一种基于对抗性知识蒸馏的联邦学习后门擦除方法
文献发布时间:2024-04-18 19:58:30
技术领域
本发明涉及网络安全领域,尤其是涉及一种基于对抗性知识蒸馏的联邦学习后门擦除方法。
背景技术
联邦学习(Federated Learning,FL)是一种分布式机器学习方法,在保证本地数据隐私的前提下允许多个客户端协作训练神经网络模型。然而,FL场景下的数据投毒攻击成为了一种被广泛关注的安全威胁。后门攻击作为一种定向数据投毒攻击,诱导全局模型在良性样本上生成正确的输出,同时在特定样本上输出攻击者指定的错误预测。
现有的后门防御措施可以分为四类:中毒数据检测、鲁棒性学习、后门检测和后门擦除。在FL场景中,由于终端设备的计算资源有限且信任关系复杂,后门防御措施需被部署在服务器上。在单体模型下上述后门防御措施均有着可观的效果,但当将它们部署到FL服务端还面临以下挑战:(1)服务器只参与模型聚合和分发,不参与本地训练,导致中毒数据检测和鲁棒性学习措施不可用;(2)隐私保护要求导致服务器的无法访问训练数据,而触发器逆向和后门擦除措施往往依赖于高质量的干净数据;(3)现有的采取检测并剔除恶意本地更新的FL后门防御方法需要检查模型权重,这也可能导致侵犯隐私。此外,它们中的大多数仅对特定的攻击模型有效,如果不满足有关数据分布或攻击者策略的假设,则可能会失败(拒绝良性权重或接受恶意权重);(4)FL中另一些后门防御工作通过裁剪、噪声或平滑来稀释后门影响,尽管这些策略不需要特定的攻击模型假设,但它们可能会显著降低模型的良性性能。
知识蒸馏(Knowledge Distillation,KD)有望克服上述挑战,为解决FL中的后门擦除问题提供新思路。现有的基于知识蒸馏的后门擦除方法包括:(1)基于模型响应的知识蒸馏;(2)基于注意力的知识蒸馏,通过将基于注意力的知识从经过干净数据微调的教师蒸馏到后门模型中来擦除后门;(3)自注意力蒸馏,对后门隐藏在深层而不是浅层的观察,让不好的深层学习好的浅层。这些方法在很大程度上依赖于高质量的数据集,因此在保护隐私的FL环境中不可用。
发明内容
本发明的目的是为了提供一种基于对抗性知识蒸馏的联邦学习后门擦除方法,通过平衡从后门教师到学生模型的知识转移和用于消除学生模型潜在后门反应的后门正则化来克服现有技术依赖于高质量数据集的限制,适用于保护隐私的FL环境。
本发明的目的可以通过以下技术方案来实现:
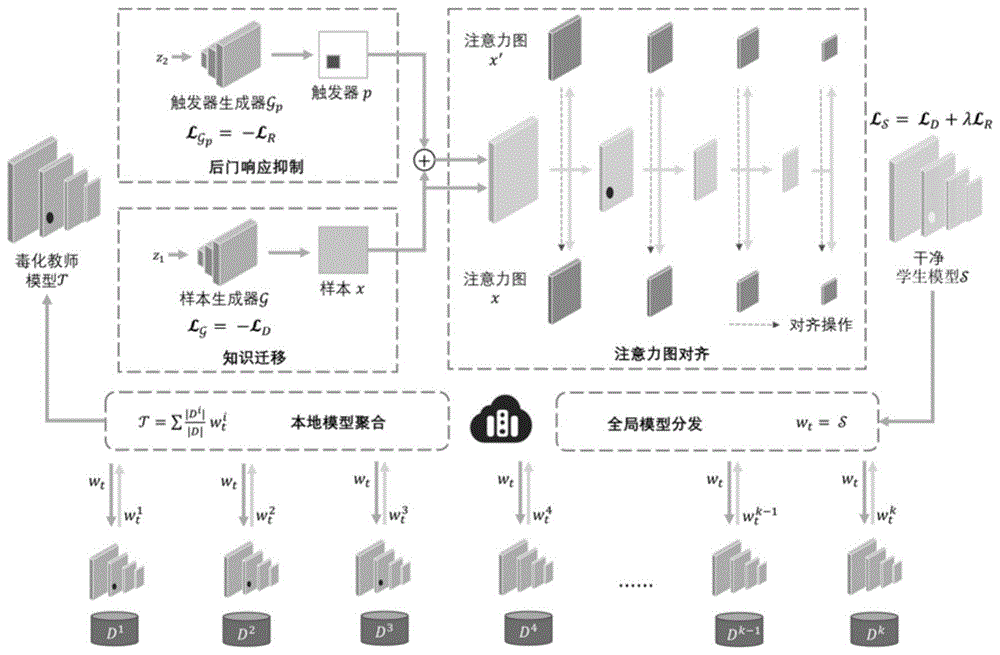
一种基于对抗性知识蒸馏的联邦学习后门擦除方法,用于联邦学习环境下服务端对全局模型中隐含的后门进行擦除,包括以下步骤:
步骤1)服务端利用客户端的本地模型更新初始化教师模型和学生模型;
步骤2)构建对抗训练损失函数,通过对抗性知识蒸馏进行从教师模型到学生模型的知识迁移;
步骤3)服务端利用步骤2)中知识迁移生成的样本,通过后门响应抑制和注意力图对齐两种方法进行后门正则化,确定后门正则化项;
步骤4)服务端交替重复步骤2)和步骤3),基于对抗训练损失函数和后门正则化项进行模型训练,直至学生模型精度收敛,得到擦除后的干净学生模型,并将干净学生模型作为全局模型分发给客户端。
在联邦服务器中执行后门擦除的具体轮次由防御者确定,若联邦学习的某一通信轮次中服务器进行后门擦除,则执行步骤1)。
所述步骤1)中,模型初始化方式具体为:服务器从客户端收集本地更新并聚合得到包含潜在后门的全局模型,将其模型参数复制到与之具有相同模型结构的教师模型和学生模型中。
所述步骤2)包括以下步骤:
步骤2-1)采用无数据对抗性蒸馏将教师的知识传授给学生,利用样本生成器动态重建导致教师和学生模型之间存在巨大差异的样本;
