目标蛋白质的制造方法
文献发布时间:2023-06-19 18:32:25
技术领域
本发明涉及目标蛋白质的制造方法。
背景技术
为了提高食品的保存性、味道、口感等,使用了各种各样的酶。酶是原本存在于微生物、植物等天然生物体内或细胞外的蛋白质。酶通过微生物培养、细胞培养、植物栽培等进行工业生产、纯化并使用。另外,为了提高酶的生产率,有时通过基因重组使它们大量表达。
在自然界中,已知除了染色体DNA以外还具有质粒DNA的生物。将质粒DNA改良为用于人为表达目标蛋白质的载体而对宿主细胞赋予新功能的技术是普遍公知的。基于该基因重组的蛋白质表达通过将包含该蛋白质的基因的载体导入宿主细胞中,并对宿主细胞进行培养来进行。此处,对于宿主细胞来说,载体不过是不需要的外来因子,因此具有在持续培养的期间载体容易脱落的问题。为了避免该问题,开发出了在宿主细胞内稳定地维持载体的各种方法。
最广泛地用于稳定维持载体的方法是向载体中加入蛋白质的基因并导入抗生素抗性基因,在抗生素的存在下对宿主细胞进行培养的方法。由于宿主细胞没有抗生素抗性基因就不能存活,因此包含抗生素抗性基因的载体也能稳定地得到维持。但是,存在抗生素抗性基因混入到酶产品中的风险。另外,还有因抗生素抗性基因或抗生素本身流出到环境中而引起耐药菌产生的担忧。
因此,提出了一种在宿主细胞的生长达到一定程度以上时,将抗生素抗性基因从载体中选择性地切出而去除的方法(专利文献1~2)。除此以外,还已知:使宿主原本具有的必需基因从宿主中缺失,并将该基因导入至载体中的方法(专利文献3);将重组酶的识别序列导入至载体中的方法(非专利文献1~2);将表达对宿主细胞为有毒物质的基因保持在宿主的基因组中,并将对应的解毒用基因导入至载体中的方法(非专利文献3);等。
现有技术文献
专利文献
专利文献1:日本特表第2008-505620号公报
专利文献2:日本特表第2013-533743号公报
专利文献3:日本特表第2017-500042号公报
非专利文献
非专利文献1:Bo Zhang et al.PLoS ONE 8(2):e55906(2013)
非专利文献2:Yuan Yu et aL.PLoS ONE 8(5):e62457(2013)
非专利文献3:Sevillano et al.Microb Cell Fact(2017)16:164
发明内容
发明所要解决的课题
专利文献1~2的方法虽然能够降低抗生素的用量,但不能排除抗生素抗性基因混入酶产品的风险。专利文献3的方法需要使宿主细胞的必需基因缺失,非专利文献1~3的方法需要在载体中导入目标蛋白质以外的特定序列。本发明的课题在于提供一种不对宿主细胞进行特别的基因操作、不使用耐药基因等、在稳定维持载体的同时制造目标蛋白质的方法。
用于解决课题的手段
本发明人研究的结果发现,不对宿主细胞进行特别的基因操作,不使用耐药基因,就能够稳定地维持载体,由此完成了本发明。
即,本发明涉及一种制造方法,其为包括对用载体转化后的细胞进行培养的步骤的目标蛋白质的制造方法,其特征在于,上述载体包含目标蛋白质的基因,不包含抗生素抗性基因、重组酶的识别序列和细胞生存所必需的基因。
细胞生存所必需的基因优选为编码核糖体再循环因子的基因或编码翻译起始因子的基因。
上述细胞优选为细菌。
上述细菌优选为放线菌。
上述目标蛋白质优选为酶。
酶优选为磷脂酶、葡聚糖酶、蛋白酶、α-淀粉酶、β-淀粉酶、麦芽糖淀粉酶、葡聚糖1,4-α-麦芽三糖水解酶、葡聚糖1,4-α-麦芽六糖水解酶、纤维素酶、半纤维素酶、半乳糖脂肪酶、葡萄糖氧化酶、抗坏血酸氧化酶、过氧化物酶、脂氧合酶、过氧化氢酶、谷胱甘肽脱氢酶、肽酶、转谷氨酰胺酶、环糊精葡萄糖基转移酶、三酰基甘油脂肪酶、磷酸二酯酶、酯酶、胞壁质酶、磷酸酶、谷氨酰胺酶、壳聚糖酶或几丁质酶。
发明的效果
本发明的制造方法中,即使不对宿主细胞进行特别的基因操作、不使用耐药基因,也能够稳定地维持载体。能够排除抗生素抗性基因混入酶产品的风险、抗生素抗性基因流出到环境中的风险。
附图说明
图1示出实施例1中的目标蛋白质的检测结果。
图2示出实施例1中的对抗生素的敏感性的试验结果。
图3示出实施例2中的目标蛋白质的检测结果。
图4示出实施例2中的对抗生素的敏感性的试验结果。
图5示出实施例3中的载体的制作方法的概要。
图6示出实施例3中的目标蛋白质的检测结果。
具体实施方式
<目标蛋白质的制造方法>
本发明的目标蛋白质的制造方法的特征在于,其包括对用载体转化后的细胞进行培养的步骤,上述载体包含目标蛋白质的基因,不包含抗生素抗性基因、重组酶的识别序列和细胞生存所必需的基因。
在培养细胞的步骤中,对后述的用载体转化后的细胞进行培养。用于培养的培养基只要是含有细胞能够同化的碳源、氮源、无机盐类等、能够有效地进行细胞培养的培养基即可,可以使用天然培养基、合成培养基中的任一种。作为碳源,可以举出葡萄糖、半乳糖、果糖、木糖、蔗糖、棉子糖、淀粉等碳水化合物、乙酸、丙酸等有机酸、乙醇、丙醇等醇类。作为氮源,可以举出氨、氯化铵、硫酸铵、乙酸铵、磷酸铵等无机酸或有机酸的铵盐或者其他含氮化合物。此外,也可以使用蛋白胨、肉提取物、鱼肉提取物、玉米浆、酵母提取物、各种氨基酸等。作为无机物,可以举出磷酸二氢钾、磷酸氢二钾、磷酸镁、硫酸镁、氯化钠、硫酸亚铁、硫酸锰、硫酸铜、碳酸钙等。另外,根据需要也可以添加植物油、表面活性剂、硅等消泡剂。
