基于自然语音处理的正则意图识别方法
文献发布时间:2023-06-19 12:07:15
技术领域
本发明涉及语言意图识别技术领域,具体为基于自然语音处理的正则意图识别方法。
背景技术
自然语言处理(NLP)是计算机科学领域与人工智能领域中的一个重要方向,它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法,自然语言处理是一门融语言学、计算机科学、数学于一体的科学,因此,这一领域的研究将涉及自然语言,即人们日常使用的语言,所以它与语言学的研究有着密切的联系,但又有重要的区别,自然语言处理并不是一般地研究自然语言,而在于研制能有效地实现自然语言通信的计算机系统,特别是其中的软件系统,因而它是计算机科学的一部分,而在自然语言处理的基础上,通常需要对用户输入的语言信息进行意图识别,以便更好的更准确的理解用户通过语言信息所要表达的意图信息;
目前在语言处理过程中,一般通过建立正则表达式的形式来判断用户的意图,而此方式来获取用户意图时需要事先建立数据量庞大的正则库,并且还需要对用户输入的语言信息进行一些列复杂的处理之后才能够建立正则表达式,以此不仅造成了语言信息处理困难,而且使得用户意图的识别过程复杂繁琐。
发明内容
本发明提供基于自然语音处理的正则意图识别方法,可以有效解决上述背景技术中提出目前意图识别方法造成了语言信息处理困难,而且使得用户意图的识别过程复杂繁琐的问题。
为实现上述目的,本发明提供如下技术方案:基于自然语音处理的正则意图识别方法,包括如下步骤:
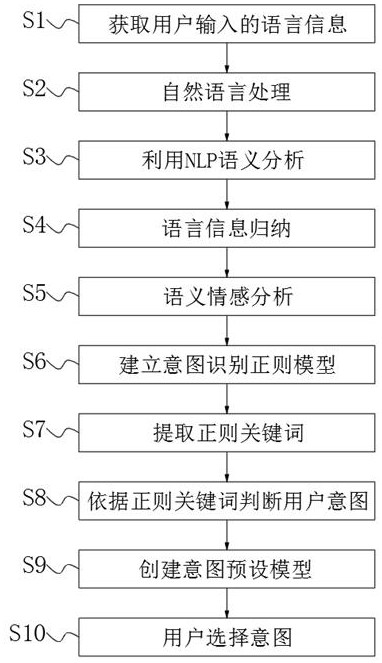
S1、获取用户输入的语言信息;
S2、自然语言处理;
S3、利用NLP语义分析;
S4、语言信息归纳;
S5、语义情感分析;
S6、建立意图识别正则模型;
S7、提取正则关键词;
S8、依据正则关键词判断用户意图;
S9、创建意图预设模型;
S10、用户选择意图。
根据上述技术方案,所述S1中,通过计算机语言输入模块来获取用户输入的语言信息;
所述S2中,在获取用户语言信息后,通过计算机来对用户的语言信息进行处理,具体包括对获取语言信息进行语义分析处理和歧义消除处理;
所述语义分析是指对获取的语言信息进行浅层语义分析和深层语义分析处理,并将语言信息所表达的语义信息进行推导翻译;
所述歧义消除是指在对语义分析的基础上判断该语言信息所要表达的语义,结合该语言信息的上下文内容来确认其表示的含义,并抽取该语言信息中的多义词,最后根据表达的含义来剔除多义词所翻译出有歧义的语义信息。
根据上述技术方案,所述S3中,语言信息经过分析和消歧处理后,利用NLP语义分析技术来对该语言信息进行进一步的分析理解处理,以进一步确定该语言信息在语言内容内所正确表达的语义。
根据上述技术方案,所述S4中,语言信息经过NLP语义分析技术进行语义分析后,对该语言信息进行进一步的归纳处理,使该语言信息能够对应分入到计算机系统内不同的归纳组别内;
归纳处理具体包括如下步骤:
A、建立归纳数据库;
B、确定归纳的组别类型;
C、深度分析语言信息的语义;
D、标记并代入组别。
根据上述技术方案,所述A中,在计算机系统内建立用于收纳语言信息的归纳数据库;
所述B中,在归纳数据库中建立用以归纳分别收集的组别文件夹,组别文件夹具体包括时间文件夹、地点文件夹、人物文件夹、事件文件夹、原因文件夹、结果文件夹和数字文件夹。
根据上述技术方案,所述C中,在组别文件夹建立后,依据组别文件夹的组别类型来对语言信息进行进一步的深度分析,并在语言信息内抽取与组别文件夹组别类型对应的关键词信息;
所述D中,将对应的语言语义信息导入到对应的组别文件夹内,来对语言语义信息进行分开分类收集,并通过抽取的关键词信息来对该语言信息进行标记。
