一种基于三维重建的人脸照片生成动画的方法及装置
文献发布时间:2023-06-19 18:58:26
技术领域
本申请涉及人脸图像处理技术领域,尤其是一种基于三维重建的人脸照片生成动画的方法及装置。
背景技术
随着动画娱乐产业的发展,越来越多的群体加入了视频创作的行列中。一些酷炫,有意思的特效动画,通常需要创作者使用专业的工具和技巧去实现,对于普通用户和初学者来说具有一定的使用门槛,因此实现特效动画的自动化,降低用户的门槛,让普通用户也能感受到特效动画的神奇,是一个比较重要的工作。
目前,人脸编辑动画特效是用户比较感兴趣的一个方向,用户输入一张照片,通过一些技术使得照片中的人物或眨眼,或张嘴,或微笑,让照片的人‘活’过来。这些技术属于人脸编辑的范畴,而人脸编辑动画主要包括两方面的内容:人脸表情的控制,例如张嘴,闭嘴,睁眼,闭眼,微笑,生气等能表示人的情绪;另外一方面是人脸的姿态控制,例如,低头,抬头,向左看,向右看,摆头等。
当前人脸编辑,包括人脸编辑动画的实现,主要是使用GAN技术为基础,例如NVIDIA的styleGAN,主要是从图片中提取人脸的眼睛,嘴巴,脸部等特性进行解耦,然后进行参数化控制实现人脸编辑动画,但是目前这种方法模型比较大,解耦性不是太好,会出现编辑眼睛时,人脸其它部分也发生了形变,导致效果看起来不真实且很奇怪,生成的动画实际看起来的效果较差。
发明内容
本申请的目的在于克服现有技术不足之处,提供一种基于三维重建的人脸照片生成动画的方法及装置。
第一方面,提供了一种基于三维重建的人脸照片生成动画的方法,包括:
获取适合特效应用场景的图像数据,其中,所述数据包括照片和视频帧画面,且所述照片和视频帧画面均包含人物头部;
对所述图像数据进行预处理;
搭建深度学习模型,并将预处理后的图像数据输入到深度学习模型中进行模型训练,以得到预训练模型;
将预处理后的人脸照片数据输入到所述预训练模型进行推理,以得出该人脸照片的FLMAE参数和相机参数,并调节出动画每一帧所需的FLMAE参数;
将相机参数和调节后的FLAME参数使用FLAME模型进行解码,以得每一帧的3D人头模型;
对人脸照片进行UV映射,以得到人脸照片的UVmap信息;
利用UVmap信息对每一帧的3D人头模型进行逐帧渲染,渲染背景后依次显示即可生成动画。
进一步的,所述数据的预处理包括:
将所述照片和视频帧画面进行裁剪,以得到尺寸同一的图像数据;
利用开源人脸检测算法FAN获取人脸的landmarks;
利用脸部分割算法获取脸部的mask。
进一步的,所述深度学习模型以Resnet50为基础,输入包含人头的图像到深度学习模型,可输出对应与这张照片的FLMAE模型参数和相机参数,其中,FLMAE模型参数包括shape参数、pose参数和expression参数。
进一步的,所述预处理后的人脸照片数据为人脸照片经过裁剪、人脸关键点检测和人脸区域分割处理后得到的数据。
进一步的,将相机参数和调节后的FLAME参数使用FLAME模型进行解码,包括:
将相机参数以及调节出的动画每一帧所需的FLMAE参数输入到FLAME模型中依次进行解码;
输出每一帧对应的3D人头模型的顶点位置信息,即得到了这一帧的3D人头模型。
进一步的,对人脸照片进行UV映射,包括:
利用相机参数将3D人头顶点投影到与原始人脸照片尺寸大小相同的2D平面,以得到UV坐标;
