用于微生物物种检测、定量和抗生素敏感性鉴定的系统
文献发布时间:2023-06-19 11:35:49
在先申请的交叉引用
本申请要求于2018年8月30日提交的标题为“System for Microbial SpeciesDetection,Quantification and Antibiotic Susceptibility Identification”的US临时专利申请序列号62/725,026和于2019年8月26日提交的标题为“System for MicrobialSpecies Detection,Quantification and Antibiotic SusceptibilityIdentification”的US专利申请序列号16/551,702的优先权。
技术领域
本发明涉及用于检测和定量存在于生物样品中的一种或更多种微生物物种并鉴定这样的微生物的抗生素敏感性的系统。更具体地,本发明涉及用于检测、定量和鉴定来自患有可能的尿路感染的患者的尿样品中的微生物以及所述微生物的抗生素敏感性的系统。
背景技术
尿路感染(urinary tract infection,UTI)是构成重大公共健康威胁的微生物感染。在2007年,在美国有1,050万门诊UTI就诊进行医疗护理(visits for medical care),而这些就诊中的21.3%为紧急情况。UTI在全世界也很流行,尤其是在具有众多人口和公共卫生挑战的国家。
美国疾病预防控制中心(United States Center for Disease Control andPrevention)将UTI描述为当微生物进入尿路时发生的感染。UTI可起因于卫生条件差、交际、解剖结构异常以及细菌、病毒或真菌的存在。一些群体患UTI的风险更高,由于解剖结构引起的妇女和女孩的UTI比率比男性更高。老年人和有尿失禁或导管植入物的患者也有较高的UTI风险。UTI症状是痛苦的,并且已被患者描述为在排尿时引起疼痛或灼痛的感觉、频繁排尿以及尽管膀胱排空但仍需要排尿的感觉。其他常见症状包括低热(约38℃)、尿混浊或血尿、以及腹股沟或下腹部的压力或痛性痉挛。进一步使准确和及时的诊断复杂化的是,UTI症状通常基于患者年龄而不同地呈现。患有UTI的婴儿通常存在有发热、性情急躁(fussy disposition)或食欲降低。相比之下,老年UTI患者可以无症状或可表现出类似于痴呆的症状,伴有过度疲劳和失禁。尽管表现范围很广,但准确和及时的诊断至关重要,因为未经治疗的UTI可发展为更严重的病症,例如肾感染或脓毒症。
在当前的实践中,UTI的诊断涉及临床和身体检查,随后是无菌尿分析和阳性尿培养测试二者,所述阳性尿培养测试通常需要数天来完成,并且通常不用于门诊环境。FoxmanB.,“Epidemiology of urinary tract infections:incidence,morbidity,and economiccosts”,American Journal of Medicine 113(1):5-13(2002)。对于可从中收集中段尿(mid-stream urine)样品的患者,遵循该“金标准”操作。对于不能自行排尿的患者,可通过导管收集尿,这至少是不舒服的并且会疼痛。
尿分析可相对快速地进行,并且可告知提供者由于读取样品中白血细胞水平升高而在尿路中是否可存在感染,但这不能鉴定引起感染的微生物、定量感染的水平或指示合适的抗生素。
尿培养测试检测所存在的特定病原体、定量微生物负荷、并且可鉴定潜在的抗生素抗性,但这需要大量时间。在该测试中,将尿样品擦拭到培养皿(Petri plate)中的生长培养基上。在合适的孵育期以使得微生物能够复制之后,视觉检查培养皿的微生物,然后由经训练的专科医师对其进行鉴定和定量。如果要寻找抗生素抗性,可制作多个测试板,其中每个都经受不同的抗生素以测试对该抗生素的抗性。该方法具有的优点是其可以找到任何类型的微生物并寻找任何类型的抗生素抗性,但缺点是微生物必须繁殖足够长时间来产生人眼明显可辨的菌落。从尿培养测试中获得结果需要至少18小时,并且通常多至72小时。值得注意地,当进行尿培养测试以诊断可疑的UTI时,多达80%的时间该测试结果为阴性(即,该测试表明患者不具有UTI)。
当前尿培养测试所需的漫长时间导致治疗方法非常不令人满意。在大多数情况下,并且尤其是在小儿或老年病例中,临床医师倾向于在可获得尿培养测试结果之前很久就默认开出广谱抗生素处方,所述抗生素涵盖了最经常与UTI相关的一系列微生物。由于多达80%的尿培养测试结果显示未感染,因此这意味着80%的患者都在对其毫无价值的情况下开出抗生素处方。如果随后的尿培养测试结果表明患者患有微生物感染,但是是对最初使用的抗生素不敏感的患者,则将停止初始抗生素并开出正确抗生素的处方。这是假设临床医师可在那时实际上接触到患者,但通常情况并非如此。
在患者不具有UTI时的情况和在患者患有对初始抗生素不敏感的感染的情况二者下,患者均被开出无效抗生素的处方。这对患者没有帮助,并且促进了抗生素抗性微生物的生长。
总之,UTI极为常见,但是实践者普遍认为当前的诊断和治疗过程是有缺陷的。特别地,通过尿培养测试对给定感染中的微生物负荷进行缓慢的检测和定量,意味着通常对实际上不具有UTI的患者、以及甚至是确实患有UTI的患者开出抗生素处方,初始开出的抗生素处方可能靶向错误的微生物,或者微生物可能对该抗生素具有抗性,因此需要对抗生素进行测试后更改。这个极为常见的问题促进抗生素抗性,这日益威胁到公共健康。
为了改善治疗,需要微生物检测、定量和抗生素抗性鉴定的新方法,其在数小时内而不是数天内发挥作用并且找到至少对已知频繁引起这样的感染的微生物的正确治疗,所有这些由于所需测试的高容量而成本相当地低。
发明内容
本发明基于对当前过度的金标准尿培养测试的认识。具体地,当前测试假设尚不知晓什么微生物可引起UTI,因此有必要寻找所有可能的微生物。但是该假设与现实相去甚远。相反,几乎所有的UTI均是由出乎意料的有限数目的微生物引起。
例如,在美国,仅一个微生物科(microbial family)引起所有单纯性UTI中的75%,而9个微生物科引起几乎所有单纯性UTI。具体地,在单纯性UTI(uncomplicated UTI)中,尿路致病性大肠杆菌(uropathogenic Escherichia coli,UPEC)引起所有单纯性UTI中的75%,肺炎克雷伯菌(Klebsiella pneumoniae)引起6%,腐生葡萄球菌(Staphylococcussaprop砂ticus)(6%),肠球菌属(Enteroccus spp.)(5%),B组链球菌(group BStreptococcus,GBS)(3%),奇异变形杆菌(Proteus mirabilis)(2%),铜绿假单胞菌(Pseudomonas aeruginosa)(1%),金黄色葡萄球菌(Staphylococcus aureaus)(1%)和念珠菌属(Candida spp)(1%)。对于复杂性UTI(complicated UTI),每种微生物的频率略有不同,但是仅4个微生物科导致所有复杂性UTI中的超过90%,而引起单纯性UTI的同一微生物科几乎导致所有复杂性UTI。具体地,UPEC导致所有复杂性UTI中的65%,肺炎克雷伯菌引起8%,肠球菌属(11%),GBS(2%),奇异变形杆菌(2%),铜绿假单胞菌(2%),金黄色葡萄球菌(3%)和念珠菌属(7%)。Ana L.Fores-Mireles et al.,“Urinary tractinfections:epidemiology,mechanisms of infection and treatment options”,NatureReviews Microbiology 13:269-284(2015)。类似地,在英国,取决于获取UTI的方式和地点,同一物种引起所有UTI中的至少85%。D.J.Farrell et al.,“A UK Multicentre Studyof the Antimicrobial Susceptibility of Microbial Pathogens Causing Urinarytract Infection”,Journal of Infection 46:94-100(2003)。
这为诊断UTI提供了完全不同的方法。代替寻找可能存在的任何微生物,本发明使用探针寻找已知引起几乎所有UTI的特定微生物。本发明无需进行尿培养测试,使用特异性地靶向这些常见微生物的DNA、RNA、抗体、适配体或小分子探针来更快速得多地检测和定量微生物。该新测试应花费不到一小时,这对于让患者等待测试结果来说是足够快的。对于80%呈阴性的测试,这将使临床医师能够继续研究引起患者症状的其他可能原因,并避免开出完全不必要的抗生素处方。对于20%呈阳性的测试,通过诊断是哪种微生物引起了UTI,该测试将使医师能够更好地了解开出哪种抗生素处方来治疗特定微生物。
根据本发明的另一个方面,本发明使用特异性地靶向已知提供抗生素抗性的核苷酸或蛋白质之存在的DNA、RNA、抗体、适配体或小分子探针,使得能够迅速鉴定哪些抗生素将对所存在的微生物不发挥作用。如同鉴定和定量测试,该测试应花费不到一小时,这对于让患者等待测试结果来说是足够快的。这样确保了如果抗生素是合适的,他们将带上正确抗生素的处方回家。
本发明的另一个方面提供了备用诊断抗生素抗性鉴定测试,其使用更类似于传统尿培养测试的方法,但是是在使测试能够更快进行的新系统中。该新测试基于对传统测试下的两个问题的认识:
首先,传统测试需要微生物复制足够的时间以使人可见。这样的复制所需的时间是导致测试花费18至72小时的原因。在根据本发明的系统中,使用小孔代替培养皿,并且使用传感器检测微生物。该传感器可在远少于人眼可以观察到的繁殖周期之后检测到微生物,从而将孵育时间缩短至最多数小时。
其次,传统测试需要经高度训练的人来读取测试。这很昂贵,并且可能花费相当长的时间,尤其是如果有多个微生物变种和/或在进行测试以鉴定抗生素抗性从而需要多个培养皿时。在根据本发明的系统中,软件在最多数秒内分析每个孔的传感器输出,即使在使用许多单元格(cell)时,也可将读取测试所需的时间缩短至最多数分钟。
更具体地,根据本发明的这个方面,一种系统使用具有多个孔的芯片来鉴定抗生素抗性。每个孔均具有生长培养基、抗生素以及指示存在活微生物的报道物(reporter)。一旦提供了尿样品,将孔密封并孵育。然后使用传感器检测来自报道物的活性,这继而指示了不同孔中的微生物生长。但是,孔可以比培养皿小得多(小于1cc,并且优选小于0.1cc),这允许孵育过程花费显著较少的时间,因为需要的复制更少。该测试应花费1至7小时,而其中非常小的孔则需要1至3小时。患者可能不想等待检测结果,但是可在数小时内将正确抗生素的处方发送至药房,并随后可以通知患者将其取走。
鉴于提供以上测试的任何系统都将必须处理和测试尿,如果同一系统可进行常规尿分析(那天与尿培养测试分开进行),也将很方便。来自尿分析的测试结果通常会在不到1小时内准备好。
为此,本发明提供了这样的系统:用于进行尿分析、检测和定量导致UTI的常见微生物物种的存在、鉴定如由DNA或RNA所示的任何抗生素抗性或者已知提供这样的抗生素抗性的其他大分子的存在,以及测试一系列抗生素针对所存在的任何微生物的效力,无论所述微生物是否具有已知提供抗生素抗性的这样的DNA或RNA。
为了进行这些测试,系统具有带有可更换微流控测试芯片(replaceablemicrofluidic test chip)的固定硬件部分(fixed hardware portion)。硬件接收尿样品并将其递送至每个芯片。芯片上的多种反应物然后进行相关测试。然后,硬件会测量芯片上测试的结果,并直接将结果报道至系统上的屏幕,或者报道至相关的计算机系统,或者报道至这二者。
优选地,系统使用3种芯片。
第一芯片是具有多个部分(优选2至100,更优选4至50,更优选8至25个部分)的微生物检测芯片(或MDC(microbial detection chip))。每个部分以用于从尿样品中捕获微生物并用于用探针对所述微生物进行测试的容积提供。每种这样的探针可测试特定的微生物或测试指示抗生素抗性的DNA或RNA的特定链的存在。在使用中,该系统将尿递送至不同的部分,然后所述部分鉴定并定量相关微生物和/或相关DNA或RNA链的存在。系统自身从每个部分读取结果,优选光学读取。
MDC与现今常用的尿培养测试之间的一个显著差异是,该系统测试已知导致几乎所有EiTIs v的特定微生物科的存在,寻找可能存在的任何类型和所有类型的微生物。类似地,MDC可测试已知提供抗生素抗性的特定微生物特征。并且所有这些都可在短时间(可能不到1小时)内进行。
第二芯片是具有多个孔(优选至少2个,更优选至少12个,更优选至少20个孔)的抗生素敏感性芯片(或ASC(antibiotic susceptibility chip))。在使用中,该系统将与生长培养基和将报道活微生物之存在和量的报道物(例如刃天青(resazurin))混合的尿递送到每个孔中。或者,可将生长培养基和报道物预装载到每个孔中,并仅添加尿。然后将孔各自分离并孵育以使任何微生物都能够繁殖。优选地,至少一个孔不包含抗生素作为对照。其他部分各自均预装载有不同的抗生素,以测试对每种抗生素的抗性。或者,可在递送之前将抗生素与尿样品混合。在合适的孵育时间以培养任何微生物之后,系统检查并报道每个孔中所存在的微生物水平。直接或与对照孔比较,结果将表明哪些抗生素在控制任何微生物感染方面将是最有效的。
ASC用作MDC的备份。ASC对特定类型的微生物不可知,它会测试可能存在的任何微生物中的抗生素抗性。它直接通过测试哪些抗生素确实具有效果和不具有效果以及效果有多大。孔的尺寸可以比培养皿小得多(小于1ml,并且优选小于0.1ml)。这种显著降低的尺寸使该测试能够比常规尿培养测试快得多地运行,例如,在小孔中运行1至7小时,并且可能1至3小时。另外,运行或读取测试几乎不需要技巧(提供尿样品,并且测试可自动运行)。
第三芯片是尿分析芯片(urinalysis chip,UC)。UC包含类似于现今在检测试纸(dip stick)上用于尿分析使用的那些的反应物。这些反应物取决于尿中特定化学物质的量而改变颜色。然后,该系统光学读取颜色以确定测试结果。该测试将花费与当前检测试纸基本相同量的时间,其为一分钟或两分钟。
芯片可以是各自单独的,或者其也可以全部在可更换盒(replaceablecartridge)中。优选地,接触尿样品的系统的所有部分也是可易于更换盒的一部分。或者,该系统将包含用于冲洗、清洁和消毒接触尿样品的系统的任何部分的规定(provisions)。
该系统使得能够在约1小时内通过已知的DNA或RNA鉴定和定量微生物和抗生素抗性,广谱抗生素敏感性测试可在最多数小时内完成,并且常规尿分析可在数分钟内完成。用于完成尿分析、微生物的鉴定和定量以及已知抗生素抗性的约1小时的初始时间足够短,对于患者等待测试结果是合理的。如果测试为阴性并且患者不具有UTI,这可以使临床医师能够快速进行其他假设的测试,这尤其可用于阴性结果的频率很高的患者组。不可知抗生素敏感性测试的数小时时间意味着临床医师可在完成初始测试之后4小时告知患者去药房取走抗生素处方,并且这将是将实际发挥作用的抗生素。同时,这将改善患者护理并显著减少无效抗生素的处方。
