突变的Cas12j蛋白及其应用
文献发布时间:2023-06-19 19:30:30
技术领域
本发明涉及基因编辑领域,特别是规律成簇的间隔短回文重复(CRISPR)技术领域。具体而言,本发明涉及一种活性提高的突变的Cas12j蛋白及其应用。
背景技术
CRISPR/Cas技术是一种被广泛使用的基因编辑技术,它通过RNA引导对基因组上的靶序列进行特异性结合并切割DNA产生双链断裂,利用生物非同源末端连接或同源重组进行定点基因编辑。
CRISPR/Cas9系统是最常用的II型CRISPR系统,它识别3’-NGG的PAM基序,对靶标序列进行平末端切割。CRISPR/Cas Type V系统是一类新发现的CRISPR系统,它具有5’-TTN的基序,对靶标序列进行粘性末端切割,例如Cpf1,C2c1,CasX,CasY。然而目前存在的不同的CRISPR/Cas各有不同的优点和缺陷。例如Cas9,C2c1和CasX均需要两条RNA进行指导RNA,而Cpf1只需要一条指导RNA而且可以用来进行多重基因编辑。CasX具有980个氨基酸的大小,而常见的Cas9,C2c1,CasY和Cpf1通常大小在1300个氨基酸左右。此外,Cas9,Cpf1,CasX,CasY的PAM序列都比较复杂多样,而C2c1识别严谨的5’-TTN,因此它的靶标位点比其他系统容易被预测从而降低了潜在的脱靶效应。
中国发明专利CN111770992B中公开了一种Cas蛋白Cas12j.19,还公开了该蛋白可以在真核细胞中进行基因编辑,但是,其编辑活性并不高,为了提高该蛋白的编辑效率,本申请对该蛋白进行了优化,提高了其在真核细胞中的编辑效率。
发明内容
本申请的发明人经过大量实验和反复摸索,通过对Cas12j.19(本申请中将其称之为,Cas12j19)蛋白的定点突变,提高了其编辑活性,扩展了其应用范围。
Cas效应蛋白
一方面,本发明提供了一种活性改善或活性提高的Cas突变蛋白,所述突变蛋白与亲本Cas蛋白的氨基酸序列相比,在对应于SEQ ID No.1所示氨基酸序列的以下氨基酸位点处存在突变:第100位。
在一个实施方式中,所述第100位氨基酸突变为非E的氨基酸,例如,A,V,G,L,D,F,W,Y,N,S,Q,K,M,T,C,P,H,R,I;优选,突变为K,Y,M,F,R,W,S,H,V,I,N,C或L。
在一个实施方式中,所述亲本Cas蛋白的氨基酸序列与SEQ ID No.1相比具有至少70%、至少80%、至少85%、至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%、至少99%、至少99.1%、至少99.2%、至少99.3%、至少99.4%、至少99.5%、至少99.6%、至少99.7%、至少99.8%、或至少99.9%的序列同一性。
在一个实施方式中,所述亲本Cas蛋白为Cas12家族的Cas蛋白,优选,Cas12j家族的Cas蛋白,例如,CN111770992B公开的Cas12j.3-Cas12j.22等;在优选的实施方式中,所述亲本Cas蛋白为Cas12j19;所述Cas12j19的氨基酸序列与SEQ ID No.1相比具有至少70%、至少80%、至少85%、至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%、至少99%、至少99.1%、至少99.2%、至少99.3%、至少99.4%、至少99.5%、至少99.6%、至少99.7%、至少99.8%、或至少99.9%或100%的序列同一性。
在一个实施方式中,所述Cas突变蛋白选自以下I-III任意一组:
I、由SEQ ID No.1所示氨基酸序列在包含以下氨基酸位点处产生突变得到的Cas突变蛋白:第100位;优选的,所述第100位氨基酸突变为非E的氨基酸,例如,A,V,G,L,D,F,W,Y,N,S,Q,K,M,T,C,P,H,R,I;优选,突变为K,Y,M,F,R,W,S,H,V,I,N,C或L;
II、与I所述的Cas突变蛋白相比,具有I中所述的突变位点;并且,与I所述的Cas突变蛋白相比,具有至少80%、至少85%、至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%、至少99%、至少99.1%、至少99.2%、至少99.3%、至少99.4%、至少99.5%、至少99.6%、至少99.7%、至少99.8%、或至少99.9%的序列同一性的Cas突变蛋白;
III、与I所述的Cas突变蛋白相比,具有I中所述的突变位点;并且,与I所述的Cas突变蛋白相比,具有一个或多个氨基酸的置换、缺失或添加的序列;所述一个或多个氨基酸包括1个,2个,3个,4个,5个,6个,7个,8个,9个或10个氨基酸的置换、缺失或添加。
来自多种生物体的Cas蛋白或Cas12j蛋白都可以用作亲本Cas蛋白,在一些实施方式中,所述亲本Cas蛋白或Cas12j蛋白具有核酸酶活性。在一些实施方案中,所述亲本Cas蛋白是核酸酶,即切割靶双螺旋核酸(例如,双螺旋DNA)的两条链。在一些实施方案中,所述亲本Cas蛋白是切口酶,即切割靶双螺旋核酸(例如,双螺旋DNA)的单链。
在一些实施方案中,所述亲本Cas蛋白为天然野生型Cas蛋白;在其他的实施方式中,所述亲本Cas蛋白为经过工程化改造后的Cas蛋白。
本领域技术人员清楚,可以改变蛋白质的结构而不对其活性和功能性产生不利影响,例如,可以在蛋白质氨基酸序列中引入一个或多个保守性氨基酸取代,而不会对蛋白质分子的活性和/或三维结构产生不利影响。本领域技术人员清楚保守性氨基酸取代的实例以及实施方式。具体的说,可以用与待取代位点属于相同组的另一氨基酸残基取代该氨基酸残基,即用非极性氨基酸残基取代另一非极性氨基酸残基,用极性不带电荷的氨基酸残基取代另一极性不带电荷的氨基酸残基,用碱性氨基酸残基取代另一碱性氨基酸残基,和用酸性氨基酸残基取代另一酸性氨基酸残基。这样的取代的氨基酸残基可以是也可以不是由遗传密码编码的。只要取代不导致蛋白质生物活性的失活,则一种氨基酸被属于同组的其他氨基酸替换的保守取代落在本发明的范围内。因此,本发明的蛋白可以在氨基酸序列中包含一个或多个保守性取代,这些保守性取代最好根据表1进行替换而产生。另外,本发明也涵盖还包含一个或多个其他非保守取代的蛋白,只要该非保守取代不显著影响本发明的蛋白质的所需功能和生物活性即可。
保守氨基酸置换可以在一个或多个预测的非必需氨基酸残基处进行。“非必需”氨基酸残基是可以发生改变(缺失、取代或置换)而不改变生物活性的氨基酸残基,而“必需”氨基酸残基是生物活性所需的。“保守氨基酸置换”是其中氨基酸残基被具有类似侧链的氨基酸残基替代的置换。氨基酸置换可以在上述Cas突变蛋白的非保守区域中进行。一般而言,此类置换不对保守的氨基酸残基,或者不对位于保守基序内的氨基酸残基进行,其中此类残基是蛋白质活性所需的。然而,本领域技术人员应当理解,功能变体可以具有较少的在保守区域中的保守或非保守改变。
表1
本领域熟知,可以从蛋白质的N和/或C末端改变(置换、删除、截短或插入)一或多个氨基酸残基而仍保留其功能活性。因此,从Cas蛋白的N和/或C末端改变了一或多个氨基酸残基、同时保留了其所需功能活性的蛋白,也在本发明的范围内。这些改变可以包括通过现代分子方法例如PCR而引入的改变,所述方法包括借助于在PCR扩增中使用的寡核苷酸之中包含氨基酸编码序列而改变或延长蛋白质编码序列的PCR扩增。
应认识到,蛋白质可以以各种方式进行改变,包括氨基酸置换、删除、截短和插入,用于此类操作的方法是本领域通常已知的。例如,可以通过对DNA的突变来制备上述蛋白的氨基酸序列变体。还可以通过其他诱变形式和/或通过定向进化来完成,例如,使用已知的诱变、重组和/或改组(shuffling)方法,结合相关的筛选方法,来进行单个或多个氨基酸取代、缺失和/或插入。
领域技术人员能够理解,本发明Cas蛋白中的这些微小氨基酸变化可以出现(例如天然存在的突变)或者产生(例如使用r-DNA技术)而不损失蛋白质功能或活性。如果这些突变出现在蛋白的催化结构域、活性位点或其它功能结构域中,则多肽的性质可改变,但多肽可保持其活性。如果存在的突变不接近催化结构域、活性位点或其它功能结构域中,则可预期较小影响。
本领域技术人员可以根据本领域已知的方法,例如定位诱变或蛋白进化或生物信息系的分析,来鉴定本发明Cas突变蛋白的必需氨基酸。蛋白的催化结构域、活性位点或其它功能结构域也能够通过结构的物理分析而确定,如通过以下这些技术:如核磁共振、晶体学、电子衍射或光亲和标记,结合推定的关键位点氨基酸的突变来确定。
本发明中,氨基酸残基可以用单字母表示,也可以用三字母表示,例如:丙氨酸(Ala,A),缬氨酸(Val,V),甘氨酸(Gly,G),亮氨酸(Leu,L),谷酰胺酸(Gln,Q),苯丙氨酸(Phe,F),色氨酸(Trp,W),酪氨酸(Tyr,Y),天冬氨酸(Asp,D),天冬酰胺(Asn,N),谷氨酸(Glu,E),赖氨酸(Lys,K),甲硫氨酸(Met,M),丝氨酸(Ser,S),苏氨酸(Thr,T),半胱氨酸(Cys,C),脯氨酸(Pro,P),异亮氨酸(Ile,I),组氨酸(His,H),精氨酸(Arg,R)。