将所述UV坐标除以对应的原始人脸照片宽和高,即得到3D人头顶点与原始人脸照片相关联的UV映射关系;
输出每个顶点对应于原始人脸照片中的颜色信息,即3D人头模型对应于原始人脸照片的UVmap信息。
进一步的,利用UVmap信息对每一帧的3D人头模型进行逐帧渲染,渲染背景后依次显示即可生成动画,包括:
将所述3D人头模型的顶点位置信息输入到顶点着色器中;
将所述相机参数计算为投影矩阵,并输入到顶点着色器中;
以原始照片为采样数据,并以所述UV映射关系作为UV坐标,即可依次渲染出每一帧的图像;
对原始人脸照片数据进行渲染,得出背景渲染图;
将背景渲染图作为每一帧图像的背景;
将添加背景后的每一帧的图像依次进行显示,即可生成动画。
第二方面,提供了一种基于三维重建的人脸照片生成动画的装置,包括:
获取模块,用于获取适合特效应用场景的图像数据,其中,所述数据包括照片和视频帧画面,且所述照片和视频帧画面均包含人物头部;
预处理模块,用于对所述图像数据进行预处理;
模型搭建和训练模块,用于搭建深度学习模型,并将预处理后的图像数据输入到深度学习模型中进行模型训练,以得到预训练模型;
推理模块,用于将预处理后的人脸照片数据输入到所述预训练模型进行推理,以得出该人脸照片的FLMAE参数和相机参数,并调节出动画每一帧所需的FLMAE参数;
解码模块,用于将相机参数和调节后的FLAME参数使用FLAME模型进行解码,以得每一帧的3D人头模型;
UV映射模块,用于对人脸照片进行UV映射,以得到人脸照片的UVmap信息;
渲染模块,用于利用UVmap信息对每一帧的3D人头模型进行逐帧渲染,渲染背景后依次显示即可生成动画。
第三方面,提供了一种计算机可读存储介质,所述计算机可读介质存储用于设备执行的程序代码,该程序代码包括用于执行如第一方面中的任意一种实现方式中方法的步骤。
第四方面,提供了一种电子设备,所述电子设备包括处理器、存储器及存储在所述存储器上并可在所述处理器上运行的程序或指令,所述程序或指令被所述处理器执行时实现如第一方面中的任意一种实现方式中的方法的步骤。
本申请具有如下有益效果:本申请提供了一种新的思路去实现图像的人脸编辑动画,通过直接采用三维重建的方式,使得三维重建的人脸模型可操作性更强,后续以此方案为基础,可衍生出更多人头人脸的编辑方法,而且,通过结合深度学习和图像渲染,可以实现人脸编辑动画的自动化操作流程,生成的动画真实感更强,使得动画显示效果更加自然和真实,还可以实现与用户的交互,大大的降低了用户进行动画创作的门槛。
附图说明
构成本申请的一部分的附图用于来提供对本申请的进一步理解,本申请的示意性实施例及其说明用于解释本申请,并不构成对本申请的不当限定。
为了更清楚地说明本申请实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本申请的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
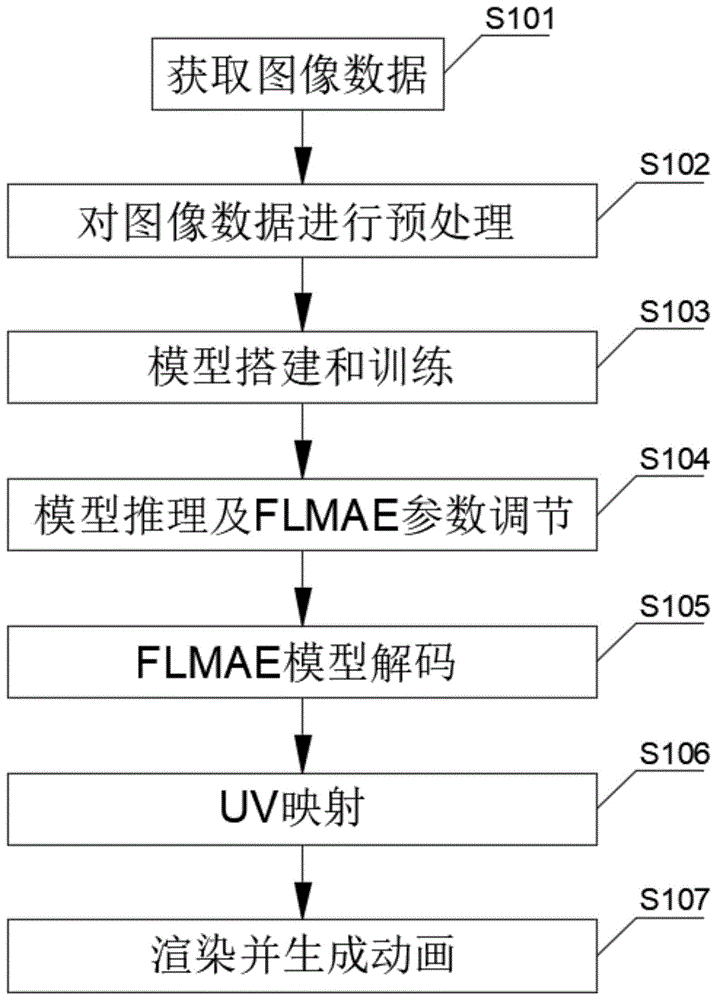
图1是本申请实施例一的基于三维重建的人脸照片生成动画的方法的流程图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
实施例一
