基于Spark的单脉冲搜索方法及其并行化研究方法
文献发布时间:2023-06-19 19:30:30
技术领域
本发明涉及单脉冲搜索技术领域,具体为基于Spark的单脉冲搜索方法及其并行化研究方法。
背景技术
脉冲星是高度磁化的旋转致密星。1967年,Hewish等人发现了第一颗射电脉冲星PSRB1919+21[1],1974年Hewish因在脉冲星发现等方面做出的贡献获得诺贝尔物理学奖。脉冲星具有大质量、小半径、超强引力、超强磁场、伴随恒星演化和超新星爆发过程、自传周期高度稳定等极端物理特征,这使得脉冲星在研究引力场、磁层粒子加速机制、高能辐射、射电辐射、超新星爆发理论以及航天器导航等领域具有极其重要的意义。
早期的脉冲星搜索方法是通过周期搜索实现,而与第一颗脉冲星同年发现的蟹云脉冲星一开始并未表现出规律的自转特性,是通过捕获到的巨脉冲探测到的。因此,对于非周期信号的搜索也日益成为射电天文界的重点。1999年,受发现蟹云脉冲星的启发,DavidJ.Nice利用阿雷西博望远镜的数据借助单脉冲搜索发现了新的脉冲星PSRJ1918+08[2]。2004年与2007年,DuncanLorimer等人通过单脉冲搜索技术分别发现了旋转射电暂现源(RotatingRadioTransients,RRAT)和快速射电暴(DastRadioBursts,FRB)[3][4]。
随着硬件和软件上的突破,单个巡天项目采集的观测数据总量再不断增大。早期的观测数据总量通常介于GB与TB之间,2021年,贵州500米口径射电望远镜(FAST)正式运行,2017年7月~2018年5月,500m口径球面射电望远镜多科学目标同时扫描巡天(TheCommensalRadioAstronomyFASTSurvey,CRAFTS)观测数据已达数PB,预计500m口径球面射电望远镜在射电脉冲星领域采集的数据总量在10~100PB,巡天数据已迈入PB时代。[5][6]如此“天文级”的数据体量,对数据的分析和处理提出了巨大的挑战。传统的基于单机和串行模式的处理程序已无法满足对于时效性的要求的问题,为此,我们提出一种实用性更高的基于Spark的单脉冲搜索方法及其并行化研究方法。
发明内容
本发明的目的在于提供基于Spark的单脉冲搜索方法及其并行化研究方法,解决了现有的问题。
为实现上述目的,本发明提供如下技术方案:基于Spark的单脉冲搜索方法及其并行化研究方法,包括以下步骤:
步骤S1、消色散:去除由色散效应引起的延迟响应;
步骤S2、匹配滤波:搜索每个消色散时间序列或“DM信道”,查找幅度高于某些S/N阈值的脉冲,阈值根据可接受的假阳性样本数量来选择;
步骤S3、候选体诊断:对判断为单脉冲候选体的数据进行人工检查。
优选的,所述步骤S2中具体的包括以下步骤:
对于长时间的观测,强脉冲的检测水平会受到抑制,可通过分段线性拟合作为平滑方法对信号进行去趋势处理以达到对最佳检测的有效近似;
在脉冲展宽参数未知的情况下
其中σ为时间序列均方根噪声,W
其中W
基于Spark的单脉冲搜索并行化研究方法,包括以下步骤:
步骤(1)、PRESTO搜索单脉冲信号使用single_pulse_search.py程序;
步骤(2)、单脉冲搜索并行化实现的系统架构,主要分为三层,最上层为数据源层,使用HDFS文件系统,用来存储消色散后生成的dat文件;
中间层为任务调度层,主要完成对一组计算任务的分配,通过将不同DM信道的搜索任务分配到不同的计算节点以实现DM信道并行搜索;
最下层为数据处理层,主要完成单脉冲搜索数据处理任务。
