一种结合主题模型和孪生网络模型的话题演化跟踪方法
文献发布时间:2023-06-19 11:16:08
技术领域
本发明涉及一种话题演化跟踪方法,特别是一种结合主题模型和孪生网络模型的话题演化跟踪方法。
背景技术
社交媒体信息作为一种数据类型具有动态变化性,而这种变化的载体就是话题,话题随着时间的发展而演化,从而反映了事态阶段性变化的过程。从认知学的角度,这样的演化过程符合人们认知事物的一般顺序,当用户关注某个话题时,一般从话题事件产生的原因开始,逐步深入到事情的发展、高潮,最终到话题事件的结束,这个逻辑顺序就是话题的动态演化,是话题随着事件变化的过程。然而随着计算机应用技术的快速发展,每时每刻产生的信息繁多复杂,面对海量的社交媒体信息,需要对离散化的数据进行挖掘与分析,需要准确完整地获取话题在每个阶段的特征,并且以话题为中心将各个阶段的内容整合,完成对话题的动态演化挖掘,使人们能够迅速且清晰地了解和把握住事情发展的过程与脉络。
通过话题检测与追踪,可以帮助人们从海量的网络信息中筛选出感兴趣的话题信息。现有话题检测技术主要分为三类,一是基于主题模型的话题检测,主要是基于主题模型(Latent Dirichlet Allocation)技术的主题模型,或者基于主题模型改进的主题模型,如公开号为CN105760499A的中国专利,先根据LDA主题模型的时间信息将语料库中的文档离散到时间序列上对应的时间窗口内;然后依次地处理每个时间窗口上的文档集合,得到不同时间片上的训练结果,把前面语料库的训练结果作为后面语料库训练过程中的先验参数;最后从训练结果中得到各LDA主题模型强度随时间的变化趋势,实现网络舆情的动态分析和预测功能。二是基于改进聚类算法的话题检测,如公开号为CN107679135A的中国专利对中文分词后的文档集构建图模型,根据图模型,构造拉普拉斯矩阵,进行特征分解,获取前k个特征向量,对前k个特征向量所构成的矩阵进行聚类,获取聚类结果,根据预先构建的话题的属性向量和聚类结果,计算话题的概率分布,根据话题的概率分布,判断当前文档是否为新话题或指定话题。以上方法对话题进行追踪演化主要基于主题模型或者传统聚类方法,然而主题模型等主题模型属于概率生成模型,侧重于文本结构,因此在文本语义提取方面表征能力相对薄弱,造成话题演化跟踪准确率不高的问题。
发明内容
针对上述现有技术缺陷,本发明的任务在于提供一种结合主题模型和孪生网络模型的话题演化跟踪方法,针对话题检测与追踪任务中提取文本语义薄弱的问题,在保证效率的同时兼顾检测的准确率。
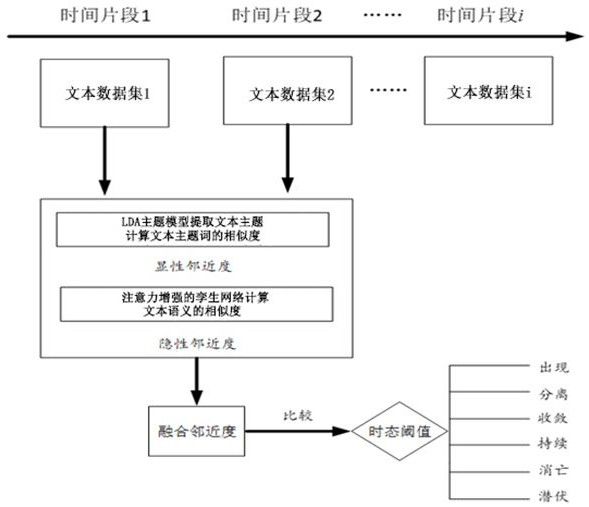
本发明技术方案如下:一种结合主题模型和孪生网络模型的话题演化跟踪方法,包括以下步骤:步骤1、数据采集,对社交媒体平台的用户数据进行爬虫提取;步骤2、对提取的用户数据进行预处理,按照设定的时间间隔把文本进行划分得到需要判别的文本数据;步骤3、采用LDA主题模型计算相邻的时间线内的文本数据进行主题提取并判断两个主题间的显性相似度;步骤4、采用孪生网络和注意力机制计算相邻的时间线内的文本数据的文本语义间的隐性相似度;步骤5、对所述显性相似度和所述隐性相似度进行加权融合得到文本数据间的融合邻近度;步骤6、由所述步骤5得到的融合邻近度确定话题在不同时间线的时态变化。
