一种基于密度峰值的高维真实场景下的聚类方法、系统及存储介质
文献发布时间:2023-06-19 12:05:39
技术领域
本发明涉及机器学习和数据挖掘技术领域,尤其涉及一种基于密度峰值的高维真实场景下的聚类方法、系统及存储介质。
背景技术
聚类分析是机器学习和数据挖掘领域重要的研究方向之一,旨在分析数据的分布、研究数据的特征,发现数据潜在的内部结构。它在数据探索和机器学习中扮演着重要角色,并广泛应用于推荐系统、目标群体分割、商业智能等领域,同时聚类算法也常作为辅助算法应用到各类研究领域,如计算机视觉、隐私保护、自然语言处理等领域。
发表在2014年的密度峰值聚类算法是一种简单并且高效的算法,由于算法易于执行和高扩展性,它被广泛应用到各类实际任务中。但算法仍存在一些缺陷,如密度度量不合理、聚类中心代表性低、人工选取聚类中心、参数敏感等问题。
合理的中心位置可以代表物体或空间的几何分布。在聚类分析领域,聚类中心是聚类的骨架,选取合适的聚类中心可有效表征簇的分布结构并提高聚类精度。随着学者们不断提出的聚类算法,聚类中心的选取方式(技术)也随之改进,如基于随机选取的K-means、FCM算法;基于迭代优化的SP-MI-FCM、FCM-AIC算法;基于统计分布和阈值截断的Str-FSFDP、DC-MDACC算法;基于决策图的DPC、LPC、CDP算法。
现有的中心选取方法多存在参数敏感、参数过多、过于依赖先验知识、人工参与(手动选取)等问题,使聚类中心的选取产生偏差,导致聚类精度不高。如何准确选取聚类中心成为提高聚类精度的关键。
以K-means、FCM为代表的基于划分的聚类算法采用随机选取策略初始化聚类中心,并不断进行聚类中心更新和对象划分,直至目标函数收敛,完成聚类。其中,FCM算法引入了模糊理论,将隶属度应用于对象划分过程,其聚类结果好于K-means算法。由于聚类中心初始化和计算方式不合理,使得此类算法无法有效处理高维、非球形簇。
以DBSCAN为代表的基于密度的聚类算法将核心对象视为广义上的聚类中心,将满足可达条件的核心对象连通,形成聚类。算法可识别任意形状的簇,但算法采用固定半径和阈值参数计算密度,使算法无法有效处理多密度、高维聚类,同时参数取值缺少先验知识参考。
以DPC为代表的基于密度峰值的聚类算法以密度等变量为依据,建立决策图,以人工方式选择密度峰值对象作为聚类中心,决策图的使用提高了聚类中心选取精度。其中,DPC与CDP算法采用全局性质的截断距离度量对象密度,对于多密度数据集,不合理的参数设置将造成对象划分错误的连锁反应,最终影响聚类精度;LPC算法将数据集视为加权无向图,使用拉普拉斯中心性表征对象密度,避免了密度参数设置不合理带来的干扰,但算法的密度度量方法依赖于传统的统计模型,对于高维、多密度数据集,其密度度量可能出现偏差,进而影响聚类中心在决策图中的聚集位置,最终导致聚类效果并不理想。
为了预估聚类中心的数量,减少聚类中心获取过程对参数的依赖,FCM-AIC与SP-MI-FCM算法给定聚类中心数量的取值范围,采用证据积累思想反复运行FCM算法,合并隶属度形成累计隶属度矩阵;通过对累积隶属度矩阵进行图切分的方式获取聚类中心数量。FCM算法的中心初始化策略决定了隶属度矩阵会存在偏差,导致FCM-AIC与SP-MI-FCM算法获取的聚类中心数量并不稳定。
DC-MDACC与Str-FSFDP算法采用线性回归和残差分析技术,将未在置信区间的对象视为聚类中心,并将剩余对象按照密度峰值聚类的划分原则进行划分。算法可自动选取聚类中心,但选取过程极易受置信因子参数的影响,导致聚类结果并不理想。
