对数据块的存储空间进行复用的方法和相关产品
文献发布时间:2023-06-19 11:26:00
技术领域
本公开涉及计算机领域,更具体地,涉及存储空间的复用。
背景技术
神经网络技术最近被普遍的应用,一些硬件厂商开始设计神经网络处理器来加速神经网络的计算。对于一个神经网络处理器来说,片上存储空间是有限的。随着神经网络的深度和宽度的增大,所需要的数据量也在逐渐增大,那么存储空间的大小有可能将会成为瓶颈,特别在神经网络的训练阶段,所需的存储空间是非常巨大的。
神经网络在运行的过程中,很多数据块的空间是可以复用。为此,许多框架做了内存管理模块,以提高内存复用。但是,现有的很多算法容易产生内存碎片,不能充分高效地利用内存。
发明内容
本公开的一个目的在于克服现有技术中在进行空间复用时容易产生内存碎片,空间复用效率较低的缺陷。
根据本公开的第一方面,提供一种对数据块的存储空间进行复用的方法,包括:确定多个数据块之间的冲突关系;根据所述冲突关系来确定存在复用关系的数据块;调整所述多个数据块的存储空间的分配顺序,以使得分配顺序中在后数据块能够复用在前数据块的存储空间。
根据本公开的第二方面,提供一种电子设备,包括:一个或多个处理器;以及存储器,所述存储器中存储有计算机可执行指令,当所述计算机可执行指令由所述一个或多个处理器运行时,使得所述电子设备执行如上所述的方法。
根据本公开的第三方面,提供一种计算机可读存储介质,包括计算机可执行指令,当所述计算机可执行指令由一个或多个处理器运行时,执行如上所述的方法。
本公开的技术方案能够取得较高的空间复用率,降低存储空间的浪费,并且能够以更快的收敛速度达到相应的空间复用率,特别是对于具有较小存储空间的边缘设备而言具有积极的意义。
附图说明
通过参考附图阅读下文的详细描述,本披露示例性实施方式的上述以及其他目的、特征和优点将变得易于理解。在附图中,以示例性而非限制性的方式示出了本披露的若干实施方式,并且相同或对应的标号表示相同或对应的部分,其中:
图1a示出了传统的神经网络结构示意图;
图1b示出了一个双核处理器执行的神经网络结构示意图;
图1c示出了示例性的执行流;
图1d示出了一个示例性的冲突矩阵;
图2a和图2b示出了根据本公开一个实施方式的不同复用方法的对比示意图;
图3示出了根据本公开的一个实施方式的对数据块的存储空间进行复用的方法流程图;
图4示出了根据本公开一个实施方式的调整所述多个数据块的存储空间的分配顺序的流程示意图;
图5a示出了根据本公开一个实施方式的为数据块预分配存储空间的示意图;
图5b示出了根据本公开另一个实施方式的为数据块预分配存储空间的示意图;
图6a至图6c示出了另外两种序列的存储空间的示例性分配情况;
图7示出了根据本公开一个实施方式的调整所述数据块序列中数据块的顺序,以使得存在复用关系的数据块的连续度最大化的方法流程图;
图8示出了调整数据块序列的示例性图示;
图9示出了根据本公开另一个实施方式的进一步调整所述数据块序列中数据块的顺序,以使得存在复用关系的数据块的连续度最大化的方法流程图;
图10a示出了本公开的技术方案(遗传算法,GA)与第一适配(first-fit,FF)算法和最佳适配合并(best fit with coalescing)算法在不同运行环境下的比较结果;
图10b示出了在ResNet50,MobileNetV1,MobileNetV2,InceptionV3,GoogLeNet,DensetNet网络类型下本公开的遗传算法与采用随机搜索算法的FF的收敛速度的对比;
图11示出了根据本公开的组合处理装置的示意图;
图12示出了一种示例性板卡。
具体实施方式
下面将结合本披露实施例中的附图,对本披露实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本披露一部分实施例,而不是全部的实施例。基于本披露中的实施例,本领域技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本披露保护的范围。
应当理解,本披露的权利要求、说明书及附图中的术语“第一”、“第二”、“第三”和“第四”等是用于区别不同对象,而不是用于描述特定顺序。本披露的说明书和权利要求书中使用的术语“包括”和“包含”指示所描述特征、整体、步骤、操作、元素和/或组件的存在,但并不排除一个或多个其它特征、整体、步骤、操作、元素、组件和/或其集合的存在或添加。
还应当理解,在此本披露说明书中所使用的术语仅仅是出于描述特定实施例的目的,而并不意在限定本披露。如在本披露说明书和权利要求书中所使用的那样,除非上下文清楚地指明其它情况,否则单数形式的“一”、“一个”及“该”意在包括复数形式。还应当进一步理解,在本披露说明书和权利要求书中使用的术语“和/或”是指相关联列出的项中的一个或多个的任何组合以及所有可能组合,并且包括这些组合。
以上对本披露实施例进行了详细介绍,本文中应用了具体个例对本披露的原理及实施方式进行了阐述,以上实施例的说明仅用于帮助理解本披露的方法及其核心思想。同时,本领域技术人员依据本披露的思想,基于本披露的具体实施方式及应用范围上做出的改变或变形之处,都属于本披露保护的范围。综上所述,本说明书内容不应理解为对本披露的限制。
首先,为了便于下文中更好地对空间复用的技术进行描述,下文中举例说明书数据块之间的冲突关系。
