一种面向方志领域的开放知识三元组抽取方法及装置
文献发布时间:2024-04-18 20:01:23
技术领域
本发明涉及知识三元组抽取领域,尤其涉及一种面向方志领域的开放知识三元组抽取方法。
背景技术
方志知识化建设是指将方志书籍的信息以知识条目的方式整合,构建方志知识库,并通过该知识库对各行各业现状与发展进行分析、推导,衍生基于知识条目的应用。由于地方志“横排竖写”的体例特点,每个门类都从源头说起,客观上将各类事物内在联系进行了分割,在使用数据和资料上造成了一定交叉,不便于读者看到事物全貌或进行整体检索。近年来,自然语言处理技术的发展使得知识层面的研究和应用取得很大的进展。知识库打破了事物内在联系割裂的局限,以实体关系三元组及属性值的方式将异构数据整合起来,组成实体对象和语义的交互网络,为智能问答、推理、推荐提供了知识驱动的基础。
在知识库的构建过程中,如何高效自动地从海量文本中提取结构化信息成为了语言学家关注的问题,信息抽取技术成为研究的重点。研究面向方志语料的开放知识三元组抽取技术,有利于推动方志知识库建设,从而进一步总结历史中的经验教训、事件关联,为党和政府资政辅治提供镜鉴,将更加立体多维地展示方志存史、资政、育人的历史使命。
在文本信息抽取过程中,非结构化的文本被抽取为了“实体-关系-实体”三元组,形成了基本的单元知识,称之为实体关系三元组或知识三元组。按照目前的研究,实体关系一般是被表示为二元关系,即关系涉及头实体和尾实体。对于多元关系通常可以将其转换为多个二元关系进行表征。
最近似的技术方案:Wang C,Liu X,Song D.Language models are openknowledge graphs[J].arXiv preprint arXiv:2010.11967,2020.
该技术方法描述:知识图谱的构建方法通常需要人工辅助参与,但是人力成本太高;同时BERT等预训练模型通常在非常大规模的语料上训练,训练好的模型本身包含常识知识,这些知识可以促进上层的其他应用。该论文提出了一种无监督的Match and Map(MAMA)模型,来将预训练语言模型中包含的知识转换为知识图谱。
1.匹配(Match)
Match阶段主要是自动抽取三元组。对于输入的文本,使用开源工具抽取出实体,并将实体两两配对为头实体和尾实体,利用预训练模型的注意力权重来提取实体对的关系。通过beam search的方法搜索多条从头实体到尾实体的路径,从而获取多个候选的三元组。再通过设置一些限制规则过滤掉不符常理的三元组,即得到用于构建知识图谱的三元组。
2.映射(Map)
Map阶段主要是将Match阶段抽取到的三元组映射到知识图谱中去。利用成熟的实体链接和关系映射技术,将三元组映射到已有的固定schema图谱中。对于部分映射或完全不匹配的三元组,就构建开放schema的知识图谱,并最后将这两类知识图谱融合,得到一个灵活的开放性知识图谱。
传统的方志信息抽取和知识抽取工作主要集中在封闭域:知识体系明确、任务场景明确,实体类型和关系类型都是预先明确定义的。不仅对手工标注的数据有很高的需求,而且需要大量专家知识构建领域本体和关系类别。
传统封闭式信息抽取仅适用从于同领域的文本语料中抽取封闭的、有限的、预先定义的实体关系。
随着时代发展,文本中关系类别越来越多样,新的关系类别不断出现,预先设定的实体和关系类型也会限制对文本信息的充分获取。封闭式知识三元组抽取面临知识表达完整度不高、召回率低和领域迁移困难的问题,限制了复杂应用场景和未知任务需求下的知识服务性能。
在缺乏大规模方志知识抽取标注语料的情况下,封闭式实体关系三元组抽取困难,知识驱动的领域应用研究也非常缺乏。