以上发明概述并非旨在描述本发明的每个实施方案或每个实施方式。本发明的其他实施方案、特征和优点将通过其以下发明详述、从附图和从权利要求书中变得明显。
附图说明
图1是根据本发明的系统的一个实施方案的投影视图(projection view);
图2是图1的系统的框图。
图3是用于图1的系统中的微生物检测芯片(或MDC)。
图4是用于图1的系统中的抗生素敏感性芯片(或ASC)。
图5是用于图1的系统中的尿分析芯片(或UC)。
具体实施方式
如图1中所示,根据本发明的第一实施方案包括其中具有样品接收区域(samplereceiving area)12的系统10。可将包含从患者接收的尿的尿样品瓶14置于样品接收区域12中。系统10还包含可插入到尿样品瓶20中以从中抽取尿的样品抽取移液管16。系统10还包含可更换地可插入到装置10中的盒18,所述盒18包含将在下文进一步描述的微流控芯片。
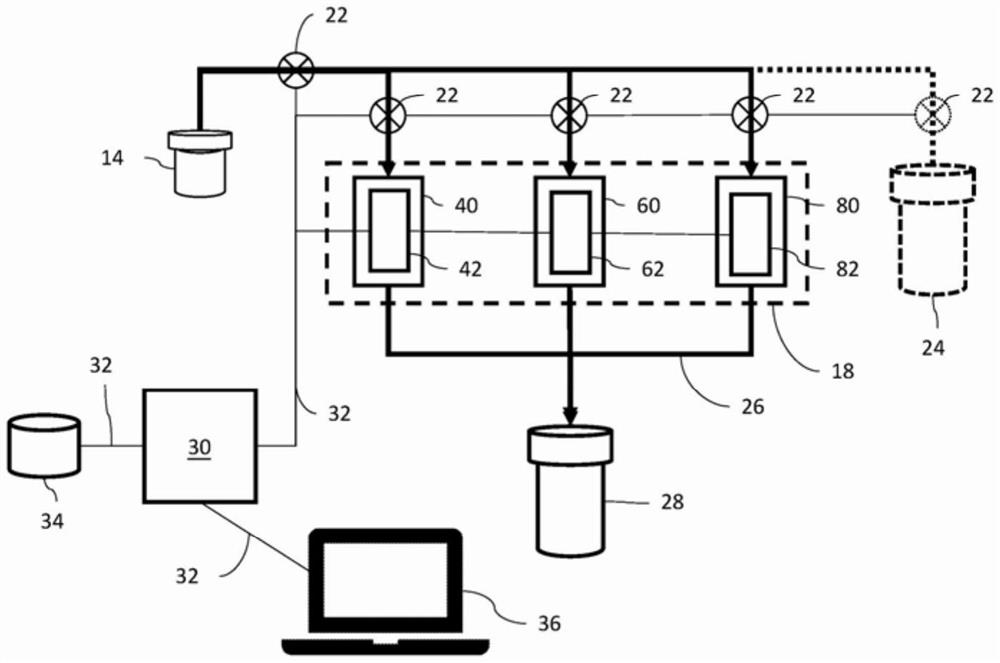
现在参考图2,盒18包含3个微流控芯片,微生物检测芯片(MDC)40、抗生素敏感性芯片(ASC)60和尿分析芯片(UC)80。样品抽取移液管16通过样品分配线(distributionline)20连接以将尿样品提供给微流控芯片40、60、80中的每一个。样品从瓶14至芯片40、60、80的流动由一系列泵22控制。如果期望的话,可以在一个或更多个溶液瓶(solutionvial)24中提供多种另外的流体,例如缓冲溶液或清洁溶液,所述溶液瓶24也通过分配线20连接至芯片40、60、80,并由泵22控制。从芯片40、60、80流出的液体通过废物收集线(wastecollection line)26收集并递送至废物收集瓶28。系统10中提供了3个传感器,用于MDC 40的MDC传感器42、用于ASC 60的ASC MDC传感器62和用于UC 80的UC MDC传感器82。在每种情况下,将相关的MDC传感器42、62、82定位为对所缔合的芯片40、60、80进行测量。编程化CPU30通过电线32连接,以控制泵22的操作并操作传感器42、62、82以及从其收集数据。CPU30还通过电线32连接至海量存储器34和一个或更多个I/O装置36,其可以是系统10上的屏幕或者独立的笔记本计算机(laptop)、移动装置、集中式病历记录系统等。下文将结合每个芯片40、60、80进一步描述系统的操作。芯片40、60、80优选地全部在可更换盒18中,因此在每次使用之后可容易地对其进行更换。
MDC结构和操作
MDC 40更详细地示于图3中。在芯片40上提供了入口44,以从样品分配线20接收尿样品。然后,尿样品通过分配通道(distribution channel)46和分支结构(branchstructure)48分配至一系列的微流控通道50。每个微流控通道50均包被有微生物将黏附的物质,例如但不限于抗体、蛋白质、双链DNA、单链DNA、双链RNA、单链RNA以及适配体,其任一个可包含100%天然氨基酸、天然和非天然氨基酸的混合物或100%非天然氨基酸。包被物可附着至所有形式的微生物,或者可靶向特定的物种或科,与下文进一步讨论的相关探针匹配。
一系列的探针储器(probe reservoir)52各自包含针对不同微生物的探针,其将在下文更详细地描述,并且其通过密封剂塞(sealant plug)53适当地保持在探针储器中。每个探针储器52连接到子分支水平(subbranch level)49处的分支结构48中,以便其将连接至微流控通道50的特定簇(specific cluster)51。当每种探针如下文所述从其探针储器52释放时,其将流入到其缔合的簇51中而不是流入到其他簇中。在每个微流控通道50的另一端是收集通道56,该收集通道56连接至出口57,通过该出口57可将流过MDC 40的流体从MDC 40中除去。任选地,也可以在MDC 40上提供流体储器58,该MDC 40可包含用于MDC 40中的多种流体,例如但不限于缓冲剂、裂解剂等。因此可从芯片上的储器60或从外部溶液瓶24中提供这样的流体,这对于系统10的特定实施方案的设计是最方便的。
从图3的检视中将明显的是,示出了通道50的2个集合,每个集合具有4个相应的储器52。可扩展或降低集合数目,储器数目以及每个集合中通道的数目,如系统10的特定实施方案的设计所需要的那样。
在使用中,尿被提供至入口44,然后尿将流过分配通道46、分支46、微流控通道50和收集通道56至出口57。当尿通过微流控通道50时,其由于包被物将黏附于壁。然后停止尿输入,并用来自芯片上储器58或外部溶液瓶24的裂解溶液冲洗通道50。当裂解溶液流过微流控通道50时,其将裂解存在于通道壁上的所有微生物。停止裂解溶液,并随后从芯片上储器58或外部溶液瓶24中提供缓冲溶液。当该缓冲溶液流过微流控通道50时,其将冲洗掉裂解溶液和未结合至通道壁的任何其他物质。
优选地,选择封闭探针储器52的密封剂塞53的材料,使得缓冲溶液将溶解密封剂塞53。如果没有,则可以使单独的溶液流过MDC 40以溶解密封剂塞53。
当密封剂塞53溶解时,探针将随后从每个探针储器52流出,流入到微流控通道50的所缔合的簇51。探针将与它们所探查的每个通道中的每种微生物的方面结合,如果存在的话。在合适的时间使探针结合之后,可使洗涤溶液冲洗通过系统以洗去任何未结合的物质,仅留下结合的探针。使用MDC传感器42测量结合的探针的存在和数目,并将所得数据提供给CPU 30,CPU 30将其存储在海量存储器32中。
如上所述的MDC结构最适用于其中探针需要靶向胞内物质(例如DNA)的情况中。如果探针仅靶向蛋白质或微生物表面上表达的其他化合物,则可以简化结构和方法。具体地,根据本发明的该实施方案,可省略探针储器52,并且将探针用作通道集合内部上的包被物。由于探针将黏附于微生物的表面并且不需要裂解,因此可省略上述的裂解步骤。
MDC探针
MDC中使用的探针通常采取附着物-报道物复合物(attacher-reporter complex)的形式,即,其具有配置成将附着至特定微生物或微生物的一部分的附着物部分,以及与该附着物部分结合的通过外部装置可易于检测的报道物部分。创建这样的附着物-报道物探针是本领域普通技术人员公知的过程,他们知道实现该目的的许多方法。
其中,最常见的附着物是将与来自微生物的属特异性、物种特异性或亚种特异性的DNA、RNA、寡核苷酸、肽或类似序列结合的单链或双链的DNA或RNA序列。例如,这样的附着物可靶向所附DNA序列No.1和/或2来鉴定大肠杆菌,序列No.3、4、5和/或6来鉴定肺炎克雷伯菌,序列No.7和/或8来鉴定腐生葡萄球菌,序列No.9和/或10来鉴定肠球菌属(Enterococcus spp),序列No.11和/或12来鉴定奇异变形杆菌,序列No.13和/或14来鉴定铜绿假单胞菌,序列No.15和/或16来鉴定金黄色葡萄球菌(Staphylococcus aureus),序列No.17和/或18来鉴定念珠菌属,序列No.19和/或20来鉴定白念珠菌(Candida albicans),序列No.21和/或22来鉴定沙眼衣原体(Chlamydia trachomatis)以及序列No.23和/或24来鉴定生殖支原体(Mycoplasma genitalium)。类似地,可使用所附序列No.25和/或26来鉴定携带对抗生素的青霉素组具有抗性的标记的微生物,序列No.27和/或28来鉴定环丙沙星(ciproflaxin),序列No.29和/或30来鉴定左氧氟沙星(levofloxacin),以及序列No.31和/或32来鉴定头孢氨苄(cephalexin)。
设计附着物的另一种公知方法是制造适配体,所述适配体是与特定靶分子结合的特异性寡核苷酸或肽分子。可将适配体改造为与存在于特定微生物物种上的已知表面标志物结合,从而达到仅将附着至一种微生物物种的目的。还可将适配体设计为靶向存在于任何细菌物种和所有细菌物种及亚种上的毒力因子。
可将合适的适配体设计为靶向存在于生物体表面上的特定蛋白质(例如外膜蛋白(outer membrane protein,OMP)、毒力因子、IgG等)或生物体的细胞内部的蛋白质和靶序列(例如DNA、mRNA、tRNA、sRNA)。抗体和/或适配体可结合的表面标志物的一个实例是存在于微生物表面上的O抗原。靶序列的一个实例是在细菌物种中高度丰富的16S核糖体RNA序列。已经为许多物种鉴定了16S序列。例如,序列No.1是大肠杆菌的16S序列。
虽然这样的DNA、RNA和适配体附着物是最常见的,但是许多其他形式的附着物是公知的,并且可在根据本发明的系统10中使用。例如,并且但不限于,这样的附着物可以是天然或合成的DNA、RNA、抗体、适配体或者使用天然和/或非天然氨基酸并且识别微生物表面分子、微生物胞内蛋白质或者微生物DNA或RNA的其他氨基酸结构。所有这样的化合物均可以被截短(例如Fab、Fab’2、scFv),进行多价改造或以其他方式检测多于一个靶标。所有这样的附着物也可以被改造为抵抗酶促或非酶促降解。
这些附着物中的任意均可适当地选择或设计为靶向物种和亚种,包括但不限于:橙黄醋杆菌(Acetobacter aurantius)、鲍曼不动杆菌(Acinetobacter baumannii)、以色列放线菌(Actinomyces israelii)、放射形土壤杆菌(Agrobacterium radiobacter)、根癌土壤杆菌(Agrobacterium tumefaciens)、吞噬细胞无形体(Anaplasmaphagocytophilum)、茎瘤固氮根瘤菌(Azorhizobium caulinodans)、棕色固氮菌(Aztobacter vinelandii)、炭疽芽孢杆菌(Bacillus anthracis)、短芽孢杆菌(Bacillusbrevis)、蜡样芽孢杆菌(Bacillus cereus)、纺锤芽孢杆菌(Bacillus fusiformis)、地衣芽孢杆菌(Bacillus licheniformis)、巨大芽孢杆菌(Bacillus megaterium)、蕈状芽孢杆菌(Bacillus mycoides)、嗜热脂肪芽孢杆菌(Bacillus stearothermophilus)、枯草芽孢杆菌(Bacillus subtilis)、苏云金芽孢杆菌(Bacillus thuringiensis)、脆弱拟杆菌(Bacteroides fragilis)、牙龈拟杆菌(Bacteroides gingivalis)、产黑素拟杆菌(Bacteroides melaninogenicus)、汉赛巴尔通体(Bartonella henselae)、五日热巴尔通体(Bartonella quintana)、支气管败血鲍特菌(Bordetella bronchiseptica)、百日咳鲍特菌(Bordetella pertussis)、伯氏疏螺旋体(Borrelia burgdorferia)、布鲁氏菌(Brucella)、流产布鲁氏菌(Brucella abortus)、马耳他布鲁氏菌(Brucellamelitensis)、猪种布鲁氏菌(Brucella suis)、鼻疽伯克霍尔德菌(Burkholderiamallei)、类鼻疽伯克霍尔德菌(Burkholderia pseudomallei)、洋葱伯克霍尔德菌(Burkholderia cepacia)、肉芽肿荚膜杆菌(Calymmatobacterium granulomatis)、结肠弯曲菌(Campylobacter coli)、胎儿弯曲菌(Campylobacter fetus)、空肠弯曲菌(Campylobacter jejuni)、幽门弯曲菌(Campylobacter pylori)、沙眼衣原体、肺炎衣原体(Chlamydophila pneumoniae)、鹦鹉热衣原体(Chlamydophila psittaci)、肉毒梭菌(Clostridium botulinum)、艰难梭菌(Clostridium difficile)、产气荚膜梭菌(Clostridium perfringens)、破伤风梭菌(Clostridium tetani)、白喉棒状杆菌(Corynebacterium diphtheriae)、梭形棒状杆菌(Corynebacteriym fusiforme)、贝纳柯克斯体(Coxiella burnetti)、查菲埃立克体(Ehrlichia chaffeensis)、阴沟肠杆菌(Enterobacter cloacae)、鸟肠球菌(Enterococcus avium)、耐久肠球菌(Enterococcusdurans)、粪肠球菌(Enterococcus faecalis)、屎肠球菌(Enteroccous faecium)、鹑鸡肠球菌(Enterococcus galllinarum)、病臭肠球菌(Enterococcus maloratus)、大肠杆菌(Eschericichia coli)、土拉弗朗西斯菌(Francisella tularenisis)、具核梭形杆菌(Fusobacterium nucleatum)、阴道加德纳菌(Gardnerella vaginalis)、杜克雷嗜血杆菌(Haemophilus ducreyi)、流感嗜血杆菌(Haemophilus influenzae)、副流感嗜血杆菌(Haemophilus parainfluenzae)、百日咳嗜血杆菌(Haemophilus pertussis)、阴道嗜血杆菌(Hamephilus vaginalis)、幽门螺杆菌(Helicobacter pylori)、肺炎克雷伯菌、嗜酸乳杆菌(Lactobacillus acidophilus)、保加利亚乳杆菌(Lactobacillus bulgaricus)、干酪乳杆菌(Lactobacillus casei)、乳酸乳球菌(Lactococcus lactis)、嗜肺军团菌(Legionella pneumophila)、单核细胞增生李斯特菌(Listeria monocytogenes)、扭脱甲烷杆菌(Methanobacterium extroquens)、多形微杆菌(Microbacterium multiforme)、藤黄微球菌(Micrococcus luteus)、卡他莫拉菌(Moraxella catarrhalis)、鸟分枝杆菌(Mycobacterium avium)、牛分枝杆菌(Mycobacterium bovis)、白喉分支杆菌(Mycobacterium diphtheriae)、胞内分枝杆菌(Mycobacterium intracellulare)、麻风分枝杆菌(Mycobacterium leprae)、鼠麻风分枝杆菌(Mycobacterium lepraemurium)、草分枝杆菌(Mycobacterium phlei)、耻垢分枝杆菌(Mycobacterium smegmatis)、结核分枝杆菌(Mycobacterium