一种大豆高蛋白含量相关的分子标记和鉴定高蛋白含量大豆的方法
文献发布时间:2023-06-19 12:24:27
技术领域
本发明属于生物技术领域,具体涉及一种大豆高蛋白含量相关的分子标记和鉴定高蛋白含量大豆的方法。
背景技术
大豆有着丰富的营养成分,蛋白质在40%左右。大豆蛋白质中含有8种人体必需氨基酸,人们可以通过食用大豆用以补充所需的营养物质,并且可以预防人体的心血管疾病,大豆同时是重要的油料作物,可以被加工为食用油,可以满足人们的饮食需求,同时主要由五种脂肪酸组成,而脂肪酸可以预防心脏病、癌症等。随着人们的生活水平日益提高,越来越多的人更多的注重于食用健康与食物的营养价值,因此对大豆的需求很大,但我国的大豆更多的是依赖于从其他国家进口,所以我国急需提高大豆蛋白及培育高蛋白、高油大豆品种,满足人们的日常所需。
大豆子粒的蛋白是品质相关性状,是比较复杂的数量性状,受到多个基因控制,一直以来受到遗传特性和育种方法的限制,传统方法过于缓慢,随着科技的不断进步,分子辅助选择被提出,在传统杂交育种方法的基础上利用分子标记与决定目标性状的基因紧密连锁,通过对标记的选择来实现对性状的选择,大幅度提高育种效率,实现定向改良大豆品种的作用即可以选择出高蛋白的大豆品种。
发明内容
本发明的目的是为了快速和准确的筛选高蛋白优质大豆品种,本发明提供了一种大豆高蛋白含量相关的分子标记,所述分子标记的核苷酸序列为SNP1,所述SNP1的序列为大豆1号染色体上50.84Mb-50.87Mb位置的的核苷酸序列,且Gm01号染色体的第50861576核苷酸位点为A或C。
在一种实施方式中,扩增SNP1的引物为Gm01_50861576-F和Gm01_50861576-R,所述Gm01_50861576-F的核苷酸序列如SEQ ID NO.15或如SEQ ID NO.16所示;所述Gm01_50861576-R的核苷酸序列如SEQ ID NO.17所示。
本发明还提供了一种大豆高蛋白含量相关的分子标记,所述分子标记的核苷酸序列为SNP2,所述SNP2的序列为大豆6号染色体上38.49Mb-47.89Mb位置的的核苷酸序列,且Gm06号染色体的第44869874核苷酸位点为A或G。
在一种实施方式中,扩增SNP2的引物为Gm06_44869874-F和Gm14_16525645-R,所述Gm06_44869874-F的核苷酸序列如SEQ ID NO.51或如SEQ ID NO.52所示;所述Gm06_44869874-R核苷酸序列如SEQ ID NO.53所示。
本发明还提供了一种大豆高蛋白含量相关的分子标记,所述分子标记的核苷酸序列为SNP3,所述SNP3的序列为大豆14号染色体上16.13Mb-16.66Mb位置的的核苷酸序列,且Gm14号染色体的第16525645核苷酸位点为A或T。
在一种实施方式中,扩增SNP3的引物为Gm14_16525645-F和Gm14_16525645-R,所述Gm14_16525645-F的核苷酸序列如SEQ ID NO.84或如SEQ ID NO.85所示;所述Gm14_16525645-R核苷酸序列如SEQ ID NO.86所示。
本发明还提供了一种SNP1、SNP2和SNP3分子标记在制备鉴定高蛋白含量的大豆的试剂盒中的应用,用(a)~(c)任一组引物扩增SNP1、SNP2和SNP3分子标记:
(a)扩增SNP1的上游引物的核苷酸序列如SEQ ID NO.15或如SEQ ID NO.16所示;扩增SNP1的下游引物的核苷酸序列如SEQ ID NO.17所示;
(b)扩增权利SNP2的上游引物的核苷酸序列如SEQ ID NO.51或如SEQ ID NO.52所示;扩增SNP2的下游引物的核苷酸序列如SEQ ID NO.53所示;
(c)扩增SNP3的上游引物的核苷酸序列如SEQ ID NO.84或如SEQ ID NO.85所示;扩增SNP3的下游引物的核苷酸序列如SEQ ID NO.86所示。
本发明还提供了一种鉴定高蛋白含量大豆的方法,所述方法的具体步骤为:
(1)提取待检测大豆的DNA;
(2)利用SNP1分子标记的引物进行PCR反应,检测待检测品种的大豆为CC基因型则待检测品种的大豆为高蛋白含量的大豆,若为AA基因型则待检测品种的大豆为低蛋白含量的大豆。
本发明还提供了一种鉴定高蛋白含量大豆的方法,所述方法的具体步骤为:
(1)提取待检测大豆的DNA;
(2)利用SNP2分子标记的引物进行PCR反应,检测待检测品种的大豆为GG基因型则待检测品种的大豆为高蛋白含量的大豆,若为AA基因型则待检测品种的大豆为低蛋白含量的大豆。
本发明还提供了一种鉴定高蛋白含量大豆的方法,所述方法的具体步骤为:
(1)提取待检测大豆的DNA;
(2)利用SNP3分子标记的引物进行PCR反应,检测待检测品种的大豆为AA基因型则待检测品种的大豆为高蛋白含量的大豆,若为TT基因型为低蛋白含量的大豆。
有益效果:本研究利用643份经过全基因组重测序的资源群体结合其2年3次重复的大豆子粒贮藏物质的表型数据,利用分层评价的方法筛选出与大豆子粒蛋白、油分极显著相关的SNP位点,采用SNP分子标记技术中的KASP在151份大豆非测序极端蛋白资源材料及162份大豆非测序极端油分资源材料中进行验证,根据其分型结果及其表型数据,开发出与大豆蛋白、油分相关的分子标记,用以在生产中提前筛选高蛋白、高油分优质品种提供一种高速准确的方法。
附图说明
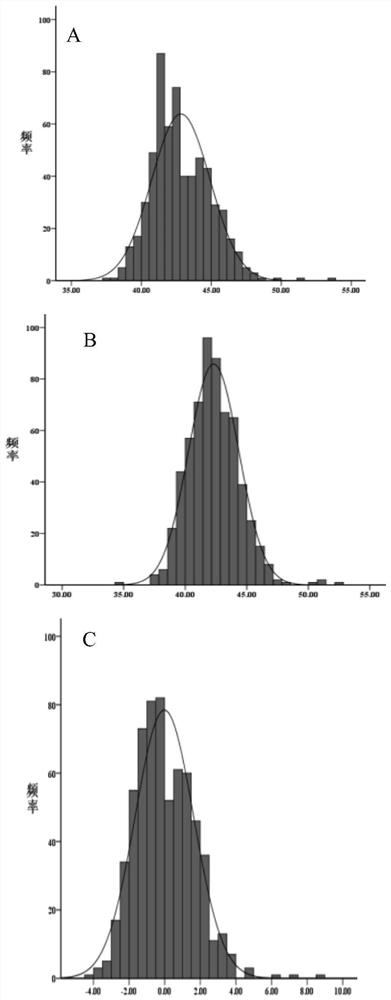
图1为2018、2019年资源测序材料蛋白、油分含量及BLUP分布直方图,其中,图A为2018年蛋白含量分布直方图,B是2019年蛋白含量分布直方图,C是2年蛋白BLUP分布直方图,横坐标是组别,纵坐标是频率;
图2为20条染色体上SNP位点数目分布,其中,横坐标是染色体,纵坐标是SNP个数;
图3为20条染色体上与蛋白相关的SNP位点数目分布,其中,横坐标是染色体,纵坐标是SNP个数;
图4为与蛋白相关的SNP位点突变基因组对应等位基因与参考基因组对应表型效应值差值,其中,横坐标是组别,纵坐标是表型效应之差值;
图5为与蛋白相关SNP位点的高蛋白优异单倍型与低蛋白单倍型表型均值,其中,横坐标是组别,纵坐标是蛋白质含量;
图6为SNP标记在151个大豆极端蛋白资源材料中的KASP基因分型。
具体实施例