深度神经网络(DNN),例如卷积神经网络神经网络(CNN)和递归神经网络(RNN),已在多个领域取得成功。以较为普遍的CNN为例,其主要由卷积层,池化层,激活层,完整连接层等组成。每个层所操作的多维数据可以称为张量。
在多核处理器平台中,为了借助于神经网络的并行特性以及充分利用硬件资源,CNN中的操作通常被划分为多个子操作,并且网络拓扑结构会动态地发生改变。
在本公开中,以图1a至图1d为例来进行示例性说明,其中,图1a示出了传统的神经网络,其包括卷积层和池化层以及三个张量数据块D0,D1和D2。当在GPU平台上执行时,可以假设数据块D0能够与数据块D2共享存储空间。但是对于多核处理器平台,传统神经网络的层和张量被进行了划分并且划分后的各个层如图1b所示。
在图1b中,在处理核A中,将数据块D0拆分为数据块D00和D01,数据块D00通过卷积层后生成数据块D10,数据块D01通过池化层后生成数据块D20;在处理核B中,数据块D01通过卷积层后生成数据块D11,数据块D11通过池化层后生成数据块D21;在处理核A中,将生成的数据块D20和D21组合为数据块D2。
需要理解的是,存在冲突的数据块可以是由不同的处理核来处理的(例如数据块D20和D21),也可以是由同一个处理核来处理的(例如数据块D01和D00)。以数据块D01和D00为例,在处理核A中,首先执行执行指令Store D00,接下来执行指令Store D01,此时数据块D00的生命周期尚未结束,因为后续还要执行指令Load D00。因此,数据块D00和数据块D01的生命周期存在重叠,二者是发生冲突的数据块,无法对存储空间进行复用。
更进一步地,从拓扑结构而言,例如数据块D11和D10似乎可以复用一个存储空间的,但是在实际中,由于他们被不同的处理核使用并且他们的生存周期存在重叠,因此这两个数据块并不能复用存储空间。因此,仅从网络拓扑结构而言,可能会得到错误的存储空间复用策略。从神经网络的拓扑结构来看,数据块D00和D11由不同的分支来使用,我们不能直接从中得到他们相对的生存周期间隔。但是,通过图1c的执行流可看出,数据块D00和D11分别被处理核A和处理核B来使用。对数据块D00和D11的访问被第二个同步操作(sync)所隔开,因此可以看出数据块D00和D11的生存周期没有发生重叠,他们可以复用同一存储空间。
图1d示出了一个示例性的冲突矩阵,其中,灰色部分表示数据块的生命周期不发生重叠,即数据块之间无冲突;而斜杠部分表示数据块的生命周期发生重叠,即数据块之间存在冲突。需要理解的是,图1d所示的冲突矩阵仅仅是一种标识数据块之间冲突的示例,对于不同的指令,数据块之间的冲突关系会有所不同,而且也并不必然需要采用冲突矩阵的形式来表示数据块之间的冲突关系。
图2a和图2b示出了根据本公开一个实施方式的不同复用方法的对比示意图。
为数据块分配存储空间的顺序会引起空间复用的效率不同。假设存在三个数据块D0,D1,D2,这三个数据块的大小分别是5,5,6,其中数据块D0和D2的空间是可以复用的。
如图2a所示,如果分配的顺序是D0,D1,D2,那么这三个数据块总体占用的存储空间大小是16;而如图1b所示,如果分配的空间顺序是D2,D1,D0,那么D0可以复用D2的空间,则总体占用的存储空间大小是11。
通过图2a和图2b所示的示例可以看出,通过改变为数据块分配存储空间的顺序,可以有更好的机会对存储空间进行复用。
如果需要搜索到最合适的分配顺序,那么假设数据块的个数是N的话,则搜索时间复杂度是N!,这样的计算效率非常低下,消耗大量的时间,因此需要合适的算法来进行搜索。
图3示出了根据本公开的一个实施方式的对数据块的存储空间进行复用的方法流程图。如图3所示,该方法可以包括:在操作S310,确定多个数据块之间的冲突关系;在操作S320,根据所述冲突关系来确定存在复用关系的数据块;以及在操作S330,调整所述多个数据块的存储空间的分配顺序,以使得分配顺序中在后数据块能够复用在前数据块的存储空间。
对于操作S310,如上文中结果图1a至图1d进行的描述,可以首先确定所述多个数据块的生存周期,然后将生存周期不存在交叉的数据块确定为无冲突关系;换言之,如果数据块的生存周期存在交叉,则意味着这些数据块存在冲突关系。无冲突关系的数据块可以对存储空间进行复用,而存在冲突关系的数据块则不能对存储空间进行复用。这在上文中已经进行了解释,这里将不再赘述。
需要理解的是,根据冲突关系来确定存在复用关系的数据块,除了如上文所述的确定数据块之间的生命周期出否重叠之外,还优选地需要确定无冲突关系的数据块的大小,以使得存储空间能够被复用的数据块的大小不小于进行复用的数据块的大小。
以图2a和图2b为例,尽管数据块D2和D0不存在冲突关系,二者可复用存储空间,但数据块D2的大小为6,而数据块D0的大小为5,因此当为数据块D2分配了大小为6的存储空间之后,则数据块D0可以复用大小为5的存储空间;但是,如果先为数据块D0分配大小为5的存储空间,那么当数据块D2需要复用该大小为5的存储空间时,则需要将大小为6的数据块D2拆分为两个不同大小的数据块(大小为5和1),由此容易产生较多的存储空间碎片。