tuberculosis)、发酵支原体(Mycoplasma fermentans)、生殖支原体、人型支原体(Mycoplasma hominis)、穿通支原体(Mycoplasma penetrans)、肺炎支原体(Mycoplasma pneumoniae)、淋病奈瑟菌(Neisseria gonorrhoeae)、脑膜炎奈瑟菌(Neisseria meningitidis)、多杀巴斯德菌(Pasteurella multocida)、土拉巴斯德菌(Pasteurella tularensis)、消化链球菌属(Peptostreptococcus)、牙龈卟啉单胞菌(Porphyromonas gingivalis)、产黑素普雷沃菌(Prevotella melaninogenica)、铜绿假单胞菌(Pseudomonas aeruginosa)、放射根瘤菌(Rhizobium radiobacter)、普氏立克次体(Rickettsia prowazekii)、鹦鹉热立克次体(Rickettsia psittaci)、五日热立克次体(Rickettsia quintana)、立氏立克次体(Rickettsia rickettsii)、沙眼立克次体(Rickettsia trachomae)、亨氏罗卡利马体(Rochalimaea henselae)、五日热罗卡利马体(Rochalimaea quintana)、龋齿罗氏菌(Rothia dentocariosa)、肠炎沙门菌(Salmonellaenteritidis)、伤寒沙门菌(Salmonella typhi)、鼠伤寒沙门菌(Salmonellatyphimurium)、黏质沙雷菌(Serratia marcescens)、金黄色葡萄球菌、表皮葡萄球菌(Staphylococcus epidermidis)、嗜麦芽窄食单胞菌(Stenotrophomonas maltophillia)、无乳链球菌(Streptococcus agalactiae)、鸟链球菌(Streptococcus avium)、牛链球菌(Streptococcus bovis)、仓鼠链球菌(Streptococcus cricetus)、屎链球菌(Streptococcus faecium)、粪链球菌(Streptococcus faecalis)、野鼠链球菌(Streptococcus ferus)、鹑鸡链球菌(Streptococcus gallinarum)、乳酸链球菌(Streptococcus lactis)、轻型链球菌(Streptococcus mitior)、变形链球菌(Streptococcus mutans)、口腔链球菌(Streptococcus oralis)、肺炎链球菌(Streptococcus pneumoniae)、酿脓链球菌(Streptococcus pyogenes)、大鼠链球菌(Streptococcus rattus)、唾液链球菌(Streptococcus salivarius)、血链球菌(Streptococcus sanguis)、远缘链球菌(Streptococcus sobrinus)、苍白密螺旋体(Treponema pallidum)、齿垢密螺旋体(Treponema denticola)、霍乱弧菌(Vibriocholerae)、逗号弧菌(Vibrio comma)、副溶血弧菌(Vibrio parahaemolyticus)、创伤弧菌(Vibrio vulnificus)、绿色链球菌(Viridans streptococci)、沃尔巴克氏体属(Wolbachia)、小肠结肠炎耶尔森菌(Yersinia enterocolitica)、鼠疫耶尔森菌(Yersiniapestis)和假结核耶尔森菌(Yersinia pseudotuberculosis)。
最常使用的报道物是荧光分子,其在结合时自然发光或被激发发荧光。一些实例包括但不限于天然荧光素,合成德克萨斯红(Texas red)染料、fluoro-max红色和绿色染料、具有铕螯合剂的荧光经羧酸根修饰颗粒(fluorescent carboxylate-modifiedparticle)、具有铕螯合剂的荧光经链霉亲和素包被颗粒(fluorescent streptavidincoated particle)、以及干燥荧光颗粒(dry fluorescent particle)。
替代的报道物包括:
a.化学发光分子和可见光谱发光,其通过可见光谱显微术和成像来检测。
b.放射性核素,其通过α和B颗粒的放射性发射来检测。
c.基于巨磁阻的磁性纳米粒(giant magnetoresistance-based magneticnanoparticle),其使用施加的磁场检测和/或使用电信号通过附着至GMR敏感性表面涂层来检测。
d.磁性纳米粒(magnetic nanoparticle,MNP),包括但不限于:氧化铁MNP、镍铁MNP、钴铁MNP和基于铁、镍、钴和其他铁磁性元素或化合物的其他MNP材料。这样的磁性纳米粒有时涂覆有有机和/或无机材料,例如链霉亲和素、油酸、油胺、聚乙二醇、多糖、聚羟基丁酸酯、生物聚合物、氧化铁等。
e.发荧光或以其他方式的表面等离激元结构,其很容易检测。
附着物和报道物可通过任何合适的手段,例如连接、缀合或通过中间结构,例如珠或氧化铁纳米虫(nanoworm)连接在一起。
附着物、报道物和/或附着物报道物复合物也可与肽连接、与蛋白质缀合、或以其他方式修饰以增强稳定性,例如通过PEG化。
作为一个具体实例,MDC 40可提供有32个探针储器52。每个探针储器包含由荧光报道物和被选择将附着至所附序列No.1至32中之一的抗体附着物形成的探针。每个MDC传感器42是荧光传感器。发光报道物优选地对于每种探针是相同的,使得可使用单一MDC传感器42并将其从一个通道50移动至下一通道。或者,MDC传感器42可与每个通道50对齐。来自靶向序列1至24的探针的结果将表明相关物种的存在。来自靶向序列25至32的探针的结果将表明将是无效的抗生素。
注意,由于已经为每种靶标提供了至少两个序列,所以使用如所述的所有序列No.1至32会导致冗余。虽然并不总是需要有这样的冗余,但是这样做将增强测试的准确性。
ASC结构和操作
ASC60更详细地示于图4中。在芯片一端的入口64通过主通道66连接至在相对端的出口68。沿主通道66的长度提供了多个孔70并且其连接至主通道66。每个孔70预装载有不同的抗微生物剂或抗生素72,除一个或更多个孔74可以留空不装载微生物剂和抗生素以用作对照。优选地,孔70、74还预装载有生长培养基和报道物化合物(例如但不限于刃天青),其将在存在活微生物的情况下发荧光。
待使用的可能的抗微生物剂和抗生素72的一些实例包括但不限于阿米卡星(amikacin)、氨基糖苷类(aminoglycosides)、阿莫西林(amoxycillin)、阿莫西林-克拉维酸(amoxycillin-clavulanate)、氨曲南(aztreonam)、β-内酰胺类(β-lactams)、碳青霉烯类(carbapenems)、羧苄西林(carbenicillin)、头孢曲松(ceffriaxone)、头孢克肟(cefixime)、头孢哌酮(cefoperazone)、头孢噻肟(cefotaxime)、头孢泊肟(cefpodoxime)、头孢丙烯(cefprozil)、头孢他啶(ceftazidime)、头孢呋辛(cefuroxime)、复合阿莫西林-克拉维酸(coamoxiclav)、头孢氨苄、头孢菌素类(cephalosporins)、氯霉素类(chloramphenicols)、环丙沙星(ciprofloxacin)、克林霉素(clindamycin)、黏菌素(colistin)、复方新诺明(cotrimoxazole)、多西环素(doxycycline)、红霉素(erythromycin)、氟氯西林(flucloxacillin)、氟喹诺酮类(fluoroquinolones)、叶酸抑制剂类、氟沙星(foloxacin)、夫西地酸类(fusidic acids)、庆大霉素(gentamicin)、糖肽类(glycopeptides)、卡那霉素(kanamycin)、脂肽类(lipopeptides)、林可酰胺类(lyncosamides)、大环内酯类(macrolides)、美罗培南(meropenem)、甲硝唑类(metronidazoles)、单环β-内酰胺类(monobactams)、莫西沙星(moxifioxacin)、莫匹罗星(mupirocin)、萘啶酸(nalidixic acid)、新霉素(neomycin)、呋喃妥因类(nitrofurantoin)、诺氟沙星(norfloxacin)、氧氟沙星(ofloxacin)、
在使用中,如果孔70、74未预装载有生长培养基和报道化合物,则将尿与生长培养基和报道化合物混合。尿或尿/生长培养基/报道化合物混合物被供应到入口64中,沿主通道66向下流动到孔70、74中,并且任何多余物通过出口68离开。一旦孔70、74被填充,高黏度油(例如但不限于FC-40),被供应到入口64中。由于其黏度,该油将沿主通道66向下流动,但不会有意义地进入孔70、74,从而形成油塞,该油塞有效地将孔70、74中的每一个与其他孔70、74密封开。然后将ASC 60孵育合适的时间,以允许微生物复制。
在孵育之后,ASC传感器62将通过检测报道物化合物来测量每个孔中微生物的量,将所得数据提供给CPU 30,然后该CPU 30将数据存储在海量存储器34中。然后,CPU 30可直接通过确定孔70中是否存在任何微生物,或者间接通过对具有抗微生物剂或抗生素的单元格(cell)70与对照孔74之间的生长率进行比较来评价每种抗微生物剂或抗生素72针对尿样品中微生物的效力水平。CPU 30将分析结果存储在海量存储器34中。通过提供每种抗生素的效力水平,可选择成本最低、谱最窄的抗生素,所述抗生素仍将是有效的。
为了使完成测试的时间最小化,应将孔70、74制成与相关抗生素的区分效力一致的小尺寸,例如,<1ml,并且优选<0.1ml。这样将使在可进行测量之前所需的微生物复制的量最小化。
虽然图4中所示的ASC 60具有40个孔70、74,但是应理解,可提高或降低孔70、74的数目,这取决于待测试的抗微生物剂或抗生素的数目,以及在系统10的具体实施方案的设计中期望的冗余水平。
作为一个具体实例,ASC 60具有44个孔70、74。提供2个对照孔74,并且2个孔70各自预装载有阿米卡星、阿莫西林-克拉维酸(amoxicillin-clavulanate)、氨苄西林(ampicillin)、头孢噻肟、头孢克肟、头孢曲松、头孢氨苄、头孢泊肟、环丙沙星、头孢丙烯、复合阿莫西林-克拉维酸、磷霉素(fosfomycin)、庆大霉素、左氧氟沙星、呋喃妥因、诺氟沙星、氧氟沙星、匹美西林、磺胺甲
两个的孔70、用于对照的74和每种抗生素可用于提供冗余。不必具有这样的冗余,但是这样做可提高测试的准确性。
UC结构和操作
UC80更详细地示于图5中。UC80包含从芯片的顶部延伸至芯片的底部的通道84,如图中所示,其中提供的UC测量部分86以感测尿中的多种化合物。优选地,这些部分与通常用于尿分析的测量匹配,例如,用于测量以下的部分:白细胞、亚硝酸盐、尿胆素原、蛋白质、pH、血红蛋白、比重、酮体(ketones)、胆红素和葡萄糖。为了实现这一目标,每个部分均预涂覆有与市售检测试纸上使用的相同的材料,以使用现今的当前产品进行测量,所述产品例如由Siemens
在使用中,尿在通道84的一端供应,流过通道84并流出另一端。然后,部分86中的相关比色化学物质将与尿反应,改变颜色以指示测量。如果期望的话,可从溶液瓶21中提供缓冲液或类似溶液以流过通道84以除去任何剩余的尿。在该配置中,UC传感器82是比色计,并且被定位为能够读取多个部分86的颜色。当测量完成时,UC传感器82将数据提供给CPU30,CPU 30将数据存储在海量存储器34中。
一旦多种测试完成,则CPU 30生成至少一个报道并将其提供给I/O装置36。优选地,CPU 30生成至少两个报道:第一报道在通过MDC 40和UC 80进行的尿分析和微生物检测完成之后生成,由于它们不需要孵育,并且可快速运行。第二报道在通过ASC 60进行的抗生素敏感性测试完成之后生成,这由于需要孵育期而需要更长时间。
对于本领域技术人员将明显的是,已经参考尿样品描述了该系统来测试UTI,但是可容易地使其适于与其他生物样品一起使用以测试其他问题。例如,可将血液、痰、唾液、黏液或者甚至来自颊或伤口的拭子用作系统的初始生物样品。取决于样品,可能有必要首先向样品添加无菌水或盐水,以使其成为足够的液体以流过所述系统。另外,可能期望更改用于鉴定和定量微生物的特定检测化合物,以使其与可能在所测试生物位置引起感染的微生物相匹配,并且可测试其他特征(例如血液化学)而不是进行尿分析。类似地,所描述的特定微生物以及已为其提供序列的是细菌,但是可使用相同的方法来分析可能的病毒、真菌、朊病毒和其他感染。但是可以看到,总体上,该系统很容易适应广泛多种的测试,有时仅替换不同的芯片即可。
本领域的技术人员将理解,可以用除公开的实施方案之外的实施方案来实践本发明。所公开的实施方案出于举例说明而非限制的目的而提出,并且本发明仅由所附权利要求书限制。
序列表
<110> Urinary Technologies Inc.
<120> 用于微生物物种检测、定量和抗生素敏感性鉴定的系统
<130> UTI001
<160> 32
<170> PatentIn version 3.5
<210> 1
<211> 770
<212> DNA
<213> 大肠杆菌(Escherichia coli)
<400> 1
aaattgaaga gtttgatcat ggctcagatt gaacgctggc ggcaggccta acacatgcaa 60
gtcgaacggt aacaggaaga agcttgctct ttgctgacga gtggcggacg ggtgagtaat 120
gtctgggaaa ctgcctgatg gagggggata actactggaa acggtagcta ataccgcata 180
acgtcgcaag accaaagagg gggaccttcg ggcctcttgc catcggatgt gcccagatgg 240
gattagctag taggtggggt aacggctcac ctaggcgacg atccctagct ggtctgagag 300
gatgaccagc cacactggaa ctgagacacg gtccagactc ctacgggagg cagcagtggg 360
gaatattgca caatgggcgc aagcctgatg cagccatgcc gcgtgtatga agaaggcctt 420
cgggttgtaa agtactttca gcggggagga agggagtaaa gttaatacct ttgctcattg 480
acgttacccg cagaagaagc accggctaac tccgtgccag cagccgcggt aatacggagg 540
