一种基于深度神经网络的视频人脸检测方法及系统
文献发布时间:2023-06-19 13:49:36
技术领域
本发明涉及基于深度神经网络的视频检测领域,具体涉及一种基于深度神经网络的视频人脸检测方法及系统。
背景技术
近几年随着互联网的飞速发展、信息量猛增及视频行业的崛起,大量政治敏感等不良信息夹杂其中。在海量的内容面前,视频审核面临巨大挑战,急需一种准确度高,识别速度快的检测方法。
发明内容
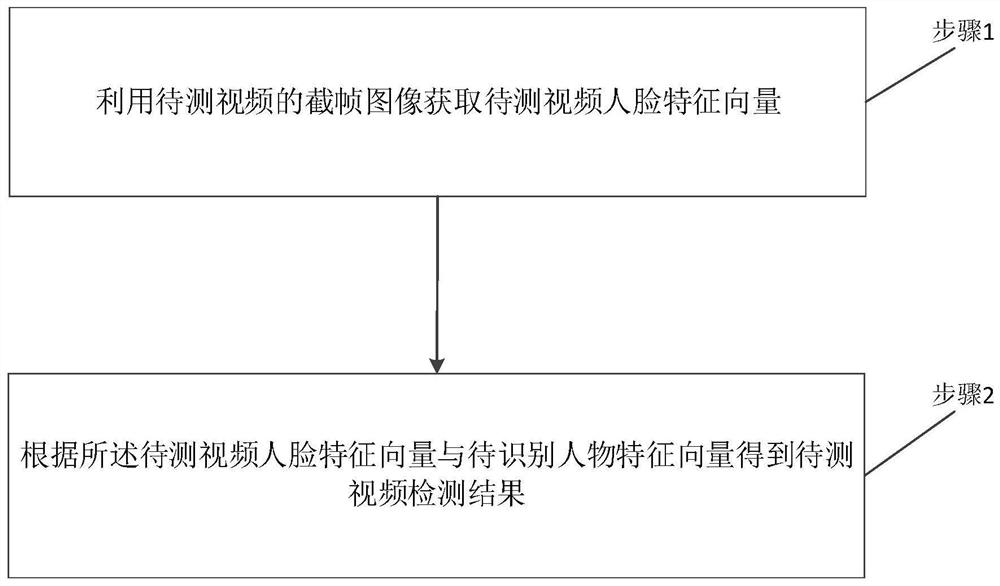
针对现有技术的不足,本发明提出了一种基于深度神经网络的视频人脸检测方法及系统,包括:
利用待测视频的截帧图像获取待测视频人脸特征向量;
根据所述待测视频人脸特征向量与待识别人物特征向量得到待测视频检测结果。
优选的,所述利用待测视频的截帧图像获取待测视频人脸特征向量包括:
判断待测视频的帧数是否大于预先设定的合理性阈值,若大于,则获取待测视频的截帧图像得到待测视频的截帧图像集合,否则,为无效视频放弃处理;
根据所述截帧图像集合内各截帧图像对应视频数据计算待测视频各截帧图像的时间戳;
将所述待测视频截帧图像集合中各截帧图像按比例划分带入预先训练的人脸图像分类模型后,基于DLIB算法得到人脸截帧图像特征向量;
其中,预先设定的合理性阈值为无法打开的视频的上限帧数,所述无法打开的视频的上限帧数为三帧。
进一步的,所述根据截帧图像集合内各截帧图像对应视频数据计算待测视频各截帧图像的时间戳的计算式如下:
其中,p
进一步的,所述按比例划分处理包括:
将图像按照最小边300至600dpi的范围进行调整处理。
进一步的,所述人脸图像分类模型的训练包括:
利用待测视频的截帧图像中包含人脸的截帧图像的方向梯度直方图特征建立正样本集合,待测视频的截帧图像中不包含人脸的截帧图像的方向梯度直方图特征建立负样本集合;
利用正样本集合与负样本集合基于支持向量机算法进行训练得到人脸图像分类初始模型;
判断人脸图像分类初始模型输出是否存在误检,若是,则获取误检的截帧图像的方向梯度直方图特征建立难例负样本集合,与正样本集合再次基于支持向量机算法进行训练,否则,得到人脸图像分类模型。
优选的,所述根据待测视频人脸特征向量与待识别人物特征向量得到待测视频检测结果包括:
获取待识别人物的不同图像进行按比例划分处理后,基于DLIB算法得到待识别人物特征向量集合;
获取所述人脸截帧图像特征向量与待识别人物特征向量集合中各特征向量的最小距离值;
根据所述最小距离值获取待测视频检测结果,并根据所述时间戳获取与其对应的截帧图像的视频。
优选的,所述获取人脸截帧图像特征向量与待识别人物特征向量集合中各特征向量的最小距离值包括:
利用人脸截帧图像特征向量与待识别人物特征向量集合中各特征向量基于欧式公式获取欧式距离值;
根据所述欧氏距离值计算人脸截帧图像特征向量与待识别人物特征向量集合中各特征向量的欧氏距离平均值;
利用所述欧式距离平均值计算人脸截帧图像特征向量与待识别人物特征向量的判断值;
获取所述判断值中最小值作为最小距离值。
进一步的,所述利用欧式距离平均值计算人脸截帧图像特征向量与待识别人物特征向量的判断值的计算式如下:
其中,t为人脸截帧图像特征向量与待识别人物特征向量的判断值,m为欧式距离平均值,X
进一步的,所述根据最小距离值获取待测视频检测结果包括:
判断所述最小距离值是否小于预先设定的检测阈值,若是,则待测视频的截帧图像与待识别的人物相同,否则,为不相同。
