代码识别方法、装置、计算设备和计算机可读存储介质
文献发布时间:2023-06-19 19:30:30
技术领域
本发明涉及计算机应用技术领域,具体涉及一种代码识别方法、装置、计算设备和计算机可读存储介质。
背景技术
在软件项目实施过程中,产品的性能和高并发支持往往是开发人员需要考虑的重要环节。开发人员在设计和开发代码的时候,往往因为项目迭代周期过短,或者因为自身经验的不足而疏于代码性能的优化。在大中型项目中,其代码量往往在数十万规模以上,如果能有效并且快速的帮助开发人员,特别是初中级开发人员,辅助其提前发现性能瓶颈并给出相关优化建议,这对于提升后续线上产品的性能将十分有益。
现有的方案往往依靠有经验的开发人员通过code review(代码审查)工具帮助初中级开发人员发现问题,或者在系统或性能测试阶段,通过相关测试用例发现性能瓶颈;开发人员再回头检查瓶颈原因,重构相应代码,这样不仅开发成本上升,同时也给将要上线的产品带来一定的性能隐患;同时,现有IDE(集成开发环境)中的代码扫描工具针对提前发现性能瓶颈等问题领域还处于空白,没有现成的分析工具可以利用。
发明内容
鉴于上述问题,提出了本发明以便提供一种克服上述问题或者至少部分地解决上述问题的代码识别方法、装置、计算设备和计算机可读存储介质。
根据本发明的一个方面,提供了一种代码识别方法,所述方法包括:
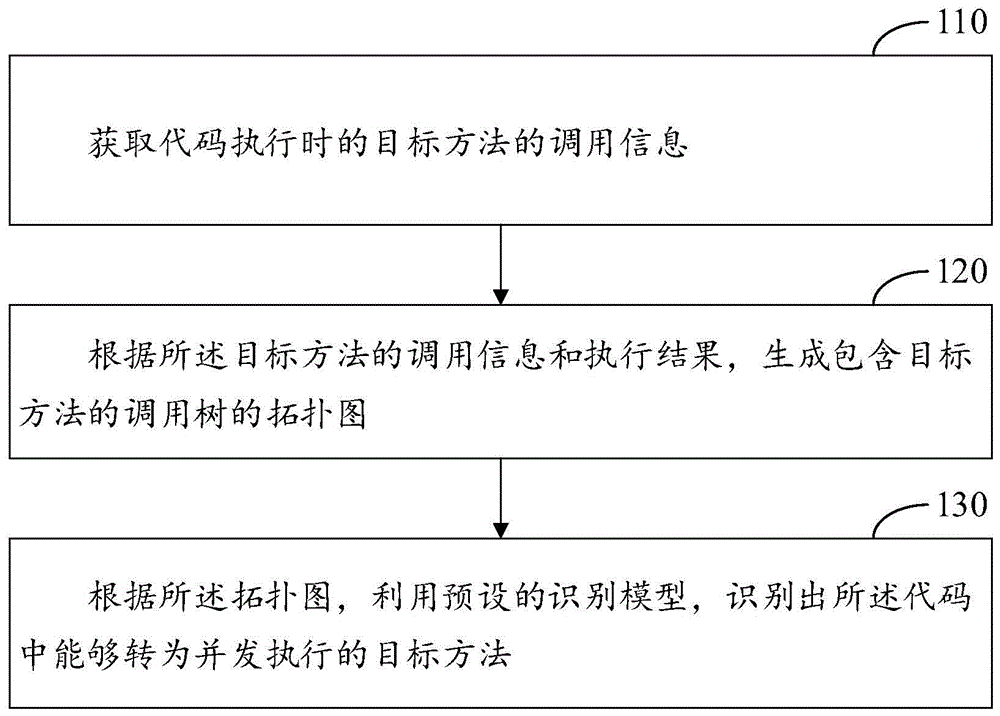
获取代码执行时的目标方法的调用信息;
根据所述目标方法的调用信息和执行结果,生成包含目标方法的调用树的拓扑图;
根据所述拓扑图,利用预设的识别模型,识别出所述代码中能够转为并发执行的目标方法。
可选的,获取代码执行时的目标方法的调用信息之前包括:
利用切面编程方式,在所述代码对应的字节码中植入目标方法调用前和调用后的增强逻辑;
其中,所述目标方法包括业务核心代码中的方法和/或与磁盘或网络之间输入输出时调用的方法。
可选的,获取代码执行时的目标方法的调用信息具体包括:
获取所述目标方法的调用时长、入参变量信息、出参变量信息和/或目标方法元信息。
可选的,根据所述拓扑图,利用预设的识别模型,识别出所述代码中能够转为并发执行的目标方法包括:
在所述拓扑图中,选取执行耗时不小于预设值的方法和/或与磁盘或网络之间输入输出时调用的方法,构成串行转并发目标方法集合;
以串行转并发目标方法集合为自变量,求解在约束条件下的所述识别模型的最优解或近似最优解;
根据所述最优解或近似最优解,识别出所述代码中能够转为并发的目标方法。
可选的,在所述拓扑图中,选取执行耗时不小于预设值的方法和/或与磁盘或网络之间输入输出时调用的方法,构成串行转并发目标方法集合进一步包括:
确定输入输出时调用的方法对应节点的最邻近共同祖先节点,根据所述祖先节点的子节点形成所述串行转并发目标方法集合。
可选的,所述识别模型为规划模型,则求解在约束条件下的所述识别模型的最优解或近似最优解进一步包括:
利用模拟退火算法,求解在约束条件下的所述规划模型的最优解或近似最优解。
可选的,所述模拟退火算法为改进的模拟退火算法,包括:分层次产生可行解邻域内的待定解;和/或,根据第一部分贪心和第二部分随机化的策略产生初始解;
所述规划模型包括:分别计算各个串行转并发目标方法集合与该串行转并发目标方法集合实现转化后预估收益的乘积,然后求解各个乘积之和的最大值;
所述约束条件包括:调用时长约束和/或CPU资源占用约束。
根据本发明的另一方面,提供了一种代码识别装置,所述装置包括:
获取模块,适于获取代码执行时的目标方法的调用信息;
