一种对有误差OCR结果进行信息抽取的方法
文献发布时间:2023-06-19 12:07:15
技术领域
本发明属于图像文本处理技术领域,尤其涉及一种对有误差 OCR结果进行信息抽取的方法。
背景技术
OCR(光学字符识别)技术用于识别图像中包含的文本。目前基于深度神经网络技术的OCR技术已经比较成熟,在很多公开数据集上都能达到很高的精度。随着OCR技术的成熟,有很多基于OCR的技术都能投入实用,比如档案数字化、身份证信息抽取、发票信息抽取等。基于OCR技术的信息抽取,大体包括用图像位置的方法和用文本匹配的方法两种。前者可以精确定位抽取目标,但不适合内容位置不固定的业务场景;后者则依赖OCR的结果准确性,往往用关键字作为锚点来定位信息抽取目标,一旦关键字识别错误,则很难获得结果。
在实际使用场景中,OCR技术要达到在公开数据集上同样的精度还面临一些挑战,面对各种字体、背景、光照、噪声、角度、变形等问题,OCR结果时常会有少量或者大量误差,包括缺字、多字或者错字。
在信息抽取中技术中,一种解决方案是利用手工编写正则表达式,针对预料中可能出错的情况一一作出匹配,但正则依然是一种精确匹配的方案,这种方法无法穷举所有可能出错的情况,同时工作量也较大、编写者容易出错。
另一种方案是利用神经网络,但往往需要大量的标注数据,这些数据在实际业务中很难获得。
发明内容
本发明提供一种对有误差OCR结果进行信息抽取的方法,旨在针对不精确的OCR结果进行信息抽取的方法,可以配合OCR技术对各种证件、票据或者其他图像文本进行信息抽取,而且兼容适配一定范围内的OCR识别误差。
本发明是这样实现的,一种对有误差OCR结果进行信息抽取的方法,包括以下步骤:
S1、通过OCR技术识别目标图片中的文本,获得OCR识别结果;OCR识别结果由一系列文字块构成,每个文字块包括文本框坐标与文字块中的文本;
S2、对OCR识别结果作后处理,合并每一行的文本;获得合并后的若干行文本字符串;
S3、根据业务目标,编写序列字符模板;
S4、对每一行文本字符串进行序列对齐匹配,计算匹配得分;
S5、选择匹配得分最高的行,并且根据序列对齐的结果,抽取目标信息。
优选的,在步骤S2中,所述合并每一行的文本,具体包括:
1)对OCR的结果按照每个识别出的文字块中心点纵坐标排序;
2)合并同一行结果,把同样纵坐标在差别在一定范围内的文字块归为同一行;
3)对获得的每一行OCR结果,按照文字块中心点的横坐标进行排序;合并排序后的文本。
优选的,在步骤S3中,所述字符模板的具体定义如下:
1)序列字符模板由一个序列的字符模板构成,字符模板分为两类,分别用Pc(sc,max,w)与Pr(sr,max,w)表示;
2)Pc(sc,l,w)表示精确匹配字符,其中sc表示需要匹配的字符, l表示最多匹配次数,w表示该模板得分的权重;
3)Pr(sr,l,w)表示匹配某个字符集,其中sr是用来表示字符集的正则表达式,l表示最多匹配次数,w表示该模板得分的权重。
优选的,步骤S4中,所述匹配采用修改过的全局序列对齐算法,所述全局序列对齐算法,包括以下步骤:
1)用一个序列的字符模板与目标字符串作匹配,而不是在两个字符串之间匹配,用来记算得分的m x n矩阵,m=目标字符串长度 +1,n=序列模板长度+1;除初始行外,每一行代表一个目标字符;除初始列外,每一列代表一个字符模板;
2)每一列从上往下的方向表示目标字符的插入,除了初始列之外,插入的得分根据所在列的字符模板决定,如果目标字符和字符模板相匹配,且连续插入的数量少于模板定义的最多匹配次数l,则得分为0分,否则得分为-0.5分,并乘上模板定义的权重w;
3)每一行从左往右的方向表示字符模板的删除,得分记为0分;
4)从左上往右下的方向表示目标字符与字符模板的匹配,匹配失败记为0分,匹配成功记为1分,并乘上模板定义的权重w;
5)初始行的得分是全0,初始列的得分是-0.5乘以行号(从0 开始);
