扩增犬冠状病毒E、M、N基因全序列的引物对及其应用
文献发布时间:2023-06-19 19:28:50
技术领域
本发明涉及分子生物学技术领域,更具体的说是涉及扩增犬冠状病毒E、M、N基因全序列的引物对及其应用。
背景技术
犬冠状病毒(Canine coroanvires,CCoV)是引起犬肠道疾病最主要的病原之一,可引起犬的急性胃肠炎,临床上表现为频繁呕吐、腹泻、沉郁、厌食以及高发病率和低死亡率。该病毒既能单独致病,也可与犬瘟热病毒、犬细小病毒、犬腺病毒等病原微生物发生混合感染,导致严重的临床症状,显著提高致死率,是当前严重威胁养犬业的病原之一。
犬冠状病毒属于套式病毒目、冠状病毒科、冠状病毒属成员,是一种带囊膜的单链正股RNA病毒,基因组大小为27-32kb之间,编码4个结构蛋白(S、E、M、N)和6个非结构蛋白(ORF1ab、ORF3a、ORF3b、ORF3c、ORF7a、ORF7b)。其中,E蛋白,即包膜蛋白E,是具有可溶性的完整膜蛋白,其包装RNA基因组形成核衣壳,在病毒的脱壳、组装和释放过程中起着重要作用。M蛋白,即膜糖蛋白,是病毒粒子被膜中含量最丰富的蛋白,它决定了病毒包膜的形状,并通过与其他结构蛋白的相互作用来指导组装过程,也被认为是冠状病毒组装的中心组织者,与所有其他主要冠状病毒结构蛋白相互作用。N蛋白,即核衣壳蛋白,是唯一一种主要与冠状病毒RNA基因组结合,构成核衣壳的蛋白质,主要功能是将病毒RNA包装成螺旋状核糖核衣壳,并在病毒粒子组装过程中与其他结构蛋白相互作用,把基因组包裹保护起来。这三个结构蛋白都与冠状病毒的结构、组成有着密不可分的联系,并在一定程度上决定病毒的致病性,是CCoV致病作用的主要成分。因此了解、掌握CCoV编码E、M、N蛋白的E、M、N基因的变异情况,有助于了解CCoV的基因重组、抗原变异、病毒感染细胞机制和基因变化规律,对CCoV致病机制的研究和疫苗等防控措施开发均有重要的指导意义。
目前,CCoV的E、M、N基因的全序列的获得主要通过设计三对针对犬冠状病毒E、M、N全长基因的引物,分别对这三个基因进行扩增、测序和/或拼接,从而获得E、M、N基因的全长片段。该方法不仅存在“工作量大”“耗时长”等问题,还因为E、M、N基因在基因组中相互毗邻,存在重复工作的问题。此外,CCoV作为一种基因组较大的RNA病毒,不同毒株之间的E、M、N基因存在着一定程度的变异。从而导致该方法在不同毒株之间存在“无法成功扩增获得目的片段”的风险。
综上,如何提供一种犬冠状病毒E、M、N基因全序列一步扩增方法是本领域技术人员亟需解决的问题。
发明内容
有鉴于此,本发明提供了扩增犬冠状病毒E、M、N基因全序列的引物对及其应用。犬冠状病毒为一种基因组比较大的RNA病毒,比较容易发生变异。本发明主要通过寻找E、M、N三个基因上下游保守序列,设计引物,并对PCR程序进行了优化。
为了实现上述目的,本发明采用如下技术方案:
一组扩增犬冠状病毒E、M、N基因全序列的引物对,其核苷酸序列如下:
上游引物CCoV-EMN1:GCCCGTAGYCGGTGTTTA;SEQ ID NO:1;
其中,Y为C或T;
下游引物CCoV-EMN2:TTCCATTGTTGGCTCGTC;SEQ ID NO:2。
进一步的,上游引物CCoV-EMN1的核苷酸序列为下列任一一个:
GCCCGTAGTCGGTGTTTA;SEQ ID NO:3;
GCCCGTAGCCGGTGTTTA;SEQ ID NO:4。
一种扩增犬冠状病毒E、M、N基因全序列的试剂盒,包括上述的引物对。
一种犬冠状病毒E、M、N基因全序列一步扩增方法,包括如下步骤:
(1)提取病毒RNA;
(2)cDNA合成;
(3)使用上述引物对进行PCR扩增;
(4)基因片段检测及测序。
进一步的,步骤(1)中采用Trizol试剂法提取病毒RNA。
进一步的,步骤(2)中采用
进一步的,步骤(3)中PCR扩增反应体系为:
其中,上游引物CCoV-EMN1、下游引物CCoV-EMN2的浓度为10pmol/μL。
进一步的,步骤(3)中PCR扩增反应程序为:95℃预变性5min;95℃变性30s,54℃退火30s,72℃延伸5min,设置35个循环;72℃终延伸10min。
进一步的,测序前,采用FastPure Gel DNAExtraction Mini Kit试剂盒对基因片段进行纯化。
经由上述的技术方案可知,与现有技术相比,本发明取得的有益效果为:本发明通过一步扩增法,无需多次扩增、裁剪,仅需通过一次PCR扩增即可实现犬冠状病毒E、M、N全基因的扩增,操作简便快捷,避免单个基因扩增的重复性,并且增加了基因扩增的保真性。同时,因设计的引物位于E、M、N三个基因上下游保守区域,有效克服因基因变异导致的无法成功扩增获得目的片段的风险。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图获得其他的附图。
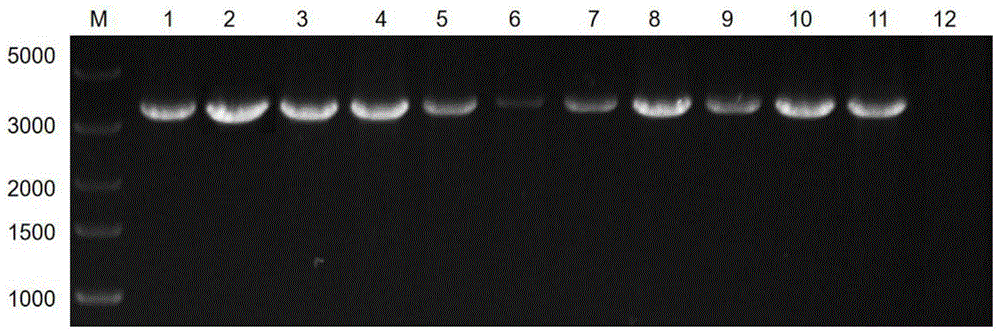
图1附图为本发明犬冠状病毒E、M、N基因全序列的PCR扩增结果,其中,M:DL5000Plus DNA Marker;1-10:泳道1为实施例2中BD15,来自福建省莆田市犬粪便样品结果,泳道2为实施例3中BQ25,来自福建省泉州市犬粪便样品结果,泳道3为实施例4中BX71,来自福建省厦门市犬粪便样品结果,泳道4-10:福建省其它地区来源的CCoV阳性粪便样品;11:阳性对照(以之前用该引物已经扩增获得目的条带样品核酸作为模板);12:阴性对照(用ddH
图2附图为本发明E基因进化树结果;
图3附图为本发明M基因进化树结果;
图4附图为本发明N基因进化树结果;
图5附图为本发明对比例1中不同退火温度的CCoV的EMN基因全序列PCR电泳图,其中,M:DL5000 Plus DNA Marker;1:45℃;2:48℃;3:50℃;4:52℃;5:54℃;6:56℃;7:58℃;8:60℃。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明所需药剂为常规实验药剂,采购自市售渠道;未提及的实验方法为常规实验方法,在此不再一一赘述。
实施例1