根据上述技术方案,所述S5中,经过NLP语义分析技术进行语义分析后,对语言信息的语义所表达的情感信息进行进一步的细化分析,主要依据语言语义信息中提出的情感信息词来判断该语言信息所表达的情感信息,具体将该语言语义信息分为喜、怒、哀、乐、愁、恐和恨七类。
根据上述技术方案,所述S6中,在语言的语义信息经过处理后,在计算机系统内建立意图识别正则模型,意图识别正则模型主要基于三类正则关键词来描述用户输入的语言信息所要表达出的意图;
三类正则关键词主要包括基于语言信息内存在关键词“一定不是”的判断正则,语言信息内存在关键词“一定是”的判断正则,语言信息内存在关键词“可能是”的判断正则;
所述S7中,根据NLP语义分析技术分析后语言信息所表达的正确语义,来提取该语义信息中的正则关键词,正则关键词包括“一定不是”、“一定是”和“可能是”三种。
根据上述技术方案,所述S8中,在语言信息中的正则关键词提取后,依据提取的正则关键词信息来判断用户输入语言信息所要表达的意图,该判断结果具体包括如下类型:
第一种:语言信息中存在正则关键词“一定不是”时,则表明该用户输入的语言信息中一定不具有某种意图;
第二种,语言信息中存在正则关键词“一定是”时,则表明该用户输入的语言信息中可能具有某种意图;
第三种,语言信息中存在正则关键词“可能是”时,则表明该用户输入的语言信息中存在两种意图情况,一是该语言信息可能具有某种意图,二是该语言信息可能不具有某种意图。
根据上述技术方案,所述S9中,用户输入的语言信息存在正则关键词“可能是”时,并出现两种可能出现意图的情况时,在计算机系统内创建意图预设模型,预设模型包含该语言信息具有某种意图和该语言信息不具有某种意图两种类型;
所述S10中,在意图预设模型创建后,使用户依据语言信息来自主选择所要表达的意图。
与现有技术相比,本发明的有益效果:
1、本发明在获取用户意图时主要通过建立意图识别正则模型的方式来方便快速的判断用户的意图,且在判断用户意图时只需通过用户语言信息内存在的正则关键词即可方便快速便捷的用户意图进行判断,同时本发明能够对语言信息内不同正则关键词所代表的意图进行分类,以此方便进一步的通过正则关键词来获取用户的意图;
另外,本发明意图识别的方法相对于传统的识别方法来说,意图识别正则模型的建立更加便捷,同时对语言信息识别判断时只需要依据语言信息内的正则关键词信息即可,进而使得整体判断识别过程能够更加的便捷,同时意图识别结果也更加方便得出,并且在意图结果判断时,当存在不同的判断结果时能够通过意图预设模型的创建来方便用户依据语言信息来自主选择所要表达的意图,进而使得意图的识别判断的结果更加准确。
2、本发明在获取用户的语言信息后,通过对语言信息进行语义分析处理和歧义消除处理,使得语言信息在处理后用户所表达的语言信息的语义更加清楚明显,且能够防止语言信息的语义产生歧义,造成后续意图识别结果的不准确,且在语言信息经过分析和消歧处理后,能够利用NLP语义分析技术来对该语言信息进行进一步的分析理解处理,以方便进一步确定该语言信息在语言内容内所正确表达的语义。
3、通过对语言信息进行归纳处理,使得该语言信息能够对应的分入到计算机系统内不同的归纳组别内,同时通过对语言信息进行归纳处理,使得该语言信息在计算机系统内能够得到更好的分类,进而使得后续对语言信息进行校验和查找时变得更加方便,同时通过对语言信息进行分类存储,使得后续在遇到相似类型的语言信息时,计算机系统能够快速的将其内部存储的原始语言信息与输入的新的语言信息进行对比识别,以此使得后续对语言信息判断识别时能够具有更加快速的响应,进而提高了计算机系统对语言信息意图识别的自学习能力
4、通过对语言信息的情感信息进行获取和细化分析,使得语言信息的语义能够依照其表达的情感来进行进一步的显示含义,进而使得后续在对语言意图识别时能够通过语言信息所表达的情感信息来对其真实的意图起到辅助识别的作用,进而使得语言信息的意图识别能够在语言基础层面的语义中进行识别,同时也能结合语言信息深层次表现的情感方便来进行辅助识别,以此来进一步确保语言信息意图识别的准确性。
