S1]的输入列与输出列的映射关系如表11所示。表11中,S1_col0依赖于F_col0,S1_col1依赖于F_col1中的name,S1_col2依赖于F_col1中的workinfo中的adds,S1_col3依赖于F_col1中的workinfo中的field。
表11
类似的,经过步骤3021-步骤3023,可以得到SelectOperator[S2]的输入列与输出列的映射关系,该映射关系可以如表12所示。表12中,S2_col0依赖于S1_col0,S2_col1依赖于S1_col1,S2_col2依赖于S1_col2,S2_col3依赖于S1_col3。
表12
基于图4所示的方法,对于多个算子中具有表达式树的第一算子,可以建立亚字段关系映射表,并根据第一节点所处路径的输入列、第一节点的表达式以及第一节点所处路径中,第一节点的下游节点的表达式,确定第一节点的输出列,当第一节点为第一节点所处路径的根节点时,将第一节点的输出列与第一算子的输出列之间的映射关系,确定为第一算子的输入列与输出列之间的映射关系,从而可以根据第一算子中,每条路径的输入列,该路径中的叶子节点的表达式得到该叶子节点的输出列,并根据该叶子节点的输出列,该叶子节点的父节点的表达式得到该叶子节点的父节点的输出列,以此类推,得到每条路径中的根节点的输出列,并将每条路径中根节点的输出列与第一算子的输出列之间的映射关系,确定为第一算子的输入列与输出列之间的映射关系,以便后续根据根据每个算子的输入列与输出列之间的映射关系,得到多个算子中根算子的输出列与源输入列之间的映射关系。
进一步可选的,如图5所示,步骤303用步骤3031和步骤3032代替。
步骤3031:对多个算子中的第i+1个算子,根据第i+1个算子的输入列与输出列之间的映射关系以及第i个算子的输出列与源输入列之间的映射关系,得到第i+1个算子的输出列与源输入列之间的映射关系。
其中,i为大于或者等于1的整数。该第i+1个算子是该第i个算子的父算子。
示例性的,以第i+1个算子是FilterOperator,第i个算子是TableScanOperator为例,根据表3和表4,可以得到FilterOperator的输出列与源输入列之间的映射关系,该映射关系可以如表13所示。表13中,F_col0依赖于struct_field_demo_src_table.user_id,F_col1依赖于struct_field_demo_src_table.user_info。
表13
重复执行步骤3031,直至第i+1个算子为根算子的子算子。
根据表11和表13,可以得到SelectOperator[S1]的输出列与源输入列之间的映射关系,该映射关系可以如表14所示。表14中,S1_col0依赖于struct_field_demo_src_table.user_id,S1_col1依赖于struct_field_demo_src_table.user_info.name,S1_col2依赖于struct_field_demo_src_table.user_info.workinfo.adds,S1_col3依赖于struct_field_demo_src_table.user_info.workinfo.field。
表14
同理,根据表12和表14,可以得到SelectOperator[S2]的输出列与源输入列之间的映射关系,该映射关系可以如表15所示。表15中,S2_col0依赖于struct_field_demo_src_table.user_id,S2_col1依赖于struct_field_demo_src_table.user_info.name,S2_col2依赖于struct_field_demo_src_table.user_info.workinfo.adds,S2_col3依赖于struct_field_demo_src_table.user_info.workinfo.field。
表15
步骤3032:当第i+1个算子为根算子的子算子时,根据第i+1个算子的输出列与源输入列之间的映射关系、以及根算子的输入列与输出列之间的映射关系,得到根算子的输出列与源输入列之间的映射关系。
示例性的,第i+1个算子为SelectOperator[S2],根算子为FileSinkOperator为例,根据表5和表15,可以得到FileSinkOperator的输出列与源输入列之间的映射关系,该映射关系可以如表16所示。表16中,FS_col0依赖于struct_field_demo_src_table.user_id,FS_col1依赖于struct_field_demo_src_table.user_info.name,FS_col2依赖于struct_field_demo_src_table.user_info.workinfo.adds,FS_col3依赖于struct_field_demo_src_table.user_info.workinfo.field。
表16
