一种基于远程监督的参数自适应农业知识图谱推荐方法
文献发布时间:2023-06-19 09:29:07
技术领域
本发明属于知识图谱和神经网络技术领域,特别涉及一种基于远程监督的参 数自适应农业知识图谱推荐方法。
背景技术
农业知识图谱结合了农业的地区性,气候性,物产多样性性等特征,利用农 业领域的实体关系与概念,挖掘出农业的潜在价值的智能辅助系统,相较于传统 的农业查询信息方式,农业知识图谱将可视化技术与农业知识库相结合,对检索 到的数据进行展示与分析,是中国计量学的新发展。为此本发明提出了一种农业 知识图谱服务系统可以利用农业知识服务系统、农业互动百科、维基百科中的数 据,分析农作物适合生长的环境以及气候,为农业研究院以及植物养殖爱好者提 供有效的辅助作用,在数据大爆炸的互联网中快速获取需要的信息。
朱全银等人已有的研究基础包括:朱全银,潘禄,刘文儒,等.Web科技新闻 分类抽取算法[J].淮阴工学院学报,2015,24(5):18-24;李翔,朱全银.联合聚类和 评分矩阵共享的协同过滤推荐[J].计算机科学与探索,2014,8(6):751-759; Quanyin Zhu,SunqunCao.A Novel Classifier-independent Feature Selection Algorithm for ImbalancedDatasets.2009,p:77-82;Quanyin Zhu,Yunyang Yan,Jin Ding,Jin Qian.The CaseStudy for Price Extracting of Mobile Phone Sell Online. 2011,p:282-285;Quanyin Zhu,Suqun Cao,Pei Zhou,Yunyang Yan,Hong Zhou.Integrated PriceForecast based on Dichotomy Backfilling and Disturbance FactorAlgorithm.International Review on Computers and Software,2011, Vol.6(6):1089-1093;李翔,朱全银,胡荣林,周泓.一种基于谱聚类的冷链物流 配载智能推荐方法.中国专利公开号:CN105654267A,2016.06.08;曹苏群,朱全银, 左晓明,高尚兵等人,一种用于模式分类的特征选择方法.中国专利公开号:CN 103425994 A,2013.12.04;刘金岭,冯万利,张亚红.基于重新标度的中文短信 文本聚类方法[J].计算机工程与应用,2012,48(21):146-150.;朱全银,潘禄,刘文 儒,等.Web科技新闻分类抽取算法[J].淮阴工学院学报,2015,24(5):18-24;李翔, 朱全银.联合聚类和评分矩阵共享的协同过滤推荐[J].计算机科学与探索,2014, 8(6):751-759;朱全银,辛诚,李翔,许康等人,一种基于K-means和LDA双向 验证的网络行为习惯聚类方法.中国专利公开号:CN 106202480 A,2016.12.07;
传统的知识图谱构建方法中涉及农业知识以及关系抽取,针对上述问题:鄂 海红.远程监督关系抽取方法及装置.中国专利公开号:CN110209836A,2019.5.17, 属于远程监督算法应用,目的是通过bootstrapping算法生成实体识别训练数据 集,通过crf++工具对句子的实体进行识别;通过远程监督方法生成实体关系抽 取训练数据集,通过关系知识库和自然语言语料生成实体关系抽取数据集;该方 法可以通过自然语料自动标注训练数据,完成实体识别以及实体关系抽取;孙 钊.一种基于知识图谱的辅助诊疗系统.中国专利公开号: CN110459320A,2019.11.15,属于医疗诊疗领域应用,目的是以两个连续医疗操作之间的患者状态为边;患者信息处理模块,接收患者信息,提取历史医疗操作和 患者状态信息,并发送至诊疗方案推送模块,将患者信息与知识图谱进行匹配, 确定患者的当前状态在知识图谱中所处的位置,基于知识图谱推送待检测的医疗 指标和/或下一步诊疗操作,能够快速得知该患者所处的诊疗阶段,给出下一步 诊疗建议;项荣.一种基于改进PCNN的番茄植株夜间图像分割方法.中国专利 公开号:CN110400327A,2019.11.1,属于农作物图像分割领域,目的是可实现番茄 植株夜间图像分割中PCNN模型参数的自适应调整,减少PCNN迭代次数,提高 算法应用的实时性。但是目前还没有采用结合神经网络的参数自适应寻优模型对 农业领域的实体识别和关系抽取,构建农业领域知识图谱并且进行辅助决策的系 统及方法。
基于启发式规则筛选算法:
信息过滤技术是为了方便用户更快的找到自己感兴趣的信息,信息过滤就是 能够解决这个问题。信息过滤通常用来处理大量的文本信息,有针对性的过滤掉 不良信息。规则是一种知识表示方法,修改或替换规则并不会对其他规则产生任 何的影响,在规则库中存放了许多不同类别的领域知识,利用已经得出来的规则 便能完成一系列的推理预测,最终得到类别。目前国内外基于启发式规则筛选的 方法还是通过关键字进行信息筛选。
远程监督算法:
远程监督算法就是基于一个标注好的人工知识图谱,给外部的文档中的句子 都要标注好关系标签,这种算法也是一种半监督的算法。首先,基于在训练阶段 先把句子中的与农作物相关的实体抽取出来,而且这两个实体在语料库都是对应 的一种关系,便认为测试集中的文本都表达了此类关系。拼接提取出来的文本特 征表示为一个词向量,作为这几种文本的一个特征向量。针对本系统,所提出的 方案是:将已有的三元组对应关系映射到海量的非结构化数据库中从而生成大量 的训练数据,而知识的来源也是多样化的,如有人工标注,现有的知识库,特定 的语句结构等。例如:设有数据集X={x
基于PCNN神经网络模型算法:
传统的词汇特征包括部分的实体本身,农产品实体之间的字序,词的上位词 等特征,比较依赖于人工处理特征过程。词法层面的特征:转换成词矢量和使用 词矢量在词汇层面代表的功能。在句法层面的特点:考虑上下文特征,设置一个 滑动窗口K,每看k个字,看完之后滑回一格,终于得到了一组句子层面的特征, 包括单词特征和位置特征。PCNN算法相较于CNN算法,它在池化层方面做出了 改进:将语句按照实体对的位置分为k段,单独对每一对进行最大池化操作,每 一段都会得到一个最大值,最后将这几个最大值构成特征向量。
发明内容
发明目的:针对现有技术中存在的问题,本发明提出一种基于远程监督的参 数自适应农业知识图谱推荐方法,通过农业知识服务系统、农业互动百科、维基 百科中的数据,分析农作物适合生长的环境以及气候,为农业研究院以及植物养 殖爱好者提供有效的辅助作用,在数据大爆炸的互联网中快速获取需要的信息。。
技术方案:为解决上述技术问题,本发明提供一种基于远程监督的参数自适 应农业知识图谱推荐方法,具体步骤如下:
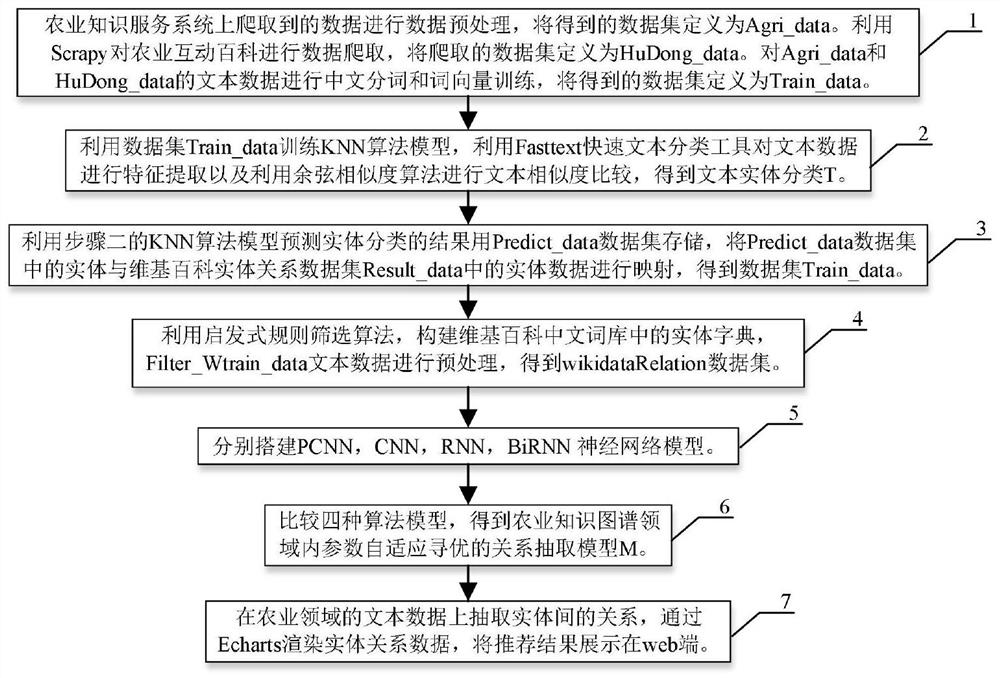
(1)农业知识服务系统上爬取到的数据进行数据预处理,将得到的数据集 定义为Agri_data;利用Scrapy对农业互动百科进行数据爬取,将爬取的数据集 定义为HuDong_data;对Agri_data和HuDong_data中的文本数据进行中文分词 和词向量训练,得到的数据集定义为Train_data;
(2)利用数据集Train_data训练KNN算法模型,利用Fasttext快速文本分 类工具对文本数据进行特征提取以及利用余弦相似度算法进行文本相似度比较, 得到文本实体分类T;
(3)利用步骤(2)的KNN算法模型预测实体分类的结果用Predict_data 数据集存储,将Predict_data数据集中的实体与维基百科实体关系数据集 Result_data中的实体数据进行映射,得到数据集Train_data;
(4)利用启发式规则筛选算法,构建维基百科中文词库中的实体字典, Filter_Wtrain_data文本数据进行预处理,得到wikidataRelation数据集;
(5)分别搭建PCNN,CNN,RNN,BiRNN神经网络模型;
(6)比较四种算法模型,得到农业知识图谱领域内参数自适应寻优的关系 抽取模型M;
(7)在农业领域的文本数据上抽取实体间的关系,通过Echarts渲染实体关 系数据,将推荐结果展示在web端。
进一步的,所述步骤(1)中得到的数据集Train_data的具体步骤如下:
(1.1)进行数据爬虫,选择爬虫页面;
(1.2)选择页面;
(1.3)选择农业知识服务系统;
(1.4)爬取农业知识服务系统,获取系统的html文件,用前端div限定爬 取范围,获取到农作物的名称Title,详细内容Detail和照片ImageList以及网页 链接Url;构成数据项Aitem={Title,Detail,ImageList,Url},数据集 Agri_data={Aitem
(1.5)选择农业互动百科;
(1.6)利用Scrapy对农业互动百科中的内容进行爬取,声明爬虫的地址域, 获取词表,构造原始的json文件,生成Url列表,获取农作物Title,爬取图片 ImageList和开放域的标签openTypeList;