当确定了数据块之间的冲突关系以及各个数据块的大小之后,可以调整各个数据块分配存储空间的分配顺序,以使得先分配了存储空间的数据块的大小不小于后分配存储空间的数据块的大小。如图2a和图2b所示的那样,需要首先为数据块D2分配存储空间,再为无冲突关系的数据块D0来分配存储空间。需要理解的是,分配的顺序可以是D2,D1和D0,也可以是D2,D0和D1,或者也可以是D1,D2和D0。
根据本公开的一个实施方式,调整所述多个数据块的存储空间的分配顺序,以使得分配顺序中在后数据块能够复用在前数据块的存储空间包括:调整所述多个数据块的存储空间的分配顺序,以使得多个数据块中至少一部分数据块的存储空间的连续性符合预设条件。
从上文中结合图2a和图2b的描述中可以看出,为数据块分配存储空间的顺序可以有多种,例如图2a和图2b中三个数据块的分配顺序可以有三种,例如D2,D1和D0;D2,D0和D1;或者D1,D2和D0,而如果存在更多数据块,则分配方式更多,分配的复杂度也将更高。
在本公开中,除了通过调整数据块分配存储空间的顺序之外,有更选地,需要考虑不同分配顺序中存储空间的连续性,存储空间的连续性越好,则存储空间复用度越高,存储空间的碎片越少。因此,在本公开的技术方案中,可以将存储空间的连续性作为一个重要指标来进行考虑。
图4示出了根据本公开一个实施方式的调整所述多个数据块的存储空间的分配顺序的流程示意图。
如图4所示,调整所述多个数据块的存储空间的分配顺序,以使得多个数据块中至少一部分数据块的存储空间的连续性符合预设条件可以包括:在操作S410,为多个数据块中的每个数据块预分配存储空间,其中预分配的存储空间大小不小于相应的数据块大小;在操作S420,根据预分配的存储空间的起始地址对所述多个数据块进行排序,以形成数据块序列;以及在操作S430,调整所述数据块序列中数据块的排列顺序,以使得存在复用关系的数据块的连续度最大化。
需要理解的是,为了方便操作,可以对每个数据块形成三元组(id,size,addr),id表示该数据块的索引,其可以是任何能够将数据块区分开的标识符,size表示该数据块的大小,addr表示该数据块的地址。通过该三元组,可以确定该数据块的位置,数据块的大小,数据块的地址等,以便于对该数据块进行操作。下文中的序列可以是对数据块的索引进行排序,而无需对数据块本身进行排序。
图5a示出了根据本公开一个实施方式的为数据块预分配存储空间的示意图。
首先,假设数据块为D1-D6(id),其大小(size)分别为9、6、2、5、3和4。在此情况下,需要在存储器中为这些数据块分配存储空间,分配给每个数据块的存储空间的大小应当不小于上述的数据块的大小。
接下来,假设该数据块的序列1={D1,D2,D3,D4,D5,D6},那么可以从存储器的起始地址开始搜索每个可用的存储空间,并将这些存储空间预分配给上述的数据块。假设该存储器从起始地址开始存在若干存储空间,前六个可用的存储空间的大小分别为S1=2、S2=7、S3=10、S4=4、S5=6、和S6=5,第7个存储空间大小S7=7,第8个存储空间大小为S8=11。这些存储空间S1-S8是根据存储地址排列的,并且这些存储空间的是离散且不相连的。那么,预分配结果如下:
首先,从存储空间S1-S6中搜索能够容纳数据块D1(size=9)的存储空间,可以看出,可以将存储空间S3(=10)预分配给数据块D1。
从存储空间S1-S6中搜索能够容纳数据块D2(size=6)的存储空间,可以看出,可以将存储空间S2(=7)预分配给数据块D2。
从存储空间S1-S6中搜索能够容纳数据块D3(size=2)的存储空间,可以看出,可以将存储空间S1(=2)预分配给数据块D3。
从存储空间S1-S6中搜索能够容纳数据块D4(size=5)的存储空间,可以看出,可以将存储空间S5(=6)预分配给数据块D3。
从存储空间S1-S6中搜索能够容纳数据块D5(size=3)的存储空间,可以看出,可以将存储空间S4(=4)预分配给数据块D5。
从存储空间S1-S6中搜索能够容纳数据块D6(size=4)的存储空间,可以看出,可以将存储空间S6(=5)预分配给数据块D6。
在预分配存储空间之后,可以将这些数据块根据每个存储空间的起始地址重新排序,从而形成重排序序列1={D3,D2,D1,D5,D4,D6}。
上面的描述仅仅是一种示例,图5b示出了根据本公开另一个实施方式的为数据块预分配存储空间的示意图。在图5b中,存储空间S1和S2是连续的,在此情况下为数据块分配数据的方式则有所不同。
根据本公开的一个实施方式,为序列1={D1,D2,D3,D4,D5,D6}预分配存储空间还可以通过如下方式:
首先,从存储空间S1-S6中搜索能够容纳数据块D1(size=9)的存储空间,可以看出,由于存储空间S1和S2是连续的,那么可以将存储空间S1和S2共同分配给数据D1。
从存储空间S1-S6中搜索能够容纳数据块D2(size=6)的存储空间,可以看出,可以将存储空间S3(=10)预分配给数据块D2,那么在存储空间S3中还剩余大小为4的可用存储空间。
从存储空间S1-S6中搜索能够容纳数据块D3(size=2)的存储空间,可以看出,可以将存储空间S3(剩余4)预分配给数据块D3。
从存储空间S1-S6中搜索能够容纳数据块D4(size=5)的存储空间,可以看出,可以将存储空间S5(=6)预分配给数据块D3。
