靶分子预测方法
文献发布时间:2023-06-19 18:32:25
技术领域
本发明涉及构建对生化反应途径的产物蓄积量进行预测的数理模型、及具有该数理模型的人工智能模型的方法。另外,涉及使用该构建的数理模型或人工智能模型对受试物质或受试细胞的生化反应途径中的靶分子进行预测的方法。另外,还涉及用于实施预测前述靶分子的方法的装置及程序。
背景技术
补体不仅是固有免疫的重要的效应器,而且还参与获得性免疫应答、炎症、血液凝固、肿瘤进展的促进。作为基于补体的激活的异物消除机制,可举出调理作用、产生过敏毒素(C5a,C3a)、形成作为最终产物的膜攻击复合物(membrane attack complex ofcomplements;MAC)。补体的激活作为生态防御发挥功能,而另一方面在病理状态下具有发挥生物体毒性的危险性。例如,在肾脏中,补体在肾组织中沉积,由此引发膜增生性肾小球肾炎(MPGN)、链球菌感染后急性肾小球肾炎(PSAGN)、狼疮肾炎。另外,通过补体的激活,形成膜攻击复合物(MAC),通过MAC的形成,在细胞膜内产生结构性的孔。作为其结果,发生渗透压流体的移动和阳离子的流入,导致细胞死亡。如此,由于补体激活异常会导致引发各种各样的疾病,因此以补体途径为靶标的化合物可能成为与补体相关的疾病的治疗或预防药的候选。作为临床上能够利用的以补体途径为靶标的治疗药,存在针对作为补体成分的C5的抗体(艾库组单抗,eculizumab),但存在下述课题:该抗体的施予途径是静脉施予(IV),因此是侵入性的,另外成本非常高(目前的成本:每人60万美元/年)。为了解决上述课题,关注溶血作用而进行了与该补体的过度激活相关的疾病的治疗药的筛选,但由于补体途径的复杂程度和实验的重现性的困难性,该治疗药的筛选尚未成功。
另外,近年来,在第四次工业革命推进过程中,以物联网(IoT)设备的激增、深度学习技术的实用化、CPU(Central Processing Unit,中央处理器)及GPU(GraphicsProcessing Unit,图形处理器)等硬件性能的提高为契机,对利用了人工智能(AI)的医药品研究(即,AI创新药物)、材料开发的期待日益高涨。特别是,大数据创新药物、基因组·组学、药物重定位、材料信息学等作为今后的医药品研究、材料开发的课题而备受瞩目。然而,尚未知晓利用人工智能以补体途径等生化反应途径为靶标的、实用的治疗药的筛选方法。
发明内容
发明所要解决的课题
因此,本发明的课题在于提供用于能够筛选以补体途径等生化反应途径为靶标的治疗药的、可预测该途径中的受试物质等的靶分子的数理模型,提供使用该模型对受试物质等的靶分子进行预测的方法。另外,还提供用于实施预测前述靶分子的方法的装置及程序。
用于解决课题的手段
本申请发明人在构建上述数理模型时考虑如下:不从头构建数理模型,针对预测生化反应途径中的各反应产物的蓄积量的已知的数理模型,基于人工智能的机器学习优化数理模型的参数(系数),由此能够构建靶标途径的预测精度更高的数理模型。首先,本申请发明人构思了通过下述步骤来优化数理模型;在现有的数理模型中预先设定参数的初始值。接着,对于靶标途径为已知的化合物,在与该靶标途径对应的数理模型中代入化合物的浓度等初始条件,制作横轴为时间、纵轴为补体因子的蓄积量的推算图表。设定由该推算图表算定的推算蓄积量与实测值之差的各时间的合计值的函数,以使该函数成为最小值的方式调节数理模型的参数。使用经调节的参数对靶标途径为已知的其他化合物进行同样的操作,调节参数。基于这些一系列调节的参数探索、及重复探索中可利用人工智能(替代模型、贝叶斯优化等)而提高效率(第一阶段)。
进一步地,本申请发明人构思了通过下述步骤来进一步对数理模型的各经调节的参数进行优化;在第一阶段中调节了参数的数理模型中,针对可设想到的所有途径的组合,输入已在第一阶段中调节完参数的数理模型,制作横轴为时间、纵轴为补体因子的蓄积量的推算图表。关于该推算图表各自以使与靶标为未知的化合物的各补体途径因子的实测值之差成为最小值的方式(其中,设定一定限制)对已在第一阶段中调节完参数的数理模型的参数进行再调节。从前述再调整后的所有数理模型之中,将与实测值的误差为最小的数理模型视为正确的数理模型,并采用该数理模型的参数。使用具有该采用的参数的数理模型,由不同的化合物的数据经由同样的步骤,将数理参数的调节利用AI反复实施,由此对在第一阶段中经调节的参数进行微调整,得到以常量而非变量的形式具有最终参数的经优化的数理模型。本申请发明人基于上述构思进行了研究,结果完成了本发明。
即,本发明为了解决上述课题,提供以下的[1]~[17]。
[1-1]构建包含经优化的参数的数理模型的方法,其包括下述工序:
工序(1),将关于生化反应途径中的靶分子为已知的物质或细胞的、显示使该物质或细胞接触靶细胞后的每经过时间的反应产物的推算存在量的数据组、显示实测存在量的数据组、和该物质或细胞的靶分子作为学习数据,使具有各靶分子的数理模型的人工智能模型学习,从而对各靶分子的数理模型的各参数进行优化;及
工序(2),将关于靶分子为未知的物质或细胞的、对各靶分子赋予权重后的、显示每经过时间的反应产物的推算存在量的数据组、和显示实测存在量的数据组作为学习数据,使具有数理模型的人工智能模型学习,从而对各靶分子的数理模型的各参数进行优化,其中,该数理模型对应于可能被该物质或细胞靶向的全部分子的各组合,并且包含在工序(1)中经优化的各参数。
[1-2]构建具有包含经优化的参数的数理模型的人工智能模型的方法,其包括下述工序:
工序(1),将关于生化反应途径中的靶分子为已知的物质或细胞的、显示使该物质或细胞接触靶细胞后的每经过时间的反应产物的推算存在量的数据组、显示实测存在量的数据组、和该物质或细胞的靶分子作为学习数据,使具有各靶分子的数理模型的人工智能模型学习,从而对各靶分子的数理模型的各参数进行优化;及
工序(2),将关于靶分子为未知的物质或细胞的、对各靶分子赋予权重后的、显示每经过时间的反应产物的推算存在量的数据组、和显示实测存在量的数据组作为学习数据,使具有数理模型的人工智能模型学习,从而对各靶分子的数理模型的各参数进行优化,其中,该数理模型对应于可能被该物质或细胞靶向的全部分子的各组合,并且包含在工序(1)中经优化的各参数。
[2]如[1-1]或[1-2]所述的方法,其中,
前述工序(1)包括下述工序:
工序(I),将显示使生化反应途径中的靶分子为已知的物质或细胞接触靶细胞后的每经过时间的反应产物的推算存在量的数据组、显示实测存在量的数据组、和各物质或细胞的靶分子输入具有各靶分子的数理模型(其包含已设定初始值的参数)的人工智能模型中,利用该人工智能模型探索与该物质或细胞的靶分子对应的数理模型的参数的最优值,并将该参数更新为该最优值;及
工序(II),使用关于其他多个物质或细胞的显示每经过时间的反应产物的推算存在量的数据组、显示实测存在量的数据组、和靶分子,对各物质或细胞依次反复进行前述工序(I)(其中,将人工智能模型替换为具有在工序(I)中各参数被更新为最优值的数理模型的人工智能模型的工序),从而对各靶分子的数理模型的各参数进行调节。
[3]如[1-1]~[2]中任一项所述的方法,其中,
前述工序(2)包括下述工序:
工序(III),将关于靶分子为未知的多个物质或细胞的、对各靶分子赋予权重后的显示每经过时间的反应产物的推算存在量的数据组、和显示实测存在量的数据组输入具有数理模型的人工智能模型中,利用该人工智能模型探索各靶分子的数理模型的各参数的最优值,并将该参数更新为该最优值,其中,该数理模型分别对应于可能被各物质或细胞靶向的全部分子的组合,并且包含在工序(1)中经优化的各参数;及
工序(IV),从在前述工序(III)中各参数被更新为最优值的各靶分子的数理模型中,将能够最好地说明实测存在量的数理模型判定为与各物质或细胞的靶分子对应的数理模型。
[4]如[3]所述的方法,其还包括:
工序(V)对工序(III)的权重的妥当性进行验证。
[5]如[3]或[4]所述的方法,其包括下述工序:
工序(VI),将在前述工序(1)中经优化的参数更新为在前述工序(IV)中所判定的数理模型的优化参数;及
工序(VII),使用关于其他多个物质或细胞的、对各靶分子赋予权重后的显示每经过时间的反应产物的推算存在量的数据组、和显示实测存在量的数据组,对各物质或细胞依次反复进行工序(III)-(VI)(其中,将工序(III)的人工智能模型替换为具有在工序(VI)中进行了参数向最优值的更新的数理模型的人工智能模型的工序),从而对各靶分子的数理模型的各参数进行调节。