从NCBI上下载已知的CCoV不同毒株的全基因序列,分别选取E、M、N基因上下游各1500bp的序列进行比对,选取保守区域。参照NCBI中犬冠状病毒HLJ-071毒株(GeneBank登录号为KY063616.1)基因组序列,E基因位全长从25826nt至26074nt,M基因位全长从26055nt至26876nt,N基因位全长从26889nt至28037nt,通过引物设计软件Primer Premier5.0于保守区域设计用于E、M、N基因全序列一步扩增引物。上游引物CCoV-EMN1(SEQ ID NO:3)从25740n至25757nt(18nt),下游引物CCoV-EMN2从29177nt至29194nt(18nt),上游引物CCoV-EMN1距离E基因起始位点86bp,下游引物CCoV-EMN2距离N基因终止位点1140bp,序列覆盖E、M、N三个基因,且位于犬冠状病毒保守区域,并采用NCBI中Primer Blast功能进行引物评估,发现部分CCoV毒株中上游引物GCCCGTAGTCGGTGTTTA(SEQ ID NO.3)中第9位“T”为“C”,故形成上游序列SEQ ID NO.4。
上游引物CCoV-EMN1的核苷酸序列为下列任一一个:
GCCCGTAGTCGGTGTTTA;SEQ ID NO:3;
GCCCGTAGCCGGTGTTTA;SEQ ID NO:4。
下游引物CCoV-EMN2:TTCCATTGTTGGCTCGTC;SEQ ID NO:2。
实施例2
一种犬冠状病毒E、M、N基因全序列一步扩增方法,包括以下步骤:
(1)提取病毒RNA:
取适量犬冠状病毒阳性的粪便病料,加入9倍体积的无菌PBS,匀浆后于-20℃保存;反复冻融3次,采用Trizol试剂法提取病毒RNA。
Trizol试剂法的具体方法为:
a、取1mL组织悬液,于4℃,经8000rpm离心10min,获得第一上清液;
b、取300μL第一上清液于无RNA酶的灭菌1.5mL EP管中,加入1000μLTrizol,充分混匀,25℃静置5min;
c、加入200μL三氯甲烷,充分混匀,25℃静置5min,于4℃,经12000rpm离心10min,获得第二上清液;
d、取500μL第二上清液至新的1.5mL EP管中,加入500μL异丙醇,充分混匀,-20℃静置20min,于4℃,经12000rpm离心10min;
e、小心弃掉上清,加入1000μL 75%的乙醇(DEPC水配置),震荡混匀后,4℃12000r离心10min;
f、小心倒掉上清液,倒置于吸水纸上,25℃自然风干;
g、加入30μL无RNase ddH
(2)cDNA合成:
采用
(3)PCR扩增:
使用上游引物CCoV-EMN1及下游引物CCoV-EMN2对cDNA进行PCR扩增,得到含有E、M、N基因全序列片段的PCR扩增产物。
上游引物CCoV-EMN1的核苷酸序列为GCCCGTAGTCGGTGTTTA;SEQ ID NO:3。
下游引物CCoV-EMN2:CAAGGCAGTCTGGTTTCA;SEQ ID NO:2。
PCR扩增反应体系为:
上游引物CCoV-EMN1、下游引物CCoV-EMN2的浓度为10pmol/μL。
PCR扩增反应程序为:
95℃预变性5min;95℃变性30s,54℃退火30s,72℃延伸5min,设置35个循环;72℃终延伸10min。
(4)基因片段检测及测序:
将PCR扩增产物经核酸凝胶电泳进行检测,电泳结果如图1中的泳道1所示,琼脂糖凝胶电泳显示CCoV阳性样本中扩增包含有E、M、N基因全长序列的3455bp的目的片段,与预期大小一致。
将目的片段采用FastPure Gel DNAExtraction Mini Kit试剂盒进行纯化,再送至深圳华大基因股份有限公司进行测序,将测序结果剪辑后的E、M、N基因序列分别如SEQID NO:5、SEQ ID NO:6、SEQ ID NO:7所示。命名该病料样品中含有的CCoV毒株为BD15。即:SEQ ID NO:5(BD15-E);SEQ ID NO:6(BD15-M);SEQ ID NO:7(BD15-N)。
BD15-E:
ATGACGTTCCCTAGGGCATTGACTGTCATAGATGACAATGGAATGGTCATTAGTATCATTTTCTGGTTCCTGTTGATAATTATATTGATATTACTCTCAATAGCATTGCTAAATATAATTAAGCTATGCATGGTATGTTGTAATTTAGGAAGAACAGTTATCATTGTCCCAGCACAACATGCCTATGATGCCTATAAGAATTTTATGCGAATTAAAGCATACAACCCCGACGAAGCACTCCTTGTTTGA;SEQ ID NO:5。
BD15-M:
ATGAAGATTTTGTTAATGCTTGCGTGCGTCTTTGCATGCGTTTATGGAGAGCGATATTGTGCTATGCAAGCTGATAGCGGCACTACACAATGTCGTAATGGCACTAATTCTGAGTGTGAATCTTGCTTCAATGGTGGCGATCTTATTTGGCATCTCGCTAACTGGAACTTCAGCTGGTCTATAATATTGATTGTGTTTATAACTGTGTTACAATATGGTAGACCTCAATATAGCTGGTTCGTGTATGGCATTAAAATGCTTATTATGTGGCTACTATGGCCCATTGTGTTAGCTCTTACGATATTTAATGCATACTCGGAATACGAAGTTTCCAGATATGTAATGTTCGGTTTTAGTGTTGCAGGTGCAATTGTTACTTTTATACTTTGGATTATGTATTTTGTTAGATCCATTCAGTTATACAGAAGGACTAAGTCTTGGTGGTCTTTTAACCCTGAAACTAATGCAATTCTTTGCGTTAGTGCATTAGGAAGAAGCTACGTGCTTCCTCTTGAAGGTGTGCCAACTGGCGTCACTTTAACATTGCTTTCAGGGAATTTGTACGCTGAAGGATTCAAAATTGCTGGTGGTATGAACATCGACAATTTACCAAAATACGTAATGGTTGCATTACCTAGCAGGACCATCGTCTACACACTTGTTGGCAAGAAATTGAAAGCAAGTAGCGCAACTGGATGGGCTTACTATGTAAAATCTAAAGCCGGTGATTACTCAACAGACGCAAGAACTGACAATTTGAGTGAGCAAGAAAAATTATTACATATGGTATAA;SEQ ID NO:6。