生成模块,适于根据所述目标方法的调用信息和执行结果,生成包含目标方法的调用树的拓扑图;
识别模块,适于根据所述拓扑图,利用预设的识别模型,识别出所述代码中能够转为并发执行的目标方法。
根据本发明的又一方面,提供了一种计算设备,包括:处理器、存储器、通信接口和通信总线,所述处理器、所述存储器和所述通信接口通过所述通信总线完成相互间的通信;
所述存储器用于存放至少一可执行指令,所述可执行指令使所述处理器执行上述代码识别方法对应的操作。
根据本发明的再一方面,提供了一种计算机存储介质,所述存储介质中存储有至少一可执行指令,所述可执行指令使处理器执行如上述代码识别方法对应的操作。
根据本发明的代码识别方案,能够分析出可以以较大概率进行串行转并发方式执行的目标方法对应的代码,通过为开发人员提供一种合理可行、并且能快速落地的可并发执行代码的识别和分析方案,从而减少项目实施过程中的风险,并帮助优化线上产品的性能,并且克服了现有方案对开发人员经验技能要求较高以及专业分析工具缺失等突出弊端。
上述说明仅是本发明技术方案的概述,为了能够更清楚了解本发明的技术手段,而可依照说明书的内容予以实施,并且为了让本发明的上述和其它目的、特征和优点能够更明显易懂,以下特举本发明的具体实施方式。
附图说明
通过阅读下文优选实施方式的详细描述,各种其他的优点和益处对于本领域普通技术人员将变得清楚明了。附图仅用于示出优选实施方式的目的,而并不认为是对本发明的限制。而且在整个附图中,用相同的参考符号表示相同的部件。在附图中:
图1示出了本发明一实施例提供的代码识别方法流程图;
图2示出了本发明一实施例提供的基于字节码级AOP增强逻辑获取方法执行信息的流程图;
图3示出了本发明一实施例提供的方法调用树的结构示意图;
图4示出了本发明另一实施例提供的代码识别方法的流程图;
图5示出了本发明一实施例提供的代码识别装置的结构示意图;
图6示出了本发明一实施例提供的计算设备的结构示意图。
具体实施方式
下面将参照附图更详细地描述本发明的示例性实施例。虽然附图中显示了本发明的示例性实施例,然而应当理解,可以以各种形式实现本发明而不应被这里阐述的实施例所限制。相反,提供这些实施例是为了能够更透彻地理解本发明,并且能够将本发明的范围完整的传达给本领域的技术人员。
图1示出了本发明代码识别方法实施例的流程图,该方法应用于计算设备中。所述计算设备为安装有使用线程池的计算机程序的智能终端设备、计算机设备和/或云,所述智能终端设备包括但不限于智能手机、PAD;所述计算机设备包括但不限于个人计算机、笔记本电脑、工业计算机、网络主机、单个网络服务器、多个网络服务器集;所述云由基于云计算(Cloud Computing)的大量计算机或网络服务器构成,其中,云计算是分布式计算的一种,由一群松散耦合的计算机集组成的一个虚拟超级计算机。
如图1所示,该方法包括以下步骤:
步骤110:获取代码执行时的目标方法的调用信息。
其中本实施例的代码可以是Java类、C类、PHP、Python等各类语言编写的代码,并且具体的项目类型也不做具体的限制。本实施例可用于分析目前的各类项目代码中的目标方法(特别是串行布置的方法)是否能够改为并发的方式,以提高产品性能和运行效率等。
需要指出的是,为了获得代码中目标方法的调用信息,包括入参和出参等参数信息以及信息流动中的结构化信息等,优选对代码对应的字节码等编译后的文件进行处理,实现以无侵入方式得到其中的调用信息。
步骤120:根据所述目标方法的调用信息和执行结果,生成包含目标方法的调用树的拓扑图。