基于同一发明构思,本发明还提供了一种基于深度神经网络的视频人脸检测系统,其特征在于,包括:
采集模块,用于给利用待测视频的截帧图像获取待测视频人脸特征向量;
识别模块,用于根据所述待测视频人脸特征向量与待识别人物特征向量得到待测视频检测结果。
与最接近的现有技术相比,本发明具有的有益效果:
利用待测视频的截帧图像获取待测视频人脸特征向量;根据所述待测视频人脸特征向量与待识别人物特征向量得到待测视频检测结果,对视频进行快速有效截帧,可根据固定间隔时长,灵活截取不同帧数,更准确更高效的提取视频有效信息,对识别的图像按比例调整,既保证了识别准确率,又提升了人脸检测识别速度,通过计算更有效的距离值和阈值来判定分类,这样防止因奇异值导致分类错误,提升了识别准确率。
附图说明
图1是本发明提供的一种基于深度神经网络的视频人脸检测方法流程图;
图2是本发明提供的基于非极大值抑制法得到的人脸的矩形框及坐标值图;
图3是本发明提供的一种人脸特征点示意图;
图4是本发明提供的一种人脸特征点应用示意图;
图5是本发明提供的一种基于深度神经网络的涉政视频检测流程图;
图6是本发明提供的一种一种基于深度神经网络的视频人脸检测系统流程图。
具体实施方式
下面结合附图对本发明的具体实施方式作进一步的详细说明。
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
实施例1:
本发明提供了一种基于深度神经网络的视频人脸检测方法,如图1所示,包括:
步骤1:利用待测视频的截帧图像获取待测视频人脸特征向量;
步骤2:根据所述待测视频人脸特征向量与待识别人物特征向量得到待测视频检测结果。
本实施例中,一种基于深度神经网络的视频人脸检测方法,对传入的视频(视频支持"avi","wma","rmvb","mp4","wmv"格式)进行帧数提取。
步骤1具体包括:
1-1:判断待测视频的帧数是否大于预先设定的合理性阈值,若大于,则获取待测视频的截帧图像得到待测视频的截帧图像集合,否则,为无效视频放弃处理;
1-2:根据所述截帧图像集合内各截帧图像对应视频数据计算待测视频各截帧图像的时间戳;
1-3:将所述待测视频截帧图像集合中各截帧图像按比例划分带入预先训练的人脸图像分类模型后,基于DLIB算法得到人脸截帧图像特征向量;
其中,预先设定的合理性阈值为无法打开的视频的上限帧数。
本实施例中,一种基于深度神经网络的视频人脸检测方法,具体截帧可根据对视频长短及细化要求的不同选择不同间隔时间,即设定不同的时间间隔参数,1分钟以内为25帧、5分钟以内为50帧、30分钟以内为100帧、1小时以内为200帧、1小时以上为300帧,截取帧数越多,整体识别的时间会相对长一些,识别精度相对高一些,反之,截取帧数越少,整体识别的时间会相对少一些,识别精度相对低一些,因为可能存在漏掉部分图像,未截帧未检测到,视频截帧图片按数字顺序保存本地,如第一张00001.jpg,第二张00002.jpg等等,根据获取到的总帧数和每秒视频帧数,计算每张图片的时间戳,便于根据时间戳定位到识别结果所在视频中的位置。
