基于多源域领域泛化的轴承剩余使用寿命预测方法和系统
文献发布时间:2023-06-19 19:30:30
技术领域
本发明涉及轴承寿命预测领域,尤其涉及一种基于多源域领域泛化的轴承剩余使用寿命预测方法和系统。
背景技术
预测和健康管理(PHM)无疑是工业性研究的热门,其中,为了帮助维护人员制定合理的维护策略,剩余使用寿命预测是PHM中非常具有挑战性的任务之一。轴承作为旋转机械中最为重要的机械零件之一,广泛应用于各个重要的工业领域。同时,作为最容易损坏的元件,轴承性能和工况的好坏能直接影响到整个设备的性能,甚至能导致设备的损坏。在现实工业环境中,不同轴承的使用寿命不同,相同轴承在不同工况下的使用寿命也不同,因此,对轴承剩余使用寿命的精准预测是非常重要的。
当前深度学习的时间序列剩余使用寿命预测方法取得了巨大的成功,但是它们通常会有训练集和测试集数据同分布的假设。但在工业场景下,训练的模型往往会用于很多不同的未知轴承剩余使用寿命预测,由于不同轴承的数据分布有差异,这就导致了预测精度的降低。
为了解决数据分布不一致的情况,领域自适应是一个有效的方法,然而,现有的领域自适应方法,通常会有至少一个目标域参与到训练当中,在实际情况中,目标域往往是未知的。所以,领域自适应方法对于未知域的剩余使用寿命预测却无能为力。
发明内容
为了解决上述现有技术中轴承寿命预测模型的学习必须使用目标域的缺陷,本发明提出了一种基于多源域领域泛化的轴承剩余使用寿命预测方法,采用多源域样本训练可用于目标域的轴承寿命预测的模型。
本发明提出的一种基于多源域领域泛化的轴承剩余使用寿命预测方法,将目标轴承最近t个时间上的采样信号输入轴承预测模型以预测目标轴承的寿命终点,结合目标轴承的寿命终点计算轴承剩余使用寿命;
轴承预测模型包括数据预处理模块和健康预测模块;数据预处理模块用于对目标轴承最近t个时间上的采样信号进行预处理,获得最近t个时间上的振动数据特征构成的目标轴承振动数据W’={w
优选的,包括以下步骤:
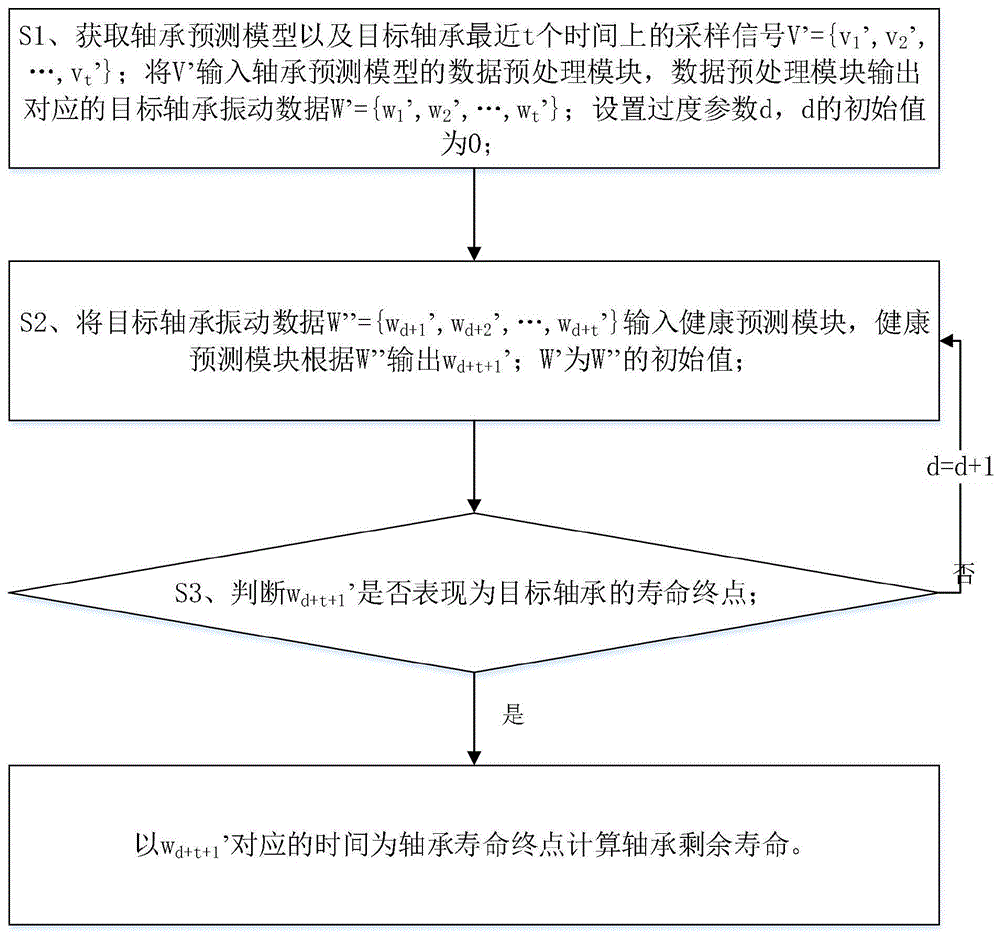
S1、获取轴承预测模型以及目标轴承最近t个时间上的采样信号V’={v
S2、将目标轴承振动数据W”={w
S3、判断w
优选的,数据预处理模块对原始振动信号V={v
w
其中,max表示取最大值,min表示取最小值;m表示原始振动信号V中所有采样信号的幅值均值,s表示原始振动信号V中所有采样信号的幅值方差;k,1≦k≦K,K为原始振动信号包含的采样信号数量。
优选的,健康预测模块的获取包括以下步骤:
SA1、构建源域样本,源域样本样本包括多组源轴承振动数据,第n个源轴承振动数据记作
SA2、对各源域样本进行滑动切片,将源域样本转换为时间序列,第n个源轴承的时间序列记作X
i为序数,1≦i≦I,t为步长,I=K’-t+1;
结合所有所有源轴承的时间序列构建学习样本
构建基础模型并初始化,基础模型包括域间归一化模块、可适配域内归一化模块、均值方差交换模块和第一神经网络;
SA3、令基础模型对学习样本进行学习以更新参数,当基础模型稳定后,从基础模型中提取第一神经网络作为健康预测模块;
