一种高维免疫结合大数据和人工智能的泛疾病风险预测系统
文献发布时间:2023-06-19 11:11:32
技术领域
本发明涉及生物医学技术领域,具体涉及一种高维免疫结合大数据和人工智能的泛疾病风险预测系统。
背景技术
现代人由于生活工作节奏紧张,加上不良生活方式和习惯,导致亚健康人群的比例逐年增加,伴随其发生的一些慢性疾病的比例,如糖尿病,高血压,心脏病,慢阻肺,自身免疫疾病,肿瘤等也呈现出逐年高发的趋势,目前国内慢性疾病等发病人群已经接近3亿人,并且随着老龄化的加剧,该数字很可能会继续增加。
慢性疾病等的发生和发展是一个漫长的过程,以肿瘤为例,最初的阶段是分子癌变阶段,这个阶段由于遗传因素或者环境因素的相互作用,导致了DNA、RNA或者蛋白分子发生了突变。此阶段往往将持续8~10年,通过多次细胞分裂的过程,逐渐进入到细胞癌变阶段,少数细胞获得无限增殖的能力,大约经历3~5年后,如果肿瘤细胞占了上风,肿瘤细胞分裂增殖就会提速,发展成肿瘤组织,进入早癌阶段,在这个阶段,部分恶性度较高的肿瘤已具有侵袭性和转移性。早癌组织经过1~3年的生长,逐渐变大,产生占位,对周围组织和神经产生压迫,让患者出现不适症状,这时已进入癌症的中晚期,肿瘤细胞侵袭血管组织,并多发转移。对疾病如肿瘤进行早筛、早诊和风险管理,可以更大概率地发现早期癌症,预防关口前移,可以显著提高其五年生存率,降低死亡率。大量研究表明,早期肿瘤的长期生存率远高于中晚期肿瘤,很多肿瘤如果能够在早期发现并得到早期治疗,其治疗效果远比中晚期肿瘤的治疗效果要好。
研究表明,90%以上的疾病发生与免疫系统相关,如果能够更加精准的检测机体的免疫细胞,对免疫系统尤其是免疫细胞进行动态监测,并对免疫力进行量化评估,对于疾病的风险评估,早期筛查,用药指导,预后监测等具有极大的应用价值。
目前临床对于免疫细胞的检测,通常使用流式细胞技术,通过采用带有荧光标签的抗体来标记细胞,对细胞表面表达的特定的CD分子是否表达及表达水平进行评估,能够对个体免疫系统的免疫细胞组成进行分析,目前临床级别的流式细胞技术,由于不同的荧光光谱之间存在比较严重的光谱重叠现象,常用的CD分子数量为8~9个指标。
质谱流式细胞技术是目前国际最先进的单细胞分析技术之一,能够在单细胞水平,基于细胞表面和内部的蛋白表达情况,能够同时检测42个指标,实现对免疫细胞的表型和功能进行全面的分析,实现精细的细胞分型和生物学功能分析。相较于传统的荧光流式细胞技术,在标签系统和检测系统上进行了技术性的突破,采用金属同位素标签的抗体来标记细胞,随后通过飞行时间质谱来精确检测每个细胞上的金属标签含量,检测通道之间无相互干扰,极大地提高了检测的深度和广度,能够挖掘到与疾病发生、发展相关或与治疗结果相关的关键细分亚群。
目前,机器学习和人工智能已经被逐步应用于临床医学实践中,例如将机器学习和医学影像学结合,实现人工智能自动识别CT影像,在新冠肺炎的诊断中已经有实践应用,将机器学习和病理图像识别相结合,能够降低病理医生的负担,提高检测效率。而将机器学习和免疫检测数据相结合,能够发现免疫系统和各类疾病发生发展阶段存在的潜在关联,并通过大数据建立模型,能够建立经由免疫系统的新的指标评价体系。
发明内容
本发明的目的是提供一种高维免疫结合大数据和人工智能的泛疾病风险预测系统,以解决现有技术的不足。
本发明采用以下技术方案:
一种高维免疫结合大数据和人工智能的泛疾病风险预测系统,所述系统包括:
模型建立模块,用于根据疾病者的高维免疫检测数据和健康者的高维免疫检测数据,通过机器学习方法构建各疾病风险预测模型;
待测样本数据获取模块,用于获取待测样本数据;
分析预测模块,用于根据所述待测样本数据与所述疾病风险预测模型进行机器学习分析预测,获得疾病风险预测值。