具体的,根据代码中方法的调用关系,可以获得相应的调用信息和调用结构类特征,从而生成各目标方法的调用树,并且根据该调用树形成相应的拓扑图。其中,图3示出了一个调用树的具体示例。
步骤130:根据所述拓扑图,利用预设的识别模型,识别出所述代码中能够转为并发执行的目标方法。
根据拓扑图以及其中的目标方法相关信息,利用构建的识别模型,识别出能够由当前串行的执行方式改成并发执行的目标方法。其中所述识别模型可以是数学模型、机器学习模型或者深度学习模型,比如,可以通过改进前和改进后代码执行效率和产品性能提高的程度来识别其中的目标方法。
综上,本发明实施例特别适于需要支持高并发的大中型Java项目,初中级开发人员往往因开发周期和经验的原因,将本可以用并发方式实现的代码用串行的方式实现,比如串行方式实现多个方法级别的消息通信、RPC或Rest调用、高IO的操作等。而基于上述方案中的识别模型,能够发现性能瓶颈,识别可并发的代码,生成的结果能较为全面的反应项目代码中可并发改造的部分,从而解决现有技术对开发人员经验技能要求较高和该领域专业分析工具缺失的突出弊端。
上述实施例可以在项目开发中可以快速落地,能帮助软件开发人员较为全面的梳理和识别项目代码中可并发改造的部分,减少项目实施过程中的风险,对线上产品的性能优化起到良好的帮助作用。
在一个或一些实施例中,获取代码执行时的目标方法的调用信息之前包括:
利用切面编程方式,在所述代码对应的字节码中植入目标方法调用前和调用后的增强逻辑;其中,所述目标方法包括业务核心代码中的方法和/或与磁盘或网络之间输入输出时调用的方法。
具体的,为了便于通过无侵入的方式获得调用信息,本实施例通过利用字节码增强技术,在不改变任何源代码的情况下,修改Java类在编译后的字节码;特别是针对核心处理逻辑的方法调用链,通过字节码级别的AOP,植入每个方法调用前和调用后的增强逻辑,其中包括处理分布式调用链trace和span方式的线程级别的调用链,以获取方法的调用时长和相关变量信息。
其中,面向切面编程AOP(Aspect Oriented Programming),是通过预编译方式和运行期动态代理实现程序功能的统一维护的一种技术。AOP是OOP的延续,是软件开发中的一个热点,也是Spring框架中的一个重要内容,是函数式编程的一种衍生范型。利用AOP可以对业务逻辑的各个部分进行隔离,从而使得业务逻辑各部分之间的耦合度降低,提高程序的可重用性,同时提高了开发的效率。
AOP主要涉及到的概念包括:切面(Aspect)、连接点(Joint point)、切点(Pointcut)、增强(Advice)、目标对象(Target)以及Weaving(织入),其中增强Advice定义了在切点里面定义的程序点具体要做的操作,它通过before、after和around来区别是在每个joint point之前、之后还是代替执行的代码。
另外,在代码系统完成一次业务调用的过程中,把服务之间的调用信息(时间、接口、层次、结果)打点到日志中,然后将所有的打点数据连接为一个树状链条就产生了一个调用链。跟踪系统把过程中产生的日志信息进行分析处理,将业务端到端的执行完整的调用过程进行还原,根据不同维度进行统计分析;从而标识出有异常的服务调用,能够快速分析定界到出异常的服务;同时可根据数据统计分析系统性能瓶颈。
其中,Trace是指一次请求调用的链路过程,Trace id是指这次请求调用的ID。在一次请求中,在网络的最开始生成一个全局唯一的用于标识此次请求的Trace id,该Traceid在这次请求调用过程中无论经过多少个节点都会保持不变,并且在随着每一层的调用不停的传递。最终,可以通过Trace id将该次用户请求在系统中的路径全部串起来。