本实施例中,一种基于深度神经网络的视频人脸检测方法,如图2所示,应用最终训练出的分类器检测人脸图片,对该图片利用滑动窗口算法进行滑动扫描,提取Hog特征,并用分类器分类。如果检测判定为人脸,则将其标定出来,经过一轮滑动扫描后必然会出现同一个人脸被多次标定的情况,就用非极大值抑制NMS方法完成收尾工作,即先将所有框的得分排序,选中最高分及其对应的框,再遍历其余的框,如果和当前最高分框的重叠面积(IOU)大于一定阈值,就将框删除,从未处理的框中继续选一个得分最高的,重复上述过程,最终得到人脸的矩形框及坐标值。
本实施例中,一种基于深度神经网络的视频人脸检测方法,如图3所示,使用dlib人脸特征点检测算法,可获取人脸的68个特征点,在检测到的人脸中,通过级联的残差回归树GBDT(One Millisecond Face Alignment with an Ensemble of Regression Trees)人脸对齐方法,找到68个人脸特征点,脸对齐的最终目的就是在已知的人脸方框上定位其准确地形状。
本实施例中,一种基于深度神经网络的视频人脸检测方法,如图4所示。
本实施例中,一种基于深度神经网络的视频人脸检测方法,预先设定的合理性阈值为无法打开的视频的上限帧数,选择800个视频文件进行实验测试,其中大部分为无法打开的视频,利用opencv读取800个视频文件的每一帧图片,当视频文件所有帧都可以打开,则视频文件可以打开;若打开视频文件部分帧可以读取,则视频文件也被认为可以打开,剩余无法的打开的视频中,有的一帧也无法读取,有的可以读取一帧,有的读取两帧,没有读到三帧的,所以按照此测试,经大量实验后得到无法打开的视频的上限帧数为三帧。
步骤1-1具体包括:
1-1-1:根据opencv算法获取视频的总帧数和每秒视频帧数。
1-1-2:根据视频总帧数和每秒视频帧数,通过设定截帧的时间间隔从第0秒开始截帧,同时可获得视频截帧总数:
其中,k为截帧数量,X为待测视频的总帧数,n为每秒视频的帧数,t为截帧的时间间隔,int为取整数。
步骤1-2具体包括:
其中,p
步骤1-3具体包括:
1-3-1:将图像按照最小边300至600dpi的范围进行调整处理。
1-3-:2:利用待测视频的截帧图像中包含人脸的截帧图像的方向梯度直方图特征建立正样本集合,待测视频的截帧图像中不包含人脸的截帧图像的方向梯度直方图特征建立负样本集合;
1-3-3:利用正样本集合与负样本集合基于支持向量机算法进行训练得到人脸图像分类初始模型;
1-3-4:判断人脸图像分类初始模型输出是否存在误检,若是,则获取误检的截帧图像的方向梯度直方图特征建立难例负样本集合,与正样本集合再次基于支持向量机算法进行训练,否则,得到人脸图像分类模型。
本实施例中,一种基于深度神经网络的视频人脸检测方法,对待测视频的截帧图像进行预处理,获取图片的大小,如果图片最小边大于600dpi,对图片长和宽遍历除以[8,7,6,5,4,3,2],直到得到的图片最小边大于300dpi,则停止遍历除法,保留图片,如果最小边小于600dpi,不进行处理,保证图片的最小边在300-600dpi之间,将处理过的图片带入DLIB算法进行人脸检测,得到人脸位置信息,查看图片检测到的人脸数量,如未检测到人脸返回空,如检测到人脸进行人脸特征点检测,将检测到的每一张人脸通过DLIB算法的GPU版本检测人脸特征点。
步骤2具体包括:
2-1:获取待识别人物的不同图像按比例划分处理后,基于DLIB人脸特征点检测算法得到待识别人物特征向量集合;
2-2:获取所述人脸截帧图像特征向量与待识别人物特征向量集合中各特征向量的最小距离值;