BD15-N:
ATGGCCAACCAGGGACAACGCGTTAGCTGGGGAGATGAATCTACCAAAAAGCGTGGTCGTTCCAATTCTCGTGGTCGGAAGAATAATAATATACCTCTTTCATTCTTCAACCCCATTACCCTCCAACAAGGTTCAAAATTTTGGAATTTATGTCCGAGAGACTTTGTACCCAAAGGAATAGGTAACAAGGATCAACAGATTGGTTATTGGAATAGACAAACTCGCTATCGCATGGTGAAGGGCCAACGTAAGGAGCTTCCTGAAAGATGGTTCTTCTACTATTTGGGCACTGGACCTCATGCAGATGCCAAATTTAAAGATAGAATAGATGGAGTTGTCTGGGTTGCCAAGGATGGTGCCATGAATAAACCAACTACACTTGGTAATCGTGGTGCTAATAATGAATCCAAAGCTTTGAAATTCGATGGTAAAGTTCCAGGAGAATTTCAACTTGAAGTGAACCAATCAAGGGACAATTCAAGGTCACGCTCTCAATCTAGATCTCAGTCTAGAAATAGATCTCAATCTAGAGGAAGGCAACAATCCAATAACAAGAAGGATGACAGTGTAGAACAAGCTGTTCTTGCTGCACTCAAAAAGTTAGGTGTTGACACAGAAAAACAACAACAACGCTCGCGTTCTAAATCCAAGGAACGTAGCAACTCTAAGACAAGAGACACTACACCTAAGAATGAAAACAAACACACCTGGAAGAGAACTGCAGGTAAAGGTGATGTGACAAAATTTTATGGAGCTAGAAGTAGTTCAGCCAATTTTGGTGACAGCGATCTCGTTGCCAATGGGAACGGTGCCAAGCATTACCCACAACTGGCTGAATGTGTTCCATCTATATCTAGCATTCTGTTTGGGAGCCATTGGACTGCAAAGGAAGATGGTGATCAGATTGAAGTCACATTCACACACAAATACCACTTGCCCAAGGATGATCCTAAGACAGGACAATTCCTTCAGCAGATTAATGCATATGCTCGTCCATCAGAGGTGGCAAAAGAACAGAGACAAAGAAAAGCTCGTTCTAAATCTGCAGATAAGTCAGAGCAAGAGGTTGTACCTGATGTATTAACAGAAAATTACACAGATGTGTTTGATGACACACAGGTTGAGATTATTGATGAGGTTACGAACTAA;SEQ ID NO:7。
实施例3
一种犬冠状病毒E、M、N基因全序列一步扩增方法,步骤(1)采用的病料为犬冠状病毒阳性的粪便,上游引物为GCCCGTAGCCGGTGTTTA;SEQ ID NO:4,其余步骤同实施例2。
在基因片段检测及测序步骤中,电泳结果如图1中的泳道2所示,琼脂糖凝胶电泳显示CCoV阳性样本中扩增包含有E、M、N基因全长序列的3455bp的目的片段,与预期大小一致。
将测序结果剪辑后的E、M、N基因序列分别如SEQ ID NO:8、SEQ ID NO:9、SEQ IDNO:10所示。命名该病料样品中含有的CCoV的毒株为BQ25。
即:SEQ ID NO:8(BQ25-E);SEQ ID NO:9(BQ25-M);SEQ ID NO:10(BQ25-N)。
BQ25-E:
ATGACGTTCCCTAGGGCATTGACTGTCATAGATGACAATGGAATGGTCATTAGTATCATTTTCTGGTTCCTGTTGATAATTATATTGATATTACTCTCAATAGCATTGCTAAATATAATTAAGCTATGCATGGTATGTTGTAATTTAGGAAGAACAGTTATCATTGTCCCAGCACAACATGCCTATGATGCCTATAAGAATTTTATGCGAATTAAAGCATACAACCCTGACGAAGCACTCCTTGTTTGA;SEQ ID NO:8。
BQ25-M:
ATGAAGATTTTGTTAATTCTTGCGTGCGTCTTTGCATGCGTTTATGGAGAGCGATATTGTGCTATGCAAGCTGATAGCGGCATCACACAATGTCGTAATGGCACTAATTTTGAGTGTGAATCTTGCTTCAATGGTGGCGATCTTATTTGGCATCTCGCTAACTGGAACTTCAGCTGGTCTATAATATTGATTGTGTTTATAACTGTGTTACAATATGGTAGACCTCAATTTAGCTGGTTCGTGTATGGCATTAAAATGCTTATTATGTGGCTACTATGGCCCATTGTGTTAGCTCTTACGATATTTAATGCATACTCGGAATACGAAGTTTCCAGATATGTAATGTTCGGCTTTAGTGTTGCAGGTGCAATTGTTACTTTTATACTTTGGATTATGTATTTTGTTAGATCCATTCAGTTATACAGAAGAACTAAGTCTTGGTGGTCTTTCAACCCTGAAACTAACGCAATTCTTTGCGTTAGTGCATTAGGAAGAAGCTACGTGCTCCCTCTCGAAGGTGTGCCAACTGGCGTCACTTTAACATTGCTTTCAGGGAATTTGTATGCTGAAGGGTTCAAAATTGCTGGTGGTATGAACATCGACAATTTACCAAAATACGTAATGGTTGCATTACCTAGCAGGACCATCGTCTACACACTTGTTGGCAAGAAATTGAAAGCAAGTAGCGCAACTGGATGGGCTTACTATGTAAAATCTAAAGCCGGTGATTACTCAACAGACGCAAGAACTGACAATTTGAGTGAGCAAGAAAAATTATTACATATGGTATAA;SEQ ID NO:9。