Span是指一个模块的调用过程,一般用span id来标识。在一次请求的过程中会调用不同的节点/模块/服务,每一次调用都会生成一个新的span id来记录。这样,就可以通过span id来定位当前请求在整个系统调用链中所处的位置,以及它的上下游节点分别是什么。
在请求的调用链中,SpanA调用了SpanB,然后SpanB又调用了SpanC和SpanD,每一次Span调用都会生成一个自己的span id,并且还会记录自己的上级span id是谁。通过这些id,整个链路基本上就都能标识出来了。
由此可知,整个调用过程中每个请求都要透传Trace id和Span id。每个服务将该次请求附带的Trace id和附带的Span id作为Parent id记录下,并且将自己生成的Spanid也记录下。要查看某次完整的调用,只要根据Trace id查出所有调用记录,然后通过Parent id和Span Id组织起整个调用父子关系即可。
具体到本发明实施例,为了获得调用信息,可以在字节码层面做方法级别的AOP拦截和增强,对源代码层无侵入性。
结合图2所示的获取方法执行信息的流程图,获取执行信息的步骤参见图2中的步骤1-6所示,需要指出的是,在相同线程的方法调用链上的第一个方法调用前,需要生成对应的Trace id和Span id(这里Trace id主要用来区分不同的性能测试实例;Span id主要用来生成方法调用链信息),并获取方法对应的入参变量信息;在相同线程方法调用链的其他方法调用前,生成对应的Span id,并获取对应的入参变量信息。上述信息都会放入线程局部变量ThreadLocal中,同时记录方法调用的开始时间;在方法执行结束后记录本方法调用的耗时(可以精确到微妙),出参变量信息和方法元信息(类名+方法签名)。如果一次性能测试用例的执行涉及到多个线程,那么每个线程对应的方法调用链上的执行信息都会被记录,供后续的最优化模型使用。同时,每个性能测试实例都可以按上述步骤执行。
通过对代码执行过程的分析可知,一般的瓶颈环节为业务核心代码执行环节以及不同设备之间的调用环节。因此,该实施例中的目标方法主要包括业务核心代码中的方法或与磁盘或网络之间输入输出时调用的方法,当然,本发明实施例在实施中可以对所有相关方法进行分析,并通过获得的方法执行信息寻求对产品性能优化的最佳方案。
在一个或一些实施例中,获取代码执行时的目标方法的调用信息具体包括:获取所述目标方法的调用时长、入参变量信息、出参变量信息和/或目标方法元信息。
并且,根据上述的信息,可以生成如图3所示的方法调用的调用树。其中,调用树上的各个节点上设置有Span id的标识、方法耗时以及变量列表等信息。
进一步的,拓扑图是一个调用树组成的森林,每一个调用树对应一个测试实例;调用树的根节点是第一个执行的方法,其子节点是该方法内部调用的子方法,按照调用顺序从左到右排列(重点关注子节点中串行执行的节点);同时子节点的子节点按照上述实施例递归定义。参见图3所示的调用树,其为在第一阶段服务的Rest API调用中一个测试实例生成的方法调用树。
在一个或一些实施例中,根据所述拓扑图,利用预设的识别模型,识别出所述代码中能够转为并发执行的目标方法包括:
在所述拓扑图中,选取执行耗时不小于预设值的方法和/或与磁盘或网络之间输入输出时调用的方法,构成串行转并发目标方法集合;
以串行转并发目标方法集合为自变量,求解在约束条件下的所述识别模型的最优解或近似最优解;
根据所述最优解或近似最优解,识别出所述代码中能够转为并发的目标方法。