从存储空间S1-S6中搜索能够容纳数据块D5(size=3)的存储空间,可以看出,可以将存储空间S4(=4)预分配给数据块D5。
从存储空间S1-S6中搜索能够容纳数据块D6(size=4)的存储空间,可以看出,可以将存储空间S6(=5)预分配给数据块D6。
在预分配存储空间之后,可以将这些数据块根据每个存储空间的起始地址重新排序,从而形成重排序序列1’={D1,D2,D3,D5,D4,D6}。
可以看出,在上文结合图5a和图5b描述的示例中,为多个数据块中的每个数据块预分配存储空间是这样进行的:从存储器的预定地址开始,检索能够容纳数据块的存储空间;为每个数据块预分配能够容纳该数据块的第一个存储空间。
基于上述规则,可以理解的是,如果数据块的初始序列不同,则最终预分配存储空间之后再排序所形成的序列也会有所不同。如上文所述结合图2a和图2b描述的那样,为数据块分配存储空间的顺序不同,会导致不同的存储空间复用效率。因此,需要找到能够最大限度地提升空间复用效率的存储空间分配方式。
优选地,可以调整所述数据块序列中数据块的排列顺序,以使得存在复用关系的数据块的连续度最大化。如果该序列中存在复用关系的数据块的连续度最佳,则可以认为该序列是最佳的,换言之,这样的序列意味着最佳的分配顺序,能够最大限度地对存储空间进行复用。
但是,对于大量的数据块,如果将所有数据块序列都进行存储空间的预分配,那么计算量将非常巨大,因此,需要找到一种能够高效地对数据块序列进行调整的方法,通过调整该序列,将使得有更多的机会找到优选的数据块序列。
根据本公开的一个实施方式,在为多个数据块中的每个数据块预分配存储空间之前,形成多个初始化数据块种群,每个初始数据块种群包括初始顺序不同的多个数据块,以便于根据初始顺序为每个初始种群中的多个数据块预分配存储空间。
实际上,上面介绍的序列1是其中一种序列,还存在多种其他序列。
图6a至图6c示出了另外两种序列的存储空间的示例性分配情况。
图6a至图6c示例性地随机地选择D1-D6中的两个序列,例如序列2={D6,D3,D1,D5,D4,D2}以及序列3={D2,D3,D5,D6,D4,D1}。
根据本公开的一个实施方式,根据预分配的存储空间的起始地址对所述多个数据块进行排序,以形成数据块序列可以包括:根据为每个初始种群中的多个数据块预分配的存储空间的起始地址,对每个初始种群中的多个数据块进行排序,以形成多个数据块序列,每个数据块序列包括排列顺序不同的所述多个数据块。
假设该存储器从起始地址开始存在若干存储空间,前六个可用的存储空间的大小分别为S1=2、S2=7、S3=10、S4=4、S5=6、和S6=5,第7个存储空间大小S7=7,第8个存储空间大小为S8=11。这些存储空间S1-S8是根据存储地址排列的,并且这些存储空间的是离散且不相连的。那么,预分配结果如下。
对于序列2,从存储空间S1-S6中搜索能够容纳数据块D6(size=4的)的存储空间,可以看出,可以将存储空间S2(=7)预分配给数据块D6。
从存储空间S1-S6中搜索能够容纳数据块D3(size=2)的存储空间,可以看出,可以将存储空间S1(=2)预分配给数据块D3。
从存储空间S1-S6中搜索能够容纳数据块D1(size=9)的存储空间,可以看出,可以将存储空间S3(=10)预分配给数据块D1。
从存储空间S1-S6中搜索能够容纳数据块D5(size=3)的存储空间,可以看出,可以将存储空间S4(=4)预分配给数据块D5。
从存储空间S1-S6中搜索能够容纳数据块D4(size=5)的存储空间,可以看出,可以将存储空间S5(=6)预分配给数据块D4。
从存储空间S1-S6中搜索能够容纳数据块D2(size=6)的存储空间,可以看出,存储空间S1-S6中剩余的存储空间没有能够容纳数据块D2的,因此可以进一步搜索新的存储空间,例如将存储空间S7(=7)预分配给数据块D2,而存储空间S6暂时处于未占用状态。
在预分配存储空间之后,可以将这些数据块根据每个存储空间的起始地址重新排序,从而形成重排序序列2={D3,D6,D1,D5,D4,D2}。
对于序列3,从存储空间S1-S6中搜索能够容纳数据块D2(size=6的)的存储空间,可以看出,可以将存储空间S2(=7)预分配给数据块D2。
从存储空间S1-S6中搜索能够容纳数据块D3(size=2)的存储空间,可以看出,可以将存储空间S1(=2)预分配给数据块D3。
从存储空间S1-S6中搜索能够容纳数据块D5(size=3)的存储空间,可以看出,可以将存储空间S3(=10)预分配给数据块D5。
从存储空间S1-S6中搜索能够容纳数据块D6(size=4)的存储空间,可以看出,可以将存储空间S4(=4)预分配给数据块D6。
从存储空间S1-S6中搜索能够容纳数据块D4(size=5)的存储空间,可以看出,可以将存储空间S5(=6)预分配给数据块D4。
从存储空间S1-S6中搜索能够容纳数据块D1(size=9)的存储空间,可以看出,存储空间S1-S7中剩余的存储空间没有能够容纳数据块D1的,因此可以进一步搜索新的存储空间,例如将存储空间S8(=11)预分配给数据块D1,而存储空间S6和S7暂时处于未占用状态。
在预分配存储空间之后,可以将这些数据块根据这些存储空间的起始地址重新排序,从而形成重排序序列3={D3,D2,D5,D6,D4,D1}。