6)计算对齐路径时,如果得分相同,优先选择插入、其次删除、最后匹配;
7)序列匹配的分为总分除以权重之和。
优选的,还包括:
建立一个形近字表,表的每一行表示一个字符以及其形近字组,每个形近字分别记有一个形近得分;在目标字符c与精确字符模板 Pc(sc,l,w)匹配时,如果c与sc不同,但与sc的某个形近字相同,则匹配不算失败,得分记为形近字表中记录的形近得分,乘以字符模板定义的权重w。
优选的,所述形近字表的生成方法包括以下步骤:
1)训练一个常见的神经网络文字识别模型;
2)输入单字符的图片;
3)提取出模型最后一层输出的softmax之后的结果数组;取结果数组的前10个最大值对应的字符,去除其中和输入字符相同的字符,即为输入字符的形近字组;形近得分为该字符对应的softmax值除以softmax结果数组中的最大值;
4)对每一个字符,取多种字体并加入噪声,生成多个形近字组,并合并这些组,形近字表中的相同字符的形近得分取其平均值,并删除得分在阈值之下的形近字;
5)所有字符及其形近字组构成了要建立的形近字表。
与现有技术相比,本发明的有益效果是:
1、本发明提供了一种不需要标注数据的方法对文本进行模糊匹配。
2、本发明提供的方法,相比常见的最大公共子序列算法,可以对字符范围而不仅仅是字符进行匹配,可以对不同位置的缺字、多字、错字以及错字的不同赋予不同的惩罚权重,大幅提高匹配效果。
3、本发明还提供了一种生成形近字表的方式,利用形近字表,减少相近的错字惩罚,从而提高模糊匹配的最终效果。
附图说明
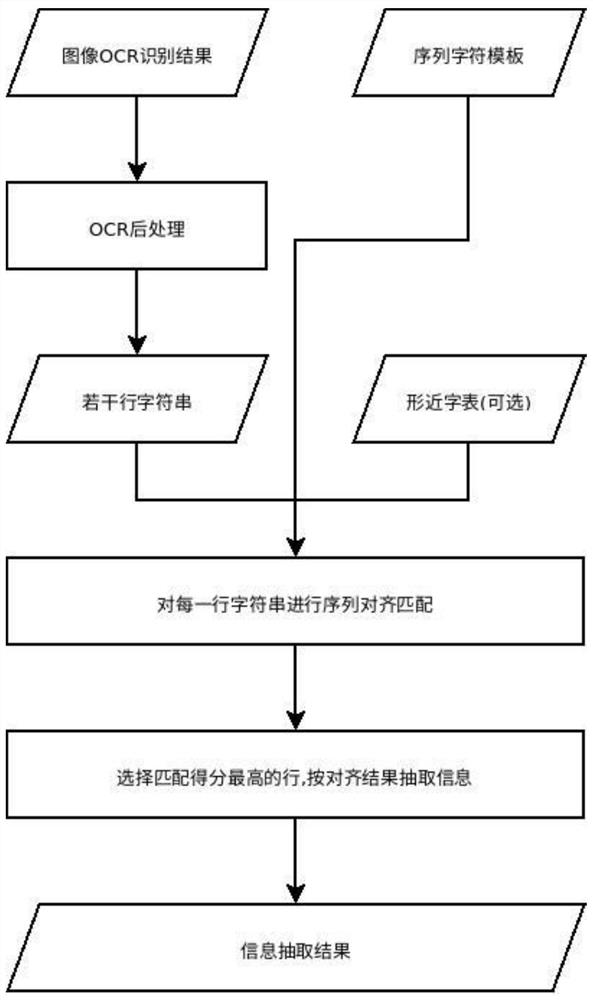
图1为本发明的一种对有误差OCR结果进行信息抽取的方法的流程示意图。
图2为本发明的序列对齐匹配的详细流程示意图。
图3为本发明的生成形近字表的流程示意图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
本发明提供一种技术方案:一种对有误差OCR结果进行信息抽取的方法,包括以下步骤:
S1、通过OCR技术识别目标图片中的文本,获得OCR识别结果;OCR识别结果由一系列文字块构成,每个文字块包括文本框坐标与文字块中的文本。
S2、对OCR识别结果作后处理,合并每一行的文本;获得合并后的若干行文本字符串。
其中,合并每一行的文本,具体包括:
1)对OCR的结果按照每个识别出的文字块中心点纵坐标排序;
2)合并同一行结果,把同样纵坐标在差别在一定范围内的文字块归为同一行;
3)对获得的每一行OCR结果,按照文字块中心点的横坐标进行排序;合并排序后的文本。
S3、根据业务目标,编写序列字符模板。
其中,字符模板的具体定义如下:
1)序列字符模板由一个序列的字符模板构成,字符模板分为两类,分别用Pc(sc,max,w)与Pr(sr,max,w)表示;
2)Pc(sc,l,w)表示精确匹配字符,其中sc表示需要匹配的字符, l表示最多匹配次数,w表示该模板得分的权重;
3)Pr(sr,l,w)表示匹配某个字符集,其中sr是用来表示字符集的正则表达式,l表示最多匹配次数,w表示该模板得分的权重。
另外,针对OCR技术一般容易把形近字识别错,还可以建立一个形近字表,表的每一行表示一个字符以及其形近字组,每个形近字分别记有一个形近得分。在目标字符c与精确字符模板Pc(sc,l,w) 匹配时,如果c与sc不同,但与sc的某个形近字相同,则匹配不算失败,得分记为形近字表中记录的形近得分,乘以字符模板定义的权重w。
其中,本发明还提供了一种基于神经网络的方法生成形近字表,形近字表的生成方法包括以下步骤:
1)训练一个常见的神经网络文字识别模型。
2)输入单字符的图片。
3)提取出模型最后一层输出的softmax之后的结果数组。取结果数组的前10个最大值对应的字符,去除其中和输入字符相同的字符,即为输入字符的形近字组。形近得分为该字符对应的softmax值除以softmax结果数组中的最大值。