术语“AxxB”表示第xx位的氨基酸A变为氨基酸B,如无特别说明,均是从N端起第xx位的氨基酸A变为氨基酸B。例如,E100R表示第100位的E突变为R。多个氨基酸位点同时存在突变时,可以采用E328R-N369R类似的形式进行表述,例如,E328R-N369R代表第328位E突变为R同时第369位N突变为R。
本发明所述蛋白质内的特定氨基酸位置(编号)是利用标准序列比对工具通过将目标蛋白质的氨基酸序列与SEQ ID No.1进行比对而确定的,譬如用Smith-Waterman运算法则或用CLUSTALW2运算法则比对两个序列,其中当比对得分最高时认为所述序列是对准的。比对得分可依照Wilbur,W.J.and Lipman,D.J.(1983)Rapid similarity searchesofnucleic acid and protein data banks.Proc.Natl.Acad.Sci.USA,80:726-730中所述的方法进行计算。在ClustalW2(1.82)运算法则中优选使用默认参数:蛋白质缺口开放罚分=10.0;蛋白质缺口延伸罚分=0.2;蛋白质矩阵=Gonnet;蛋白质/DNA端隙=-1;蛋白质/DNAGAPDIST=4。优选采用AlignX程序(vectorNTI组中的一部分),以适于多重比对的默认参数(缺口开放罚分:10og缺口延伸罚分0.05)通过将蛋白质的氨基酸序列与SEQ IDNo.1进行比来确定本发明所述蛋白质内特定氨基酸的位置。
在一个实施方式中,所述亲本Cas蛋白的氨基酸序列与SEQ ID No.1相比具有至少80%、至少85%、至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%、至少99%、至少99.1%、至少99.2%、至少99.3%、至少99.4%、至少99.5%、至少99.6%、至少99.7%、至少99.8%、或至少99.9%的序列同一性。
在一个实施方式中,所述Cas突变蛋白选自以下I-III任意一组:
I、由SEQ ID No.1所示氨基酸序列在包含以下任一或任意几个氨基酸位点处产生突变得到的Cas突变蛋白:第100位;
II、与I所述的Cas突变蛋白相比,具有I中所述的突变位点;并且,与I所述的Cas突变蛋白相比,具有至少80%、至少85%、至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%、或至少99%的序列同一性的Cas突变蛋白;
III、与I所述的Cas突变蛋白相比,具有I中所述的突变位点;并且,与I所述的Cas突变蛋白相比,具有一个或多个氨基酸的置换、缺失或添加的序列;所述一个或多个氨基酸包括1个,2个,3个,4个,5个,6个,7个,8个,9个或10个氨基酸的置换、缺失或添加。
所述Cas蛋白的生物学功能包括但不限于,与指导RNA结合的活性、核酸内切酶活性、在指导RNA引导下与靶序列特定位点结合并切割的活性,包括但不限于Cis切割活性和Trans切割活性。
本发明中,“Cas突变蛋白”也可以称之为突变的Cas蛋白,或者Cas蛋白变体。
本发明还提供了一种融合蛋白,所述融合蛋白包括如上所述的Cas突变蛋白和其他的修饰部分。
在一个实施方式中,所述修饰部分选自另外的蛋白或多肽、可检测的标记或其任意组合。
在一个实施方式中,所述修饰部分选自表位标签、报告基因序列、核定位信号(NLS)序列、靶向部分、转录激活结构域(例如,VP64)、转录抑制结构域(例如,KRAB结构域或SID结构域)、核酸酶结构域(例如,Fok1),以及具有选自下列的活性的结构域:核苷酸脱氨酶,腺苷脱氨酶,胞苷脱氨酶,甲基化酶活性,去甲基化酶,转录激活活性,转录抑制活性,转录释放因子活性,组蛋白修饰活性,核酸酶活性,单链RNA切割活性,双链RNA切割活性,单链DNA切割活性,双链DNA切割活性和核酸结合活性;以及其任意组合。所述NLS序列是本领域技术人员熟知的,其实例包括但不限于所述,SV40大T抗原,EGL-13,c-Myc以及TUS蛋白。
在一个实施方式中,所述NLS序列位于、靠近或接近本发明的Cas蛋白的末端(例如,N端、C端或两端)。
所述表位标签(epitope tag)是本领域技术人员熟知的,包括但不限于His、V5、FLAG、HA、Myc、VSV-G、Trx等,并且本领域技术人员可以选择其他合适的表位标签(例如,纯化、检测或示踪)。
所述报告基因序列是本领域技术人员熟知的,其实例包括但不限于GST、HRP、CAT、GFP、HcRed、DsRed、CFP、YFP、BFP等。
在一个实施方式中,本发明的融合蛋白包含能够与DNA分子或细胞内分子结合的结构域,例如麦芽糖结合蛋白(MBP)、Lex A的DNA结合结构域(DBD)、GAL4的DBD等。
在一个实施方式中,本发明的融合蛋白包含可检测的标记,例如荧光染料,例如FITC或DAPI。
在一个实施方式中,本发明的Cas蛋白任选地通过接头与所述修饰部分偶联、缀合或融合。
在一个实施方式中,所述修饰部分直接连接至本发明的Cas蛋白的N端或C端。
在一个实施方式中,所述修饰部分通过接头连接至本发明的Cas蛋白的N端或C端。这类接头是本领域熟知的,其实例包括但不限于包含一个或多个(例如,1个,2个,3个,4个或5个)氨基酸(如,Glu或Ser)或氨基酸衍生物(如,Ahx、β-Ala、GABA或Ava)的接头,或PEG等。
本发明的Cas蛋白、蛋白衍生物或融合蛋白不受其产生方式的限定,例如,其可以通过基因工程方法(重组技术)产生,也可以通过化学合成方法产生。
Cas蛋白的核酸
另一方面,本发明提供了一种分离的多核苷酸,其包含:
(a)编码本发明的Cas突变蛋白或融合蛋白的多核苷酸序列;
或者,与(a)所述的多核苷酸互补的多核苷酸。
在一个实施方式中,所述的核苷酸序列经密码子优化用于在原核细胞中进行表达。在一个实施方式中,所述的核苷酸序列经密码子优化用于在真核细胞中进行表达。
在一个实施方式中,所述细胞是动物细胞,例如,哺乳动物细胞。
在一个实施方式中,所述细胞是人类细胞。
在一个实施方式中,所述细胞是植物细胞,例如栽培植物(如木薯、玉米、高粱、小麦或水稻)、藻类、树或蔬菜具有的细胞。
在一个实施方式中,所述的多核苷酸优选是单链的或双链的。
指导RNA(gRNA)
另一方面,本发明提供了一种gRNA,所述gRNA包括第一区段和第二区段;所述第一区段又称为“骨架区”、“蛋白质结合区段”、“蛋白质结合序列”、或者“同向重复(DirectRepeat)序列”;所述第二区段又称为“靶向核酸的靶向序列”或者“靶向核酸的靶向区段”,或者“靶向靶序列的引导序列”。
所述gRNA的第一区段能够与本发明的Cas蛋白相互作用,从而使Cas蛋白和gRNA形成复合物。
在优选的实施方式中,所述第一区段为如上所述的同向重复序列。
本发明靶向核酸的靶向序列或靶向核酸的靶向区段包含与靶核酸中的序列互补的核苷酸序列。换言之,本发明靶向核酸的靶向序列或靶向核酸的靶向区段经过杂交(即,碱基配对)以序列特异性方式与靶核酸相互作用。因此,靶向核酸的靶向序列或靶向核酸的靶向区段可改变,或可被修饰以杂交靶核酸内的任何希望的序列。所述核酸选自DNA或RNA。
靶向核酸的靶向序列或靶向核酸的靶向区段与靶核酸的靶序列之间的互补百分比可为至少60%(例如,至少65%、至少70%、至少75%、至少80%、至少85%、至少90%、至少95%、至少97%、至少98%、至少99%或100%)。
本发明gRNA的“骨架区”、“蛋白质结合区段”、“蛋白质结合序列”、或者“同向重复序列”可以与CRISPR蛋白(或者,Cas蛋白)相互作用。本发明gRNA经过靶向核酸的靶向序列的作用将其相互作用的Cas蛋白引导至靶核酸内的特异性核苷酸序列。
优选的,所述指导RNA从5’至3’方向包含第一区段和第二区段。
本发明中,所述第二区段还可以理解为与靶序列杂交的引导序列。
本发明的gRNA能够与所述Cas蛋白形成复合物。
载体
本发明还提供了一种载体,其包含如上述的Cas突变蛋白、分离的核酸分子或多核苷酸;优选的,其还包括与之可操作连接的调控元件。
在一个实施方式中,所述的调控元件选自下组中的一种或多种:增强子、转座子、启动子、终止子、前导序列、多腺苷酸序列、标记基因。
在一个实施方式中,所述的载体包括克隆载体、表达载体、穿梭载体、整合载体。
在一些实施方案中,所述系统中包括的载体是病毒载体(例如逆转录病毒载体,慢病毒载体,腺病毒载体,腺相关载体和单纯疱疹载体),还可以是质粒、病毒、粘粒、噬菌体等类型,它们是本领域技术人员所熟知的。
CRISPR系统
本发明提供了一种工程化的非天然存在的载体系统,或者是CRISPR-Cas系统,该系统包括Cas突变蛋白或编码所述Cas突变蛋白的核酸序列以及编码一种或多种指导RNA的核酸。
在一种实施方式中,所述编码所述Cas突变蛋白的核酸序列和编码一种或多种指导RNA的核酸是人工合成的。
在一种实施方式中,所述编码所述Cas突变蛋白的核酸序列和编码一种或多种指导RNA的核酸并不共同天然存在。