大豆蛋白含量的MQTL记载在文献Qi et al.2018 Meta-analysis andtranscriptome profiling reveal hub genes for soybean seed storage compositionduring seed development。
实施例1.
实验群体:选取643份东北地区大豆核心种质测序资源作为实验群体,于2018、2019年在吉林省农科院及东北农业大学向阳农场试验田中种植且3次重复,1m行长,每1行播撒20粒种子,播种的深度为3-4cm,田间管理方法同大田管理,收获后考察各个性状,选择长势一致的5株进行测量。在营养生长阶段,采取植株顶端最幼嫩处叶片用于提取DNA,收获时每个株系随机取5株进行脱粒,用于测定蛋白质含量。
一、大豆子粒蛋白含量测定及处理:使用FOSS谷物分析仪(Infratec1241)用大量法测出实验材料及验证材料的蛋白含量,该仪器利用近红外透射技术进行全谱扫描,可获得丰富的光谱信息,通过对比定标数据库从而获得精度非常高的蛋白含量表型数据。测量时要保证子粒在安全含水量范围内,每份单株子粒重复测量3次,取3次测量数据的平均值作为最终蛋白含量表型数据。利用Microsoft Office excel2013进行表型数据处理,取其平均值,利用SPSS统计分析2年3次重复的大豆子粒蛋白,包括显著性检验,频率分布直方图,计算均值等。通过R软件进行最佳线性无偏预测值(The Best Linear UnbiasedPredictions,BLUP)的计算。
由表1可知,该群体1个品质相关性状两年均无较大变幅,变异系数在4%-5%之间,蛋白这个性状标准差较小,2年分别为2.09、2.04。通过分析峰度、偏度发现,该群体的1个品质相关性状的蛋白表现中等偏态分布,将2018、2019两年蛋白油分表型数据进行BLUP分析,并将2018、2019两年蛋白均值(图1中的A和B)及BLUP值利用SPSS软件做了正态分布图(图1中的C),从图中可看出测得的大豆子粒蛋白的两年数据和BLUP值均显示连续分布,而且分布趋势均很明显,从正态曲线上也能得知大豆子粒蛋白均呈现出正态分布。其次,从蛋白两年及其BLUP值的图中可以看出,BLUP值的峰值较2年数据较低一些,数据分布也较广且较均匀;这个品质性状的BLUP值分布特征也符合数量性状遗传特点,更适合利用BLUP值进行后续分析研究。
表1大豆测序材料2018、2019年蛋白品质性状的描述性分析
DNA提取方法:取大豆3-4g新鲜叶片装入1.5mL离心管,再加入3颗3mm灭菌的小钢珠。将离心管浸于液氮中,应用组织研磨仪将冻干的叶片组织震荡成粉末。加入650-700μL预先在65℃水浴锅中水浴的CTAB提取液,置于涡旋震荡仪上充分混匀,65℃水浴1小时,每15min颠倒混匀一次。加入等体积氯仿充分混匀,12,000rpm离心20min,吸取上清液注入新的离心管中,重新加入700μL氯仿,充分颠倒混匀后离心12,000rpm,20min,吸取上清匀速滴加入预先装有-20℃预冷异丙醇的离心管中,-20℃环境下保存20min。8,000rpm离心10min,将上清液倒入废液缸,分别用无水乙醇和75%乙醇洗涤底部团状DNA。将离心管开盖置于超净工作台中吹干,加入灭菌水。用分光光度计(NanoDrop)检测提取得到的DNA的质量水平,利用琼脂糖凝胶电泳检测出DNA浓度,统一稀释到工作液浓度20ng/μL。
二、资源测序材料SNP位点的分层评价:选取643份大豆资源群体进行重测序,20条染色体共获得SNP位点53,946个,SNP质量控制MAF<0.05,杂合率<10%,平均每条染色体含有2,697个。其中Chr18染色体中SNP数量最多,有4,462个;Chr11染色体中SNP数量最少,有862个,其余染色体上的SNP数目见图2。
三、重要等位基因挖掘:(1)针对表型将材料进行分类,分别按照研究的性状不同即大豆蛋白,求其所有数据平均值及其标准差,将平均值分别加减标准差所得数据分别作为临界,高于平均值加标准差材料作为高蛋白。(2)把研究的该SNP位点的测序结果根据是参考基因组的等位基因还是突变后基因组对应的等位基因统计分析,并且结合表型数据即蛋白、油分按照平均值加减一倍标准差作为标准将材料进行分类,取两端高于和低于该标准材料,将所统计得到的数据列入如下四联表如表2中,进行卡方检测:
表2卡方分析的四联表
注:i为A/C/T/G,a
(3)原假设H0:蛋白含量的大小与i等位基因相互独立,HA:2个变数有关联。通过下列公式得到χ2结果,当所得到的χ2<χ2α时,同意H0成立;当所得到的χ2≥χ2α时,不同意H0成立,HA成立。因此根据得到的χ2值与α=0.001时的阈值针对研究的SNP位点进行判断。
(4)重复(2)、(3)步骤,对蛋白性状的所有SNP位点进行独立性检验,用以来判断对该研究性状的具体影响,本实验以alpha=0.001作为阈值,当所得到的结果对应的P<0.001时,则判断该SNP位点为影响该性状的显著位点,进行后续研究,而P≥0.001时,则放弃继续研究该位点。(5)对于(4)步骤所选出的显著位点进行下一步的表型效应值验证,在所有材料中对显著位点进行表型效应计算,通过以下公式:
注:Rate of change表示效应值,A等位基因表示该SNP位点的参考基因组对应的等位基因,Value A表示有着A样品的蛋白的均值,B等位基因表示该SNP位点的突变基因组对应的等位基因,Value B表示有着B样品蛋白含量的均值。
结果:通过以蛋白表型的平均值加减一倍标准差为标准取两端蛋白表型及测序结果,将其进行重要等位基因挖掘,通过利用卡方分析方法,选择显著性alpha=0.001作为分层阈值,将分析所得到结果进行分层,当检验P值小于0.001时,我们将其认为是与蛋白相关的极显著的SNP位点,其余P值大于0.001的相较之下效应相对小,选择意义甚小,因此得到与蛋白相关极显著位点个数为7,404,其中4号染色体上最多,达1,537个,其他染色体上数目见图3,为进一步挖掘好的位点因此针对其SNP位点等位基因突变分别在高低表型中占比进行进一步限制,并且将其得到极显著位点与大豆蛋白MQTL结果相比较找到重合区间的位点,比较后得到的相关SNP位点个数为147个,与蛋白相关的SNP位点在14号染色体上最多,达48个。