发明内容
本发明目的在于针对现有技术的不足,提出一种面向方志领域的开放知识三元组抽取方法。开放知识抽取无需事先预定义实体关系抽取体系和任何人工输入,直接生成候选实体并抽取句子中的关系指示词来隐式表达关系类型,减少了对领域专家的依赖,同时可以脱离训练集的局限进行全量知识抽取。
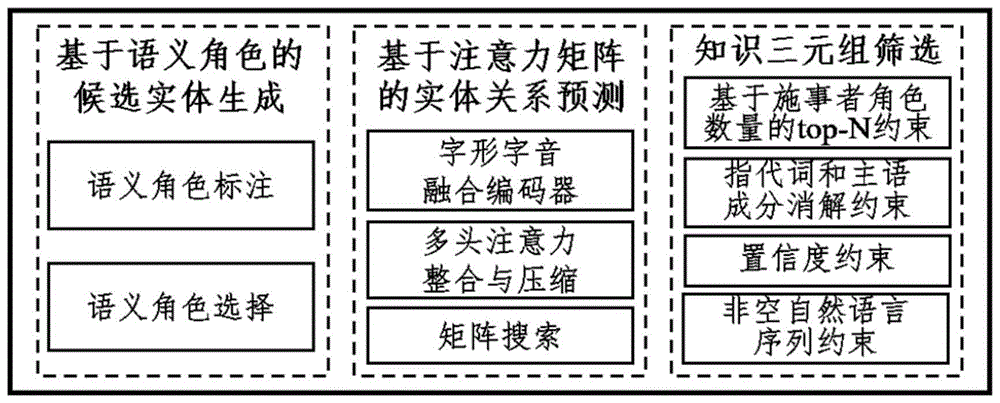
本发明的目的是通过以下技术方案来实现的:一种面向方志领域的开放知识三元组抽取方法,该方法包括以下步骤:
(1)基于语义角色的候选实体生成:对于方志领域的文本语句,找到谓语并将其作为核心词,用语义角色描述各论元与谓语间的关系并进行标注,包括核心语义角色和附属语义角色;然后对语义角色标签进行选择从而对头尾实体在语义层面进行筛选,得到语义角色的候选实体;
(2)基于注意力矩阵的实体关系预测:采用ChineseBERT预训练模型作为方志文本的基础编码器,将汉字的字形与拼音信息融入到中文语料的预训练过程;在底层的融合层融合了除字嵌入之外的字形嵌入和拼音嵌入;然后提取最后一层注意力权重采用平均策略,对多个头的最后一层注意力矩阵权值求平均,并基于语义角色标注及选择的结果求取对应子矩阵即注意力矩阵权值求平均之后的二维矩阵的平均值,得到实体关系矩阵,采用基于宽度优先搜索的波束搜索算法来确定关系词,得到若干实体关系三元组;
(3)知识三元组筛选:通过基于施事者数量的Top-N约束、指代词和主语成分消解约束、置信度约束和非空自然语言序列约束对实体关系三元组进行筛选,得到筛选后的实体关系三元组。
进一步地,步骤(1)中,根据Chinese Proposition Bank(CPB)语料的语义角色标签对方志语料进行标注并进行筛选后得到ARG0、ARG1、ARG2、ARG3、ARG4及ARGM-TMP共6类语义角色作为候选实体,其中,ARG0为施事者,是谓语所表达动作或行为的发出者,由名词和名词性短语充当,或者用定语修饰词、指代词作为施事者的成分;ARG1为受事者,是谓语所表达动作和行为的承受者,受谓语影响;ARG2、ARG3、ARG4为随谓语确定的主要语义角色,表示动作的开始、结束;方志中大量篇幅是按照时间脉络编纂的,用时间ARGM-TMP作为知识三元组成立的约束条件。
进一步地,步骤(2)中,对多个头的最后一层注意力矩阵权值求平均具体如下:
其中,N
进一步地,注意力矩阵权值求平均使多头注意力从多维矩阵整合成为二维矩阵,然后对字级矩阵按照语义角色标注及选择的结果进行一一对应取子矩阵平均值,得到实体关系矩阵。
进一步地,所述基于施事者数量的Top-N约束具体为:假定句子想要传达的信息个数Nt和语义角色为ARG0的施事者数量Na正相关,则Nt=k*Na;Top-N按照Nt个候选三元组的置信度排序,k表示施事者角色对抽取数量的相关程度,根据实际抽取效果自定义,k=1时,对输入文本抽取出等同于施事者角色数量的三元组,k取值越大,从输入文本中抽取的三元组越多。
进一步地,所述指代词和主语成分消解约束具体为:对于候选实体存在指代词或主语成分缺失的句子,需对语料进行指代消解。
进一步地,所述置信度约束具体为:实体关系三元组的置信度需高于指定阈值以过滤没有意义的三元组,阈值根据抽取结果进行定义。
进一步地,所述非空自然语言序列约束具体为:实体关系三元组中关系词不可为空字符或空列表,且由输入文本中的连续自然语言序列构成。
第二方面,本发明提供了一种面向方志领域的开放知识三元组抽取装置,包括存储器和一个或多个处理器,所述存储器中存储有可执行代码,所述处理器执行所述可执行代码时,用于实现所述的面向方志领域的开放知识三元组抽取方法的步骤。
