基于高光谱图像的尿液成分异常检测方法及系统
文献发布时间:2024-04-18 19:58:53
技术领域
本发明涉及图像分析技术领域,具体为基于高光谱图像的尿液成分异常检测方法及系统。
背景技术
本部分的陈述仅仅是提供了与本发明相关的背景技术信息,不必然构成在先技术。
通过对尿液样本的高光谱图像进行分析,能够获得样本中各类蛋白的形态,从而确定尿液中存在异常的成分。现有技术处理此类高光谱图像时,会利用样本中蛋白分子对光线吸收和散射的能力,从获取的图像中选取感兴趣区域,将拍摄区域内RGB图像重建为高光谱图像并提取特征值,从而得到所需的蛋白形态等参数。由于高光谱图像中除了包含被拍摄目标的信息以外还包含有光谱信息,虽然利用这一特性可以从图像中分析一些肉眼无法观察到的信息,但得到的数据维度过大,使得对计算机和存储器的需求较高。
发明内容
为了解决上述背景技术中存在的技术问题,本发明提供基于高光谱图像的尿液成分异常检测方法及系统,通过获取尿液样本的高光谱图像,分析出图像中所需的蛋白类物质的信息,处理图像的过程中,特征波长经过二次筛选,减少数据的维度,并能够平衡波长的多样性和相关性。
为了实现上述目的,本发明采用如下技术方案:
本发明的第一个方面提供基于高光谱图像的尿液成分异常检测方法,包括以下步骤:
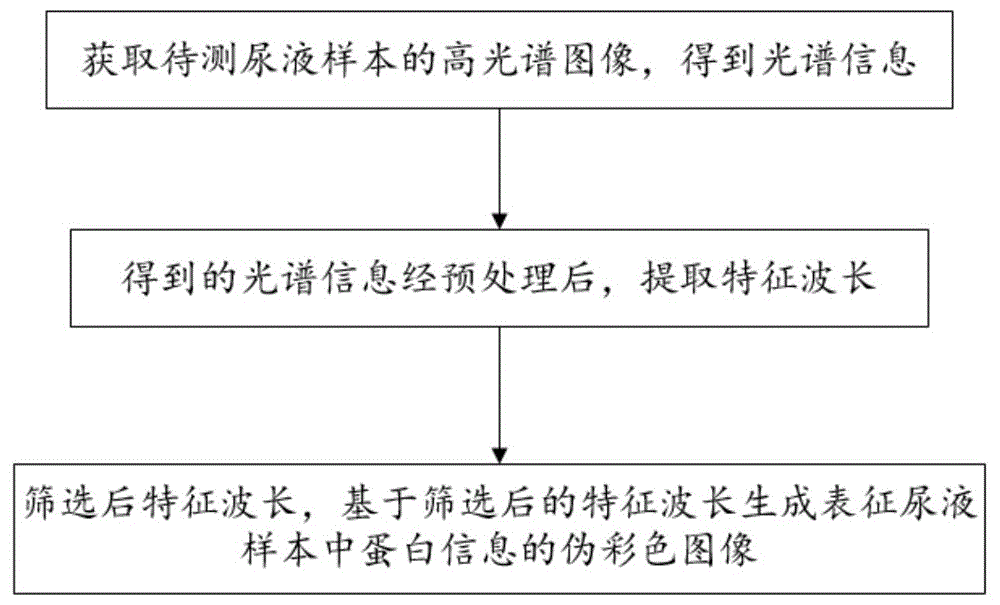
获取待测尿液样本的高光谱图像,并利用校准图像得到光谱信息;
得到的光谱信息经预处理后,提取特征波长;
在得到的特征波长中选择一个初始波长集作为特征集合的起点,从未包括在当前特征集合中的波长中选择一个波长,将其添加到当前集合中实现迭代,每次迭代后确定是否保留新添加的波长,直至满足设定迭代次数或设定需求,得到筛选后的特征波长,基于筛选后的特征波长生成表征尿液样本中蛋白信息的伪彩色图像。
进一步的,校准图像包括第一校准图像和第二校准图像;
第一校准图像为没有光源的图像,该图像包含暗电流的均值和标准差信息;
第二校准图像为在均匀光源下获取的白板图像,该图像包含不同波长下的反射率和敏感度信息。
进一步的,预处理,具体为,基于光谱阵的行对没一条光谱信息进行处理,消除光谱信息采集过程中的背景噪声、基线漂移和杂散光。
进一步的,得到的光谱信息经预处理后,提取特征波长,具体为,
基于权重二进制矩阵采样法将光谱数据进行随机组合,产生子数据集;
将得到的子数据集作为校正集模型进行回归分析;
分析比较若干个子模型的均方根误差和平均预测误差,取设定数量的模型中两值较低的子模型,求得每个波长在这些子模型中出现的次数,并重新定义该波长的权重;
重回归分析和重定义波长权重的过程来变换波长和权重值,当所有子模型的均方根误差和平均预测误差不再改变时,通过权重结果满足设定值的波长,得到原始光谱数据的特征波长。
进一步的,基于筛选后的特征波长生成表征尿液样本中蛋白信息的伪彩色图像,具体的:
设定尿液样本的异常类型与对应的蛋白信息;
根据蛋白信息中得到的特征波长与设定的异常类型进行模型训练;
基于训练完毕的模型输出表征尿液样本中蛋白信息的伪彩色图像,该图像与设定的尿液样本异常类型对应。
本发明的第二个方面提供实现上述方法所需的系统,包括:
图像采集模块,被配置为:获取待测尿液样本的高光谱图像,并利用校准图像得到光谱信息;