经卡方检测及与MQTL对比得到的关键SNP位点突变前后的效应各不相同,有些是对蛋白含量起正向效应,有些为负向效应:如果含有某等位基因的蛋白含量平均值比所有资源的蛋白含量平均值高,那么该等位基因能够增加蛋白含量;相反,如果含有其突变等位基因的蛋白含量平均值比所有资源蛋白含量平均值低,那么该等位基因具有能够减少蛋白含量的作用。SNP位点对蛋白含量的效应值有所不同(如图4),图中上方的点列出的是突变对应等位基因的表型效应值与参考基因组含有等位基因对应的表型效应值的差值为正值,即突变后蛋白含量增加,图中下方的点是突变对应等位基因的表型效应值与参考基因组对应等位基因的表型效应值的差值为负值,即突变后蛋白含量减少。
在1号染色体上50.84Mb-50.87Mb的5个SNP位点,其占高蛋白的比例为63.17-66.99%,其表型效应率在1.56%-2.44%;在3号染色体上36.79-38.93的34个SNP位点,其占高蛋白的比例为60.19%-64.52%,其表型效应率在1.92%-2.59%;在5号染色体上40081658、40270960处的2个SNP位点,其占高蛋白的比例分别为60.19%、61.17%,其表型效应率均为2.43%;在6号染色体上38.49-47.89的37个SNP位点,其占高蛋白的比例为60.22%-73.79%,其表型效应率在1.65%-2.52%;在8号染色体上9.23-9.24的5个SNP位点,其占高蛋白的比例为60.19%-64.08%,其表型效应率在1.30%-1.71%;在11号染色体上14918130处的SNP位点,其占高蛋白的比例为60.19%,其表型效应率为2.29%;在13号染色体上1389378处的SNP位点,其占高蛋白的比例为62.14%,其表型效应率2.51%;在14号染色体上16.13-16.66的48个SNP位点,其占高蛋白的比例为60.22%-77.67%,其表型效应率在1.76%-2.69%;在19号染色体上42.65-42.75的4个SNP位点,其占高蛋白的比例为62.14%-65.59%,其表型效应率在1.39%-1.76%;在20号染色体上33.67-33.99的9个SNP位点,其占高蛋白的比例为60.19%-62.14%,其表型效应率在1.56%-2.29%(结果如表3)。以上大豆的染色体的信息是来自于网站:https://phytozome.jgi.doe.gov/pz/portal.html#!info?alias=Org_Gmax。
表3筛选后的与蛋白相关的SNP位点
四、蛋白相关SNP位点单倍型分析:为了确定所得到的与蛋白相关SNP位点与蛋白的关系,分析147个其变异位点的单倍型,将接近的位点分为一组共同分析,共得到46组,每组均产生不同单倍型,分析得到该单倍型在643份测序材料中所占比例,并计算出该单倍型的表型均值,最后分析得到分析14组位点存在高蛋白优异单倍型和低蛋白单倍型的蛋白表型均值有较大差异,能够较好的达到蛋白的分离见图5。
在1号染色体上50836411(代表在染色体上的位置)、50838581、50840858、50854308、50861576处分析得到,高蛋白优异单倍型Hap_1(TCCCC)和低蛋白单倍型Hap_4(TCCCA),高蛋白优异单倍型占34.8%,蛋白主要分布在41-48左右,低蛋白单倍型占1.5%,蛋白主要分布在40-43,达到明显差异;在3号染色体上36911977、36956744、36976313、37015622处分析得到,高蛋白优异单倍型Hap_1(TACTCATATTAC)和低蛋白单倍型Hap_35(CAAATGAGCCGA),高蛋白优异单倍型占36.12%,蛋白主要分布在41-48左右,低蛋白单倍型占1.17%,蛋白主要分布在40-42,达到明显差异;在3号染色体上38222729处分析得到,高蛋白优异单倍型Hap_4(ACGCAATGTAGA)和低蛋白单倍型Hap_102(CGATGGTAACAT),高蛋白优异单倍型占42.31%,蛋白主要分布在41-47.5左右,低蛋白单倍型占1.17%,蛋白主要分布在39-40,达到明显差异;在5号染色体上40081658处分析得到,高蛋白优异单倍型Hap_5(TAGTTCCCTCTCA)和低蛋白单倍型Hap_12(TAATTCCCTCTCA),高蛋白优异单倍型占20.40%,蛋白主要分布在41-46左右,低蛋白单倍型占1.67%,蛋白主要分布在39-43,达到明显差异;在5号染色体上40270960处分析得到,高蛋白优异单倍型Hap_1(CCAGGTTAGCCGA)和低蛋白单倍型Hap_10(CCGTGTTAGCCGA),高蛋白优异单倍型占23.91%,蛋白主要分布在41-48左右,低蛋白单倍型占1.00%,蛋白主要分布在36-40,达到明显差异;在6号染色体上44869874、45732460、46313677、46682433、47893908处分析得到,高蛋白优异单倍型Hap_5(GTGGCGCCTG)和低蛋白单倍型Hap_60(ACTATACTCC),高蛋白优异单倍型占19.23%,蛋白主要分布在41-48左右,低蛋白单倍型占1.17%,蛋白主要分布在38-42,达到明显差异;在11号染色体上14918130处分析得到,高蛋白优异单倍型Hap_3(AAGTCAGTAGCAAATGGCA)和低蛋白单倍型Hap_58(TGACTCTGAAAGGGGTA TG),高蛋白优异单倍型占39.46%,蛋白主要分布在41-48左右,低蛋白单倍型占1.17%,蛋白主要分布在38-42,达到明显差异;在13号染色体上13893781处分析得到,高蛋白优异单倍型Hap_1(AATGGACAGGAGCA)和低蛋白单倍型Hap_27(AATGGACAGAAGCA),高蛋白优异单倍型占24.75%,蛋白主要分布在41-48左右,低蛋白单倍型占1.00%,蛋白主要分布在40-41,达到明显差异;在13号染色体上13893781处分析得到,高蛋白优异单倍型Hap_1(AATGGACAGGAGCA)和低蛋白单倍型Hap_27(AATGGACAGAAGCA),高蛋白优异单倍型占24.75%,蛋白主要分布在41-48左右,低蛋白单倍型占1.00%,蛋白主要分布在40-41,达到明显差异。
五、验证群体:选取151份东北地区大豆核心非测序极端蛋白资源材料(表4),用于重要等位基因挖掘的验证,种植、管理、采样、收获方法同实验材料。
表4 151份大豆非测序极端蛋白材料品种名称及蛋白含量