基础模型的输入为
域间归一化模块对输入数据
μ
可适配域内归一化模块对输入数据
μ
μ
均值方差交换模块输入为输入数据
其中,
表示第n个源轴承的振动数据特征/>
第n个源轴承和第n’个源轴承互为关联轴承,即两者在同一个时间的时间序列上相互交换均值和方差;
第一神经网络的输入为域间归一化模块、可适配域内归一化模块和均值方差交换模块三者的输出,第一神经网络模型的输出为
优选的,SA3具体包括以下分步骤
SA31、将学习样本划分为训练样本和测试样本;令基础模型学习训练样本以迭代基础模型参数;
SA32、当基础模型迭代次数达到设定的迭代阈值,则选择测试样本对基础模型进行测试;
基础模型测试过程为:将测试样本
将测试样本中各源轴承的第i个时间序列
SA33、判断是否满足MMDLoss≦L1且RMSELoss≦L2;L1和L2均为设定的损失阈值;是,则提取第一神经网络作为健康预测模块;否,则返回步骤SA31。
优选的,第一损失函数为:
其中,Φ(z)表示将数据z映射到再生希尔伯特空间,
优选的,第二损失函数为:
N为源轴承数量,
本发明还提出了一种基于多源域领域泛化的轴承剩余使用寿命预测系统,为上述方法提供了载体;该系统包括存储器;所述存储器中存储有计算机程序,所述计算机程序被执行时用于实现所述的基于多源域领域泛化的轴承剩余使用寿命预测方法。
优选的,还包括处理器,处理器与存储器连接,处理器用于执行所述计算机程序,以实现所述的基于多源域领域泛化的轴承剩余使用寿命预测方法。
本发明的优点在于:
(1)本发明提出的一种基于多源域领域泛化的轴承剩余使用寿命预测方法,通过顺序预测下一个振动数据特征来获取轴承的寿命终点,从而计算轴承的剩余寿命预测值。
(2)本发明中采用的健康预测模块在训练过程中,结合了域内、域间归一化以及均值方差交叉互换。域内归一化将同一轴承的不同时间点归一化处理,学习域内差异性;域间归一化将不同轴承的同一时间点一起做归一化处理,结合MMD损失,学习域间差异性;再通过每两个轴承的全寿命周期数据均值方差交叉互换,增强模型的鲁棒性。
(3)本发明中,四个可适配的自适应参数W
(4)本发明中直接利用源域数据训练模型,应用于目标域,避免了在训练过程中需要目标域参与的问题。本发明最终获得的轴承预测模型可以有效地解决现实工业环境中,轴承工况未知的情况,实现了一种更通用的剩余使用寿命方法。
附图说明
图1为一种基于多源域领域泛化的轴承剩余使用寿命预测方法流程图;
图2为轴承预测模型训练流程概图;
图3为轴承预测模型训练流程细图;
图4(a)为第n个源轴承的振动数据特征曲线;
图4(b)为第n’个源轴承的振动数据特征曲线;
图4(c)为第n个源轴承和第n’个源轴承交换均值和方差后,第n个源轴承的退化数据曲线;
图4(d)为第n个源轴承和第n’个源轴承交换均值和方差后,第n’个源轴承的退化数据曲线;
图5为实施例中PHM2012的10个测试轴承的统计图;
图6为XJTU-SY的6个测试轴承的统计图。
具体实施方式
数据预处理模块
原始振动信号V={v
采样信号v
w
轴承预测模型