并且,在形成所述串行转并发目标方法集合时,首先确定输入输出时调用的方法对应节点的最邻近共同祖先节点,然后,根据所述祖先节点的子节点形成所述串行转并发目标方法集合。
在一个可选的实施例中,所述识别模型为规划模型,则求解在约束条件下的所述识别模型的最优解或近似最优解进一步包括:
利用模拟退火算法,求解在约束条件下的所述规划模型的最优解或近似最优解。
根据上述的实施例,在生成所有方法调用链上的执行耗时和元信息拓扑图后,根据生成的拓扑图,进一步分析出可以以较大概率进行串行转并发方式执行的代码,并生成报告。
根据本实施例中的识别模型需求,可以从拓扑图上的方法调用树中,抽取方法执行耗时不小于预设值和涉及到磁盘或网络IO的调用方法:比如redis调用、数据库调用、MQ调用、RPC调用、磁盘读写等;同时以相关IO调用方法对应节点的最邻近共同祖先的儿子节点,作为类划分依据,得到多个串行转并发目标方法集合。
具体的,继续结合图3所示,以磁盘或网络IO调用的方法和方法调用链的并发改造为例,选择比如redis调用、数据库调用、MQ调用、RPC调用、磁盘读写的相应的目标方法;图3中,有2类上述调用符合要求,Redis和Mysql数据库访问;同时,图3中的方法A3不计入改造考虑。然后配置方法调用耗时阀值,小于阀值的方法以及该方法调用链上的所有调用方法都不考虑。
然后,合并和归类符合上述要求的方法节点,上述方法节点在一个类中的目标方法节点集合将成为可并发改造的对象。
上述实施例提出的归类方法是,找到涉及磁盘或网络IO调用的方法对应节点最邻近的共同祖先,然后将该祖先节点对应的儿子归为一类得到一个目标方法集合,进行相关并发改造。这里需要同时考察儿子节点的变量列表信息;如果儿子节点集之间的变量列表存在交集,即方法出参和入参对应的Object对象地址有相同情况,那么将在最后的报告中,给出对应的代码并发改造存在操作共享变量的风险;这也是之前提到的按概率可并发改造的原因。
继续以图3中的实例为例说明,针对2个“Redis connection类send“方法节点,找到其最邻近的共同祖先节点,即入口方法A节点,其调用链上对应的儿子节点是方法A1和方法A2,将A1和A2归为一类作为识别模型的自变量因子x1;同时2个“MySQL JDBC”方法调用节点,找到其最邻近的共同祖先节点,即方法A4节点,其调用链上对应的儿子节点是方法D1和方法D2,将D1和D2也归为新的一类,作为识别模型的自变量因子x2。
然后,建立带约束条件的规划模型作为识别模型,并采用本发明实施例中提出的一种改进的模拟退火SA算法,求解在当前软硬件资源约束条件下的模型最优解或近似最优解;从而得到哪些方法可以进行并发改造的相关结果报告。
在一个或一些实施例中,所述模拟退火算法为改进的模拟退火算法,包括:分层次产生可行解邻域内的待定解;和/或,根据第一部分贪心和第二部分随机化的策略产生初始解;
所述规划模型包括:分别计算各个串行转并发目标方法集合与该串行转并发目标方法集合实现转化后预估收益的乘积,然后求解各个乘积之和的最大值;
所述约束条件包括:调用时长约束和/或CPU资源占用约束。
具体的,改进的模拟退火算法(SA)主要包括三方面:分层次产生当前可行解邻域内的待定解;第一部分贪心+第二部分随机化的策略产生初始解,其中第二部分大于第一部分,从而通过上述三个方面对模拟退火算法进行改进。
针对每个测试实例的并发改造的规划模型如下:
其中,共有n个类别x
可知,预估收益可以分成三部分:改造前后的时长加速比、改并发后单CPU资源占用预估、权重项。
其中T