SNP位点的标记筛选及方法:KASP反应体系由混合引物,Master Mix和样本DNA组成。根据分层评价得到的SNP位点,通过本地Blast提取SNP位点上下游各50bp的碱基序列,利用Primer 5.0软件设计KASP引物。每一个位点的引物皆由2条具有不同等位基因和荧光标签的特异性正向引物(F1/F2)以及1条公共的反向引物(R)构成,其中各组分主要配方分别是46μL的ddH
表5引物序列信息
KASP反应所需组分加于384孔板,采用罗氏LightCycler480Ⅱ实时荧光定量PCR仪并在反应终止后读取终端荧光信号,其PCR扩增程序:95℃,15min;95℃,20s;65℃,25s;Goto step 2,10cycles,-0.8℃ per cycle;95℃,10s;57℃,1min;Go to step 4,35cycles;4℃,∞。
KASP分型验证:罗氏LightCycler480Ⅱ得到分型结果,转置到Excel软件,进行分析,计算该位点符合率,基本思路为:(1)根据不同的极端大豆蛋白、油分非测序材料,统计出每个引物在高蛋白、低蛋白材料或高油分、低油分材料中SNP位点的参考基因组对应的等位基因及突变基因组对应的等位基因的个数及分布,构建符合率的四格表如表6所示:
表6符合率的四格表
注:x、y为SNP位点设计引物的KASP分型的基因型,a为非测序高蛋白材料分型结果中有x等位基因数量,b为非测序低蛋白材料分型结果中有x等位基因数量,c为非测序高蛋白材料分型结果中有y等位基因数量,d为非测序低蛋白材料分型结果中有y等位基因数量,M为非测序高蛋白材料总数,N为非测序低蛋白材料的总数。
(2)原假设H
(3)重复(1)、(2)步骤,对蛋白性状的所有引物分型结果进行独立性检验,用以来验证对该性状的影响,对于(3)步骤所得到的所有结果进行进一步表型效应验证,在所有材料中对主效位行表型效应计算,利用以下公式:
结果:利用蛋白的29个标记进行分型验证,利用KASP对极端蛋白非测序资源材料151份进行基因分型。与蛋白相关的标记最终20个分型成功,图6表示,1个KASP分型成功标记的的结果示意图,其中表示2种不同的纯合等位基因型(GG、AA),表示合基因型(AG)。表示蛋白相关SNP标记的KASP验证结果,分析可知与蛋白相关的Gm01_50861576标记在高蛋白材料中54份CC基因型,低蛋白材料中42份为AA基因型,分别占高蛋白、低蛋白材料为70.13%和56.76%,其表型效应值为3.31%;与蛋白相关的Gm06_44869874标记在高蛋白材料中73份GG基因型,低蛋白材料中57份为AA基因型,分别占高蛋白、低蛋白材料为94.81%和77.03%,其表其表型效应值为8.34%;与蛋白相关的Gm14_16525645标记在高蛋白材料中41份AA基因型,低蛋白材料中51份为TT基因型,分别占高蛋白、低蛋白材料为53.25%和68.92%,其表型效应值为2.24%,以上3个标记均能够成功分型且在高低蛋白中表现不同的基因型,能够成功开发出SNP标记。
一种大豆高蛋白含量相关的分子标记,所述分子标记的核苷酸序列为SNP1,所述SNP1的序列为大豆1号染色体上50.84Mb-50.87Mb位置的的核苷酸序列,且Gm01号染色体的第50861576核苷酸位点为A或C;
一种大豆高蛋白含量相关的分子标记,所述分子标记的核苷酸序列为SNP2,所述SNP2的序列为大豆6号染色体上38.49Mb-47.89Mb位置的的核苷酸序列,且Gm06号染色体的第44869874核苷酸位点为A或G。
一种大豆高蛋白含量相关的分子标记,所述分子标记的核苷酸序列为SNP3,所述SNP3的序列为大豆14号染色体上16.13Mb-16.66Mb位置的的核苷酸序列,且Gm14号染色体的第16525645核苷酸位点为A或T。
实施例2.
一、一种筛选高蛋白大豆的试剂盒:
(a)扩增SNP1的上游引物的核苷酸序列如SEQ ID NO.15或如SEQ ID NO.16所示;扩增SNP1的下游引物的核苷酸序列如SEQ ID NO.17所示;
(b)扩增SNP2的上游引物的核苷酸序列如SEQ ID NO.51或如SEQ ID NO.52所示;扩增SNP2的下游引物的核苷酸序列如SEQ ID NO.53所示;
(c)扩增SNP3的上游引物的核苷酸序列如SEQ ID NO.84或如SEQ ID NO.85所示;扩增SNP3的下游引物的核苷酸序列如SEQ ID NO.86所示。
筛选方法:选择未知大豆蛋白含量的样品,利用步骤一所述的筛选高蛋白大豆的试剂盒,进行PCR扩增程序:95℃,15min;95℃,20s;65℃,25s;Go to step 2,10cycles,-0.8℃ per cycle;95℃,10s;57℃,1min;Go to step 4,35cycles;4℃,∞。经过KASP分析,步骤如下:
二、一种鉴定高蛋白含量大豆的方法,所述方法的具体步骤为:
(1)提取待检测大豆的DNA;
(2)利用SNP1分子标记的引物进行PCR反应,检测待检测品种的大豆为CC基因型则待检测品种的大豆为高蛋白含量的大豆,若为AA基因型则待检测品种的大豆为低蛋白含量的大豆;利用SNP2分子标记的引物进行PCR反应,检测待检测品种的大豆为GG基因型则待检测品种的大豆为高蛋白含量的大豆,若为AA基因型则待检测品种的大豆为低蛋白含量的大豆;利用SNP3分子标记的引物进行PCR反应,检测待检测品种的大豆为AA基因型则待检测品种的大豆为高蛋白含量的大豆,若为TT基因型为低蛋白含量的大豆。
结果:检测未知的大豆蛋白含量的样品中大豆蛋白含量有大于42%,利用基因型为SNP1标记检测为CC基因型,SNP2标记检测为GG基因型,SNP3标记检测为AA基因型,大豆高蛋白的含量与标记检测得到的基因型是相符的。大豆低蛋白的含量与标记检测得到的基因型是相符的。
SEQUENCE LISTING
<110> 东北农业大学
<120> 一种大豆高蛋白含量相关的分子标记和鉴定高蛋白含量大豆的方法
<160> 119
<170> PatentIn version 3.5
<210> 1
<211> 21
<212> DNA
<213> 人工合成
<400> 1
gaaggtgacc aagttcatgc t 21
<210> 2
<211> 21
<212> DNA
<213> 人工合成
<400> 2