进一步地,所述模型建立模块包括:
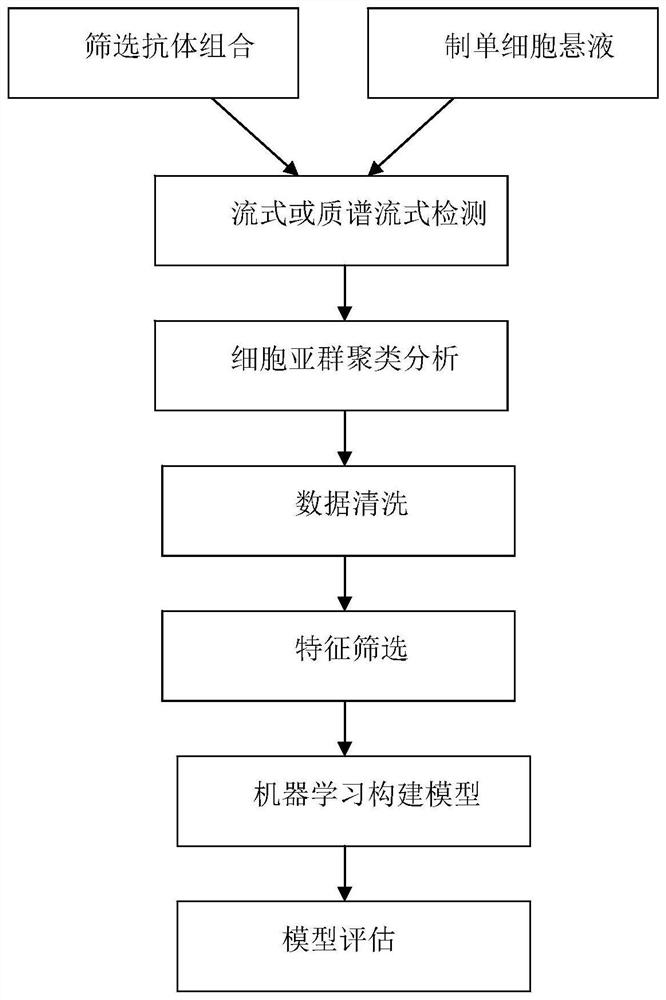
抗体组合筛选单元,用于从抗体库中筛选特定疾病对应的抗体组合,获得抗体组合;
单细胞悬液获取单元,用于从疾病者和健康者的血液或组织中分离单个核细胞,制得单细胞悬液;
高维免疫检测单元,用于将单细胞悬液和抗体组合,通过流式或质谱流式进行检测,获得流式或质谱流式检测数据;
细胞亚群分析单元,用于基于流式或质谱流式检测数据,对细胞亚群进行聚类分析,获得有效细胞亚群数据;
数据清洗单元,用于将有效细胞亚群数据归一化处理,剔除异常值的样本;
特征筛选单元,对清洗后的有效细胞亚群数据进行特征筛选,筛选出特异的亚群特征;
机器学习模型建立单元,将筛选出的特异的亚群特征作为特征值进行机器学习建立疾病风险预测模型,并寻找最优模型参数;
模型评估单元,用于对建立的疾病风险预测模型进行评估。
进一步地,抗体组合筛选单元筛选的抗体组合中各抗体分别被荧光素标记或者金属元素标记。
进一步地,细胞亚群分析单元基于流式或质谱流式检测数据,利用包括Flowjo软件或Cytobank软件或算法代码对细胞亚群进行聚类分析,获得有效细胞亚群数据。
进一步地,数据清洗单元对有效细胞亚群数据采用包括标准归一化处理或最大最小归一化处理,剔除异常值的样本。
进一步地,特征筛选单元采用包括Lasso、Ridge或ElasticNet中的一种或多种,对清洗后的有效细胞亚群数据进行多次迭代,筛选出特异的亚群特征。
进一步地,机器学习模型建立单元中机器学习包括Logistic回归、SVM、DecisionTree、Random Forest、GBDT、XGBoost、Adaboost、FNN、BP神经网络、CNN、RNN、ANN中的一种或多种。
进一步地,机器学习模型建立单元中采用网格搜索与交叉验证方法寻找最优模型参数。
进一步地,模型评估单元从准确率、灵敏性、特异性、混淆矩阵及ROC曲线多个方面对建立的疾病风险预测模型进行评估;其中,
准确率计算公式为:(TP+TN)/(TP+FN+FP+TN),
灵敏性计算公式为:TP/(TP+FN),
特异性计算公式为:TN/(FP+TN),
ROC曲线是根据特异性、灵敏性画出来的曲线图,曲线与x轴形成的面积称为AUC值,AUC值范围在0~1之间,AUC值越大,表示模型越好,如果小于0.5,表明模型不适用;
混淆矩阵的形式为:
TP表示实际标签为正,预测标签为正;FN表示实际标签为正,预测标签为负;FP表示实际标签为负,预测标签为正;TN为实际标签为负,预测标签为负。
进一步地,所述待测样本数据获取模块获取待测样本数据包括:
通过单细胞悬液获取单元获取待测样本单细胞悬液;
利用高维免疫检测单元将待测样本单细胞悬液和抗体组合筛选单元筛选出的抗体组合,通过流式或质谱流式进行检测,获得待测样本流式或质谱流式检测数据;
利用细胞亚群分析单元基于待测样本流式或质谱流式检测数据,对细胞亚群进行聚类分析,获得有效细胞亚群数据。
本发明的有益效果:
本发明利用高维免疫技术识别健康人和非健康人的免疫系统中免疫细胞的差异,结合大数据和人工智能,构建了高特异性和灵敏性的泛疾病风险预测系统,能够区分健康人和非健康人,或者区分疾病的不同状态,可以大大提高泛疾病早筛风险预测特别是肿瘤早筛风险预测的特异性和灵敏性,并且执行起来简单方便。
附图说明
图1为本发明高维免疫结合大数据和人工智能的泛疾病风险预测系统构建示意图。
具体实施方式
下面结合实施例和附图对本发明做更进一步地解释。下列实施例仅用于说明本发明,但并不用来限定本发明的实施范围。
一种高维免疫结合大数据和人工智能的泛疾病风险预测系统,所述系统包括:
模型建立模块,用于根据疾病者的高维免疫检测数据和健康者的高维免疫检测数据,通过机器学习方法构建各疾病风险预测模型;
待测样本数据获取模块,用于获取待测样本数据;
分析预测模块,用于根据所述待测样本数据与所述疾病风险预测模型进行机器学习分析预测,获得疾病风险预测值。
本发明所述疾病包括但不限于呼吸系统疾病、过敏性疾病、胃肠道性疾病、心血管疾病、衰老相关疾病、糖尿病、高血压、自身免疫性疾病、各类癌症包括但不限于肺癌、肝癌、胰腺癌、前列腺癌、肠癌、结直肠癌、胃癌、乳腺癌、卵巢癌、宫颈癌等。
具体地,所述模型建立模块包括:
抗体组合筛选单元,用于从抗体库中筛选特定疾病对应的抗体组合,获得抗体组合;抗体组合中各抗体分别被荧光素标记或者金属元素标记,以用于后续进行流式或质谱流式分析;
单细胞悬液获取单元,用于从疾病者和健康者的血液或组织中分离单个核细胞,制得单细胞悬液;
高维免疫检测单元,用于将单细胞悬液和抗体组合,通过流式或质谱流式进行检测,获得流式或质谱流式检测数据;
细胞亚群分析单元,用于基于流式或质谱流式检测数据,利用包括Flowjo软件或Cytobank软件或算法代码对细胞亚群进行聚类分析,但不限于此,获得有效细胞亚群数据;
数据清洗单元,用于将有效细胞亚群数据归一化处理,剔除异常值的样本;其中,归一化处理可采用标准归一化处理或最大最小归一化处理,但不限于此;
特征筛选单元,利用包括Lasso、Ridge或ElasticNet中的一种或多种对清洗后的有效细胞亚群数据进行特征筛选,但不限于此,通过多次迭代,筛选出特异的亚群特征;
机器学习模型建立单元,将筛选出的特异的亚群特征作为特征值进行机器学习建立疾病风险预测模型,并寻找最优模型参数;其中,机器学习包括Logistic回归、SVM、Decision Tree、Random Forest、GBDT、XGBoost、Adaboost、FNN、BP神经网络、CNN、RNN、ANN中的一种或多种,但不限于此;寻找最优模型参数的方法可采用网格搜索与交叉验证方法;
模型评估单元,用于对建立的疾病风险预测模型进行评估,具体地可从准确率、灵敏性、特异性、混淆矩阵及ROC曲线多个方面对建立的疾病风险预测模型进行评估;其中,
准确率计算公式为:(TP+TN)/(TP+FN+FP+TN),
灵敏性计算公式为:TP/(TP+FN),
特异性计算公式为:TN/(FP+TN),
ROC曲线是根据特异性、灵敏性画出来的曲线图,曲线与x轴形成的面积称为AUC值,AUC值范围在0~1之间,AUC值越大,表示模型越好,如果小于0.5,表明模型不适用;
混淆矩阵的形式为:
TP表示实际标签为正,预测标签为正;FN表示实际标签为正,预测标签为负;FP表示实际标签为负,预测标签为正;TN为实际标签为负,预测标签为负。
具体地,所述待测样本数据获取模块获取待测样本数据包括:
通过单细胞悬液获取单元获取待测样本单细胞悬液;
利用高维免疫检测单元将待测样本单细胞悬液和抗体组合筛选单元筛选出的抗体组合,通过流式或质谱流式进行检测,获得待测样本流式或质谱流式检测数据;
利用细胞亚群分析单元基于待测样本流式或质谱流式检测数据,对细胞亚群进行聚类分析,获得有效细胞亚群数据。
利用上述系统进行泛疾病风险预测,包括如下步骤:
S1:利用模型建立模块,根据疾病者的高维免疫检测数据和健康者的高维免疫检测数据,通过机器学习方法构建各疾病风险预测模型;
S1.1:利用抗体组合筛选单元,从抗体库中筛选特定疾病对应的抗体组合,根据特异性的细胞亚群或者特定疾病的特异性表达的抗体去筛选,从而获得抗体组合;抗体组合中各抗体分别被荧光素标记或者金属元素标记,以用于后续进行流式或质谱流式分析;
S1.2:利用单细胞悬液获取单元,从疾病者和健康者的血液或组织中分离单个核细胞,制得单细胞悬液;