进一步地,所述显性相似度和所述隐性相似度的加权融合使用以下公式进行
P
其中T
进一步地,所述显性相似度为余弦相似度,
P
所述隐性相似度为
式中T
进一步地,所述孪生网络的子网络为双向长短期记忆网络。
进一步地,所述注意力机制采用以下公式计算
公式中
进一步地,所述步骤6中设定阈值θ
本发明结合LDA主题模型和注意力增强的孪生网络模型对当前的社交媒体文本进行学习,在提取当前文本的主题以及语义后与相邻时间间隔的文本进行相似计算,判断出两个时间段内话题的演化并进行追踪。本发明采用了人工智能的方法,不需要对社交媒体文本进行要求筛选,具有更为广泛的应用性。
本发明与现有技术相比的优点在于:
1、采用LDA主题模型结合注意力增强的孪生BiLSTM网络模型,在现有对文本结构分析的基础上加入了对于文本语义的提取,加强了对于社交媒体文本之间的相关性判定,使得对于话题间关系判定更加准确;
2、通过融合技术为不同的相似度计算分配了不同的权重,在最终决策时能够充分利用各方法计算相似度的优势,选择最优的结果作为模型的权重比例,有利于对于话题关系间的判定;
3、在文本数据的语义提取部分的孪生网络结构中,对学习到的特征描述进行了增强的注意力机制融合,通过引入注意力机制从全局方面把握对于文本语义的提取,以消除冗余信息和由于文本过长导致前序文本丢失而造成的干扰,同时强化那些最具辨别特性的特征描述;
4、本发明通过网络爬虫在社交媒体平台进行信息爬取作为数据集,可以对话题间的演化分析做出准确的预测,让人在短时间内掌握话题的整体脉络发展,易于使用。
附图说明
图1为结合主题模型和孪生网络模型的话题演化跟踪方法示意图。
图2为本发明使用的具有注意力机制的孪生网络结构示意图。
图3为显性相似度权重对判断结果精确度的影响示意图。
具体实施方式
下面结合实施例对本发明作进一步说明,但不作为对本发明的限定。
请结合图1所示,本发明实施例所涉及的一种结合主题模型和孪生网络模型的话题演化跟踪方法,包括以下步骤:
步骤一:数据采集
通过网络爬虫技术在社交网络平台进行信息爬取,确保数据真实性,数据集中可包含用户、时间和社交文本等数据。
步骤二:数据预处理
为了让数据以文本的形式输入网络,本发明将通过爬虫技术提取到的社交媒体文本数据转化为csv文件。首先,通过步骤一所获取的数据是txt的文本格式,给一个用户的信息文本为不确定长度的信息,由于所需要分析的数据为话题演化,因此从步骤一中的数据按照提取到的时间特征进行排序,接着按照设定的时间间隔对文本进行划分。其次由于社交媒体文本存在的非正式性,行为随机性等特点,通过jieba工具将文本进行词句切分并通过筛选停止词,剔除社交媒体文本中的无意义文本数据。接着将本发明将用户,时间与文本数据转化成csv文件格式,并将从csv文件中读取的数据,按照前面设定的时间间隔为整体作为网络模型所需的文本输入数据。
步骤三:使用话题演化追踪模型学习文本特征
本发明的目的是为了根据已有的社交媒体文本进行话题演化分析,本发明将话题的时态分为六个时态依次为:出现,持续,分离,收敛,消亡和潜伏。