对于序列3,还优选地存在其他分配方式,如图6c所示。
对于序列3,从存储空间S1-S6中搜索能够容纳数据块D2(size=6的)的存储空间,可以看出,可以将存储空间S2(=7)预分配给数据块D2。
从存储空间S1-S6中搜索能够容纳数据块D3(size=2)的存储空间,可以看出,可以将存储空间S1(=2)预分配给数据块D3。
与图6b所示的不同,从存储空间S1-S6中搜索能够容纳数据块D5(size=3)的存储空间,可以看出,可以将存储空间S3(=10)预分配给数据块D5,此时存储空间S3中剩余的可用存储空间的大小为7。
接下来,从存储空间S1-S6中搜索能够容纳数据块D6(size=4)的存储空间,可以看出,可以将存储空间S3(剩余存储空间为3)预分配给数据块D6,此时存储空间S3中剩余的存储空间的大小为3。
从存储空间S1-S6中搜索能够容纳数据块D4(size=5)的存储空间,可以看出,可以将存储空间S5(=6)预分配给数据块D4。
从存储空间S1-S6中搜索能够容纳数据块D1(size=9)的存储空间,可以看出,存储空间S1-S7中剩余的存储空间没有能够容纳数据块D1的,因此可以进一步搜索新的存储空间,例如将存储空间S8(=11)预分配给数据块D1,而存储空间S4、S6和S7暂时处于未占用状态。
在预分配存储空间之后,可以将这些数据块根据这些存储空间的起始地址重新排序,从而形成重排序序列3’={D3,D2,D5,D6,D4,D1}。
上面举例说明了为不同的数据块序列分配存储空间后生成的重排序序列,因此,根据本公开的一个实施方式,可以从原始的数据块中随机地选择一些数据块序列作为初始化数据块种群,通过该初始化种群,可以形成不同的重排序序列,而通过对这些重排序序列进行进一步的排序,可以形成更多的数据块序列,由此能够有更多的机会找到更优的数据块序列。
在上文中,为了便于理解起见,为不同的数据块分配了不同的存储空间,而根据本公开的一个实施方式,为每个数据块预分配能够容纳该数据块的第一个存储空间可以包括:为存在复用关系的数据块分配相同的起始地址。
假设数据块D2(size=6),D3(size=2),D4(size=5)和D6(size=4)不存在冲突关系并且可以复用相同的存储空间。那么对于重排序序列1={D3,D2,D1,D5,D4,D6}而言,数据块D4和D6可以复用数据块D2的存储空间,即可以将存储空间S2也复用地分配给数据D4和D6。
对于重排序序列2={D3,D6,D1,D5,D4,D2}而言,由于存在复用关系的数据块D2(size=6),D3(size=2),D4(size=5)和D6(size=4)的大小随着分配顺序呈递增关系,因此在后分配的数据块难以复用在前分配的数据块的存储空间,即数据块D2(size=6),D4(size=5)和D6(size=4)难以复用数据块D3(size=2)的存储空间,数据块D2(size=6)和D4(size=5)难以复用数据块D6(size=4)的存储空间,而数据块D2(size=6)难以复用数据块D4(size=5)的存储空间。
对于重排序序列3={D3,D2,D5,D6,D4,D1}而言,数据块D6和D4可以复用数据块D2的存储空间,即可以将存储空间S2也复用地分配给数据D6和D4。
可以看出,对于重排序序列1={D3,D2,D1,D5,D4,D6},重排序序列2={D3,D6,D1,D5,D4,D2}以及重排序序列3={D3,D2,D5,D6,D4,D1}而言,对于四个存在复用关系的数据块D2(size=6),D3(size=2),D4(size=5)和D6(size=4),理论上应当首先为数据块D2分配存储空间,因在此之后再为D3(size=2),D4(size=5)和D6(size=4)来分配存储空间,因为在这些可以复用的数据块中,数据块D2的大小最大,而数据块D3的大小最小。而在重排序序列1和重排序序列3中,数据块D3的分配处于数据块D2之前,因此数据块D2无法复用数据块D3的存储空间;而在重排序序列2中,数据块D3,D4和D6的分配顺序均处于数据块D2之前,这显然使得D2(size=6),D3(size=2),D4(size=5)和D6(size=4)无法被很好地进行复用。
因此,在为数据块实际分配存储空间之前,需要进一步对数据块的分配顺序进行调整,以使得存在复用关系的数据块的连续度最大化。
图7示出了根据本公开一个实施方式的调整所述数据块序列中数据块的顺序,以使得存在复用关系的数据块的连续度最大化的方法流程图。
如图7所示,可以通过如下操作来调整所述数据块序列中数据块的顺序:在操作S710,选择包括连续空间数据块序列的第一数据块序列作为第一父代序列,其中所述连续空间数据块序列包括多个具有连续存储空间的数据块;在操作S720,选择第二数据块序列作为第二父代序列;在操作S730,将所述第一父代序列中的连续空间数据块序列作为遗传因子,与第二父代序列中的其他数据块结合,形成初始子代序列;在操作S740,调整所述初始子代序列中一个或多个数据块的排列位置,从而形成第一变异子代序列;在操作S750,将所述初始子代序列与所述第一变异子代序列进行比较,以选择存在复用关系的数据块的连续度最大的子代序列。
图8示出了调整数据块序列的示例性图示。下面结合图8来详细介绍图7所示的流程图。