S1.3:利用高维免疫检测单元,将单细胞悬液和抗体组合,通过流式或质谱流式进行检测,获得流式或质谱流式检测数据;
S1.4:利用细胞亚群分析单元,基于流式或质谱流式检测数据,利用包括Flowjo软件或Cytobank软件或算法代码对细胞亚群进行聚类分析,但不限于此,获得有效细胞亚群数据;
S1.5:利用数据清洗单元,将有效细胞亚群数据归一化处理,剔除异常值的样本;其中,归一化处理可采用标准归一化处理或最大最小归一化处理,但不限于此;
S1.6:利用特征筛选单元,采用包括Lasso、Ridge或ElasticNet中的一种或多种对清洗后的有效细胞亚群数据进行特征筛选,但不限于此,通过多次迭代,筛选出特异的亚群特征;
S1.7:利用机器学习模型建立单元,将筛选出的特异的亚群特征作为特征值进行机器学习建立疾病风险预测模型,并寻找最优模型参数;其中,机器学习包括Logistic回归、SVM、Decision Tree、Random Forest、GBDT、XGBoost、Adaboost、FNN、BP神经网络、CNN、RNN、ANN中的一种或多种,但不限于此;寻找最优模型参数的方法可采用网格搜索与交叉验证方法;
S1.8:利用模型评估单元,对建立的疾病风险预测模型进行评估,具体地可从准确率、灵敏性、特异性、混淆矩阵及ROC曲线多个方面对建立的疾病风险预测模型进行评估;其中,
准确率计算公式为:(TP+TN)/(TP+FN+FP+TN),
灵敏性计算公式为:TP/(TP+FN),
特异性计算公式为:TN/(FP+TN),
ROC曲线是根据特异性、灵敏性画出来的曲线图,曲线与x轴形成的面积称为AUC值,AUC值范围在0~1之间,AUC值越大,表示模型越好,如果小于0.5,表明模型不适用;
混淆矩阵的形式为:
TP表示实际标签为正,预测标签为正;FN表示实际标签为正,预测标签为负;FP表示实际标签为负,预测标签为正;TN为实际标签为负,预测标签为负;
合格的模型标准:准确率在95%以上,特异性、灵敏性在90%以上,且泛化能力强;
S2:利用待测样本数据获取模块,获取待测样本数据;
S2.1:通过单细胞悬液获取单元获取待测样本单细胞悬液;
S2.2:利用高维免疫检测单元将待测样本单细胞悬液和抗体组合筛选单元筛选出的抗体组合,通过流式或质谱流式进行检测,获得待测样本流式或质谱流式检测数据;
S2.3:利用细胞亚群分析单元基于待测样本流式或质谱流式检测数据,对细胞亚群进行聚类分析,获得有效细胞亚群数据;
S3:利用分析预测模块,根据所述待测样本数据与所述疾病风险预测模型进行机器学习分析预测,获得疾病风险预测值。
实施例1
本实施例以构建肺癌风险预测模型为例,具体包括:
一.抗体组合筛选
针对肺癌,本申请人筛选的抗体组合包括40种抗体,所述40种抗体为:
单克隆抗体CD45、CD3、CD56、gdTCR、CD196/CCR6、CD14、IgD、CD123/IL-3R、CD85j、CD19、CD25/IL-2R、CD274/PD-L1、CD278/ICOS、CD39、CD27、CD24、CD45RA、CD86、CD28、CD197/CCR7、CD11c、CD33、CD152/CTLA-4、CD161、CD185/CXCR5、CD66b、CD183/CXCR3、CD94、CD57、CD45RO、CD127/IL-7Ra、CD279/PD-1、CD38、CD194/CCR4、CD20、CD16、HLA-DR、CD4、CD8a、CD11b。
所述40种抗体分别被荧光素标记(流式细胞仪检测法)或者金属元素标记(质谱流式细胞仪检测法)。