2-3:根据所述最小距离值获取待测视频检测结果,并根据所述时间戳获取待测视频截帧图像的视频数据。
步骤2-1具体包括:
2-1-1:将图像按照最小边300至600dpi的范围进行调整处理。
步骤2-2具体包括:
2-2-1:利用人脸截帧图像特征向量与待识别人物特征向量集合中各特征向量基于欧式公式获取欧式距离值;
2-2-2:根据所述欧氏距离值计算人脸截帧图像特征向量与待识别人物特征向量集合中各特征向量的欧氏距离平均值;
2-2-3:利用所述欧式距离平均值计算人脸截帧图像特征向量与待识别人物特征向量的判断值;
2-2-4:获取所述判断值中最小值作为最小距离值。
步骤2-1-1具体包括:
其中,d为欧氏距离值,(x,y)为人脸截帧图像特征向量,(x
步骤2-2-2具体包括:
其中,m为欧氏距离平均值,r为欧氏距离平均值的数量,d
步骤2-2-3具体包括:
其中,t为人脸截帧图像特征向量与待识别人物特征向量的判断值,m为欧式距离平均值,X
本实施例中,一种基于深度神经网络的视频人脸检测方法,如图5所示,取人脸截帧图像特征向量与待识别人物特征向量集合中各特征向量的欧氏距离平均值和最小值和的一半作为与该政治敏感人物的距离值,再将待检测图片与各个政治敏感人物的距离值排序,如最小值小于阈值,则待识别人物属于得分最少的政治敏感人物,否则,不属于政治敏感人物,为正常图片。
本实施例中,一种基于深度神经网络的视频人脸检测方法,最初计算出一组欧式距离之后,取平均值作为最终距离,这样存在因与某一张图片特别不像(出现奇异值),而拉远近似度,导致是同一人而识别错误,尝试取平均值和中位数的最小值作为距离值,但其实平均值和中位数值一般差不多,尝试取平均值和最小值和的一半作为距离值,最小值说明与目标人物最接近的程度,平均值代表与目标人物接近程度的平均水平,两者结合更能判定是否为同一人,根据取距离值后的大量测试结果得出一个阈值0.397,对包含某人物的4秒视频(涉及政治人物),截帧25张有三张因模糊和侧脸,识别正确但距离值大于0.4,其他识别正确且距离值在0.3左右;某人物8秒视频(涉及敏感人物)截帧26张,识别正确且距离值全部在0.3左右;某人物1分18秒视频(涉及敏感人物),截帧50张,有三个识别错误(将主持人识别成某人物)且距离值均大于0.397;及不包含政治人物敏感人物视频,1分55秒,截帧50张,识别正确,未检测出相关人物。再经过50张包含不同人物图片测试,其值均在0.3左右正确识别。取0.397之后应用中未出现错误。
实施例2:
本发明提供了一种基于深度神经网络的视频人脸检测系统,如图6所示,包括:
采集模块,用于利用待测视频的截帧图像获取待测视频人脸特征向量;
识别模块,用于根据所述待测视频人脸特征向量与待识别人物特征向量得到待测视频检测结果。
利用待测视频的截帧图像获取待测视频人脸特征向量;
根据所述待测视频人脸特征向量与待识别人物特征向量得到待测视频检测结果。
所述利用待测视频的截帧图像获取待测视频人脸特征向量包括:
判断待测视频的帧数是否大于预先设定的合理性阈值,若大于,则获取待测视频的截帧图像得到待测视频的截帧图像集合,否则,为无效视频放弃处理;
根据所述截帧图像集合内各截帧图像对应视频数据计算待测视频各截帧图像的时间戳;
将所述待测视频截帧图像集合中各截帧图像按比例划分带入预先训练的人脸图像分类模型后,基于DLIB算法得到人脸截帧图像特征向量;
其中,预先设定的合理性阈值为无法打开的视频的上限帧数。