轴承预测模型包括数据预处理模块和健康预测模块;数据预处理模块用于对目标轴承最近t个时间上的采样信号进行预处理,获得最近t个时间上的振动数据特征构成的目标轴承振动数据W’={w
健康预测模块用于根据目标轴承振动数据W’预测下一个时间点t+1上的振动数据特征w
轴承寿命预测方法
参照图1,本实施方式提供的轴承寿命预测方法,包括以下步骤:
S1、获取轴承预测模型以及目标轴承最近t个时间上的采样信号V’={v
S2、将目标轴承振动数据W”={w
S3、判断w
值得注意的是,W”的初始值为W’,即W”的初始值对应d=0;随着d的取值的变化,健康预测模块将其输出迁移到输入以更新W”,从而实现在时间维度上依次预测下一个振动数据特征,直至获得目标轴承的寿命终点上的振动数据特征。
健康预测模块的训练方法
参照图2,图3,本实施方式中健康预测模块的训练包括以下步骤:
SA1、构建源域样本,源域样本样本包括多组源轴承振动数据,第n个源轴承振动数据记作:
表示第n个源轴承的第k’个振动数据特征;/>
令第n个源轴承的原始振动信号记作
分别表示采样信号/>
SA2、对各源域样本进行滑动切片,将源域样本转换为时间序列,第n个源轴承的时间序列记作X
i为序数,1≦i≦I,t为步长,I=K’-t+1;
结合所有所有源轴承的时间序列构建学习样本
构建基础模型并初始化,基础模型包括域间归一化模块、可适配域内归一化模块、均值方差交换模块和第一神经网络;
SA31、将学习样本划分为训练样本和测试样本;令基础模型学习训练样本。
基础模型的输入为
域间归一化模块对输入数据
μ
可适配域内归一化模块对输入数据
μ
均值方差交换模块输入为输入数据
其中,
参照图4(a)(b)(c)(d),
第n个源轴承和第n’个源轴承互为关联轴承,即两者在同一个时间的时间序列上相互交换均值和方差;
即:
表示第n’个源轴承的振动数据特征/>
第一神经网络的输入为域间归一化模块、可适配域内归一化模块和均值方差交换模块三者的输出,第一神经网络模型的输出为
值得注意的是,均值方差交换模块可通过对
SA432、当基础模型迭代次数达到设定的迭代阈值,则选择测试样本对基础模型进行测试,判断域间归一化模块和第一神经网络是否分别满足第一损失函数和第二损失函数;
第一损失函数为:
其中,Φ表示映射函数,
第二损失函数为:
N为源轴承数量,
SA33、判断第一损失函数和第二损失函数是否均达到对应的损失阈值;是,则提取第一神经网络作为健康预测模块;反之,则返回步骤SA31。
实施例
本实施例中采用IEEE PHM Challenge 2012轴承数据集以及XJTU-SY(西安交通大学轴承)数据集来验证本发明提供的轴承预测模型。
IEEE PHM Challenge 2012轴承数据集采自PRONOSTIA测试平台;XJTU-SY轴承数据集由设计科学研究所《西安交通大学基础研究》提供,其收录了15个滚动轴承从运行到故障的振动数据,轴承试验台如图3所示。