所述荧光素选自Biotin、FITC、PE、TRITC、Alexa Fluor 405、Alexa Fluor 430、Alexa Fluor 488、Alexa Fluor 532、Alexa Fluor 546、Alexa Fluor 594、Alexa Fluor633、Alexa Fluor 647、Alexa Fluor 660、Alexa Fluor 680、Alexa Fluor 700、AlexaFluor 750、APC、APC/Alexa Fluor750、APC/Cy7、APC/eflour 750、APC/FireTM750、PerCP/Cy5.5、PerCP、PerCP-eFlour 710、PE/Cy7、PE、PE/Cy5、PE/Dazzle 594、Pacific Blue、Brilliant Violet 421、Brilliant Violet 510、Brilliant Violet 570、BrilliantViolet 605、Brilliant Violet 650、Brilliant Violet 711、Brilliant Violet 750、Brilliant Violet 785、Super Bright 436、Super Bright 600、Super Bright 645、SuperBright 702、eFluor450、eFluor 506、eFluor 660、eFluor 710、eFluor 780、BD HorizonBB515、BD Horizon PE-CF594、BD Horizon BV421、BD Horizon BV480、BD Horizon BV510、BD Horizon BV605、BD Horizon BV650、BD Horizon BV711、BD Horizon BV786、BDHorizon BUV395、BD Horizon BUV496、BD Horizon BUV737、BD Horizon BUV805、BDHorizon APC R700、Cy3、Cy5、Cy7。
所述金属元素选自89Y、106Cd、110Cd、111Cd、112Cd、113Cd、114Cd、115In、116Cd、139La、141Pr、142Nd、143Nd、144Nd、145Nd、146Nd、147Sm、148Nd、149Sm、150Nd、151Eu、152Sm、153Eu、154Sm、155Gd、156Gd、157Gd、158Gd、159Tb、160Gd、161Dy、162Dy、163Dy、164Dy、165Ho、166Er、167Er、168Er、169Tm、170Er、171Yb、172Yb、173Yb、174Yb、175Lu、176Yb、197Au、198Pt、209Bi。
本实施例40种抗体被金属元素标记,且抗体与金属元素标记对应如下:
二.获取132名肺癌患者和130名健康者流式或质谱流式检测数据
流式细胞仪检测法可以以单细胞悬液染色,也可以以人体外周血直接染色,以下以人体外周血直接染色为例:
1.采集不少于100μL的人体外周血作为检测样本;样本采集后即刻检测,或者2~8℃冷藏,48h内检测;
2.分别吸取40种荧光素标记的抗体各0.5~5μL于流式管内,将所述的检测样本加入所述的流式管,振荡混匀,得第一预样品;
3.将所述的第一预样品于常温下避光孵育10~20min,优选15min,或2~8℃20~40min,优选30min,得第二预样品;
4.于所述的第二预样品中加入红细胞裂解液300ul~2mL,振荡混匀,于常温下避光孵育2min,得第三预样品;
5.将所述的第三预样品离心,得第四预样品;所述离心的离心条件为500g,常温,5min;
