一种基于证据关联折扣的多分类器融合识别方法
文献发布时间:2023-06-19 19:28:50
技术领域
本发明属于目标识别领域,具体涉及一种基于证据关联折扣的多分类器融合识别方法。
背景技术
目标识别是机器学习技术的一个重要领域,主要目的是通过训练一个机器学习模型对未知目标的类型进行识别,并通过多种手段提升目标类型识别的准确率。常见的目标识别方法大致可分为两类,一种是基于单分类器的目标识别算法,一种是基于多分类器的目标识别算法。相较于单分类器目标识别算法,基于多分类器的目标识别方法通过利用不同分类器在识别机理、识别性能、场景适用性等方面的互补性和冗余性,将多个不同分类器的识别结果整合成一个综合的识别结果,从而在整体上提升目标识别的准确性和稳定性。
在基于多分类器的目标识别过程中,一个关键的问题在于如何有效融合不同分类器的识别结果,从而最终实现识别准确率的提升。现有的多分类器融合方法大体可分为特征层融合与决策层融合两类。特征层融合利用各分类器提取到的目标特征,在特征层面实现不同分类器识别结果的整合,更加充分地利用了目标的原始信息。但特征层融合面临计算量大,各分类器提取的特征形式不一导致难以有效整合等问题。决策层融合则直接对各分类器的最终识别结果进行处理,不涉及底层分类器的具体实现,有利于实现分布式的目标识别,在计算资源有限、识别输出稳定性要求高的场景具有较强的现实需求,并且目前已有大量广泛的应用。
现有的决策层融合方法主要包括贝叶斯推理、多数票决、加权融合、模糊推理、神经网络、证据理论等。这些方法结果的好坏特别依赖于对底层分类器性能信息利用的程度。常见的分类器性能信息主要包括整体识别准确率、精度、召回率、F1 score等,这些度量指标都是来自于分类器在已知类别数据集上识别结果的混淆矩阵,混淆矩阵包含了分类器对不同类型目标识别能力的全部信息。现有的决策层融合方法大都不是直接基于各分类器的混淆矩阵,而是利用各分类器的类别识别准确率、精度、召回率等指标,一定程度上丢失了不同分类器在不同类别上识别能力的差异性,造成融合识别结果的准确性难以保证。
对此,为了解决底层分类器识别能力的差异性信息丢失问题,本申请直接利用各底层分类器在已知类别数据集上识别结果的混淆矩阵,充分挖掘各分类器在不同类别上识别能力的互补性和冗余性,有效实现基于多分类器融合的目标识别过程,提升综合识别的准确性。
发明内容
本发明所要解决的技术问题是:如何实现基于多分类器决策层融合的目标识别,充分利用底层的基分类器在不同类别上识别能力的差异性和互补性。
为解决上述技术问题,本发明采用的技术方案是一种基于证据关联折扣的多分类器融合识别方法,其特征在于,包括以下步骤:
步骤一、利用基分类器混淆矩阵生成语义关联矩阵;
步骤101:输入一个包含N个样本的数据集D,这些样本来自n个类别,样本的类别集合记为Ω={c
步骤102:根据以下公式对每个混淆矩阵M
W
其中,k=1,2,…,K,ε=0.0001是一个极小量,I
步骤103:对于每个基分类器
矩阵U
因此,U
(1)若
(2)若A,B∈{1,2,…,n}且A,B都不为空,则令i=A,j=B,然后得到
(3)若A,B不属于上述(1)(2)两种情况,则
步骤二、根据语义关联矩阵生成证据泛化转移矩阵;
步骤201:根据步骤103中的确定的序列S生成矩阵U
其中p=1,2,…,2
步骤202:对于每个基分类器
T
其中U
步骤三、基于证据关联折扣操作进行未知目标融合识别;
步骤301:输入未知目标R,利用步骤101中训练得到的K个基分类器
步骤302:将P
其中,
步骤303:根据步骤103中的确定的序列S对m
步骤304:根据证据泛化转移矩阵T
得到的
步骤305:利用Dempster组合规则融合所有的新证据
其中m表示融合结果;所用到的Dempster组合规则如下:
假设m