特征波长提取模块,被配置为:得到的光谱信息经预处理后,提取特征波长;
特征波长筛选模块,被配置为:在得到的特征波长中选择一个初始波长集作为特征集合的起点,从未包括在当前特征集合中的波长中选择一个波长,将其添加到当前集合中实现迭代,每次迭代后确定是否保留新添加的波长,直至满足设定迭代次数或设定需求,得到筛选后的特征波长,基于筛选后的特征波长生成表征尿液样本中蛋白信息的伪彩色图像。
本发明的第三个方面提供一种计算机可读存储介质。
一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现如上述所述的基于高光谱图像的尿液成分异常检测方法中的步骤。
本发明的第四个方面提供一种计算机设备。
一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现如上述所述的基于高光谱图像的尿液成分异常检测方法中的步骤。
与现有技术相比,以上一个或多个技术方案存在以下有益效果:
1、通过获取尿液样本的高光谱图像,分析出图像中蛋白类物质的信息,处理图像的过程中,特征波长经过二次筛选能够减少数据的维度,降低对计算机和存储器的资源消耗。
2、二次筛选的过程倾向于选择具有高变异性的波长,这有助于捕捉到特征数据,能够平衡波长的多样性和相关性,提高模型泛化能力,从而确保模型最终选取所需的信息。
3、通过提取尿液样本高光谱图像中每个像素的光谱值,结合筛选出的最佳特征波段,对特征波段或非特征波段赋予相应的更高或更低权重系数,以此通过伪彩色图像不同区域的颜色差异及深浅表示蛋白质含量和空间分布情况,最终生成的伪彩色图像利用色彩替代灰阶,能够提高人眼分辨率,补偿人眼的生理缺陷。
附图说明
构成本发明的一部分的说明书附图用来提供对本发明的进一步理解,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。
图1是本发明一个或多个实施例提供的基于高光谱图像的尿液成分异常检测整体过程示意图;
图2是本发明一个或多个实施例提供的基于高光谱图像的尿液成分异常检测的应用过程示意图。
具体实施方式
下面结合附图与实施例对本发明作进一步说明。
应该指出,以下详细说明都是示例性的,旨在对本发明提供进一步的说明。除非另有指明,本文使用的所有技术和科学术语具有与本发明所属技术领域的普通技术人员通常理解的相同含义。
正如背景技术中所介绍的,由于高光谱图像中除了包含被拍摄目标的信息以外还包含有光谱信息,虽然利用这一特性可以从图像中分析一些肉眼无法观察到的信息,但得到的数据维度过大,使得对计算机和存储器的需求较高。
因此,以下实施例给出基于高光谱图像的尿液成分异常检测方法及系统,以肾移植术后肾病复发检测期间所需的尿液检验为例,通过获取尿液样本的高光谱图像,分析出图像中有关肾移植术后肾病复发的相关蛋白类物质的信息,处理图像的过程中,特征波长经过二次筛选,减少数据的维度,并能够平衡波长的多样性和相关性。
实施例一:
如图1-图2所示,基于高光谱图像的尿液成分异常检测方法,包括以下步骤:
一、采集接受肾移植手术的受体的尿液,取其上清液制作为样本;
二、利用高光谱成像设备系统获取受体尿液样本的光谱信息:高光谱图像由紫外(波长范围10~380nm)高光谱成像系统获取;由于肾移植受体术后肾病复发会产生蛋白尿的症状,故主要波长集中在蛋白质的紫外特征波段200~380nm。在高光谱图像采集前需要进行对焦和黑白校准。