发明内容
为解决现有的聚类方法无法高效处理高维真实数据以及聚类中心选取偏差导致的聚类精度较低的问题,以聚类中心的空间分布特征为理论依据,本发明提供了一种基于密度峰值的高维真实场景下的聚类方法CSMCA,该聚类方法通过提出的无参数局部核密度计算方法度量对象密度,并结合提出的边界度计算方法建立聚类中心选取模型CSM来确定聚类中心,最后将剩余对象按划分原则进行分派,完成聚类任务。
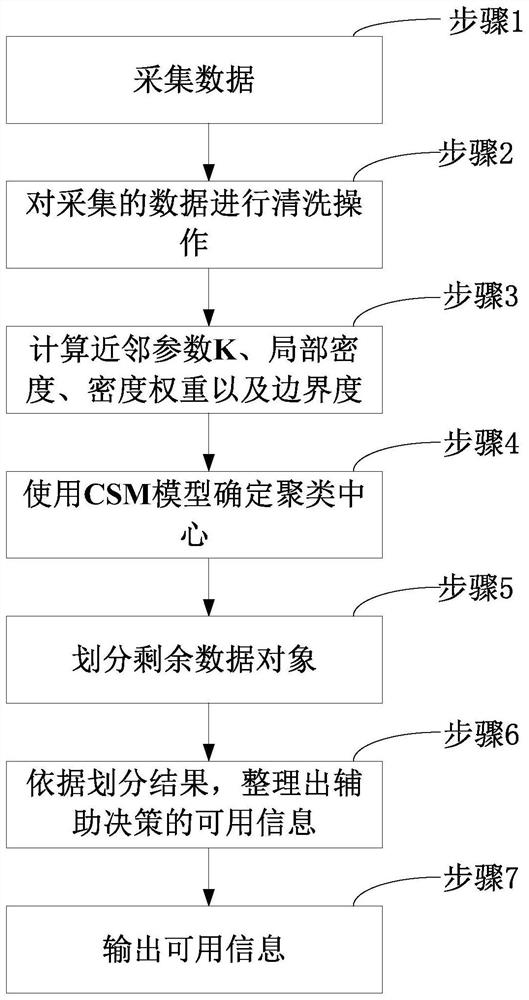
本发明提供了一种基于密度峰值的高维真实场景下的聚类方法,包括如下步骤:
步骤1:采集数据;
步骤2:对采集的数据进行清洗操作;
步骤3:计算近邻参数K、局部密度、密度权重以及边界度;
步骤4:使用CSM模型确定聚类中心;
步骤5:划分剩余数据对象;
步骤6:依据划分结果,整理出辅助决策的可用信息;
步骤7:输出可用信息。
作为本发明的进一步改进,在所述步骤3中,将k近邻作为指数核函数的采样空间,形成局部密度,定义如下:设x∈D,对象x的局部密度den(x)公式如下:
den(x)=∑
其中dist(x,y)为对象x与y的欧氏距离,knn(x)为对象x的k近邻集合。
作为本发明的进一步改进,在所述步骤3中,近邻参数K的自适应计算过程为:首先将循环变量T的初始值设置为1,递增步长为1;然后迭代计算对象的T近邻集合以及互近邻集合,直至达到稳定状态:对象的互近邻集合大小不再变化,此时对象的互近邻个数已充分表征其周围的分布情况;最后将稳定状态时对象的互近邻个数的均值作为k近邻参数的取值。
作为本发明的进一步改进,在所述步骤3中,对象x的边界度BD(x)计算公式如下:
sc(x)表示偏斜度,偏斜度sc(x)计算公式如下:
作为本发明的进一步改进,在所述步骤3中,对象x的密度权重W(x)计算公式如下:
W(x)=den(x)*δ(x) (5)
其中,δ(x)表示x与高密度数据对象之间的最小距离。
作为本发明的进一步改进,在所述步骤4中,首先,CSM模型依据边界度和占比因子λ提取核心对象,形成集合core_object_set,基于图的思想,建立核心对象的互近邻关系,形成互近邻关系图knn_graph,通过遍历算法计算连通区域数量,即为聚类中心数量cluster_no,最后结合聚类中心在密度权重降序序列中的位置分布,确定期望的聚类中心,形成集合cluster_center_set。
本发明还提供了一种基于密度峰值的高维真实场景下的聚类系统,包括:
采集模块:用于采集数据;
清洗模块:用于对采集的数据进行清洗操作;
变量计算模块:用于计算近邻参数K、局部密度、密度权重以及边界度;
处理模块:用于使用CSM模型确定聚类中心;
划分模块:用于划分剩余数据对象;
整理模块:用于依据划分结果,整理出辅助决策的可用信息;
输出模块:用于输出可用信息。
作为本发明的进一步改进,在所述变量计算模块中,将k近邻作为指数核函数的采样空间,形成局部密度,定义如下:设x∈D,对象x的局部密度den(x)公式如下:
den(x)=∑
其中dist(x,y)为对象x与y的欧氏距离,knn(x)为对象x的k近邻集合;近邻参数K的自适应计算过程为:首先将循环变量T的初始值设置为1,递增步长为1;然后迭代计算对象的T近邻集合以及互近邻集合,直至达到稳定状态:对象的互近邻集合大小不再变化,此时对象的互近邻个数已充分表征其周围的分布情况;最后将稳定状态时对象的互近邻个数的均值作为k近邻参数的取值;