本申请实施例一所涉及的一种基于三维重建的人脸照片生成动画的方法,包括:获取适合特效应用场景的图像数据,其中,所述数据包括照片和视频帧画面,且所述照片和视频帧画面均包含人物头部;对所述图像数据进行预处理;搭建深度学习模型,并将预处理后的图像数据输入到深度学习模型中进行模型训练,以得到预训练模型;将预处理后的人脸照片数据输入到所述预训练模型进行推理,以得出该人脸照片的FLMAE参数和相机参数,并调节出动画每一帧所需的FLMAE参数;将相机参数和调节后的FLAME参数使用FLAME模型进行解码,以得每一帧的3D人头模型;对人脸照片进行UV映射,以得到人脸照片的UVmap信息;利用UVmap信息对每一帧的3D人头模型进行逐帧渲染,渲染背景后依次显示即可生成动画,本申请的实施例提供了一种新的思路去实现图像的人脸编辑动画,通过直接采用三维重建的方式,使得三维重建的人脸模型可操作性更强,后续以此方案为基础,可衍生出更多人头人脸的编辑方法,而且,通过结合深度学习和图像渲染,可以实现人脸编辑动画的自动化操作流程,生成的动画真实感更强,使得动画显示效果更加自然和真实,还可以实现与用户的交互,大大的降低了用户进行动画创作的门槛。
具体的,图1示出了申请实施例一中的基于三维重建的人脸照片生成动画的方法的流程图,包括:
S101、获取适合特效应用场景的图像数据,其中,所述数据包括照片和视频帧画面,且所述照片和视频帧画面均包含人物头部;
需要说明的是,适合特效应用场景的图像数据是指包含有人物头部的图像,来源于公开的人头数据集或者视频数据集,其中,对于视频数据,需要选取包含人物头部的帧画面。
S102、对所述图像数据进行预处理;
具体的,所述数据的预处理包括:
S201、将所述照片和视频帧画面进行裁剪,以得到尺寸同一的图像数据;
S202、利用开源人脸检测算法FAN获取人脸的landmarks;
S203、利用脸部分割算法获取脸部的mask。
示例性的,由于获取的图像数据中图像的尺寸大小不一致,而输入到深度学习网络的图像尺寸大小需要保持统一,因此,需要将图像数据进行裁剪或上采样(指放大图像),以使得图像数据的尺寸大小相关,例如:将图像数据的尺寸大小调整为224像素x224像素,然后再使用开源人脸检测算法FAN获取人脸的68个landmarks(特征点),使用脸部分割算法获取脸部的mask(脸部模型),即完成原始图像数据的预处理。
S103、搭建深度学习模型,并将预处理后的图像数据输入到深度学习模型中进行模型训练,以得到预训练模型;
示例性的,所述深度学习模型以Resnet50为基础,输入包含人头的图像到深度学习模型,需要注意的是,这里输入的图像是经过预处理后的图像数据,其中,图像的数据已经被统一调整为224像素x224像素,可输出对应与这张照片的FLMAE模型参数和相机参数,其中,FLMAE模型参数包括shape(外形)参数、pose(姿势)参数和expression(表情)参数。
S104、将预处理后的人脸照片数据输入到所述预训练模型进行推理,以得出该人脸照片的FLMAE参数和相机参数,并调节出动画每一帧所需的FLMAE参数;
需要说明的是,所述预处理后的人脸照片数据为人脸照片经过裁剪、人脸关键点检测和人脸区域分割处理后得到的数据。