如图8所示,假设重排序序列4={D1,D4,D6,D3,D5,D2},其中,D2(size=6),D3(size=2),D4(size=5)和D6(size=4)不存在冲突关系并且可以复用相同的存储空间。可以看出,在该重排序序列4中,存在一个连续空间数据块序列1={D4,D6,D3},显然该连续空间数据块序列非常有利于进行空间复用。其可以作为有一个遗传因子进行遗传,以期望找到更优的重排序序列。在图8中,以灰色标识了该连续空间数据块序列1。
可以将该重排序序列4作为一个第一父代序列,与另外一个第二父代序列进行结合或“交叉”,以形成初始子代序列,该初始子代序列保留了上述的父代序列中的遗传因子。
假设随机选择了对于重排序序列2={D3,D6,D1,D5,D4,D2}作为第二父代序列,如图8所示,则作为第一父代序列的重排序序列4={D1,D4,D6,D3,D5,D2}与作为第二父代序列的重排序序列2={D3,D6,D1,D5,D4,D2}的交叉过程如下。
首先,将上文中确定的连续空间数据块序列1={D4,D6,D3}作为遗传因子提出取来形成序列A,然后将第二附带序列中的其他数据块{D1,D5,D2}提出取出来形成序列B,在保留序列A的情况下,将序列A和序列B进行任意结合或交叉,以形成初始子代序列C,例如初始子代序列C={D5,D1,D4,D6,D3,D2}。
需要理解的是,由于初始子代序列C是序列A和序列B随机组合生成的,因此上面的初始子代序列C仅仅是一个示例,其也可以是其他形式。
在得到初始子代序列C={D5,D1,D4,D6,D3,D2}之后,可以将其与第一父代序列进行比较,以确定初始子代序列C和第一父代序列中更优的那个。
如果初始子代序列C比第一父代序列更优,例如包括的存在复用关系的数据块的连续度最大,那么可以将该初始子代序列作为一个更优质的子代序列进一步遗传。
而如果并不比第一父代序列更优,那么可以进一步对该子代序列进行调整。例如,随机地调整该初始子代序列中的一个或多个数据块的排列位置,例如将初始子代序列C从C={D5,D1,D4,D6,D3,D2}调整为第一变异子代序列D={D2,D5,D1,D4,D6,D3}。
上面得到的第一变异子代序列D相较于第一父代序列和初始子代序列C而言更优,因为存在复用关系的数据块的连续度仍然保持最大,并且由于数据块D2的分配顺序移动到了数据块D4,D6,D3之前,这样D4,D6,D3就可以对数据块D2分配的空间进行复用。
需要理解的是,上文中的示例仅仅是移动了数据块D2的位置,但在具体的实现中,可以移动数据块D1-D6中的任意一个,以便于调整整个序列数据块的顺序。对于大量数据块而言,调整后的数据块序列可能比上一个数据块序列更优。
从图8中可以看出,第一变异子代序列虽然已经能够满足将D2(size=6),D3(size=2),D4(size=5)和D6(size=4)进行复用的需要,但仍然具有进一步改进的需要。
图9示出了根据本公开另一个实施方式的进一步调整所述数据块序列中数据块的顺序,以使得存在复用关系的数据块的连续度最大化的方法流程图。
如图9所示,其包括如图7所示的操作S710-S750,这里省略对其下赘述。进一步地,可以通过如下进一步操作来调整所述数据块序列中数据块的顺序,在操作S760,将存在复用关系的数据块的连续度最大的子代序列作为最佳子代序列;在操作S770,调整所述最佳子代序列中一个或多个数据块的排列位置,从而形成第二变异子代序列;以及在操作S780,将所述最佳子代序列与所述第二变异子代序列进行比较,以选择存在复用关系的数据块的连续度最大的最佳子代序列。
图9所示的方法实际上是一个迭代过程,即不断地将更优的遗传因子向下传递或遗传,随着子代序列不断调整,逐渐找到更优或者最优的数据块序列。
进一步如图8所示,如上文所述,第一变异子代序列D相较于第一父代序列和初始子代序列C而言更优,因为存在复用关系的数据块的连续度仍然保持最大,并且由于数据块D2的分配顺序移动到了数据块D4,D6,D3之前,这样D4,D6,D3就可以对数据块D2分配的空间进行复用。但第一变异子代序列D仍然能够进一步调整,以找到更优的数据块序列。
可以将第一变异子代序列D={D2,D5,D1,D4,D6,D3}作为当前最佳子代序列,并调整该当前最佳子代序列中的某个或某些数据块的排列位置,每调整一次,则将调整后的新子代序列与原有的当前最佳子代序列进行比较,知道找到符合条件的子代序列。例如当子代序列变化为E1={D5,D1,D2,D4,D6,D3},或者E2={D2,D4,D6,D3,D5,D1},或者E3={D5,D2,D4,D6,D3,D1},或者E4={D1,D2,D4,D6,D3,D5}时,则可以认为最终的最佳子代序列。需要理解的是,在图8中示出了子序列E1作为一个示例性的第二变异子代序列,其中灰色部分表示能够复用的连续数据块序列。
可以理解,对于一个连续的存储空间而言,上述的子代序列E1-E4占用的总存储空间为3(D5)+9(D1)+6(D2)=18,相较于传统技术方案中需要占用大小为29(D1至D6占用的总存储空间)的存储空间而言,节省了大约38%的存储空间。
而对于离散的存储空间而言,存在复用关系的数据块D2,D4,D6和D3也只需要占用大小为6的存储空间,相较于没有复用时占用大小为17的存储空间,那么节省了大约11/17=64%的存储空间。