该一种或多种指导RNA在细胞中靶向一个或多个靶序列。所述一个或多个靶序列与编码一种或多种基因产物的DNA分子的基因组座位杂交,并且引导该Cas蛋白到达所述一种或多种基因产物的DNA分子的基因组座位部位,Cas蛋白到达靶序列位置后对靶序列进行修饰、编辑或切割,由此该一种或多种基因产物的表达被改变或修饰。
本发明的细胞包括动物、植物或微生物中的一种或多种。
在一些实施例中,该Cas蛋白是密码子优化的,用于在细胞中进行表达。
在一些实施例中,该Cas蛋白指导切割在该靶序列位置处的一条或两条链。
本发明还提供了一种工程化的非天然存在的载体系统,该载体系统可以包括一种或多种载体,该一种或多种载体包括:
a)第一调控元件,该第一调控元件可操作地与gRNA连接,
b)第二调控元件,该第二调控元件可操作地与所述Cas蛋白连接;
其中组分(a)和(b)位于该系统的相同或不同载体上。
所述第一和第二调控元件包括启动子(例如,组成型启动子或诱导型启动子)、增强子(例如35S promoter或35S enhanced promoter)、内部核糖体进入位点(IRES)、和其他表达控制元件(例如转录终止信号,如多聚腺苷酸化信号和多聚U序列)。
在一些实施方案中,所述系统中的载体是病毒载体(例如逆转录病毒载体,慢病毒载体,腺病毒载体,腺相关载体和单纯疱疹载体),还可以是质粒、病毒、粘粒、噬菌体等类型,它们是本领域技术人员所熟知的。
在一些实施例中,本文提供的系统处于递送系统中。在一些实施方案中,递送系统是纳米颗粒,脂质体,外体,微泡和基因枪。
在一个实施方式中,所述靶序列是来自原核细胞或真核细胞的DNA或RNA序列。在一个实施方式中,所述靶序列是非天然存在的DNA或RNA序列。
在一个实施方式中,所述靶序列存在于细胞内。在一个实施方式中,所述靶序列存在于细胞核内或细胞质(例如,细胞器)内。在一个实施方式中,所述细胞是真核细胞。在其他实施方式中,所述细胞是原核细胞。
在一个实施方式中,所述Cas蛋白连接有一个或多个NLS序列。在一个实施方式中,所述融合蛋白包含一个或多个NLS序列。在一个实施方式中,所述NLS序列连接至所述蛋白的N端或C端。在一个实施方式中,所述NLS序列融合至所述蛋白的N端或C端。
另一方面,本发明涉及一种工程化的CRISPR系统,所述系统包含上述Cas蛋白以及一种或多种指导RNA,其中,所述指导RNA包括同向重复序列和能够与靶核酸杂交的间隔序列,所述Cas蛋白能够结合所述指导RNA并靶向与间隔序列互补的靶核酸序列。
蛋白-核酸复合物/组合物
另一方面,本发明提供了一种复合物或者组合物,其包含:
(i)蛋白组分,其选自:上述Cas蛋白、衍生化蛋白或融合蛋白,及其任意组合;和
(ii)核酸组分,其包含(a)能够与靶序列杂交的引导序列;以及(b)能够与本发明的Cas蛋白结合的同向重复序列。
所述蛋白组分与核酸组分相互结合形成复合物。
在一个实施方式中,所述核酸组分是CRISPR-Cas系统中的指导RNA。
在一个实施方式中,所述复合物或组合物是非天然存在的或经修饰的。在一个实施方式中,所述复合物或组合物中的至少一个组分是非天然存在的或经修饰的。在一个实施方式中,所述第一组分是非天然存在的或经修饰的;和/或,所述第二组分是非天然存在的或经修饰的。
活化的CRISPR复合物
另一方面,本发明还提供了一种活化的CRISPR复合物,所述活化的CRISPR复合物包含:(1)蛋白组分,其选自:本发明的Cas蛋白、衍生化蛋白或融合蛋白,及其任意组合;(2)gRNA,其包含(a)能够与靶序列杂交的引导序列;以及(b)能够与本发明的Cas蛋白结合的同向重复序列;以及(3)结合在gRNA上的靶序列。优选的,所述结合为通过gRNA上的靶向核酸的靶向序列与靶核酸进行的结合。
本文所用术语“活化的CRISPR复合物”,“活化复合物”或“三元复合物”是指CRISPR系统中Cas蛋白、gRNA与靶核酸结合或修饰后的复合物。
本发明的Cas蛋白和gRNA可以形成二元复合物,该二元复合物在与核酸底物结合时被活化,形成活化的CRISPR复合物该核酸底物与gRNA中的间隔序列(或者称之为,与靶核酸杂交的引导序列)互补。在一些实施方案中,gRNA的间隔序列与靶底物完全匹配。在其它实施方案中,gRNA的间隔序列与靶底物的部分(连续或不连续)匹配。
在优选的实施方式中,所述活化的CRISPR复合物可以表现出侧枝核酸酶切活性,所述侧枝核酸酶切活性是指活化的CRISPR复合物表现的对单链核酸的非特异切割活性或乱切活性,在本领域又称之为trans切割活性。
递送及递送组合物
本发明的Cas蛋白、gRNA、融合蛋白、核酸分子、载体、系统、复合物和组合物,可以通过本领域已知的任何方法进行递送。此类方法包括但不限于,电穿孔、脂转染、核转染、显微注射、声孔效应、基因枪、磷酸钙介导的转染、阳离子转染、脂质体转染、树枝状转染、热激转染、核转染、磁转染、脂转染、穿刺转染、光学转染、试剂增强性核酸摄取、以及经由脂质体、免疫脂质体、病毒颗粒、人工病毒体等的递送。
因此,在另一个方面,本发明提供了一种递送组合物,其包含递送载体,以及选自下列的一种或任意几种:本发明的Cas蛋白、融合蛋白、核酸分子、载体、系统、复合物和组合物。
在一个实施方式中,所述递送载体是粒子。
在一个实施方式中,所述递送载体选自脂质颗粒、糖颗粒、金属颗粒、蛋白颗粒、脂质体、外泌体、微泡、基因枪或病毒载体(例如,复制缺陷型逆转录病毒、慢病毒、腺病毒或腺相关病毒)。
宿主细胞
本发明还涉及一种体外的、离体的或体内的细胞或细胞系或它们的子代,所述细胞或细胞系或它们的子代包含:本发明所述的Cas蛋白、融合蛋白、核酸分子、蛋白-核酸复合物、活化的CRISPR复合物、载体、本发明递送组合物。
在某些实施方案中,所述细胞是原核细胞。
在某些实施方案中,所述细胞是真核细胞。在某些实施方案中,所述细胞是哺乳动物细胞。在某些实施方案中,所述细胞是人类细胞。某些实施方案中,所述细胞是非人哺乳动物细胞,例如非人灵长类动物、牛、羊、猪、犬、猴、兔、啮齿类(如大鼠或小鼠)的细胞。在某些实施方案中,所述细胞是非哺乳动物真核细胞,例如家禽鸟类(如鸡)、鱼类或甲壳动物(如蛤蜊、虾)的细胞。在某些实施方案中,所述细胞是植物细胞,例如单子叶植物或双子叶植物具有的细胞或栽培植物或粮食作物如木薯、玉米、高粱、大豆、小麦、燕麦或水稻具有的细胞,例如藻类、树或生产植物、果实或蔬菜(例如,树类如柑橘树、坚果树;茄属植物、棉花、烟草、番茄、葡萄、咖啡、可可等)。
在某些实施方案中,所述细胞是干细胞或干细胞系。
在某些情况下,本发明的宿主细胞包含基因或基因组的修饰,该修饰是在其野生型中不存在的修饰。
基因编辑方法和应用
本发明的Cas突变蛋白、核酸、上述组合物、上述CIRSPR/Cas系统、上述载体系统、上述递送组合物或上述活化的CRISPR复合物或者上述宿主细胞可用于以下任一或任意几个用途:靶向和/或编辑靶核酸;切割双链DNA、单链DNA或单链RNA;非特异性切割和/或降解侧枝核酸;非特异性切割单链核酸;核酸检测;检测目标样品中的核酸;特异性地编辑双链核酸;碱基编辑双链核酸;碱基编辑单链核酸。在其他的实施方式中,还可以用于制备用于上述任一或任意几个用途的试剂或试剂盒。
本发明还提供了上述Cas蛋白、核酸、上述组合物、上述CIRSPR/Cas系统、上述载体系统、上述递送组合物或上述活化的CRISPR复合物在基因编辑、基因靶向或基因切割中的应用;或者,在制备用于基因编辑、基因靶向或基因切割的试剂或试剂盒中的用途。
在一个实施方式中,所述基因编辑、基因靶向或基因切割为在细胞内和/或细胞外进行基因编辑、基因靶向或基因切割。
本发明还提供了一种编辑靶核酸、靶向靶核酸或切割靶核酸的方法,所述方法包括将靶核酸与上述Cas蛋白、核酸、上述组合物、上述CIRSPR/Cas系统、上述载体系统、上述递送组合物或上述活化的CRISPR复合物进行接触。在一个实施方式中,所述方法为在细胞内或细胞外编辑靶核酸、靶向靶核酸或切割靶核酸。
所述基因编辑或编辑靶核酸包括修饰基因、敲除基因、改变基因产物的表达、修复突变、和/或插入多核苷酸、基因突变。
所述编辑可以在原核细胞和/或真核细胞中进行编辑。
另一方面,本发明还提供了上述Cas蛋白、核酸、上述组合物、上述CIRSPR/Cas系统、上述载体系统、上述递送组合物或上述活化的CRISPR复合物在核酸检测中的应用,或在制备用于核酸检测的试剂或试剂盒中的用途。
另一方面,本发明还提供了一种切割单链核酸的方法,所述方法包括,使核酸群体与上述Cas蛋白和gRNA接触,其中所述核酸群体包含靶核酸和多个非靶单链核酸,所述Cas蛋白切割所述多个非靶单链核酸。
所述gRNA能够结合所述Cas蛋白。
所述gRNA能够靶向所述靶核酸。
所述接触可以是在体外、离体或体内的细胞内部。
优选的,所述切割单链核酸为非特异性的切割。
另一方面,本发明还提供了上述Cas蛋白、核酸、上述组合物、上述CIRSPR/Cas系统、上述载体系统、上述递送组合物或上述活化的CRISPR复合物在非特异性的切割单链核酸中的应用,或在制备用于非特异性的切割单链核酸的试剂或试剂盒中的用途。