对象x的边界度BD(x)计算公式如下:
sc(x)表示偏斜度,偏斜度sc(x)计算公式如下:
对象x的密度权重W(x)计算公式如下:
W(x)=den(x)*δ(x) (5)
其中,δ(x)表示x与高密度数据对象之间的最小距离。
作为本发明的进一步改进,在所述处理模块中,首先,CSM模型依据边界度和占比因子λ提取核心对象,形成集合core_object_set,基于图的思想,建立核心对象的互近邻关系,形成互近邻关系图knn_graph,通过遍历算法计算连通区域数量,即为聚类中心数量cluster_no,最后结合聚类中心在密度权重降序序列中的位置分布,确定期望的聚类中心,形成集合cluster_center_set。
本发明还提供了一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序配置为由处理器调用时实现本发明所述的聚类方法的步骤。
本发明的有益效果是:本发明解决了参数设置不合理导致的密度度量失衡问题,解决了中心选取偏差和参数敏感的问题,且具有良好的鲁棒性,可以对含有噪声的多密度和高维数据集进行有效的聚类,并具有较高的精度。
附图说明
图1(a)为Syn的分布情况图;
图1(b)、(c)、(d)分别给出了不同k值下密度的热量分布图,在图1(b)中K=2,在图1(c)中K=9,在图1(d)中K=75;
图2(a)至图2(f)给出了各算法在不同参数取值下聚类中心获取情况的示意图,其中,图2(a)为4k2-far,图2(b)为Aggregation,图2(c)为Heart Disease,图2(d)为CylinderBands,图2(e)为Jain,图2(f)为Japanese;
图3是本发明的方法流程图。
具体实施方式
本发明公开了一种基于密度峰值的高维真实场景下的聚类方法CSMCA。方法以提出的无参数局部核密度计算方法和边界度度量方法为依据,建立了聚类中心选取模型Clustering Center Selection Model(CSM);并按照密度峰值聚类的划分原则,将剩余对象划分到相应的簇中,形成最终聚类。在合成数据集和真实数据集上的实验结果验证了聚类中心选取模型和该方法的有效性。与同类算法相比,该方法具有较高的聚类精度。
本发明的聚类方法的创新点如下:(1)提出了一种无参数局部核密度计算方法;(2)提出了一种对象边界度的计算方法,并建立了聚类中心选取模型。
下面介绍本发明的相关定义
密度度量分析:
对象的密度计算实质(本质上)是对数据对象周围分布情况的采样,采样技术可分为静态采样和动态采样。超球采样、立方采样、网格采样属于静态采样技术,其思想是以定长邻域作为采样半径,在对象周围形成采样空间,将采用空间中的对象个数作为对象密度。对于多密度或高维数据,对象周围的分布相对稀疏,静态采样技术难以设置合适大小的采样半径,造成对象的分布特征度量不准确,进而影响聚类结果。
静态采样技术只适用于处理低维、分布均匀的数据,而动态采样可以根据对象的分布情况动态定义采样空间的形状和大小。k近邻采样是动态采样,它总是提取k个最近的对象形成采样空间。由于对象分布的随机性,对象的k近邻采样空间为不规则的多边体,它真实的反映了对象周围的分布情况,从而可以准确的表征对象的密度。本发明结合核密度估计思想,将k近邻作为指数核函数的采样空间,形成局部核密度,定义如下:
定义1.(局部密度)设x∈D,对象x的局部核密度den(x)公式如下:
den(x)=∑
其中dist(x,y)为对象x与y的欧氏距离,knn(x)为对象x的k近邻集合。