PHM Challenge 2012数据集:该试验台由三个主要部分组成:分别是旋转部分、退化产生部分(在被测轴承上施加径向力)和测量部分。轴承退化的特征是基于传感器的两种数据类型来确定的:振动和温度。测量部分包括加速度传感器,加速度传感器的采样频率为25.6kHz,数据采集时每隔10秒记录一次测量振动信号,每次采集时长0.1秒,每次采集的数据点是2560个,当振动信号的振幅即幅值达到20g时,实验停止,默认轴承完全失效。此实验平台上进行了三种工况下的轴承退化实验如表1所示。
表1PHM2012轴承基本信息
XJTU-SY数据集:轴承试验台由交流(AC)感应电机、电机转速控制器、支撑轴、两个支撑轴承(重型滚子轴承)和液压加载系统组成。本试验台旨在不同的操作条件下(即不同的径向力和转速)对试验轴承进行加速退化试验。径向力由液压加载系统产生,施加于被测轴承的壳体上,转速由交流感应电机的速度控制器设定并保持,此实验平台上进行了三种工况下的轴承退化实验,如表2所示。
表2XJTU-SY轴承基本信息
本实施例中,首先以IEEE PHM Challenge 2012轴承数据集中的轴承1_2、轴承1_3、轴承2_2和轴承2_3作为源轴承,结合该4个源轴承训练基础模型,以获得健康预测模块,然后结合数据预处理模块和健康预测模块构建轴承预测模型。
然后根据轴承预测模型分别预测IEEE PHM Challenge 2012轴承数据集中的轴承1_5、轴承1_6、轴承1_7、轴承2_4、轴承2_5、轴承2_6、轴承2_7、轴承3_1、轴承3_2、轴承3_3以及XJTU-SY数据集中的轴承1_1、轴承1_2、轴承2_1、轴承2_2、轴承3_1、轴承3_2的预测寿命。
表三实验训练集和测试集分布情况
为了衡量轴承预测模型的性能,本实施例中采用拟合R方和RMSE一起作为评价标准,用RMSE表示预测寿命相对于剩余寿命真实值的误差大小,用拟合R方显示拟合曲线的解释力度。
/>
其中,R
本实施例中,对PHM2012挑战数据集上的10个跨轴承故障诊断任务结果如图5所示。可以看到,10个测试轴承中,拟合R方最低为86.48%,最高能达到95.94%,除了轴承1_6和轴承3_1外的测试轴承都能达到90%以上,说明本发明提供的轴承预测模型对每个未知的测试集的预测能力都很强。
此外,10个测试轴承的RMSE范围为[0-1.3),轴承1_6的RMSE最小值可达0.03,轴承2_5的RMSE最大值仅为1.2076,且趋于稳定。产生RMSE差距的主要原因是某些轴承振动数据噪声较大,从而影响了预测精度。
本实施例中,对西交数据集上的6个跨轴承故障诊断任务结果如图6所示。可以看到,该6个测试轴承中,RMSE最高也仅仅只有轴承3_2的0.1347,在这个轴承上拟合R方同时也是最低,但也有着85.4%的解释力度。其他5个测试轴承每个RMSE都在[0-0.06]之间,拟合R方也都在90%以上。由此可见,本发明提供的轴承预测模型对于跨平台的轴承数据集的预测能力很强。
以上仅为本发明创造的较佳实施例而已,并不用以限制本发明创造,凡在本发明创造的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明创造的保护范围之内。
- 基于标记分布学习的多源域领域泛化行人重识别系统及方法
- 一种基于图卷积网络和无监督域自适应的航空发动机剩余使用寿命预测方法