4)对每一个字符,取多种字体并加入噪声,生成多个形近字组,并合并这些组,形近字表中的相同字符的形近得分取其平均值,并删除得分在阈值之下的形近字。
5)所有字符及其形近字组构成了要建立的形近字表。
S4、对每一行文本字符串进行序列对齐匹配,计算匹配得分。
其中,匹配采用修改过的全局序列对齐算法,全局序列对齐算法是为Needleman-Wunsch算法的一种动态规划算法,本发明对其作出改动以及具体的得分函数设计,包括以下步骤:
1)用一个序列的字符模板与目标字符串作匹配,而不是在两个字符串之间匹配,用来记算得分的m x n矩阵,m=目标字符串长度 +1,n=序列模板长度+1。除初始行外,每一行代表一个目标字符;除初始列外,每一列代表一个字符模板;
2)每一列从上往下的方向表示目标字符的插入,除了初始列之外,插入的得分根据所在列的字符模板决定,如果目标字符和字符模板相匹配,且连续插入的数量少于模板定义的最多匹配次数l,则得分为0分,否则得分为-0.5分,并乘上模板定义的权重w;
3)每一行从左往右的方向表示字符模板的删除,得分记为0分;
4)从左上往右下的方向表示目标字符与字符模板的匹配,匹配失败记为0分,匹配成功记为1分,并乘上模板定义的权重w;
5)初始行的得分是全0,初始列的得分是-0.5乘以行号(从0 开始;
6)计算对齐路径时,如果得分相同,优先选择插入、其次删除、最后匹配;
7)序列匹配的分为总分除以权重之和。
S5、选择匹配得分最高的行,并且根据序列对齐的结果,抽取目标信息。
实施例1
本实施例基于上述的一种对有误差OCR结果进行信息抽取的方法,以抽取身份证上的性别与民族为例,提供一种具体实施的技术方案。
如图1所示,本发明提供的方法的主要步骤包括:获取图像OCR 识别结果;对OCR结果进行后处理;获得OCR后处理后的若干行文本字符串;输入编写好的序列字符模板;输入预生成的形近字表;对每一行文本字符串进行序列对齐匹配;选择匹配得分最高的行,抽取信息。具体过程如下:
1、通过OCR技术识别目标图片中的文本,获得OCR结果。
2、对OCR识别结果作后处理,合并每一行的文本,具体方法如下:
1)对OCR的结果按照每个识别出的文字块中心点纵坐标排序。
2)合并同一行结果,把同样纵坐标在差别在一定范围内的文字块归为同一行。
3)对获得的每一行OCR结果,按照文字块中心点的横坐标进行排序。合并排序后的文本。
利用形近字库,可以更有效地利用OCR识别中的错字提供的信息,提高信息抽取的精度。
3、获得合并后的若干行文本字符串。
本实施例中,给出获得的文本字符串样例(样例中包含了OCR 识别错误,性别之间多了一个1字,以及缺少民族的民字,族字误识别为旅字):
行1:姓名张三
行2:性1别男旅朝鲜
行3:出生1999年1月1日
行4:地址xx市xx区xx路xxxx号
行5:公民身份号码xxxxxxxxxxxxx
4、根据业务目标,编写序列字符模板,模板具体定义如下:
1)序列字符模板由一个序列的字符模板构成,字符模板分为两类,分别用Pc(sc,max,w)与Pr(sr,max,w)表示。
2)Pc(sc,l,w)表示精确匹配字符,其中sc表示需要匹配的字符, l表示最多匹配次数,w表示该模板得分的权重。
3)Pr(sr,l,w)表示匹配某个字符集,其中sr是用来表示字符集的正则表达式,l表示最多匹配次数,w表示该模板得分的权重。
本实施例中,抽取目标为性别和名族,编写的序列字符模板为: [Pc(性,1,1),Pc(别,1,1),Pr(男| 女,1,1),Pc(民,1,1),Pc(族,1,1),Pc(汉,1,1),Pr(.,10,0)]
5、输入预生成的形近字表。在本实施例中,形近字表为:
性:牲雌姓
别:剐剁郧郢累
民:良呆氏
族:旅炭恢挨
所有形近字得分简单记为0.5分。