[6]如[2]~[5]中任一项所述的方法,其中,工序(I)的显示推算存在量的数据组是通过将该物质或细胞在培养基中的浓度、和该物质或细胞的接触时间点的反应产物的存在量作为初始值代入已对所有参数设定初始值的数理模型中而得到的。
[7]如[1]~[6]中任一项所述的方法,其中,工序(1)的人工智能模型是将每经过时间的反应产物的推算存在量与实测存在量之差的2次方的合计值的最小化设定为目标函数的模型。
[8]如[3]~[7]中任一项所述的方法,其中,工序(III)的显示推算存在量的数据组是通过将各物质或细胞在培养基中的浓度、和该物质或细胞与靶细胞的接触时间点的反应产物的存在量作为初始值代入包含在工序(1)中经优化的各靶分子的各参数的数理模型而得到的。
[9]如[3]~[8]中任一项所述的方法,其中,前述工序(III)的探索是从在前述工序(1)中经优化的各靶分子的参数集中、将物质或细胞与靶细胞接触后所推算的参数范围设定为探索范围的范围内进行的。
[10]如[3]~[9]中任一项所述的方法,其中,前述工序(IV)的工序是将经赋予前述权重的每经过时间的反应产物的推算存在量与实测存在量之差的2次方的合计值为最小值的数理模型判定为与该物质或细胞的靶分子对应的数理模型的工序。
[11]如[2]~[10]中任一项所述的方法,其中,前述工序(I)的探索是利用替代模型进行的。
[12]如[3]~[11]中任一项所述的方法,其中,前述工序(III)的针对推算存在量的权重是基于物质的结构数据而设定的。
[13]如[1-1]~[12]中任一项所述的方法,其中,前述生化反应途径为补体途径。
[14]如[1]~[13]中任一项所述的方法,其中,前述物质选自由低分子化合物、核酸、肽及抗体组成的组。
[15]对受试物质或受试细胞的生化反应途径中的靶分子进行预测的方法,其包括下述工序:
工序(A),将关于受试物质或受试细胞的、各物质或细胞在培养基中的浓度、该物质或细胞与靶细胞的接触时间点的反应产物的存在量、和显示每经过时间的实测存在量的数据组输入具有利用[1-1]~[14]中任一项所述的方法构建的数理模型的人工智能模型中,利用该人工智能模型算出各靶分子的反应产物的每经过时间的推算存在量;及
工序(B),通过在前述工序(A)中算定的各靶分子的推算存在量与实测存在量的比较,对关于各靶分子的受试物质或受试细胞将其作为靶标的概率进行算定。
[16]用于对受试物质或受试细胞的生化反应途径中的靶分子进行预测的计算机程序,其用于使计算机作为下述各部发挥功能:
(P1)接收部,其至少接收关于受试物质或受试细胞的、各物质或细胞在培养基中的浓度、该受试物质或受试细胞与靶细胞的接触时间点的反应产物的存在量、和显示每经过时间的实测存在量的数据组;
(P2)第一运算部,其将该输入的数据组输入具有利用[1]~[14]中任一项所述的方法构建的数理模型的人工智能模型中,对各靶分子的反应产物的每经过时间的推算存在量进行算定;
(P3)第二运算部,其通过第一运算部中得到的各靶分子的推算存在量与实测存在量的比较,对关于各靶分子的该受试物质或受试细胞将其作为靶标的概率进行算定;及
(P4)输出部,其输出第二运算部中得到的运算结果。
[17]用于对受试物质或受试细胞的生化反应途径中的靶分子进行预测的装置,其具有:
(M1)接收部,其至少接收关于受试物质或受试细胞的、各物质或细胞在培养基中的浓度、该物质或细胞与靶细胞的接触时间点的反应产物的存在量、和显示每经过时间的实测存在量的数据组;
(M2)第一运算部,其将该输入的数据组输入具有利用[1]~[14]中任一项所述的方法构建的数理模型的人工智能模型中,对各靶分子的反应产物的每经过时间的推算存在量进行算定:
(M3)第二运算部,其通过第一运算部中得到的各靶分子的推算存在量与实测存在量的比较,对关于各靶分子的该受试物质或细胞将其作为靶标的概率进行算定;和
(M4)输出部,其输出第二运算部中得到的运算结果。
发明效果
根据本发明,通过积累已知的文库化合物的数据,优化参数,能够以良好的精度预测未知的化合物的靶标。只要能够确认基于细胞的反应和其时间序列,即使不是补体相关疾病,也能够同样地预测化合物的靶标。
附图说明
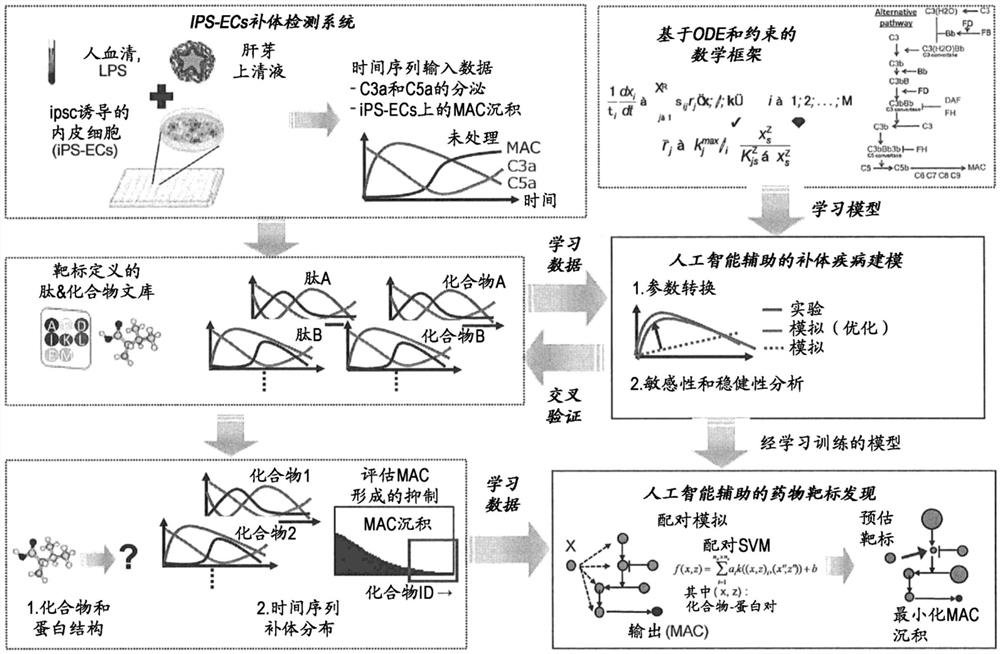
[图1]图1示出基于本发明的、构建各参数经优化的数理模型的方法的概要。
[图2]图2为示出本发明的装置的构成的一优选例的框图。以虚线表示本发明的装置与外部装置(输入数据组的发送源、预测结果的发送目的)的通讯关系。图2的例子中,输入数据组的发送源也是预测结果的发送目的。
[图3]图3为示出本发明的程序的流程的图。
具体实施方式
-1.数理模型或人工智能模型的构建方法-
本发明提供通过使用人工智能对预测生化反应途径的产物蓄积量的数理模型的各参数进行优化,从而构建具有该经优化的参数的数理模型的方法、及构建具有该所构建的数理模型的人工智能模型的方法(以下,作为包括构建数理模型的方法、和构建人工智能模型的方法这两者的方法,有时也称为“本发明的模型构建方法”)。当然,构建人工智能模型的方法属于生产作为事物的人工智能模型的方法。
本发明的模型构建方法包括:
工序(1),将关于生化反应途径中的靶分子为已知的物质或细胞(以下也称作“靶标已知物质或细胞”)的、显示使该物质或细胞接触靶细胞后的每经过时间(典型而言,以特定间隔对经过时间进行划分,使用各区段的数据。以下同样)的反应产物的推算存在量的数据组、显示实测存在量的数据组、和该物质或细胞的靶分子作为学习数据(以下也称作“工序(1)用学习数据”),使具有各靶分子的数理模型的人工智能模型学习,从而对各靶分子的数理模型的各参数进行优化。
另外,本发明的模型构建方也可以在上述工序(1)之后包括:
工序(2),将关于该途径中的靶分子为未知的物质或细胞(以下也称作“靶标未知物质或细胞”)的、对各靶分子赋予权重后的、显示每经过时间的反应产物的推算存在量的数据组、和显示实测存在量的数据组作为学习数据(以下也称作“工序(2)用学习数据”),使具有数理模型的人工智能模型学习,从而对各靶分子的数理模型的各参数进行优化。工序(2)中的数理模型对应于可能被靶标已知物质或细胞靶向的全部分子的各组合,并且包含在工序(1)中经优化的各参数。
本说明书中,所谓“包含(comprise(s)或comprising)~”,是指包括但不限于该短语后面的要素。因此,暗示了包含该短语后面的要素,但并未暗示将其他任意要素排除在外。
作为可采用本发明的模型构建方法的生化反应途径,可举出例如补体途径、凝血途径、血小板激活途径、抗原呈递途径、中心碳代谢途径、脂肪酸代谢途径、氨基酸代谢途径、核苷酸代谢途径、药物代谢途径、基因表达调控途径、RNA调控途径、翻译调控途径、泛素·蛋白酶体途径、神经传导途径、钙信号途径、cAMP信号转导途径、G蛋白偶联受体信号转导途径、磷酸化信号途径、细胞粘附·结合信号途径等,优选为补体途径。另外,本说明书中,“生化反应途径中的靶分子”是指被靶标已知物质或细胞靶向的、促进上述生化反应途径中的各产物的生成或分解、或者抑制该促进效果的蛋白质或蛋白质复合物的组成蛋白。“靶分子”不仅包括单一的分子,也包括多个靶分子的组合(即,受试物质或受试细胞将同一生化反应途径中的多个分子作为靶标)。另外,所谓“被靶向”,是指通过与靶细胞接触的物质或细胞,生化反应途径中的靶分子的功能被促进或抑制。
若以补体途径为例,可举出例如:与靶蛋白、表面结合、作为补体反应的基点的C1q;为丝氨酸蛋白酶、降解并激活C4、C2的C1r及C1s;产生C4b2a复合物并激活C3的C2及C4;构建C3b4b2a复合物并形成C3C5转化酶的C3;等等。作为生化反应途径中的各产物,若以补体途径的补体因子为例,可举出例如:C2、C2b、C3(H2O)/Bb复合物、C3a、C3b、C3b/Bb复合物、C4、C4a、C4b、C4b/C2a复合物、C3b/C3b/Bb复合物、C3b/C4b/C2a复合物、C5a、C5b、膜攻击复合物(MAC)等,优选为MAC、C3a、C5a。
作为上述工序(1)中使用的靶标已知物质或细胞,没有特别限定,可例示出例如:细胞提取物、细胞培养上清液、微生物发酵产物、源自海洋生物的提取物、植物提取物、纯化蛋白或粗蛋白(例:抗体、抗体片段等)、肽、非肽化合物、合成低分子化合物、及天然化合物(例:核酸、基因等)。另外,作为细胞种类,可举出例如:神经细胞、少突胶质细胞、红细胞、单核细胞(例:淋巴细胞(NK细胞、B细胞、T细胞、单核细胞、树突细胞等))、粒细胞(例:嗜酸性粒细胞、中性粒细胞、嗜碱性粒细胞)、巨核细胞、上皮细胞(例:视网膜色素上皮细胞等)、内皮细胞(例:血管内皮细胞、肝窦内皮细胞等)、肌肉细胞、成纤维细胞(例:皮肤细胞等)、毛细胞、肝细胞、胃黏膜细胞、肠细胞、脾细胞、胰腺细胞(例:胰腺外分泌细胞等)、脑细胞、肺细胞、肾细胞及脂肪细胞等已分化的细胞、或者它们的未成熟细胞等。