gtgcaagcgt taatcggaat tactgggcgt aaagcgcacg caggcggttt gttaagtcag 600
atgtgaaatc cccgggctca acctgggaac tgcatctgat actggcaagc ttgagtctcg 660
tagagggggg tagaattcca ggtgtagcgg tgaaatgcgt agagatctgg aggaataccg 720
gtggcgaagg cggccccctg gacgaagact gacgctcagg tgcgaaagcg 770
<210> 2
<211> 700
<212> DNA
<213> 大肠杆菌
<400> 2
ggttaaaccg cctggctgtg gatgaatgct atttttaaga cttttgccaa actggcggat 60
gtagcgaaac tgcacaaatc cggtgcgaaa agtgaaccaa caacctgcgc cgaagagcag 120
gtaaatcatt accgatcccc aaaggacgct gttaataaag gagaaaaaat ctggcatgca 180
tatccctctt attgccggtc gcgatgactt tcctgtgtaa acgttaccaa ttgtttaaga 240
agtatatacg ctacgaggta cttgataact tctgcgtagc atacatgagg ttttgtataa 300
aaatggcggg cgatatcaac gcagtgtcag aaatccgaaa cagtctcgcc tggcgataac 360
cgtcttgtcg gcggttgcgc tgacgttgcg tcgtgatatc atcagggcag accggttaca 420
tccccctaac aagctgttta aagagaaata ctatcatgac ggacaaattg acctcccttc 480
gtcagtacac caccgtagtg gccgacactg gggacatcgc ggcaatgaag ctgtatcaac 540
cgcaggatgc cacaaccaac ccttctctca ttcttaacgc agcgcagatt ccggaatacc 600
gtaagttgat tgatgatgct gtcgcctggg cgaaacagca gagcaacgat cgcgcgcagc 660
agatcgtgga cgcgaccgac aaactggccg taaatattgg 700
<210> 3
<211> 539
<212> DNA
<213> 肺炎克雷伯菌(Klebsiella pneumoniae)
<400> 3
atcctggctc agattgaacg ctggcggcag gcctaacaca tgcaagtcga gcggtagcac 60
agagagcttg ctctcgggtg acgagcggcg gacgggtgag taatgtctgg gaaactgcct 120
gatggagggg gataactact ggaaacggta gctaataccg cataacgtcg caagaccaaa 180
gtgggggacc ttcgggcctc atgccatcag atgtgcccag atgggattag ctagtaggtg 240
gggtaacggc tcacctaggc gacgatccct agctggtctg agaggatgac cagccacact 300
ggaactgaga cacggtccag actcctacgg gaggcagcag tggggaatat tgcacaatgg 360
gcgcaagcct gatgcagcca tgccgcgtgt gtgaagaagg ccttcgggtt gtaaagcact 420
ttcagcgggg aggaaggcga tgaggttaat aacctcgtcg attgacgtta cccgcagaag 480
aagcaccggc taactccgtg ccagcagccg cggtaatacg gagggtgcaa gcgttaatc 539
<210> 4
<211> 770
<212> DNA
<213> 肺炎克雷伯菌
<220>
<221> misc_feature
<222> (432)..(432)
<223> n是a、c、g或t
<400> 4
ggcaggccta acacatgcaa gtcgagcggt agcacagaga gcttgctctc gggtgacgag 60
cggcggacgg gtgagtaatg tctgggaaac tgcctgatgg agggggataa ctactggaaa 120
cggtagctaa taccgcataa tgtcgcaaga ccaaagtggg ggaccttcgg gcctcatgcc 180
atcagatgtg cccagatggg attagctagt aggtggggta acggctcacc taggcgacga 240
tccctagctg gtctgagagg atgaccagcc acactggaac tgagacacgg tccagactcc 300
tacgggaggc agcagtgggg aatattgcac aatgggcgca agcctgatgc agccatgccg 360
cgtgtgtgaa gaaggccttc gggttgtaaa gcactttcag cggggaggaa ggcgatgagg 420
ttaataacct tntcgattga cgttacccgc agaagaagca ccggctaact ccgtgccagc 480
agccgcggta atacggaggg tgcaagcgtt aatcggaatt actgggcgta aagcgcacgc 540
aggcggtctg tcaagtcgga tgtgaaatcc ccgggctcaa cctgggaact gcattcgaaa 600
ctggcaggct agagtcttgt agaggggggt agaattccag gtgtagcggt gaaatgcgta 660
gagatctgga ggaataccgg tggcgaaggc ggccccctgg acaaagactg acgctcaggt 720
gcgaaagcgt ggggagcaaa caggattaga taccctggta gtccacgccg 770
<210> 5
<211> 617
<212> DNA
<213> 肺炎克雷伯菌
<400> 5
tgaacgctgg cggcaggcct aacacatgca agtcgagcgg tagcacagag agcttgctct 60
cgggtgacga gcggcggacg ggtgagtaat gtctgggaaa ctgcctgatg gagggggata 120
actactggaa acggtagcta ataccgcata aygtcgcaag accaaagtgg gggaccttcg 180
ggcctcatgc catcagatgt gcccagatgg gattagctag taggtggggt aacggctcac 240
ctaggcgacg atccctagct ggtctgagag gatgaccagc cacactggaa ctgagacacg 300
gtccagactc ctacgggagg cagcagtggg gaatattgca caatgggcgc aagcctgatg 360
cagccatgcc gcgtgtgtga agaaggcctt cgggttgtaa agcactttca gcggggagga 420
aggcgatgag gttaataacc tyatcgattg acgttacccg cagaagaagc accggctaac 480
tccgtgccag cagccgcggt aatacggagg gtgcaagcgt taatcggaat tactgggcgt 540
aaagcgcacg caggcggtct gtcaagtcgg atgtgaaatc cccgggctca acctgggaac 600
tgcattcgaa actggca 617
<210> 6
<211> 693
<212> DNA
<213> 肺炎克雷伯菌
<220>
<221> misc_feature
<222> (149)..(149)
<223> n是a、c、g或t
<400> 6
acgctggcgg caggcctaac acatgcaagt cgagcggtag cacagagagc ttgctctcgg 60
gtgacgagcg gcggacgggt gagtaatgtc tgggaaactg cctgatggag ggggataact 120
actggaaacg gtagctaata ccgcataang tcgcaagacc aaagtggggg accttcgggc 180
ctcatgccat cagatgtgcc cagatgggat tagctagtag gtggggtaac ggctcaccta 240
ggcgacgatc cctagctggt ctgagaggat gaccagccac actggaactg agacacggtc 300
cagactccta cgggaggcag cagtggggaa tattgcacaa tgggcgcaag cctgatgcag 360
ccatgccgcg tgtgtgaaga aggccttcgg gttgtaaagc actttcagcg gggaggaagg 420
cgatgaggtt aataacctca tcgattgacg ttacccgcag aagaagcacc ggctaactcc 480
gtgccagcag ccgcggtaat acggagggtg caagcgttaa tcggaattac tgggcgtaaa 540
gcgcacgcag gcggtctgtc aagtcggatg tgaaatcccc gggctcaacc tgggaactgc 600
attcgaaact ggcaggctag agtcttgtag aggggggtag aattccaggt gtagcggtga 660
aatgcgtaga gatctggagg aataccggtg gcg 693
<210> 7
<211> 294
<212> DNA
<213> 腐生葡萄球菌(Staphylococcus saprophyticus)
<400> 7
atgattgcag tacaagattt agatgattta gacgcagatt atatcgctgt tcatactggt 60
tatgacttac aagctgaagg tcaatctcct ttagaaagtt tacgtaaagt taaatctgta 120
attagtaatt ctaaagtagc agtcgcaggt ggtattaaac cagatacaat taaagatatt 180
gttgcagaaa atcctgattt aattattgtt ggtggcggca ttgcaaatgc tgatgaccct 240
gtagaagctg ctaaacaatg tcgtgatatt gtagatgccc atacaaatgc ataa 294
<210> 8
<211> 456
<212> DNA
<213> 腐生葡萄球菌
<400> 8
atggagcata aagagggaaa cttagaaata ataattaacc aattctatga tgctacagcg 60
aatattaata aagcaattac taacatggtt aaagaattgg aaccaggtcg ttacttatct 120
tatgaacaaa tagaaacaat gtattttatt cagcataatg aaaaagtatc gattaacgac 180
ttagcaaata agcaacgtac ttataagaca gctgcatcaa aacgtgttaa gaagttagaa 240
agcaaaggtt atgtgcaacg agtttattcg aatgataaac gtactaaatt attgagtttg 300
acgcataatg gagaacgctt attaaaagaa atgaaaataa acttaacaaa agaaataaag 360
ttacttttgt taagttgttt tgttagagaa gattttgaaa aatttatgta tcagctcatg 420
aattttgaaa agacattttt aaaaaagtac tactag 456
<210> 9
<211> 360
<212> DNA
<213> 肠球菌属(Enterococcus spp)
<400> 9
tacttgtacc actggatgag cagcgaacgg tgagtacgcg tgggatctgc ctttgagcgg 60
ggacacattt ggaacgaatg ctaataccgc ataaaacttt aacacaagtt ttaagtttga 120
agatgcattg catcactcag atgatcccgc gttgtattag ctagtggtga ggtaaagctc 180
accaaggcga tgatacatta gccgacctga gaggtgatcg cacaatggac tgagacacgg 240
cccaactcct acgggggcgc gtagggaatc ttcggcaatg acgaagtctg accgagcacg 300
cccgtgagtg aagaagtttt cggatctaaa ctctgtggta gagaagaaca tcggtgagag 360
<210> 10
<211> 519
<212> DNA
<213> 肠球菌属
<400> 10
attcatgact ggggtgaagt cgtaacaagg taaccgtagg ggaacctgcg gttggatcac 60
ctccttacct gaagatacga aatattgtgt agtgctcaca cagattgtct gataagtgtc 120
acgagcaaat accttatgca ggcttgtagc tcaggtggtt agagcgcacc cctgataagg 180
gtgaagtcgg tggttcgagt ccactcaggc ctaccaactc ccttcctgtg tgaagcggac 240
ggtggtaata aggtattgca gtaaagtcat ggggctatag ctcagctggg agagcgcctg 300
ctttgcacgc aggaggttct gcggttcgat cccgcatagc tccaccatat ttcagaacat 360