(1.7)将爬取到的每一个实体对应到农业百科的一个词条,其中包括标题 Title、互动百科的链接Url、图片ImageList、开放分类列表TypeList,详细信息InfoList 以及基本信息ValueList;构成数据项 Hitem={Title,Url,ImageList,TypeList,InfoList,ValueList},数据集 Hudong_data={Hitem
(1.8)获取到两类数据库集合Agri_data和HuDong_data;
(1.9)两个数据集合Agri_data和HuDong_data中的数据进行词性筛选;
(1.10)将含有非中文和英文或数字的词丢弃;
(1.11)两个数据库集合Agri_data和HuDong_data分别进行中文分词和词 向量训练;
(1.12)得到数据集Train_data。
进一步的,所述步骤(2)中得到文本实体分类T的具体步骤如下:
(2.1)将文本数据集Train_data传入KNN文本分类器,定义各分量均值为 Mean,各分量的方差为Var,逆文本频率指数为Text_IDF,文本数量为Item_Num; 定义相似度权值为:Weight={Title,TypeList,Detail,InfoList,ValueList}={0.2,0.2,0.2,0.2,0.2};
(2.2)如若每个Item都有Weight中的5个属性,各个属性的IDF值均加1;
(2.3)每次返回2个Item的Title的相似度,将名称相似度定义为Title_sim, 返回2个Item的TypeList的相似度,将开放分类列表相似度定义为TypeList_sim, 返回2个Item的Detail的相似度,将详细内容相似度定义为Detail_sim,返回2 个Item的InfoList的相似度,将相似度定义为InfoList_sim,返回2个Item的 ValueList的相似度,将相似度定义为ValueList_sim,5个属性的相似度求平均,定 义为Dsim;
(2.4)得到的相似度Dsim线性加权,定义为Simi;
(2.5)Item的各个属性相似度存储在临时表CurList中,计算各分量的方差 和均差,对Title和TypeList的相似度进行高斯归一,对没有出现的相似度的值均 赋予相似度平均值;
(2.6)各个Item的相似度进行加权和,和义为Count_sim,将相似度Count_sim 前k个进行排序,将k个值归为一类;
(2.7)得到文本实体的分类T。
进一步的,所述步骤(3)中得到数据集Train_data的具体步骤如下:
(3.1)从KNN算法中得到的预测实体分类结果用Predict_data存储;
(3.2)利用Scrapy爬取维基百科网页下汇总的所有关系及其对应的中文名 称,存储格式为json格式;
(3.3)爬取的内容为关系rid,关系所属属性rtype,关系所属的子类rmention 及对应的rlink链接,存储在relation.json文件,定义数据样本为 Ritem={rid,rtype,rmention,rlink};数据集relation={Ritem
(3.4)关系数据集合relation.json和chrelation.json中的数据进行合并,定 义一个数据集合result.json,结果存储在result.json文件中;
(3.5)定义一个entities.json数据库,Predict_data中的数据在维基百科上搜索返回json内容存储在entities.json文件中;
(3.6)Wikidata是一个开放的知识库,爬取Wikidata实体页面中对实体的描 述以及与该实体相关联的对应关系,定义一个wikidataRelation.json文件,结果 存储在wikidataRelation.json文件中,定义数据样本Witem={entity
(3.7)WikidataRelation.json数据库中的数据处理成csv文件格式,农业互动 百科HuDong_data中的数据对应到Predict_data数据库中,得到Node.csv文件, 定义数据样本Nitem={Title,Label},数据集Node={Nitem
(3.8)Wiki中文百科语料库由繁体化为简体以及将换行语句中的换行符号去 掉;
(3.9)选择和农业有关的训练集,选择关系"instance of""taxon rank""subclass of""parent taxon";
(3.10)预加载实体列表(挑选出如下类别的实体: 5:Animal,6:Plant,7:Chemicals,9:Fooditems,10:Diseases,12:Nutrients,13:Biochemistry. 14:Agricultural implements,15:Technology);