6、对每一行文本字符串进行序列对齐匹配,计算匹配得分。匹配采用修改过的全局序列对齐算法,所述全局序列对齐算法,即名为 Needleman-Wunsch算法的一种动态规划算法,本发明对其作出改动以及具体的得分函数设计,包括:
1)用一个序列的字符模板与目标字符串作匹配,而不是在两个字符串之间匹配,用来记算得分的m x n矩阵,m=目标字符串长度 +1,n=序列模板长度+1。除初始行外,每一行代表一个目标字符;除初始列外,每一列代表一个字符模板。
2)每一列从上往下的方向表示目标字符的插入,除了初始列之外,插入的得分根据所在列的字符模板决定,如果目标字符和字符模板相匹配,且连续插入的数量少于模板定义的最多匹配次数l,则得分为0分,否则得分为-0.5分,并乘上模板定义的权重w。
3)每一行从左往右的方向表示字符模板的删除,得分记为0分。
4)从左上往右下的方向表示目标字符与字符模板的匹配,匹配失败记为0分,匹配成功记为1分,并乘上模板定义的权重w。
5)初始行的得分是全0,初始列的得分是-0.5乘以行号(从0 开始)。
6)计算对齐路径时,如果得分相同,优先选择插入、其次删除、最后匹配。
7)序列匹配得分为总分除以权重之和。
具体步骤如图2所示,包括:
1)输入序列字符模板与目标字符串。
2)建立初始得分矩阵。
3)从左到右,从上倒下依次计算矩阵单元中的最优得分。
4)从右下到左上回溯最优的分路径。
5)获得对齐结果。
本实施例中,序例字符模板与行2目标字符串对齐结果及匹配得分如下:
Pc(性,1,1),性,匹配,记1分。
Pc(性,1,1),1,插入,记负0.5分。
Pc(别,1,1),别,匹配,记1分。
Pr(/男|女/,1,1),男,匹配,记1分。
Pc(民,1,1),None,删除,记0分。
Pc(族,1,1),旅,匹配形近字,记0.5分。
Pc(汉,1,1),汉,None,删除,记0分。
Pr(/./,10,0),朝,匹配,记0分。
Pr(/./,10,0),鲜,插入,记0分。
序列匹配得分为总分4分除以权重之和6约为0.67分。
本实施例中,序例字符模板与其他行匹配得分皆是负分。
7、选择匹配得分最高的行,并且根据序列对齐的结果,抽取目标信息。
本实施例中,匹配得分最高为行2,抽取的目标信息为:
性别=男
民族=朝鲜
8、额外地,针对形近字表的建立,本发明还提供了一种基于神经网络的方法生成形近字表,如图3所示,包括以下步骤:
1)利用文本识别训练数据,训练一个神经网络文字识别模型,在本实施例中模型为crnn-ctc。
2)输入多张单字符的图片。在本实施例中,输入字符包括性、别、民、族四个字。
3)提取出模型最后一层输出的softmax之后的结果数组。取结果数组的前10个最大值对应的字符,去除其中和输入字符相同的字符,即为输入字符的形近字组。形近得分为该字符对应的softmax值除以softmax结果数组中的最大值。
4)对每一个字符,取多种字体并加入噪声,生成多个形近字组,并合并这些组,形近字表中的相同字符的形近得分取其平均值,并删除得分在阈值之下的形近字。
5)获得形近字表。
在本实施例中,获得的形近字表为:
性:牲雌姓
别:剐剁郧郢累
民:良呆氏
族:旅炭恢挨
所有形近字得分简单记为0.5分。
综上所述,本发明提供一种不需要标注数据的方法对文本进行模糊匹配,从而可以针对识别有误的OCR结果进行信息抽取。本发明提供的模糊匹配方法,相比常见的最大公共子序列算法,可以对字符范围而不仅仅是字符进行匹配,可以对不同位置的缺字、多字、错字以及错字的不同赋予不同的惩罚权重,大幅提高匹配效果。
本发明还提供了一种生成形近字表的方法,利用形近字表,减少相近的错字惩罚,从而提高模糊匹配的最终效果。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 一种对有误差OCR结果进行信息抽取的方法
- 一种应用于医疗领域文档的OCR和信息抽取方法