一种制备麦角硫因的方法
文献发布时间:2023-06-19 19:30:30
技术领域
本发明属于生物化工技术领域,具体涉及一种生物酶催化制备麦角硫因的方法。
背景技术
麦角硫因是1909年在麦角菌中发现的一种含硫醇的特殊氨基酸,随后,在粗糙脉孢菌、蓝细菌、蘑菇等均有发现。人类和其他无脊椎动物不能直接合成他,但它可以通过食物汲取并积累到人体的各个部位,它具有超强的抗氧化能力,已知的抗氧化能力高于维生素E,维生素C,半胱氨酸、谷胱甘肽等,这使得它被广泛应用于食品、化妆品以及医药等行业中。
麦角硫因结构式如下:
麦角硫因在好氧生物体内的合成存在来源于细菌生物合成以及来源于真菌生物合成的两条途径。在细菌中涉及到有5个关键酶的基因簇,这5个酶分别是γ-谷氨酰半胱氨酸合成酶(EgtA)、单核非血红素铁酶(EgtB)、酰胺转移酶(EgtC)、S-腺苷蛋氨酸依赖型组氨酸甲基转移酶(EgtD)、磷酸吡哆醛(PLP)结合型C-S裂解酶(EgtE)。在真核生物中的麦角硫因合成主要涉及Egt1和Egt2两个关键酶,Egt1催化半胱氨酸和组氨酸甜菜碱(海西宁)合成中间体海西宁半胱氨酸亚砜(CHER),然后CHER再由Egt2裂解成麦角硫因。
目前合成麦角硫因的方法主要有化学法、微生物发酵法、酶促制备。化学法的原料较昂贵,且合成困难,导致产量不足。采用代谢改造进行微生物发酵是现在研究的热点,公开号为CN113234652A的中国专利申请通过将EgtABCDE克隆至大肠杆菌中,并对其进行所需底物的通路进行代谢改造的情况下得到的工程菌,最终发酵108h产量达到1.1g/L。公开号为CN114277042A的中国专利申请报道将粗糙脉孢菌(Neurospora crassa)中克隆得到的麦角硫因合成基因Egt1、Egt2导入并整合到圆红冬孢酵母菌中,其最终通过发酵120h可以达到8.5g/L的产量。与发酵法相比,酶催化法有产率较高、提纯较简单等优点,例如公开号为CN104854245A的中国专利申请报道了体外以组氨酸或组氨酸甜菜碱为底物制备麦角硫因的方法,一种是通过酶EgtABCDE制备,一种是通过蛋白OvoA/酶NcEgtl和酶EgtE制备。虽然公开了相关酶的信息,但是转化周期以及底物转化率是未知的,实际效果能否进行规模化应用尚不明确。
因此,进一步开发反应时间短、转化率高且工艺步骤精简的酶催化合成麦角硫因的新方法,对促进麦角硫因的工业化、规模化生产具有重要意义。
发明内容
本发明的目的在于提供一种麦角硫因的酶催化合成方法。
本发明提供了一种生物酶催化制备麦角硫因的方法,包括如下步骤:
(1)组氨酸甜菜碱、L-半胱氨酸在亚铁离子和还原剂作用下,加入Egt1酶在温度为25~40℃,pH为6.0~8.0的有氧环境下反应制得中间体CHER;
(2)中间体CHER在辅酶和还原剂作用下,加入Egt2酶在温度为25~40℃,pH为6.0~9.0的条件下反应制得麦角硫因;
反应式如下:
进一步地,步骤(1)所述反应温度为25~30℃,pH为6.0~7.5;
和/或步骤(2)所述反应温度为25~30℃,pH为7.0~8.5。
更进一步地,步骤(1)所述反应温度为30℃,pH为6.5~7.0;
和/或步骤(2)所述反应温度为30℃,pH为8.0~8.5。
进一步地,所述Egt1酶的氨基酸序列如SEQ ID NO.2或SEQ ID NO.4所示;
所述Egt2酶的氨基酸序列如SEQ ID NO.6或SEQ ID NO.8所示。
更进一步地,步骤(1)所述加入Egt1酶是加入表达Egt1酶的湿菌体,或加入Egt1酶的粗酶液;步骤(2)所述加入Egt2酶是加入表达Egt2酶的湿菌体,或加入Egt2酶的粗酶液。
更进一步地,上述Egt1酶的粗酶液或Egt2酶的粗酶液制备方法如下:
(a)制备表达Egt1酶的湿菌体或表达Egt2酶的湿菌体;
(b)步骤(a)制备的湿菌体用PBS缓冲液混旋,均质破碎,离心收集上清液。
进一步地,上述表达Egt1酶的湿菌体是含有Egt1基因的重组大肠杆菌进行蛋白表达后的菌体;所述表达Egt2酶的湿菌体是含有Egt2基因的重组大肠杆菌进行蛋白表达后的菌体;
所述Egt1基因序列如SEQ ID NO.1或SEQ ID NO.3所示,所述Egt2基因序列如SEQID NO.5或SEQ ID NO.7所示。
更进一步地,上述表达Egt1酶的湿菌体或表达Egt2酶的湿菌体的制备方法如下:
(a’)将Egt1基因或Egt2基因克隆到表达载体中得到重组表达质粒,将重组表达质粒转如大肠杆菌中制得重组菌;优选地,所述表达载体是PET-28a质粒;
(b’)重组菌接种、培养,加入亚铁离子、诱导剂诱导蛋白表达并培养,离心收集菌体,即得表达Egt1酶的湿菌体或表达Egt2酶的湿菌体。
进一步地,步骤(1)所述还原剂是三(2-羧乙基)膦、二硫苏糖醇或巯基乙醇中的一种或多种,步骤(2)所述辅酶是磷酸吡哆醛,所述还原剂是三(2-羧乙基)膦、二硫苏糖醇或巯基乙醇中的一种或多种。
进一步地,步骤(1)所述组氨酸甜菜碱、L-半胱氨酸、还原剂和Egt1酶的质量比例为(18~23):(15~20):(0.5~1.5):(20~30);优选为20:16:1:(20~30);
和/或步骤(2)所述辅酶、还原剂和Egt2酶与步骤(1)所述还原剂的质量比为(0.1~0.3):(0.3~0.8):(1~3):1,优选为0.2:0.5:2:1。