(3.11)与农业相关的语句存储在FileRead文件中,wikidataRelation.json中 获取的三元组关系对齐到中文维基的语料库上,定义一个训练集的语料库 Wtrain_data;
(3.12)加载实体到标注的映射字典,对句子中的词语进行词性筛选,读取 实体的类别,同Predict_data中的实体类别一致;
(3.13)同维基百科数据集对齐得到的训练集中的属性关系是空值的过滤掉, 得到filter_Wtrain_data;定义数据样本 Fitem={entity
进一步的,所述步骤(4)中得到wikidataRelation数据集的具体步骤如下:
(4.1)筛选出来的Filter_Wtrain_data数据集中每行第一个元素为实体,根 据正则表达式筛选全部为中文字符的实体,转换为字典格式;
(4.2)根据实体字典获取句子集合,存为列表格式,句子集合进行预处理, 去除所有中文字符、中文常用标点之外的所有字符,并对句子进行拆分;
(4.3)每个句子进行实体遍历,根据字符匹配规则,保存出现子句子中的 所有实体,过滤没有实体或仅有一个实体的句子,数据处理为 ‘[[sentence,[entity
(4.4)使用jieba库进行中文分词,对中文句子进行分词。定义sentence文 本数据,sentence_seg为文本分词,entity
(4.5)训练词向量;
(4.6)分词后的句子重新对实体进行筛选;
(4.7)实体在分词后的句子中出现,如果没出现,执行步骤(4.10);
(4.8)实体集合两两组合,数据处理为[[sentence,entity
(4.9)wikidataRelation数据集中的数据按照3:1的比例划分训练集和测试集;
(4.10)去除实体以及该文本。
进一步的,所述步骤(5)中分别搭建PCNN,CNN,RNN,BiRNN神经网络模 型的具体步骤如下:
(5.1)搭建人工神经网络,嵌入层embedding中,定义单词映射函数为 word_embedding,定义词嵌入空间向量大小为Word_embedding_dim=50,定义 位置特征嵌入空间向量大小为Position_embedding=5,最大长度为120,设定 word_position_embedding函数将上述两个embedding函数结果相加;
(5.2)定义三个损失函数为softmax_cross_entropy,sigmoid_cross_entropy,
soft_label_softmax_cross_entropy,每个样本数据softmax或sigmoid层都可以得到不同的概率分布和预测关系,将最大的预测结果作为实体预测结果,用于计 算损失交叉熵。
(5.3)设定drop_out为定义0.5,计算张量维度上元素的最大值,分为三段 最大池化,每个卷积核得到一个3维向量,将池化层得到的结果输入到归一化函 数层,用tanh激活函数进行非线性处理。
(5.4)每一个实例定义为一个bag,若训练集中bag为正,正例个数大于等 于1个;若为负,实例皆为负;
(5.5)在每个bag上加入attention机制;
(5.6)是否已经训练,若已经训练,执行步骤(5.14);
(5.7)是否dropout;
(5.8)定义一个实体列表,定义为bag_pre,定义基于attention的逻辑回归 值为attention_logit;
(5.9)定义变量i,用来在局部作用域中遍历,定义作用域为scope;
(5.10)若i>scope.shape[0],执行步骤(5.13);
(5.11)计算softmax损失函数的attention值;
(5.12)i=i+1,执行步骤(5.10);
(5.13)得到的秩向量存储在bag_pre实体列表中,执行步骤(5.19);
(5.14)训练结束,开始测试;
(5.15)定义变量i
(5.16)若i
(5.17)计算sigmoid激活函数值,得到的实体值存储在bag_logit实体列表的 逻辑回归列表中;
(5.18)i
(5.19)定义pcnn,cnn,rnn,birnn四种函数,定义隐含因子为hidden_size=230,定义卷积核大小为3,步长为1,运用激活函数relu函数,设定局部变量count;
(5.20)投入训练,搭建pcnn,cnn,rnn,birnn神经网络模型;
(5.21)若count>n,执行步骤(5.28);
(5.22)将句子依次分解成单词,每个单词映射到维矢量d
(5.23)使用位置特征指出标记在句子中entity
(5.24)将步骤(5.23)中这两个相对位置结果连接起来,得到矩阵M∈R
(5.25)设置W=W
(5.26)用不同的W矩阵,重复上述过程;
(5.27)count=count+1,执行步骤(5.21);
(5.28)Piecewise Max-pooling通常用于在每个功能图中选择最大激活值;