作为本发明中使用的靶细胞,只要可测定生化反应途径中的产物的存在量、例如产物的蓄积量,则没有特别限定,可以是培养的细胞,也可以是从生物体中分离的细胞。从抑制细胞的不均的观点考虑,细胞优选为培养的细胞、例如由干细胞分化诱导的细胞。作为该细胞种类,可举出与上述的靶标已知物质或细胞中列举的细胞相同的细胞。
由干细胞制作(分化诱导)前述细胞的方法可根据目标细胞的种类而适当选择本身已知的方法。例如,作为制作血管内皮细胞的方法,可举出例如Yamashita J.等,Nature,408(6808):92-96(2000)中记载的方法、Narazaki G.等,Circulation,29;118(5):498-506(2008)中记载的方法等;作为制作神经细胞的方法,可举出例如Yan Y.等,Stem CellsTrans Med,2:862-870(2013)中记载的方法、Kondo T.等,Cell Stem Cell,12:487-496(2013)中记载的方法、WO2015/020234中记载的方法、Doi D.等,Stem Cell Reports,2(3):337-50(2014)中记载的方法等;作为制作少突胶质细胞的方法,可举出例如Kawabata S.等,Stem Cell Reports,6(1):1-8(2016)中记载的方法等;作为制作肝细胞的方法,可举出例如Cai J.等,Hepatology,45:1229-1239(2007)中记载的方法等;作为制作视网膜色素上皮细胞的方法,可举出例如Yan Y.等,Stem Cells Trans Med,2:862-870(2013)中记载的方法、WO2015/053375中记载的方法等,作为造血祖细胞的方法,可举出例如WO2013/075222中记载的方法、WO2016/076415中记载的方法、及Liu S.等,Cytotherapy,17:344-358(2015)中记载的方法等;作为制作红细胞或红细胞祖细胞的方法;可举出例如Miharada K.等,Nat.Biotechnol.,24:1255-1256(2006)中记载的方法、Kurita R.等,PLoS One,8:e59890(2013)中记载的方法等;作为制作巨核细胞或血小板的方法,可举出例如YamamizuK.等,J.Cell Biol.,189:325-338(2010)中记载的方法、Laflamme M.等,Nat.Biotechnol.,25:1015-1024(2007)中记载的方法等;作为制作T细胞的方法,可举出例如WO2016/076415中记载的方法、WO2017/221975中记载的方法等;作为制作骨骼肌细胞的方法,可举出例如WO2013/073246中记载的方法、Uchimura T.et al,.Stem CellResearch,25:98-106(2017)中记载的方法、Shoji E.等,Science Reports,5:12831(2015)中记载的方法等;作为制作心肌细胞的方法,可举出例如Shimoji K.等,Cell Stem Cell,6:227-237(2010)中记载的方法等。
若具体地进行说明,为了由干细胞制作血管内皮细胞,例如,将干细胞在包含血清替代物(例:B-27)、BMP4及GSK-3抑制剂(例:CHIR99021)的培养基中进行培养而诱导成中胚层系细胞之后,将该细胞在包含VEGF及佛司可林(Folskolin)的培养基中进行培养,由此可制作血管内皮细胞。另外,为了由干细胞制作肝细胞,在包含Wnt蛋白(例:Wnt3a)及激活素A的培养基中进行培养而诱导成内胚层系细胞之后,将该细胞在包含血清替代物(B-27)及FGF2的培养基中进行培养,由此可制作肝细胞。
作为前述“干细胞(stem cell)”,可举出例如多潜能干细胞(pluripotent stemcell)。本说明书中,所谓“多潜能干细胞(pluripotent stem cell)”,是指具有能够分化成生物体的具有各种不同的形态、功能的组织、细胞、可分化成三胚层(内胚层、中胚层、外胚层)中的任何一个谱系的细胞的能力的干细胞。作为多潜能干细胞,没有特别限定,可举出例如:诱导性多潜能干细胞(本说明书中,有时也称作“iPS细胞”)、胚胎干细胞(ES细胞)、源自通过核移植而获得的克隆胚胎的胚胎干细胞(nuclear transfer Embryonic stemcell:ntES细胞)、多潜能生殖干细胞、胚胎生殖干细胞(EG细胞)等。本说明书中,作为“多能干细胞(multipotent stem cell)”,是指具有能够分化成多个有限数量的谱系的细胞的能力的干细胞。另外,作为“多能干细胞(multipotent stem cell)”,可举出例如:牙髓干细胞、源自口腔粘膜的干细胞、毛囊干细胞、源自培养的成纤维细胞、骨髓干细胞的成体干细胞。优选的多潜能干细胞(pluripotent stem cell)为ES细胞及iPS细胞。上述多潜能干细胞为来源于ES细胞或人胚胎的任意细胞的情况下,该细胞可以为破坏胚胎而制作的细胞,也可以为不破坏胚胎而制作的细胞,优选为不破坏胚胎而制作的细胞。上述干细胞优选来源于哺乳动物(例:小鼠、大鼠、仓鼠、豚鼠、犬、猴、红毛猩猩(Orang hutan)、黑猩猩、人),更优选来源于人。
所谓“诱导性多潜能干细胞”,是指在哺乳动物体细胞或未分化干细胞中导入特定的因子(核重编程因子)并进行重编程而得到的细胞。现在,“诱导性多潜能干细胞”的种类很多,除了山中等人通过在小鼠成纤维细胞中导入Oct3/4·Sox2·Klf4·c-Myc这4种因子而建立的iPS细胞(Takahashi K,Yamanaka S.,Cell,(2006)126:663-676)以外,还可以使用将同样的4种因子导入人成纤维细胞中而建立的源自人细胞的iPS细胞(Takahashi K,Yamanaka S.等,Cell,(2007)131:861-872.)、导入上述4种因子后以Nanog的表达为指标进行分选而建立的Nanog-iPS细胞(Okita,K.,Ichisaka,T.,and Yamanaka,S.(2007).Nature448,313-317.)、以不含c-Myc的方法而制作的iPS细胞iPS细胞(Nakagawa M,Yamanaka S.等,Nature Biotechnology,(2008)26,101-106)、用无病毒法(virus-free method)导入6种因子而建立的iPS细胞(Okita K等,Nat.Methods2011May;8(5):409-12,Okita K等,StemCells.31(3):458-66.)。另外,还可使用由Thomson等制作的导入OCT3/4·SOX2·NANOG·LIN28这4种因子而建立的诱导性多潜能干细胞(Yu J.,ThomsonJA.等,Science(2007)318:1917-1920.)、由Daley等制作的诱导性多潜能干细胞(Park IH,Daley GQ.等,Nature(2007)451:141-146)、由樱田等制作的诱导性多潜能干细胞(日本特开2008-307007号)等。
除此以外,也可使用已公开的所有论文(例如,Shi Y.,Ding S.等,Cell StemCell,(2008)Vol 3,Issue 5,568-574;Kim JB.,ScholerHR.等,Nature,(2008)454,646-650;Huangfu D.,Melton,DA.等,Nature Biotechnology,(2008)26,No 7,795-797)、或专利(例如,日本特开2008-307007号、日本特开2008-283972号、US2008-2336610、US2009-047263、WO2007/069666、WO2008/118220、WO2008/124133、WO2008/151058、WO2009/006930、WO2009/006997、WO2009/007852)中记载的本领域中已知的诱导性多潜能干细胞中的任一种。作为诱导多潜能干细胞株,可利用NIH、理研、京都大学等建立的各种iPS细胞株。例如,若为人iPS细胞株,则可举出理研的HiPS-RIKEN-1A株、HiPS-RIKEN-2A株、HiPS-RIKEN-12A株、Nips-B2株、京都大学的253G1株、201B7株、409B2株、454E2株、606A1株、610B1株、648A1株等。另外,iPS细胞也可以为来源于疾病患者的iPS细胞。