传统基于LDA主题模型的方法中存在的缺乏对文本语义提取的缺陷,因此本发明结合了孪生网络对社交文本进行提取。本发明在文本间关系计算中主要分为两个部分:一为对于文本结构中主题词的提取,并将其在词向量空间中计算主题词间的相似度;二为对于文本语义的提取,主要使用注意力增强的孪生双向长短期记忆网络模型对文本间的语义关系进行计算。
将文本间关系计算定义为融合邻近度:
P
其中T
对于第一部分中主题词的提取,本发明采用David Blei提出的LDA主题模型,将文本表示成一系列话题的集合,生成过程相当于实现了文本的话题聚类和文本的压缩,每个文本根据不同权重被分配到不同话题中。采用LDA方法确定各时间线中的文本的主题,提取相邻时间段内的主题,对于时间线T
P
请结合图2所示,对于第二部分中文本于语义提取部分,本发明采用的核心模型为基于循环神经网络改进的长短期记忆网络,相较侧重于识别跨空间的模式的卷积神经网络,其在检测局部的任务中取得较优的结果而言,循环神经网络侧重于跨时间的模式,对于长程语义的文本中可以得到优异的效果,因此在社交文本数据本身存在的时序性特点前提下,循环神经网络具有更好的表现,而长短期记忆网络作为循环神经网络的改进模型,其模型结构中记忆单元能有效的记录文本时序特征,在解决传统方法中提取文本语义较弱的缺点上能够得到更好的效果。
长短期记忆网络只能通过正向提取文本语义,且存在文本序列过长可能产生丢失前部序列信息的问题,在长短期记忆网络的基础上增加逆向文本的语义信息,在学习文本语义信息的同时加强了对于语义学习的能力,即为Graves提出的双向长短期记忆网络,该模型可以获得更多的文本语义信息。且在该基础上引入了注意力机制解决上述存在的信息丢失问题,从全局考虑文本语义信息,提取全局文本信息进行计算。注意力层的注意力机制的计算公式如下式所示:
公式中
隐性相似度使用基于孪生双向长短期记忆网络和注意力机制并且使用曼哈顿距离的方法来实现句对之间的相似度度量。两个输入文本经过双向长短期记忆网络得到表征当前词段前后文语义的向量,并通过注意力机制中Q,K,V权重矩阵,对得到的向量进行权重分配,然后经过上述注意力层得到两个向量,该向量表征其对应的输入文本语义,通过曼哈顿函数进行计算得到两者相似度。当计算时间线T
本步骤结合LDA主题模型和注意力增强的孪生双向长短期记忆网络模型能够在现有技术的基础上加入了对于文本语义信息的关注,提高了分辨文本间关系的准确率。本步骤中选择采用网格搜索来确定对于文本结构和文本语义关系的计算权重,即线性相似度和隐性相似度的权重,如图3所示,可以看出当计算两文本之间的关系通过对于其文本结构间的关系可以占据总结果的四成(a=0.4),而对于文本间的语义关系占据总结果的六成(b=0.6),这样的分配比例得出的结果最为优异。
步骤四:话题时态关系判定
时态关系的判定基准由θ
若时间线T
若有且仅有一个时间线k中话题T
若时间线k中至少两个话题T
若一个时间线k中话题T
如果时间线T
由于社交媒体中用户行为随机性的特点,若用户在时间线T
各个时态转化成的数学计算公式如下表所示
表中E,P,C,D,E
- 一种结合主题模型和孪生网络模型的话题演化跟踪方法
- 一种面向实时新闻内容的流式话题演化跟踪方法