(5.29)基于两个实体的位置将每个特征图Ci分为三个分量{c
(5.30)搭建好上述步骤(5.20)的四种神经网络模型。
进一步的,所述步骤(6)中得到农业知识图谱领域内参数自适应寻优的关 系抽取模型M的具体步骤如下:
(6.1)将PCNN神经网络模型的链接系数a、初始阈值b、衰减系数c,这 三个系数进行参数自适应寻优;
(6.2)确定了相对固定的链接系数、初始阈值、衰减系数,首先采用较大 的搜索步距在初始参数范围内进行搜索,找到此时的最佳模型参数;
(6.3)存在多个参数组合同时达到最优神经网络模型,若不存在,执行步 骤(6.10);
(6.4)选择较小的链接系数所在的组合作为寻优结果;
(6.5)若步距step小于0.0005,执行步骤(6.10);
(6.6)网格搜索寻找最优参数;
(6.7)遍历参数结束,若没有结束,执行步骤(6.6);
(6.8)最优的PCNN神经网络模型的链接系数、初始阈值、衰减系数得到最 高的准确率;
(6.9)
(6.10)得到神经网络的最优参数模型。
进一步的,所述步骤(7)中在农业领域的文本数据上抽取实体间的关系, 通过Echarts渲染实体关系数据,将推荐结果展示在web端的具体步骤如下:
(7.1)得到最优参数的神经网络模型PCNN,抽取农业文本数据中的两个实 体entity
(7.2)基于一个已经建立好的小型三元组知识图谱库wikidataRelation,将 三元组关系进行映射;
(7.3)利用算法模型对维基语料库中的语句进行实体抽取,实体映射到wikidataRelation数据库中,实现远程监督的算法中的自动打标签功能;
(7.4)输入农业文本数据,筛选文本数据中的实体,并抽取二者之间的关系;
(7.5)农业知识服务系统、农业互动百科以及维基百科中的数据导入到neo4j 图数据库中;
(7.6)数据库中存在搜索的实体,若没有,则执行步骤(7.9);
(7.7)用Cython语句将搜索结果以图的形式展示在web端;
(7.8)python接口封装,利用web框架Dijango对数据进行展示,则执行步 骤(7.10);
(7.9)显示不存在该实体;
(7.10)在任务框中搜索农业知识问题的文本数据,文本数据进行中文分词 技术,得到实体;
(7.11)利用Cython语句对数据库进行搜索;
(7.12)数据库中存在该问题答案,若不存在,则执行步骤(7.9);
(7.13)在农业领域的文本数据上抽取实体间的关系,通过Echarts渲染实体 关系数据,将推荐结果展示在web端。
本发明采用上述技术方案,具有以下有益效果:
本发明利用Scrapy爬虫框架爬取到农业领域的非结构化文本数据,采用KNN 算法进行实体识别,采用参数自适应的PCNN神经网络模型进行关系抽取,构建 三元组关系,比起传统的卷积神经网络,该模型能够提取出更多的句子特征。本 方法改变了传统神经网络根据经验设置参数值,采用参数自适应寻优技术,增强 了模型关系抽取的准确率。
附图说明
图1为本发明的总体流程图;
图2为具体实施例中农业知识服务系统和农业互动百科上爬取的数据进行 预处理的流程图;
图3为具体实施例中构建KNN算法模型,文本相似度比较的流程图;
图4为具体实施例中预测实体的分类结果用Predict_data存储,将 Predict_data数据集中的实体与维基百科实体关系数据集Result_data中的实体数 据进行映射,得到数据集Train_data的流程图;
图5为具体实施例中根据规则,替换实体属性关系,构建维基百科中文词库 中的实体字典,文本数据进行预处理的流程图;
图6为具体实施例中分别搭建PCNN,CNN,RNN,BiRNN神经网络模型的 流程图;
图7为具体实施例中比较四种算法模型,得到农业知识图谱领域内参数自适 应寻优的关系抽取模型M的流程图;
图8为具体实施例中在农业领域的文本数据上抽取实体间的关系,建立农业 知识图谱应用于辅助决策的流程图。
具体实施方式
下面结合工程国家标准的具体实施例,进一步阐明本发明,应理解这些实施 例仅用于说明本发明而不用于限制本发明的范围,在阅读了本发明之后,本领域 技术人员对本发明的各种等价形式的修改均落于本申请所附权利要求所限定的 范围。
如图1-8所示,本发明所述的一种基于远程监督的参数自适应农业知识图谱 推荐方法,包括如下步骤:
步骤1:农业知识服务系统上爬取到的数据进行数据预处理,将得到的数据 集定义为Agri_data。利用Scrapy对农业互动百科进行数据爬取,将爬取的数据 集定义为HuDong_data。对Agri_data和HuDong_data的文本数据进行中文分词 和词向量训练,将得到的数据集定义为Train_data。具体方法为:
步骤1.1:进行数据爬虫,选择爬虫页面;
步骤1.2:选择页面;
步骤1.3:选择农业知识服务系统;
步骤1.4:爬取农业知识服务系统,获取系统的html文件,用前端div限定 爬取范围,获取到农作物的名称Title,详细内容Detail和照片ImageList以及网 页链接Url。构成数据项Aitem={Title,Detail,ImageList,Url},数据集 Agri_data={Aitem
步骤1.5:选择农业互动百科;
步骤1.6:利用Scrapy对农业互动百科中的内容进行爬取,声明爬虫的地址 域,获取词表,构造原始的json文件,生成Url列表,获取农作物Title,爬取图 片ImageList和开放域的标签openTypeList;
步骤1.7:将爬取到的每一个实体对应到农业百科的一个词条,其中包括标 题Title、互动百科的链接Url、图片ImageList、开放分类列表TypeList,详细信 息InfoList以及基本信息ValueList。构成数据项 Hitem={Title,Url,ImageList,TypeList,InfoList,ValueList},数据集 Hudong_data={Hitem
步骤1.8:获取到两类数据库集合Agri_data和HuDong_data;
步骤1.9:两个数据集合Agri_data和HuDong_data中的数据进行词性筛选;
步骤1.10:将含有非中文和英文或数字的词丢弃;
步骤1.11:两个数据库集合Agri_data和HuDong_data分别进行中文分词和 词向量训练;
步骤1.12:得到数据集Train_data。
步骤2:利用数据集Train_data训练KNN算法模型,利用Fasttext快速文本 分类工具对文本数据进行特征提取以及利用余弦相似度算法进行文本相似度比 较,得到文本实体分类T,具体方法为:
步骤2.1:将文本数据集Train_data传入KNN文本分类器,定义各分量均值 为Mean,各分量的方差为Var,逆文本频率指数为Text_IDF,文本数量为Item_Num。
定义相似度权值 为:Weight={Title,TypeList,Detail,InfoList,ValueList}={0.2,0.2,0.2,0.2,0.2};
步骤2.2:如若每个Item都有Weight中的5个属性,各个属性的IDF值均 加1;
步骤2.3:每次返回2个Item的Title的相似度,将名称相似度定义为Title_sim,返回2个Item的TypeList的相似度,将开放分类列表相似度定义为TypeList_sim, 返回2个Item的Detail的相似度,将详细内容相似度定义为Detail_sim,返回2 个Item的InfoList的相似度,将相似度定义为InfoList_sim,返回2个Item的 ValueList的相似度,将相似度定义为ValueList_sim,5个属性的相似度求平均,定 义为Dsim;
步骤2.4:得到的相似度Dsim线性加权,定义为Simi;
步骤2.5:Item的各个属性相似度存储在临时表CurList中,计算各分量的方 差和均差,对Title和TypeList的相似度进行高斯归一,对没有出现的相似度的值 均赋予相似度平均值;
步骤2.6:各个Item的相似度进行加权和,和义为Count_sim,将相似度 Count_sim前k个进行排序,将k个值归为一类;
步骤2.7:得到文本实体的分类T。
步骤3:利用步骤二的KNN算法模型预测实体分类的结果用Predict_data数 据集存储,将Predict_data数据集中的实体与维基百科实体关系数据集 Result_data中的实体数据进行映射,得到数据集Train_data,具体方法为:
步骤3.1:从KNN算法中得到的预测实体分类结果用Predict_data存储;
步骤3.2:利用Scrapy爬取维基百科网页下汇总的所有关系及其对应的中文 名称,存储格式为json格式;
步骤3.3:爬取的内容为关系rid,关系所属属性rtype,关系所属的子类 rmention及对应的rlink链接,存储在relation.json文件,定义数据样本为 Ritem={rid,rtype,rmention,rlink};数据集relation={Ritem
步骤3.4:关系数据集合relation.json和chrelation.json中的数据进行合并,定义一个数据集合result.json,结果存储在result.json文件中;
步骤3.5:定义一个entities.json数据库,Predict_data中的数据在维基百科 上搜索返回json内容存储在entities.json文件中;