BQ25-N:
ATGGCCAACCAGGGACAACGCGTTAGCTGGGGAGATGAATCTACCAAAAAGCGTGGTCGTTCCAATTCTCGTGGTCGGAAGAATAATAATATACCTCTTTCATTCTTCAACCCCATTACCCTCCAACAAGGTTCAAAATTTTGGAATTTATGTCCGAGAGACTTTGTACCCAAAGGAATAGGTAACAAGGATCAACAGATTGGTTATTGGAATAGACAAACTCGCTATCGCATGGTGAAGGGCCAACGTAAGGAGCTTCCTGAAAGATGGTTCTTCTACTATTTGGGCACTGGACCTCATGCAGATGCCAAATTTAAAGATAGAATAGATGGAGTTGTCTGGGTTGCCAAGGATGGTGCCATGAATAAACCAACTACACTTGGTAATCGTGGTGCTAATAATGAATCCAAAGCTTTGAAATTCGATGGTAAAGTTCCAGGAGAATTTCAACTTGAAGTGAACCAATCAAGGGACAATTCAAGGTCACGCTCTCAATCTAGATCTCAGTCTAGAAATAGATCTCAATCTAGAGGAAGGCAACAATCCAATAACAAGAAGGATGACAGTGTAGAACAAGCTGTTCTTGCTGCACTCAAAAAGTTAGGTGTTGACACAGAAAAACAACAACAACGCTCGCGTTCTAAATCCAAGGAACGTAGCAACTCTAAGACAAGAGACACTACACCTAAGAATGAAAACAAACACACCTGGAAGAGAACTGCAGGTAAAGGTGATGTGACTAAATTTTATGGAGCTAGAATTAGTTCAGCCAATTTTGGTGACAGCGATCTCGTTGCCATGGGAACGGTGCCAAGCATTACCCACAACTGGCTGAATGTGTTCCATCTATATCTAGCATTCTGTTTGGGAGCCATTGGACTGTAAAGGAAGATGGTGACCAGATTGAAGTCACTTTCACACACAAATACCACTTGCCCAAGGATGATCCTAAGACAGGACAATTCCTTCAGCAGATTAATGCATATGCTCGTCCATCAGAGGTGGCAAAAGAACAGAGACAAAGAAAAGCTCGTTCTAAATCTGCAGATAAGTCAGAGCAAGAGGTTGTACCTGATGTATTAACAGAAAATTACACAGATGTGTTTGATGACACACAGGTTGAGATTATTGATGAGGTTACGAACTAA;SEQ ID NO:10。
实施例4
一种犬冠状病毒E、M、N基因全序列一步扩增方法,步骤(1)采用的病料为犬冠状病毒阳性的粪便,上游引物为GCCCGTAGCCGGTGTTTA;SEQ ID NO:4,其余步骤同实施例2。
在基因片段检测及测序步骤中,电泳结果如图1中的泳道3所示,琼脂糖凝胶电泳显示CCoV阳性样本中扩增包含有E、M、N基因全长序列的3455bp的目的片段,与预期大小一致。
将测序结果剪辑后的E、M、N基因序列分别如SEQ ID NO:11、SEQ ID NO:12、SEQ IDNO:13所示。命名该病料样品中含有的CCoV毒株为BX71。
即:SEQ ID NO:11(BX71-E);SEQ ID NO:12(BX71-M);SEQ ID NO:13(BX71-N)。
BX71-E:
ATGACGTTCCCTAGGGCATTGACTGTCATAGATGACAATGGAATGGTCATTAGTATCATTTTCTGGTTCCTGTTGATAATTATATTGATATTACTCTCAATAGCATTGCTAAATATAATTAAGCTATGCATGGTATGTTGTAATTTAGGAAGAACAGTTATCATTGTCCCAGCACAACATGCCTATGATGCCTATAAGAATTTTATGCGAATTAAAGCATATAACCCCGACGAAGCACTCCTTGTTTGA;SEQ ID NO:11。
BX71-M:
ATGAAGATTTTGTTAATGCTTGCGTGCGTTTTTGCATGCGTTTATGGAGAGCGATATTGTGCTATGCAAGCTGATAGCGGCATCACACAATGTCGTAATGGCACTAACTCTGAGTGTGAATCTTGCTTCAATGGTGGTGATCTTATTTGGCACCTCGCTAACTGGAACTTCAGCTGGTCTATAATATTGATTGTTTTTATAACTGTGTTACAATATGGTAGACCTCAATTTAGCTGGTTCGTGTATGGCATTAAAATGCTCATTATGTGGCTACTATGGCCCATTGTGCTAGCTCTTACGATATTTAATGCATACTCGGAATACGAAGTTTCCAGATATGTAATGTTCGGCTTTAGTGTTGCAGGTGCAATTGTTACTTTTATACTTTGGATTATGTATTTTGTTAGATCCATTCAGTTATATAGAAGGACTAAGTCTTGGTGGTCTTTTAACCCTGAAACTAATGCAATTCTTTGCGTTAGTGCATTAGGAAGAAGCTACGTGCTTCCTCTTGAAGGTGTGCCAACTGGCGTCACTTTAACATTGCTTTCAGGGAATTTGTATGCTGAAGGATTCAAAATTGCTGGTGGTATGAACATCGACAATTTACCAAAATATGTAATGGTTGCATTACCTAGCAGGACCATCGTCTACACACTTGTTGGCAAGAAATTGAAAGCAAGTAGCGCAACTGGATGGGCTTACTATGTAAAATCTAAAGCCGGTGATTACTCAACAGACGCAAGAACGGACAATTTGAGTGAGCAAGAAAAATTATTACATATGGTATAA;SEQ ID NO:12。
BX71-N:
ATGGCCAACCAGGGACAACGCGTTAGCTGGGGAGATGAATCTACCAAAAAGCGTGGTCGTTCCAATTCTCGTGGTCGGAAGAATAATAATATACCTCTTTCATTCTTCAACCCCATTACCCTCCAACAAGGTTCTAAATTTTGGAATTTATGTCCGAGAGACTTTGTACCCAAAGGAATAGGTAACAAGGATCAACAGATTGGTTATTGGAATAGACAAACTCGCTATCGCATGGTGAAGGGCCAACGTAAGGAGCTTCCTGAAAGATGGTTCTTCTATTATTTGGGCACTGGACCTCATGCAGATGCCAAATTTAAAGATAGAATAGATGGAGTTGTCTGGGTTGCCAAGGATGGTGCCATGAATAAACCAACTACACTTGGTAATCGTGGTGCTAATAATGAATCCAAAGCTTTGAAATTCGATGGTAAAGTTCCAGGAGAATTTCAACTTGAAGTGAACCAATCAAGGGACAATTCAAGGTCACGCTCTCAATCTAGATCTCAGTCTAGAAATAGATCTCAATCTAGAGGAAGGCAACAATCCAATAACAAGAAGGATGACAGTGTAGAACAAGCTGTTCTTGCTGCACTCAAAAAGTTAGGTGTTGACACAGAAAAACAACAACAACGCTCGCGTTCTAAATCCAAAGAACGTAGCAACTCTAAGACAAGAGACACTACACCTAAGAATGAAAACAAACACACCTGGAAGAGAACTGCAGGTAAAGGTGATGTGACAAAATTTTATGGAGCTAGAAGTAGTTCAGCCAATTTTGGTGACAGCGATCTCGTTGCCAATGGGAACGGTGCCAAGCATTACCCACAACTGGCTGAATGTGTTCCATCTATATCTAGCATTCTGTTTGGGAGCCATTGGACTGCAAAGGAAGATGGTGACCAGATTGAAGTCACATTCACACACAAATACCACTNNCCNAAGGATGANNCTAAGACAGGACAATTCCTTCAGCAGATTAATGCATACGCTCGTCCATCAGAGGTGGCAAAAGAACAGAGACAAAGAAAAGCTCGTTCTAAATCTGCAGATAAGTCAGAGCAAGAGGTTGTACCTGATGTATTAACAGAAAATTACACAGATGTGTTTGATGACACACAGGTTGAGATTATTGATGAGGTGACGAACTAA;SEQ ID NO:13。
实施例5
使用本发明方法分离得BX71、BD15、BQ25三个毒株的E、M、N基因序列,与NCBI上已知的犬冠状病毒E、M、N基因进行比对,同源性比对毒株的名称、GeneBank登录号、来源及年份如表1所示。
E基因进化树结果如图2所示:BX71、BD15、BQ25毒株的E基因在同一个分支上,亲缘性较高;与英国2020年分离的CCoV2020/7毒株在一个分支上,进化距离较近;且与最早分离出来的德国171毒株不在一个枝干上,进化关系距离最远。
M基因进化树结果如图3所示:BX71、BD15、BQ25毒株的M基因在同一个分支上,亲缘性较高;与美国2008年分离的CCoV/NTU336/F/2008毒株在一个分支上,进化距离较近;且与最早分离出来的德国171毒株不在一个枝干上,进化关系距离最远。
N基因进化树结果如图2所示:BX71、BD15、BQ25毒株的N基因在同一个分支上,亲缘性较高;与英国2020年分离的CCoV2020/7毒株在一个分支上,进化距离较近;且与最早分离出来的德国171毒株不在一个枝干上,进化关系距离最远。
表1:同源性比对毒株
对比例1
PCR条件的优化
在反应体系与反应程序中,设置退火温度为45℃、48℃、50℃、52℃、54℃、56℃、58℃和60℃,其余操作同实施例2。
实验结果如图5所示,结果表明,各退火温度均扩增出特异性条带,目的条带大小与预期大小相符,约为3455bp。当退火温度为45、50、54℃时,特异性条带最清晰。在PCR检测中,退火温度越高特异性越强,故选择54℃为本发明的最适退火温度。
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。
对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
序列表
<110>龙岩学院
<120>扩增犬冠状病毒E、M、N基因全序列的引物对及其应用
<160>13
<170>SIPOSequenceListing 1.0
<210>1
<211>18
<212>DNA
<213>人工序列(Artificial Sequence)
<220>
<221>misc_feature
<222>(9)..(9)
<223>y为c或t
<400>1
gcccgtagyc ggtgttta18
<210>2
<211>18
<212>DNA
<213>人工序列(Artificial Sequence)
<400>2
ttccattgtt ggctcgtc18
<210>3
<211>18
<212>DNA
<213>人工序列(Artificial Sequence)
<400>3
gcccgtagtc ggtgttta18
<210>4
<211>18
<212>DNA
<213>人工序列(Artificial Sequence)
<400>4
gcccgtagcc ggtgttta18
<210>5
<211>249
<212>DNA
<213>人工序列(Artificial Sequence)
<400>5
atgacgttcc ctagggcatt gactgtcata gatgacaatg gaatggtcat tagtatcatt60
ttctggttcc tgttgataat tatattgata ttactctcaa tagcattgct aaatataatt 120
aagctatgca tggtatgttg taatttagga agaacagtta tcattgtccc agcacaacat 180