可以为图9所示的方法设定一个迭代次数的阈值,当迭代次数达到该阈值之后,则可以停止迭代而选择当前最佳的数据块序列;或者可以比较当前最佳的子代序列与第二变异子代序列的差别,如果二者差别小于预设条件,则可以停止上述迭代操作。
需要理解的是,上文中采用的术语“序列”、“父代序列”、“子代序列”、“变异子代序列”等虽然有所不同,但他们本质上是表示一个数据块序列,对他们采用不同的名称仅在于在不同的应用场景下清楚地将他们区分开,而不构成对本公开的任何限制。
为了验证本公开的技术方案所达到的技术效果,以不同的平台和网络类型进行了对比试验,图10a示出了本公开的技术方案(遗传算法,GA)与第一适配(first-fit,FF)算法和最佳适配合并(best fit with coalescing)算法在不同运行环境下的比较结果,其比较的指标为存储空间降低率(MRR),MRR的计算方式如下:如果一个没有存储空间复用的任务所需的存储空间大小为n字节,而如果一个采用空间复用技术的任务所需的存储空间为s比特,那么MRR=(n-s)/n。
采用了ResNet50,MobileNetV1,MobileNetV2,InceptionV3,GoogLeNet,DensetNet作为测试的网络类型,采用了Cambricon-X作为测试平台。
可以看出,在单核中,本公开的基因算法,FF算法以及BFC算法分别实现了平均91.1%,89.8%和89.9%的平均MRR,三者在单核情况下均实现了良好的空间复用效果,本公开的基因算法略好一些;而在4核的情况下,三个算法分别实现了91.9%,90.6%和56.6%的平均MRR,本公开的遗传算法和FF算法明显优于BFC算法;而对于16核的情况,三个算法分别实现了87.9%,86.3%和50.7%的平均MRR,本公开的遗传算法和FF算法明显优于BFC算法;而在所有情况下,本公开的遗传算法均优于FF算法。
图10b示出了在ResNet50,MobileNetV1,MobileNetV2,InceptionV3,GoogLeNet,DensetNet网络类型下本公开的遗传算法与采用随机搜索算法的FF的收敛速度的对比,其中横坐标为迭代次数,纵坐标为MRR。可以看出,除了在MobileNetV2网络中二者呈现几乎一样的收敛速度之外,在其他物种类型的算法中,本公开的GA算法均实现了更快的收敛速度。
神经网络架构的应用正变得越来越深入和广泛,操作之间的联系变得更密集,但内存容量成为瓶颈。相较于传统的方法,本公开的技术方案能够取得较高的空间复用率,降低存储空间的浪费,并且能够以更快的收敛速度达到相应的空间复用率,特别是对于具有较小存储空间的边缘设备而言具有积极的意义。
本公开还提供一种电子设备,包括:一个或多个处理器;以及存储器,所述存储器中存储有计算机可执行指令,当所述计算机可执行指令由所述一个或多个处理器运行时,使得所述电子设备执行如上所述的方法。
本公开还提供一种计算机可读存储介质,包括计算机可执行指令,当所述计算机可执行指令由一个或多个处理器运行时,执行如上所述的方法。
本公开的技术方案可应用于人工智能领域,实现为或者实现在人工智能芯片中。该芯片可以单独存在,也可以包含在计算装置中。
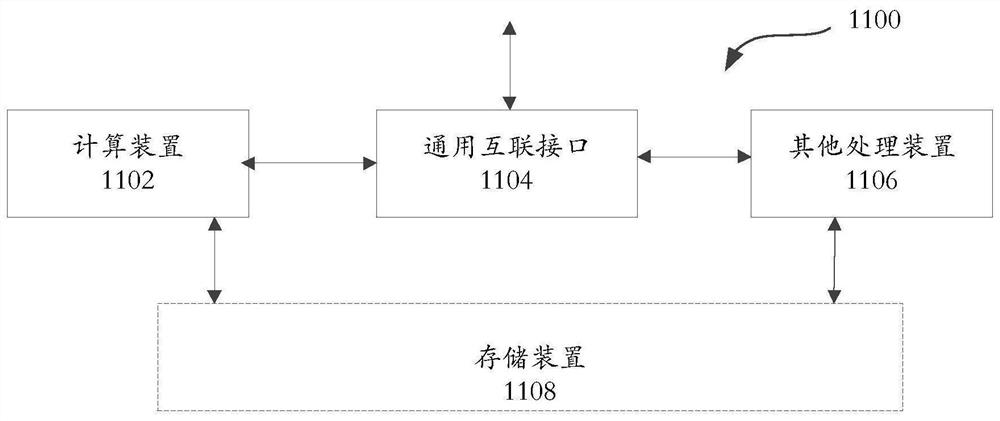
图11示出了一种组合处理装置1100,其包括上述的计算装置1102,通用互联接口1104,和其他处理装置1106。根据本公开的计算装置与其他处理装置进行交互,共同完成用户指定的操作。图11为组合处理装置的示意图。
其他处理装置,包括中央处理器CPU、图形处理器GPU、神经网络处理器等通用/专用处理器中的一种或以上的处理器类型。其他处理装置所包括的处理器数量不做限制。其他处理装置作为机器学习运算装置与外部数据和控制的接口,包括数据搬运,完成对本机器学习运算装置的开启、停止等基本控制;其他处理装置也可以和机器学习运算装置协作共同完成运算任务。
通用互联接口,用于在计算装置(包括例如机器学习运算装置)与其他处理装置间传输数据和控制指令。该计算装置从其他处理装置中获取所需的输入数据,写入该计算装置片上的存储装置;可以从其他处理装置中获取控制指令,写入计算装置片上的控制缓存;也可以读取计算装置的存储模块中的数据并传输给其他处理装置。
可选的,该结构还可以包括存储装置1108,存储装置分别与所述计算装置和所述其他处理装置连接。存储装置用于保存在所述计算装置和所述其他处理装置的数据,尤其适用于所需要运算的数据在本计算装置或其他处理装置的内部存储中无法全部保存的数据。
该组合处理装置可以作为手机、机器人、无人机、视频监控设备等设备的SOC片上系统,有效降低控制部分的核心面积,提高处理速度,降低整体功耗。此情况时,该组合处理装置的通用互联接口与设备的某些部件相连接。某些部件譬如摄像头,显示器,鼠标,键盘,网卡,wifi接口。
在一些实施例里,本披露还公开了一种芯片封装结构,其包括了上述芯片。
在一些实施例里,本披露还公开了一种板卡,其包括了上述芯片封装结构。参阅图12,其提供了一种示例性的板卡,上述板卡除了包括上述芯片1202以外,还可以包括其他的配套部件,该配套部件包括但不限于:存储器件1204、接口装置1206和控制器件1208。