gaaggtcgga gtcaacggat t 21
<210> 3
<211> 46
<212> DNA
<213> 人工合成
<400> 3
gaaggtgacc aagttcatgc tcctgcttta gtttattgtt gacaaa 46
<210> 4
<211> 46
<212> DNA
<213> 人工合成
<400> 4
gaaggtcgga gtcaacggat tcctgcttta gtttattgtt gacaat 46
<210> 5
<211> 30
<212> DNA
<213> 人工合成
<400> 5
gaagtggaaa aagttatcag tgcttgacac 30
<210> 6
<211> 44
<212> DNA
<213> 人工合成
<400> 6
gaaggtgacc aagttcatgc ttgcagcttt aaaataccaa taat 44
<210> 7
<211> 44
<212> DNA
<213> 人工合成
<400> 7
gaaggtcgga gtcaacggat ttgcagcttt aaaataccaa taac 44
<210> 8
<211> 25
<212> DNA
<213> 人工合成
<400> 8
aaatcccatt tggactatat cagcg 25
<210> 9
<211> 41
<212> DNA
<213> 人工合成
<400> 9
gaaggtgacc aagttcatgc tttgaagaag agttttcaag t 41
<210> 10
<211> 41
<212> DNA
<213> 人工合成
<400> 10
gaaggtcgga gtcaacggat tttgaagaag agttttcaag c 41
<210> 11
<211> 23
<212> DNA
<213> 人工合成
<400> 11
tataaatacc ataccccatc acg 23
<210> 12
<211> 43
<212> DNA
<213> 人工合成
<400> 12
gaaggtgacc aagttcatgc ttcacccgag tatcttatat cat 43
<210> 13
<211> 43
<212> DNA
<213> 人工合成
<400> 13
gaaggtcgga gtcaacggat ttcacccgag tatcttatat cac 43
<210> 14
<211> 21
<212> DNA
<213> 人工合成
<400> 14
gaaacatgga gtgacttgtg g 21
<210> 15
<211> 41
<212> DNA
<213> 人工合成
<400> 15
gaaggtgacc aagttcatgc ttttcgtccc aaaattggtt a 41
<210> 16
<211> 41
<212> DNA
<213> 人工合成
<400> 16
gaaggtcgga gtcaacggat ttttcgtccc aaaattggtt c 41
<210> 17
<211> 23
<212> DNA
<213> 人工合成
<400> 17
ccttcttcac caaataccaa cca 23
<210> 18
<211> 40
<212> DNA
<213> 人工合成
<400> 18
gaaggtgacc aagttcatgc tgggttcaac atttccttgg 40
<210> 19
<211> 40
<212> DNA
<213> 人工合成
<400> 19
gaaggtcgga gtcaacggat tgggttcaac atttccttga 40
<210> 20
<211> 21
<212> DNA
<213> 人工合成
<400> 20
attggcagtc tgctgaggtc a 21
<210> 21
<211> 45
<212> DNA
<213> 人工合成
<400> 21
gaaggtgacc aagttcatgc tcaagtctgc ttaaaatgaa cacaa 45
<210> 22
<211> 45
<212> DNA
<213> 人工合成
<400> 22
gaaggtcgga gtcaacggat tcaagtctgc ttaaaatgaa cacat 45
<210> 23
<211> 23
<212> DNA
<213> 人工合成
<400> 23
agactcttgc attcaacagg gat 23
<210> 24
<211> 46
<212> DNA
<213> 人工合成
<400> 24
gaaggtgacc aagttcatgc taaacaagta aacatgccat attcat 46
<210> 25
<211> 46
<212> DNA
<213> 人工合成
<400> 25
gaaggtcgga gtcaacggat taaacaagta aacatgccat attcaa 46
<210> 26
<211> 22
<212> DNA
<213> 人工合成
<400> 26
cgaaattaat taggcatgca aa 22
<210> 27
<211> 46
<212> DNA
<213> 人工合成
<400> 27
gaaggtgacc aagttcatgc tgtcactgaa gctaggcgaa gcttgg 46
<210> 28
<211> 46
<212> DNA
<213> 人工合成
<400> 28
gaaggtcgga gtcaacggat tgtcactgaa gctaggcgaa gcttga 46
<210> 29
<211> 25
<212> DNA
<213> 人工合成
<400> 29
gtcactgaag ctaggcgaag cttgg 25
<210> 30
<211> 41
<212> DNA
<213> 人工合成
<400> 30
gaaggtgacc aagttcatgc ttcctcttct tcttcctgct c 41
<210> 31
<211> 41
<212> DNA
<213> 人工合成
<400> 31
gaaggtcgga gtcaacggat ttcctcttct tcttcctgct a 41
<210> 32
<211> 27
<212> DNA