ES细胞为由人、小鼠等哺乳动物的早期胚胎(例如囊胚)的内部细胞团建立的具有多能性与自我复制带来的增殖能力的干细胞。ES细胞是于1981年在小鼠中发现的(M.J.Evans and M.H.Kaufman(1981),Nature 292:154-156),然后在人、猴等灵长类中也建立了ES细胞株(J.A.Thomson等,(1998),Science 282:1145-1147;J.A.Thomson等,(1995),Proc.Natl.Acad.Sci.USA,92:7844-7848;J.A.Thomson等,(1996),Biol.Reprod.,55:254-259;J.A.Thomson and V.S.Marshall(1998),Curr.Top.Dev.Biol.,38:133-165)。ES细胞可通过从对象动物的受精卵的囊胚中取出内部细胞团,并在成纤维细胞的饲养层上对内部细胞团进行培养而建立。人及猴的ES细胞的建立与维持的方法记载于例如USP5,843,780;Thomson JA等,(1995),Proc Natl.Acad.Sci.U S A.92:7844-7848;Thomson JA等,(1998),Science.282:1145-1147;Suemori H.等,(2006),Biochem.Biophys.Res.Commun.,345:926-932;Ueno M.等,(2006),Proc.Natl.Acad.Sci.USA,103:9554-9559;Suemori H.等,(2001),Dev.Dyn.,222:273-279;Kawasaki H.等,(2002),Proc.Natl.Acad.Sci.USA,99:1580-1585;Klimanskaya I.等,(2006),Nature.444:481-485等。或者,ES细胞可通过仅使用囊胚期以前的卵裂期的胚胎的单一卵裂球来建立(Chung Y.等,(2008),Cell Stem Cell 2:113-117),也可以使用已停止发育的胚胎来建立(Zhang X.等,(2006),Stem Cells24:2669-2676.)。作为“ES细胞”,若为小鼠ES细胞,则能利用inGenious targeting laboratory公司、理研(理化学研究所)等建立的各种小鼠ES细胞株,若为人ES细胞,则能利用威斯康星大学、NIH、理研、京都大学、国立成育医疗研究中心及Cellartis公司等建立的各种人ES细胞株。例如,作为人ES细胞株,可利用ESI Bio公司出售的CHB-1~CHB-12株、RUES1株、RUES2株、HUES1~HUES28株等、WiCell Research出售的H1株、H9株等、理研出售的KhES-1株、KhES-2株、KhES-3株、KhES-4株、KhES-5株、SSES1株、SSES2株、SSES3株等。
nt ES细胞为源自通过核移植技术而制作的克隆胚胎的ES细胞,具有与源自受精卵的ES细胞几乎相同的特性(Wakayama T.等,(2001),Science,292:740-743;S.Wakayama等,(2005),Biol.Reprod.,72:932-936;Byrne J.等,(2007),Nature,450:497-502)。即,由源自通过将未受精卵的核与体细胞的核进行置换而获得的克隆胚胎的囊胚的内部细胞团建立的ES细胞为nt ES(nuclear transfer ES)细胞。为了制作nt ES细胞,可利用核移植技术(Cibelli J.B.等,(1998),Nature Biotechnol.,16:642-646)与ES细胞制作技术(上述)的组合(若山清香等(2008),实验医学,26卷,5号(增刊),47~52页)。核移植中,在哺乳动物的去除核的未受精卵中注入体细胞的核,进行数小时培养,由此可进行重编程。
多潜能生殖干细胞为源自生殖干细胞(GS细胞)的多潜能干细胞。该细胞与ES细胞同样地,能分化诱导成各种系列的细胞,例如具有若移植于小鼠囊胚则可制作嵌合小鼠等的性质(Kanatsu-Shinohara M.等,(2003)Biol.Reprod.,69:612-616;Shinohara K.等,(2004),Cell,119:1001-1012)。能够在包含源自胶质细胞系的神经营养因子(glial cellline-derived neurotrophic factor(GDNF))的培养液中自我复制,且通过在与ES细胞同样的培养条件下反复进行传代,可得到生殖干细胞(竹林正则等人(2008),实验医学,26卷,5号(增刊),41~46页,羊土社(东京、日本))。
EG细胞为由胎生期的原始生殖细胞建立、具有与ES细胞同样的多潜能性的细胞。可通过在LIF、bFGF、干细胞因子(stem cell factor)等物质的存在下对原始生殖细胞进行培养而建立(Matsui Y.等,(1992),Cell,70:841-847;J.L.Resnick等,(1992),Nature,359:550-551)。
另外,靶细胞也可以为构成类器官(Organoid)的细胞。作为该类器官,举出例如仅由血管内皮细胞制作的三维结构体、由血管内皮细胞及肝细胞制作的三维结构体(特征在于在肝细胞间具有由血管内皮细胞形成的脉管网络)等。这些类器官通常利用本身已知的培养方法(例如,Nature Cell Biology 18,246-254(2016))而制作。具体而言,作为类器官的制作方法,可举出例如Nahmias Y.等,Tissue Eng.,12(6),2006,pp.1627-1638中记载的方法等。
前述类器官的制作中使用的血管内皮细胞可以是造血性血管内皮细胞(hemogenic endothelial cell;HEC),也可以是非造血性血管内皮细胞(non-hemogenicendothelial cell;non-HEC)。HEC为能够产生造血干细胞的(具有造血能力)血管内皮细胞,也被称作血细胞产生型血管内皮细胞。另外,可以使用HEC或non-HEC中的任一者,可以使用HEC及non-HEC这两者,也可以使用它们的祖细胞,或者还可以使用HEC、non-HEC、及它们的祖细胞的任意组合。作为前述血管内皮细胞的祖细胞,可举出从Flk-1(CD309、KDR)阳性的血管内皮细胞的祖细胞(例,侧板中胚层系细胞)分化为HEC细胞的过程中存在的细胞(参见Cell Reports 2,553-567,2012)。
该类器官的制作中使用的肝细胞可以为已分化的肝细胞(分化肝细胞),也可以为已确定了分化成肝细胞的命运但尚未分化为肝细胞的细胞(未分化肝细胞)、所谓的肝祖细胞(例,肝内胚层细胞)。分化肝细胞或未分化肝细胞可以为从生物体采集的(从生物体内的肝脏分离的)细胞,也可以为ES细胞、iPS细胞等多潜能干细胞、肝祖细胞、使其他具有分化为肝细胞的能力的细胞分化而得到的细胞。可分化为肝细胞的细胞例如可按照K.Si-Taiyeb等,Hepatology,51(1):297-305(2010)、T.Touboul等,Hepatology.51(5):1754-65.(2010)而制作。
另外,前述类器官的制作中,可以使用间充质干细胞。该间充质干细胞可以为已分化的细胞(分化间充质细胞),也可以为已确定了分化成间充质细胞的命运但尚未分化为间充质细胞的细胞(未分化间充质细胞)、所谓的间充质干细胞。本领域技术人员间使用的、mesenchymal stem cells、mesenchymal progenitor cells、mesenchymal cells(R.Peters等,PLoS One.30;5(12):e15689.(2010))等术语所指的对象相当于本说明书中的“间充质细胞”。
就用于制作前述类器官的血管内皮细胞及肝细胞的细胞数的比率而言,例如,可以从所回收的培养上清液中所含的成分为所期望的物质等观点考虑而在适宜的范围内进行调节。本发明的一个实施方式中,血管内皮细胞及肝细胞的细胞数的比率(血管内皮细胞:肝细胞)代表性地为1:0.1~5,优选为1:0.1~2。使用间充质干细胞的情况下,该比例也可以适当调节,作为优选的实施方式,以细胞数的比率(血管内皮细胞:肝细胞:干细胞)为7:10:1而使用。