第三方面,本发明提供了一种计算机可读存储介质,其上存储有程序,该程序被处理器执行时,实现所述的面向方志领域的开放知识三元组抽取方法的步骤。
本发明的有益效果:本发明针对方志知识化水平低、知识利用率有限的现状,研究面向方志领域的中文开放知识三元组抽取方法,为任务场景不明确时做好全量三元组抽取的基础性支撑;研究实体关系的无监督预测方法,从而减少对专家领域知识的依赖,解决方志缺乏高质量标注语料库的冷启动问题,具体包括以下优点:
1.实体要求宽松,语义信息完整。在生成候选实体时,本方法对文本中的实体的边界和类型要求更加宽松,修饰词、约束语也被保留在候选实体中,从而实现语义信息更完整的三元组抽取。对于实体的类型,也不要求是领域术语和通用命名实体类型。尤其对于尾实体的约束更为宽泛,长文本片段也可以成为候选实体。
2.隐式表达关系,抽取关系指示词。在封闭式信息抽取中,由于数据集标注的限制,往往只能抽取既定且有限的关系类型。本方法可以直接使用句子中的关系指示词来隐式表达关系类型。这些关系指代词虽然不是领域专家设置的精准关系词,但是更能体现文本风格特征以及适应关系变化、关系新增的应用场景。
3.内容抽取灵活,无需构建本体。本方法的灵活性在于没有严格正确的三元组抽取答案,对于抽取结果的倾向可以通过设计抽取方法中的各个子模块灵活实现。也正因为无需构建领域本体,本方法有一定的各类语料通用性。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图做简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动前提下,还可以根据这些附图获得其他附图。
图1为开放知识三元组抽取方法总体框架图
图2为开放知识三元组抽取流程图。
图3为多头注意力矩阵整合示意图。
图4为本发明提供的一种面向方志领域的开放知识三元组抽取装置的结构图。
具体实施方式
以下结合附图对本发明具体实施方式作进一步详细说明。
如图1所示,本发明提供的面向方志领域的开放知识三元组抽取方法,用以解决以下问题:给定句子s=[ch
其中h
面向方志知识化建设,本发明方法将知识抽取定义为(实体,关系,实体)三元组抽取。实体关系三元组形成了方志知识库的基本单元知识,也可以表示为一个SPO三元组(Subject,Predicate,Object)。挖掘并结构化蕴含在文本中的知识三元组是构建知识库的基础。
开放知识抽取无需事先预定义实体关系抽取体系和任何人工输入,直接生成候选实体并抽取句子中的关系指示词来隐式表达关系类型。无论是头实体、尾实体甚至是关系通常都是直接来源于文本中片段,即关系类型不再是预先定义,而是使用称之为关系指示词的文本片段来替代。
对于输入的文本,根据选择的6种语义角色抽取出候选实体,并根据位置关系将每两个实体配对为头实体和尾实体。从汉语特征出发,结合语义角色,利用字形字音编码器的注意力权重矩阵来搜索实体对的关系。通过矩阵整合、压缩、搜索,获取多个候选的三元组。最后结合施事者角色数量等约束条件对实体关系三元组进行筛选,得到较高质量又主题相关的知识三元组。
步骤1:基于语义角色的候选实体生成
汉语是缺乏词形态变化的语言之一,中文方志领域实体有表述复杂、常用词兼类现象严重、语言学划分标准不统一的特点。本发明方法基于语义角色的候选实体生成方法,将语义信息融入候选实体的生成,即通过语言模型对句子进行语义角色标注,根据语义角色标签生成开放三元组的候选实体,从而提取出具有语义依存关系的句子主干要素。