gcctatgatg cctataagaa ttttatgcga attaaagcat acaaccccga cgaagcactc 240
cttgtttga 249
<210>6
<211>792
<212>DNA
<213>人工序列(Artificial Sequence)
<400>6
atgaagattt tgttaatgct tgcgtgcgtc tttgcatgcg tttatggaga gcgatattgt60
gctatgcaag ctgatagcgg cactacacaa tgtcgtaatg gcactaattc tgagtgtgaa 120
tcttgcttca atggtggcga tcttatttgg catctcgcta actggaactt cagctggtct 180
ataatattga ttgtgtttat aactgtgtta caatatggta gacctcaata tagctggttc 240
gtgtatggca ttaaaatgct tattatgtgg ctactatggc ccattgtgtt agctcttacg 300
atatttaatg catactcgga atacgaagtt tccagatatg taatgttcgg ttttagtgtt 360
gcaggtgcaa ttgttacttt tatactttgg attatgtatt ttgttagatc cattcagtta 420
tacagaagga ctaagtcttg gtggtctttt aaccctgaaa ctaatgcaat tctttgcgtt 480
agtgcattag gaagaagcta cgtgcttcct cttgaaggtg tgccaactgg cgtcacttta 540
acattgcttt cagggaattt gtacgctgaa ggattcaaaa ttgctggtgg tatgaacatc 600
gacaatttac caaaatacgt aatggttgca ttacctagca ggaccatcgt ctacacactt 660
gttggcaaga aattgaaagc aagtagcgca actggatggg cttactatgt aaaatctaaa 720
gccggtgatt actcaacaga cgcaagaact gacaatttga gtgagcaaga aaaattatta 780
catatggtat aa 792
<210>7
<211>1149
<212>DNA
<213>人工序列(Artificial Sequence)
<400>7
atggccaacc agggacaacg cgttagctgg ggagatgaat ctaccaaaaa gcgtggtcgt60
tccaattctc gtggtcggaa gaataataat atacctcttt cattcttcaa ccccattacc 120
ctccaacaag gttcaaaatt ttggaattta tgtccgagag actttgtacc caaaggaata 180
ggtaacaagg atcaacagat tggttattgg aatagacaaa ctcgctatcg catggtgaag 240
ggccaacgta aggagcttcc tgaaagatgg ttcttctact atttgggcac tggacctcat 300
gcagatgcca aatttaaaga tagaatagat ggagttgtct gggttgccaa ggatggtgcc 360
atgaataaac caactacact tggtaatcgt ggtgctaata atgaatccaa agctttgaaa 420
ttcgatggta aagttccagg agaatttcaa cttgaagtga accaatcaag ggacaattca 480
aggtcacgct ctcaatctag atctcagtct agaaatagat ctcaatctag aggaaggcaa 540
caatccaata acaagaagga tgacagtgta gaacaagctg ttcttgctgc actcaaaaag 600
ttaggtgttg acacagaaaa acaacaacaa cgctcgcgtt ctaaatccaa ggaacgtagc 660
aactctaaga caagagacac tacacctaag aatgaaaaca aacacacctg gaagagaact 720
gcaggtaaag gtgatgtgac aaaattttat ggagctagaa gtagttcagc caattttggt 780
gacagcgatc tcgttgccaa tgggaacggt gccaagcatt acccacaact ggctgaatgt 840
gttccatcta tatctagcat tctgtttggg agccattgga ctgcaaagga agatggtgat 900
cagattgaag tcacattcac acacaaatac cacttgccca aggatgatcc taagacagga 960
caattccttc agcagattaa tgcatatgct cgtccatcag aggtggcaaa agaacagaga1020
caaagaaaag ctcgttctaa atctgcagat aagtcagagc aagaggttgt acctgatgta1080
ttaacagaaa attacacaga tgtgtttgat gacacacagg ttgagattat tgatgaggtt1140
acgaactaa1149
<210>8
<211>249
<212>DNA
<213>人工序列(Artificial Sequence)
<400>8
atgacgttcc ctagggcatt gactgtcata gatgacaatg gaatggtcat tagtatcatt60
ttctggttcc tgttgataat tatattgata ttactctcaa tagcattgct aaatataatt 120