所述存储器件与所述芯片封装结构内的芯片通过总线连接,用于存储数据。所述存储器件可以包括多组存储单元1210。每一组所述存储单元与所述芯片通过总线连接。可以理解,每一组所述存储单元可以是DDR SDRAM(英文:Double Data Rate SDRAM,双倍速率同步动态随机存储器)。
DDR不需要提高时钟频率就能加倍提高SDRAM的速度。DDR允许在时钟脉冲的上升沿和下降沿读出数据。DDR的速度是标准SDRAM的两倍。在一个实施例中,所述存储装置可以包括4组所述存储单元。每一组所述存储单元可以包括多个DDR4颗粒(芯片)。在一个实施例中,所述芯片内部可以包括4个72位DDR4控制器,上述72位DDR4控制器中64bit用于传输数据,8bit用于ECC校验。在一个实施例中,每一组所述存储单元包括多个并联设置的双倍速率同步动态随机存储器。DDR在一个时钟周期内可以传输两次数据。在所述芯片中设置控制DDR的控制器,用于对每个所述存储单元的数据传输与数据存储的控制。
所述接口装置与所述芯片封装结构内的芯片电连接。所述接口装置用于实现所述芯片与外部设备1212(例如服务器或计算机)之间的数据传输。例如在一个实施例中,所述接口装置可以为标准PCIE接口。比如,待处理的数据由服务器通过标准PCIE接口传递至所述芯片,实现数据转移。在另一个实施例中,所述接口装置还可以是其他的接口,本披露并不限制上述其他的接口的具体表现形式,所述接口单元能够实现转接功能即可。另外,所述芯片的计算结果仍由所述接口装置传送回外部设备(例如服务器)。
所述控制器件与所述芯片电连接。所述控制器件用于对所述芯片的状态进行监控。具体的,所述芯片与所述控制器件可以通过SPI接口电连接。所述控制器件可以包括单片机(Micro Controller Unit,MCU)。如所述芯片可以包括多个处理芯片、多个处理核或多个处理电路,可以带动多个负载。因此,所述芯片可以处于多负载和轻负载等不同的工作状态。通过所述控制装置可以实现对所述芯片中多个处理芯片、多个处理和/或多个处理电路的工作状态的调控。
在一些实施例里,本披露还公开了一种电子设备或装置,其包括了上述板卡。
电子设备或装置包括数据处理装置、机器人、电脑、打印机、扫描仪、平板电脑、智能终端、手机、行车记录仪、导航仪、传感器、摄像头、服务器、云端服务器、相机、摄像机、投影仪、手表、耳机、移动存储、可穿戴设备、交通工具、家用电器、和/或医疗设备。
所述交通工具包括飞机、轮船和/或车辆;所述家用电器包括电视、空调、微波炉、冰箱、电饭煲、加湿器、洗衣机、电灯、燃气灶、油烟机;所述医疗设备包括核磁共振仪、B超仪和/或心电图仪。
需要说明的是,对于前述的各方法实施例,为了简单描述,故将其都表述为一系列的动作组合,但是本领域技术人员应该知悉,本披露并不受所描述的动作顺序的限制,因为依据本披露,某些步骤可以采用其他顺序或者同时进行。其次,本领域技术人员也应该知悉,说明书中所描述的实施例均属于可选实施例,所涉及的动作和模块并不一定是本披露所必须的。
在上述实施例中,对各个实施例的描述都各有侧重,某个实施例中没有详述的部分,可以参见其他实施例的相关描述。
在本披露所提供的几个实施例中,应该理解到,所披露的装置,可通过其它的方式实现。例如,以上所描述的装置实施例仅仅是示意性的,例如所述单元的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,例如多个单元或组件可以结合或者可以集成到另一个系统,或一些特征可以忽略,或不执行。另一点,所显示或讨论的相互之间的耦合或直接耦合或通信连接可以是通过一些接口,装置或单元的间接耦合或通信连接,可以是电性、光学、声学、磁性或其它的形式。
所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部单元来实现本实施例方案的目的。
另外,在本披露各个实施例中的各功能单元可以集成在一个处理单元中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个单元中。上述集成的单元既可以采用硬件的形式实现,也可以采用软件程序模块的形式实现。
所述集成的单元如果以软件程序模块的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储器中。基于这样的理解,当本披露的技术方案可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储器中,包括若干指令用以使得一台计算机设备(可为个人计算机、服务器或者网络设备等)执行本披露各个实施例所述方法的全部或部分步骤。而前述的存储器包括:U盘、只读存储器(ROM,Read-Only Memory)、随机存取存储器(RAM,Random Access Memory)、移动硬盘、磁碟或者光盘等各种可以存储程序代码的介质。
以上对本披露实施例进行了详细介绍,本文中应用了具体个例对本披露的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本披露的方法及其核心思想;同时,对于本领域的一般技术人员,依据本披露的思想,在具体实施方式及应用范围上均会有改变之处,综上所述,本说明书内容不应理解为对本披露的限制。