另一方面,本发明还提供了一种用于基因编辑、基因靶向或基因切割的试剂盒,所述试剂盒包括上述Cas蛋白、gRNA、核酸、上述组合物、上述CIRSPR/Cas系统、上述载体系统、上述递送组合物、上述活化的CRISPR复合物或上述宿主细胞。
另一方面,本发明还提供了一种用于检测样品中的靶核酸的试剂盒,所述试剂盒包含:(a)Cas蛋白,或编码所述Cas蛋白的核酸;(b)指导RNA,或编码所述指导RNA的核酸,或包含所述指导RNA的前体RNA,或编码所述前体RNA的核酸;和(c)为单链的且不与所述指导RNA杂交的单链核酸检测器。
本领域知晓,前体RNA可被切割或加工成为上述成熟的指导RNA。
另一方面,发明提供了上述Cas蛋白、核酸、上述组合物、上述CIRSPR/Cas系统、上述载体系统、上述递送组合物、上述活化的CRISPR复合物或上述宿主细胞在制备制剂或试剂盒中的用途,所述制剂或试剂盒用于:
(i)基因或基因组编辑;
(ii)靶核酸检测和/或诊断;
(iii)编辑靶基因座中的靶序列来修饰生物或非人类生物;
(iv)疾病的治疗;
(iv)靶向靶基因。
优选的,上述基因或基因组编辑为在细胞内或细胞外进行基因或基因组编辑。
优选的,所述靶核酸检测和/或诊断为在体外进行靶核酸检测和/或诊断。
优选的,所述疾病的治疗为治疗由靶基因座中的靶序列的缺陷引起的病症。
另一个方面,本发明提供了一种检测样品中靶核酸的方法,所述方法包括将样品与所述Cas蛋白、gRNA(指导RNA)和单链核酸检测器接触,所述gRNA包括与所述Cas蛋白结合的区域和与靶核酸杂交的指导序列;检测由所述Cas蛋白切割单链核酸检测器产生的可检测信号,从而检测靶核酸;所述单链核酸检测器不与所述gRNA杂交。
特异性修饰靶核酸的方法
另一方面,本发明还提供了一种特异性修饰靶核酸的方法,方法包括:使靶核酸与上述Cas蛋白、核酸、上述组合物、上述CIRSPR/Cas系统、上述载体系统、上述递送组合物或上述活化的CRISPR复合物接触。
该特异性修饰可以发生在体内或者体外。
该特异性修饰可以发生在细胞内或者细胞外。
在一些情况下,细胞选自原核细胞或真核细胞,例如,动物细胞、植物细胞或微生物细胞。
在一个实施方式中,所述修饰是指所述靶序列的断裂,如,DNA的单链/双链断裂,或者RNA的单链断裂。
在一些情况下,所述方法还包括使靶核酸与供体多核苷酸接触,其中将供体多核苷酸、供体多核苷酸的部分、供体多核苷酸的拷贝或供体多核苷酸的拷贝的部分整合到靶核酸中。
在一个实施方式中,所述修饰还包括将编辑模板(例如外源核酸)插入所述断裂中。
在一个实施方式中,所述方法还包括:将编辑模板与所述靶核酸接触,或者递送至包含所述靶核酸的细胞中。在此实施方式中,所述方法通过与外源模板多核苷酸同源重组修复所述断裂的靶基因;在一些实施方式中,所述修复导致一种突变,包括所述靶基因的一个或多个核苷酸的插入、缺失、或取代,在其他的实施方式中,所述突变导致在从包含该靶序列的基因表达的蛋白质中的一个或多个氨基酸改变。
检测(非特异切割)
另一方面,本发明提供了一种检测样品中靶核酸的方法,所述方法包括将样品与上述Cas蛋白、核酸、上述组合物、上述CIRSPR/Cas系统、上述载体系统、上述递送组合物或上述活化的CRISPR复合物和单链核酸检测器接触;检测由所述Cas蛋白切割单链核酸检测器产生的可检测信号,从而检测靶核酸。
本发明中,所述靶核酸包括核糖核苷酸或脱氧核糖核苷酸;包括单链核酸、双链核酸,例如单链DNA、双链DNA、单链RNA、双链RNA。
在一个实施方式中,所述靶核酸来源于病毒、细菌、微生物、土壤、水源、人体、动物、植物等样品。优选的,所述靶核酸为PCR、NASBA、RPA、SDA、LAMP、HAD、NEAR、MDA、RCA、LCR、RAM等方法富集或扩增的产物。
在一个实施方式中,所述靶核酸为病毒核酸、细菌核酸、与疾病相关的特异核酸,如特定的突变位点或SNP位点或与对照有差异的核酸;优选地,所述病毒为植物病毒或动物病毒,例如,乳头瘤病毒,肝DNA病毒,疱疹病毒,腺病毒,痘病毒,细小病毒,冠状病毒;优选地,所述病毒为冠状病毒,优选地,SARS、SARS-CoV2(COVID-19)、HCoV-229E、HCoV-OC43、HCoV-NL63、HCoV-HKU1、Mers-Cov。
本发明中,所述gRNA与靶核酸上的靶序列至少有50%的匹配度,优选至少60%,优选至少70%,优选至少80%,优选至少90%。
在一个实施方式中,当所述的靶序列含有一个或多个特征位点(如特定的突变位点或SNP)时,所述的特征位点与gRNA完全匹配。
在一个实施方式中,所述检测方法中可以包含一种或多种导向序列互不相同的gRNA,其靶向不同的靶序列。
本发明中,所述单链核酸检测器包括但不限于单链DNA、单链RNA、DNA-RNA杂交体、核酸类似物、碱基修饰物、以及含有无碱基间隔物的单链核酸检测器等;“核酸类似物”包括但不限于:锁核酸、桥核酸、吗啉核酸、乙二醇核酸、己糖醇核酸、苏糖核酸、阿拉伯糖核酸、2’氧甲基RNA、2’甲氧基乙酰基RNA、2’氟RNA、2’氨基RNA、4’硫RNA及其组合,包括任选的核糖核苷酸或脱氧核糖核苷酸残基。
本发明中,所述可检测信号通过以下方式实现:基于视觉的检测,基于传感器的检测,颜色检测,基于荧光信号的检测,基于金纳米颗粒的检测,荧光偏振,胶体相变/分散,电化学检测和基于半导体的检测。
本发明中,优选的,所述单链核酸检测器的两端分别设置荧光基团和淬灭基团,当所述单链核酸检测器被切割后,可以表现出可检测的荧光信号。所述荧光基团选自FAM、FITC、VIC、JOE、TET、CY3、CY5、ROX、Texas Red或LC RED460中的一种或任意几种;所述淬灭基团选自BHQ1、BHQ2、BHQ3、Dabcy1或Tamra中的一种或任意几种。
在其他的实施方式中,所述单链核酸检测器的5’端和3’端分别设置不同的标记分子,通过胶体金检测的方式,检测所述单链核酸检测器被Cas蛋白切割前和被Cas蛋白切割后的胶体金测试结果;所述单链核酸检测器被Cas蛋白切割前和被Cas蛋白切割后在胶体金的检测线和质控线上将表现出不同的显色结果。
在一些实施方案中,检测靶核酸的方法还可以包括将可检测信号的电平与参考信号电平进行比较,以及基于可检测信号的电平确定样品中靶核酸的量。
在一些实施方案中,检测靶核酸的方法还可以包括在不同的通道上使用RNA报告核酸和DNA报告核酸(例如,荧光颜色),并通过测量RNA和DNA报告分子的信号电平,以及通过测量RNA和DNA报告分子中靶核酸的量来确定可检测信号的电平,基于组合(例如,使用最小或乘积)可检测信号的电平来采样。
在一个实施方式中,所述靶基因存在于细胞内。
在一个实施方式中,所述细胞是原核细胞。
在一个实施方式中,所述细胞是真核细胞。
在一个实施方式中,所述细胞是动物细胞。
在一个实施方式中,所述细胞是人类细胞。
在一个实施方式中,所述细胞是植物细胞,例如栽培植物(如木薯、玉米、高粱、小麦或水稻)、藻类、树或蔬菜具有的细胞。
在一个实施方式中,所述靶基因存在于体外的核酸分子(例如,质粒)中。
在一个实施方式中,所述靶基因存在于质粒中。
术语定义
在本发明中,除非另有说明,否则本文中使用的科学和技术名词具有本领域技术人员所通常理解的含义。并且,本文中所用的分子遗传学、核酸化学、化学、分子生物学、生物化学、细胞培养、微生物学、细胞生物学、基因组学和重组DNA等操作步骤均为相应领域内广泛使用的常规步骤。同时,为了更好地理解本发明,下面提供相关术语的定义和解释。
本文中的核酸切割或切割核酸包括:由本文所述Cas酶产生的靶核酸中的DNA或RNA断裂(Cis切割)、DNA或RNA在侧枝核酸底物(单链核酸底物)中的断裂(即非特异性或非靶向性,Trans切割)。在一些实施方式中,所述切割是双链DNA断裂。在一些实施方案中,切割是单链DNA断裂或单链RNA断裂。
CRISPR系统
如本文中所使用的,术语“规律成簇的间隔短回文重复(CRISPR)-CRISPR-相关(Cas)(CRISPR-Cas)系统”或“CRISPR系统”可互换地使用并且具有本领域技术人员通常理解的含义,其通常包含与CRISPR相关(“Cas”)基因的表达有关的转录产物或其他元件,或者能够指导所述Cas基因活性的转录产物或其他元件。
CRISPR/Cas复合物
如本文中所使用的,术语“CRISPR/Cas复合物”是指,指导RNA(guide RNA)或成熟crRNA与Cas蛋白结合所形成的复合体,其包含杂交到靶序列的引导序列上并且与Cas蛋白结合的同向重复序列,该复合体能够识别并切割能与该指导RNA或成熟crRNA杂交的多核苷酸。
指导RNA(guide RNA,gRNA)
如本文中所使用的,术语“指导RNA(guide RNA,gRNA)”、“成熟crRNA”、“指导序列”可互换地使用并且具有本领域技术人员通常理解的含义。一般而言,指导RNA可以包含同向重复序列(direct repeat)和引导序列,或者基本上由或由同向重复序列和引导序列组成。