制作类器官之际,优选使用将用于血管内皮细胞的培养基和用于肝细胞的培养基(培养液)以适宜的比例(例如以1:1)进行混合而得的类器官用培养基。作为用于血管内皮细胞的培养基,可举出例如:DMEM/F-12(Gibco)、Stempro-34SFM(Gibco)、Essential6培养基(Gibco)、Essential 8培养基(Gibco)、EGM(Lonza)、BulletKit(Lonza)、EGM-2(Lonza)、BulletKit(Lonza)、EGM-2MV(Lonza)、VascuLife EnGS Comp Kit(LCT)、HumanEndothelial-SFM Basal Growth Medium(Invitrogen)、人微血管内皮细胞增殖培养基(TOYOBO)等。用于血管内皮细胞的培养基可以包含选自由B27 Supplements(GIBCO)、BMP4(骨形成因子4)、GSKβ抑制剂(例、CHIR99021)、VEGF(血管内皮细胞生长因子)、FGF2(成纤维细胞生长因子(也称为bFGF(碱性成纤维细胞生长因子)))、Folskolin、SCF(干细胞因子,Stem Cell Factor)、TGFβ受体抑制剂(例,SB431542)、Flt-3L(Fms相关酪氨酸激酶3配体)、IL-3(白细胞介素3)、IL-6(白细胞介素6)、TPO(血小板生成素)、hEGF(重组人上皮细胞生长因子)、氢化可的松、抗坏血酸、IGF1、FBS(胎牛血清)、抗生素(例如,庆大霉素、两性霉素B)、肝素、L-谷氨酰胺、酚红、BBE等中的1种以上的添加物。这些添加物的添加量是本领域技术人员可参考用于培养血管内皮细胞的通常的培养条件而适当确定的。
作为用于肝细胞的培养基,可举出例如RPMI(Fujifilm)、HCM(Lonza)等。用于肝细胞的培养基可以含有选自Wnt3a、激活素A、BMP4、FGF2、FBS(胎牛血清)、HGF(肝细胞生长因子)、抑瘤素M(OSM)、地塞米松(Dex)等中的1种以上的添加物。这些添加物的添加量是本领域技术人员可参考用于培养肝细胞的通常的培养条件而适当确定的。或者,作为用于肝细胞的培养基,可以使用:包含选自抗坏血酸、BSA-FAF、胰岛素、氢化可的松及GA-1000中的至少1种的用于肝细胞的培养基、从HCM BulletKit(Lonza)中去除hEGF(重组人上皮细胞生长因子)而得的培养基、向RPMI1640(Sigma-Aldrich)中添加1% B27 Supplements(GIBCO)和10ng/mL hHGF(Sigma-Aldrich)而得的培养基、向将GM BulletKit(Lonza)和去除了hEGF(重组人上皮细胞生长因子)后的HCM BulletKit(Lonza)以1:1混合而得的培养基中添加地塞米松、抑瘤素M及HGF而得的培养基等。
工序(1)中使用的显示推算存在量的数据组例如可通过将靶标已知物质或细胞在培养基中的浓度、和该物质或细胞的接触时间点的反应产物的存在量作为初始值代入已对所有参数设定初始值的数理模型中而得到。
作为工序(1)中使用的数理模型,若以补体途径为例,可举出例如Sagar A等,PLoSOne,(2017)12(11):e0187373、Zewde N等,PloS One,(2016)11(3):e0152337、Hirayama H等,Biosystems,(1996)39(3):173-185、Korotaevskiy AA等,Math Biosci,(2009)222(2):127-143、Liu B等,PLoS Comput Biol,(2011)7(1):e1001059等,但并不限于此。若以凝血途径为例,可举出例如Hockin MF等,J Biol Chem,(2002)277(21):18322-18333、Chatterjee MS等,PLoS Comput Biol,(2010)6(9):e1000950、Nayak S等,CPTPharmacometrics Syst Pharmacol,(2015)4(7):396-405、http://biomodels.caltech.edu/content/model-of-the-month?year=2019&month=04中公开的模型等,但并不限于此。若以脂肪酸代谢途径为例,可举出例如Wallstab C等,FEBS J,(2017)284(19):3245-3261、Patt AC等,Math Biosci,(2015)262:167-181、Adiels M等,JLipid Res,(2005)46:58-67、Shorten PR&Upreti GC,Biochim Biophys Acta,(2005)1736:94-108等,但并不限于此。若以中心碳代谢途径和脂肪酸代谢途径的组合为例,可举出例如Dean JT等,Biophys J.,(2010)98(8):1385-1395等,但并不限于此。若以磷酸化信号途径为例,可举出Sulaimanov N等,Wiley Interdiscip Rev Syst Biol Med.,(2017)9(4):e1379、该文献中引用的各模型(自该文献的引用示为表1)等,但并不限于此。若为药物代谢途径为例,可举出例如Toth A等,PLoS One,(2015)10(2):e0115533、Stamatelos SK等,BMC Syst Biol,(2011)5:16、Stamatelos SK等,J Theor Biol,(2013)317:244-256、Suzuki T等,Trends Pharmacol Sci,(2013)34(6):340-346、Zhang Q等,PLoScomputational biology,(2007)3:e24、Zhang Q等,Toxicology and appliedpharmacology,(2009)237:345-356等,但并不限于此。工序(1)中使用的数理模型也可使用数理模型的数据库网站(例如,BioModels(http://biomodels.caltech.edu/))中列举的模型。另外,数理模型的初始值例如优选采用前述的关于数理模型的已公开的文献中记载的初始值。
[表1]
[表1]
靶标已知物质或细胞与靶细胞的接触可通过下述方式进行:向靶细胞的培养培养基中添加靶标已知物质或细胞;将靶细胞转移或接种于已预先添加有靶标已知物质或细胞的培养基中。细胞为构成类器官的细胞的情况下,上述“细胞的培养培养基”可替换记载为“类器官的培养培养基”。另外,靶标已知物质或细胞可以在与靶细胞的接触时、或接触的前后,还与促进或者抑制反应产物的生成的物质接触。本申请发明人以前发现了通过使细胞与补体供给源接触,可促进该细胞中的MAC的形成。因此,作为促进上述反应产物的生成的物质,可举出补体途径中的补体供给源,但并不限于此,可根据靶标的生化反应途径的种类而适当选择。另外,以补体途径为靶标的情况下,也可以进一步使补体激活因子接触靶标已知物质或细胞。作为该补体激活因子,可举出例如LPS(脂多糖)、酵母的细胞壁的多糖质酵母聚糖(zymosan)等。
作为上述补体供给源,可举出例如:血清(例:人血清、牛血清、马血清、绵羊血清、山羊血清、猪血清、羊驼血清、犬血清、鸡血清、驴血清、猫血清、兔血清、豚鼠血清、仓鼠血清、大鼠血清、小鼠血清等)中所含的补体、肝脏、血管内皮细胞(包含其器官的类器官)的培养上清液中所含的补体、或者各补体成分(例:C1q、C1r、C1s、C2、C4、C3、C3a、C5s、C3b、C5a、C5b6789、及它们的组合等)等。另外,本申请发明人以前确认了人工制作的类器官会分泌补体。因此,前述类器官的培养上清液也可用作补体供给源。此外,本申请发明人确认了通过组合多个种类的补体供给源,较之组合各个单体的情况,可进一步促进MAC的形成,因此补体或补体供给源也优选为组合多个种类的补体或补体供给源(例:血清与器官的类器官的培养上清液的组合)。
作为细胞的培养中使用的培养基,可举出例如:BME培养基、BGJb培养基、CMRL1066培养基、Glasgow MEM培养基、Improved MEM(IMEM)培养基、Improved MDM(IMDM)培养基、Medium199培养基、Eagle MEM培养基、αMEM培养基、DMEM培养基(高糖、低糖)、DMEM/F12培养基、Ham培养基、RPMI 1640培养基、Fischer's培养基、它们的混合培养基等。另外,也可以使用上述的用于血管内皮细胞的培养基、用于肝细胞的培养基、类器官用培养基、或者它们的混合培养基。
前述培养基中除上述成分以外,可根据必要添加氨基酸、L-谷氨酰胺、GlutaMAX(产品名)、非必需氨基酸、维生素、抗生素(例如,抗菌-抗真菌剂,Antibiotic-Antimycotic(本说明书中,有时称为AA)、青霉素、链霉素、或它们的混合物)、抗菌剂(例如,两性霉素B)、抗氧化剂、丙酮酸、缓冲剂、无机盐类等。