这一步骤的目的在于获取人脸照片(即需要生成动画效果的原始人脸照片)的PLMAE参数和相机参数c,其中,FLMAE模型参数包括shape参数、pose参数和expression参数,由于FLAME模型是由参数进行控制的,手动修改FLMAE模型参数,即可得到修改后的一些列shape参数、pose参数、expression参数和相机参数c(相机参数c是保持不变的,也不需要进行调节)。
S105、将相机参数和调节后的FLAME参数使用FLAME模型进行解码,以得每一帧的3D人头模型;
具体的,将相机参数和调节后的FLAME参数使用FLAME模型进行解码,包括:
S501、将相机参数以及调节出的动画每一帧所需的FLMAE参数输入到FLAME模型中依次进行解码;
S502、输出每一帧对应的3D人头模型的顶点位置信息,即得到了这一帧的3D人头模型。
示例性的,将步骤S104得到的动画每一帧所需的FLMAE参数和相机参数c,输入到FLAME人头模型中进行解码(解码是指将一维的shape参数、pose参数、expression参数转换成3D数据,这个算法是开源的),输出是这一帧对应的FLAME模型的5023个3D人头顶点信息,即得到了这一帧的3D人头模型。
S106、对人脸照片进行UV映射,以得到人脸照片的UVmap信息;
具体的,对人脸照片进行UV映射,包括:
S601、利用相机参数将3D人头顶点投影到与原始人脸照片尺寸大小相同的2D平面,以得到UV坐标;
S602、将所述UV坐标除以对应的原始人脸照片宽和高,即得到3D人头顶点与原始人脸照片相关联的UV映射关系;
S603、输出每个顶点对应于原始人脸照片中的颜色信息,即3D人头模型对应于原始人脸照片的UVmap信息。
示例性的,对原始人脸照片进行UV映射,将3D人头模型的5023个顶点与原始人脸照片建立联系,得到每个顶点对应于原始人脸照片中的颜色信息,即3D人头模型对应于原始人脸照片的UVmap信息。
S107、利用UVmap信息对每一帧的3D人头模型进行逐帧渲染,渲染背景后依次显示即可生成动画。
具体的,利用UVmap信息对每一帧的3D人头模型进行逐帧渲染,渲染背景后依次显示即可生成动画,包括:
S701、将所述3D人头模型的顶点位置信息输入到顶点着色器中;
S702、将所述相机参数计算为投影矩阵,并输入到顶点着色器中;
S703、以原始照片为采样数据,并以所述UV映射关系作为UV坐标,即可依次渲染出每一帧的图像;
S704、对原始人脸照片数据进行渲染,得出背景渲染图;
S705、将背景渲染图作为每一帧图像的背景;
S706、将添加背景后的每一帧的图像依次进行显示,即可生成动画。
值得注意的是,基于三维重建的人脸照片编辑动画的实现,依赖于3D人头人脸模型,目前人头人脸模型主要使用3DMM的方法,主要有BFM模型和FLAME模型,由于BFM数据集来源于欧洲的人脸,因此对于亚洲人脸的估计会产生一定的偏差,而FLAME模型,其数据集由33000个3D人头扫描数据组成,涉及各个年龄段,各种类型,因此泛化能力很强,因此在本申请的技术方案中选用FLAME模型作为人头人脸模型;结合深度学习的方法,从单张图片,学习输出FLAME模型的参数,然后通过这些参数,生成人头的三维模型(即得到人头的顶点位置信息)。
得到人头的3D模型之后,可以通过改变模型的顶点位置来实现人头动画,例如,可以使用BlendShape来实现动画,但是BlendShape的方法需要产生新的表情基;而FLAME人头模型可由相关的表情参数进行控制,因此可以通过手动调节这些参数来控制顶点的变化,使3D人头模型‘动’起来,从而实现眨眼、摇头、点头和张嘴等动作。