在以上列举的物质中,优选以蛋白胨、鱼肉提取物、玉米浆或酵母提取物为主要成分的培养基,更优选包含酵母提取物的培养基。酵母提取物的浓度在培养基中优选为0.5~10重量%,更优选为1~5重量%。
培养条件根据培养基的种类、培养方法等适当选择即可,只要是细胞增殖、能够产生目标蛋白质的条件就没有特别限制。通常,在液体培养基中在振荡培养或通气搅拌培养等需氧条件下进行。振荡培养时的振荡速度优选为50~300rpm,更优选为100~200rpm。培养温度优选为25~35℃,更优选为27~30℃。pH优选为pH3.0~9.0,更优选为pH6.0~8.0。
培养时间优选为24~96小时,更优选为48~72小时。另外,也可以通过将培养液稀释10~250倍来进行传代培养。为了维持目标蛋白质的高纯度,传代次数优选为2~4次,但10次传代培养后也能够稳定地保持质粒。
目标蛋白质的制造方法优选在对细胞进行培养的步骤之后包括对目标蛋白质进行纯化的步骤。在对目标蛋白质进行纯化的步骤中,在目标蛋白质蓄积于细胞内的情况下,通过离心分离或过滤器过滤回收细胞,通过超声波处理等将回收的细胞破碎后,通过离心分离、或使用硅藻土或纤维素粉末等过滤助剂的固液分离等而得到无细胞提取液。将其作为起始材料,可以通过盐析法、离子交换色谱法、凝胶过滤色谱法、疏水色谱法、亲和色谱法等各种色谱法等一般的蛋白纯化法来对目标蛋白质进行纯化。在目标蛋白质被分泌到细胞外的情况下,可以代替无细胞提取液而使用培养上清同样地进行纯化。
<细胞>
细胞只要是能够表达目标蛋白质的细胞就没有特别限定,可以使用微生物细胞、动物细胞、植物细胞中的任一种。从目标蛋白质的生产率和培养容易性的方面出发,优选微生物细胞,更优选细菌。
作为细菌,可以举出链霉菌(Streptomyces)属、红球菌(Rhodococcus)属等宿主载体系的已开发的放线菌;埃希氏菌(Escherichia)属、芽胞杆菌(Bacillus)属、假单胞菌(Pseudomonas)属、沙雷氏菌(Serratia)属、短杆菌(Brevibacterium)属、棒状杆菌(Corynebacterium)属、链球菌属(Streptococcus)属、乳酸杆菌(Lactobacillus)属等宿主载体系的已开发的细菌。此外,可以举出酵母菌(Saccharomyces)属、克鲁维酵母菌(Kluyveromyces)属、裂殖酵母(Schizosaccharomyces)属、接合酵母菌(Zygosaccharomyces)属、亚罗酵母(Yarrowia)属、毛孢子菌(Trichosporon)属、红冬孢酵母(Rhodosporidium)属、毕赤酵母(Pichia)属、假丝酵母(Candida)属等宿主载体系的已开发的酵母;脉孢菌(Neurospora)属、曲霉菌(Aspergillus)属、头孢霉(Cephalosporium)属、木霉菌(Trichoderma)属等宿主载体系的已开发的霉菌等。这些之中,优选放线菌,更优选链霉菌属。
作为链霉菌属,可以举出变铅青链霉菌(Streptomyces lividans)、紫红链霉菌(Streptomyces violaceoruber)、肉桂链霉菌(Streptomyces cinnamoneus)、阿维链霉菌(Streptomyces avermetilis)、热紫链霉菌(Streptomyces thermoviolaceus)、霍耳斯特德氏链霉菌(Streptomyces halstedii)等。
作为变铅青链霉菌的具体菌株,可以举出变铅青链霉菌1326株。该菌株的别名为紫红链霉菌(Streptomyces violaceoruber)1326株,其培养物或纯化物用于食品时的安全性已得到了确认。
作为埃希氏菌属,可以举出大肠埃希氏菌(Escherichia coli)。
作为动物细胞,可以举出来自人、小鼠、大鼠、狗、猴、中国仓鼠、果蝇、夜蛾、粉纹夜蛾等的细胞。作为植物细胞,可以举出来自烟草、玉米、水稻等的细胞。
上述细胞可以是原本就表达目标蛋白质的细胞,也可以是原本不表达目标蛋白质的细胞。在原本就表达目标蛋白质的细胞的情况下,也可以通过用载体进行转化来提高目标蛋白质的生产率。
<载体>
载体只要能够在细胞内表达目标蛋白质即可,作为具体形态,可以举出质粒载体、噬菌体载体、粘粒载体等。从转化的容易性的方面出发,优选质粒载体。载体包括后述的目标蛋白质的基因序列等在内的全长优选为3,000~10,000bp、优选为4,500~6,500bp。全长若超过10,000bp,则具有在细胞内变得不稳定的倾向;若小于3,000bp,则可使用的目标蛋白质的基因序列的长度受到限制。
<目标蛋白质>