<213> 人工合成
<400> 32
atgagacata cctggtacct ccgactc 27
<210> 33
<211> 43
<212> DNA
<213> 人工合成
<400> 33
gaaggtgacc aagttcatgc tttgaaatgg gaatcttcct ttg 43
<210> 34
<211> 43
<212> DNA
<213> 人工合成
<400> 34
gaaggtcgga gtcaacggat tttgaaatgg gaatcttcct ttc 43
<210> 35
<211> 30
<212> DNA
<213> 人工合成
<400> 35
ttatctcatt gataataatg caatcttcaa 30
<210> 36
<211> 41
<212> DNA
<213> 人工合成
<400> 36
gaaggtgacc aagttcatgc ttgttccatc aacatgacag a 41
<210> 37
<211> 41
<212> DNA
<213> 人工合成
<400> 37
gaaggtcgga gtcaacggat ttgttccatc aacatgacag c 41
<210> 38
<211> 28
<212> DNA
<213> 人工合成
<400> 38
agaaattata aaggtaaggg attgcatt 28
<210> 39
<211> 43
<212> DNA
<213> 人工合成
<400> 39
gaaggtgacc aagttcatgc taccaagaga caatgctgtc tca 43
<210> 40
<211> 43
<212> DNA
<213> 人工合成
<400> 40
gaaggtcgga gtcaacggat taccaagaga caatgctgtc tct 43
<210> 41
<211> 25
<212> DNA
<213> 人工合成
<400> 41
ttgagaggga tgaatgaaag agtgt 25
<210> 42
<211> 44
<212> DNA
<213> 人工合成
<400> 42
gaaggtgacc aagttcatgc taaaaaaaag tgattcaaga ttaa 44
<210> 43
<211> 44
<212> DNA
<213> 人工合成
<400> 43
gaaggtcgga gtcaacggat taaaaaaaag tgattcaaga ttaa 44
<210> 44
<211> 23
<212> DNA
<213> 人工合成
<400> 44
tgaggggaag aggggttaga gtt 23
<210> 45
<211> 44
<212> DNA
<213> 人工合成
<400> 45
gaaggtgacc aagttcatgc taccatgatt ttgtctgggt atat 44
<210> 46
<211> 44
<212> DNA
<213> 人工合成
<400> 46
gaaggtcgga gtcaacggat taccatgatt ttgtctgggt ataa 44
<210> 47
<211> 27
<212> DNA
<213> 人工合成
<400> 47
ggaaattgaa gcactacaaa atgataa 27
<210> 48
<211> 42
<212> DNA
<213> 人工合成
<400> 48
gaaggtgacc aagttcatgc tattcattaa aaagcctggt ct 42
<210> 49
<211> 42
<212> DNA
<213> 人工合成
<400> 49
gaaggtcgga gtcaacggat tattcattaa aaagcctggt cc 42
<210> 50
<211> 27
<212> DNA
<213> 人工合成
<400> 50
caaggactgg taaagcttga gactcta 27
<210> 51
<211> 40
<212> DNA
<213> 人工合成
<400> 51
gaaggtgacc aagttcatgc tcccgaaatt tctcttggga 40
<210> 52
<211> 40
<212> DNA
<213> 人工合成
<400> 52
gaaggtcgga gtcaacggat tcccgaaatt tctcttgggg 40
<210> 53
<211> 26
<212> DNA
<213> 人工合成
<400> 53
tgttcctatc atcgcataaa actcag 26
<210> 54
<211> 44
<212> DNA
<213> 人工合成
<400> 54
gaaggtgacc aagttcatgc tgggagataa gaaagctaat attt 44
<210> 55
<211> 44
<212> DNA
<213> 人工合成
<400> 55
gaaggtcgga gtcaacggat tgggagataa gaaagctaat attc 44
<210> 56
<211> 26
<212> DNA
<213> 人工合成
<400> 56
catatttgag acagggacag tcgaag 26
<210> 57
<211> 41
<212> DNA
<213> 人工合成
<400> 57
gaaggtgacc aagttcatgc ttcttcagtc cctcctttga c 41
<210> 58
<211> 41
<212> DNA
<213> 人工合成
<400> 58
gaaggtcgga gtcaacggat ttcttcagtc cctcctttga t 41
<210> 59
<211> 27
<212> DNA
<213> 人工合成
<400> 59
gtctctacac aatgccacaa cactaat 27
<210> 60
<211> 41
<212> DNA
<213> 人工合成
<400> 60
gaaggtgacc aagttcatgc tcaacgagag tcaaatcgct c 41
<210> 61
<211> 41
<212> DNA
<213> 人工合成
<400> 61
gaaggtcgga gtcaacggat tcaacgagag tcaaatcgct a 41