关于培养时间,也没有特别限定,典型而言,可举出10分钟至7天,优选为0.5小时~96小时,更优选为4小时~48小时。培养温度也没有特别限定,优选以30~40℃(例:37℃)进行。另外,作为培养容器中的二氧化碳浓度,例如可举出5%左右。
反应产物的实测存在量的测定没有特别限定,例如,可以利用各时间序列的、使用了抗体(例:可检测MAC的抗CD59抗体、抗LDH抗体等)的免疫学分析而进行,具体而言,可以利用ELISA、Western印迹法、免疫染色、流式细胞术、荧光成像等而进行。为了基于免疫染色、Western印迹法等的结果对表达量进行定量,也可由所得到的图像数据使用图像处理软件(例:ImageJ等)进行数值化。另外,反应产物具有酶活性的情况下,也可以以该酶活性为指标,根据需要使用试剂盒,测定反应产物的存在量。
工序(1)中的各靶分子的数理模型的各参数的优化例如可利用以下的工序而进行。
工序(I),将工序(1)用学习数据输入具有各靶分子的数理模型(其包含已设定初始值的参数)的人工智能模型(以下也称作“第一人工智能模型”)中,利用该人工智能模型探索与靶标已知物质或细胞的靶分子对应的数理模型的参数的最优值,并将该参数更新为该最优值;及
工序(II),使用关于其他多个靶标已知物质或细胞的、显示每经过时间的反应产物的推算蓄积量的数据组、显示实测存在量的数据组、和靶分子作为学习数据,对各靶标已知物质或细胞依次反复进行前述工序(I)(其中,将人工智能模型替换为在工序(I)中各参数被更新为最优值的第一人工智能模型的工序),从而对各靶分子的数理模型的各参数进行调节。
上述工序(I)中,参数的最优值的探索例如可通过下述方式进行:使用将每经过时间的反应产物的推算存在量与实测存在量之差的2次方的合计值的最小化设定为目标函数的人工智能模型,利用或组合遗传算法、梯度法(例:最速下降法、随机梯度下降法等)等从而将该目标函数最小化。参数的最优值的探索也可通过使用基于贝叶斯优化法的替代模型对目标函数进行逼近,将动作高速化而进行。
作为上述工序(2)中使用的靶标未知物质或细胞,没有特别限定,可例示出例如:细胞提取物、细胞培养上清液、微生物发酵产物、源自海洋生物的提取物、植物提取物、纯化蛋白或粗蛋白(例:抗体、抗体片段等)、肽、非肽化合物、合成低分子化合物、及天然化合物(例:核酸、基因等)。另外,作为细胞种类,可举出例如:神经细胞、少突胶质细胞、红细胞、单核细胞(例:淋巴细胞(NK细胞、B细胞、T细胞、单核细胞、树突细胞等))、粒细胞(例:嗜酸性粒细胞、中性粒细胞、嗜碱性粒细胞)、巨核细胞、上皮细胞(例:视网膜色素上皮细胞等)、内皮细胞(例:血管内皮细胞、肝窦内皮细胞等)、肌肉细胞、成纤维细胞(例:皮肤细胞等)、毛细胞、肝细胞、胃黏膜细胞、肠细胞、脾细胞、胰腺细胞(例:胰腺外分泌细胞等)、脑细胞、肺细胞、肾细胞及脂肪细胞等已分化的细胞、或它们的未成熟细胞等。
如上所述,工序(2)中使用的人工智能模型(以下,也称作“第二人工智能模型”)具有对应于可能被靶标未知物质或细胞靶向的全部分子的各组合,并且具有包含在上述工序(1)中经优化的各参数的数理模型。此处,前述全部分子的组合的数量例如可以以在将靶标途径数设m、化合物所能靶向的生化反应途径的靶标的最大数设为k时的下式的形式表示。
[数学式1]
其中,n=0为该化合物不靶向补体途径中的任一者的情况。根据需要,组合的数量可根据靶标未知物质或细胞的抑制方式(例:可逆抑制、竞争性抑制、反竞争性抑制、混合型抑制、非竞争性抑制、别构抑制等)而增加。
工序(2)中,通过将对各靶分子赋予权重后的、显示每经过时间的反应产物的推算存在量的数据组、和显示实测存在量的数据组作为学习数据输入第二人工智能模型中,能够对各靶分子的数理模型的各参数进行优化。典型而言,通过将上述学习数据输入人工智能模型中,制作横轴为时间、纵轴为反应产物的乘以权重后的蓄积量的、推算图表(推算图表以上述全部分子的组合的数量存在)。
工序(2)中的各靶分子的数理模型的各参数的优化例如可利用以下的工序进行。
工序(III),将工序(2)用学习数据输入第二人工智能模型中,利用该人工智能模型探索各靶分子的数理模型的各参数的最优值,并将该参数更新为该最优值;及
工序(IV),从在前述工序(III)中各参数被更新为最优值的各靶分子的数理模型中,将能够最好地说明实测存在量的数理模型判定为与各物质或细胞的靶分子对应的数理模型。
工序(2)中的权重可基于例如靶标未知物质或细胞的相似性、例如物质的结构数据的相似性、细胞的性质的相似性等而确定,典型而言,相似性高则设定为高权重,相似性低则设定为低权重。通过如此从结构数据等靶分子之外的观点考虑设定权重,能够防止参数探索的发散。物质的结构数据的相似性可通过例如共通的骨架的数量越多、且越是共有复杂的骨架,则相似性越高来确定。作为上述骨架,例如低分子化合物的情况下,可举出官能团、烃骨架(例:烷烃、烯烃、炔烃等)、芳香烃(例:苯、萘等)、环状烃等,蛋白质等肽的情况下,可举出氨基酸序列、α螺旋结构、β结构等,但并不限于此。更具体而言,低分子化合物的结构数据的相似性可利用例如使用了化学结构的拓扑片段谱(Topological FragmentSpectra)(TFS)表现的手法(Takahashi Y等,Advances in Molecular Similarity,(1998)2:93-104)、使用了KCOMBU(Kemical compound COMparison using Build-Up algorithm)的方法(Kawabata T等,J Chem Inf Model,(2011)51:1775-1787)等而确定。另外,肽的相似性可使用BLAST、DSSP算法(Kabsch W等,Biopolymers,(1983)22(12):2577-637)等而确定。
权重值可以直接采用利用上述方法设定的值,也可以以具有该值作为初始值的变量的形式,通过机器学习进行调节。例如,也可使用具有已在上述工序(1)或工序(2)中调节完的参数作为定量的数理模型,在设定了利用上述方法设定的初始值的基础上进行学习以提高能选择正确的靶标途径的概率,从而调节权重值。利用该工序,对于靶标途径未知的化合物,可提高靶标途径的预测精度。另外,工序(2)还可以包含工序(V):对工序(III)的权重的妥当性进行验证。权重的妥当性的验证例如可通过下述方式进行:通过利用了靶标未知物质或细胞与靶细胞接触后的反应产物的显示实测存在量的数据组与显示包含权重值的数理模型的推算存在量的数据组的比较的交叉验证,来判定最好地说明实测存在量的权重值。
工序(III)的显示推算存在量的数据组例如可通过将各物质或细胞在培养基中的浓度、和该物质或细胞与靶细胞的接触时间点的反应产物的存在量作为初始值代入包含在工序(1)中经优化的各靶分子的各参数的数理模型而得到。
为了防止参数探索的发散,也优选预先限定参数范围的探索范围。因此,本发明的一个方式中,提供前述工序(III)的探索是从在前述工序(1)中经优化的各靶分子的参数集中、在将物质或细胞与靶细胞接触后所推算的参数范围设定为探索范围的范围内进行的方法。上述参数范围的探索范围的设定例如可通过预先实施基于遗传算法等的全局解的锁定而进行。
上述工序(III)中,参数的最优值的探索例如可通过下述方式进行:使用将每经过时间的反应产物的推算存在量与实测存在量之差的2次方的合计值的最小化设定为目标函数的人工智能模型,利用或组合遗传算法、梯度法(例:最速下降法、随机梯度下降法等)等从而将该目标函数最小化。参数的最优值的探索也可通过使用基于贝叶斯优化法的替代模型对目标函数进行逼近,将动作高速化而进行。通过高速化,能够将上述遗传算法、梯度法的探索次数进行数万次以上,或者进行数百万次以上也是可能的,精度可进一步得以提高。
反应产物的实测存在量的测定可以与上述工序(1)中记载的方法同样地进行。另外,靶标未知物质或细胞与靶细胞的接触方法、细胞的培养方法等也可以与靶标已知物质或细胞与靶细胞接触的情况同样地进行。
前述工序(IV)或(V)之后,可以包括:工序(VI),将在前述工序(1)中经优化的参数更新为在前述工序(IV)中所判定的数理模型的最优参数;及工序(VII),使用关于其他多个靶标未知物质或细胞的、对各靶分子赋予权重后的显示每经过时间的反应产物的推算存在量的数据组、和显示实测存在量的数据组,对各物质或细胞依次反复进行上述工序(III)-(VI)(其中,将工序(III)的人工智能模型替换为具有在工序(VI)中进行了参数向最优值的更新的数理模型的人工智能模型的工序),从而对各靶分子的数理模型的各参数进行调节。