模型动画生成后,另外一个需要解决的问题是纹理,需要将皮肤的材质赋予给模型,使模型看起来更加真实化,目前常用的做法是通过深度学习的方法学习得到人物的albedo图、normal图和光照参数等等,然后通过光照渲染,得到模型的颜色,但是这种方法在真实感方面与用户的感受仍然具有一定的差距,这种方法是为了还原出照片中人物的颜色,而照片中人物的颜色是正常的,因此直接将原始人脸照片的颜色通过UV映射的方式,渲染出来的结果在真实感方面和原始人脸照片基本相同,结合上面的基于3D模型的动画即可实现真实的人脸照片编辑动画。
基于三维重建的人脸照片编辑动画实现,充分利用深度学习的强大‘学习’能力和现有的人头人脸模型相结合,并且从原始人脸照片中获取模型纹理表示,解决了FLAME模型不具备纹理表示或者其它方案生成纹理不真实的问题,产生的人脸动画真实感很强,可玩性很高。下面以一个实现人脸照片眨眼动画的实现来进一步说明本文的方法,需要说明的是下面这些操作的前提是已经搭建并训练得到了预训练模型:
1.用户输入一张包含人脸的照片数据;
2.将用户的原始照片经过裁剪、人脸关键点检测和人脸区域分割预处理后,得到预处理后的数据;
3.将预处理的数据送入深度学习的预训练模型进行推理,得到FLAME模型的中shape参数、pose参数和expression参数,以及相机参数c等相关数据;
4.在FLAME模型中,控制眨眼动作的系数在expression参数中,将推理得到的expression参数中眨眼相关的系数替换为调整后的一系列系数;
5.将推理以及调整后得到的一系列FLAME参数送入FLAME模型依次进行解码,得到每一帧对应的3D人头模型的顶点位置信息;
6.将上述步骤3中得到的FLAME参数送入FLAME模型中进行解码,得到原始图片对应的3D人头顶点信息,然后利用步骤3中获取的相机参数c,将3D人头顶点投影到与原始人脸照片大小相同的2D平面,得到的UV坐标除以对应的图片宽高,即可得到与原始人脸照片相关联的UV映射关系;
7.渲染,这一步骤中,选取跨平台的OpenGL进行渲染,这里展示渲染一帧的操作:将步骤5中的3D顶点数据输入到顶点着色器中,并且将步骤3中得到的c计算为投影矩阵,输入到顶点着色器中;同时以原始人脸照片作为采样数据,步骤6中的UV映射关系作为UV坐标,这样即可渲染得到一帧图片,依照相同的渲染方法,对所有帧进行渲染;
8.由于步骤7中渲染得到的仅仅是重建的人头数据,不包含其它的信息,因此需要补充,为此,将原始人脸照片数据进行渲染,作为步骤7的背景使用;
9.将步骤7和步骤8产生的每一帧图片依次进行显示,即可生成原始照片的眨眼动画。
实施例二
本申请实施例二所涉及的一种基于三维重建的人脸照片生成动画的装置,包括:
获取模块,用于获取适合特效应用场景的图像数据,其中,所述数据包括照片和视频帧画面,且所述照片和视频帧画面均包含人物头部;
预处理模块,用于对所述图像数据进行预处理;
模型搭建和训练模块,用于搭建深度学习模型,并将预处理后的图像数据输入到深度学习模型中进行模型训练,以得到预训练模型;
推理模块,用于将预处理后的人脸照片数据输入到所述预训练模型进行推理,以得出该人脸照片的FLMAE参数和相机参数,并调节出动画每一帧所需的FLMAE参数;