步骤306:根据博弈概率转换公式
/>
本发明与现有技术相比具有以下有益效果:
1、本发明的步骤简单、设计合理,实现及使用操作方便。
2、本发明通过利用基分类器混淆矩阵生成对应的语义关联矩阵,能够有效表征各基分类器在不同类别上识别能力的差异性和互补性。
3、本发明通过构建证据泛化转移矩阵,实现未知目标识别结果的证据关联折扣操作,达到了基于基分类器混淆矩阵的识别结果精细化加权效果。
4、本发明通过利用证据理论Dempster组合规则融合精细化加权的基分类器识别结果,能够实现基分类器识别结果间冲突的有效处理。
综上所述,本发明技术方案设计合理,充分利用底层的基分类器在不同类别上识别能力的差异性和互补性,有效实现基于多分类器决策层融合的目标综合识别。
下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。
附图说明
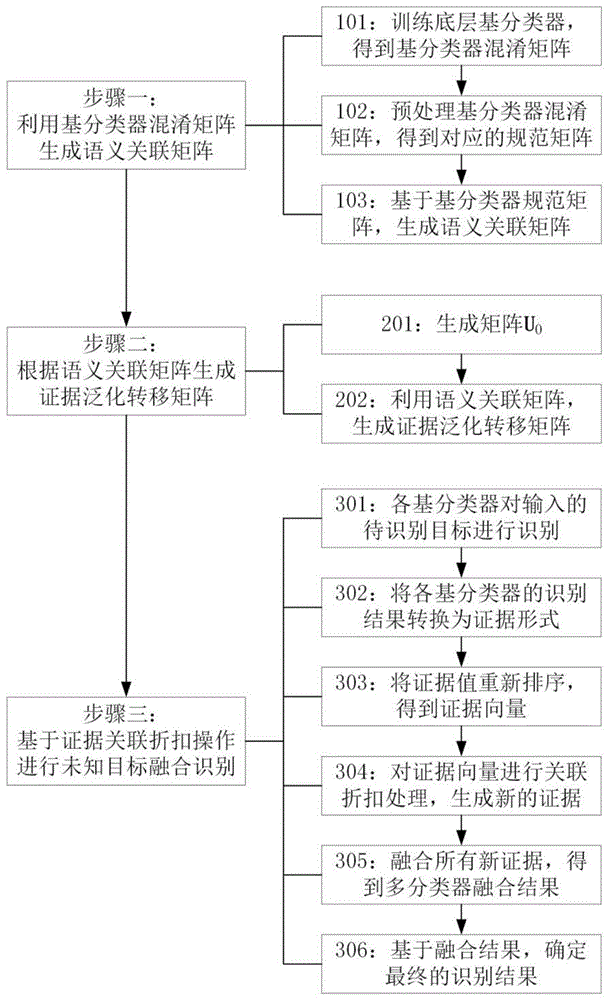
图1为本发明的方法流程图
图2为KNN基分类器
图3为SVM基分类器
图4为GNB基分类器
图5为与基分类器
图6为与基分类器
图7为与基分类器
图8为矩阵U
图9为证据泛化转移矩阵T
图10为证据泛化转移矩阵T
图11为证据泛化转移矩阵T
图12为证据向量m
图13为关联折扣后的新证据
具体实施方式
下面结合附图及本发明的实施例对本发明的方法做进一步的详细说明。
需要说明的是,在不冲突的情况下,本申请中的实施例及实施例中的属性可以相互组合。下面将参考附图并结合实施例来详细说明本发明。
需要注意的是,这里所使用的术语仅仅是为了描述具体实施方式,而非意图限制根据本申请的示例性实施方式。如在这里所使用的,除非上下文另外明确指出,否则单数形式也意图包括复数形式,此外,还应当理解的是,当在本说明书中使用术语“包含”和/或“包括”时,其指明存在特征、步骤、操作、器件、组件和/或它们的组合。
如图1所示,本发明包括以下步骤:
步骤一、利用基分类器混淆矩阵生成语义关联矩阵;
选取UCI机器学习数据库网站(https://archive.ics.uci.edu/ml/datasets.php)中的小麦种子Seeds数据集进行详细说明。该数据集包含210个样本,每个样本具有7个属性;这些样本均匀来自Kama(c
步骤101:从Kama(c
选取K近邻(K-Nearest Neighbor,KNN)、支持向量机(Support Vector Machines,SVM)、高斯朴素贝叶斯(Gaussian
各基分类器
步骤102:根据公式W
步骤103:对于基分类器
首先,根据条件
然后,以序列S作为矩阵的行与列方向上的索引,依据以下方式确定语义关联矩阵U
(1)若
(2)若A,B∈{1,2,3}且A,B都不为空,则令i=A,j=B,然后得到
(3)若A,B不属于上述(1)(2)两种情况,则
生成的语义关联矩阵U
步骤二、根据语义关联矩阵生成证据泛化转移矩阵;
步骤201:根据步骤103中的确定的序列S生成矩阵U
其中p=1,2,…,2
步骤202:令U
步骤三、基于证据关联折扣操作进行未知目标融合识别;
步骤301:随机选取Seeds数据集中未参与训练的一个样本R作为输入的待识别未知样本,利用步骤101中训练得到的3个基分类器
KNN基分类器
SVM基分类器
GNB基分类器
步骤302:根据公式
步骤303:根据步骤103中的确定的序列S对m
步骤304:根据证据泛化转移矩阵T
步骤305:利用Dempster组合规则融合新证据
步骤306:根据博弈概率转换公式
BetP(c
可以发现,类别c
以上所述,仅是本发明的实施例,并非对本发明作任何限制,凡是根据本发明技术实质对以上实施例所作的任何简单修改、变更以及等效结构变化,均仍属于本发明技术方案的保护范围内。