目标蛋白质只要能够在细胞内表达即可,没有特别限定,可以举出酶、激素、受体、胶原蛋白等结构蛋白、血红蛋白等运载蛋白、肌球蛋白等收缩蛋白等。这些之中,出于容易适用于食品的原因,优选酶。
作为酶,可以举出磷脂酶、葡聚糖酶、蛋白酶、α-淀粉酶、β-淀粉酶、麦芽糖淀粉酶、葡聚糖1,4-α-麦芽三糖水解酶、葡聚糖1,4-α-麦芽六糖水解酶、纤维素酶、半纤维素酶、半乳糖脂肪酶、葡萄糖氧化酶、抗坏血酸氧化酶、过氧化物酶、脂氧合酶、过氧化氢酶、谷胱甘肽脱氢酶、肽酶、转谷氨酰胺酶、环糊精葡萄糖基转移酶、三酰基甘油脂肪酶、磷酸二酯酶、酯酶、胞壁质酶、磷酸酶、谷氨酰胺酶、壳聚糖酶、几丁质酶等。这些之中,优选磷脂酶、葡聚糖酶、蛋白酶。
作为编码磷脂酶的DNA,可以举出下述(a)、(b)或(c)的DNA。
(a)包含序列表的序列号1所示的碱基序列的DNA;
(b)与序列表的序列号1所示的碱基序列显示出85%以上的序列一致性、编码具有磷脂酶活性的多肽的DNA;
(c)由序列表的序列号1所示的碱基序列中1个或2个以上的碱基发生缺失、插入、置换和/或添加而成的碱基序列构成、编码具有磷脂酶活性的多肽的DNA。
与序列号1所示的碱基序列的序列一致性优选为90%以上、更优选为95%以上、进一步优选为98%以上。
序列表的序列号1所示的碱基序列中,发生缺失、插入、置换和/或添加的碱基的数量优选为243个以下、更优选为162个以下、进一步优选为81个以下、进而更优选为32个以下、特别优选为20个、10个、5个、4个、3个、或2个以下。
作为编码葡聚糖酶的DNA,可以举出下述(a)、(b)或(c)的DNA。
(a)包含序列表的序列号2所示的碱基序列的DNA;
(b)与序列表的序列号2所示的碱基序列显示出85%以上的序列一致性、编码具有葡聚糖酶活性的多肽的DNA;
(c)由序列表的序列号2所示的碱基序列中1个或2个以上的碱基发生缺失、插入、置换和/或添加而成的碱基序列构成、编码具有葡聚糖酶活性的多肽的DNA。
与序列号2所示的碱基序列的序列一致性优选为90%以上、更优选为95%以上、进一步优选为98%以上。
序列表的序列号2所示的碱基序列中,发生缺失、插入、置换和/或添加的碱基的数量优选为179个以下、更优选为119个以下、进一步优选为59个以下、进而更优选为23个以下、特别优选为20个、10个、5个、4个、3个、或2个以下。
作为激素,可以举出生长激素、促卵泡激素、胰岛素、降血钙素等。
<复制起始序列>
载体需要具有复制起始序列,以在细胞内维持和扩增。作为复制起始序列,可以举出来自质粒载体pIJ101的复制起始序列、来自质粒载体pSG5的复制起始序列、来自质粒载体SLP2的复制起始序列等。这些之中,优选来自pIJ101的复制起始序列。复制起始序列的长度优选为500~2000bp、更优选为1000~1500bp。
<启动子序列>
载体在编码目标蛋白质的基因中具有启动子序列。启动子序列可以是目标蛋白质原本具有的启动子,也可以是异源启动子。在使用异源启动子的情况下,作为该启动子的来源基因,可以举出金属内肽酶基因、磷脂酶D(PLD)基因、木糖异构酶基因、木聚糖酶基因、淀粉酶基因、蛋白酶基因等。这些之中,优选来自金属内肽酶基因、磷脂酶D(PLD)基因的启动子序列。启动子序列的长度优选为50~2000bp、更优选为60~400bp。
作为具有来自金属内肽酶基因的启动子序列的DNA,可以举出下述(a)、(b)或(c)的DNA。
(a)包含序列表的序列号3所示的碱基序列的DNA;
(b)与序列表的序列号3所示的碱基序列显示出85%以上的序列一致性、在细胞内诱导目标蛋白质的表达的DNA;
(c)由序列表的序列号3所示的碱基序列中1个或2个以上的碱基发生缺失、插入、置换和/或添加而成的碱基序列构成、在细胞内诱导目标蛋白质的表达的DNA。
与序列号3所示的碱基序列的序列一致性优选为90%以上、更优选为95%以上、进一步优选为98%以上。
在序列表的序列号3所示的碱基序列中,发生缺失、插入、置换和/或添加的碱基的数量优选为44个以下、更优选为29个以下、进一步优选为14个以下、进而更优选为5个以下、特别优选为4个、3个或2个以下。
作为具有来自磷脂酶D(PLD)基因的启动子序列的DNA,可以举出下述(a)、(b)或(c)的DNA。
(a)包含序列表的序列号4所示的碱基序列的DNA;
(b)与序列表的序列号4所示的碱基序列显示出85%以上的序列一致性、在细胞内诱导目标蛋白质的表达的DNA;
(c)由序列表的序列号4所示的碱基序列中1个或2个以上的碱基发生缺失、插入、置换和/或添加而成的碱基序列构成、在细胞内诱导目标蛋白质的表达的DNA。
与序列号4所示的碱基序列的序列一致性优选为90%以上、更优选为95%以上、进一步优选为98%以上。
序列表的序列号4所示的碱基序列中,发生缺失、插入、置换和/或添加的碱基的数量优选为10个以下、更优选为7个以下、进一步优选为3个以下、进而更优选为1个以下。
<终止子序列>
载体在编码目标蛋白质的基因中具有用于使转录停止的终止子序列。终止子序列可以是目标蛋白质原本具有的终止子,也可以是异源终止子。在使用异源终止子的情况下,作为该终止子的来源基因,可以举出磷脂酶D(PLD)基因、金属内肽酶基因、淀粉酶基因等。这些之中,优选来自磷脂酶D(PLD)基因的终止子序列。