步骤2-2)利用样本生成器重建样本,学生模型基于对抗训练损失函数最小化与教师模型之间的差异。
所述对抗训练损失函数为:
其中,z是从正态分布中随机抽样的向量,
所述步骤3)包括以下步骤:
步骤3-1)利用触发器生成器生成对学生模型最敏感的触发器;
步骤3-2)后门响应抑制:
为了抑制学生模型输出中的后门响应,后门在模型输出层面的特征被描述为:在原始图像上,模型输出正确标签;在包含触发器的图像上,模型输出与正确标签不同的后门目标标签;利用步骤3-1)所生成的触发器,学生模型通过最小化后门响应抑制正则化项,消除在模型输出层面的后门反应;
步骤3-3)注意力图对齐:
为了抑制学生模型中间层的后门相应,后门在模型中间注意力层面的特征被描述为:在原始图像上,中间层注意力分散在对图像分类有贡献的所有图像特征上;在包含触发器的图像上,中间层注意力集中在图像中的触发器区域;利用步骤3-1)所生成的触发器,学生模型通过最小化注意力图对齐正则化项,消除在中间层注意力层面的后门反应;
步骤3-4)结合后门响应抑制正则化项和注意力图对齐正则化项确定总的后门正则化项。
所述后门响应抑制正则化项表示为:
其中,
其中,
其中,
所述总的后门正则化项为:
其中,μ表示注意力图对齐正则化项的权重。
所述步骤4)中,基于对抗训练损失函数和后门正则化项进行模型训练的总体对抗过程描述为:
其中,
在本发明的技术方案中,首先分析了后门反应的特征并提出结合了后门响应抑制和注意力图对齐的后门正则化损失项。其关键思想是,后门模型在良性样本和具有触发器的样本上表现出显著差异的输出和逐层注意力。通过利用对抗优化来最小化这两种差异,可以抑制由任何潜在后门激活的模型输出突变和注意力突变,并最终获得一个没有后门反应的干净学生模型。
与现有技术相比,本发明具有以下有益效果:
(1)与需要干净数据的后门擦除方法相比,本发明通过在服务器端部署对抗性无数据知识蒸馏和后门正则化技术,支持联邦环境下服务器在不掌握任何训练数据前提下的后门擦除;
(2)本发明通过对抗性知识蒸馏中教师模型良性知识向学生模型的充分转移,将后门擦除对模型精度的损害降到了最低程度;
(3)由于本发明提出的后门防御措施仅涉及服务端和全局模型,与联邦学习中本地模型的训练、分发和聚合过程相互独立,因此本发明与原始的联邦学习框架兼容,可以作为一种即插即用式的防御措施应用于联邦学习的任何通信轮次中。
附图说明
图1为本发明的方法流程图;
图2为一种实施例中对抗性知识蒸馏过程中的生成样本与真实训练样本的对比图;
图3为一种实施例中执行后门擦除后的中间层注意力图对比结果;
图4为一种实施例中联邦学习不同擦除周期对模型性能指标的影响曲线图。
具体实施方式
下面结合附图和具体实施例对本发明进行详细说明。本实施例以本发明技术方案为前提进行实施,给出了详细的实施方式和具体的操作过程,但本发明的保护范围不限于下述的实施例。
本实施例提供一种基于对抗性知识蒸馏的联邦学习后门擦除方法,用于联邦学习环境下服务端对全局模型中隐含的后门进行擦除,如图1所示,包括以下步骤:
步骤1)服务端利用客户端的本地模型更新初始化教师模型和学生模型。
在联邦服务器中执行后门擦除的具体轮次由防御者确定,若联邦学习的某一通信轮次中服务器进行后门擦除,则执行步骤1)。
具体的,模型初始化方式为:服务器从客户端收集本地更新并聚合得到包含潜在后门的全局模型,将其模型参数复制到与之具有相同模型结构的教师模型和学生模型中。
步骤2)构建对抗训练损失函数,通过对抗性知识蒸馏进行从教师模型到学生模型的知识迁移。
步骤2)包括以下步骤:
步骤2-1)为了不侵犯数据隐私,采用无数据对抗性蒸馏将教师的知识传授给学生,利用样本生成器
步骤2-2)利用样本生成器重建样本,学生模型基于对抗训练损失函数最小化与教师模型之间的差异。
本实施例中,对抗训练损失函数为:
其中,z是从正态分布中随机抽样的向量,
如图2所示,为了展示本发明不侵犯数据隐私的特点,本实施例在两个数据集:CIFAR10(第一列)和CIFAR100(第二列)上,将模型的真实训练样本(第一行)和对抗性知识蒸馏过程中的生成样本(第二行)进行了比较。由图可知本发明所使用的生成样本与真实样本相似性极低,从而在一定程度上保证了客户端的本地数据隐私。
步骤3)服务端利用步骤2)中知识迁移生成的样本,通过后门响应抑制和注意力图对齐两种方法进行后门正则化,确定后门正则化项,抑制步骤2)中后门知识向学生模型的迁移。
步骤3)包括以下步骤:
步骤3-1)利用触发器生成器
步骤3-2)后门响应抑制
为了抑制学生模型输出中的后门响应,后门在模型输出层面的特征被描述为:在原始图像上,模型输出正确标签;在包含触发器的图像上,模型输出与正确标签不同的后门目标标签。利用步骤3-1)所生成的触发器,学生模型通过最小化后门响应抑制(BackdoorResponse Suppression,BRS)正则化项,消除在模型输出层面的后门反应;
后门响应抑制正则化项表示为:
其中,
步骤3-3)注意力图对齐
隐含后门的神经网络模型,除了在模型输出层面具有一定的后门特征,在中间层注意力层面也包含后门特征。为了抑制学生模型中间层的后门相应,后门在模型中间注意力层面的特征被描述为:在原始图像上,中间层注意力分散在对图像分类有贡献的所有图像特征上;在包含触发器的图像上,中间层注意力集中在图像中的触发器区域。利用步骤3-1)所生成的触发器,学生模型通过最小化注意力图对齐(Attention Map Alignment,AMA)正则化项,消除在中间层注意力层面的后门反应;
其中,
其中,
其中C
步骤3-4)结合后门响应抑制正则化项和注意力图对齐正则化项确定总的后门正则化项。
总的后门正则化项为:
其中,μ表示注意力图对齐正则化项的权重。
如图3所示,对一个后门模型执行本实施例后,模型在注意力层面的后门反应被基本消除,即在包含真实触发器的中毒图像上,学生模型的中间层注意力与不包含后门的干净模型在干净数据上的注意力保持高度近似。
步骤4)服务端交替重复步骤2)和步骤3),基于对抗训练损失函数和后门正则化项进行模型训练,直至学生模型精度收敛,得到擦除后的干净学生模型,并将干净学生模型作为全局模型分发给客户端。
所述步骤4)中,基于对抗训练损失函数和后门正则化项进行模型训练的总体对抗过程描述为:
其中,
对抗性蒸馏过程中,持续观察模型精度是否达到收敛状态,若收敛,则将执行后门擦除得到的干净模型作为全局模型分发给客户端。
如图4所示,本实施例假定联邦学习中第250轮攻击者开始持续投毒,防御者在无防御措施、擦除周期T=10、擦除周期T=20、擦除周期T=30这四种防御部署方式上分别绘制全局模型的模型精度和后门攻击成功率变化曲线。由图可知,在保证模型精度损害较低的情况下,本发明能够将后门攻击成功率降低至1%以下,且擦除周期越短,后门攻击成功率所能达到的最大幅度越低。
以上详细描述了本发明的较佳具体实施例。应当理解,本领域的普通技术人员无需创造性劳动就可以根据本发明的构思做出诸多修改和变化。因此,凡本技术领域中技术人员依据本发明的构思在现有技术的基础上通过逻辑分析、推理、或者有限的实验可以得到的技术方案,皆应在权利要求书所确定的保护范围内。
- 一种基于对抗样本检测的联邦学习后门防御方法和装置
- 一种基于注意力蒸馏的联邦学习后门防御方法