虽然k近邻空间可以有效的度量对象密度,但近邻参数k的取值难以确定。若k值选取过小,则采样不充分,(K近邻空间)无法表征对象的真实分布;k值选取过大,则退化为全局采样,所有对象的采样空间(K近邻空间)几乎一致。选取合适的k值是准确进行密度度量的关键。基于社交网络中真正朋友的思想,本发明提出了一种近邻参数k的自适应计算方法。对于对象x、y,若的x近邻中存在y,y的k近邻中存在x,则对象x、y具有互近邻关系,表示对象间的性质相似。因此,对象的互近邻个数可以表征其周围的分布情况。
基于此,k值的自适应计算过程为:首先将循环变量T的初始值设置为1,递增步长为1;然后迭代计算对象的T近邻集合以及互近邻集合,直至达到稳定状态:对象的互近邻集合大小不再变化,此时对象的互近邻个数已充分表征其周围的分布情况;最后将稳定状态时对象的互近邻个数的均值作为k近邻参数的取值,计算步骤如表1所示:
表1参数k的自适应计算过程
以数据集Syn为例,该数据集由合成数据集Compound提取部分对象形成,共有83个对象,分为两个簇,靠近簇中心的对象分布稠密,外围的对象分布稀疏。图1(a)显示了Syn的分布情况,图1(b)、(c)、(d)分别给出了不同k值下密度的热量分布图。如图1(b)所示,当k取值过小时,其(K近邻空间)采样空间过小,不能充分获取对象的分布特征;如图1(d)所示,当k取值过大时,采样空间(K近邻空间)几乎覆盖全部对象,核心与非核心对象的密度差异变小,导致密度度量存在偏差;如图1(c)所示,本发明提出的局部密度计算方法自适应计算了参数k,由K近邻形成的采样空间准确获取了对象的周围分布特征,有效的度量了对象密度。
核心对象获取:
在基于密度的聚类算法中,对象可分为核心对象和非核心对象。核心对象是聚类的内部对象,构成了聚类的骨架,可以较好的表征数据集的特征;而非核心对象包括噪音、离群点、边界点,主要位于簇的边缘、簇与簇的中间或远离簇的区域。非核心对象往往造成一些不良现象,如桥接干扰、噪音干扰、边界不清、簇合并等,使算法无法进行有效聚类。准确地提取核心对象是获得正确聚类中心的前提,本发明结合偏斜度概念,利用提出的边界度计算方法提取核心对象。
核心对象的K近邻均匀的分布在其周围。非核心对象,如噪音、边界、桥接对象,其周围的对象分布较为稀疏,并具有较大的偏向性,即往往聚集在某一方向。如边界对象周围的对象集中在簇内方向,簇外方向分布稀疏,呈现较大的偏斜状态。基于核心对象与非核心对象的空间分布差异,我们给出偏斜度的定义。
定义1.(偏斜度)设x∈D,在对象x的k近邻空间中,偏斜度sc(x)定义如下:
核心对象周围的对象分布较为均匀,其偏斜度较小;非核心对象周围的对象分布较为稀疏,其偏斜度较大。对于一些特殊噪声,如随机噪声,周围对象的分布同样均匀,使得这些对象的偏斜度与核心对象相差不大。为了增加核心对象与非核心对象的差异度,本发明提出了一种边界度计算方法,定义如下:
定义3.(边界度)设x∈D,对象x的边界度BD(x)定义如下:
边界度概念反映了对象属于非核心对象的程度,非核心对象的边界度较大,而核心对象的边界度较小。将对象按照边界度降序排序后,依据核心对象的占比因子λ,可将对象划分为核心对象或非核心对象。所有的核心对象构成了核心对象集core_object_set={x|x∈D AND BD(x)≤bd_sort_des(flag)},其中bd_sort_asc为边界度集合BD的升序排序,
关于本发明的聚类方法CSMCA
聚类中心选取模型:
合理的聚类中心可有效的表征簇的分布结构并提高聚类精度,DPC算法给出了聚类中心的选取原则:聚类中心拥有较大的密度,并且被一些较低密度的对象包围,同时距高密度对象的距离较远。为了增加聚类中心与其他对象的特征差异,基于局部密度定义,我们给出密度权重定义。
定义4.(密度权重)设x∈D,数据对象x的密度权重W(x)公式如下:
W(x)=den(x)*δ(x) (5)
其中,δ(x)表示x与高密度数据对象之间的最小距离,即:
密度权重用来衡量对象成为聚类中心的可能性。由于聚类中心具有较高的密度且距高密度对象的距离较远,因此,对象的密度权重越大,表示对象成为聚类中心的可能性越大。将对象按照密度权重降序排序后,聚类中心将存在(位于)序列的前半部分。
本发明提出了一种中心选取模型(Center Selection Model)CSM。首先,模型依据边界度和占比因子λ提取核心对象,形成集合core_object_set;基于图的思想,建立核心对象的互近邻关系,形成互近邻关系图knn_graph;通过遍历算法计算连通区域数量,即为聚类中心数量cluster_no;最后结合聚类中心在密度权重降序序列中的位置分布,确定期望的聚类中心,形成集合cluster_center_set。CSM模型的处理过程如表2所示:
表2模型的处理过程
模型有效性检验:
本发明从表3中选取部分典型数据集来检验CSM模型在复杂分布、高维、真实数据下的有效性。除表3中编号为1、2、3、4、13、15的数据集外,Aggregation数据集共有七个大小不同的簇,簇间存在桥接干扰现象,用来检测模型在桥接干扰下聚类中心的识别能力;Japanese Credit数据集为真实数据集,用来检测算法对于高维数据的聚类中心检测能力。表4给出了CSM模型与各聚类中心选取算法的实验结果。
表3数据集的基本信息
DC-MDACC算法提出的聚类中心选取方法将未在置信区间中的对象视为聚类中心,但选取过程易受置信因子参数影响,如置信因子参数偏大,则置信区间缩小,算法只能获取部分聚类中心,导致算法的聚类中心获取能力并不稳定,如Jain、Compound、Spiral数据集。SP-MI-FCM算法提出的聚类中心选取方法将最小化误差平方和作为目标函数收敛条件,对于非球形簇,算法的中心识别能力较低,同时FCM算法的聚类中心初始化方式决定了隶属度矩阵存在偏差,将影响到后续的迭代过程,导致聚类中心选取偏差,如Spiral、Compound数据集。
本发明提出的CSM模型在不同类型、维度、样本量下的数据集上均可正确识别聚类中心,说明模型在选取聚类中心时是有效的。
表4聚类中心识别结果对比
模型鲁棒性检验:
为了检验CSM模型的参数鲁棒性,本发明选取合成数据集和UCI数据集对模型进行参数敏感性分析。由于参与实验分析的算法拥有不同的参数,且参数取值范围并不相同,因此我们对每个参数给定不同的取值区间,统一采用插值法获取10个参数取值。CSM模型参数λ的取值区间为[0.5-0.75,Str-FSFDP算法的参数取值区间为[0.01-0.46],SP-MI-FCM算法的参数取值区间为[5-50]。图2(a)至图2(f)给出了各算法在不同参数取值下聚类中心获取的情况,每个横坐标位置代表在取值区间中等分情况下的参数值。
本发明提出的中心选取模型可以准确识别各个数据集的聚类中心且效果稳定,可以看出本文的中心选取模型是有效的。(CSM模型的参数具有较高的鲁棒性)。