具体来说,语义角色是构建句子意义的关键因素。语义角色(Semantic roles,SR)在生成语法中称为题元或题元角色,是语义学上的一个概念,其理论基础来源于Fillmore提出的格语法,指短语或句子中的名词短语即论元与谓语中心词之间的语义关系。例如历史上,“云南长期保持着封闭、低产的自给农业经济水平”,“云南”就是“保持”的行为者,即施事;“封闭、低产的自给农业经济水平”就是“保持”的对象,即受事。相对于传统通过词性标注对名词进行迭代搜索生成名词块(Noun_chunks)作为候选实体的方法,本发明方法既能有效从方志语料中获取主题突出、关系聚焦、条件约束的首尾实体对,也能减少数据噪声的影响。
(1)语义角色标注
语义角色标注其实质上是在句子级别进行浅层的语义分析,这一层语义标注主要处理汉语动词的谓语结构及其名词化。谓语是整个句子的核心词,一般是动词或者形容词。对于输入文本语句,语义角色标注(Semantic Role Labeling,SRL)首先找到谓语并将其作为核心词,用语义角色描述各论元与谓语间的关系,包括核心语义角色和附属语义角色。
英文的SRL标注语料库有FrameNet和PropBank,中文SRL常用宾州大学汉语语义角色标注库(Chinese Proposition Bank,CPB)。如表1所示,CPB语料库中共有5类核心语义角色即核心论元(Core argument),表示跟谓语直接相关,用ARGN来表示,其中N∈{0,1,2,3,4,5}。除了核心语义角色,CPB语料库还有14类附属语义角色即语义修饰语(Semanticadjunct),表示可独立存在的不与谓语直接相关的论元,用ARGM-XXX来表示,例如时间、目的、程度、范围等等。
表1语义角色标签格式表
本发明方法采用Hanlp发布的基于Biaffine+CRF的SpanBIO语义角色标注开源模型CPB3_SRL_ELECTRA_SMALL作为标注工具,根据Chinese Proposition Bank(CPB)语料的语义角色标签对方志语料进行标注,包括5类核心语义角色ARG0-ARG4,和14种附加语义角色,共计19种语义角色。具体的语义角色释义如表2所示。
表2 CPB语料19种语义角色标注表
(2)语义角色选择
知识三元组的头尾实体是实体关系预测的基础,候选实体的生成对三元组的质量和知识的指向性有决定性作用。目前的开放实体和关系抽取存在最主要问题为无意义三元组及错误三元组对关键信息的干扰,并带来数据噪音。就方志语料而言,对方志文本按照CPB标准进行语义角色标注可以获得核心语义角色及附属角色共计19类。为了捕获核心信息并增强主题相关度,本发明方法通过对语义角色标签进行选择从而对头尾实体在语义层面进行筛选,通过对核心语义角色的选择从方志语料中生成主题突出、关系聚焦、条件约束的低噪音、低冗余的首尾实体对,减少数据噪声的影响。
语言研究和实践都表明结构与意义是不可分离的,话语信息主要是由核心语义角色传递的。从句法结构、语义标注的角度出发,结合方志语料陈述句、肯定句和主动句多、语言表达凝练准确且语法上主谓关系和动宾关系多的特点,本发明方法选取ARG0、ARG1、ARG2、ARG3、ARG4及ARGM-TMP共6类语义角色作为候选实体。
ARG0(施事者)是谓语所表达动作或行为的发出者,一般是由名词和名词性短语充当,定语修饰词、指代词等也可以作为施事者的成分。ARG1(受事者)是谓语所表达动作和行为的承受者,受谓语影响。ARG2、ARG3、ARG4为随谓语确定的主要语义角色,可以表示动作的开始、结束等。方志大量篇幅是按照时间脉络编纂的,ARGM-TMP(时间)不仅是重要候选实体,更是大量知识三元组成立的约束条件。
