一种基于半监督学习的高频振荡标签自动生成方法
文献发布时间:2023-06-19 18:37:28
技术领域
本发明涉及信号检测技术领域,尤其涉及一种基于半监督学习的高频振荡标签自动生成方法。
背景技术
癫痫在世界疾病负担中占很大的比例,影响着全球约5000万人。在癫痫患者中,有三分之一的患者对药物治疗没有反应(难治性癫痫患者)。因此,难治性癫痫患者可能通过癫痫外科手术来获得无癫痫发作,但癫痫手术的效果仍依赖于准确的致痫区(EZ)定位。
致痫病灶的准确定位是改善药物难治性癫痫预后的重要前提。颅内脑电图(iEEG)记录中的高频振荡(HFOs)被认为是有效定位致痫灶的新的临床生物标志物,对EZ的准确定位至关重要。而HFOs产生组织的切除与良好的预后之间存在显著的相关性。根据频率,HFOs被分为两种类型:Rs(Ripples,80-250Hz)、FRs(Fast Ripples,250-500Hz)。
目前,基于颅内脑电图(iEEG)和视频记录的HFOs视觉标记被认为是临床医生的诊断标准,然而,脑电图记录通常需要连续进行几天的监测,而且HFO信号持续时间短、波幅小,因此手工分析如此大量的HFOs数据对临床医生来说是很困难的,因此,寻找HFOs的自动检测方法具有重要意义。
在以往的研究中,已经提出了许多HFOs的自动检测方法。基于HFOs的形态特征,研究人员使用了多种方法来检测HFOs,如短时线长特征、希尔伯特变换包络和复合小波变换。近年来,越来越多的机器学习方法被应用于检测HFOs。Jrad等人利用率Gabor变换,并使用了一个多分类的SVM;Wan等人使用模糊熵和短期能量作为输入,并使用模糊神经网络进行HFOs的检测;Burelo等人则提出了峰值神经网络(SNN)的方法。
然而,这些自动检测方法通常需要足够的标签来进行有效地训练。在实践中,标记医疗数据需要有经验的临床医生的专业知识,并且可能需要大量的时间。此外,视觉分析受到医生各种主观和客观因素的影响,不可避免地导致遗漏或错误标签,有标记的数据样本数量较少,严重影响了计算模型的结果。相比之下,未标记的数据很容易获得,而且数据量是巨大的。因此考虑如何使用大量未标记的数据样本是必要的。
发明内容
有鉴于此,本发明对当前的HFOs的自动检测方法进行优化创新,提出一种基于半监督学习的高频振荡标签自动生成方法。
为了实现上述目的,本发明提供如下技术方案:
一种基于半监督学习的高频振荡标签自动生成方法,利用包含循环神经网络和卷积神经网络的神经网络提取HFOs信号的时间特征和空间特征,然后将时间特征和空间特征进行融合,得到HFOs的特征向量,最后使用多层感知器对结果进行识别;所述神经网络利用一致性正则化的半监督算法来优化模型参数。
进一步地,一致性正则化的半监督算法包括以下步骤:
S1、初始化两个结构相同的网络模型;每个网络模型包括循环神经网络和卷积神经网络两部分,循环神经网络用于提取HFOs信号的时间特征,卷积神经网络用于提取HFOs信号的空间特征;
S2、对输入的滤波信号添加不同的高斯白噪声,分别作为网络模型的输入,输入到两个结构相同的网络模型中去;
S3、根据损失函数训练其中一个网络模型的模型参数,损失函数由无监督损失和有监督损失两部分组成,无监督损失用于最小化标记数据和未标记数据的相同输入对应的两个网络的不同输出之间的差异,有监督损失只用于计算标记数据;无监督损失在训练过程中的权重逐渐上升;
S4、对步骤S3训练的模型参数进行指数移动平均,得到另一个模型的模型参数。
进一步地,所述的无监督损失使用MSE损失。
进一步地,所述的有监督损失使用交叉熵损失。
进一步地,所述循环神经网络由LSTM组成,用来学习信号的时间特征。
进一步地,LSTM网络的隐藏单元数为100,层数为2。