需要说明的是,上述数据血缘生成方法的过程是推导得到每个算子的输入列与输出列之间的映射关系,根据每个算子的输入列与输出列之间的映射关系,得到多个算子中根算子的输出列与所述源输入列之间的映射关系,除了上述方法,还可以在推导每个算子的输入列与输出列之间的映射关系的过程中,引入源输入列,则可以得到每个算子的输出列与源输入列之间的映射关系,推导结束时,可以输出根算子的输出列与源输入列之间的映射关系,即得到该数据血缘。
基于图5所示方法,对多个算子中的第i+1个算子,可以根据第i+1个算子的输入列与输出列之间的映射关系以及第i个算子的输出列与源输入列之间的映射关系,得到第i+1个算子的输出列与源输入列之间的映射关系,当第i+1个算子为根算子的子算子时,可以根据第i+1个算子的输出列与源输入列之间的映射关系、以及根算子的输入列与输出列之间的映射关系,得到根算子的输出列与源输入列之间的映射关系,从而可以根据LOT中,叶子算子的父算子的输入列与输出列之间的映射关系,以及叶子算子的输出列与源输入列之间的映射关系,得到叶子算子的父算子的输出列与源输入列之间的映射关系,并以此类推,得到根算子的输出列与源输入列之间的亚字段级的映射关系,以便后续根据根算子的输出列与源输入列之间的映射关系进行亚字段级的数据分析,得到更精确的分析结果。
图6是根据一示例性实施例示出的一种数据血缘生成装置60框图。参照图6,该装置包括处理模块601和推导模块602。
该处理模块601被配置为根据结构化查询语言SQL,得到逻辑执行计划树LOT,其中,所述SQL用于指示源输入列以及多个处理操作;所述LOT包括与所述多个处理操作对应的多个算子,具有串行关系的两个算子通过有向边连接,每个算子包括所述算子的输出列,每个算子具有表达式树或者不具有表达式树。
推导模块602被配置为将所述源输入列作为所述多个算子中起始算子的输入列,推导得到每个算子的输入列与输出列之间的映射关系;其中,对于所述多个算子中具有表达式树的第一算子,所述第一算子的输入列与输出列之间的映射关系包括所述第一算子的输入列包括的亚字段与所述第一算子的输出列之间的映射关系。
处理模块601还被配置为根据所述每个算子的输入列与输出列之间的映射关系,得到所述多个算子中根算子的输出列与所述源输入列之间的映射关系。
可选的,所述表达式树包括至少一条路径,所述路径包括至少一个节点,所述路径与所述第一算子的具有映射关系的输入列与输出列对应,所述至少一个节点串行连接;推导模块602,具体被配置为建立亚字段关系映射表;其中,所述亚字段关系映射表包括所述至少一个节点中每个节点的标识、所述节点所处路径的输入列以及所述节点的表达式间的对应关系;推导模块602,还具体被配置为对于第一节点,所述第一节点为所述至少一个节点中的任一节点,根据所述第一节点所处路径的输入列、所述第一节点的表达式以及所述第一节点所处路径中,所述第一节点的下游节点的表达式,确定所述第一节点的输出列;推导模块602,还具体被配置为若所述第一节点为所述第一节点所处路径的根节点,将所述第一节点的输出列与所述第一算子的输出列之间的映射关系,确定为所述第一算子的输入列与输出列之间的映射关系。
可选的,所述至少一个节点包括相关节点,所述相关节点的输入列包括一个或多个亚字段,所述相关节点的表达式使用所述相关节点的输入列包括的亚字段执行相应操作;若所述第一节点为相关节点,推导模块602,还具体被配置为根据所述第一节点所处路径的输入列以及所述第一节点所处路径中,所述第一节点的下游节点的表达式,确定所述第一节点的输入列;推导模块602,还具体被配置为根据所述第一节点的输入列以及所述第一节点的表达式,得到所述第一节点的输出列。
可选的,所述至少一个节点包括非相关节点,所述非相关节点的输入列包括一个或多个亚字段,所述非相关节点的表达式不使用所述非相关节点的输入列包括的亚字段执行相应操作;若所述第一节点为非相关节点,推导模块602,还具体被配置为根据所述第一节点所处路径的输入列以及所述第一节点所处路径中,所述第一节点的下游节点的表达式,确定所述第一节点的输入列;推导模块602,还具体被配置为将所述第一节点的输入列确定为所述第一节点的输出列。
可选的,处理模块601,具体被配置为对所述多个算子中的第i+1个算子,根据所述第i+1个算子的输入列与输出列之间的映射关系以及所述第i个算子的输出列与所述源输入列之间的映射关系,得到所述第i+1个算子的输出列与所述源输入列之间的映射关系;其中,i为大于或者等于1的整数;处理模块601,还具体被配置为当所述第i+1个算子为所述根算子的子算子时,根据所述第i+1个算子的输出列与所述源输入列之间的映射关系、以及所述根算子的输入列与输出列之间的映射关系,得到所述根算子的输出列与所述源输入列之间的映射关系。
关于上述实施例中的装置,其中各个模块执行操作的具体方式已经在有关该方法的实施例中进行了详细描述,此处将不做详细阐述说明。
图7是根据一示例性实施例示出的一种数据血缘生成装置70的框图。该数据血缘生成装置70可以包括至少一个处理器701,通信线路702以及存储器703。