在CPB语料中每个谓语及语义角色都进行了详细标注,达19种的语义角色类型加大了语义角色标注的难度。事实上,不同语义角色的标注准确率不尽相同,目前的模型往往能准确区分句子的核心语义角色(如施事、受事)和表达规则、特征突出、实体类型识别容易的附属角色(如时间、地点)。
如上所述,在开放知识三元组抽取的候选实体生成中,结合中文方志的语言学特征和语义角色标注特点,本发明方法选取如表3所示的6类语义角色。
表3本发明方法选择的6种语义角色
步骤2:基于注意力矩阵的无监督实体关系预测
(1)字形字音融合编码器
目前大规模预训练模型已经成为复杂自然语言处理任务的基础。除了英语自然语言处理任务外,对汉语也很有效。但预训练模型不管是BERT、RoBERTa、GPT2、GPT3,还是改变预训练方法从Mask Language Model到Prompt Pretraining,本质都是以英语为基础设计的。
汉字是一种典型的意音文字,从其起源来看,它的字形本身就蕴含了一部分语义。方志是记载特定区域内的地情、风俗、物产、财税、贸易、气象、水运、检疫、畜牧、及诗文著作等的史志,所载内容横陈百业、纵贯古今、取材宏富,其汉语特征尤为突出。从字形来看,比如,《地理志》中常见“花草藤蔓”都有偏旁草字头,这表明它们都与植物有关;“蟒蛇蜥蜴”都有偏旁“虫”,这表明它们都有虫类有直接关联。从读音来看,汉字的拼音也能在一定程度上反映一个汉字的语义,起到区别词义的作用。比如,《旅游志》中常见“乐”字有两个读音,yuè与lè,输入一个多音字,模型是无法得知它所代表的具体含义,这时候就需要额外的读音信息进行去编码。
从汉字本身字形和拼音的两大特性出发,本发明方法沿用Sun等人的工作,从方志语料的汉语特征出发,采用ChineseBERT预训练模型作为方志文本的基础编码器,将汉字的字形与拼音信息融入到中文语料的预训练过程。在底层的融合层(Fusion Layer)融合了除字嵌入(Char Embedding)之外的字形嵌入(Glyph Embedding)和拼音嵌入(PinyinEmbedding)。
(2)多头注意力整合与压缩
为了从注意力矩阵中搜索出实体对的唯一关系,需要将多个不同的头注意力矩阵进行整合。注意力矩阵编码了丰富的语料库语言学特征,Ramsauer等人研究发现较底层的注意力权重一般是表层的低级语言特性,与事实知识相关性较小,句法信息特征在注意力矩阵的中间层,而语义信息特征往往在最后几层网络。
为了捕获更多的语义信息,本发明方法提取最后一层注意力权重。本发明方法采用平均策略,对多个头的最后一层注意力矩阵权值求平均,如图2所示,具体定义如下:
其中,N
注意力整合使多头注意力从多维矩阵整合成为二维矩阵。为了将语义角色和候选实体信息融入二维注意力矩阵中,本发明方法基于语义角色的矩阵压缩算法对矩阵进一步压缩。同样采取求平均的策略,对字级矩阵按照上文中语义角色标注及选择的结果进行一一对应取子矩阵平均值,得到实体关系矩阵。
(3)矩阵搜索
目前的研究已经证明大规模的预训练语言模型如GPT2和BERT等模型中存储了从大规模高质量语料上获得的部分关系事实和知识。注意力矩阵反映了预训练语言模型从大数据中习得的语义和统计信息。近期的研究MAMA和Deepex模型都尝试对注意力矩阵进行知识挖掘,并取得了超越sota的效果。
本发明方法通过在大规模汉语语料上预先训练好的ChineseBERT中提取注意力权重来预测实体间关系r,其中首尾候选实体基于语义角色获得,注意力权重矩阵来自对ChineseBERT模型的多头注意力进行整合与压缩。为了降低时间复杂度同时有效的对实体关系进行预测,本方法采用基于宽度优先搜索的波束搜索算法来确定关系词。