1.黑校准中,遮挡相机镜头获得黑暗图像,获得包含暗电流的均值和标准差等信息的黑校正帧。在实际成像过程中,黑校正帧和实际的成像帧相减,从而消除暗电流噪声的影响。
2.白校准中,相机镜头面向一个均匀光源拍摄一系列白板图像,捕获传感器在统一亮度下的响应。获得包含传感器对于不同波长下的反射率和敏感度等信息的白校正帧。在实际成像过程中,白校正帧校正原始的高光谱图像,消除非均匀性和光照差异的影响。
通过黑白校正,高光谱成像系统能够提供更准确和可靠的图像数据,以保证后续分析和应用的准确性和可重复性。
采集到受体尿液样本的光谱信息后,通过SNV(标准正态变量)对原始光谱数据进行预处理,消除光谱采集过程中存在的背景噪声、基线漂移和杂散光等干扰信号,降低模型的复杂性。SNV主要用来消除固体颗粒大小、表面散射以及光程变化对光谱信息的影响。SNV算法基于光谱阵的行对一条光谱进行处理:
三、利用iVISSA-IRIV模型进行特征波长提取。提取特征波长能够删除样本中关注成分以外的光谱信息,缩短运算时间,提高运算效率,增强模型稳定性。
iVISSA算法利用波段权重对整体和个体进行分析选,同时保证波段宽度以及间隔位置。
设光谱数据为X,样品个数为n,波长变量个数为p。其原理如下:
(1)采用权重二进制矩阵采样法( WBMS) 将X进行随机组合,产生子数据集x(k×p),其中0<k<n,权重列数为0.5,且x个数均为0.5k,保证了波长变量在运算时有相同的可能性;
(2)将得到的子数据集x作为校正集模型进行回归分析;
(3) 分析比较m个子模型的RMSECV值和RMSEP值,取k个模型中两值较低子模型,求得每个波长在这些子模型中出现的次数f
通过重复(2)和(3)过程来变换波长和权重值,当所有子模型的RMSECV值和RMSEP值误差不改变时,权重结果为1的波长构成原始光谱数据的特征波长,运行程序结束。
权重二进制矩阵采样法是一种随机抽样方法,通过使用二进制矩阵和样本权重来进行抽样。这种方法首先准备一个与样本数量相同大小的权重矩阵,然后根据样本的权重将其分配到矩阵中。接下来,通过生成随机数与权重矩阵进行比较,选择权重超过随机数的样本进行抽样。这样可以实现根据权重进行有偏向性的抽样,适用于各种抽样场景。
其中,RMSECV表示交叉验证中的均方根误差,用于评估在交叉验证过程中模型的预测误差。较小的RMSECV值表示模型的预测误差较小,性能较好;RMSEP表示模型在预测新样本时的平均预测误差大小,计算预测结果与实际观测值之间的均方根误差。RMSEP值越小,表示模型的预测能力越好。
IRIV是一种迭代保留信息变量以在多元校准中选择最优变量子集的策略。考虑随机组合产生的变量之间的相互作用,称为迭代保留信息变量。变量分为四类:强信息、弱信息、非信息和干扰变量。IRIV在每轮迭代中同时保留强和弱信息变量,直到不存在非信息和干扰变量,最后反向消除弱信息变量,将强信息变量作为特征变量。
在通过iVISSA法筛选的波长数据中选择一个初始波长集,作为特征集的起点,这些波长可以是iVISSA筛选出的最相关波长。通过IRIV方法迭代,逐步添加或者删除波长,步骤如下:
(1)每次迭代中,从未包括在当前特征集合中的波长中选择一个波长,将其添加到当前集合中;
(2)使用扩展的特征集合重新训练模型;
(3)每次迭代后使用均方根误差RMSE评估模型性能,并决定是否保留新添加的波长。如果新添加的波长显著提高模型性能则将其保留,否则将其删除。
当达到预定的迭代次数或者模型性能不再显著提升时终止IRIV并获得最终模型。
利用IRIV法对iVISSA法筛选出的波长进行二次提取,形成了iVISSA-IRIV变量选择混合方法,iVISSA方法倾向于选择具有高变异性的波长,这有助于捕捉到特征数据,IRIV方法则通过迭代过程,结合模型性能评估,更注重特征预测能力。结合两种方法可以平衡更选择波长的多样性和相关性,提高模型的泛化能力,从而确保模型最终选取最能代表肾病复发受体的样本信息。iVISSA-IRIV方法显著降低数据维度,减少计算和存储的需求,这对处理大型光谱数据集尤为重要。
由于上述方法通过筛选特征波段提高模型的可解释性,强调了对预测分类模型至关重要的波段,能够提升模型预测和分类准确性,可以利用这一特性,使得到的蛋白质信息与常见的异常类型对应起来,最终得到设定的异常类型。可以通过下列步骤实现:
设定尿液样本的异常类型与对应的蛋白信息;
根据蛋白信息中得到的特征波长与设定的异常类型进行模型训练;
基于训练完毕的模型输出表征尿液样本中蛋白信息的伪彩色图像,该图像与设定的尿液样本异常类型对应。
建立常见异常类型模型:肾移植受体术后常见的复发类型有:IgA,局灶性节段性肾小球硬化(FSGS),膜性等,受体在肾移植术后复发类型不同,其蛋白尿中主要成分也会不同,IgA患者尿液样本中以IgA蛋白为主,FSGS患者样本则以白蛋白为主,膜性患者样本以尿蛋白酶解产物UPR3为主要成分。
因此可根据不同类型的特征蛋白在特征波段的峰值差异,实现基于SVM分类模型的肾病复发常见病识别模型。SVM可以将高维的数据降维,从而减少特征的数量,消除一些噪音,有助于改善分类模型的性能,在本实施例中,基于SVM建立分类模型可以选择更具代表性的特征波段,有助于更好地区分不同类别。
其步骤如下:
1.对肾移植术后,受体发生的常见异常类型进行分类,同时不断采集新鲜尿液样本扩充数据库样本数量:采集足够的IgA,(FSGS),膜性和正常受体的尿液样本,使用SPXY算法(一种划分样本的算法)按照8:2划分训练集、测试集;SPXY算法在Kennard-Stone算法基础上发展而来,选择欧氏距离最远的两个样本进入训练集,再计算剩下的每个样本到训练集内已知样本的欧式距离,将拥有最大最小距离的待选样本放入训练集,保证训练集中样本按照空间距离分布;SPXY在计算样本间距离时能够将光谱和蛋白含量同时考虑,利用两种变量同时计算样品间距离以保证最大程度表征样本分布,有效地覆盖多维向量空间,增加样本间的差异性和代表性,提高模型稳定性。
2.提取各类类型的患者和未复发受体尿液样本的高光谱信息,基于SVM分类模型机器学习,建立识别模型:常见异常类型和正常受体样本的光谱信息峰值和峰值所在特征波长存在差异,故将已有样本按不同异常类型进行分类,每类都将所有像素点光谱平均值作为代表性光谱数据,选用SVM分类器。
具体建模步骤如下:
(1)收集并准备训练数据集,包括特征向量和相应的类别标签。特征进行适当的预处理;选择合适的特征并进行提取。