处理器701可以是一个通用中央处理器(central processing unit,CPU),微处理器,特定应用集成电路(application-specific integrated circuit,ASIC),或一个或多个用于控制本公开方案程序执行的集成电路。
通信线路702可包括一通路,在上述组件之间传送信息,例如总线。
存储器703可以是只读存储器(read-only memory,ROM)或可存储静态信息和指令的其他类型的静态存储设备,随机存取存储器(random access memory,RAM)或者可存储信息和指令的其他类型的动态存储设备,也可以是电可擦可编程只读存储器(electricallyerasable programmable read-only memory,EEPROM)、只读光盘(compact disc read-only memory,CD-ROM)或其他光盘存储、光碟存储(包括压缩光碟、激光碟、光碟、数字通用光碟、蓝光光碟等)、磁盘存储介质或者其他磁存储设备、或者能够用于携带或存储具有指令或数据结构形式的期望的程序代码并能够由计算机存取的任何其他介质,但不限于此。存储器可以是独立存在,通过通信线路702与处理器相连接。存储器也可以和处理器集成在一起。本公开实施例提供的存储器通常可以具有非易失性。其中,存储器703用于存储执行本公开方案所涉及的计算机执行指令,并由处理器701来控制执行。处理器701用于执行存储器703中存储的计算机执行指令,从而实现本公开实施例提供的方法。
可选的,本公开实施例中的计算机执行指令也可以称之为应用程序代码,本公开实施例对此不作具体限定。
在具体实现中,作为一种实施例,处理器701可以包括一个或多个CPU,例如图7中的CPU0和CPU1。
在具体实现中,作为一种实施例,数据血缘生成装置70可以包括多个处理器,例如图7中的处理器701和处理器707。这些处理器中的每一个可以是一个单核(single-CPU)处理器,也可以是一个多核(multi-CPU)处理器。这里的处理器可以指一个或多个设备、电路、和/或用于处理数据(例如计算机程序指令)的处理核。
在具体实现中,作为一种实施例,数据血缘生成装置70还可以包括通信接口204。通信接口204,使用任何收发器一类的装置,用于与其他设备或通信网络通信,如以太网接口,无线接入网接口(radio access network,RAN),无线局域网接口(wireless localarea networks,WLAN)等。
在具体实现中,作为一种实施例,数据血缘生成装置70还可以包括输出设备705和输入设备706。输出设备705和处理器701通信,可以以多种方式来显示信息。例如,输出设备705可以是液晶显示器(liquid crystal display,LCD),发光二级管(light emittingdiode,LED)显示设备,阴极射线管(cathode ray tube,CRT)显示设备,或投影仪(projector)等。输入设备706和处理器701通信,可以以多种方式接收用户的输入。例如,输入设备706可以是鼠标、键盘、触摸屏设备或传感设备等。
在具体实现中,数据血缘生成装置70可以是台式机、便携式电脑、网络服务器、掌上电脑(personal digital assistant,PDA)、移动手机、平板电脑、无线终端设备、嵌入式设备或有图7中类似结构的设备。本公开实施例不限定数据血缘生成装置70的类型。
在一些实施例中,图7中的处理器701可以通过调用存储器703中存储的计算机执行指令,使得数据血缘生成装置70执行上述方法实施例中的数据血缘生成方法。
示例性的,图6中的处理模块601和推导模块602的功能/实现过程可以通过图7中的处理器701调用存储器703中存储的计算机执行指令来实现。
在示例性实施例中,还提供了一种包括指令的存储介质,例如包括指令的存储器703,上述指令可由数据血缘生成装置70的处理器701执行以完成上述方法。
在上述实施例中,可以全部或部分地通过软件、硬件、固件或者其任意组合来实现。当使用软件程序实现时,可以全部或部分地以计算机程序产品的形式来实现。该计算机程序产品包括一个或多个计算机指令。在计算机上加载和执行计算机程序指令时,全部或部分地产生按照本申请实施例的流程或功能。计算机可以是通用计算机、专用计算机、计算机网络、或者其他可编程装置。
本领域技术人员在考虑说明书及实践这里公开的发明后,将容易想到本公开的其它实施方案。本申请旨在涵盖本公开的任何变型、用途或者适应性变化,这些变型、用途或者适应性变化遵循本公开的一般性原理并包括本公开未公开的本技术领域中的公知常识或惯用技术手段。说明书和实施例仅被视为示例性的,本公开的真正范围和精神由下面的权利要求指出。
应当理解的是,本公开并不局限于上面已经描述并在附图中示出的精确结构,并且可以在不脱离其范围进行各种修改和改变。本公开的范围仅由所附的权利要求来限制。
- 数据血缘管理方法及装置、数据血缘解析方法及装置
- 数据仓库的血缘图生成方法、装置、设备及存储介质