actgagaaat cagcatgttg tgaaatattt tgctctttaa caatctggaa caagctgaaa 420
ttcgaaaaca ctcggattgc ttttaataaa gtgatccgag agtctctcaa atgcttacag 480
cacgaagtga aacaccttcg ggttgtgagg ttaatgtga 519
<210> 11
<211> 542
<212> DNA
<213> 奇异变形杆菌(Proteus mirabilis)
<400> 11
ttgaacgctg gcggcaggcc taacacatgc aagtcgagcg gtaacaggag aaagcttgct 60
ttcttgctga cgagcggcgg acgggtgagt aatgtatggg gatctgcccg atagaggggg 120
ataactactg gaaacggtgg ctaataccgc atgatgtcta cggaccaaag caggggctct 180
tcggaccttg cgctatcgga tgaacccata tgggattagc tagtaggtgg ggtaatggct 240
cacctaggcg acgatctcta gctggtctga gaggatgatc agccacactg ggactgagac 300
acggcccaga ctcctacggg aggcagcagt ggggaatatt gcacaatggg cgcaagcctg 360
atgcagccat gccgcgtgta tgaagaaggc cttagggttg taaagtactt tcagcgggga 420
ggaaggtgtt aagattaata ctcttagcaa ttgacgttac ccgcagaaga agcaccggct 480
aactccgtgc cagcagccgc ggtaatacgg agggtgcaag cgttaatcgg aattactggg 540
cg 542
<210> 12
<211> 420
<212> DNA
<213> 奇异变形杆菌
<400> 12
aggatgagtt acctgccact gaatttagta tgtggatacg tcccttgcag gcagaactaa 60
gcgataacac gctggcactg tatgcaccta atcgttttgt gttagattgg gtaagagaaa 120
agtacattaa taatattaat gcattattag tcgacttttg tggttctgat gtcccttcgc 180
tgcgttttga agtgggaaat aaacctgtat cagcacgtac caccgagagt gttcccaaaa 240
ccgtgacaca tcccgcggtt aattccacac cgactaacag ccagccggtg cgtcctagct 300
gggataatca accgcaatcc cagttacctg aacttaatta tcgttctaat gttaatccta 360
agcataaatt tgataatttc gttgaaggta aatcgaacca acttgctaga gcagccgcaa 420
<210> 13
<211> 1120
<212> DNA
<213> 铜绿假单胞菌(Pseudomonas aeruginosa)
<400> 13
atagatacaa ggaagtcatt tttcttttaa aggatagaaa cggttaatgc tcttgggacg 60
gcgcttttct gtgcataact cgatgaagcc cagcaattgc gtgtttctcc ggcaggcaaa 120
aggttgtcga gaaccggtgt cgacgctgtt tccttcctga gcgaagcctg gggatgaacg 180
agatggttat ccacagcggt tttttccaca cggctgtgcg cagggatgta cccccttcaa 240
agcaagggtt atccacaaag tccaggacga ccgtccgtcg gcctgcctgc ttttattaag 300
gtcttgattt gcttggggcc tcagcgcatc ggcatgtgga taagtccggc ccgtccggct 360
acaataggcg cttatttcgt tgtgccgcct ttccaatctt tgggggatat ccgtgtccgt 420
ggaactttgg cagcagtgcg tggatcttct ccgcgatgag ctgccgtccc aacaattcaa 480
cacctggatc cgtcccttgc aggtcgaagc cgaaggcgac gaattgcgtg tgtatgcacc 540
caaccgtttc gtcctcgatt gggtgaacga gaaatacctc ggtcggcttc tggaactgct 600
cggtgaacgc ggcgagggtc agttgcccgc gctttcctta ttaataggca gcaagcgtag 660
ccgtacgccg cgcgccgcca tcgtcccatc gcagacccac gtggctcccc cgcctccggt 720
tgctccgccg ccggcgccag tgcagccggt atcggccgcg cccgtggtag tgccacgtga 780
agagctgccg ccagtgacga cggctcccag cgtgtcgagc gatccctatg agccggaaga 840
acccagcatc gatccgctgg ccgccgccat gccggccgga gcagcgcctg cggtgcgcac 900
cgagcgcaac gtccaggtcg aaggtgcgct gaagcacacc agctatctca accgtacctt 960
caccttcgag aacttcgtcg agggcaagtc caaccagttg gcccgcgccg ccgcctggca 1020
ggtggcggac aacctcaagc acggctacaa cccgctgttc ctctacggtg gcgtcggtct 1080
gggcaagacc cacctgatgc atgcggtggg caaccacctg 1120
<210> 14
<211> 1050
<212> DNA
<213> 铜绿假单胞菌
<400> 14
ttggcgttgg ccgggtcgag cttgcccagt tcgcgggcga tggtgttgac ctgggtgatc 60
gaggcgctga tggacaggaa ggtgtgcggg ttgaccacct tgccggcgcc gcgcgcggcc 120
atgccggtgg cggccagcag cggcaccttg gcgttcgcct cgatcaccgg gatgccgggc 180
ttttcgctgg aggcgatcat gcgctcggcg aaatcgtcgt ggccgacgcc gttgagcacc 240
accacgtcga gcgtgccgat gcgcttgatg tcctcggcgc gcggctcgta ggcatgcggg 300
ttgaaaccgg cggggatcag cggcaccacc tcggccttgt cgccgacgat gttgctcacg 360
tagctgtagt agggatgcag ggtgatgccg atgcgcaggc gcttgccgtc ttcggcctgg 420
gccagcgggg cgagcagggc cagcagcagg gcggccagca gggcacggcc cgggaggagg 480
gcggcgaggc cgcgcggacg ggatgagcga cgggagaaca gcatggaaaa acgccttctg 540
tggagtcgat gtgcgatcaa tggcggtgct gacgggtcac gccggcgtcg aagcggctga 600
ccacctggcg ccagccggcg tcggccaggg ctcgggcgtc gcccggtacg gcgccggcag 660
cggccgtggc gggcttcagc cagacttcgg cggggccgag cagcaggagg aacgagccgg 720
ccacctcggg cttgccgctg acgcccaggt agctcggacg cccggcggtt tcgccgtggc 780
tccagcggtg ctcgccgcgg ctgcttgcgg cgacgtcggc gacgaagggc gggaagccct 840
cggcggccag ttcgtcgacg gagggcgcgg cttcgccgtc gtccaggcgc gcctggatat 900
cttcggcggc gacctgcagg tcggcgtaga tgccctgttc ggcggcattc aggtcgagcc 960
gggcgtccac ctggtgggcg tccagggctt gcgcttcatg ggactgctgg cgcagcccga 1020
ccaccgtggc ggcgagggcc aggatcagca 1050
<210> 15
<211> 774
<212> DNA
<213> 金黄色葡萄球菌(Staphylococcus aureus)
<400> 15
aggatgaacg ctggcggcgt gcctaataca tgcaagtcga gcgaacggac gagaagcttg 60
cttctctgat gttagcggcg gacgggtgag taacacgtgg ataacctacc tataagactg 120
ggataacttc gggaaaccgg agctaatacc ggataatatt ttgaaccgca tggttcaaaa 180
gtgaaagacg gtcttgctgt cacttataga tggatccgcg ctgcattagc tagttggtaa 240
ggtaacggct taccaaggca acgatgcata gccgacctga gagggtgatc ggccacactg 300
gaactgagac acggtccaga ctcctacggg aggcagcagt agggaatctt ccgcaatggg 360
cgaaagcctg acggagcaac gccgcgtgag tgatgaaggt cttcggatcg taaaactctg 420
ttattaggga agaacatatg tgtaagtaac tgtgcacatc ttgacggtac ctaatcagaa 480
agccacggct aactacgtgc cagcagccgc ggtaatacgt aggtggcaag cgttatccgg 540
aattattggg cgtaaagcgc gcgtaggcgg ttttttaagt ctgatgtgaa agcccacggc 600
tcaaccgtgg agggtcattg gaaactggaa aacttgagtg cagaagagga aagtggaatt 660
ccatgtgtag cggtgaaatg cgcagagata tggaggaaca ccagtggcga aggcgacttt 720
ctggtctgta actgacgctg atgtgcgaaa gcgtggggat caaacaggat taga 774
<210> 16
<211> 1555
<212> DNA
<213> 金黄色葡萄球菌
<400> 16
ttttatggag agtttgatcc tggctcagga tgaacgctgg cggcgtgcct aatacatgca 60
agtcgagcga acggacgaga agcttgcttc tctgatgtta gcggcggacg ggtgagtaac 120
acgtggataa cctacctata agactgggat aacttcggga aaccggagct aataccggat 180
aatattttga accgcatggt tcaaaagtga aagacggtct tgctgtcact tatagatgga 240
tccgcgctgc attagctagt tggtaaggta acggcttacc aaggcaacga tacgtagccg 300
acctgagagg gtgatcggcc acactggaac tgagacacgg tccagactcc tacgggaggc 360
agcagtaggg aatcttccgc aatgggcgaa agcctgacgg agcaacgccg cgtgagtgat 420
gaaggtcttc ggatcgtaaa actctgttat tagggaagaa catatgtgta agtaactgtg 480
cacatcttga cggtacctaa tcagaaagcc acggctaact acgtgccagc agccgcggta 540
atacgtaggt ggcaagcgtt atccggaatt attgggcgta aagcgcgcgt aggcggtttt 600
ttaagtctga tgtgaaagcc cacggctcaa ccgtggaggg tcattggaaa ctggaaaact 660
tgagtgcaga agaggaaagt ggaattccat gtgtagcggt gaaatgcgca gagatatgga 720
ggaacaccag tggcgaaggc gactttctgg tctgtaactg acgctgatgt gcgaaagcgt 780
ggggatcaaa caggattaga taccctggta gtccacgccg taaacgatga gtgctaagtg 840
ttagggggtt tccgcccctt agtgctgcag ctaacgcatt aagcactccg cctggggagt 900
acgaccgcaa ggttgaaact caaaggaatt gacggggacc cgcacaagcg gtggagcatg 960
tggtttaatt cgaagcaacg cgaagaacct taccaaatct tgacatcctt tgacaactct 1020
agagatagag ccttcccctt cgggggacaa agtgacaggt ggtgcatggt tgtcgtcagc 1080
tcgtgtcgtg agatgttggg ttaagtcccg caacgagcgc aacccttaag cttagttgcc 1140