<210> 62
<211> 29
<212> DNA
<213> 人工合成
<400> 62
ggtttaatcg ttttctccga gagtagtta 29
<210> 63
<211> 43
<212> DNA
<213> 人工合成
<400> 63
gaaggtgacc aagttcatgc tcctcctagg aaaccaatgt tac 43
<210> 64
<211> 43
<212> DNA
<213> 人工合成
<400> 64
gaaggtcgga gtcaacggat tcctcctagg aaaccaatgt tag 43
<210> 65
<211> 30
<212> DNA
<213> 人工合成
<400> 65
acattaaatc atagagcaaa agagggatat 30
<210> 66
<211> 40
<212> DNA
<213> 人工合成
<400> 66
gaaggtgacc aagttcatgc tctcaccgta cgaagcttct 40
<210> 67
<211> 40
<212> DNA
<213> 人工合成
<400> 67
gaaggtcgga gtcaacggat tctcaccgta cgaagcttcc 40
<210> 68
<211> 25
<212> DNA
<213> 人工合成
<400> 68
gtacggcaag tgacaaactg acagc 25
<210> 69
<211> 40
<212> DNA
<213> 人工合成
<400> 69
gaaggtgacc aagttcatgc tcttgatgag tattttgata 40
<210> 70
<211> 40
<212> DNA
<213> 人工合成
<400> 70
gaaggtcgga gtcaacggat tcttgatgag tattttgatt 40
<210> 71
<211> 23
<212> DNA
<213> 人工合成
<400> 71
tattggggtg gtcactagca tta 23
<210> 72
<211> 42
<212> DNA
<213> 人工合成
<400> 72
gaaggtgacc aagttcatgc tatgcttaag gatagtgatg gc 42
<210> 73
<211> 42
<212> DNA
<213> 人工合成
<400> 73
gaaggtcgga gtcaacggat tatgcttaag gatagtgatg ga 42
<210> 74
<211> 28
<212> DNA
<213> 人工合成
<400> 74
aatttggtga ccatagtctc caacttta 28
<210> 75
<211> 40
<212> DNA
<213> 人工合成
<400> 75
gaaggtgacc aagttcatgc tagaacaggg gaaaggaatt 40
<210> 76
<211> 40
<212> DNA
<213> 人工合成
<400> 76
gaaggtcgga gtcaacggat tagaacaggg gaaaggaatg 40
<210> 77
<211> 27
<212> DNA
<213> 人工合成
<400> 77
actgttaaac ccttaagctc atcaatg 27
<210> 78
<211> 42
<212> DNA
<213> 人工合成
<400> 78
gaaggtgacc aagttcatgc ttctccattc tttgctactc at 42
<210> 79
<211> 42
<212> DNA
<213> 人工合成
<400> 79
gaaggtcgga gtcaacggat ttctccattc tttgctactc ac 42
<210> 80
<211> 28
<212> DNA
<213> 人工合成
<400> 80
cataatgaac aaataaaggg acaaggta 28
<210> 81
<211> 45
<212> DNA
<213> 人工合成
<400> 81
gaaggtgacc aagttcatgc tcaagtgaaa atttttttat ttaag 45
<210> 82
<211> 45
<212> DNA
<213> 人工合成
<400> 82
gaaggtcgga gtcaacggat tcaagtgaaa atttttttat ttaat 45
<210> 83
<211> 21
<212> DNA
<213> 人工合成
<400> 83
tttagtggga tcgacaggcc c 21
<210> 84
<211> 41
<212> DNA
<213> 人工合成
<400> 84
gaaggtgacc aagttcatgc tgtcaaggtc tttgaaacct a 41
<210> 85
<211> 41
<212> DNA
<213> 人工合成
<400> 85
gaaggtcgga gtcaacggat tgtcaaggtc tttgaaacct t 41
<210> 86
<211> 22
<212> DNA
<213> 人工合成
<400> 86
gcagctgatg caacctaatt ga 22
<210> 87
<211> 46
<212> DNA
<213> 人工合成
<400> 87
gaaggtgacc aagttcatgc tggtgctaag gcaatttgac catgtc 46
<210> 88
<211> 46
<212> DNA
<213> 人工合成
<400> 88
gaaggtcgga gtcaacggat tggtgctaag gcaatttgac catgtg 46
<210> 89
<211> 22
<212> DNA
<213> 人工合成
<400> 89
ataggacaag gatgttgttg gc 22
<210> 90
<211> 41
<212> DNA
<213> 人工合成
<400> 90
gaaggtgacc aagttcatgc tacgccaaaa atagtaaaat g 41
<210> 91
<211> 41
<212> DNA
<213> 人工合成