本发明的聚类方法(CSMCA)主要分为计算、中心选取、划分三个步骤。算法首先计算近邻参数K、局部密度、密度权重以及边界度;其次依据CSM模型获取聚类中心;最后将剩余对象划分至相应的簇中,完成聚类任务。算法详细步骤如表5:
表5:聚类方法(CSMCA)的步骤
综上,如图3所示,本发明公开了一种基于密度峰值的高维真实场景下的聚类方法,包括如下步骤:
步骤1:采集数据,例如采集医疗、金融、生物工程所产生的数据。
步骤2:对采集的数据进行清洗操作。
步骤3:计算近邻参数K、局部密度、密度权重以及边界度。
步骤4:使用CSM模型确定聚类中心。
步骤5:划分剩余数据对象。
步骤6:依据划分结果,整理出辅助决策的可用信息。
步骤7:输出可用信息。
在步骤7中,例如,输出金融领域可用信息:用户高风险、用户中风险、用户低风险。
在步骤7中,例如,输出医疗诊断可用信息:患病、无病。
在步骤7中,例如,输出生物工程可用信息:门类1、门类2……。
可以看出,本发明可应用于真实场景的数据挖掘中,可以为金融信贷、医疗诊断、生物工程领域的大数据分析提供决策支持,例如,对于医疗诊断领域产生的真实数据,本发明可以将数据大致归为两类,即高概率患病、低概率患病、无患病可能,以此来减轻医疗诊断工作量;对于金融信贷领域产生的数据集,本发明可以根据实际需求将用户归为不同风险等级,减轻金融机构信贷审核的工作量;对于生物工程领域产生的数据,本发明可以根据动植物真实纲目分为若干类,可以解决在缺少大量样本进行训练的情况下深度学习方法分类精度不理想的问题。
算法实验分析:
硬件环境:CPU为AMD Athlon(tm)X4750 Quad Core Processor 3.40GHz,内存为4.00GB,操作系统为Microsoft Windows 7,编译环境为MatlabR2014a。
实验数据集包括人工合成数据集和UCI数据集。详细信息见表3,编号1-6是人工合成数据集,用来检验算法在不同数据形态下的聚类效果;编号7-15为UCI数据集,用来检测算法在真实环境下的聚类效果。
为了全面地评价聚类结果,本发明选用准确度(ACC:Accuracy)、纯度(Purify)、FM指数(FMI:Fowlkes and Mallows Index)、兰德系数(RI:RAND INDEX)、杰卡德相似系数(JC:Jaccard similarity coefficient)来衡量聚类质量。
对比算法的参数设置原则如下:
对于将聚类中心作为参数的算法,我们给出正确的聚类中心个数参数;
对于其他参数,我们根据参数的取值区间,采用插值法获取参数值,将最佳聚类结果作为最终的聚类结果;
对于聚类过程涉及迭代计算的算法,我们给定统一的运行次数,多次运行,取各指标的均值作为最终聚类效果。
合成数据集:
为了检验算法在不同数据分布形态下的聚类效果,本发明选用了不同特征的合成数据集,实验选取的合成数据集包含了以下分布形态:多密度、流型螺旋、微型簇、非球形、簇间嵌套、簇间半包含,并且存在多类型的噪声干扰:随机噪声、桥接噪声、离群噪声。其中,R15数据集共有15个位置相邻的微型簇,且存在少量离群噪声,用来检验算法能否完整识别数据集中所有聚类;Compound数据集包含6个密度不均的簇,簇间存在嵌套和包围关系,用来检验算法能否识别多密度和嵌套聚类;Spiral、Jain数据集呈现螺旋分布,簇之间存在互相包含关系,用以检验算法是否能识别非球形簇;4k2-far数据集含有4个簇和随机噪声,用来检测算法能否在噪音干扰下准确聚类。表6给出了各算法在合成数据集上的聚类评价指标值,其中粗体部分表示该指标达到的最高值。
表6合成数据集上的聚类结果比较