atcattaagt tgggcactct aagttgactg ccggtgacaa accggaggaa ggtggggatg 1200
acgtcaaatc atcatgcccc ttatgatttg ggctacacac gtgctacaat ggacaataca 1260
aagggcagcg aaaccgcgag gtcaagcaaa tcccataaag ttgttctcag ttcggattgt 1320
agtctgcaac tcgactacat gaagctggaa tcgctagtaa tcgtagatca gcatgctacg 1380
gtgaatacgt tcccgggtat tgtacacacc gcccgtcaca ccacgagagt ttgtaacacc 1440
cgaagccggt ggagtaacct tttaggagct agccgtcgaa ggtgggacaa atgattgggg 1500
tgaagtcgta acaaggtagc cgtatcggaa ggtgcggctg gatcacctcc tttct 1555
<210> 17
<211> 1491
<212> DNA
<213> 念珠菌属(Candida spp)
<400> 17
gctggaaaaa cgtctccaaa tcacattcct taagcaatta tctcatatcg gaaacagaat 60
atatacaaca acgcctggaa tgcagcataa aacaatttaa atctttccat cccaccagat 120
tcaacctctt gttctctttc aaggataaac ttgttcaacc atccaacaag ataactaact 180
ataaacacaa cttggtgacg cgataacccc ttggctcgtg caatatacga cgacaaatac 240
tgcatcgctt tcaatcgttt ctccaaaatc tccgtagggt taaatgcaac atcaatcaac 300
aagaccaaaa acgaatcagc caactcaggt tggtactggg taacatgaaa caacacaaac 360
tgaatcagct tcgtaaaatg tgttgggagt atatgactct tgaataatga gttaatagta 420
ttgaacaaat taaccccatt gccgttattc aactcttcaa gagtgaatga gtctctggtc 480
gacgtcaaca ataaactaat cacactgtca agcttgttca gcaacgattt gatatctgta 540
gtaggagcag taacccattc ctcgtcgtca ctctcatcat cactctcgtc atcaccactc 600
tcgtcatctc cactctcatc atcactttca tcctcactat cactggccac ttcgtcttct 660
tcatcgttca acaattcttc aatctcttca tcatcaacat catcaagtga tgtctgcaaa 720
tctgtatcca ttttgatcga cgactcaata atcatttgcc agatttcaaa ttgcaactcg 780
ggacagtaac gtattatctt aacaaggttg tgcacataat tagtcaattc actattacta 840
gacgatatat gatgagggaa attcttctgc aacacctgtg gaatcatact aatagaagtg 900
gggatatact tgataatctt gatcaacacc tcgtggtggg tatccacatc ctgtctgtca 960
aactctctaa ccaacttgct cataacttca tgcaaatatt taggtaatgt cgataccaat 1020
gcaactaaaa actgggaata catttccaca aacctgctat acccatcacg atgtttcaca 1080
tccatccatc gatactcaag aatggcaaaa atcatattat gacacgcctt gttatccaac 1140
cgtgacgtat tcgaagccaa tgatctaaga actatggaga aatgacttat gctaatggct 1200
tctttattgc caatggggag acttatctta tcagtgatgg tatttatctg aactggatca 1260
tccttctcca atgcagattt cacatacgac gagtacatct tttctgaaaa ctcatcatca 1320
ctcatcgtat tctgtttctt attcgggagg tcttcagtgg taatacctct ttttcgtgaa 1380
acttcaagag acatcatatg ttatagagat gggggagtaa aagagaagaa ggagaaaaaa 1440
tttttttttt tttttttttt tttttttata cgataaactt tttggagcta c 1491
<210> 18
<211> 1190
<212> DNA
<213> 念珠菌属
<400> 18
aagtttccca tcaagagcac caccgtcgta tccaaaatcc gcaaacatct ccttagtctc 60
ctttggattg gcaatagcca tttgcatatt aacagctaaa tggccccctg cagaatcacc 120
aataagatgt atatccttaa acccagcttt gattaaattg gtataactct caagactctc 180
caccaattgt gctggaaata catgatcaaa aagtgtcaac aggtaatcaa caaccaaaat 240
agacaactca tcagcaaccc ttgcatccaa tgcataatgc aacgcagcaa tagaaaccaa 300
ctgcgattta aacaaattca acaaataccc accaccatga aggtaaacca aaactttacc 360
cgatggattg tcactcttgt ggatccaata cgaacgggca tcaaactttt ccccaaaccc 420
attcaaagat ttaaccatag gatttttggc aacttgctta aacaccttct caactggctc 480
ataaacaaca gccttgacgt tttgcttctt gtaattacca ctcatatgat attctaccga 540
taacaacaca ttcttccaca aagaattgcg aaactcaatg tttgtacgac tatagatggt 600
acccacagtg taatactgca atacagcctt gatcaccaca tacggtaaac taagtaactt 660
ggccaaaaag tcaatgctaa tcatggtttg gtggttgaac aaaaagaaac cttttcttta 720
attggttttt cttttctcgt tgttcaaaaa agaaaaaaaa aaaaaaattt ccacgaggaa 780
cacttttcga gaacaaaaag aaaagcaaaa tgctttttgt acaatcggcc ataaaacgcg 840
tgtacctgaa tcattcaatt agtagtatag ggggagatat aaccaatatg tgtatgcatc 900
acgttttccc agcacgtgcc acgcacacat ttctaatttt tgttggctta tcttatcttc 960
ccggatcccc gcttccgcac tttaatttcg gcaatttctc aattagtcat ttttcacttg 1020
tcgcctaaag tagacaaatt ttttttttct tcctctttcc gcagcgttat aaattcctac 1080
atttcttccc ccagaaaaat caacaaccag ctactcacca aacagctact caccaaacaa 1140
ccaactatca aactaccctc catgacagca tctacaaaag ccaaagactt 1190
<210> 19
<211> 1190
<212> DNA
<213> 白念珠菌(Candida albicans)
<400> 19
ctggttgttg aagaagaaaa gtgatgtttt ctgccatctt ttttttgcca tctttttttt 60
tctgtcagct ttttttctgc catctttttt tgttgacgtg tcccysgctc accgatcacc 120
cacgggtctc ccaccggcac cccgattttc acaactacac aatcaactgc ctccaaaaca 180
gtcaaataac ttacccacta aacttcacaa tagagtcgca ackttaatag ttsttctgac 240
ttgtttagct gtttctaaat ttaacttttg ccatcttaaa ctcaaaaata gacttccctt 300
actcctttca gtaaattcta ttctcctgct tcttctttga agttaattct cttactatac 360
acaattacaa gtctaaaact ctattatttg ctgtgcatca attctttgtt tgaatttccc 420
cattttcacc ccaactagaa ccaactttta gctcagaatt tttgcaaact cgagcccaaa 480
attttcctct cctcggaaat racttattcc cgaaaatggy aaaaaatgtc gtcgcctcaa 540
aaaagatggc aaaaaatccc catacaaaat taaagatgac aaaaaatgtc gcaccaccaa 600
aaaaaagatg gcaaaaatat gtcgcaccac caaaaaaaag tcgcatagtt aaaaaaaaga 660
tgacaaaaaa atgtcgtaaa atcggccaaa actgactaaa acgggctcta gctcaacacc 720
caaaagaggt atcgacttct aaccttgata ggtagaatct acagagtgag agcwatctas 780
tggtgcttta aaaagtrcaa aaagtgggca tctacctact gtttttccgc cttttctgtt 840
ctcccacctt taaccgcgca tatctcggca accagtgctc cgtttgctcy caaacacagc 900
ccatcctatt cctacacccc taaacaacct atataagcct aaaaaaaacc ccaaaaaaac 960
cccaaaaaaa cttggtaaat ttttgtcatc tttttttgac agcttgtaaa atctttgcca 1020
tctttttttt cgcgcctaac aaaatttgtt agcaaaaaaa tttttgccat cttttttccg 1080
cgtttccatt agtatggaac aacacggggg gtccttgtag gttgtgttga tagagcaggt 1140
agagcaggta gagatgtgtt cgtatttttg cgcgtatttg cgcattgtgg 1190
<210> 20
<211> 961
<212> DNA
<213> 白念珠菌
<400> 20
ggtgttgttg cgcatttttt ctgttgacca cggatgtcta acttcaagcg agcacccgag 60
caaagcgaga gtcacacaaa caagtttaga tttagcaata attttctagc caatacaggc 120
cacacacctc gagtgagcag cacttctcaa actgccgcac cacaaccgta cggatgctca 180
cctttttttt ttttttcttt tttggggtgc ttgcaccccc aatagtccgg atgtgtgtga 240
gaatgagttg ggtgtgcgga tgctttagat agttgattga ccgtacggat gtttaaattg 300
ggtagtgtgt tgtttaatta gagattggtt tatttgagag agttgtaatt taggttcgag 360
gagttgttga ggtatagagt atttcaaaat aggaatgttg ttccaaacta ggggggttgt 420
tcaattaggt atgaaagtgg ttcaaatcag tgaataagtt taattttgat atagtttttc 480
aatctcagag tagttccaat ttgaagagag ttctagattg gtgtagttgt tttagagtta 540
gtgttgagag atgtttaaat caagggtagt tccggtacag tgatttgtac aaagtcagag 600
tagttgtaaa cgagaagaga gttttaaact attggggttg ttgttcaatt agaaattggt 660
ttatttgaga gagttgtaat ttgggttcag ggagttgttg aaattccgag tggctcattt 720
cagaagagag ttccaaacta gtgttgttgt tgaattagtt ttaagagtgg tctaaatcaa 780
gggttgagtt cttggttcag ggagttgctc aaacttagag ttgctcattt gtgaagagag 840
ttctaaatag attgtacagt tattcaaatt tatcacccgg ttaatacatt tgttgaaatt 900
agctattcac tcaaccaaaa ataaaatttt ttttttagct ttcaaccaaa aaagcaatag 960
t 961
<210> 21
<211> 1050
<212> DNA
<213> 沙眼衣原体(Chlamydia trachomatis)
<400> 21