就前述工序(IV)中的能够最好地说明实测存在量的数理模型而言,例如,可以将经赋予前述权重的每经过时间的反应产物的推算存在量与实测存在量之差的2次方的合计值最小的数理模型视为最好地说明实测存在量的数理模型。因此,本发明的一个方式中,前述工序(IV)的工序可以为将经赋予前述权重的每经过时间的反应产物的推算存在量与实测存在量之差的2次方的合计值为最小值的数理模型判定为与该物质或细胞的靶分子对应的数理模型的工序。
本发明中使用的、靶标已知物质、靶标未知物质、补体供给源等例如为低分子化合物的情况下,可利用现有的合成方法等而制造。另外,为蛋白质等肽的情况下,可以利用本身已知的肽合成方法(例:固相合成法、液相合成法等)、从生物体分离的方法而制备,也可以使用市售的肽。或者,将编码蛋白质的基因导入大肠杆菌等宿主细胞而产生蛋白质也能够得到蛋白质。编码蛋白质的基因、或者本发明中使用的核酸也可以通过下述方式得到:使用从具有该基因的细胞提取的基因组DNA,或者由提取的mRNA制作cDNA,以该DNA为模板通过PCR法扩增为所期望的长度的核酸;或者使用市售的DNA/RNA自动合成仪等通过化学合成而得到。以此方式得到的蛋白质可利用已知的提纯法、例如溶剂萃取、蒸馏、柱色谱、液相色谱、重结晶、它们的组合等而纯化分离。
以下,通过具体例对本发明的构建方法详细地进行说明,但本发明的范围并不限于该构建方法。
工序(1)
以补体途径为例,利用Liu B等,PLoS Comput Biol,(2011)7(1):e1001059中报道的、对包含42个物质的补体途径通过包含85个参数的42种反应的常微分方程进行描述的数理模型。上述文献的Text S1中已具体公开了上述微分方程式,通常可以用以下的数式表示。
[数学式2]
[t为经过时间,
x
r
n
g
对于产物存在量及参数的初始值,输入前述的文献中记载的值(引用自该文献,分别示为表2及表3)。需要说明的是,表中的*表示是已知的参数。
[表2]
[表3]
将数理模型中包含的常微分方程通过基于Raissi M等,arXiv:1708.07469的手法,以深度神经网络的层的形式进行逼近,从而构建工序(1)用人工智能模型。分别使选自作为对象的文库的靶标已知物质与源自通过酵母聚糖进行了补体激活的源自人iPS细胞的血管内皮细胞接触,进行24小时培养。在此期间,每6小时回收培养基上清液,对上清液中的反应产物(C3、C5、MAC)进行定量,从而取得工序(1)用学习数据。将由工序(1)用人工智能模型输出的推算存在量与工序(1)用学习数据之差的2次方的合计值的最小化定义为目标函数,执行贝叶斯优化。通过对每靶标已知物质反复进行该操作,从而取得各靶分子的人工智能模型参数集,输入该参数集作为工序(2)用人工智能模型群的参数初始值。
工序(2)
用与工序(1)同样的步骤,使选自作为对象的文库的靶标未知物质与源自通过酵母聚糖进行了补体激活的源自人iPS细胞的血管内皮细胞接触,取得工序(2)用学习数据。利用Kawabata,T.(2011)J.Chem.Info.Model.51,1775-1787.的通过累积法计算基于最大公共子结构(Maximum Common Substructure;MCS)的物质间的映射的近似解的算法,将靶标未知物质的结构信息与各靶标已知物质的结构信息进行比较从而计算相似率,根据相似度的高度,以0~1的比例设定权重值。相似率的计算利用作为Web资源的KCOMBU(http://strcomp.protein.osaka-u.ac.jp/kcombu/)中所公开的Flexible Transformation of 3DConformer by Pairwise MCS Comparison而实施。为了验证权重值的调节和妥当性,使用包含权重值的工序(2)用人工智能模型,作为贝叶斯优化的学习选项,仅将权重值指定为优化对象,以工序(1)同样的步骤执行优化。再次将经调整的权重值输入工序(2)用人工智能模型中,将不包括权重值的所有途径中包含的参数作为优化对象,以与工序(1)同样的步骤实施优化。并且,输出使用了最终得到的最优解的情况下的目标函数误差。对各靶标未知物质反复进行该操作,采用目标函数误差最小的人工智能模型中包含的数理模型的参数及权重值作为最优解。由该权重值推算该靶标未知物质靶向各分子的概率。
基于以上的工序的模型构建、优化算法的实施等的数值计算在MATLAB(Mathworks公司)上实行。
-2.预测靶分子的方法-
可使用上述1.中记载的本发明的模型构建方法利用所构建的具有数理模型的人工智能模型(以下,也称作“本发明的人工智能模型”)来预测靶分子。因此,在本发明的其他方式中,提供对受试物质或受试细胞的生化反应途径中的靶分子进行预测的方法(以下有时称为“本发明的预测方法”),其包括下述工序:
工序(A),将关于受试物质或受试细胞的、各物质或细胞在培养基中的浓度、该物质或细胞与靶细胞的接触时间点的反应产物的存在量、和显示每经过时间的实测存在量的数据组(以下,也称为“输入数据组”)输入本发明的人工智能模型中,利用该人工智能模型算出各靶分子的反应产物的每经过时间的推算存在量;
及
工序(B),从由工序(A)算出的、每靶分子的反应产物的每经过时间的推算存在量中,将能够最好地说明实测存在量的靶分子判定为该受试物质或受试细胞的靶标。
作为工序(A)中使用的受试物质或受试细胞,没有特别限定,可例示出例如:细胞提取物、细胞培养上清液、微生物发酵产物、源自海洋生物的提取物、植物提取物、纯化蛋白或粗蛋白(例:抗体、抗体片段等)、肽、非肽化合物、合成低分子化合物、及天然化合物(例:核酸、基因等)。另外,作为细胞,可举出例如:神经细胞、少突胶质细胞、红细胞、单核细胞(例:淋巴细胞(NK细胞、B细胞、T细胞、单核细胞、树突细胞等))、粒细胞(例:嗜酸性粒细胞、中性粒细胞、嗜碱性粒细胞)、巨核细胞、上皮细胞(例:视网膜色素上皮细胞等)、内皮细胞(例:血管内皮细胞、肝窦内皮细胞等)、肌肉细胞、成纤维细胞(例:皮肤细胞等)、毛细胞、肝细胞、胃黏膜细胞、肠细胞、脾细胞、胰腺细胞(例:胰腺外分泌细胞等)、脑细胞、肺细胞、肾细胞及脂肪细胞等已分化的细胞、或它们的未成熟细胞等。
受试物质或受试细胞另外也可使用包括(1)生物学的文库、(2)使用反褶积的合成文库法、(3)“单珠单化合物(one-bead one-compound)”文库法、及(4)使用亲和层析分选的合成文库法在内的本领域中已知的组合文库法中的大量路径中的任一者而得到。使用亲和层析分选的生物学的文库法限于肽文库,其他4个路径可适用于非肽寡聚物、或化合物的低分子化合物文库(Lam(1997)Anticancer Drug Des.12:145-67)。分子文库的合成方法的例子可在本技术领域中找到(DeWitt等,(1993)Proc.Natl.Acad.Sci.USA90:6909-13;Erb等,(1994)Proc.Natl.Acad.Sci.USA 91:11422-6;Zuckermann等,(1994)J.Med.Chem.37:2678-85;Cho等,(1993)Science 261:1303-5;Carell等,(1994)Angew.Chem.Int.Ed.Engl.33:2059;Carell等,(1994)Angew.Chem.Int.Ed.Engl.33:2061;Gallop等,(1994)J.Med.Chem.37:1233-51)。化合物文库可以以溶液(参见Houghten(1992)Bio/Techniques 13:412-21)或珠(Lam(1991)Nature 354:82-4)、芯片(Fodor(1993)Nature 364:555-6)、细菌(美国专利第5,223,409号)、孢子(美国专利第5,571,698号、美国专利第5,403,484号、及美国专利第5,223,409号)、质粒(Cull等,(1992)Proc.Natl.Acad.Sci.USA 89:1865-9)或噬菌体(Scott and Smith(1990)Science 249:386-90;Devlin(1990)Science 249:404-6;Cwirla等,(1990)Proc.Natl.Acad.Sci.USA87:6378-82;Felici(1991)J.Mol.Biol.222:301-10;美国专利申请第2002103360号)的形式制作。
工序(A)中使用的输入数据组可利用与上述1.的学习数据的取得(测定)方法同样的方法而得到。关于使用的靶细胞的种类、培养基的种类、培养方法、受试物质或受试细胞与靶细胞的接触方法,也可使用与上述1.中记载同样的细胞、培养基或方法。