与现有技术相比,本发明的有益效果如下:
本发明分析了Spark相比于主流分布式架构的优势,对现有脉冲星搜索程序中的单脉冲搜索模块,完成了基于Spark的并行优化,构建了分布式集群,同时结合批处理应用场景,基于负载均衡的理念设计了面向分布式集群的任务分配算法;通过实验对系统性能进行评估,结果表明本系统在大规模数据处理应用场景具有显著优势,为后续运用到实际环境中提供有效的数据支撑。
本发明对比原搜索程序加速效果显著,并且加速效果会随着计算数据量的增大而愈发突出,并且系统扩展性强,能够兼容不同性能,不同架构的计算节点,充分利用已有资源实现分布式并行搜索,适用于大规模的单脉冲搜索场景。同时,对后续将单脉冲搜索中去干扰和消色散部分与搜索部分进行整合具有重要参考意义。
附图说明
图1为本发明的single_pulse_search.py搜索流程示意图;
图2为本发明单脉冲搜索分布式处理模型设计示意图;
图3为本发明任务分配算法流程示意图;
图4为本发明线程数量对加速效果影响示意图;
图5为本发明计算数据大小对加速效果影响示意图;
图6为本发明集群节点数量对加速效果影响示意图;
图7为本发明任务分配算法效果对比示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。
基于Spark的单脉冲搜索方法及其并行化研究方法,包括:
步骤S1、消色散:去除由色散效应引起的延迟响应;
步骤S2、匹配滤波:搜索每个消色散时间序列或“DM信道”,查找幅度高于某些S/N阈值的脉冲,阈值根据可接受的假阳性样本数量来选择;
其中,对于长时间的观测,强脉冲的检测水平会受到抑制,可通过分段线性拟合作为平滑方法对信号进行去趋势处理以达到对最佳检测的有效近似;
在脉冲展宽参数未知的情况下
其中σ为时间序列均方根噪声,W
其中W
步骤S3、候选体诊断:对判断为单脉冲候选体的数据进行人工检查。
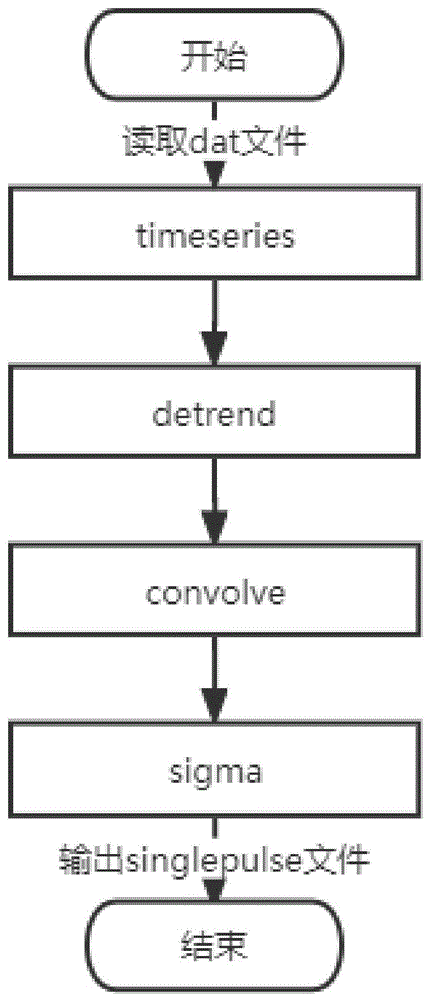
如图1所示,基于Spark的单脉冲搜索并行化研究方法,包括以下步骤:
步骤(1)、PRESTO搜索单脉冲信号使用single_pulse_search.py程序;
首先读取消色散后生成的dat文件,之后对读取到的时间序列进行去趋势,接着使用不同宽度的窗函数与时间序列做卷积运算并计算sigma值(信噪比),然后将低于所选择的阈值的信号过滤,最后记录筛选后的候选体并输出singlepulse文件;
其中,对于消色散后得到的dat文件,不同的DM值对应不同的dat时间序列文件,而单脉冲搜索需要在每个不同的DM信道上单独进行,因此不同的DM信道之间可以并行搜索,而对时间序列进行平滑操作时,需要对整体数据进行分段线性拟合,不同的数据段之间可以并行进行,之后再将平滑后的数据段合并进行后续计算,同时平滑处理模块也是搜索程序耗时,因此适合并行化;
步骤(2)、单脉冲搜索并行化实现的系统架构(图2),主要分为三层,最上层为数据源层,使用HDFS文件系统,用来存储消色散后生成的dat文件;