在某些情况下,指导序列是与靶序列具有足够互补性从而与所述靶序列杂交并引导CRISPR/Cas复合物与所述靶序列的特异性结合的任何多核苷酸序列。在一个实施方式中,当最佳比对时,指导序列与其相应靶序列之间的互补程度为至少50%、至少60%、至少70%、至少80%、至少90%、至少95%、或至少99%。确定最佳比对在本领域的普通技术人员的能力范围内。例如,存在公开和可商购的比对算法和程序,诸如但不限于ClustalW、matlab中的史密斯-沃特曼算法(Smith-Waterman)、Bowtie、Geneious、Biopython以及SeqMan。
靶序列
“靶序列”是指被gRNA中的引导序列所靶向的多核苷酸,例如与该引导序列具有互补性的序列,其中靶序列与引导序列之间的杂交将促进CRISPR/Cas复合物(包括Cas蛋白和gRNA)的形成。完全互补性不是必需的,只要存在足够互补性以引起杂交并且促进一种CRISPR/Cas复合物的形成即可。
靶序列可以包含任何多核苷酸,如DNA或RNA。在某些情况下,所述靶序列位于细胞内或细胞外。在某些情况下,所述靶序列位于细胞的细胞核或细胞质中。在某些情况下,该靶序列可位于真核细胞的一个细胞器例如线粒体或叶绿体内。可被用于重组到包含该靶序列的靶基因座中的序列或模板被称为“编辑模板”或“编辑多核苷酸”或“编辑序列”。在一个实施方式中,所述编辑模板为外源核酸。在一个实施方式中,该重组是同源重组。
在本发明中,“靶序列”或“靶多核苷酸”或“靶核酸”可以是对细胞(例如,真核细胞)而言任何内源或外源的多核苷酸。例如,该靶多核苷酸可以是一种存在于真核细胞的细胞核中的多核苷酸。该靶多核苷酸可以是一个编码基因产物(例如,蛋白质)的序列或一个非编码序列(例如,调节多核苷酸或无用DNA)。在某些情况下,该靶序列应该与原间隔序列临近基序(PAM)相关。
单链核酸检测器
本发明所述的单链核酸检测器是指含有2-200个核苷酸的序列,优选,具有2-150个核苷酸,优选,3-100个核苷酸,优选,3-30个核苷酸,优选,4-20个核苷酸,更优选,5-15个核苷酸。优选为单链DNA分子、单链RNA分子或单链DNA-RNA杂交体。
所述的单链核酸检测器两端包括不同的报告基团或标记分子,当其处于初始状态(即未被切割状态时)不呈现报告信号,当该单链核酸检测器被切割后,呈现出可检测的信号,即切割后与切割前表现出可检测的区别。
在一个实施方式中,所述的报告基团或标记分子包括荧光基团和淬灭基团,所述荧光基团选自FAM、FITC、VIC、JOE、TET、CY3、CY5、ROX、Texas Red或LC RED460中的一种或任意几种;所述淬灭基团选自BHQ1、BHQ2、BHQ3、Dabcy1或Tamra中的一种或任意几种。
在一个实施方式中,所述的单链核酸检测器具有连接至5’端第一分子(如FAM或FITC)和连接至3’端的第二分子(如生物素)。所述的含有单链核酸检测器的反应体系与流动条配合用以检测靶核酸(优选,胶体金检测方式)。所述的流动条被设计为具有两条捕获线,在样品接触端(胶体金)设有结合第一分子的抗体(即第一分子抗体),在第一线(control line)处含有结合第一分子抗体的抗体,在第二线(test line)处含有与第二分子结合的第二分子的抗体(即第二分子抗体,如亲和素)。当反应沿着条带流动时,第一分子抗体与第一分子结合携带切割或未切割的寡核苷酸至捕获线,切割的报告子将在第一个捕获线处结合第一分子抗体的抗体,而未切割的报告子将在第二捕获线处结合第二分子抗体。报告基团在各条线的结合将导致强读出/信号(例如颜色)。随着更多的报告子被切割,更多的信号将在第一捕获线处累积,并且在第二线处将出现更少的信号。在某些方面,本发明涉及如本文所述的流动条用于检测核酸的用途。在某些方面,本发明涉及用本文定义的流动条检测核酸的方法,例如(侧)流测试或(侧)流免疫色谱测定。在某些方面,所述单链核酸检测器中的分子可相互替换,或改变分子的位置,只要其报告原理与本发明相同或相近,所改进的方式也均包含在本发明中。
本发明所述的检测方法,可用于待检测靶核酸的定量检测。所述的定量检测指标可以根据报告基团的信号强弱进行定量,如根据荧光基团的发光强度,或根据显色条带的宽度等。
野生型
如本文中所使用的,术语“野生型”具有本领域技术人员通常理解的含义,其表示生物、菌株、基因的典型形式或者当它在自然界存在时区别于突变体或变体形式的特征,其可从自然中的来源分离并且没有被人为有意地修饰。
衍生化
如本文中所使用的,术语“衍生化”是指,对氨基酸、多肽或蛋白的化学修饰,其中一个或多个取代基已与所述氨基酸、多肽或蛋白共价连接。取代基也可称为侧链。
衍生化的蛋白是该蛋白的衍生物,通常,蛋白的衍生化不会不利影响该蛋白的期望活性(例如,与指导RNA结合的活性、核酸内切酶活性、在指导RNA引导下与靶序列特定位点结合并切割的活性),也就是说蛋白的衍生物与蛋白有相同的活性。
衍生化蛋白
又称“蛋白衍生物”,是指蛋白的经修饰形式,例如其中所述蛋白的一个或多个氨基酸可以被缺失、插入、修饰和/或取代。
非天然存在的
如本文中所使用的,术语“非天然存在的”或“工程化的”可互换地使用并且表示人工的参与。当这些术语用于描述核酸分子或多肽时,其表示该核酸分子或多肽至少基本上从它们在自然界中或如发现于自然界中的与其结合的至少另一种组分游离出来。
直系同源物(orthologue,ortholog)
如本文中所使用的,术语“直系同源物(orthologue,ortholog)”具有本领域技术人员通常理解的含义。作为进一步指导,如本文中所述的蛋白质的“直系同源物”是指属于不同物种的蛋白质,该蛋白质执行与作为其直系同源物的蛋白相同或相似的功能。
同一性
如本文中所使用的,术语“同一性”用于指两个多肽之间或两个核酸之间序列的匹配情况。当两个进行比较的序列中的某个位置都被相同的碱基或氨基酸单体亚单元占据时(例如,两个DNA分子的每一个中的某个位置都被腺嘌呤占据,或两个多肽的每一个中的某个位置都被赖氨酸占据),那么各分子在该位置上是同一的。两个序列之间的“百分数同一性”是由这两个序列共有的匹配位置数目除以进行比较的位置数目×100的函数。例如,如果两个序列的10个位置中有6个匹配,那么这两个序列具有60%的同一性。例如,DNA序列CTGACT和CAGGTT共有50%的同一性(总共6个位置中有3个位置匹配)。通常,在将两个序列比对以产生最大同一性时进行比较。这样的比对可通过使用,例如,可通过计算机程序例如Align程序(DNAstar,Inc.)方便地进行的Needleman等人(1970)J.Mol.Biol.48:443-453的方法来实现。还可使用已整合入ALIGN程序(版本2.0)的E.Meyers和W.Miller(Comput.ApplBiosci.,4:11-17(1988))的算法,使用PAM120权重残基表(weight residue table)、12的缺口长度罚分和4的缺口罚分来测定两个氨基酸序列之间的百分数同一性。此外,可使用已整合入GCG软件包(可在www.gcg.com上获得)的GAP程序中的Needleman和Wunsch(J MoIBiol.48:444-453(1970))算法,使用Blossum 62矩阵或PAM250矩阵以及16、14、12、10、8、6或4的缺口权重(gap weight)和1、2、3、4、5或6的长度权重来测定两个氨基酸序列之间的百分数同一性。
载体
术语“载体”是指一种核酸分子,它能够运送与其连接的另一种核酸分子。载体包括但不限于,单链、双链、或部分双链的核酸分子;包括一个或多个自由端、无自由端(例如环状的)的核酸分子;包括DNA、RNA、或两者的核酸分子;以及本领域已知的其他多种多样的多核苷酸。载体可以通过转化,转导或者转染导入宿主细胞,使其携带的遗传物质元件在宿主细胞中获得表达。一种载体可以被引入到宿主细胞中而由此产生转录物、蛋白质、或肽,包括由如本文所述的蛋白、融合蛋白、分离的核酸分子等(例如,CRISPR转录物,如核酸转录物、蛋白质、或酶)。一种载体可以含有多种控制表达的元件,包括但不限于,启动子序列、转录起始序列、增强子序列、选择元件及报告基因。另外,载体还可含有复制起始位点。
一种类型的载体是“质粒”,其是指其中可以例如通过标准分子克隆技术插入另外的DNA片段的环状双链DNA环。
另一种类型的载体是病毒载体,其中病毒衍生的DNA或RNA序列存在于用于包装病毒(例如,逆转录病毒、复制缺陷型逆转录病毒、腺病毒、复制缺陷型腺病毒、以及腺相关病毒)的载体中。病毒载体还包含由用于转染到一种宿主细胞中的病毒携带的多核苷酸。某些载体(例如,具有细菌复制起点的细菌载体和附加型哺乳动物载体)能够在它们被导入的宿主细胞中自主复制。
其他载体(例如,非附加型哺乳动物载体)在引入宿主细胞后整合到该宿主细胞的基因组中,并且由此与该宿主基因组一起复制。而且,某些载体能够指导它们可操作连接的基因的表达。这样的载体在此被称为“表达载体”。
宿主细胞
如本文中所使用的,术语“宿主细胞”是指,可用于导入载体的细胞,其包括但不限于,如大肠杆菌或枯草菌等的原核细胞,如微生物细胞、真菌细胞、动物细胞和植物细胞的真核细胞。