综合所述,本发明通过对语言信息进行分析、消歧和归纳处理方便将语音信息进行更好的深度解析和存储,同时通过对语言信息进行关键词提取,并通过关键词判断用户意图,降低了语言信息处理时的数据量,同时简化了判断模型,能够最大深度上降低了语言信息意图的识别判断的时间,方便更好的对用户意图进行响应。
附图说明
附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。
在附图中:
图1是本发明识别方法的步骤流程图;
图2是本发明归纳处理方法的步骤流程图。
具体实施方式
以下结合附图对本发明的优选实施例进行说明,应当理解,此处所描述的优选实施例仅用于说明和解释本发明,并不用于限定本发明。
实施例1:如图1-2所示,本发明提供一种技术方案,基于自然语音处理的正则意图识别方法,包括如下步骤:
S1、获取用户输入的语言信息;
S2、自然语言处理;
S3、利用NLP语义分析;
S4、语言信息归纳;
S5、语义情感分析;
S6、建立意图识别正则模型;
S7、提取正则关键词;
S8、依据正则关键词判断用户意图;
S9、创建意图预设模型;
S10、用户选择意图。
基于上述技术方案,S1中,通过计算机语言输入模块来获取用户输入的语言信息;
S2中,在获取用户语言信息后,通过计算机来对用户的语言信息进行处理,具体包括对获取语言信息进行语义分析处理和歧义消除处理;
语义分析是指对获取的语言信息进行浅层语义分析和深层语义分析处理,并将语言信息所表达的语义信息进行推导翻译;
歧义消除是指在对语义分析的基础上判断该语言信息所要表达的语义,结合该语言信息的上下文内容来确认其表示的含义,并抽取该语言信息中的多义词,最后根据表达的含义来剔除多义词所翻译出有歧义的语义信息。
基于上述技术方案,S3中,语言信息经过分析和消歧处理后,利用NLP语义分析技术来对该语言信息进行进一步的分析理解处理,以进一步确定该语言信息在语言内容内所正确表达的语义。
基于上述技术方案,S4中,语言信息经过NLP语义分析技术进行语义分析后,对该语言信息进行进一步的归纳处理,使该语言信息能够对应分入到计算机系统内不同的归纳组别内;
归纳处理具体包括如下步骤:
A、建立归纳数据库;
B、确定归纳的组别类型;
C、深度分析语言信息的语义;
D、标记并代入组别。
基于上述技术方案,A中,在计算机系统内建立用于收纳语言信息的归纳数据库;
B中,在归纳数据库中建立用以归纳分别收集的组别文件夹,组别文件夹具体包括时间文件夹、地点文件夹、人物文件夹、事件文件夹、原因文件夹、结果文件夹和数字文件夹。
基于上述技术方案,C中,在组别文件夹建立后,依据组别文件夹的组别类型来对语言信息进行进一步的深度分析,并在语言信息内抽取与组别文件夹组别类型对应的关键词信息;
D中,将对应的语言语义信息导入到对应的组别文件夹内,来对语言语义信息进行分开分类收集,并通过抽取的关键词信息来对该语言信息进行标记。
基于上述技术方案,S5中,经过NLP语义分析技术进行语义分析后,对语言信息的语义所表达的情感信息进行进一步的细化分析,主要依据语言语义信息中提出的情感信息词来判断该语言信息所表达的情感信息,具体将该语言语义信息分为喜、怒、哀、乐、愁、恐和恨七类。
基于上述技术方案,S6中,在语言的语义信息经过处理后,在计算机系统内建立意图识别正则模型,意图识别正则模型主要基于三类正则关键词来描述用户输入的语言信息所要表达出的意图;
三类正则关键词主要包括基于语言信息内存在关键词“一定不是”的判断正则,语言信息内存在关键词“一定是”的判断正则,语言信息内存在关键词“可能是”的判断正则;
S7中,根据NLP语义分析技术分析后语言信息所表达的正确语义,来提取该语义信息中的正则关键词,正则关键词包括“一定不是”、“一定是”和“可能是”三种。