步骤3.6:Wikidata是一个开放的知识库,爬取Wikidata实体页面中对实体 的描述以及与该实体相关联的对应关系,定义一个wikidataRelation.json文件, 结果存储在wikidataRelation.json文件中,定义数据样本Witem={entity
步骤3.7:WikidataRelation.json数据库中的数据处理成csv文件格式,农业 互动百科HuDong_data中的数据对应到Predict_data数据库中,得到Node.csv文 件,定义数据样本Nitem={Title,Label},数据集Node={Nitem
步骤3.8:Wiki中文百科语料库由繁体化为简体以及将换行语句中的换行符 号去掉;
步骤3.9:选择和农业有关的训练集,选择关系"instance of""taxon rank" "subclass of""parent taxon";
步骤3.10:预加载实体列表(挑选出如下类别的实体: 5:Animal,6:Plant,7:Chemicals,9:Fooditems,10:Diseases,12:Nutrients,13:Biochemistry. 14:Agricultural implements,15:Technology);
步骤3.11:与农业相关的语句存储在FileRead文件中,wikidataRelation.json中获取的三元组关系对齐到中文维基的语料库上,定义一个训练集的语料库 Wtrain_data;
步骤3.12:加载实体到标注的映射字典,对句子中的词语进行词性筛选,读 取实体的类别,同Predict_data中的实体类别一致;
步骤3.13:同维基百科数据集对齐得到的训练集中的属性关系是空值的过滤 掉,得到Filter_Wtrain_data。定义数据样本 Fitem={entity
步骤4:利用启发式规则筛选算法,构建维基百科中文词库中的实体字典,Filter_Wtrain_data文本数据进行预处理,得到wikidataRelation数据集,具体方 法为:
步骤4.1:筛选出来的Filter_Wtrain_data数据集中每行第一个元素为实体, 根据正则表达式筛选全部为中文字符的实体,转换为字典格式;
步骤4.2:根据实体字典获取句子集合,存为列表格式,句子集合进行预处 理,去除所有中文字符、中文常用标点之外的所有字符,并对句子进行拆分;
步骤4.3:每个句子进行实体遍历,根据字符匹配规则,保存出现子句子中 的所有实体,过滤没有实体或仅有一个实体的句子,数据处理为 ‘[[sentence,[entity
步骤4.4:使用jieba库进行中文分词,对中文句子进行分词。定义sentence 文本数据,sentence_seg为文本分词,entity
步骤4.5:训练词向量;
步骤4.6:分词后的句子重新对实体进行筛选;
步骤4.7:实体在分词后的句子中出现,如果没出现,执行步骤4.10;
步骤4.8:实体集合两两组合,数据处理为[[sentence,entity
步骤4.9:wikidataRelation数据集中的数据按照3:1的比例划分训练集和测 试集;
步骤4.10:去除实体以及该文本。
步骤5:分别搭建PCNN,CNN,RNN,BiRNN神经网络模型,具体方法为:
步骤5.1:搭建人工神经网络,嵌入层embedding中,定义单词映射函数为 word_embedding,定义词嵌入空间向量大小为Word_embedding_dim=50,定义 位置特征嵌入空间向量大小为Position_embedding=5,最大长度为120,设定 word_position_embedding函数将上述两个embedding函数结果相加;
步骤5.2:定义三个损失函数为softmax_cross_entropy, sigmoid_cross_entropy,
soft_label_softmax_cross_entropy,每个样本数据softmax或sigmoid层都可以得到不同的概率分布和预测关系,将最大的预测结果作为实体预测结果,用于计 算损失交叉熵。
步骤5.3:设定drop_out为定义0.5,计算张量维度上元素的最大值,分为 三段最大池化,每个卷积核得到一个3维向量,将池化层得到的结果输入到归一 化函数层,用tanh激活函数进行非线性处理。
步骤5.4:每一个实例定义为一个bag,若训练集中bag为正,正例个数大 于等于1个;若为负,实例皆为负;
步骤5.5:在每个bag上加入attention机制;
步骤5.6:是否已经训练,若已经训练,执行步骤5.14;
步骤5.7:是否dropout;