约束条件1为所有n个类(目标方法集合)的并发改造后的时间和加上排除的小于预设的阀值T
约束条件2为CPU资源占用约束,含义参见v
运行该规划模型,得到x
图4示出了本发明代码识别方法另一个实施例的流程图,该方法包括以下步骤:首先,设置需要进行AOP增强的类和方法特征,可以主要包括业务核心代码和用到的开源软件、JDK涉及词频和网络IO的调用类和方法;然后,导入要分析的源代码工程;准备获取代码执行耗时等性能测试用例;然后利用最优化模型(规划模型)和AOP自动搜集和分析可并发执行方法代码信息。最后一个步骤具体可分为配置目标方法、数据搜集、调用树拓扑图生成和识别模型执行等阶段。
下面针对智能硬件推荐的一个测试实例,利用ltgrass4j-synctoasync-1.0.0进行可并发改造分析如下:
测试用例rest url:recommend-music/aihdw/list/rec/v1
首先对相关被分析的服务加入如下启动jvm配置,并启动:
-javaagent:xxxpath/mdp-starter-metrics-bytecodeagent.jar
然后启动分析工具ltgrass4j-synctoasync,输入相关参数,根据需要回车,开始分析。
最后生成可并发改造的相关报告。该报告是一个建议性的方案,具体还要开发人员结合实际情况进行分析。
比如上述报告的内容包括:提示项目中AiHdwHotRecallingProcessor类的方法buildHotItemsContext所代表的类在最优化模型求解后值为1(为1表示在当前约束条件下,该类别下的方法调用可以尝试并发改造;为0的表示在当前约束条件下,不要进行并发改造)。
同时buildHotItemsContext方法内部有2次调用AiHdwRecallService类的recallItems方法,而这2个方法正是可并发改造的对象。
当开发人员得到上述分析报告后,可以查看对应的源代码。比如源码中上述buildHotItemsContext方法调用的recallItems,发现对应的recallItems方法被串行的执行了2次,recallItems内部会调用redis相关操作;从而可以考虑对其进行并发执行改造。
图5示出了本发明代码识别装置实施例的结构示意图。如图5所示,该装置500包括:
获取模块510,适于获取代码执行时的目标方法的调用信息;
生成模块520,适于根据所述目标方法的调用信息和执行结果,生成包含目标方法的调用树的拓扑图;
识别模块530,适于根据所述拓扑图,利用预设的识别模型,识别出所述代码中能够转为并发执行的目标方法。
在一个实施例中,获取模块510还适于:
利用切面编程方式,在所述代码对应的字节码中植入目标方法调用前和调用后的增强逻辑;
其中,所述目标方法包括业务核心代码中的方法和/或与磁盘或网络之间输入输出时调用的方法。
在一个可选的实施例中,获取模块510具体适于:
获取所述目标方法的调用时长、入参变量信息、出参变量信息和/或目标方法元信息。
在一个实施例中,识别模块530还适于:
在所述拓扑图中,选取执行耗时不小于预设值的方法和/或与磁盘或网络之间输入输出时调用的方法,构成串行转并发目标方法集合;
以串行转并发目标方法集合为自变量,求解在约束条件下的所述识别模型的最优解或近似最优解;
根据所述最优解或近似最优解,识别出所述代码中能够转为并发的目标方法。
在一个实施例中,识别模块530进一步适于:
确定输入输出时调用的方法对应节点的最邻近共同祖先节点,根据所述祖先节点的子节点形成所述串行转并发目标方法集合。