作为具有来自磷脂酶D(PLD)基因的终止子序列的DNA,可以举出下述(a)、(b)或(c)的DNA。
(a)包含序列表的序列号5所示的碱基序列的DNA;
(b)与序列表的序列号5所示的碱基序列显示出85%以上的序列一致性、在细胞内使目标蛋白质的基因转录停止的DNA;
(c)由序列表的序列号5所示的碱基序列中1个或2个以上的碱基发生缺失、插入、置换和/或添加而成的碱基序列构成、在细胞内使目标蛋白质的基因转录停止的DNA。
与序列号5所示的碱基序列的序列一致性优选为90%以上、更优选为95%以上、进一步优选为98%以上。
序列表的序列号5所示的碱基序列中,缺失、插入、置换和/或添加的碱基的数量优选为30个以下、更优选为20个以下、进一步优选为10个以下、进而更优选为4个以下、特别优选为3个或2个以下。
<抗生素抗性基因等>
本发明中使用的载体的特征在于,不包含抗生素抗性基因、重组酶的识别序列和细胞生存所必需的基因。
在使用抗生素抗性基因的情况下,由于在培养基中添加抗生素来作为选择压力,因此抗生素本身或抗生素抗性基因向环境中流出,引起耐药菌的产生。本发明中使用的载体不包含抗生素抗性基因,因此可以排除这些风险。作为抗生素抗性基因,是指维持了分解抗生素的活性、抑制抗生素作用的活性的基因。作为此处所说的抗生素,可以举出硫链丝菌素、青霉素、卡那霉素、万古霉素、红霉素、紫霉素、新霉素、链霉素、四环素、氯霉素等。
重组酶的识别序列用于在专利文献1~2、非专利文献1~2中将抗生素抗性基因从载体中选择性地切出而去除。作为这样的重组酶,可以举出Cre、Flp、R、XerC、XerD、RipX、CodV等。另外,作为重组酶的识别序列,可以举出转座酶靶位点、Ecdif、cer、psi、pif、mwr、Bsdif、loxP、FRT、RS等。
细胞生存所必需的基因在专利文献3中通过导入载体中来代替使其从宿主细胞中缺失而稳定地维持了载体。作为这样的基因,可以举出编码核糖体再循环因子的基因、编码翻译起始因子的基因、编码毒素-抗毒素系统的基因等。
<载体的制造和细胞的转化>
本发明中使用的载体是通过利用公知的方法将上述目标蛋白质的基因、复制起始序列、启动子序列等连结而得到的。作为连结方法,可以举出利用限制酶切割和利用DNA连接酶连接的连结方法。被限制酶切割的DNA可以为质粒DNA,也可以为PCR产物。
转化方法只要能够将载体导入至细胞中就没有特别限定。可以使用电穿孔法、原生质体-PEG法、氯化钙法、粒子枪法等公知的方法。转化后,可以通过菌落PCR等公知的方法来确认细胞中载体的存在。另外,来自细胞的目标蛋白质的表达可以通过SDS-PAGE来确认。
实施例
下面举出实施例来说明本发明,但本发明不限定于下述实施例。以下,除非另外说明,“份”或“%”分别是指“重量份”或“重量%”。
<实施例1>限制酶处理导致的耐药基因的缺失
<质粒DNA的分离>
将葡聚糖酶生产菌株紫红链霉菌pGlu株在胰蛋白酶大豆培养基(BectonDickinson公司制造)5mL中于28℃培养3天,进行集菌。表达质粒pGlu的提取使用QIAprepMiniprep试剂盒(QIAGEN公司制造)来制备。其中,在缓冲液P1中按照最终浓度为2.5mg/mL的方式加入溶菌酶(Sigma公司制造),将pGlu株的菌体悬浮于含溶菌酶的缓冲液P1中,在该状态下于37℃静置30分钟后,根据所附说明书进行表达质粒pGlu的提取。
<表达质粒制作和宿主细胞的转化>
用限制酶PvuII和EcoRV消化所提取的pGlu质粒。将所得到的片段连接后,导入变铅青链霉菌1326株中,制作转化体。
<酶生产菌株的筛选>
转化后的各菌落移植到胰蛋白酶大豆琼脂培养基(Becton Dickinson公司制造)中,于28℃培养3天。使一接种环的菌体分散于0.1N NaOH水溶液10μL中,在95℃加热处理15分钟。将该溶液作为模板进行PCR反应。根据表达质粒的复制因子rep pIJ101基因的碱基序列设计出正义引物(序列号6)、反义引物(序列号7)。PCR反应液组成如下。GO Taq(Bio-Rad公司制造)3μL、100μM正义引物0.05μL、100μM反义引物0.05μL、按总量为10μL的方式添加蒸馏水。PCR反应条件如下。步骤1:98℃、3分钟;步骤2:98℃、15秒;步骤3:50℃、30秒;步骤4:72℃、1分钟。步骤2至步骤4重复30次。通过该PCR,在48个菌落中的4个菌落得到约500bp的特异性扩增产物。
将上述得到了扩增产物的转化体移植到装于经121℃、20分钟高压釜灭菌的试管中的胰蛋白酶大豆培养基(Becton Dickinson公司制造)6mL中,于28℃以300rpm往返振荡培养3天。将培养液1mL离心分离(10,000rpm、10分钟、室温)后,弃去上清,使用菌体沉淀物与上述同样地进行质粒提取。