tcaaagtttt gtgtttccaa agctttaata ataagagcta caggaaccgg gattgctgaa 60
acacgctcat agatttcagc atcaataatg ggccgttttt ctccatgcat gttggtatcc 120
atatccatga agacccgttt tctcttgaaa aaaccagata gataggttcg tgtgactgta 180
agtttattcc aacctaagcg caagaaactg aaagattcac gagttttagg attaggaagg 240
agtgttatgg tatggtctct catacctaaa caaggatttt cttctttttt acataatctt 300
cctgtaagag gatctccaga aataagggta atctcatcgg aagagaaaat gtctttagga 360
agaagatcag agaaactagc gcctttcgca gtaatgagat attttctttg agaaggagga 420
agagctgatc ctgctaaggc aacgatttgt tgtcctaaaa caaagccttt taaaaataga 480
tgccctatag ataacacctc ttggaagcta atagtaaaca caacatctct ttcgtttcga 540
atacgagcga tgtgatgaat gtgcgttgaa ggagatcctg atgggaaggg gccatctatt 600
gtgtgtaagt gggctatgga tacgagatcc tgggttggga gagttagtct gtctgtagaa 660
atgatatgag gcttcagtcc aaatagtttt gctattgcct gaactcccac aacaaaaatg 720
taataaccat cttcttttga agaaaaaaga ctgagatgtt tttccacaga aggggtgaaa 780
gggcgattat ccgctaagtt aataaaaaca tctcgaggag attgtgttgg aagagctggg 840
atatcaaaag gtctttgttt gaaaagagcg aaaagacctt cctttttaaa aacttctaaa 900
agatcttttt gagtcaaaga ttgaagatca taagaaaact tagtttgaga aataccaggc 960
ttcttcttga tgacgatctc taaaagagca cgtttatttc ctctacggat ctctacaacc 1020
tctccatcaa caggagaggt aataaacact 1050
<210> 22
<211> 700
<212> DNA
<213> 沙眼衣原体
<400> 22
cttgattttg taagagatca tacaggtgga tcgcgcggat caagtaagat tctggagagg 60
aaaaaggagg gaggataggc tcaatgtcat gaggtgtaac gcggaggatg gtagcttctt 120
taggaagtag atgagaggct tgtagtaacg ctaaggatag gtaggattct aaataagatt 180
ctagttcaaa ggcatcttta gggaatccat gagttttctg agttttctta aaggcttctc 240
ccggatgcat agaaaataga tatacccctt ttgaacatac gccatgaatc gtcccttgaa 300
gatgaatatt ttttaggggg agagatagga gtagaggagg gacttgttga tcattaggat 360
ggagtgggtc gtgaaaaagt tgatcggaaa atacaacaga aaagggggtt gtagcaggat 420
ctttctgcaa agtttctaag cgtttactta cagagtcttg tacatcggtg tatagagatt 480
ctgtaaaggc tgaaagataa ttagtagtgg gtagaggagt tttagaagag agaaggtggt 540
tccaaaaagc tttagcatcg tgaggactag gaaagacttt ttctgattta gaaaatagtg 600
ctttgggatg aaaggaaaag ccatgttgcg tgcttaggaa aaagtttaaa ggatctttga 660
aagctttgat tagatgttgt agggataggt gtgaaggtaa 700
<210> 23
<211> 840
<212> DNA
<213> 生殖支原体(Mycoplasma genitalium)
<400> 23
agtaagaatg ttactgctta cacccccttc gccaccccca tcaccgattc taaaagtgat 60
ctggttagtt tggcacaact tgattcttct tatcaaatcg ctgaccaaac catccataac 120
accaacttgt ttgtgttgtt caagtccaag gatgtgaagc ttacatatag ttcaagtggc 180
tcaaataacc agattagttt tgattcaact agtcaaggtg aaaaaccatc ctatgtggtc 240
gagtttacta actctaccaa cattggcatc aagtgaagcg tggtgaaaaa gtatcagtta 300
gatctaccaa atgttaccaa tgagatgaac caagtgttgc aagaattgat cctagaacaa 360
ccccttacca agtatacctt aaacagtagt ttggctaaac aaaagggcaa aagccagata 420
gaggtacatc ttggttcaaa ttcaaatcag tgacaatcga tgcgtaatca acatgaccta 480
aacaacaatc ccagccccaa tgcttcaact gggtttaaac tcactaccgg caacgcatat 540
agaaaattaa atgagtcctg accaatttat caaccaattg atgggaccaa gcagggcaaa 600
gggaaggata gtagtgggtg gagttcaaca gaagcaacaa cggcaaaaaa tgatgcgccc 660
agtgtttctg gaagtggaac atcagacacc gcttcaaaat tcaaaagtta cctcaacacc 720
aagcaagcgt tagagagcat cggcatcttg tttgatgggg atggaatgag gaatgtggtt 780
acccagctct attatgcttc tactagcaag ctagcagtca ccaacaacca cattgtcgtg 840
<210> 24
<211> 1483
<212> DNA
<213> 生殖支原体
<400> 24
agtaagaatg ttactgctta cacccccttc gccaccccca tcaccgattc taaaagtgat 60
ctggttagtt tggcacaact tgattcttct tatcaaatcg ctgaccaaac catccataac 120
accaacttgt ttgtgttgtt caagtccaag gatgtgaagc ttacatatag ttcaagtggc 180
tcaaataacc agattagttt tgattcaact agtcaaggtg aaaaaccctc ctatgtggtc 240
gagtttacta actctaccaa cattggcatc aagtgaacga tggtgaaaaa gtatcagtta 300
gatgtaccga atgtaagtag tgacatgaac caagtgttgc aagaattgat ccttgaacaa 360
cctttgacta agtatacgct taatagtagt ttggccaaag agaagggcaa aagccaaagg 420
gaggtgcatc tgggttcaaa ttcaaatcag tgacaatcga tgcgtaatca acatgaccta 480
aacaacaatc ccagccccaa tgcttcaact ggatttaaac tcactaccgg caacgcatat 540
agaaaactaa gtgagtcctg accaatttat caaccaattg atgggaccaa gcagggcaaa 600
gggaaggata gtagtgggtg gagttcaact gaagcaacaa cggcaaaaaa tgatgcgccc 660
agtgtttctg gagggagatc atcagacaac gcttcaaaat tcaccaagta cctcaacacc 720
aaacaagcgt tagagagcat cggtatcttg tttgatgatc aaaccccaag aaatgttatc 780
acccaactct attatgcttc tactagcaag ctagcagtca ccaacaacca cattgtcgtg 840
atgggtaaca gctttctacc cagcatgtgg tactgggtgg tggagcggag tgcaacaact 900
gattcatcat caaaacccac ctggtttgct aataccaatt tagactgagg ggaagacaaa 960
caaaaacaat ttgttgagaa ccagttgggg tataaggaaa ctaccagtac caattcccac 1020
aacttccatt ccaaatcttt cacccaactt gcatatctga tcagtggcat tgacagtgtc 1080
aatgatcaaa tcatcttcag tggctttaaa gcggggagtg tggggtatga tagtagtagt 1140
agtagtagta gtagtagtag tagtagtagt agtaccaaag accaagcact tgcttgatca 1200
acaacaacta gcttagatag taaaacgggg tataaggatt tggtgaccaa cgacacggga 1260
ttaaatggtc cgatcaatgg gagtttttca atccaagaca ccttctcatt cgttgttcct 1320
tattcgggga atcatacaaa taatggaaca actggaccca ttaaaactgc ttatccagtg 1380
aaaaaagatc aaaaatcaac tgtcaagatc aattctttga ttaacgctac gcccttgaat 1440
agttatgggg atgaggggat tggggtgttt gatgcgttag gtt 1483
<210> 25
<211> 657
<212> DNA
<213> 青霉素组
<400> 25
atggatatta ttgataaagt ttttcagcaa gaggatttct cacgccagga tttgagtgac 60
agccgttttc gccgctgccg cttttatcag tgtgacttca gccactgtca gctgcaggat 120
gccagtttcg aggattgcag tttcattgaa agcggcgccg ttgaagggtg tcacttcagc 180
tatgccgatc tgcgcgatgc cagtttcaag gcctgccgtc tgtctttggc caacttcagc 240
ggtgccaact gctttggcat agagttcagg gagtgcgatc tcaagggcgc caacttttcc 300
cgggcccgct tctacaatca agtcagccat aagatgtact tctgctcggc ttatatctca 360
ggttgcaacc tggcctatac caacttgagt ggccaatgcc tggaaaaatg cgagctgttt 420
gaaaacaact ggagcaatgc caatctcagc ggcgcttcct tgatgggctc agatctcagc 480
cgcggcacct tctcccgcga ctgttggcaa caggtcaatc tgcggggctg tgacctgacc 540
tttgccgatc tggatgggct cgaccccaga cgggtcaacc tcgaaggagt caagatctgt 600
gcctggcaac aggagcaact gctggaaccc ttgggagtaa tagtgctgcc ggattag 657
<210> 26
<211> 861
<212> DNA
<213> 青霉素组
<400> 26
atgagtattc aacattttcg tgtcgccctt attccctttt ttgcggcatt ttgccttcct 60
gtttttgctc acccagaaac gctggtgaaa gtaaaagatg ctgaagatca gttgggtgca 120
cgagtgggtt acatcgaact ggatctcaac agcggtaaga tccttgagag ttttcgcccc 180
gaagaacgtt ttccaatgat gagcactttt aaagttctgc tatgtggtgc ggtattatcc 240
cgtgttgacg ccgggcaaga gcaactcggt cgccgcatac actattctca gaatgacttg 300
gttgagtact caccagtcac agaaaagcat cttacggatg gcatgacagt aagagaatta 360
tgcagtgctg ccataaccat gagtgataac actgctgcca acttacttct gacaacgatc 420
ggaggaccga aggagctaac cgcttttttg cacaacatgg gggatcatgt aactcgcctt 480
gatcgttggg aaccggagct gaatgaagcc ataccaaacg acgagcgtga caccacgatg 540
cctgcagcaa tggcaacaac gttgcgcaaa ctattaactg gcgaactact tactctagct 600