基于上述技术方案,S8中,在语言信息中的正则关键词提取后,依据提取的正则关键词信息来判断用户输入语言信息所要表达的意图,语言信息中存在正则关键词“一定不是”时,则表明该用户输入的语言信息中一定不具有某种意图。
实施例2:如图1-2所示,本发明提供一种技术方案,基于自然语音处理的正则意图识别方法,包括如下步骤:
S1、获取用户输入的语言信息;
S2、自然语言处理;
S3、利用NLP语义分析;
S4、语言信息归纳;
S5、语义情感分析;
S6、建立意图识别正则模型;
S7、提取正则关键词;
S8、依据正则关键词判断用户意图;
S9、创建意图预设模型;
S10、用户选择意图。
基于上述技术方案,S1中,通过计算机语言输入模块来获取用户输入的语言信息;
S2中,在获取用户语言信息后,通过计算机来对用户的语言信息进行处理,具体包括对获取语言信息进行语义分析处理和歧义消除处理;
语义分析是指对获取的语言信息进行浅层语义分析和深层语义分析处理,并将语言信息所表达的语义信息进行推导翻译;
歧义消除是指在对语义分析的基础上判断该语言信息所要表达的语义,结合该语言信息的上下文内容来确认其表示的含义,并抽取该语言信息中的多义词,最后根据表达的含义来剔除多义词所翻译出有歧义的语义信息。
基于上述技术方案,S3中,语言信息经过分析和消歧处理后,利用NLP语义分析技术来对该语言信息进行进一步的分析理解处理,以进一步确定该语言信息在语言内容内所正确表达的语义。
基于上述技术方案,S4中,语言信息经过NLP语义分析技术进行语义分析后,对该语言信息进行进一步的归纳处理,使该语言信息能够对应分入到计算机系统内不同的归纳组别内;
归纳处理具体包括如下步骤:
A、建立归纳数据库;
B、确定归纳的组别类型;
C、深度分析语言信息的语义;
D、标记并代入组别。
基于上述技术方案,A中,在计算机系统内建立用于收纳语言信息的归纳数据库;
B中,在归纳数据库中建立用以归纳分别收集的组别文件夹,组别文件夹具体包括时间文件夹、地点文件夹、人物文件夹、事件文件夹、原因文件夹、结果文件夹和数字文件夹。
基于上述技术方案,C中,在组别文件夹建立后,依据组别文件夹的组别类型来对语言信息进行进一步的深度分析,并在语言信息内抽取与组别文件夹组别类型对应的关键词信息;
D中,将对应的语言语义信息导入到对应的组别文件夹内,来对语言语义信息进行分开分类收集,并通过抽取的关键词信息来对该语言信息进行标记。
基于上述技术方案,S5中,经过NLP语义分析技术进行语义分析后,对语言信息的语义所表达的情感信息进行进一步的细化分析,主要依据语言语义信息中提出的情感信息词来判断该语言信息所表达的情感信息,具体将该语言语义信息分为喜、怒、哀、乐、愁、恐和恨七类。
基于上述技术方案,S6中,在语言的语义信息经过处理后,在计算机系统内建立意图识别正则模型,意图识别正则模型主要基于三类正则关键词来描述用户输入的语言信息所要表达出的意图;
三类正则关键词主要包括基于语言信息内存在关键词“一定不是”的判断正则,语言信息内存在关键词“一定是”的判断正则,语言信息内存在关键词“可能是”的判断正则;
S7中,根据NLP语义分析技术分析后语言信息所表达的正确语义,来提取该语义信息中的正则关键词,正则关键词包括“一定不是”、“一定是”和“可能是”三种。
基于上述技术方案,S8中,在语言信息中的正则关键词提取后,依据提取的正则关键词信息来判断用户输入语言信息所要表达的意图,语言信息中存在正则关键词“一定是”时,则表明该用户输入的语言信息中可能具有某种意图。
实施例3:如图1-2所示,本发明提供一种技术方案,基于自然语音处理的正则意图识别方法,包括如下步骤:
S1、获取用户输入的语言信息;
S2、自然语言处理;
S3、利用NLP语义分析;
S4、语言信息归纳;