另外,将胰蛋白酶大豆培养基中的培养液移植到酶生产培养基6mL中,于28℃以300rpm培养3天。培养液进行离心分离,上清供至十二烷基硫酸钠-聚丙烯酰胺电泳(SDS-PAGE),由此确认了酶生产。按照SDS-PAGE法,使用Bio-Rad制聚丙烯酰胺凝胶(商品名Criterion TGX Stain-Free Any kD预制凝胶),在200V固定电压下进行电泳,利用凝胶拍摄装置(商品名Gel Doc RZ Imager、Bio-Rad制Stain-Free系统)拍摄泳动图像(图1、表1)。
<硫链丝菌素敏感性的确认>
将确认了酶生产的筛选菌株涂布到包含硫链丝菌素(50ppm)的胰蛋白酶大豆琼脂培养基上,于28℃培养3天(图2、表1)。
<酶生产筛选菌株的表达质粒的碱基序列的确认>
对于确认了酶生产并为硫链丝菌素敏感性的筛选菌株,利用与上述同样的方法制备质粒DNA,利用DNA测序仪进行分析,确定碱基序列。其结果示于表1。
【表1】
菌落No.1、17和26通过限制酶的作用缺失了tsr基因的一部分,实际上未显示出耐药性。菌落No.38维持了tsr基因,为耐药性。
<实施例2>PCR导致的耐药基因的缺失
将由葡聚糖酶生产菌株紫红链霉菌pGlu株提取的质粒DNA作为模板,进行以下的PCR反应。
设计出添加有EcoRV位点的正义引物(序列号8)、添加有EcoRV位点的反义引物(序列号9)。PCR反应液组成如下。在10×PCR KOD-plus缓冲液(东洋纺公司制造)5μL、引物各300nM、dNTP混合物各0.2mM、MgSO4 1mM、DMSO 5%和KOD-plus-DNA聚合酶1.0单位中,按照总量为50μL的方式添加蒸馏水。PCR反应条件如下。步骤1:98℃、2分钟;步骤2:98℃、15秒;步骤3:60℃、30秒;步骤4:68℃、5分钟。步骤2至步骤4重复30次。通过该PCR,得到约5Kbp的特异性扩增产物。用EcoRV消化该扩增的片段,连接后导入至变铅青链霉菌1326株中,制作转化体。
对于转化体,与实施例1同样地,利用菌落PCR法进行质粒DNA的检测,利用SDS-PAGE进行蛋白质产生的检测,进行琼脂培养基中的硫链丝菌素敏感性的确认,筛选出酶生产菌株。用DNA测序仪分析筛选出的酶生产菌株的质粒DNA,确定碱基序列。其结果,转化体表达葡聚糖酶(图3),并且为硫链丝菌素敏感性(图4)。
<酶生产菌株的质粒保持能力的评价>
在500mL带挡板烧瓶中移植胰蛋白酶大豆培养基(Becton Dickinson公司制造)50mL,将转化体在28℃下以160rpm振荡培养3天。将该培养液0.5mL再次移植到含有胰蛋白酶大豆培养基50mL的烧瓶中,同样地进行培养。重复10次该操作。将各培养液0.1mL涂布到胰蛋白酶大豆琼脂培养基(Becton Dickinson公司制造)上,于28℃培养3天。随机地选择24个出现的菌落,进行上述菌落PCR法,由观察到扩增物的数量计算出质粒保持率。其结果示于表2。
【表2】
转化体在重复10次28℃下3天的培养后,质粒保持率也极高,为96%。另外,通过10次培养,质粒保持率维持为70%以上。
<实施例3>PCR和限制酶处理导致的耐药基因的缺失
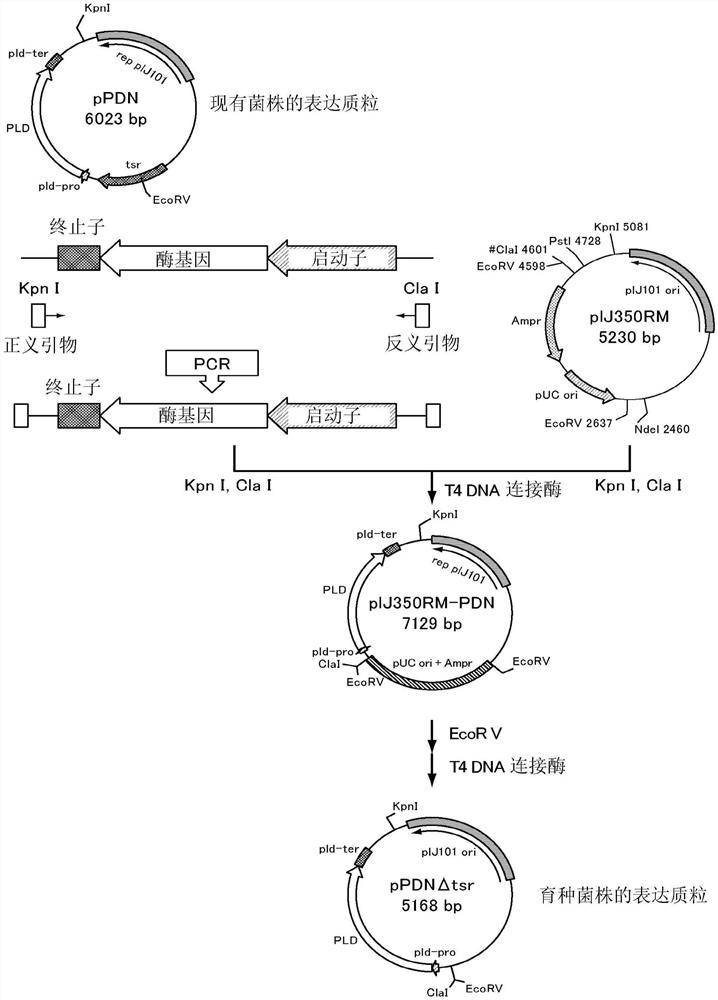
<不含硫链丝菌素耐性基因的载体的制作>
利用下述方法将以放线菌质粒pIJ702为模板而得到的PCR片段与以大肠杆菌用质粒pBluescript II KS+为模板而得到的PCR片段连接,制作出不含硫链丝菌素耐性基因的载体。
以放线菌质粒pIJ702为模板,设计出添加有EcoRV位点的正义引物(序列号10)、添加有EcoRV位点的反义引物(序列号11)。PCR反应液组成如下。在10×PCR KOD-plus缓冲液(东洋纺公司制造)5μL、引物各300nM、dNTP混合物各0.2mM、MgSO4 1mM、DMSO 5%和KOD-plus-DNA聚合酶1.0单位中,按照总量为50μL的方式添加蒸馏水。PCR反应条件如下。步骤1:98℃、2分钟;步骤2:98℃、15秒;步骤3:60℃、30秒;步骤4:68℃、3分钟。步骤2至步骤4重复30次。通过该PCR,得到约3kbp的特异性扩增产物。用EcoRV消化该扩增的片段。
以大肠杆菌用质粒pBluescript II KS+为模板,设计出添加有EcoRV位点的正义引物(序列号12)、添加有EcoRV位点的反义引物(序列号13)。PCR反应液组成如下。在10×PCR KOD-plus缓冲液(东洋纺公司制造)5μL、引物各300nM、dNTP混合物各0.2mM、MgSO41mM、DMSO 5%和KOD-plus-DNA聚合酶1.0单位中,按照总量为50μL的方式添加蒸馏水。PCR反应条件如下。步骤1:98℃、2分钟;步骤2:98℃、15秒;步骤3:60℃、30秒;步骤4:68℃、3分钟30秒。步骤2至步骤4重复30次。通过该PCR,得到约3.3kbp的特异性扩增产物。用EcoRV消化该扩增的片段。连接两片段,导入至大肠杆菌JM109株中,制作出转化体。将该转化体中包含的质粒作为pIJ350RM。pIJ350RM是放线菌和大肠杆菌的穿梭载体。