本领域技术人员将理解,表达载体的设计可取决于诸如待转化的宿主细胞的选择、所希望的表达水平等因素。
调控元件
如本文中所使用的,术语“调控元件”旨在包括启动子、增强子、内部核糖体进入位点(IRES)、和其他表达控制元件(例如转录终止信号,如多聚腺苷酸化信号和多聚U序列),其详细描述可参考戈德尔(Goeddel),《基因表达技术:酶学方法》(GENE EXPRESSIONTECHNOLOGY:METHODS IN ENZYMOLOGY)185,学术出版社(Academic Press),圣地亚哥(SanDiego),加利福尼亚州(1990)。在某些情况下,调控元件包括指导一个核苷酸序列在许多类型的宿主细胞中的组成型表达的那些序列以及指导该核苷酸序列只在某些宿主细胞中表达的那些序列(例如,组织特异型调节序列)。组织特异型启动子可主要指导在感兴趣的期望组织中的表达,所述组织例如肌肉、神经元、骨、皮肤、血液、特定的器官(例如肝脏、胰腺)、或特殊的细胞类型(例如淋巴细胞)。在某些情况下,调控元件还可以时序依赖性方式(如以细胞周期依赖性或发育阶段依赖性方式)指导表达,该方式可以是或者可以不是组织或细胞类型特异性的。在某些情况下,术语“调控元件”涵盖的是增强子元件,如WPRE;CMV增强子;在HTLV-I的LTR中的R-U5’片段((Mol.Cell.Biol.,第8(1)卷,第466-472页,1988);SV40增强子;以及在兔β-珠蛋白的外显子2与3之间的内含子序列(Proc.Natl.Acad.Sci.USA.,第78(3)卷,第1527-31页,1981)。
启动子
如本文中所使用的,术语“启动子”具有本领域技术人员公知的含义,其是指一段位于基因的上游能启动下游基因表达的非编码核苷酸序列。组成型(constitutive)启动子是这样的核苷酸序列:当其与编码或者限定基因产物的多核苷酸可操作地相连时,在细胞的大多数或者所有生理条件下,其导致细胞中基因产物的产生。诱导型启动子是这样的核苷酸序列,当可操作地与编码或者限定基因产物的多核苷酸相连时,基本上只有当对应于所述启动子的诱导物在细胞中存在时,其导致所述基因产物在细胞内产生。组织特异性启动子是这样的核苷酸序列:当可操作地与编码或者限定基因产物的多核苷酸相连时,基本上只有当细胞是该启动子对应的组织类型的细胞时,其才导致在细胞中产生基因产物。
NLS
“核定位信号”或“核定位序列”(NLS)是对蛋白质“加标签”以通过核转运导入细胞核的氨基酸序列,即,具有NLS的蛋白质被转运至细胞核。典型地,NLS包含暴露在蛋白质表面的带正电荷的Lys或Arg残基。示例性核定位序列包括但不限于来自以下的NLS:SV40大T抗原,EGL-13,c-Myc以及TUS蛋白。在一些实施例中,该NLS包含PKKKRKV序列。在一些实施例中,该NLS包含AVKRPAATKKAGQAKKKKLD序列。在一些实施例中,该NLS包含PAAKRVKLD序列。在一些实施例中,该NLS包含MSRRRKANPTKLSENAKKLAKEVEN序列。在一些实施例中,该NLS包含KLKIKRPVK序列。其他核定位序列包括但不限于hnRNP A1的酸性M9结构域、酵母转录抑制子Matα2中的序列KIPIK和PY-NLS。
可操作地连接
如本文中所使用的,术语“可操作地连接”旨在表示感兴趣的核苷酸序列以一种允许该核苷酸序列的表达的方式被连接至该一种或多种调控元件(例如,处于一种体外转录/翻译系统中或当该载体被引入到宿主细胞中时,处于该宿主细胞中)。
互补性
如本文中所使用的,术语“互补性”是指核酸与另一个核酸序列借助于传统的沃森-克里克或其他非传统类型形成一个或多个氢键的能力。互补百分比表示一个核酸分子中可与一个第二核酸序列形成氢键(例如,沃森-克里克碱基配对)的残基的百分比(例如,10个之中有5、6、7、8、9、10个即为50%、60%、70%、80%、90%、和100%互补)。“完全互补”表示一个核酸序列的所有连续残基与一个第二核酸序列中的相同数目的连续残基形成氢键。如本文使用的“基本上互补”是指在一个具有8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、30、35、40、45、50个或更多个核苷酸的区域上至少为60%、65%、70%、75%、80%、85%、90%、95%、97%、98%、99%、或100%的互补程度,或者是指在严格条件下杂交的两个核酸。
严格条件
如本文中所使用的,对于杂交的“严格条件”是指与靶序列具有互补性的一个核酸主要地与该靶序列杂交并且基本上不杂交到非靶序列上的条件。严格条件通常是序列依赖性的,并且取决于许多因素而变化。一般而言,该序列越长,则该序列特异性地杂交到其靶序列上的温度就越高。
杂交
术语“杂交”或“互补的”或“基本上互补的”是指核酸(例如RNA、DNA)包含使其能够非共价结合的核苷酸序列,即以序列特异性,反平行的方式(即核酸特异性结合互补核酸)与另一核酸形成碱基对和/或G/U碱基对,“退火”或“杂交”。
杂交需要两个核酸含有互补序列,尽管碱基之间可能存在错配。两个核酸之间杂交的合适条件取决于核酸的长度和互补程度,这是本领域公知的变量。典型地,可杂交核酸的长度为8个核苷酸或更多(例如,10个核苷酸或更多,12个核苷酸或更多,15个核苷酸或更多,20个核苷酸或更多,22个核苷酸或更多,25个核苷酸或更多,或30个核苷酸或更多)。
应当理解,多核苷酸的序列不需要与其靶核酸的序列100%互补以特异性杂交。多核苷酸可包含60%或更高,65%或更高,70%或更高,75%或更高,80%或更高,85%或更高,90%或更高,95%或更高,98%或更高,99%或更高,99.5%或更高,或与其杂交的靶核酸序列中的靶区域的序列互补性为100%。
靶序列与gRNA的杂交代表靶序列和gRNA的核酸序列至少60%、70%、75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%的可以杂交,形成复合物;或者代表靶序列和gRNA的核酸序列至少有12个、15个、16个、17个、18个、19个、20个、21个、22个或更多个碱基可以互补配对,杂交形成复合物。
表达
如本文中所使用的,术语“表达”是指,藉此从DNA模板转录成多核苷酸(如转录成mRNA或其他RNA转录物)的过程和/或转录的mRNA随后藉此翻译成肽、多肽或蛋白质的过程。转录物和编码的多肽可以总称为“基因产物”。如果多核苷酸来源于基因组DNA,表达可以包括真核细胞中mRNA的剪接。
接头
如本文中所使用的,术语“接头”是指,由多个氨基酸残基通过肽键连接形成的线性多肽。本发明的接头可以为人工合成的氨基酸序列,或天然存在的多肽序列,例如具有铰链区功能的多肽。此类接头多肽是本领域众所周知的(参见例如,Holliger,P.等人(1993)Proc.Natl.Acad.Sci.USA 90:6444-6448;Poljak,R.J.等人(1994)Structure 2:1121-1123)。
治疗
如本文中所使用的,术语“治疗”是指,治疗或治愈病症,延缓病症的症状的发作,和/或延缓病症的发展。
受试者
如本文中所使用的,术语“受试者”包括但不限于各种动物、植物和微生物。
动物
例如哺乳动物,例如牛科动物、马科动物、羊科动物、猪科动物、犬科动物、猫科动物、兔科动物、啮齿类动物(例如,小鼠或大鼠)、非人灵长类动物(例如,猕猴或食蟹猴)或人。在某些实施方式中,所述受试者(例如人)患有病症(例如,疾病相关基因缺陷所导致的病症)。
植物
术语“植物”应理解为能够进行光合作用的任何分化的多细胞生物,在包括处于任何成熟或发育阶段的作物植物,特别是单子叶或双子叶植物,蔬菜作物,包括洋蓟、球茎甘蓝、芝麻菜、韭葱、芦笋、莴苣(例如,结球莴苣、叶莴苣、长叶莴苣)、小白菜(bok choy)、黄肉芋、瓜类(例如,甜瓜、西瓜、克伦肖瓜(crenshaw)、白兰瓜、罗马甜瓜)、油菜作物(例如,球芽甘蓝、卷心菜、花椰菜、西兰花、羽衣甘蓝、无头甘蓝、大白菜、小白菜)、刺菜蓟、胡萝卜、洋白菜(napa)、秋葵、洋葱、芹菜、欧芹、鹰嘴豆、欧洲防风草、菊苣、胡椒、马铃薯、葫芦(例如,西葫芦、黄瓜、小西葫芦、倭瓜、南瓜)、萝卜、干球洋葱、芜菁甘蓝、紫茄子(也称为茄子)、婆罗门参、苣菜、青葱、苦苣、大蒜、菠菜、绿洋葱、倭瓜、绿叶菜类(greens)、甜菜(糖甜菜和饲料甜菜)、甘薯、唐莴苣、山葵、西红柿、芜菁、以及香辛料;水果和/或蔓生作物,如苹果、杏、樱桃、油桃、桃、梨、李子、西梅、樱桃、榅桲、杏仁、栗子、榛子、山核桃、开心果、胡桃、柑橘、蓝莓、博伊增莓(boysenberry)、小红莓、穗醋栗、罗甘莓、树莓、草莓、黑莓、葡萄、鳄梨、香蕉、猕猴桃、柿子、石榴、菠萝、热带水果、梨果、瓜、芒果、木瓜、以及荔枝;大田作物,如三叶草、苜蓿、月见草、白芒花、玉米/玉蜀黍(饲料玉米、甜玉米、爆米花)、啤酒花、荷荷芭、花生、稻、红花、小粒谷类作物(大麦、燕麦、黑麦、小麦等)、高粱、烟草、木棉、豆科植物(豆类、小扁豆、豌豆、大豆)、含油植物(油菜、芥菜、罂粟、橄榄、向日葵、椰子、蓖麻油植物、可可豆、落花生)、拟南芥属、纤维植物(棉花、亚麻、黄麻)、樟科(肉桂、莰酮)、或一种植物如咖啡、甘蔗、茶、以及天然橡胶植物;和/或花坛植物,如开花植物、仙人掌、肉质植物和/或观赏植物,以及树如森林(阔叶树和常绿树,如针叶树)、果树、观赏树、以及结坚果的树(nut-bearingtree)、以及灌木和其他苗木。