所述根据截帧数量计算待测视频各截帧图像的时间戳的计算式如下:
其中,p
所述人脸图像分类模型的训练包括:
利用待测视频的截帧图像中包含人脸的截帧图像的方向梯度直方图特征建立正样本集合,待测视频的截帧图像中不包含人脸的截帧图像的方向梯度直方图特征建立负样本集合;
利用正样本集合与负样本集合基于支持向量机算法进行训练得到人脸图像分类初始模型;
判断人脸图像分类初始模型输出是否存在误检,若是,则获取误检的截帧图像的方向梯度直方图特征建立难例负样本集合,与正样本集合再次基于支持向量机算法进行训练,否则,得到人脸图像分类模型。
所述根据待测视频人脸特征向量与待识别人物特征向量得到待测视频检测结果包括:
获取待识别人物的不同图像按比例划分处理后,基于DLIB人脸特征点检测算法得到待识别人物特征向量集合;
获取所述人脸截帧图像特征向量与待识别人物特征向量集合中各特征向量的最小距离值;
根据所述最小距离值获取人脸截帧图像对应的时间戳得到待测视频检测结果。
所述按比例划分处理包括:
将图像按照最小边300至600dpi的范围进行调整处理。
所述获取人脸截帧图像特征向量与待识别人物特征向量集合中各特征向量的最小距离值包括:
利用人脸截帧图像特征向量与待识别人物特征向量集合中各特征向量基于欧式公式获取欧式距离值;
根据所述欧氏距离值计算人脸截帧图像特征向量与待识别人物特征向量集合中各特征向量的欧氏距离平均值;
利用所述欧式距离平均值计算人脸截帧图像特征向量与待识别人物特征向量的判断值;
获取所述判断值中最小值作为最小距离值。
所述利用人脸截帧图像特征向量与待识别人物特征向量集合中各特征向量计算欧式距离值的计算式如下:
其中,d为欧氏距离值,(x,y)为人脸截帧图像特征向量,(x
所述根据欧氏距离值计算人脸截帧图像特征向量与待识别人物特征向量集合中各特征向量的欧氏距离平均值的计算式如下:
其中,m为欧氏距离平均值,r为欧氏距离平均值的数量,d
所述利用欧式距离平均值计算人脸截帧图像特征向量与待识别人物特征向量的判断值的计算式如下:
其中,t为人脸截帧图像特征向量与待识别人物特征向量的判断值,m为欧式距离平均值,X
所述根据最小距离值获取人脸截帧图像对应的时间戳得到待测视频检测结果包括:
判断所述最小距离值是否小于预先设定的检测阈值,若是,则待测视频的截帧图像与待识别的人物相同,否则,为不相同。
本领域内的技术人员应明白,本发明的实施例可提供为方法、系统、或计算机程序产品。因此,本发明可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本发明可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、CD-ROM、光学存储器等)上实施的计算机程序产品的形式。
本发明是参照根据本申请实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
最后应当说明的是:以上实施例仅用以说明本发明的技术方案而非对其限制,尽管参照上述实施例对本发明进行了详细的说明,所属领域的普通技术人员应当理解:依然可以对本发明的具体实施方式进行修改或者等同替换,而未脱离本发明精神和范围的任何修改或者等同替换,其均应涵盖在本发明的权利要求保护范围之内。
- 一种基于深度神经网络的视频人脸检测方法及系统
- 基于关键帧人脸特征的人脸交换篡改视频检测方法、系统及介质