在一个实施例中,所述识别模型为规划模型,则识别模块530进一步适于:
利用模拟退火算法,求解在约束条件下的所述规划模型的最优解或近似最优解。
在一个实施例中,所述模拟退火算法为改进的模拟退火算法,包括:分层次产生可行解邻域内的待定解;和/或,根据第一部分贪心和第二部分随机化的策略产生初始解;
所述规划模型包括:分别计算各个串行转并发目标方法集合与该串行转并发目标方法集合实现转化后预估收益的乘积,然后求解各个乘积之和的最大值;
所述约束条件包括:调用时长约束和/或CPU资源占用约束。
根据上述实施例可知,本发明的关键点和欲保护点和有益效果:
1、本发明实施例提出了基于方法调用树组成的拓扑图,并在相应的分类规则上(例如方法节点最邻近的共同祖先的儿子节点作为类划分依据)得到目标方法集合,有针对性的设计一种最优化模型和改进的SA算法来识别可并发代码,从而实现了一种全新的代码识别工具。
2、针对核心处理逻辑的方法调用链,在不改变任何源代码的情况下,通过字节码级别的AOP方式,植入每个方法调用前和调用后的增强逻辑。具体为处理类似分布式调用链trace和span方式的线程级别的调用链,获取方法的调用时长和相关变量信息。上述方式能够较为广泛适用于代码扫描工具方向的应用场景。
3、上述实施例公开的基于最优化模型和字节码级AOP的可并发代码自动识别方案,生成的结果能较为全面的反应项目代码中可并发改造的部分;能够实现的相应自动识别工具在Java相关的项目开发中可以快速落地,帮助软件开发人员较为全面的梳理和识别项目代码中可并发改造的部分,减少项目实施过程中的风险,对线上产品的性能优化起到良好的帮助作用。
本发明实施例提供了一种非易失性计算机存储介质,所述计算机存储介质存储有至少一可执行指令,该计算机可执行指令可执行上述任意方法实施例中的代码识别方法。
图6示出了本发明计算设备实施例的结构示意图,本发明具体实施例并不对计算设备的具体实现做限定。
如图6所示,该计算设备可以包括:处理器(processor)602、通信接口(Communications Interface)604、存储器(memory)606、以及通信总线608。
其中:处理器602、通信接口604、以及存储器606通过通信总线608完成相互间的通信。通信接口604,用于与其它设备比如客户端或其它服务器等的网元通信。处理器602,用于执行程序610,具体可以执行上述用于计算设备的代码识别方法实施例中的相关步骤。
具体地,程序610可以包括程序代码,该程序代码包括计算机操作指令。
处理器602可能是中央处理器CPU,或者是特定集成电路ASIC(ApplicationSpecific Integrated Circuit),或者是被配置成实施本发明实施例的一个或多个集成电路。计算设备包括的一个或多个处理器,可以是同一类型的处理器,如一个或多个CPU;也可以是不同类型的处理器,如一个或多个CPU以及一个或多个ASIC。
存储器606,用于存放程序610。存储器606可能包含高速RAM存储器,也可能还包括非易失性存储器(non-volatile memory),例如至少一个磁盘存储器。
程序610具体可以用于使得处理器602执行如上述各个代码识别方法实施例对应的操作。
在此提供的算法或显示不与任何特定计算机、虚拟系统或者其它设备固有相关。各种通用系统也可以与基于在此的示教一起使用。根据上面的描述,构造这类系统所要求的结构是显而易见的。此外,本发明实施例也不针对任何特定编程语言。应当明白,可以利用各种编程语言实现在此描述的本发明的内容,并且上面对特定语言所做的描述是为了披露本发明的最佳实施方式。