发明的有益效果
本发明通过突变提高了Cas12j19蛋白的活性,具有广泛的应用前景。
下面将结合附图和实施例对本发明的实施方案进行详细描述,但是本领域技术人员将理解,下列附图和实施例仅用于说明本发明,而不是对本发明的范围的限定。根据附图和优选实施方案的下列详细描述,本发明的各种目的和有利方面对于本领域技术人员来说将变得显然。
附图说明
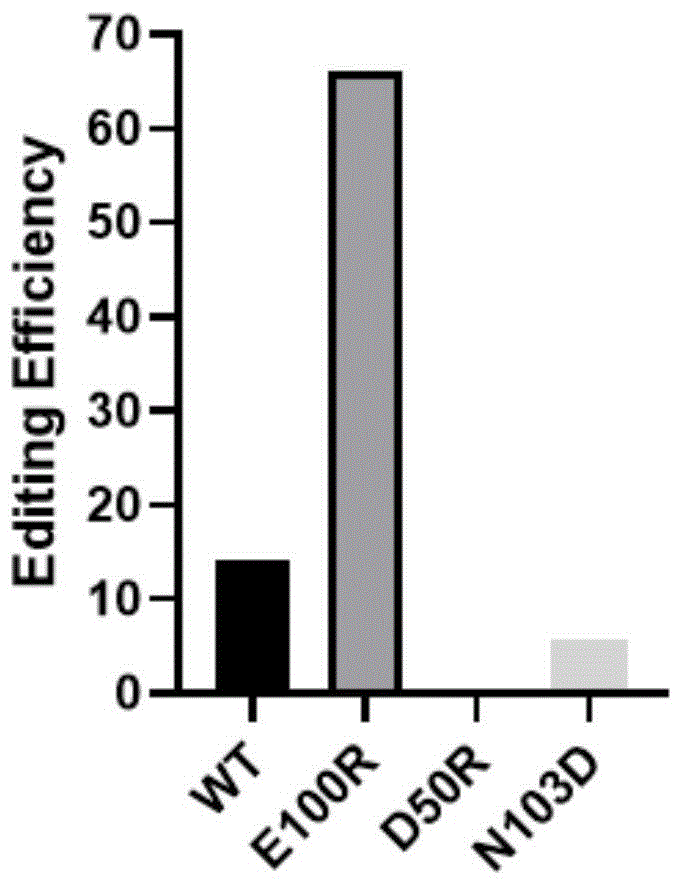
图1.单位点氨基酸突变Cas蛋白编辑效率的验证结果。
图2.突变后的E100R蛋白与野生型Cas12j19在大豆中编辑效率的验证结果。横坐标代表不同的靶点位置,纵坐标代表编辑效率。
图3.单位点氨基酸饱和突变的Cas蛋白编辑效率的验证结果。
具体实施方式
以下实施例仅用于描述本发明,而非限定本发明。除非特别指明,否则基本上按照本领域内熟知的以及在各种参考文献中描述的常规方法进行实施例中描述的实验和方法。例如,本发明中所使用的免疫学、生物化学、化学、分子生物学、微生物学、细胞生物学、基因组学和重组DNA等常规技术,可参见萨姆布鲁克(Sambrook)、弗里奇(Fritsch)和马尼亚蒂斯(Maniatis),《分子克隆:实验室手册》(MOLECULAR CLONING:A LABORATORY MANUAL),第2次编辑(1989);《当代分子生物学实验手册》(CURRENT PROTOCOLS IN MOLECULAR BIOLOGY)(F.M.奥苏贝尔(F.M.Ausubel)等人编辑,(1987));《酶学方法》(METHODS IN ENZYMOLOGY)系列(学术出版公司):《PCR 2:实用方法》(PCR 2:A PRACTICAL APPROACH)(M.J.麦克弗森(M.J.MacPherson)、B.D.黑姆斯(B.D.Hames)和G.R.泰勒(G.R.Taylor)编辑(1995))、哈洛(Harlow)和拉内(Lane)编辑(1988)《抗体:实验室手册》(ANTIBODIES,ALABORATORYMANUAL),以及《动物细胞培养》(ANIMAL CELL CULTURE)(R.I.弗雷谢尼(R.I.Freshney)编辑(1987))。
另外,实施例中未注明具体条件者,按照常规条件或制造商建议的条件进行。所用试剂或仪器未注明生产厂商者,均为可以通过市购获得的常规产品。本领域技术人员知晓,实施例以举例方式描述本发明,且不意欲限制本发明所要求保护的范围。本文中提及的全部公开案和其他参考资料以其全文通过引用合并入本文。
实施例1.Cas突变蛋白的获得
针对已知的Cas蛋白(CN111770992B中的Cas12j.19,本实施例中,将其称之为Cas12i19),申请人通过生物信息学预测可能影响其生物学功能的关键氨基酸位点,并将氨基酸位点进行突变,得到了编辑活性提高的Cas突变蛋白。具体的,将Cas12j19编码序列经过密码子优化并合成,野生型Cas12j19的氨基酸序列如SEQ ID No.1所示,其核酸序列如SEQ ID No.2所示,通过生物信息学方法对潜在的Cas12j19与目标序列相互结合的氨基酸进行定点突变。
SEQ ID No.1:
MPSYKSSRVLVRDVPEELVDHYERSHRVAAFFMRLLLAMRREPYSLRMRDGTEREVDLDETDDFLRSAGCEEPDAVSDDLRSFALAVLHQDNPKKRAFLESENCVSILCLEKSASGTRYYKRPGYQLLKKAIEEEWGWDKFEASLLDERTGEVAEKFAALSMEDWRRFFAARDPDDLGRELLKTDTREGMAAALRLRERGVFPVSVPEHLDLDSLKAAMASAAERLKSWLACNQRAVDEKSELRKRFEEALDGVDPEKYALFEKFAAELQQADYNVTKKLVLAVSAKFPATEPSEFKRGVEILKEDGYKPLWEDFRELGFVYLAERKWERRRGGAAVTLCDADDSPIKVRFGLTGRGRKFVLSAAGSRFLITVKLPCGDVGLTAVPSRYFWNPSVGRTTSNSFRIEFTKRTTENRRYVGEVKEIGLVRQRGRYYFFIDYNFDPEEVSDETKVGRAFFRAPLNESRPKPKDKLTVMGIDLGINPAFAFAVCTLGECQDGIRSPVAKMEDVSFDSTGLRGGIGSQKLHREMHNLSDRCFYGARYIRLSKKLRDRGALNDIEARLLEEKYIPGFRIVHIEDADERRRTVGRTVKEIKQEYKRIRHQFYLRYHTSKRDRTELISAEYFRMLFLVKNLRNLLKSWNRYHWTTGDRERRGGNPDELKSYVRYYNNLRMDTLKKLTCAIVRTAKEHGATLVAMENIQRVDRDDEVKRRKENSLLSLWAPGMVLERVEQELKNEGILAWEVDPRHTSQTSCITDEFGYRSLVAKDTFYFEQDRKIHRIDADVNAAINIARRFLTRYRSLTQLWASLLDDGRYLVNVTRQHERAYLELQTGAPAATLNPTAEASYELVGLSPEEEELAQTRIKRKKREPFYRHEGVWLTREKHREQVHELRNQVLALGNAKIPEIRT
SEQ ID No.2:
atgcccagctacaagagcagcagagtgctggtgagGgacgtgccagaggagctggtggaccactacgaaagaagccacagggtggccgccttcttcatgagactgctgctggccatgagaagagagccctacagcctgagaatgagGgacggaaccgagagagaggtggacctggacgaaaccgacgacttcctgagaagcgccggatgcgaggagccagacgccgtgtctgacgacctgagaagcttcgccctggccgtgctgcaccaggacaacccaaagaagagagcctttctggagagcgagaactgcgtgtcaatcctgtgtctggagaaaagcgcctccggcaccagatactacaaaagacccggctaccagctgctgaagaaggccatcgaggaggagtggggatgggacaagttcgaggcctctctgctggacgagagaacaggagaagtggccgagaagttcgccgccctgagcatggaagactggagaagattcttcgccgccagagaccccgacgatctgggaagagagctgctgaagaccgacaccagagaaggcatggccgccgccctgagactgagagaaagaggagtgttccccgtgagcgtgcccgagcacctggacctggacagcctgaaggccgccatggccagcgccgctgaaagactgaagtcatgg ctggcctgtaaccagcgcgccgtggacgagaagagcgaactgagaaagagattcgaggaggccctggacggagtggaccctgaaaagtatgccctgtttgagaagttcgctgccgagctgcagcaggccgactacaacgtgaccaagaaactggtgctggccgtgagcgccaagttccccgctaccgagcctagcgagtttaagagaggagtggagatcctgaaggaagatggctacaagcccctgtgggaggactttagagagctgggctttgtgtatctggccgagagaaagtgggaaagaagaagaggcggagccgccgtgaccctgtgtgacgctgacgacagccctatcaaggtgagatttggactgactggcagaggcagaaagtttgtgctgtccgccgccgggagcagattcctgatcacagtgaagctgccctgcggcgatgtgggactgaccgccgtgcccagcaggtacttttggaacccctcagtgggcagaaccacctccaactcttttagaattgagttcaccaagcggaccaccgagaatcgcaggtacgtgggcgaggtgaaagagattggcctggtgaggcagagaggcagatactattttttcatcgactacaacttcgacccagaggaggtgagcgacgagaccaaggtgggcagagccttcttcagagcccccctgaacgagtcaagacctaagccaaaggacaagctgaccgtgatggggattgacctgggcattaacccagcctttgcctttgccgtgtgcaccctgggcgaatgccaggacggaatccggagccccgtggccaaaatggaggacgtgagcttcgactctaccggactgagaggcggaatcggcagccagaagctgcacagagagatgcacaacctgagcgacagatgcttttacggcgccagatacattagactgagcaagaagctgagggacagaggagctctgaacgatatcgaggctagactgctggaagagaagtacatccccggctttagaattgtgcacattgaggacgccgacgagagaagaagaaccgtgggaagaacagtgaaagaaatcaaacaggagtacaaaagaatcagacaccagttctacctgaggtaccacaccagcaagagggacagaacagagctgattagcgccgagtacttcagaatgctgttcctggtgaagaacctgagaaacctgctgaagagctggaacagataccactggacaaccggcgacagagaaagaagaggagggaacccagacgagctgaagagctatgtgagatactataacaatctgagaatggacaccctgaagaaactgacctgcgccatcgtgaggaccgccaaggaacacggagccaccctggtggccatggagaacatccagagagtggacagGgacgacgaggtgaaaagaagaaaggaaaatagcctgctgagcctgtgggcccccggaatggtgctggagagagtggagcaggagctgaagaacgagggaatcctggcctgggaggtggacccaagacatacaagtcagacaagctgcatcaccgacgaatttggctacagaagcctggtggccaaggacaccttctactttgaacaggacagaaaaatccacagaatcgacgccgacgtgaacgccgccatcaacatcgcccgccgcttcctgacccggtacaggagcctgacccagctgtgggccagcctgctggacgacggcagatacctggtgaacgtgaccagacagcacgagagagcctacctggaactgcagaccggcgcccccgccgctacactgaaccctaccgccgaagccagctacgaactggtgggactgagccccgaagaagaagagctggcccagaccagaatcaaacgcaaaaagagagaaccattctacagacacgaaggcgtgtggctgacaagagagaagcacagagagcaggtgcacgaactgagaaaccaggtgctggccctgggcaacgccaagatccccgaaatcagaacc
通过基于PCR的定点诱变产生Cas蛋白的变体。具体的方法是以突变的位点为中心将Cas12j19蛋白的DNA序列设计分成两部分,设计两对引物分别扩增这两部分DNA序列,同时引物上引入需要突变的序列,最后通过Gibson克隆的方式将两个片段装载到pcDNA3.3-eGFP载体上。突变体的组合则通过将Cas12j19蛋白的DNA拆分成多段,使用PCR、Gibsonclone实现构建。片段扩增试剂盒:TransStart FastPfu DNA Polymerase(含2.5mMdNTPs),具体实验流程详见说明书。胶回收试剂盒:
基于上述氨基酸突变位点,分别获得了Cas12j19的野生型蛋白(WT),以及上述氨基酸单个位点发生突变的蛋白(以突变类型命名):D50R、E100R和N103D,其相对于SEQ IDNo.1所示的序列,自N端起第50位氨基酸突变为R,自N端起第100位氨基酸突变为R,自N端起第103位氨基酸突变为D。
实施例2.Cas突变蛋白的编辑活性的验证
采用实施例1获得的不同的Cas蛋白在动物细胞中验证其基因编辑的活性,针对中国仓鼠卵巢细胞(CHO)FUT8基因设计靶点,FUT8-3:ATGGAGGCTGTCTACAATGGGGA,斜体部分为PAM序列,其余区域为靶向区。载体pcDNA3.3经改造后带有EGFP荧光蛋白及PuroR抗性基因。经酶切位点XbaI和PstI插入SV40 NLS-Cas-XX融合蛋白;经酶切位点Mfe1插入U6启动子及gRNA序列。CMV启动子启动融合蛋白SV40 NLS-Ca s-XX-NLS-GFP表达。蛋白Cas-XX-NLS与蛋白GFP用连接肽T2A进行连接。启动子EF-1α启动嘌呤霉素抗性基因表达。铺板:CHO细胞融合度至70-80%进行铺板,12孔板中接种细胞数为8*10^4细胞/孔。转染:铺板24h进行转染,100μl opti-MEM中加入6.25μlHieff Trans
提DNA、PCR扩增编辑区附近、送hiTOM测序:细胞经胰酶消化处理后进行收集,经细胞/组织基因组DNA提取试剂盒(百泰克)进行基因组DNA提取。对基因组DNA扩增靶点附近区域。PCR产物进行hiTOM测序。测序数据分析,统计靶点位置上游15nt、下游10nt范围内的序列种类及比例,统计序列中SNV频率大于/等于1%或非SNV的突变频率大于/等于0.06%的序列,得到Cas-XX蛋白对靶点位置的编辑效率。CHO细胞FUT8基因靶点序列:FUT8-Cas-XX-g3:ATGGAGGCTGTCTACAATGGGGA,斜体部分为PAM序列,其余区域为靶向区。gRNA序列为:GUGCUGCUGUCUCCCAGACGGGAGGCAGAACUGCACGAGGCUGUCUACAAUGGGGA,加粗区域为靶向区,其他区域为DR(同向重复序列)区。
图1示出了野生型Cas12j19蛋白(WT,SEQ ID No.1所示)以及单个氨基酸位点突变的突变蛋白的编辑活性。如图1,与WT相比,E100R氨基酸位点的突变能够显著提高Cas12j19蛋白的编辑效率,而D50R和N103D的突变则会降低Cas12j19蛋白的编辑效率。
实施例3.Cas突变蛋白在大豆中编辑活性的验证
对大豆基因组中FAD基因以及BADH基因分别设计多个靶点,靶点信息如表2所示,将设计的靶点分别构入含有实施例1中的Cas突变蛋白E100R的载体中,为验证载体的编辑效率,将构建完成的载体进行大豆幼苗的发根农杆菌瞬时转化。
(1)大豆种子萌发:取营养土及蛭石按2:1的比例混匀,平铺在穴盘上,将大豆种子以0.5cm的深度点播到穴盘中,浇适量水准备萌发。
(2)菌板及菌液的准备:取500~600μl发根农杆菌K599甘油菌液涂板,同时取50μl菌液加入含有相应抗生素的TY培养液,28℃过夜培养。
(3)发根农杆菌侵染大豆:用刀片在生长7-14天的大豆幼苗子叶的下胚轴1cm处切一倾斜的伤口,伤口处蘸取接种发根农杆菌。然后将接种的幼苗的下胚轴直接种植在潮湿的无菌蛭石培养盒中,每棵浇10ml K599侵染悬浮液,随后在16天内保持高湿度,以促进大豆毛状根生长。
毛状根长出后,利用TPS法提取大豆毛状根的DNA,分别用检测引物扩增相应片段,引物信息见表3,扩增产物经sanger法进行测序,根据测序结果确定编辑效率。
表2.靶点的序列信息
表3.检测引物的序列信息
结果如图2所示,检测到野生型Cas12j19与突变后的E100R在不同靶点处的编辑效率明显不同,突变后的E100R蛋白在靶点BADH2-6,FAD-1A-1,BADH1-5,FAD-1B-2,FAD-1B-3表现出显著的编辑活性,野生型Cas12j19在各靶点处均未检测到编辑活性;突变后的E100R蛋白与野生型Cas12j19相比在各靶点的编辑效率均显著提高。
实施例4.对野生型Cas12j19第100位进行饱和突变并验证其编辑活性
以野生型Cas12j19蛋白为模板,参考实施例1中获得突变蛋白的方法,设计相应的点突引物,通过基于PCR的定点诱变产生Cas蛋白的变体,获得第100位突变为多种氨基酸类型(A,V,G,L,D,F,W,Y,N,S,Q,K,M,T,C,P,H,或I)的Cas蛋白变体。
采用实施例2中验证不同Cas蛋白在动物细胞中编辑活性的方法,验证上述各Cas蛋白变体在动物细胞的活性。结果如图3所示,对野生型Cas蛋白第100位氨基酸位点进行饱和突变,突变后的氨基酸类型不同对于动物细胞的编辑活性也不相同,其中第100位突变为K,Y,M,F,W,S,H,V,I,N时,Cas蛋白变体的编辑效率显著高于野生型Cas12j19,氨基酸突变为C或L后与野生型Cas12j19活性基本一致,氨基酸突变为Q,G,T,D,P后编辑活性低于野生型Cas12j19,氨基酸类型突变为A时,Cas蛋白变体失去编辑活性。
尽管本发明的具体实施方式已经得到详细的描述,但本领域技术人员将理解:根据已经公布的所有教导,可以对细节进行各种修改和变动,并且这些改变均在本发明的保护范围之内。本发明的全部分为由所附权利要求及其任何等同物给出。