上述工序(B)中,例如,通过在前述工序(A)中算定的各靶分子的推算存在量与实测存在量的比较,可以基于该受试物质或受试细胞靶向各靶分子的概率来判定靶分子。例如,对各靶分子算出工序(A)中算定的、每经过时间的反应产物的推算存在量与实测存在量之差的2次方的合计值,将该值输入softmax函数,可将输出的值视为各靶分子的概率。并且,可以将概率最高的靶分子判定为受试物质或受试细胞的靶标。
也可以是,将基于本发明的预测方法的判定结果作为学习数据,如本发明的模型构建方法中所记载的那样使本发明的人工智能模型再次学习,对该人工智能模型所具有的数理模型的各参数进行再调节。
-3.用于预测靶分子的装置-
接着,具体示出用于实施本发明的预测方法的装置(以下有时称为“本发明的装置”)的构成。
图2为示意性地示出本发明的装置的构成的一个例子的框图。如图2所示,该装置至少具有接收部M1、第一运算部M2、第二运算部M3和输出部M4而构成。
该装置可以组合电子电路、电气电路、独立的处理装置而构建,但通过计算机和由其执行的计算机程序构成前述的各部(接收部M1、第一运算部M2、第二运算部M3和输出部M4等)是优选的实施方式。以下,举出通过该计算机和该计算机程序构成该装置的情况的例子对各部进行说明。以下,也将作为该装置的(计算机和由其执行的计算机程序)简称为“计算机”而进行说明。
该装置可以构成为用户各人所使用的台式型、笔记本型、或平板型的计算机,也可以构成为介由局部区域网(LAN)、因特网等通讯途径从1个以上的终端计算机访问的服务器计算机。从可在多个终端计算机中利用1个共通的程序、共通的学习数据等方面考虑,前述服务器计算机为优选的方式。作为该装置的计算机可适当具备操作所需的输入装置、显示屏幕、和外部装置进行数据交换所需的接口(interface)、外围设备等。以下的说明中,该装置为介由因特网从外部的计算机访问的服务器计算机,但并不限于此。
接收部M1是用于从外部的输入装置、外部的计算机接收关于受试物质或受试细胞的输入数据组的部分。输入数据组的取得方法如本发明的模型构建方法及本发明的预测方法中的说明所述。
就用于将输入数据组输入接收部M1的外部装置而言,典型而言为以可介由因特网访问的方式连接于该装置的外部的计算机,也可以为介由USB等接口连接于该装置的存储器(USB存储器)、各种读取数据的装置。接收部M1构成为接收来自外部的计算机、各种外部仪器的输入数据组,将该输入数据组传送给第一运算部M2的方式。另外,接收部M1以传送输入数据组所包含的上述的每经过时间的实测存在量的方式构成。
第一运算部M2是执行上述本发明的预测方法的工序(A)的部分,以处理由接收部M1传送的输入数据组,算出各靶分子的反应产物的每经过时间的推算存在量。具体而言,利用本发明的人工智能模型作为子程序(subroutine),在该人工智能模型中输入前述输入数据组,接收作为来自该人工智能模型的运算结果的、各靶分子的反应产物的每经过时间的推算存在量。该人工智能模型中实施的运算的过程如本发明的模型构建方法及本发明的预测方法中的说明所述。由人工智能模型得到的各靶分子的反应产物的每经过时间的推算存在量被传送至第二运算部M3。
第二运算部M3为执行上述本发明的预测方法的工序(B)的装置部分。具体而言,是实施通过由第一运算部M2传送的各靶分子的推算存在量与由接收部M1传送的实测存在量的比较来求出关于各靶分子的该受试物质或细胞将其作为靶标的概率的运算的装置部分。第二运算部M3中实施的运算的过程如本发明的模型构建方法及本发明的预测方法中的说明所述。具体而言,例如,对各靶分子算出由M2传送的每经过时间的反应产物的推算存在量与由M1传送的实测存在量之差的2次方的合计值,将该值输入softmax函数,可将输出的值视为各靶分子的概率。第二运算部M3中实施的运算结果被传送至输出部M4。
输出部M4是将第二运算部中的运算结果(例:关于各靶分子的、受试物质或细胞将其作为靶标的概率、靶分子的预测结果(概率最高的靶分子)等)输出至外部的计算机等外部设备的部分。
第二运算部中的运算结果的输出的手段可以是例如:对各靶分子单纯地以列表形式并列地输出各概率、并对概率最高的靶分子施加标记而示出的方式;以按概率的降序排列靶分子的列表形式输出的方式;或者通过用软件等读取而以上述方式显示的电子数据的形式。
向接收部M1的输入数据组的发送源没有特别限定,可举出能与本发明的装置通讯的计算机,可以为研究者等所使用的终端计算机、由该终端计算机接收输入数据组并将输入数据组送信至本发明的装置的LAN的服务器计算机等。
另一方面,作为输出预测结果的对象的规定输出目的也没有特别限定,可以是各种图像显示装置、各种印刷输出装置、能与本发明的装置通讯的计算机等预先确定的输出目的。通常的研究部门的网络系统中,多数情况下输入数据组的发送源也是预测结果的输出目的(例如,从研究者的终端计算机发送数据组,将预测结果送回至该研究者的终端计算机的情况等),从本发明的装置观察时的输入数据组的发送源与预测结果的发送目的也可以彼此不同。
-4.用于预测靶分子的计算机程序-
构成本发明的装置的各部(上述的接收部M1、第一运算部M2、第二运算部M3、输出部M4等)可以分别组合电子电路、电气回路、独立的处理装置而构建,但使用计算机,通过由该计算机执行的程序(以下有时称为“本发明的程序”)构成上述各部是优选的实施方式。
本发明的程序如图3中示出的流程所示,基本上与上述本发明的预测方法的流程完全相同,具有作为接收手段发挥功能的接收部P1、作为第一运算手段发挥功能的第一运算部P2、作为第二运算手段发挥功能的第二运算部P3、和作为由第二运算部P3输出的预测结果的输出手段发挥功能的输出部P4而构成计算机。
接收部P1为用于从外部的输入装置、外部的计算机接收关于受试物质或受试细胞的输入数据组的程序部分。输入数据组的取得方法如本发明的模型构建方法及本发明的预测方法中的说明所述。对于输入数据组而言,可分别设为直接接收由操作员发送的输入数据组的程序配置。另外,对于输入数据组而言,也可以为基于操作员输入数据组的数据名称访问自身的存储装置(SSD、HDD、DVD-ROM、CD-ROM等)、外部数据库而获取数据的程序配置。
就用于将输入数据组输入至接收部P1的外部装置而言,典型而言为以可介由因特网访问的方式连接于该装置的外部的计算机,也可以为介由USB等接口连接于该装置的存储器(USB存储器)、各种读取数据的装置。接收部P1构成为接收来自外部的计算机、各种外部设备的输入数据组,将该输入数据组传送给第一运算部P2的方式。另外,接收部P1以传送输入数据组所包含的上述的每经过时间的实测存在量的方式构成。
第一运算部P2是执行上述本发明的预测方法的工序(A)的程序部分,以处理由接收部P1传送的输入数据组,算出各靶分子的反应产物的每经过时间的推算存在量。具体而言,利用本发明的人工智能模型作为子程序,在该人工智能模型中输入前述输入数据组,接收作为来自该人工智能模型的运算结果的、各靶分子的反应产物的每经过时间的推算存在量。该人工智能模型中实施的运算的过程如本发明的模型构建方法及本发明的预测方法中的说明所述。由人工智能模型得到的各靶分子的反应产物的每经过时间的推算存在量被传送至第二运算部P3。
第二运算部P3为执行上述本发明的预测方法的工序(B)的程序部分。第二运算部P2中实施的运算的过程如本发明的模型构建方法及本发明的预测方法中的说明所述。具体而言,例如,对各靶分子算出由P2传送的每经过时间的反应产物的推算存在量与由P1传送的实测存在量之差的2次方的合计值,将该值输入softmax函数,可将输出的值视为各靶分子的概率。第二运算部P3中实施的运算结果被传送至输出部P4。
输出部P4是将关于第二运算部P3中求出的关于各靶分子的上述概率输出的程序部分。第二运算部中的运算结果的输出目的、输出的手段等如输出部M4中的说明所述。
本发明的人工智能模型通过输入各种输入数据组,从而算出各靶分子的反应产物的每经过时间的推算存在量,因此可以基于该算出数据来预测受试物质或细胞的靶分子。这在疾病的治疗药等的筛选中可以以良好的精度预测补体途径等复杂的生化反应途径中的靶分子,因此有助于可靠性高的创新药物筛选。
本申请以于日本提出申请的日本特愿2020-099489(申请日:2020年6月8日)为基础,其内容全部包含在本说明书中。
附图标记说明
1 靶分子预测装置
2 已学习的人工智能模型
3 输入数据组的发送源(外部的计算机等)
- 颗粒封入方法、检测靶分子的方法、阵列、试剂盒及靶分子检测装置
- 颗粒封入方法、检测靶分子的方法、阵列、试剂盒及靶分子检测装置