<放线菌酶生产菌株的制作方法>
将由磷脂酶D生产菌株紫红链霉菌pPDN株提取的质粒DNA作为模板,进行下述PCR反应。
设计出添加有KpnI位点的正义引物(序列号14)、添加有ClaI位点的反义引物(序列号15)。PCR反应液组成如下。在10×PCR KOD-plus缓冲液(东洋纺公司制造)5μL、引物各300nM、dNTP混合物各0.2mM、MgSO4 1mM、DMSO 5%和KOD-plus-DNA聚合酶1.0单位中,按照总量为50μL的方式添加蒸馏水。PCR反应条件如下。步骤1:98℃、2分钟;步骤2:98℃、15秒;步骤3:60℃、30秒;步骤4:68℃、2分钟。步骤2至步骤4重复30次。通过该PCR,得到约5kbp的特异性扩增产物。用KpnI和ClaI消化该扩增的片段。另一方面,将新制作的载体pIJ350RM用KpnI和ClaI进行消化。连接两片段后,导入至大肠杆菌JM109株中,制作出转化体。将该转化体中包含的质粒作为pIJ350RM-PDN。
用EcoRV消化由大肠杆菌JM109株的转化体提取的质粒DNA(pIJ350RM-PDN),连接后导入至变铅青链霉菌1326株中,制作出转化体。将该转化体中包含的质粒作为pPDNΔtsr(图5)。
<酶生产菌株的筛选>
通过与实施例1~2同样的操作筛选出酶生产菌株。对于筛选菌株,利用与上述同样的方法制备质粒DNA,利用DNA测序仪进行分析,确定碱基序列。另外,将用SDS-PAGE确认蛋白质产生的结果示于图6。育种菌株在50kDa的位置确认到磷脂酶D(图6)的条带。
序列表
<110> 长濑化成株式会社(Nagase ChemteX Corporation)
<120> 目标蛋白质的制造方法(METHOD FOR PRODUCING A PROTEIN OF INTEREST)
<130> FFP2021-1
<150> JP 2020-102499
<151> 2020-06-12
<160> 15
<170> PatentIn version 3.5
<210> 1
<211> 1623
<212> DNA
<213> 未知
<220>
<223> 磷脂酶
<400> 1
atgctccgcc accggctccg ccgtttacac cgtctgaccc gcagtgcggc ggtctcggcc 60
gtcgtcctgg ccgccctgcc cgcggctccg gccttcgcga gcagcccctc gcccgccccg 120
cacctggacg ccgtggagaa ggcgctgcgc gaggtctcac cggggctgga gggtgacgtc 180
tggcagcgca ccgacggcaa caagctggac gcctccgccg cggacccctc cgactggctg 240
ctgcagaccc ccggttgctg gggcgacgcc gcgtgcaagg agcgtcccgg caccgagcgc 300
ctgctcgcca aggtgacgga gaacatctcc aaggccaggc gcacggtgga catctccacg 360
ctcgcgccct tcccgaacgg tgcgttccag gacgcgatag ccgccggcct caaggcgtcg 420
gtcgcgtccg gcaacaagcc gaaggtccgc gtcctggtcg gcgccgcgcc ggtctaccac 480
atgaacgtac tgccctcgaa gtaccgggac gacctcaagg cccggctcgg caaggccgcc 540
gacgacatca cgctgaacgt cgcgtcgatg acgacgtcga agaccagctt ctcctggaac 600
cactccaagc tcctcgtcgt ggacggcgag tcggccgtca ccggtggcat caacagctgg 660
aaggacgact acgtcgacac ccagcacccg gtgaccgacg tggacctggc gctgaccggc 720
cccgccgcga gctccgccgg ccgctacctg gacacgctct ggacgtggac gtgccagaac 780
aagagcaaca tcgccagtgt gtggttcgcg gcctcgggcg gcgactgcat ggccacgatg 840
gagaaggacg cgaaccccag gcccgccggg cccacgggca acgtccccgt gatcgccgtg 900
ggcggcctcg gcgtcggcat caaggactcc gaccccgcct ggacgttccg cccgcagctg 960
ccctccgccc cggacaccaa gtgcgtcgtc ggcctgcccg acaagaccaa cgccgaccgt 1020