S5、语义情感分析;
S6、建立意图识别正则模型;
S7、提取正则关键词;
S8、依据正则关键词判断用户意图;
S9、创建意图预设模型;
S10、用户选择意图。
基于上述技术方案,S1中,通过计算机语言输入模块来获取用户输入的语言信息;
S2中,在获取用户语言信息后,通过计算机来对用户的语言信息进行处理,具体包括对获取语言信息进行语义分析处理和歧义消除处理;
语义分析是指对获取的语言信息进行浅层语义分析和深层语义分析处理,并将语言信息所表达的语义信息进行推导翻译;
歧义消除是指在对语义分析的基础上判断该语言信息所要表达的语义,结合该语言信息的上下文内容来确认其表示的含义,并抽取该语言信息中的多义词,最后根据表达的含义来剔除多义词所翻译出有歧义的语义信息。
基于上述技术方案,S3中,语言信息经过分析和消歧处理后,利用NLP语义分析技术来对该语言信息进行进一步的分析理解处理,以进一步确定该语言信息在语言内容内所正确表达的语义。
基于上述技术方案,S4中,语言信息经过NLP语义分析技术进行语义分析后,对该语言信息进行进一步的归纳处理,使该语言信息能够对应分入到计算机系统内不同的归纳组别内;
归纳处理具体包括如下步骤:
A、建立归纳数据库;
B、确定归纳的组别类型;
C、深度分析语言信息的语义;
D、标记并代入组别。
基于上述技术方案,A中,在计算机系统内建立用于收纳语言信息的归纳数据库;
B中,在归纳数据库中建立用以归纳分别收集的组别文件夹,组别文件夹具体包括时间文件夹、地点文件夹、人物文件夹、事件文件夹、原因文件夹、结果文件夹和数字文件夹。
基于上述技术方案,C中,在组别文件夹建立后,依据组别文件夹的组别类型来对语言信息进行进一步的深度分析,并在语言信息内抽取与组别文件夹组别类型对应的关键词信息;
D中,将对应的语言语义信息导入到对应的组别文件夹内,来对语言语义信息进行分开分类收集,并通过抽取的关键词信息来对该语言信息进行标记。
基于上述技术方案,S5中,经过NLP语义分析技术进行语义分析后,对语言信息的语义所表达的情感信息进行进一步的细化分析,主要依据语言语义信息中提出的情感信息词来判断该语言信息所表达的情感信息,具体将该语言语义信息分为喜、怒、哀、乐、愁、恐和恨七类。
基于上述技术方案,S6中,在语言的语义信息经过处理后,在计算机系统内建立意图识别正则模型,意图识别正则模型主要基于三类正则关键词来描述用户输入的语言信息所要表达出的意图;
三类正则关键词主要包括基于语言信息内存在关键词“一定不是”的判断正则,语言信息内存在关键词“一定是”的判断正则,语言信息内存在关键词“可能是”的判断正则;
S7中,根据NLP语义分析技术分析后语言信息所表达的正确语义,来提取该语义信息中的正则关键词,正则关键词包括“一定不是”、“一定是”和“可能是”三种。
基于上述技术方案,S8中,在语言信息中的正则关键词提取后,依据提取的正则关键词信息来判断用户输入语言信息所要表达的意图,语言信息中存在正则关键词“可能是”时,则表明该用户输入的语言信息中存在两种意图情况,一是该语言信息可能具有某种意图,二是该语言信息可能不具有某种意图。
基于上述技术方案,S9中,用户输入的语言信息存在正则关键词“可能是”时,并出现两种可能出现意图的情况时,在计算机系统内创建意图预设模型,预设模型包含该语言信息具有某种意图和该语言信息不具有某种意图两种类型;
S10中,在意图预设模型创建后,使用户依据语言信息来自主选择所要表达的意图。
最后应说明的是:以上所述仅为本发明的优选实例而已,并不用于限制本发明,尽管参照前述实施例对本发明进行了详细的说明,对于本领域的技术人员来说,其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 基于自然语音处理的正则意图识别方法
- 一种基于正则表达式的空管指令意图识别方法