真实数据集:
为了检验算法在真实、高维环境下的聚类效果,本发明选用了来自地质勘探、生物工程、医疗诊断、游戏博弈、金融等领域的UCI数据集。Sonar数据集来自地质勘探领域,记录了不同岩石的声呐回波;Cylinder Bands、Balloons数据集来自物理工程领域;Heartdisease、Parkinson、SPECT Heart数据集来自医疗诊断领域,记录了病患的生化指标;Soybean数据集来自生物工程领域,记录了大豆疾病的特征;Tic-tac-toe数据集来自博弈领域,记录了三连棋的棋盘数据;German Credit数据集来自金融领域,记录了不同地区的用户信贷情况。表7给出了各算法在真实数据集上的评价指标值。
对于真实数据集,属性维度普遍较高且数据结构多为异构类型,对象分布并不严格遵守欧氏空间的统计规律,聚类形状并非为传统的球形簇。因此,对适用于处理球形簇的传统聚类算法,算法的聚类效果不佳,如K-means算法的Soybean、Tic-Tac-Toe、Wine数据集,FCM算法的Zoo、Cylinder Bands数据集。
由于高维空间中数据分布较为稀疏,DBSCAN算法的半径和阈值参数难以设置合适取值,使算法的聚类效果并不稳定,如算法在Soybean数据集上聚类效果最好,在Iris、German Credit、Wine数据集上效果较差。
由于决策图技术在聚类过程中的应用,DPC、LPC、CDP算法均可有效的聚类,但在某些高维数据下,DPC和CDP算法的截断距离参数难以设置合适取值,使部分对象在决策图中的位置过于接近或重合,决策图的优势被削弱,干扰了中心选取过程,如CDP算法在Sonar数据集上效果不佳,DPC算法在Balloons上数据集上效果不佳;LPC算法使用拉普拉斯中心性来度量密度,其原理依据统计分布规律,对于高维数据集,拉普拉斯中心性度量会产生偏差,进而影响聚类效果,如算法在Heart disease、Balloons、SPECT Heart上聚类效果不佳。
本发明的聚类方法(CSMCA)在各个数据集上聚类指标大部分达到最佳,其余指标均与最佳指标相差不大,说明本发明的聚类方法(CSMCA)在处理真实、高维的聚类时是有效的。
表7真实数据集上的聚类结果比较
算法复杂度分析:
时间复杂度是衡量算法效率的重要指标,本发明的聚类方法(CSMCA)的主要时间开销如下:近邻参数k、边界度等变量计算、核心对象的互近邻关系建立和遍历、对象划分等。
对象间的近邻关系是各变量计算的基础,本发明采用局部敏感哈希函数查找对象的近邻关系,通过增加代码量来降低时间复杂度,其时间复杂度为O(nlog
表8算法的时间复杂度分析
结论:基于聚类中心的空间分布特征,本发明提出了一种基于密度峰值的高维真实场景下的聚类方法(CSMCA)。提出了一种无参数局部核密度计算方法,解决了参数设置不合理导致的密度度量失衡问题;同时在提出的边界度计算方法基础上建立了聚类中心选取模型,有效的提取了聚类中心,解决了中心选取偏差和参数敏感的问题。本发明的聚类方法(CSMCA)仅有一个参数:占比因子λ,参数少于大多数聚类算法且具有良好的鲁棒性,可以对含有噪声的多密度和高维数据集进行有效的聚类,并具有较高的精度。
以上内容是结合具体的优选实施方式对本发明所作的进一步详细说明,不能认定本发明的具体实施只局限于这些说明。对于本发明所属技术领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干简单推演或替换,都应当视为属于本发明的保护范围。