gactacgaca cggtcaaccc cgaggagagc gccctgcggg ccctggtggc cagcgccgac 1080
cgccagatcg tcatctccca gcaggacctg aacgccacct gcccgcccat cgcccgctac 1140
gacgtccgcc tctacgacat cctcgccgcc aagatggcgg ccggggtgaa ggtgcgcatc 1200
gtcgtcagcg accccgccaa ccgcggcgcg gtcggcagcg gcggctactc gcaaatcaag 1260
tccctggccg agatcagcga cacgctccgc aaccgtctcg ccctgctcaa gggcggcgac 1320
cagcagaagg ccaaggcggc catgtgctcc accctccagc tggggacctt ccgcagctcc 1380
gcgagcgcca cgtgggccga cgggcacccc tacgccctgc accacaagct ggtggcggtc 1440
gacagctccg ccttcaacat cggctccaag aacctctacc cctcgtggct gcaggacttc 1500
ggctacatcg tggagagccc ggaggccgcc aagcagcttg aggccaagct cctcgacccc 1560
gagtggaagt tctcgcagga gaccgcgacg gtcgaccacg cgcggggcgt ctgctcgctc 1620
tga 1623
<210> 2
<211> 1197
<212> DNA
<213> 未知
<220>
<223> 葡聚糖酶
<400> 2
atgctctccc gactcagaca ccgtctgctc gccgtggccg cggccgcagg cctgaccggc 60
gccctgctct cgttcggcgc cgcaccgccc gcggacgccg cggtgcccgc caccatcccc 120
ctgaagatca ccaacaactc cgctcgtggc gacgccgtcc acatctacaa cctgggcacc 180
tcgctgacga ccggtcagca gggctgggcg gacgagaacg gaaccttcca cgcctggccc 240
gccggcggca atccccccac tcccgcaccg gacgcgtcca tccctggacc ggccgcggga 300
cagaccaaga ccatccggat cccgaagctg tcgggacgca tctacttctc ctacggccag 360
aagctggact tccggctcac caccggcggc ctggtccagc ccgccgtgca gaaccccagc 420
gaccccaacc gcaacatcct cttcaactgg tccgagtaca cgctcaacga cggcgggctg 480
tggctgaaca gcacccaggt cgacatgttc tccgcgccct acacggtcgg cgtgcagcgc 540
gccgacggcg gcgtgaccag cgccggacag ctcaaggccg gtggctaccg cggggtgttc 600
gacgcgctgc gggcccagcc gggctggggc gggctgatcc agacccggcc cgacggcacc 660
gtactgcggg cgctggcgcc gctgtacggg gtggagaccg gggcgctgcc cgcgtcggtc 720
atggacgact acatcaaccg ggtctggcag aagtacacga cgaccacgct caccgtcacg 780
cccttcggcg accgtccgga caccaagtac ttcggacgcg tctcgggcaa cgtcatgaac 840
ttcaccaaca cctccggcgc ggtcgtcacc agcttccaga agccggacgc ctccagcgtc 900
ttcggctgcc accggctcct ggacgcgccc aacgaccagg tgcgcgggcc gatctcgcgc 960
acgctgtgcg ccggcttcaa ccgctcgacg ctgctgagca accccaacca gcccgatccc 1020
tcggcggcga acttctaccg ggacccggtg accaaccact acgcccggat catccacgag 1080
cgcatggccg acgggaaggc gtacgcgttc gccttcgacg acgtcggcaa ccacgagtcg 1140
ctggtgcacg acggcaaccc ggccgaggcg aggctcacgc tcgccccgct cgactga 1197