aagctatgca tggtatgttg taatttagga agaacagtta tcattgtccc agcacaacat 180
gcctatgatg cctataagaa ttttatgcga attaaagcat acaaccctga cgaagcactc 240
cttgtttga 249
<210>9
<211>792
<212>DNA
<213>人工序列(Artificial Sequence)
<400>9
atgaagattt tgttaattct tgcgtgcgtc tttgcatgcg tttatggaga gcgatattgt60
gctatgcaag ctgatagcgg catcacacaa tgtcgtaatg gcactaattt tgagtgtgaa 120
tcttgcttca atggtggcga tcttatttgg catctcgcta actggaactt cagctggtct 180
ataatattga ttgtgtttat aactgtgtta caatatggta gacctcaatt tagctggttc 240
gtgtatggca ttaaaatgct tattatgtgg ctactatggc ccattgtgtt agctcttacg 300
atatttaatg catactcgga atacgaagtt tccagatatg taatgttcgg ctttagtgtt 360
gcaggtgcaa ttgttacttt tatactttgg attatgtatt ttgttagatc cattcagtta 420
tacagaagaa ctaagtcttg gtggtctttc aaccctgaaa ctaacgcaat tctttgcgtt 480
agtgcattag gaagaagcta cgtgctccct ctcgaaggtg tgccaactgg cgtcacttta 540
acattgcttt cagggaattt gtatgctgaa gggttcaaaa ttgctggtgg tatgaacatc 600
gacaatttac caaaatacgt aatggttgca ttacctagca ggaccatcgt ctacacactt 660
gttggcaaga aattgaaagc aagtagcgca actggatggg cttactatgt aaaatctaaa 720
gccggtgatt actcaacaga cgcaagaact gacaatttga gtgagcaaga aaaattatta 780
catatggtat aa 792
<210>10
<211>1148
<212>DNA
<213>人工序列(Artificial Sequence)
<400>10
atggccaacc agggacaacg cgttagctgg ggagatgaat ctaccaaaaa gcgtggtcgt60
tccaattctc gtggtcggaa gaataataat atacctcttt cattcttcaa ccccattacc 120
ctccaacaag gttcaaaatt ttggaattta tgtccgagag actttgtacc caaaggaata 180
ggtaacaagg atcaacagat tggttattgg aatagacaaa ctcgctatcg catggtgaag 240
ggccaacgta aggagcttcc tgaaagatgg ttcttctact atttgggcac tggacctcat 300
gcagatgcca aatttaaaga tagaatagat ggagttgtct gggttgccaa ggatggtgcc 360
atgaataaac caactacact tggtaatcgt ggtgctaata atgaatccaa agctttgaaa 420
ttcgatggta aagttccagg agaatttcaa cttgaagtga accaatcaag ggacaattca 480
aggtcacgct ctcaatctag atctcagtct agaaatagat ctcaatctag aggaaggcaa 540
caatccaata acaagaagga tgacagtgta gaacaagctg ttcttgctgc actcaaaaag 600
ttaggtgttg acacagaaaa acaacaacaa cgctcgcgtt ctaaatccaa ggaacgtagc 660
aactctaaga caagagacac tacacctaag aatgaaaaca aacacacctg gaagagaact 720
gcaggtaaag gtgatgtgac taaattttat ggagctagaa ttagttcagc caattttggt 780
gacagcgatc tcgttgccat gggaacggtg ccaagcatta cccacaactg gctgaatgtg 840
ttccatctat atctagcatt ctgtttggga gccattggac tgtaaaggaa gatggtgacc 900
agattgaagt cactttcaca cacaaatacc acttgcccaa ggatgatcct aagacaggac 960
aattccttca gcagattaat gcatatgctc gtccatcaga ggtggcaaaa gaacagagac1020
aaagaaaagc tcgttctaaa tctgcagata agtcagagca agaggttgta cctgatgtat1080
taacagaaaa ttacacagat gtgtttgatg acacacaggt tgagattatt gatgaggtta1140
cgaactaa 1148
<210>11
<211>249
<212>DNA
<213>人工序列(Artificial Sequence)
<400>11