本发明的有益效果:本发明选择路径相对简单的真核生物合成途径,筛选出转化率高的Egt1酶和Egt2酶,在适宜的特定温度、pH条件下实现了体外酶催化制备麦角硫因,其可以在较短时间内完成转化,并且可以达到较高的底物浓度及转化率,工艺操作简单,适合麦角硫因的规模化生产。
显然,根据本发明的上述内容,按照本领域的普通技术知识和惯用手段,在不脱离本发明上述基本技术思想前提下,还可以做出其它多种形式的修改、替换或变更。
以下通过实施例形式的具体实施方式,对本发明的上述内容再作进一步的详细说明。但不应将此理解为本发明上述主题的范围仅限于以下的实例。凡基于本发明上述内容所实现的技术均属于本发明的范围。
附图说明
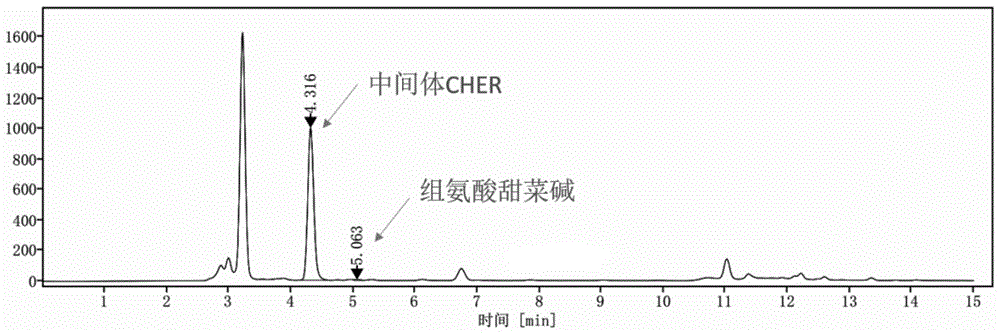
图1为Egt1催化生成中间体CHER的HPLC图谱。
图2为Egt2催化生成麦角硫因的HPLC图谱。
具体实施方式
本发明所用原料与设备均为已知产品,通过购买市售产品所得。
实施例1、构建及表达合成麦角硫因酶的重组大肠杆菌以及粗酶液
查阅文献并检索NCBI数据库,确定了16个来源于不同真核生物的候选Egt1和Egt2,其可能将组氨酸甜菜碱催化合成麦角硫因,如表1所示。将这些酶对应的基因进行人工合成,并克隆到表达载体PET-28a的NcoI和HindIII中,并将重组表达质粒转于大肠杆菌BL21(DE3)中。
将含有重组质粒的大肠杆菌菌株接种于50ml的LB液体培养基,37℃摇床培养16h,培养结束后,移取8ml培养后的菌液至400mlTB液体培养基中,培养2~3h后检测OD至值为0.6-0.8之间,加入终浓度为0.1mM的柠檬酸亚铁铵(提供亚铁离子作为酶的激活剂)以及0.1mM的异丙基-β-D-硫代半乳糖苷(诱导剂)诱导蛋白表达,20℃摇床培养18h。8000rpm离心收集菌体,得到湿菌体。
制备的含有表达目的基因的湿菌体用0.1M的PBS缓冲液(pH=7.0)混旋,均质破碎,离心收集上清液,得到粗酶液。
实施例2、合成麦角硫因酶的活性分析
Egt1酶对底物组氨酸甜菜碱的催化活性分析:在上述Egt1粗酶反应液中,分别加入终浓度1g/L的TCEP、8g/L的L-半胱氨酸、10g/L的组氨酸甜菜碱,将上述反应液置于100mL的微型反应器,在转速200rpm、通气速率为0.15vvm、pH为7.0、温度为30℃下转化6h,在搅拌情况下,取50μL加入950μL的0.1M盐酸溶液中,12000rpm离心5min,取上清经过滤之后用于HPLC分析。
Egt2酶对底物组氨酸甜菜碱的催化活性分析:取Egt1对组氨酸甜菜碱转化完全的反应液,分别加入终浓度为0.1g/L的磷酸吡哆醛(PLP)、0.5g/L的二硫苏糖醇(DTT)以及5g/L的Egt2湿菌体,调节反应液pH为7.5,在30℃水浴锅中磁力搅拌1h,在搅拌情况下,取50μL加入950μL的0.1M盐酸溶液中,12000rpm离心5min,取上清经过滤之后用于HPLC分析。
HPLC分析条件是:分析柱Agilent ZORBAX StableBond AQ,流动相为20mM的K
表1:Egt1对组氨酸甜菜碱和Egt2对中间体CHER的活性比较
根据表1中的各个酶的活性表明,Egt1对组氨酸甜菜碱活性较好的酶来源于Chaetomium thermophilum、Bipolaris sorokiniana,并将其分别命名为CtEgt1,BsEgt1。
Egt2对中间体CHER活性较好的有来源于Rhodotorula mucilaginosa、Tremellamesenterica,并将其分别命名为RmEgt2,TmEgt2。
后续使用效果相对最好的CtEgt1,BsEgt1,RmEgt2,TmEgt2进行麦角硫因的合成。
其中,编码BsEgt1的核苷酸序列如SEQ ID NO.1:
ATGGCAGCTAATATAATTGATATAAGGGTAGACAAGGCGGAAAGCGATATTCTGGCGGACATCAAGAAAGGTCTGCGTCCTGTTGCGGACGCCGAGAAGACGCTGCCGACCCTGTTGTTGTACGACCAGGAGGGCTTGCGACTGTTCGAACAGATCACGTACCAAGAAGAATATTACTTAACTAACGCCGAGATCGAGGTTCTGGAAACCTACGCGGACAAAATCGCCCAACGCATCAGCCCGGGTTCTATCGTGGTTGAATTGGGCTCTGGTAACCTGCGGAAGGTGAATATTCTCCTCCAGGCGGTGGACCGTCTGGGTAAGGACATCGAGTACTACGCGGTTGATCTTAGCCTGCCTGAGCTGGAACGCACCTTCAAGCAAATCCCAATTGAGGGTTATAGCCATGTTAAGTGCTTTGGCCTGCACGGCACGTACGACGACGCTCTCGAATGGCTGAAATCCCCGGCGGTCGAGGCGAAGCCGAAAACCATCCTATGGCTGGGCTCATCCCTGGGAAACTTTAAACGCCATGAAGTTCCGCCGTTTCTGGCGGGTTTCGGAAAGGTGTTGCAAACCGGCGACACCATGCTCATTGGTATCGATAGTTGTAAAGACCCGAAGCGCGTCTTTCATGCTTACAATGATCGTGACGGTGTGACCCATCGTTTTATTCTGAATGGTCTGAAACACGCGAATGCACTGATGGGCGAGAACGCCTTCAACCTGGATGACTGGGAAGTGATTGGTGAATATGACACGAAAGCGGGCCGTCACCACGCGTTCGTTGCTCCGCGTAAAGACGTGGTGGTTGACGGCGTCCCGATGAAACAAGGTGAACGTATCCGTATCGAGGAATCTTACAAATATAGCCGTGAAGAAGCTAAGAAGCTGTGGGAATTGGCGAAACTGGCGGAGAACGCGGTATGGGCGAACAGCAAGGGCGATTATGGCCTTCACATGGTGAGCAAACCATCGTTCTTTTTCCCGACGACCCCGGAAGAGTATGCGGAAAAACCGGTTCCGTCCTTGACCGAATGGCAGGAGTTGTGGAAAGCCTGGGATGCTGTTTCGAAACAAATGATTCCAAATAGCGAACTGTTGGCAAAGCCGATTAAACTGCGCAACGAGTGCATTTTTTATCTGGGTCACATTCCGACTTTTCTGGATATTCATATTGCGCGCGCGACCGATGGCAAGCCGACCGAACCGGCTTACTTCTGGAAGATCTTCGAGCGCGGTGTCGACCCAGATGTTGACGACCCGACCTTATGCCACGCGCATAGCGAAGTTCCGGAAGAGTGGCCTCCGCTGGGGACCATCCTGCAGTATCAACAAACCATTCGCAAAAACCTTGAGGCGCTGTACGACAGCGGTGAGGCCGAGAAAAACTGCCGTATCAGCCGTGGTCTGTGGATTGCATTTGAACATGAAGCCATGCATCTGGAAACTTTGCTCTACATGTTAATTCAATCCGATAAAGTGCTGCCGCCACCGGGCATCAAGCAGCCGGACTTCGCCGCATTCGCGGCACAGAGCGAGGTTATGGCAGTTGAAAACGAGTGGTTTACCATCCCGGAATCCGACATCGATATCGGCCTGAACGATCCGGAGAAGGACTTTGGTTCCAAGCGTTATTTCGGCTGGGATAACGAACGTCCGTGTCGTAGCGTCCACGTGAAGAGCTTTCGTGCAAAGGCTCGTCCGATCACCAATGGCGAGTACGCAACCTACTTGTTGCAAACGGGTAAAAAAGAGATTCCGGCGAGCTGGTGTGATAAAGCGTACAGCAACGGTCACGATACCAATACCACAAAGCGCGATAGCGTAGTGAACGGTCAGTCTAACGGTAACGGTGAGTCTAGCCAGGGTATTATCGAAGGCAAGTTCGTGCGTACCGTTTATGGTACCATTCCGCTTAAGCTGGCGATGGGTTGGCCGGTAGTGGCCAGCTACGACGAATTGGTTGGCTGCGCACAGTGGATGGGTGGTCGTATCCCAACGATGGAGGAGGCCAGAAGCATCTATGCTTATGTTGACTCGATCAAACCGGAGTTCGAGCAGTCTCTGGGCAACACGATCCCGGCGGTCAACGGTCACCTGTTAAACGAAGGCGTGTTCGAGACGCCGCCGTCCCACCACCTGAGCAATGGCAATTCCGGTGCGGTTACCGGTCTGAAGCCCCGTGATCTGTTTATCGATCTGGAAGGTACAAACGTGGGTTTTAAACATTGGCATCCGGTATCTGTGGCGGAGAAAGGTGATAAGTTGTGCGGTCAGAGTGACCTGGGTGGCGTTTGGGAGTGGACCAGCACCGTTTTAGAAAAGCACGATGGTTTTGAGCCGATGGAATTGTACCCGGGCTATACCGCAGACTTCTTCGATGGGAAGCACAACATTACCCTGGGCGGATCATGGGCAACCCACCCGCGTATAGCGGGCCGTAAGACCTTCGTGAATTGGTATCAGCGTAATTATCCGTACGTGTGGGCTGGCGCACGCATCGTCACTGACCTGTAA
BsEgt1酶的氨基酸序列如SEQ ID NO.2:
MAANIIDIRVDKAESDILADIKKGLRPVADAEKTLPTLLLYDQEGLRLFEQITYQEEYYLTNAEIEVLETYADKIAQRISPGSIVVELGSGNLRKVNILLQAVDRLGKDIEYYAVDLSLPELERTFKQIPIEGYSHVKCFGLHGTYDDALEWLKSPAVEAKPKTILWLGSSLGNFKRHEVPPFLAGFGKVLQTGDTMLIGIDSCKDPKRVFHAYNDRDGVTHRFILNGLKHANALMGENAFNLDDWEVIGEYDTKAGRHHAFVAPRKDVVVDGVPMKQGERIRIEESYKYSREEAKKLWELAKLAENAVWANSKGDYGLHMVSKPSFFFPTTPEEYAEKPVPSLTEWQELWKAWDAVSKQMIPNSELLAKPIKLRNECIFYLGHIPTFLDIHIARATDGKPTEPAYFWKIFERGVDPDVDDPTLCHAHSEVPEEWPPLGTILQYQQTIRKNLEALYDSGEAEKNCRISRGLWIAFEHEAMHLETLLYMLIQSDKVLPPPGIKQPDFAAFAAQSEVMAVENEWFTIPESDIDIGLNDPEKDFGSKRYFGWDNERPCRSVHVKSFRAKARPITNGEYATYLLQTGKKEIPASWCDKAYSNGHDTNTTKRDSVVNGQSNGNGESSQGIIEGKFVRTVYGTIPLKLAMGWPVVASYDELVGCAQWMGGRIPTMEEARSIYAYVDSIKPEFEQSLGNTIPAVNGHLLNEGVFETPPSHHLSNGNSGAVTGLKPRDLFIDLEGTNVGFKHWHPVSVAEKGDKLCGQSDLGGVWEWTSTVLEKHDGFEPMELYPGYTADFFDGKHNITLGGSWATHPRIAGRKTFVNWYQRNYPYVWAGARIVTDL
编码CtEgt1的核苷酸序列如SEQ ID NO.3:
ATGCCAGGATTAGAAAATCCCGTACTAGCTAGCCAAACTGGTCAGGGCCGTCTGCTGGCAATTAAAGAGAAGAAGCGCTTACCGGATGTGCGCGTGAAAATCGGCGAAAAGGCGTCGTTCGATATTATCGACATCCGTCAAGGTAGCGTGGAAATGAATCTGAAGGTGGAAATCTTGAGCATGTTTCTGACCAAAAACGGCCCTCGTAAGCTGCCGACTCTGTTGTTGTACGATGAGCGTGGTTTACAATTGTTCGAGAAAATTACCTACTTGGAGGAATACTACCTGACTAACGACGAAATCGAAGTTCTGCAGAAGTACTCTGCGGACATCGCGAAGCTGATTCCGGAAGGTGCAATGCTCATTGAACTGGGTTCCGGTAACCTGCGTAAAGTCAATCTGTTGCTGCGCGCGTTCGAGGACGCAGGCAAGTCTATCGACTATTACGCTTTGGACCTGTCCAAGCAAGAACTGGAACGGACCTTAGCGCAGCTGCCGCATTACCAGTATGTCCGTGCACACGGCCTGCTGGGTACGTACGACGATGGTAGAGCGTGGCTGAAACACCCGAGCCGTGCGTCCCGCCAGAAGTGCATCCTGTCGCTGGGCTCTAGCGTCGGAAACTTCGACCGCGCGGATGCCGCTGCTTTCCTGAAAACCTTTGCCGACATCTTAGGTCCGGGTGACACGATGCTCATCGGCTTGGACGCCTGCAATGATCCGGCGCGCGTGTATCATGCATATAACGATAAAGAGGGCGTTACCCACGAGTTGGCGTCCCAGGCCGGTTCCGGCGACAGCGCAGACGAGAGCATTCATCGTTTCATTTTAAATGGTCTGCGCCACGCTAATAAAATCTTGGGTGAAACCGTGTTTGTGGAGGCGGAGTGGCGTGTTATTGGCGAGTACGTGTACGACGGCCAAGGTGGTAGACACCAGGCGTTCTATGCGCCACTGCATGATACCACCGTCCTGGGCCAGCTGATTCGCCCACACGATCGTATTCAGGTTGAACAGTCCCTGAAGTACTCGCCGGCGGAAGCAGAACTTCTGTGGAAACGTGCGGGCATGGAAGAGATCGGTCACTGGCGTTGTCGTGATGAGTACGGCGTTCACATGCTGTCCAAGCCGAAAATGGCGTTCGGCCTGATTCCGTCTGTTTACGCACGTTCTGCTCTGCCGAGCTTGGAGGAGTGGGAAAGCCTGTGGGCAGCGTGGGATACTCTTACGCAGGAGATGCTGCCGCCAGAAGAACTTTTGTCTAAGCCGATCAAGCTGCGCAACGCGTGCATCTTCTACTTGGGTCACATCCCGAATTTTCTGGATGTTCAGCTGAGTAAGGTCACCACGGATCCTCTGACCGACCCGGCTTGGTACAGGCGTATCTTCGAGCGCGGTATTGACCCGGATGTGGACAACCCGGAAATCTGTCATGATCATAGCGAAATTCCGGATGAGTGGCCACCGGCGGATGAGATTTTGGAGTATCAAACCCGTGTTCGTGCACGTTTGCGTAAGTATTATGAAAACGGAGTTGAGAACATTCCGCGTCACATCGGGAGAGCCATTTGGGTTGGTTTCGAGCACGAGATCATGCATCTGGAAACCTTGCTGTATATGATGTTGCAGAGCGATAAGACCCGTCCGCCTCCGAATGTGCCGGTTCCCGACTGGGAAAAATTGGCGGCCAAGGCACGTAGCGAACGCGTACCGAATGAATGGTTTGATATCCCGGAGCAAGAGATCACGATTGGCCTGGACGACCCGGAAGATGAAACCGACCCGAACGTGCATTATGGTTGGGATAATGAAAAACCGGTGCGTCGTGCTAAAGTTCACGCTTTCCAAGCCAAGGGTCGTCCGATTACGAACGAGGAGTACGCGACCTACCTGTATAACACTCATGGTAGCCAGATTCCGGCTTCATGGGCCTACACCAAAGAGAAAGATCCGCAAAATGGCGTTAGCGGTACGAACGGCCACTCCACCATCGCCAACGGCACCGCTCCGCTGCCGGAGAGCTTCCTAGAGGATAAGGCCGTTAAAACCGTGTTCGGCCTGGTCCCGCTCAAATACGCGTTGGATTGGCCAGTGTTTGCATCCTATAATGAGCTTGCCGCGTGCGCTGCCTGGATGGGTGGTCGTATCCCGACCTTTGAGGAAGTGCGTAGCATTTATGCGCACGTTGAGGCGCGCAAGAAACAGAAGGAGGCTCAAAAACATCTCGCGCAAACCGTGCCGGCGGTTAACGCTCACCTGTGCAACAACGGCGTAGAAATCAGCCCGCCCGCGACGCCTCCGGCGGGGACCGCGGCGGCGACCGCGGAAGGAGACGAGTCCGAAAACAGCCTGTTCATCGACCTGGACGGCGCGAACGTTGGTTTTCAGCATTGGCATCCAGTGCCGGTGACAAACCGTGGTGGCGAGCTGGCTGGCCAGGCAGAATGTGGTGGTGTGTGGGAATGGACCAGCAGCGTTCTGCGTCCCTGGGACGGTTTCAAACCGATGACCCTATACCCAGGTTATACCGCGGACTTTTTTGACGAGAAGCACAATATTGTTCTGGGCGGTTCATGGGCGACTCACCCGCGTATAGCCGGTCGCAAGAGTTTCGTGAATTGGTACCAACGTAACTATCCGTATGCGTGGGTTGGCGCTCGCCTTGTTCGCGATCTGCCGTAA
CtEgt1酶的氨基酸序列如SEQ ID NO.4:
MPGLENPVLASQTGQGRLLAIKEKKRLPDVRVKIGEKASFDIIDIRQGSVEMNLKVEILSMFLTKNGPRKLPTLLLYDERGLQLFEKITYLEEYYLTNDEIEVLQKYSADIAKLIPEGAMLIELGSGNLRKVNLLLRAFEDAGKSIDYYALDLSKQELERTLAQLPHYQYVRAHGLLGTYDDGRAWLKHPSRASRQKCILSLGSSVGNFDRADAAAFLKTFADILGPGDTMLIGLDACNDPARVYHAYNDKEGVTHELASQAGSGDSADESIHRFILNGLRHANKILGETVFVEAEWRVIGEYVYDGQGGRHQAFYAPLHDTTVLGQLIRPHDRIQVEQSLKYSPAEAELLWKRAGMEEIGHWRCRDEYGVHMLSKPKMAFGLIPSVYARSALPSLEEWESLWAAWDTLTQEMLPPEELLSKPIKLRNACIFYLGHIPNFLDVQLSKVTTDPLTDPAWYRRIFERGIDPDVDNPEICHDHSEIPDEWPPADEILEYQTRVRARLRKYYENGVENIPRHIGRAIWVGFEHEIMHLETLLYMMLQSDKTRPPPNVPVPDWEKLAAKARSERVPNEWFDIPEQEITIGLDDPEDETDPNVHYGWDNEKPVRRAKVHAFQAKGRPITNEEYATYLYNTHGSQIPASWAYTKEKDPQNGVSGTNGHSTIANGTAPLPESFLEDKAVKTVFGLVPLKYALDWPVFASYNELAACAAWMGGRIPTFEEVRSIYAHVEARKKQKEAQKHLAQTVPAVNAHLCNNGVEISPPATPPAGTAAATAEGDESENSLFIDLDGANVGFQHWHPVPVTNRGGELAGQAECGGVWEWTSSVLRPWDGFKPMTLYPGYTADFFDEKHNIVLGGSWATHPRIAGRKSFVNWYQRNYPYAWVGARLVRDLP
编码RmEgt2的核苷酸序列如SEQ ID NO.5:
ATGGTACAAAGTCACTCACTATTCTTTTATGGCACCCTGTGTCATGCAGCGGTTCTGCGTCGCGTTATCGGTAACAACGGTGAGCACTCCACCTGCCGTGATGCACTGCTGGAGGATCATGTGCGTCTCCATGTTGCTGGTGAGGACTATCCGGCTGTTGTCTCCGTGGACAGCGCGGAAAGCGCCCGTCTTTTGAAGCGCAATCTGGCACCGACCGAACGTCGTGTACAAGGTGTGGTGGTGCAGGGCTTGACCGATGATGATGTTGCCATGCTGGACGAATTCGAGGGCGACGCTTCCCAGACCGCGGTTCTCGAGCCGGAAGGCCGTGGCGAAATCGCCGACTCAGTGAGCCGTGTCGTTCGCTTGGATTACAGCAGGCGTACCACCGTTTACCTGTGGACCGCTCCGCTGTCTCGCCTGGAGCCGCGTATTTGGAGCTTTACTGACTTCCTGAGAGATTCCGCACACCGTTGGGTTGGCTCCGGTGCTGACTCCAATCCGGATTACGTTGAGGTCGACCGTCGTCGAAACATGAAAGGTGTCATCACGCCGCGTGGCGTACGCGAGGAATCGGCGAAGGTGCTGGAGGGCGCTACTGCCCAATTGAGCCTGGACCGCAAGAACGGTGGTGGCGGTGGCGAGAAGCACGTGAACGGCACCGCGTTCGAGCCCTTTGGCCGTGAACTCGCAAAAAAATACTGGCGTTTCGAAGAGGGCTGGGTTAACCTGAATCATGGTAGCTATGGTGCGGCGCCGTTGCCGGTTGTAGAGAGCCTGCATGCGATTCAGGCAAGATGTGATTCCGCTCCGGACCGTTTCATGCGTGTGGAGTATGAGCAAGAACTCATCGACGTGCGCACCCGTTTAGCCGACTTCGTAGATTGTGAAACGGATGACCTGGTTCTGGTCCCGAATGCAACCAGCGGCGTCAACGAGGCGCTGCGTGGGCTGACCACGGAGTGGAATAAAGGTGATCGACTATTGTTTTTCTCCTCTTCTATTTACAATGCTTGCAGCTCGACGCTGCAGTACATCGTTGACACCCATCGCCACCTGGACTTGGAGTTGCTGCCTGTTGTGTTTACCTACCCGAAACCACACTCGGAAGTGGTTCGGTTAGCGCGCGACGCGATTGAACGTGCTAACAGCGATGGTACCGGTCGCCGCGTGCGTTTGGCGCTCATCGATGCGATCAGCTCAGCCCCAGGCGTTGTTGTGCCGTGGGAAGATCTGGTGGATTTGTTTCGTGAGAAAGATATCATATCTCTAGTGGACGCTGCCCACCAAATTGGCCAGCTGCCGGTGAGCCTGCGTACCTCGAAGCCGGACTTCTGGATTTCTAACTGCCACAAATGGCTGCACGCTCACCGTGGAGTCGCGGTGCTCTATGTTGACAAGAAGTTCCAGCATCTTGTTCACAGCTCCCCGATTGGTCATTATTACGGTGTTAAAGGCGGTTTTGTGAACGAGCACAGTTGGTCTGGTACGGTTGATTGGAGCCCGTATCTGTCCGTTGCGGCCGCGCTGGATTTCCGCCGCGACATTCTGGGTGGAGAGGAACGCATCTATCAGTACTGCTTTGATCTGGCGGTTCAAGGCGGCGACCTGGTCGCCGCGGAATTGGGCACCAAAGTGATGCGTAATGCGACACCGGAAGAAGGCGAACTGATCGCGACTATGGTTAACGTGGAATTGCCGCTGCCGGCACCAAGCACCTTTAGCACCAGCGACCTGAAGCTGCTGAACCCGTTCTGGTTTCGTGAGCTGGCGAGCAAACACCAAACGGTGGTGCCGATCTTTGCACATGGTGACGTGTTCTGGACCCGCCTGAGCGCTCAGGTTTACAACGATCTTGACGACTTCGCCCACGTGGCGAAGGCACTCAAGACCGTGTGCGAACAGATTACGGCGGGTACTTGGCGTTAA
RmEgt2酶的氨基酸序列如SEQ ID NO.6:
MVQSHSLFFYGTLCHAAVLRRVIGNNGEHSTCRDALLEDHVRLHVAGEDYPAVVSVDSAESARLLKRNLAPTERRVQGVVVQGLTDDDVAMLDEFEGDASQTAVLEPEGRGEIADSVSRVVRLDYSRRTTVYLWTAPLSRLEPRIWSFTDFLRDSAHRWVGSGADSNPDYVEVDRRRNMKGVITPRGVREESAKVLEGATAQLSLDRKNGGGGGEKHVNGTAFEPFGRELAKKYWRFEEGWVNLNHGSYGAAPLPVVESLHAIQARCDSAPDRFMRVEYEQELIDVRTRLADFVDCETDDLVLVPNATSGVNEALRGLTTEWNKGDRLLFFSSSIYNACSSTLQYIVDTHRHLDLELLPVVFTYPKPHSEVVRLARDAIERANSDGTGRRVRLALIDAISSAPGVVVPWEDLVDLFREKDIISLVDAAHQIGQLPVSLRTSKPDFWISNCHKWLHAHRGVAVLYVDKKFQHLVHSSPIGHYYGVKGGFVNEHSWSGTVDWSPYLSVAAALDFRRDILGGEERIYQYCFDLAVQGGDLVAAELGTKVMRNATPEEGELIATMVNVELPLPAPSTFSTSDLKLLNPFWFRELASKHQTVVPIFAHGDVFWTRLSAQVYNDLDDFAHVAKALKTVCEQITAGTWR
编码TmEgt2的核苷酸序列如SEQ ID NO.7:
ATGACAGTTAGTACGACTGTACACAATTCAACCTCTTTAAAGTGCGTTGTGTTTTTTTATGGCACTCTGTGCGTGCCGGCCATTTTGGCGCGTGTTCTGGGTCATGGCTGCCAGAATTTGACCTTTCAGGATGCTTTGCTGCCGGATTACACCCGTCATTGTGTTGTCGGACAGGATTACCCGGCGGTTATCGATTCCAAATCTACGCGTATCATCAGCGGTGACGACGTCGAGGACACCAGCACCCGTGGTACGCTGGTTAGCGGTCTGAGCGTTGCTGACGTACTGGCCCTCGACATTTTTGAAGGTGATGAGTACACCCGCAAAATCCTTAAGGTGCACACTTTCAGCAGCGCGGCTGCGATCGACCAATTGCCGCAAGAACTAATGAATCCGAACCTGAGAGAAAGCACCATTAACACCCCGCCTTCAATCTATGCAAAAAAGGAGGCGTGGGTTTACACATGGTCGGCTGGTCTCGACCGCCTGGATCCGAAAGTGTGGTCTTTCGCGGAGTTCGTTAAGGAGCGCGCGGATCAGTGGACCGGCAAAGATACCACTGAATTCGATGAGATCGAACACCACCTGGCGATTCGTGCTGAACCGGGCATTCGTGATGAAAAAAGCCAGTCCGATTTCAAACCGACGGGTGTGAAGGGCAAGACCAAAGAAGGTTTTCCGGATTTTGGTCGCAACATGCTGAAGTATTGGGGTTTCCAACCGGGCTATGTCAACCTGAACCACGGTAGCTATGGCTCTCCGCCGAAGCCAGTGATCGAGCGCATGCGTGCGTTGACTGATGAAATCGAACGCTTCCCGGATCTGTTCATGCGTCGTACGTGCCGTCCGATGTTGGACCGTGTGAAGCAGCGTGTCGCCAAATTGATTGGCGCGGACGAGCACGAATGTGTGATTGTTCCAAATACCACCCACGGTATCAACACCGTCATGTATAACATTGACTGGGAAGAGGGCGACGTCATCGTAATTTATAACACCACGTATGGCGCAGTTGGCCAAACCGAGAAGTTTATCTGCGACAAATACCCGGGTGTAAGCCTCGAGCAGATTTCCATCACCTTCCCCTGCAGCCATGAGGAAGTTGTGAAAAAAACCGAAGACGTGCTGGGCCGTTACAATCAACAAGTTAACCCGACCCAATTAGAAATCAAACCGGTAGGTAGAGGTGAAAAGCGCGTGCGTATGGTTGTTGTGGACCAAATAGCGAGCAATCCGGGTGTTGTGTATCCTTGGGAAGACATTGTGCGTCTGTGTAAAAAGTACGGTGCTCTGTCTGTGGTCGACGCGGCGCACGCCATCGGTCAAGTTAAAACCAATGTGAAGTTGGCGGACTGTGATTTCTGGATTTCCAACTGCCATAAATGGCTGATGGCACACCGTGGCTGCTCCGTTCTGTATGTGCCGTTTCGTAATCAGCATCTGATGCGCACTACGTTCCCGACTTCACACGCGTATGAGAGCAGCCGTTACCCGACTCTGGATATTGATGGTCAGCAGGCAGGTCGCCCACGTAGCTTCGAGATGCAGTACGAGTGGACCGGTACGCAAGATTGGGCACCGCTGTTGTCGCCGTCCTTCGCTCTGGACTTCCGTGAGGAGATTGGCGGTGAAGAGCGAATCATGGAATACTGCCATACCCTGGCAGTGGAAGGCGGCAAGCGCATCGCGGAGCGCTGGGAAACCGAGGTTATGGATATCCCGGGTGACATCCTGACCGCAGCGATGGTGAACGTGGCACTGCCTTACATTCCGAGCCCGATGAGCCTGAAAGAGCAGTATACGCAATTACGTTACATCGAGGATACCCTTTTTTCGTCCAACTGCTTTGCTCCGTGTTACGTTCACGGCGGCAAGTGGTGGACCCGTTTTTCTGCACAGGTTTGGAATGAACTGGAGGACTTCGACTACGTTGCGAACATCTTGGAGAAGGCCTGCCTGGACATCAAGAAGGGGCTCCATCTGCAGCATCACACCGTTGACACAGATCACATTCATCAGCCGGCGGACGTGCCAGCGCACGACGAGTAA
TmEgt2酶的氨基酸序列如SEQ ID NO.8:
MTVSTTVHNSTSLKCVVFFYGTLCVPAILARVLGHGCQNLTFQDALLPDYTRHCVVGQDYPAVIDSKSTRIISGDDVEDTSTRGTLVSGLSVADVLALDIFEGDEYTRKILKVHTFSSAAAIDQLPQELMNPNLRESTINTPPSIYAKKEAWVYTWSAGLDRLDPKVWSFAEFVKERADQWTGKDTTEFDEIEHHLAIRAEPGIRDEKSQSDFKPTGVKGKTKEGFPDFGRNMLKYWGFQPGYVNLNHGSYGSPPKPVIERMRALTDEIERFPDLFMRRTCRPMLDRVKQRVAKLIGADEHECVIVPNTTHGINTVMYNIDWEEGDVIVIYNTTYGAVGQTEKFICDKYPGVSLEQISITFPCSHEEVVKKTEDVLGRYNQQVNPTQLEIKPVGRGEKRVRMVVVDQIASNPGVVYPWEDIVRLCKKYGALSVVDAAHAIGQVKTNVKLADCDFWISNCHKWLMAHRGCSVLYVPFRNQHLMRTTFPTSHAYESSRYPTLDIDGQQAGRPRSFEMQYEWTGTQDWAPLLSPSFALDFREEIGGEERIMEYCHTLAVEGGKRIAERWETEVMDIPGDILTAAMVNVALPYIPSPMSLKEQYTQLRYIEDTLFSSNCFAPCYVHGGKWWTRFSAQVWNELEDFDYVANILEKACLDIKKGLHLQHHTVDTDHIHQPADVPAHDE
实施例3、CtEgt1合成CHER
在反应器中,分别加入终浓度1g/L的TCEP、16g/L的L-半胱氨酸、20g/L的组氨酸甜菜碱后,加去离子水200mL,调节pH为6.75,加入实施例1制备的CtEgt1湿菌体20g,全程控制反应液pH为6.75,将其在转速200rpm、通气速率为0.15vvm温度为30℃下转化8h后,反应液进行HPLC分析,结果如图1,转化率≥99%。
实施例4、BsEgt1合成CHER
在反应器中,分别加入终浓度1g/L的TCEP、16g/L的L-半胱氨酸、20g/L的组氨酸甜菜碱后,加去离子水200mL,调节pH为6.75,加入实施例1制备的BsEgt1湿菌体30g,全程控制反应液pH为6.75,将其在转速200rpm、通气速率为0.15vvm温度为30℃下转化8h后,反应液进行HPLC分析,转化率≥98%。
实施例5、RmEgt2合成麦角硫因
取实施例2中的CtEgt1反应液,分别加入终浓度为0.2g/L的PLP以及0.5g/L的DTT,加入实施例1制备的RmEgt2湿菌体2g,控制pH为8.2,在30度水浴锅中磁力搅拌2h后,反应液进行HPLC分析,结果如图2,转化率≥98%
实施例6、TmEgt2合成麦角硫因
取实施例3中的CtEgt1反应液,分别加入终浓度为0.2g/L的PLP以及0.5g/L的DTT,加入实施例1制备的TmEgt2湿菌体2g,控制pH为8.2,在30度水浴锅中磁力搅拌2h后,反应液进行HPLC分析,转化率≥99%
以下通过实验例证明本发明的有益效果。
实验例1、Egt1合成CHER的催化条件的优化
按下述操作制备4份催化液:取实施例1的CtEgt1粗酶液,分别加入终浓度1g/L的TCEP、8g/L的L-半胱氨酸、10g/L的组氨酸甜菜碱,分成4份催化液后置于100mL的微型反应器,分别将其pH调为6.0-8.0后,在转速200rpm、通气速率为0.15vvm温度为30℃下转化6h后,反应液进行HPLC分析,结果如表2所示。
表2:不同PH条件下的Egt1转化率
结果表明,pH为6.5-7.0的反应条件下,所获得的转化率显著优于其他pH范围,因此pH为6.5-7.0为最佳的反应pH条件。
按下述操作制备4份催化液:取实施例1的CtEgt1粗酶液,分别加入终浓度1g/L的TCEP、8g/L的L-半胱氨酸、10g/L的组氨酸甜菜碱,分成4份催化液后置于100mL的微型反应器,调节反应液pH为6.75,分别置于25℃、30℃、35℃、40℃温度下,在转速200rpm、通气速率为0.15vvm转化6h后,反应液进行HPLC分析,结果如下表所示:
表3:不同反应温度条件下的Egt1转化率
结果表明,温度为30℃的反应条件下,所获得的转化率显著优于其他温度,因此30℃为最佳的反应温度。
实验例2、Egt2合成CHER的催化条件的优化
按下述操作制备5份催化液:取实施例3中的CtEgt1反应液,使用Tris-HCl缓冲液稀释成底物浓度10g/L以及缓冲液浓度为100mM,加入0.1g/L的PLP以及0.5g/L的DTT之后,分成5份催化液,分别将其pH调为6.0-9.0,分别加入5g/L的TmEgt2。在30度水浴锅中磁力搅拌2h后,反应液进行HPLC分析,结果如下表所示:
表4:不同PH条件下的Egt2转化率
结果表明,pH为8.0-8.5的反应条件下,所获得的转化率显著优于其他pH范围,因此8.0-8.5为最佳的反应pH条件。
按下述操作制备4份催化液:取实施例3中的CtEgt1反应液,使用Tris-HCl缓冲液稀释成底物浓度10g/L以及缓冲液浓度为100mM,加入0.1g/L的PLP以及0.5g/L的DTT之后,调节pH为8.0后,加入5g/L的TmEgt2,分成5份催化液,分别置于25℃、30℃、35℃、40℃的水浴锅中磁力搅拌2h后,反应液进行HPLC分析,结果如下表所示:
表5:不同反应温度条件下的Egt2转化率
结果表明,温度为30℃的反应条件下,所获得的转化率显著优于其他温度,因此30℃为最佳的反应温度。
综上,本发明提供了一种新的制备麦角硫因的方法,本发明选择路径相对简单的真核生物合成途径,筛选出转化率高的Egt1酶和Egt2酶,在适宜的特定温度、pH条件下实现了体外酶催化制备麦角硫因,其可以在较短时间内完成转化,并且可以达到较高的底物浓度及转化率,工艺操作简单,适合麦角硫因的规模化生产。