<210> 3
<211> 298
<212> DNA
<213> 未知
<220>
<223> 金属内肽酶启动子
<400> 3
caggactgct caggtgcgtt ttcgtatgcc cgaacgcgcc cggacgactc cccgaacccg 60
tccggtattt gagacgcgcc cacagggcgc cggggtgcca cgaaacaaac ccccgtccca 120
gttcaccgca tagcggaacc aaacaaccgc actccggaga acgggagatc aaatccttgt 180
tgcgcccctg tcaatgacgc ccaaacaatg gcactctctc ctcaattcgc tcctgcacca 240
cacctgcacc acagggcggt cgtacaaccg gctgctccaa cccccctcat aggagaca 298
<210> 4
<211> 72
<212> DNA
<213> 未知
<220>
<223> 磷脂酶启动子
<400> 4
ggctcccggg agctgatagc ttctccgcgt tgatcttccg ttcgcggaat cgttacttcg 60
tttaaggatg ca 72
<210> 5
<211> 206
<212> DNA
<213> 未知
<220>
<223> 磷脂酶终止子
<400> 5
gcatgcgacg actgagcgcc cggacgttcc ggggcgcatg acgggggaat gcccgtaccg 60
ctgaggtacg ggcattcccc cgttcgctca tataactacg ttcgaatatc ggggaatgat 120
ccgatcgtct tcactccata gtgaacggat ttcattccgt gtcgctccgg atgcaaccat 180
gcgctggccc cgaaccgacc ggaaat 206
<210> 6
<211> 30
<212> DNA
<213> 人工序列
<220>
<223> 正义引物
<400> 6
ctctcgccgt cggcgtgcag ttgcttcctc 30
<210> 7
<211> 30
<212> DNA
<213> 人工序列
<220>
<223> 反义引物
<400> 7
catggacgcc ctccagggca cccggaagag 30
<210> 8
<211> 30
<212> DNA
<213> 人工序列
<220>
<223> 正义引物
<400> 8
ggaattccag gactgctcag gtgcgttttc 30
<210> 9
<211> 30
<212> DNA
<213> 人工序列
<220>
<223> 反义引物
<400> 9
ggaattctcc tggggtgtga caccctacgc 30
<210> 10
<211> 34
<212> DNA
<213> 人工序列
<220>
<223> 正义引物
<400> 10
ggtggggata tcggtcgtcc taccggctgc tgtg 34
<210> 11
<211> 36
<212> DNA
<213> 人工序列
<220>
<223> 反义引物
<400> 11
ggtggggata tcgatcaccc ccgacagcgg atcaag 36
<210> 12
<211> 31
<212> DNA
<213> 人工序列
<220>
<223> 正义引物
<400> 12
ggttcggcga tatcagctca ctcaaaggcg g 31
<210> 13
<211> 43
<212> DNA
<213> 人工序列
<220>
<223> 反义引物
<400> 13
ggaattcccg gctcgcgata tcccgatttc ggcctattgg tta 43
<210> 14
<211> 30
<212> DNA
<213> 人工序列
<220>
<223> 正义引物
<400> 14
ccatcgatcc cccgacagcg gatcaagggg 30
<210> 15
<211> 30
<212> DNA
<213> 人工序列
<220>
<223> 反义引物
<400> 15
ggcggtacct cgcgcccgac tcgcctcgct 30
- 在制造蛋白质期间连续灭活病毒的方法
- 肝型脂肪酸结合蛋白质制剂、对其评价的方法、抑制使用其的测定中的肝型脂肪酸结合蛋白质引起的测定值的变动幅度的方法、肝型脂肪酸结合蛋白质、其的制造方法、编码其的DNA、由该DNA转化得到的细胞、制作肝型脂肪酸结合蛋白质的校准曲线的方法及对该蛋白质进行定量的方法
- 具有催泪成分合成酶活性的蛋白质或多肽、编码该蛋白质或多肽的 DNA、利用该 DNA制造具有催泪成分合成酶活性的蛋白质或多肽的制造方法以及具有抑制该蛋白质或多肽的mRNA翻译的功能的核酸分子