6.弃所述的第四预样品的上清液,向弃上清液后剩余的样品中加入PBS(pH7.4)重悬,得检测样品;
7.将检测样品上流式细胞仪检测。
质谱流式细胞仪检测法以单细胞悬液染色:
1.采集不少于5mL的人体外周血作为检测样本;样本采集后即刻检测,或者2~8℃冷藏,48h内检测;
2.将检测样本使用淋巴细胞分离液分离,获得单个核细胞;
3.进行细胞计数,取1~3×10
4.用PBS(pH7.4)配置终浓度0.25μM 194Pt(1mM)死活染液,取50ul~1.5ml194Pt死活染液重悬细胞,优选100μL,冰上染色5min;
5.每个样本加入100ul~1.5ml FACS Buffer,优选500ul,重悬细胞,2~8℃400g离心5min,弃上清;
6.每个样本加入20ul~1.5ml封闭液,优选50ul,重悬细胞,冰上封闭20min~1h,优选20min;
7.分别吸取40种金属标记的抗体各0.5~4μL于离心管内,用封闭液将总体积调整至50μL;
8.将所述的检测样本加入所述的离心管,总体积为100μL,振荡混匀;
9.轻柔吹打混匀细胞,冰上染色20~60min,优选30min;
10.每个样本加入1mL FACS Buffer,重悬细胞,2~8℃400g离心5min,弃上清;
11.用Fix and Perm Buffer配置终浓度100~500nM Ir染液,优选250nM,每个样本取200μL~1.5ml重悬细胞,室温孵育1h;
12.弃上清液,使用500ul~1.5mL FACS Buffer,优选1mL,重悬细胞,2~8℃800g离心5min,弃上清,去离子水重悬细胞,将检测样品上质谱流式细胞仪检测。
本实施例以质谱流式检测数据进行后续操作。
基于质谱流式检测数据,利用Cytobank软件对细胞亚群进行聚类分析,每份样本获得40个marker阳性占比以及94个聚类细胞亚群占比。
三.构建肺癌风险预测模型
1.数据清洗
针对262份有效细胞亚群数据,分别进行归一化处理,本实施例采用标准归一化处理,剔除异常值的样本:存在大于三倍标准差的样本,缺失值样本剔除。
2.特征筛选
采用ElasticNet,通过500次迭代,筛选出特异的亚群特征:选择特征出现次数大于300次,并且保留特征系数较大(指定阈值0.5)的特征。
3.模型建立
针对上述筛选的特征利用机器学习建立肺癌风险预测模型,本实施例采用Logistic回归建立肺癌风险预测模型,并采用网格搜索与交叉验证方法寻找最优模型参数。
4.模型评估
从准确率、灵敏性、特异性、混淆矩阵及ROC曲线多个方面对建立的疾病风险预测模型进行评估:
准确率计算公式为:(TP+TN)/(TP+FN+FP+TN),
灵敏性计算公式为:TP/(TP+FN),
特异性计算公式为:TN/(FP+TN),
ROC曲线是根据特异性、灵敏性画出来的曲线图,曲线与x轴形成的面积称为AUC值,AUC值范围在0~1之间,AUC值越大,表示模型越好,如果小于0.5,表明模型不适用;
混淆矩阵的形式为:
TP表示实际标签为正,预测标签为正;FN表示实际标签为正,预测标签为负;FP表示实际标签为负,预测标签为正;TN为实际标签为负,预测标签为负。
已知实际健康的130例受试者和实际肺癌的132例受试者的数据,将这些数据安照上述步骤进行处理后,运行该肺癌风险预测模型,得到的混淆矩阵结果如下表所示:
肺癌与健康受试者的疾病预测
上表说明,在实际为健康的130例受试者中有6例被预测为肺癌,模型特异性为95.38%;在实际为肺癌的132例受试者中有4例被预测为健康者,模型灵敏性为96.97%。通过建模和测试数据,对肺癌检测准确率高达96.18%。
- 一种高维免疫结合大数据和人工智能的泛疾病风险预测系统
- 一种基于大数据探测设备异常人工智能预测系统