步骤5.8:定义一个实体列表,定义为bag_pre,定义基于attention的逻辑 回归值为attention_logit;
步骤5.9:定义变量i,用来在局部作用域中遍历,定义作用域为scope;
步骤5.10:若i>scope.shape[0],执行步骤5.13;
步骤5.11:计算softmax损失函数的attention值;
步骤5.12:i=i+1,执行步骤5.10;
步骤5.13:得到的秩向量存储在bag_pre实体列表中,执行步骤5.19;
步骤5.14:训练结束,开始测试;
步骤5.15:定义变量i
步骤5.16:若i
步骤5.17:计算sigmoid激活函数值,得到的实体值存储在bag_logit实体 列表的逻辑回归列表中;
步骤5.18:i
步骤5.19:定义pcnn,cnn,rnn,birnn四种函数,定义隐含因子为 hidden_size=230,定义卷积核大小为3,步长为1,运用激活函数relu函数,设定 局部变量count;
步骤5.20:投入训练,搭建pcnn,cnn,rnn,birnn神经网络模型;
步骤5.21:若count>n,执行步骤5.28;
步骤5.22:将句子依次分解成单词,每个单词映射到维矢量d
步骤5.23:使用位置特征指出标记在句子中entity
步骤5.24:将步骤(5.23)中这两个相对位置结果连接起来,得到矩阵M∈ R
步骤5.25:设置W=W
步骤5.26:用不同的W矩阵,重复上述过程;
步骤5.27:count=count+1,执行步骤5.21;
步骤5.28:Piecewise Max-pooling通常用于在每个功能图中选择最大激活值;
步骤5.29:基于两个实体的位置将每个特征图Ci分为三个分量{c
步骤5.30:搭建好上述步骤5.20的四种神经网络模型。
步骤6:比较四种算法模型,得到农业知识图谱领域内参数自适应寻优的关 系抽取模型M,具体步骤如下:
步骤6.1:将PCNN神经网络模型的链接系数a、初始阈值b、衰减系数c, 这三个系数进行参数自适应寻优;
步骤6.2:确定了相对固定的链接系数、初始阈值、衰减系数,首先采用较 大的搜索步距在初始参数范围内进行搜索,找到此时的最佳模型参数;
步骤6.3:存在多个参数组合同时达到最优神经网络模型,若不存在,执行 步骤6.10;
步骤6.4:选择较小的链接系数所在的组合作为寻优结果;
步骤6.5:若步距step小于0.0005,执行步骤6.10;
步骤6.6:网格搜索寻找最优参数;
步骤6.7:遍历参数结束,若没有结束,执行步骤6.6;
步骤6.8:最优的PCNN神经网络模型的链接系数、初始阈值、衰减系数得 到最高的准确率;
步骤6.9:
步骤6.10:得到神经网络的最优参数模型。
步骤7:在农业领域的文本数据上抽取实体间的关系,通过Echarts渲染实 体关系数据,将推荐结果展示在web端,具体步骤如下:
步骤7.1:得到最优参数的神经网络模型PCNN,抽取农业文本数据中的两个 实体entity
步骤7.2:基于一个已经建立好的小型三元组知识图谱库wikidataRelation, 将三元组关系进行映射;
步骤7.3:利用算法模型对维基语料库中的语句进行实体抽取,实体映射到wikidataRelation数据库中,实现远程监督的算法中的自动打标签功能;
步骤7.4:输入农业文本数据,筛选文本数据中的实体,并抽取二者之间的 关系;
步骤7.5:农业知识服务系统、农业互动百科以及维基百科中的数据导入到 neo4j图数据库中;
步骤7.6:数据库中存在搜索的实体,若没有,则执行步骤7.9;
步骤7.7:用Cython语句将搜索结果以图的形式展示在web端;
步骤7.8:python接口封装,利用web框架Dijango对数据进行展示,则执 行步骤7.10;
步骤7.9:显示不存在该实体;
步骤7.10:在任务框中搜索农业知识问题的文本数据,文本数据进行中文分 词技术,得到实体;
步骤7.11:利用Cython语句对数据库进行搜索;
步骤7.12:数据库中存在该问题答案,若不存在,则执行步骤7.9;
步骤7.13:在农业领域的文本数据上抽取实体间的关系,通过Echarts渲染 实体关系数据,将推荐结果展示在web端。
上述所有参数定义见下表所示:
对264093条数据进行处理,使用KNN算法提取特征对实体进行分类预测, 搭建基于远程监督的人工神经网络PCNN模型进行关系抽取和模型训练,得到训 练文本的三元组关系,向用户展现不同农作物实体间的关系,加快信息搜索的速 度。经测试,使用PCNN算法实验模型的准确率超过94%。
本发明创造性地提出了一种基于远程监督的参数自适应农业知识图谱系统, 经过自适应寻优调参,得到农业领域关系抽取的最佳神经网络模型,适用于普遍 有关农作物的非结构化文本数据。