进一步地,循环神经网络输出的维度为1*100。
进一步地,所述卷积神经网络利用残差神经网络的核心思想重写为一维版本,用来学习信号的空间特征。
进一步地,卷积神经网络输出的维度为1*512。
进一步地,所述多层感知器隐藏单元数为300。
与现有技术相比,本发明的有益效果为:
考虑到获得高质量HFOs标签的难度和高成本,本发明提供的基于半监督学习的高频振荡标签自动生成方法,来缓解HFOs标签严重缺乏的问题。首先,为了同时关注时间和空间特征,我们设计了一个用循环神经网络和卷积神经网络组成的网络架构。其次,为了充分利用大量的未标记数据,我们探索了一种由有监督成分和无监督成分组成的半监督算法。有监督成分利用有标记样本最小化输入和输出标签的交叉熵。同时,无监督成分基于原始输入和受干扰的输入,利用整个训练集(有标记样本和无标记样本)最大化输出的一致性,利用大量的未标记数据样本来生成HFOs的标签,提高了未标记数据的利用率,以降低标签的成本,同时提高HFOs标记的准确性和速度。通过实验证明,在仅使用5%有标签数据的情况下,我们的方法实现了较高的准确率和灵敏度。此外,在临床应用方面,我们以患者为单位对数据进行划分,避免了现有研究中数据泄露的问题。在使用临床数据的情况下,我们的方法有效地缓解了HFOs标签不足的情况。
附图说明
为了更清楚地说明本申请实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明中记载的一些实施例,对于本领域普通技术人员来讲,还可以根据这些附图获得其他的附图。
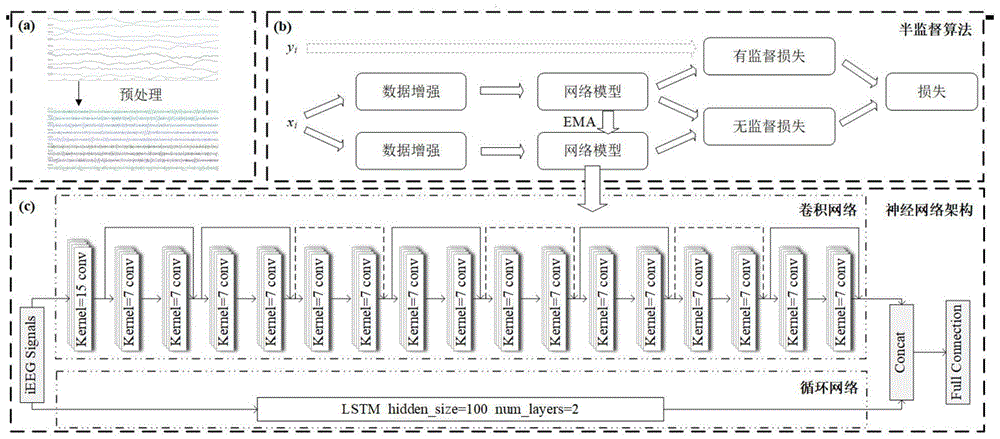
图1为本发明实施例提供的基于半监督学习的高频振荡标签自动生成方法。
图2为本发明实施例提供的预处理流程图。
图3为本发明实施例提供的对比试验的混淆矩阵图。图中,(a)为Pseudo-Label(伪标签模型),(b)为Pi-Model(pi模型),(c)为Mean-Teacher(平均教师模型),(d)为本发明方法。NPV:阴性预测值;Prec:精度;Acc:准确率;Spec:特异性;Sens:敏感度。
具体实施方式
尽管有很多的HFOs自动检测方法被提出,但HFOs的标签标注是一项昂贵、主观、耗时且费力的工作,而HFOs标签严重缺乏的情况下,现有的自动检测方法表现的性能较差,存在严重的误诊和漏诊问题。基于此,我们对当前的HFOs的自动检测方法进行优化创新,提出一种基于半监督学习(CRM)的高频振荡标签自动生成方法。首先,我们的网络架构由循环神经网络(RNN)和卷积神经网络(CNN)两部分组成,分别考虑HFOs信号的时间和空间特征,最后将两个角度的特征进行融合,得到HFOs的特征向量。其次,为了利用大量的未标记数据,我们探索了一种由有监督和无监督两部分组成的半监督算法,对有标记样本和未标记样本采用不同的损失函数计算方法。
为了更好地理解本技术方案,下面结合附图对本发明的方法做详细的说明。
本发明所提出方法的整体流程如图1所示,首先,对原始的脑电图信号进行预处理。然后,为了同时关注HFOs的时间和空间特征,本发明的神经网络架构包括循环神经网络和卷积神经网络两部分。循环神经网络由LSTM组成,卷积神经网络部分利用残差神经网络(ResNet)的核心思想,对过滤后的信号数据进行表征,并通过融合模块对两部分的输出进行特征融合。然后,使用多层感知机(MLP)分类器对结果进行识别。最后,为了缓解有标记数据严重缺乏的问题,本发明设计了一种基于一致性正则化的半监督算法,并利用有标记数据和未标记数据计算损失函数来优化模型参数。
预处理的总体流程如图2所示,包括以下步骤:
步骤一:双极导联的波形、波幅失真较少,故需要对原始脑电进行极性转换操作;
步骤二:将明显收到干扰的通道和空电极进行去除;
步骤三:对双导信号通过50Hz的倍频陷波滤波器滤除工频干扰及其倍频干扰;
步骤四:通过带通滤波器保留80-500Hz频率范围的脑电信号。
基于半监督学习的高频振荡标签自动生成方法所采用的神经网络架构如图1所示,网络架构分为循环网络和卷积网络两部分。
在循环网络部分,考虑到输入信号的时间特征,引入了一个长短期记忆(LSTM)神经网络来学习信号的时间相关性。具体来说,所使用的LSTM网络的隐藏单元数为100,层数为2。
卷积网络部分更加关注输入信号的空间特征,并根据残差神经网络(Resnet)的核心思想将其重写为一维版本。具体来说,输入信号首先通过一个核大小为15的卷积层。然后,通过四个残差块得到卷积网络部分的输出,每个块由两个核大小为7的卷积层组成。块堆叠的数目为[2,2,2,2]。
最后,对循环网络部分的输出和卷积网络部分的输出进行特征融合。循环神经网络输出的维度为1*100,卷积神经网络输出的维度为1*512,故融合后的维度为1*612。最终的输出是通过一个多层感知器(MLP)获得的,其隐藏单元数为300。
半监督算法的具体过程如下:
步骤一:初始化两个个结构相同的模型;
步骤二:对输入的滤波信号添加不同的高斯白噪声,分别作为模型的输入,输入到两个结构相同的模型中去;
步骤三:根据损失函数训练其中一个模型的模型参数。
我们将所有训练数据表示为D,标记数据表示为D
我们的损失函数由两部分组成:无监督损失(L
在无监督损失部分,我们使用MSE损失来最小化D
其中,f
在有监督损失部分,我们只对标记数据使用交叉熵损失L
由于网络初始化的随机性,在训练开始时,我们希望有监督损失项的权值相对较大。随着训练的进行,我们希望缓慢地增加无监督损失项的权重,以加快模型的收敛速度。因此,我们使用一个权重上升函数。在无监督损失项中,权重函数
因此,总损失计算如下:
步骤四:对上述训练的模型的参数进行指数移动平均(EMA)得到另一个模型的参数,具体公式如下所示:
θ′
如图3所示,通过实验证明,在仅使用5%有标签数据的情况下,我们的方法实现了较高的准确率和灵敏度。
此外,在早期的研究中,研究者大多只关注于信号检测的性能,因此在实验数据划分方面,多是采用随机划分训练集与测试集的方式。这种方法可以在一定程度上检查模型的性能,然而,在训练集和测试集中可能存在同一患者的不同数据,因此该方法一定程度上引入了数据泄露问题。在这种情况下,当模型应用于新患者时,很可能会出现性能显著下降,无法满足临床需求。
在实际的临床应用领域,理想情况是,当考虑一个新患者时,需要将从已有病例中获得的先验知识转移到对新患者的判断上。因此,必须考虑到模型在不同患者之间的泛化能力。
我们在一个基于SEEG的高频振荡数据集和一个私人临床数据集上评估了本发明的方法,在我们的方法中,考虑到上述临床需求,采用留一法进行交叉验证,以患者为单位进行数据划分,保证训练集和测试集没有来自同一患者的数据。
结果表明,在标签较少的情况下,我们的方法能够较为准确地标记HFOs数据。如表1所示。即使在交叉验证中,我们的检测器仍然表现良好,所有指标都优于同类型研究。如表2所示。这已经证明,利用相对容易获得的未标记数据来提高HFOs标记的准确性是可行的,我们的方法可以应用于临床应用,缓解了HFOs标记的严重缺乏问题,降低了标记成本。
表1临床验证的实验结果
表2对比试验的性能对比
以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换,但这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。