tcccggcaac aattaataga ctggatggag gcggataaag ttgcaggacc acttctgcgc 660
tcggcccttc cggctggctg gtttattgct gataaatctg gagccggtga gcgtgggtct 720
cgcggtatca ttgcagcact ggggccagat ggtaagccct cccgtatcgt agttatctac 780
acgacgggga gtcaggcaac tatggatgaa cgaaatagac agatcgctga gataggtgcc 840
tcactgatta agcattggta a 861
<210> 27
<211> 478
<212> DNA
<213> 环丙沙星
<400> 27
aggtggctca agtatgggca tcattcgcac atgtaggctc ggccctgacc aagtcaaatc 60
catgagggct gctcttgatc ttttcggtcg tgagttcgga gacgtagcca cctactccca 120
acatcagccg gactccgatt acctcgggaa cttgctccgt agtaagacat tcatcgcgct 180
tgctgccttc gaccaagaag cggttgttgg cgctctcgcg gcttacgttc tgccaaagtt 240
tgagcaggcg cgtagtgaga tctatatcta tgatctcgca gtctccggcg agcaccggag 300
gcaaggcatt gccaccgcgc tcatcaatct cctcaagcat gaggccaacg cgcttggtgc 360
ttatgtgatc tacgtgcaag cagattacgg tgacgatccc gcagtggctc tctatacaaa 420
gttgggcata cgggaagaag tgatgcactt tgatatcgac ccaagtaccg ccacctaa 478
<210> 28
<211> 657
<212> DNA
<213> 环丙沙星
<400> 28
atggatatta ttgataaagt ttttcagcaa gaggatttct cacgccagga tttgagtgac 60
agccgttttc gccgctgccg cttttatcag tgtgacttca gccactgtca gctgcaggat 120
gccagtttcg aggattgcag tttcattgaa agcggcgccg ttgaagggtg tcacttcagc 180
tatgccgatc tgcgcgatgc cagtttcaag gcctgccgtc tgtctttggc caacttcagc 240
ggtgccaact gctttggcat agagttcagg gagtgcgatc tcaagggcgc caacttttcc 300
cgggcccgct tctacaatca agtcagccat aagatgtact tctgctcggc ttatatctca 360
ggttgcaacc tggcctatac caacttgagt ggccaatgcc tggaaaaatg cgagctgttt 420
gaaaacaact ggagcaatgc caatctcagc ggcgcttcct tgatgggctc agatctcagc 480
cgcggcacct tctcccgcga ctgttggcaa caggtcaatc tgcggggctg tgacctgacc 540
tttgccgatc tggatgggct cgaccccaga cgggtcaacc tcgaaggagt caagatctgt 600
gcctggcaac aggagcaact gctggaaccc ttgggagtaa tagtgctgcc ggattag 657
<210> 29
<211> 681
<212> DNA
<213> 左氧氟沙星
<400> 29
atgacgccat tactgtataa aaaaacaggt acaaatatgg ctctggcact cgttggcgaa 60
aaaattgaca gaaaccgttt caccggtgag aaaattgaaa atagtacatt ttttaactgt 120
gatttttcag gtgccgacct gagcggcact gaatttatcg gctgtcagtt ctatgatcgt 180
gaaagccaga aagggtgcaa ttttagtcgt gcgatgctga aagatgccat ttttaaaagc 240
tgtgatttat ccatggcgga ttttcgcaat gccagtgcgc tgggcattga aattcgccac 300
tgccgcgcac aaggcgcaga tttccgcggc gcaagcttta tgaatatgat caccacgcgc 360
acctggtttt gtagcgcata tatcacgaat accaatctaa gctacgccaa tttttcgaaa 420
gtcgtgttgg aaaagtgtga gctgtgggaa aaccgttgga tgggtgccca ggtactgggc 480
gcgacgttca gtggttcaga tctctccggc ggcgagtttt cgactttcga ctggcgagca 540
gcgaacttca cacattgcga tctgaccaat tcggagttgg gtgacttaga tattcggggc 600
gttgatttac aaggcgttaa gctggacaac taccaggcgt cgttgctcat ggagcggctt 660
ggcatcgcgg tgattggtta g 681
<210> 30
<211> 600
<212> DNA
<213> 左氧氟沙星
<400> 30
atgagcaacg caaaaacaaa gttaggcatc acaaagtaca gcatcgtgac caactgcaac 60
gattccgtca cactgcgcct catgactgag catgaccttg cgatgctcta tgggtggcta 120
aatcgatctc atatcgtcga gtggtggggc ggagaagaag cacgcccgac acttgctgac 180
gtacaggaac agtacttgcc aagcgtttta gcgcaagagt ccgtcactcc atacattgca 240
atgctgaatg gagagccgat tgggtatgcc cagtcgtacg ttgctcttgg aagcggggac 300
ggacggtggg aagaagaaac cgatccagga gtacgcggaa tagaccagtt actggcgaat 360
gcatcacaac tgggcaaagg cttgggaacc aagctggttc gagctctggt tgagttgctg 420
ttcaatgatc ccgaggtcac caagatccaa acggacccgt cgccgagcaa cttgcgagcg 480
atccgatgct acgagaaagc ggggtttgag aggcaaggta ccgtaaccac cccatatggt 540
ccagccgtgt acatggttca aacacgccag gcattcgagc gaacacgcag tgatgcctaa 600
<210> 31
<211> 1161
<212> DNA
<213> 头孢氨苄
<400> 31
atgcagaaca cattgaagct gttatccgtg attacctgtc tggcagcaac tgtccaaggt 60
gctctggctg ctaatatcga tgagagcaaa attaaagaca ccgttgatga cctgatccag 120
ccgctgatgc agaagaataa tattcccggt atgtcggtcg cagtgaccgt caacggtaaa 180
aactacattt ataactatgg gttagcggca aaacagcctc agcagccggt tacggaaaat 240
acgttatttg aagtgggttc gctgagtaaa acgtttgctg ccaccttggc gtcctatgcg 300
caggtgagcg gtaagctgtc tttggatcaa agcgttagcc attacgttcc agagttgcgt 360
ggcagcagct ttgaccacgt tagcgtactc aatgtgggca cgcatacctc aggcctacag 420
ctatttatgc cggaagatat taaaaatacc acacagctga tggcttatct aaaagcatgg 480
aaacctgccg atgcggctgg aacccatcgc gtttattcca atatcggtac tggtttgcta 540
gggatgattg cggcgaaaag tctgggtgtg agctatgaag atgcgattga gaaaaccctc 600
cttcctcagt taggcatgca tcacagctac ttgaaggttc cggctgacca gatggaaaac 660
tatgcgtggg gctacaacaa gaaagatgag ccagtgcacg ggaatatgga gattttgggt 720
aacgaagctt atggtatcaa aaccacctcc agcgacttgt tacgctacgt gcaagccaat 780
atggggcagt taaagcttga tgctaatgcc aagatgcaac aggctctgac agccacccac 840
accggctatt tcaaatcggg tgagattact caggatctga tgtgggagca gctgccatat 900
ccggtttctc tgccgaattt gctcaccggt aacgatatgg cgatgacgaa aagcgtggct 960
acgccgattg ttccgccgtt accgccacag gaaaatgtgt ggattaataa gaccggatca 1020
actaacggct tcggtgccta tattgcgttt gttcctgcta agaagatggg gatcgtgatg 1080
ctggctaaca aaaactactc aatcgatcag cgagtgacgg tggcgtataa aatcctgagc 1140
tcattggaag ggaataagta g 1161
<210> 32
<211> 1364
<212> DNA
<213> 头孢氨苄
<400> 32
atagtgattt ttgaagctaa taaaaaacac acgtggaatt taggaaaaac ttatatctgc 60
tgctaaattt aaccgtttgt caacacggtg caaatcaaac acactgattg cgtctgacgg 120
gcccggacac ctttttgctt ttaattacgg aactgatttc atgatgaaaa aatcgttatg 180
ctgcgctctg ctgctgacag cctctttctc cacatttgct gccgcaaaaa cagaacaaca 240
gattgccgat atcgttaatc gcaccatcac cccgttgatg caggagcagg ctattccggg 300
tatggccgtt gccgttatct accagggaaa accctattat ttcacctggg gtaaagccga 360
tatcgccaat aaccacccag tcacgcagca aacgctgttt gagctaggat cggttagtaa 420
gacgtttaac ggcgtgttgg gcggcgatgc tatcgcccgc ggcgaaatta agctcagcga 480
tccggtcacg aaatactggc cagaactgac aggcaaacag tggcagggta tccgcctgct 540
gcacttagcc acctatacgg caggcggcct accgctgcag atccccgatg acgttaggga 600
taaagccgca ttactgcatt tttatcaaaa ctggcagccg caatggactc cgggcgctaa 660
gcgactttac gctaactcca gcattggtct gtttggcgcg ctggcggtga aaccctcagg 720
aatgagttac gaagaggcaa tgaccagacg cgtcctgcaa ccattaaaac tggcgcatac 780
ctggattacg gttccgcaga acgaacaaaa agattatgcc tggggctatc gcgaagggaa 840
gcccgtacac gtttctccgg gacaacttga cgccggagcc tatggcgtga aatccagcgt 900
tattgatatg gcccgctggg ttcaggccaa catggatgcc agccacgttc aggagaaaac 960
gctccagcag ggcattgcgc ttgcgcagtc tcgctactgg cgtattggcg atatgtacca 1020
gggattaggc tgggagatgc tgaactggcc gctgaaagct gattcgatca tcaacggcag 1080
cgacagcaaa gtggcattgg cagcgcttcc cgccgttgag gtaaacccgc ccgcccccgc 1140
agtgaaagcc tcatgggtgc ataaaacggg ctccactggt ggatttggca gctacgtagc 1200
cttcgttcca gaaaaaaacc ttggcatcgt gatgctggca aacaaaagct atcctaaccc 1260
tgtccgtgtc gaggcggcct ggcgcattct tgaaaagctg caataactga cgatgaggcc 1320
caggatattg ggcctccttt ctttctcttt ttttcctgtg tcat 1364
- 用于微生物物种检测、定量和抗生素敏感性鉴定的系统
- 获取和制备用于鉴定和抗生素敏感性试验的微生物样品的自动化方法和系统