中间层为任务调度层,主要完成对一组计算任务(每个DM信道对应一个子任务)的分配,通过将不同DM信道的搜索任务分配到不同的计算节点以实现DM信道并行搜索;由于Spark计算模型需要由Driver容器驱动任务,再将计算任务分配到Executor容器中执行,而单脉冲搜索程序算法需要先由Driver读取dat数据文件,此时若Driver与Executor不在同一节点中,就会产生巨大的数据IO开销降低搜索效率;因此本文选择在数据源层与数据处理层之间加入任务调度层,将一个DM信道的搜索严格限制在一台节点上完成以提高搜索效率,同时,考虑到不同节点的计算性能差异,需要避免因某一节点计算时间过长而导致的集群总计算时间的延长,通过动态分配实现负载均衡;任务调度系统使用YarnAPI开发,算法流程如图3,为每一台计算节点分配一个任务队列并对各节点作业队列实时监控,根据节点性能设置合适的阈值,当某一节点任务队列中的任务数量小于其性能阈值时为其分配新的任务;
最下层为数据处理层,主要完成单脉冲搜索数据处理任务;Spark集群的Master节点在接收到任务调度层传来的参数后,将计算任务分配到指定计算节点,计算节点接受到任务请求后,根据请求参数从HDFS中读取对应的DM信道的dat文件进行搜索;搜索过程中,每个DM信道会得到一个Driver驱动,将读取到的时间序列生成RDD,使用Spark的map算子将RDD中的数据块映射到多个Executor中执行去趋势操作,实现去趋势模块多线程并行化执行,之后再通过collect算子将平滑后的时间序列收集到Driver容器中,合并后在Driver完成后续计算。
实验与结果分析
由于分布式计算受到多种因素制约,实验分别从线程数量、节点数量和数据文件大小三个维度对本文系统的性能进行了测试;实验环境为Ubuntu18.04.6,Hadoop3.2.3,Spark3.1.3。实验使用节点硬件配置参数见表1,其中,选择一台配置了AMD芯片,32G内存的节点作为系统管理节点,其余作为计算节点;实验使用500m口径球面射电望远镜CRAFTS巡天项目的观测文件,参数见表2。
表1实验节点配置参数
表2实验文件参数
首先分别测试了X86架构下和ARMv8-A架构下使用本系统设置不同线程数量对系统性能的影响,测试选用5.fits文件,分别使用不同架构的同一台计算节点,在DM为8.10的信道中进行搜索,记录使用Spark程序设置不同线程数时程序运行的耗时分布,并与PRESTO串行计算搜索程序对比,测试结果如图4,其中presto表示原程序运行时间,spark_local表示Spark程序单机模式运行时间,spark_on_yarn表示使用yarn调度Spark程序单机运行时间;结果显示,无论是在X86架构还是ARMv8-A架构下,当线程数设置为6时,加速效果显著提升,随后继续增大线程数加速效果仍会有微小提升;其中,对于X86架构,在spark_local模式下加速比最高可达1.83,在spark_on_yarn模式下最高可达1.27;而对于ARMv8-A架构,在spark_local模式下加速比最高可达1.86,在spark_on_yarn模式下加速比最高可达1.46。程序并行化后的加速比理论上应接近我们所开启的线程数,然而实际测试结果却有一定差距,通过分析程序运行过程发现其原因是目前的数据文件相对较小,数据计算耗时在整体程序耗时中占比不够大,故不能完全体现本系统优势,因此我们接下来对数据文件大小对系统的加速效果影响进行测试。
对于数据文件大小对系统性能的影响测试,实验选用不同大小的漂移扫描数据消色散后产生的多组dat数据文件(每组计算任务包含多个不同DM信道的子计算任务),分别对使用本文系统单机多线程搜索和集群多节点并行搜索耗时进行测试,测试环境为X86架构,集群共使用6台计算节点,得到系统处理不同大小计算任务的时间分布,并与PRESTO串行计算搜索程序作对比,如图5所示,其中,Spark单机多线程测试节点与PRESTO串行程序测试为同一计算节点,同时根据上文实验结论,为了实现资源利用最大化,线程数选择设置为6;结果表明,本系统在处理较大的数据文件(观测时间长)时具有较大优势,随着数据文件的增大,加速效果显著提升,在处理8.34G大小的数据任务时,使用Spark单机多线程加速比约为1.90,使用集群加速比约为5.83。