步骤3:知识三元组筛选
对于含有n个候选实体的输入,通过对矩阵的波束搜索可以抽取出:
MAMA模型为英文知识抽取提出了3种三元组筛选方式,分别为置信度约束、关系词连续约束和关系词频率约束。Deepex使用Ranking排序模型在英文实体关系抽取中实现了Top-k约束。本发明方法认为低频率的关系词也有一定意义,此外输入语句表达的有价值的信息个数与句子的语义角色数量紧密相关。恰当的约束条件可以筛选出高质量、高信息密度、高主题相关度的知识三元组。因此本方法根据方志语料的文本风格特征,针对方志领域的中文开放知识抽取特点,提出以下4种约束,具体如表4所示。
表4知识三元组筛选规则表
基于以上四种条件约束,对步骤2中得到的实体关系三元组进行筛选,得到筛选后的实体关系三元组。
与前述面向方志领域的开放知识三元组抽取方法的实施例相对应,本发明还提供了面向方志领域的开放知识三元组抽取装置的实施例。
参见图4,本发明实施例提供的一种面向方志领域的开放知识三元组抽取装置,包括存储器和一个或多个处理器,所述存储器中存储有可执行代码,所述处理器执行所述可执行代码时,用于实现上述实施例中的面向方志领域的开放知识三元组抽取方法。
本发明面向方志领域的开放知识三元组抽取装置的实施例可以应用在任意具备数据处理能力的设备上,该任意具备数据处理能力的设备可以为诸如计算机等设备或装置。装置实施例可以通过软件实现,也可以通过硬件或者软硬件结合的方式实现。以软件实现为例,作为一个逻辑意义上的装置,是通过其所在任意具备数据处理能力的设备的处理器将非易失性存储器中对应的计算机程序指令读取到内存中运行形成的。从硬件层面而言,如图4所示,为本发明面向方志领域的开放知识三元组抽取装置所在任意具备数据处理能力的设备的一种硬件结构图,除了图4所示的处理器、内存、网络接口、以及非易失性存储器之外,实施例中装置所在的任意具备数据处理能力的设备通常根据该任意具备数据处理能力的设备的实际功能,还可以包括其他硬件,对此不再赘述。
上述装置中各个单元的功能和作用的实现过程具体详见上述方法中对应步骤的实现过程,在此不再赘述。
对于装置实施例而言,由于其基本对应于方法实施例,所以相关之处参见方法实施例的部分说明即可。以上所描述的装置实施例仅仅是示意性的,其中所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部模块来实现本发明方案的目的。本领域普通技术人员在不付出创造性劳动的情况下,即可以理解并实施。
本发明实施例还提供一种计算机可读存储介质,其上存储有程序,该程序被处理器执行时,实现上述实施例中的面向方志领域的开放知识三元组抽取方法。
所述计算机可读存储介质可以是前述任一实施例所述的任意具备数据处理能力的设备的内部存储单元,例如硬盘或内存。所述计算机可读存储介质也可以是任意具备数据处理能力的设备的外部存储设备,例如所述设备上配备的插接式硬盘、智能存储卡(Smart Media Card,SMC)、SD卡、闪存卡(Flash Card)等。进一步的,所述计算机可读存储介质还可以既包括任意具备数据处理能力的设备的内部存储单元也包括外部存储设备。所述计算机可读存储介质用于存储所述计算机程序以及所述任意具备数据处理能力的设备所需的其他程序和数据,还可以用于暂时地存储已经输出或者将要输出的数据。
上述实施例用来解释说明本发明,而不是对本发明进行限制,在本发明的精神和权利要求的保护范围内,对本发明作出的任何修改和改变,都落入本发明的保护范围。
- 一种可折叠式桥梁桁架检查车
- 安装在桥梁检查车桁架内的可升降检查平台