解码模块,用于将相机参数和调节后的FLAME参数使用FLAME模型进行解码,以得每一帧的3D人头模型;
UV映射模块,用于对人脸照片进行UV映射,以得到人脸照片的UVmap信息;
渲染模块,用于利用UVmap信息对每一帧的3D人头模型进行逐帧渲染,渲染背景后依次显示即可生成动画。
实施例三
本申请实施例三所涉及的一种计算机可读存储介质,所述计算机可读介质存储用于设备执行的程序代码,该程序代码包括用于执行如本申请实施例一中的任意一种实现方式中方法的步骤;
其中,计算机可读存储介质可以是只读存储器(read only memory,ROM),静态存储设备,动态存储设备或者随机存取存储器(random access memory,RAM);计算机可读存储介质可以存储程序代码,当计算机可读存储介质中存储的程序被处理器执行时,处理器用于执行如本申请实施例一中的任意一种实现方式中方法的步骤。
实施例四
本申请实施例四所涉及的一种电子设备,所述电子设备包括处理器、存储器及存储在所述存储器上并可在所述处理器上运行的程序或指令,所述程序或指令被所述处理器执行时实现如本申请实施例一中的任意一种实现方式中的方法;
其中,处理器可以采用通用的中央处理器(central processing unit,CPU),微处理器,应用专用集成电路(application specific integrated circuit,ASIC),图形处理器(graphics processing unit,GPU)或者一个或多个集成电路,用于执行相关程序,以实现本申请实施例一中的任意一种实现方式中的方法。
处理器还可以是一种集成电路电子设备,具有信号的处理能力。在实现过程中,本申请实施例一中的任意一种实现方式中方法的各个步骤可以通过处理器中的硬件的集成逻辑电路或者软件形式的指令完成。
上述处理器还可以是通用处理器、数字信号处理器、专用集成电路(ASIC)、现成可编程门阵列(field programmable gatearray,FPGA)或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件。可以实现或者执行本申请实施例中的公开的各方法、步骤及逻辑框图。通用处理器可以是微处理器或者该处理器也可以是任何常规的处理器等。结合本申请实施例所公开方法的步骤可以直接体现为硬件译码处理器执行完成,或者用译码处理器中的硬件及软件模块组合执行完成。软件模块可以位于随机存储器,闪存、只读存储器,可编程只读存储器或者电可擦写可编程存储器、寄存器等本领域成熟的存储介质中。该存储介质位于存储器,处理器读取存储器中的信息,结合其硬件完成本申请实施例的数据处理的装置中包括的单元所需执行的功能,或者执行本申请实施例一中的任意一种实现方式中方法。
以上,仅为本申请较佳的具体实施方式;但本申请的保护范围并不局限于此。任何熟悉本技术领域的技术人员在本申请揭露的技术范围内,根据本申请的技术方案及其改进构思加以等同替换或改变,都应涵盖在本申请的保护范围内。
- 一种多目立体视觉的人脸三维重建装置及方法
- 基于多任务学习的单视图人脸三维重建及纹理生成的方法
- 一种从单幅图像生成人脸动画的方法
- 一种基于侧脸照片进行人脸三维重建的方法
- 基于全景照片的动画生成方法及装置