atgacgttcc ctagggcatt gactgtcata gatgacaatg gaatggtcat tagtatcatt60
ttctggttcc tgttgataat tatattgata ttactctcaa tagcattgct aaatataatt 120
aagctatgca tggtatgttg taatttagga agaacagtta tcattgtccc agcacaacat 180
gcctatgatg cctataagaa ttttatgcga attaaagcat ataaccccga cgaagcactc 240
cttgtttga 249
<210>12
<211>792
<212>DNA
<213>人工序列(Artificial Sequence)
<400>12
atgaagattt tgttaatgct tgcgtgcgtt tttgcatgcg tttatggaga gcgatattgt60
gctatgcaag ctgatagcgg catcacacaa tgtcgtaatg gcactaactc tgagtgtgaa 120
tcttgcttca atggtggtga tcttatttgg cacctcgcta actggaactt cagctggtct 180
ataatattga ttgtttttat aactgtgtta caatatggta gacctcaatt tagctggttc 240
gtgtatggca ttaaaatgct cattatgtgg ctactatggc ccattgtgct agctcttacg 300
atatttaatg catactcgga atacgaagtt tccagatatg taatgttcgg ctttagtgtt 360
gcaggtgcaa ttgttacttt tatactttgg attatgtatt ttgttagatc cattcagtta 420
tatagaagga ctaagtcttg gtggtctttt aaccctgaaa ctaatgcaat tctttgcgtt 480
agtgcattag gaagaagcta cgtgcttcct cttgaaggtg tgccaactgg cgtcacttta 540
acattgcttt cagggaattt gtatgctgaa ggattcaaaa ttgctggtgg tatgaacatc 600
gacaatttac caaaatatgt aatggttgca ttacctagca ggaccatcgt ctacacactt 660
gttggcaaga aattgaaagc aagtagcgca actggatggg cttactatgt aaaatctaaa 720
gccggtgatt actcaacaga cgcaagaacg gacaatttga gtgagcaaga aaaattatta 780
catatggtat aa 792
<210>13
<211>1149
<212>DNA
<213>人工序列(Artificial Sequence)
<400>13
atggccaacc agggacaacg cgttagctgg ggagatgaat ctaccaaaaa gcgtggtcgt60
tccaattctc gtggtcggaa gaataataat atacctcttt cattcttcaa ccccattacc 120
ctccaacaag gttctaaatt ttggaattta tgtccgagag actttgtacc caaaggaata 180
ggtaacaagg atcaacagat tggttattgg aatagacaaa ctcgctatcg catggtgaag 240
ggccaacgta aggagcttcc tgaaagatgg ttcttctatt atttgggcac tggacctcat 300
gcagatgcca aatttaaaga tagaatagat ggagttgtct gggttgccaa ggatggtgcc 360
atgaataaac caactacact tggtaatcgt ggtgctaata atgaatccaa agctttgaaa 420
ttcgatggta aagttccagg agaatttcaa cttgaagtga accaatcaag ggacaattca 480
aggtcacgct ctcaatctag atctcagtct agaaatagat ctcaatctag aggaaggcaa 540
caatccaata acaagaagga tgacagtgta gaacaagctg ttcttgctgc actcaaaaag 600
ttaggtgttg acacagaaaa acaacaacaa cgctcgcgtt ctaaatccaa agaacgtagc 660
aactctaaga caagagacac tacacctaag aatgaaaaca aacacacctg gaagagaact 720
gcaggtaaag gtgatgtgac aaaattttat ggagctagaa gtagttcagc caattttggt 780
gacagcgatc tcgttgccaa tgggaacggt gccaagcatt acccacaact ggctgaatgt 840
gttccatcta tatctagcat tctgtttggg agccattgga ctgcaaagga agatggtgac 900
cagattgaag tcacattcac acacaaatac cactnnccna aggatgannc taagacagga 960
caattccttc agcagattaa tgcatacgct cgtccatcag aggtggcaaa agaacagaga1020
caaagaaaag ctcgttctaa atctgcagat aagtcagagc aagaggttgt acctgatgta1080
ttaacagaaa attacacaga tgtgtttgat gacacacagg ttgagattat tgatgaggtg1140
acgaactaa1149