在此处所提供的说明书中,说明了大量具体细节。然而,能够理解,本发明的实施例可以在没有这些具体细节的情况下实践。在一些实例中,并未详细示出公知的方法、结构和技术,以便不模糊对本说明书的理解。
类似地,应当理解,为了精简本发明并帮助理解各个发明方面中的一个或多个,在上面对本发明的示例性实施例的描述中,本发明实施例的各个特征有时被一起分组到单个实施例、图、或者对其的描述中。然而,并不应将该公开的方法解释成反映如下意图:即所要求保护的本发明要求比在每个权利要求中所明确记载的特征更多的特征。更确切地说,如下面的权利要求书所反映的那样,发明方面在于少于前面公开的单个实施例的所有特征。因此,遵循具体实施方式的权利要求书由此明确地并入该具体实施方式,其中每个权利要求本身都作为本发明的单独实施例。
本领域那些技术人员可以理解,可以对实施例中的设备中的模块进行自适应性地改变并且把它们设置在与该实施例不同的一个或多个设备中。可以把实施例中的模块或单元或组件组合成一个模块或单元或组件,以及此外可以把它们分成多个子模块或子单元或子组件。除了这样的特征和/或过程或者单元中的至少一些是相互排斥之外,可以采用任何组合对本说明书(包括伴随的权利要求、摘要和附图)中公开的所有特征以及如此公开的任何方法或者设备的所有过程或单元进行组合。除非另外明确陈述,本说明书(包括伴随的权利要求、摘要和附图)中公开的每个特征可以由提供相同、等同或相似目的的替代特征来代替。
此外,本领域的技术人员能够理解,尽管在此的一些实施例包括其它实施例中所包括的某些特征而不是其它特征,但是不同实施例的特征的组合意味着处于本发明的范围之内并且形成不同的实施例。例如,在下面的权利要求书中,所要求保护的实施例的任意之一都可以以任意的组合方式来使用。
本发明的各个部件实施例可以以硬件实现,或者以在一个或者多个处理器上运行的软件模块实现,或者以它们的组合实现。本领域的技术人员应当理解,可以在实践中使用微处理器或者数字信号处理器(DSP)来实现根据本发明实施例的一些或者全部部件的一些或者全部功能。本发明还可以实现为用于执行这里所描述的方法的一部分或者全部的设备或者装置程序(例如,计算机程序和计算机程序产品)。这样的实现本发明的程序可以存储在计算机可读介质上,或者可以具有一个或者多个信号的形式。这样的信号可以从因特网网站上下载得到,或者在载体信号上提供,或者以任何其他形式提供。
应该注意的是上述实施例对本发明进行说明而不是对本发明进行限制,并且本领域技术人员在不脱离所附权利要求的范围的情况下可设计出替换实施例。在权利要求中,不应将位于括号之间的任何参考符号构造成对权利要求的限制。单词“包含”不排除存在未列在权利要求中的元件或步骤。位于元件之前的单词“一”或“一个”不排除存在多个这样的元件。本发明可以借助于包括有若干不同元件的硬件以及借助于适当编程的计算机来实现。在列举了若干装置的单元权利要求中,这些装置中的若干个可以是通过同一个硬件项来具体体现。单词第一、第二、以及第三等的使用不表示任何顺序。可将这些单词解释为名称。上述实施例中的步骤,除有特殊说明外,不应理解为对执行顺序的限定。
- 声纹识别方法、装置、计算机设备和计算机可读存储介质
- 一种车牌识别方法、装置、计算机装置及计算机可读存储介质
- 一种构件识别方法、装置、设备及计算机可读存储介质
- 可疑团伙识别方法、装置、设备及计算机可读存储介质
- 新设备识别方法、装置、服务器及计算机可读存储介质
- 代码更新识别方法、装置、计算机设备及可读存储介质
- 代码文件的识别方法、装置、计算机设备和可读存储介质