<400> 91
gaaggtcgga gtcaacggat tacgccaaaa atagtaaaat a 41
<210> 92
<211> 25
<212> DNA
<213> 人工合成
<400> 92
ggggaggaaa taaagggtgt tgtgt 25
<210> 93
<211> 41
<212> DNA
<213> 人工合成
<400> 93
gaaggtgacc aagttcatgc tggtttatgt tcaggccaat g 41
<210> 94
<211> 41
<212> DNA
<213> 人工合成
<400> 94
gaaggtcgga gtcaacggat tggtttatgt tcaggccaat a 41
<210> 95
<211> 24
<212> DNA
<213> 人工合成
<400> 95
tctccccagt caaaaggtaa cctc 24
<210> 96
<211> 43
<212> DNA
<213> 人工合成
<400> 96
gaaggtgacc aagttcatgc tgcattgttc atttgttagc ttc 43
<210> 97
<211> 43
<212> DNA
<213> 人工合成
<400> 97
gaaggtcgga gtcaacggat tgcattgttc atttgttagc ttt 43
<210> 98
<211> 22
<212> DNA
<213> 人工合成
<400> 98
gtgaaccaac aataaccaag gc 22
<210> 99
<211> 44
<212> DNA
<213> 人工合成
<400> 99
gaaggtgacc aagttcatgc tgctgtgagg aacctaacac aacc 44
<210> 100
<211> 44
<212> DNA
<213> 人工合成
<400> 100
gaaggtcgga gtcaacggat tgctgtgagg aacctaacac aact 44
<210> 101
<211> 22
<212> DNA
<213> 人工合成
<400> 101
gttgcatagt tggtccaaat cc 22
<210> 102
<211> 41
<212> DNA
<213> 人工合成
<400> 102
gaaggtgacc aagttcatgc tacaagttgc caaagaattg t 41
<210> 103
<211> 41
<212> DNA
<213> 人工合成
<400> 103
gaaggtcgga gtcaacggat tacaagttgc caaagaattg a 41
<210> 104
<211> 26
<212> DNA
<213> 人工合成
<400> 104
ggcaacgcca tgaataactt acctta 26
<210> 105
<211> 46
<212> DNA
<213> 人工合成
<400> 105
gaaggtgacc aagttcatgc tctactagag tttcaaagca ttagaa 46
<210> 106
<211> 46
<212> DNA
<213> 人工合成
<400> 106
gaaggtcgga gtcaacggat tctactagag tttcaaagca ttagag 46
<210> 107
<211> 24
<212> DNA
<213> 人工合成
<400> 107
atggagacag tgaaattgag gctc 24
<210> 108
<211> 42
<212> DNA
<213> 人工合成
<400> 108
gaaggtgacc aagttcatgc tcctagtact atgatatgga cg 42
<210> 109
<211> 42
<212> DNA
<213> 人工合成
<400> 109
gaaggtcgga gtcaacggat tcctagtact atgatatgga ca 42
<210> 110
<211> 30
<212> DNA
<213> 人工合成
<400> 110
taggtatttc attggatatg ccaaaacgtc 30
<210> 111
<211> 40
<212> DNA
<213> 人工合成
<400> 111
gaaggtgacc aagttcatgc tgagagatac aagacaagac 40
<210> 112
<211> 40
<212> DNA
<213> 人工合成
<400> 112
gaaggtcgga gtcaacggat tgagagatac aagacaagaa 40
<210> 113
<211> 30
<212> DNA
<213> 人工合成
<400> 113
gtctttatgt aatcaattgc ttctttttga 30
<210> 114
<211> 46
<212> DNA
<213> 人工合成
<400> 114
gaaggtgacc aagttcatgc tcctggattc gttagccgtt ggattg 46
<210> 115
<211> 46
<212> DNA
<213> 人工合成
<400> 115
gaaggtcgga gtcaacggat tcctggattc gttagccgtt ggatta 46
<210> 116
<211> 22
<212> DNA
<213> 人工合成
<400> 116
gcacaaatga atcttgaacc ac 22
<210> 117
<211> 40
<212> DNA
<213> 人工合成
<400> 117
gaaggtgacc aagttcatgc tcgaccacaa aaaatgaggc 40
<210> 118
<211> 40
<212> DNA
<213> 人工合成
<400> 118
gaaggtcgga gtcaacggat tcgaccacaa aaaatgagga 40
<210> 119
<211> 24
<212> DNA
<213> 人工合成
<400> 119
acactatttt tcttattttt cccg 24
- 一种大豆高蛋白含量相关的分子标记和鉴定高蛋白含量大豆的方法
- 一种大豆高蛋白含量相关的分子标记和鉴定高蛋白含量大豆的方法