(2)将数据集划分为训练集和测试集(也可以使用交叉验证)。
(3)在训练集上使用SVM算法训练模型。在训练过程中,优化模型参数(权重和偏置)以最小化目标函数。线性SVM的目标是找到一个超平面,使得不同类别的样本能够在该超平面上有最大的边缘(Margin)。Margin是离超平面最近的样本点到超平面的距离。线性SVM目标函数:
当样本被正确分类时,Hinge Loss为0。当样本被错误分类时,Hinge Loss将为正数,其值随着误分类程度的增加而增加。SVM的决策函数是基于超平面的方程构建的,可以表示为:
(4)使用测试集评估模型的性能。可以计算准确率、精确度、召回率指标来衡量模型的效果。
3.保存模型,实现肾移植术后常见异常类型分类:通过对经验样本的深度学习,基于SVM分类模型,提取每一种不同异常类型样本的光谱信息特征,根据关键特征对未知样本进行判断。在临床应用上,当获得未知情况的肾移植受体尿液样本时,通过观察其高光谱特征波段特征信息,将其与各种分类结果进行比较,依据机器学习形成的分类模型由相似度高低,给出最可能的类型,从而提供建议。
生成伪彩色图像,可视化细胞内成分空间信息:伪彩色图像利用色彩替代灰阶,能够提高人眼分辨率,补偿人眼的生理缺陷。通过提取尿液样本高光谱图像中每个像素的光谱值,结合最佳特征波段选择模型,对特征波段或非特征波段赋予相应的更高或更低权重系数,以此通过伪彩色图像不同区域的颜色差异及深浅表示蛋白质含量和空间分布情况。在面向使用者的伪彩色图像模块中,通过含量数据能够更直观地向医生体现异常类型的严重程度,通过颜色深浅还可向病患及其家属展示诊断结果,提升医患交流效率。
实施例二:
实现上述方法的系统,包括:
图像采集模块,被配置为:获取待测尿液样本的高光谱图像,并利用校准图像得到光谱信息;
特征波长提取模块,被配置为:得到的光谱信息经预处理后,提取特征波长;
特征波长筛选模块,被配置为:在得到的特征波长中选择一个初始波长集作为特征集合的起点,从未包括在当前特征集合中的波长中选择一个波长,将其添加到当前集合中实现迭代,每次迭代后确定是否保留新添加的波长,直至满足设定迭代次数或设定需求,得到筛选后的特征波长,基于筛选后的特征波长生成表征尿液样本中蛋白信息的伪彩色图像。
实施例三:
本实施例提供了一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现如上述实施例一所述的基于高光谱图像的尿液成分异常检测方法中的步骤。
实施例四:
本实施例提供了一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现如上述实施例一所述的基于高光谱图像的尿液成分异常检测方法中的步骤。
以上实施例二至四中涉及的各步骤或网络与实施例一相对应,具体实施方式可参见实施例一的相关说明部分。术语“计算机可读存储介质”应该理解为包括一个或多个指令集的单个介质或多个介质;还应当被理解为包括任何介质,所述任何介质能够存储、编码或承载用于由处理器执行的指令集并使处理器执行本发明中的任一方法。
以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 基于高光谱图像的麻竹笋营养成分检测方法、系统和存储介质
- 一种基于高光谱图像的成分分析方法及系统