为了测试节点数量的增加对系统加速效果的影响,测试选用X86架构的四台相同性能的节点和两台性能较优的节点对5.fits进行搜索测试,搜索范围为DM7.50至DM9.40,步长为0.10,任务大小共计8.34G测试结果如图6;测试环境为X86架构,其中前四台节点计算性能相同(内存16G),后两台节点计算性能较优(内存32G);结果显示,增加相同计算性能的节点时,由于集群管理消耗增大,会产生一定的性能损失,但结合上文实验,随着计算任务的增大,集群整体性能仍几乎呈线性增长;而加入计算性能较优的节点时,集群整体性能会有明显高于加入相同计算节点时的提升幅度,表明本文系统对不同性能的计算节点具有良好的兼容性,能充分利用集群中不同节点的性能。
最后测试了批处理场景下,使用本文提出的任务分配算法对于系统性能的影响;实验使用X86架构的三台计算节点,其中两台节点计算性能相同(内存16G),一台节点计算性能较优(内存32G);测试使用数据同上,结果如图7,其中average表示将任务平均分配到各计算节点,balance为本文提出的分配算法;结果显示,对于批处理应用场景,使用本文提出的任务分配算法时,能够更合理的利用集群资源,对系统性能提升显著。
[1]高清鹏,李春晓,李荣旺,等.鹊桥卫星激光测距时间窗口及测距成功概率分析[J].天文研究与技术,2019,16(4):422-430.
GAOQingpeng,LI Chunxiao,LI Rongwang,etal.Magpiebridgesatellitelaserrangingtimewindowand
distance probability analysis[J].Astronomical Research&
Technology,2019,16(4):422-430.
[2]MORINA.Simulationofinforaredimagingseekingmissiles[C]//ProceedingsofSPIE,2001,4365:46-57.
张辉,谢晓尧,李菂,刘志杰,王培,于徐红,游善平,许余云,姜家涛.一种面向FASTPB量级脉冲星数据处理加速方法及系统[J].天文研究与技术,2021,18(01):129-137.DOI:10.14005/j.cnki.issn1672-7673.20200628.001.
潘之辰,钱磊,岳友岭.脉冲星搜索技术及FAST望远镜脉冲星搜索展望[J].天文研究与技术,2017,14(01):8-16.DOI:10.14005/j.cnki.issn1672-7673.20160518.002.
熊聪聪,田祖宸,赵青,冯阔,崔辰州.基于Spark的大规模天文数据天区覆盖生成算法[J].天津科技大学学报,2018,33(05):63-67+78.DOI:10.13364/j.issn.1672-6510.20170159.
汪森.基于Spark射电干涉阵成像算法实现研究[D].昆明理工大学,2021.DOI:10.27200/d.cnki.gkmlu.2021.000780。
- 一种基于Spark框架的文本聚类模型PW-LDA的并行化方法
- 基于spark集群并行化计算的交通拥堵点发现方法