基于多关系图模型的多模态对话问答生成方法
文献发布时间:2023-06-19 18:37:28
技术领域
本发明属于对话问答技术领域,具体涉及一种多模态对话问答生成方法。
背景技术
当前对话问答系统领域内研究主要分为文本和多模态两大分支。文本对话问答任务主要具有两大难点:回答生成需要对话上下文推理和欠缺大规模对话数据集。由于预训练语言模型(Language Models,LMs)已经从其它文本数据中习得丰富的语义信息,可以进行一定程度的推理,并且有效弥补对话数据量不足的问题,使系统在低资源背景下仍能取得较好的结果。因此,将预训练语言模型引入对话问答任务可以加深系统对文本的理解,基于历史对话轮次的推理处理当前用户提问,提高生成回答的质量。ISCA2020中,Whang等人在开放域对话中应用预训练语言模型来选择候选回答,其中预训练语言模型的输出(如BERT中的[CLS]标志)被用作每个对话上下文和候选答案对的上下文表示。WNGT2019中,Budzianowski等人假设可以获得真实对话状态,将输入合并为单个序列以生成任务导向型对话的响应。由于对话状态和数据库状态可以视作原始文本输入,可以使用预训练语言模型对系统进行微调。ICASSP2020中,Lai等人引入GPT-2模型,利用模型的输出表示预测插槽值,进而跟踪对话状态。
ACL2020中,层次指针网络也在文本对话系统中得到了广泛应用。ICLR2019中,Wu等人合并了全局编码器和本地解码器,实现了在任务导向型对话设置中共享外部知识。NAACL2019中,Reddy等人面向任务导向型对话设计了一个多级存储的框架。ACL2019中,Tian等人探索了如何在训练过程中提取有价值的信息,并以此搭建了一个记忆启动架构。此外,多任务学习也被证明可以优化自然语言回答的表现。ACL2019中Chen等人的工作中,工作记忆被引入该任务,通过与两个长期记忆充分交互,它可以捕获对话历史和知识库的元组以生成高质量回答。EMNLP2019中,Lin等人鉴于异构记忆网络具有同时利用话上下文、用户提问和知识库信息的能力,也将其应用于该领域的研究。
多模态对话问答为实现功能强大的对话系统开创了新的格局。当前研究主要聚焦于如何利用静态图像和文本之间多粒度互补信息弥合语言和视觉的差距,例如CVPR2017中,Das等人提出的视觉对话(Visual Dialog)任务提供了图片及与之相关的多轮对话,要求模型可以根据给定的图像和对话历史,用自然语言正确回答提问者相关的问题。尽管该任务在推进多模态对话问答系统的发展进程上具有重大意义,但根据静态图像的对话存在一定固有的限制,它很大程度上限制了问答系统对时空变化的动态感知能力,使之无法合理应对许多需要理解特定场景上下文以作出合理推断的应用。因此,为提升问答系统对时空智能性,引入一个新任务——视听场景感知对话(Audio-Visual Scene-Aware Dialog,AVSD),它可以看作视觉对话的一般形式,即基于连续图片帧和音频信息的视觉对话,相较于视觉对话有更广泛的应用前景。然而,现有方案主要使用独立编码器对不同模态分别进行编码,然后利用注意力机制融合其表示并生成响应语句。这种后期融合的方案只考虑了场景和对话的序列化特征,且忽视了不同模态间多粒度语义互补关系,导致现有模型的效果并不尽如人意。因此,探索对话场景的语义信息表示和模态融合方式对实现更高性能的多模态对话问答系统具有重要意义。
与此同时,多模态对话领域相关研究的重心正在向如何充分融合多源异构信息偏移,包括图像、音频、视频和文本等。相较于文本对话问答,多模态对话问答任务额外引入了对话相关的音视频特征,因而需要解决不同模态间的细粒度交互问题。
注意力机制是该领域的主流研究方法,它可以缩小视觉和语言模态表示间的差距。CVPR2018中,Wu等人设计的CoAtt模型包含一个序列化的共同注意力机制的编码器,使得每个输入特征由其它两个特征以序列化的方式共同提供。ACL2019中Gan等人提出的ReDAN模型和AAAI2020中Chen等人提出的DMRM模型通过基于双注意力机制的多步推理来回答图像相关的一系列问题。ECCV2020中,Nguyen等人设计的LTMI模型利用多头注意力机制关注模态的交互关系。
基于注意力机制实现的Transformer架构的预训练语言模型体系结构也在学习视觉-文本自然语言处理任务的跨模态表示上表现良好。在图像描述任务中,AAAI2020中Li等人构造基于BERT的架构改善文本和视觉表示,NIPS2019中,Lu等人使用相似的方法应对视觉问答任务,和前者区别在于在处理多模态输入时,将视觉和文本表示分开而非合并为整个序列。IJCNLP2019中,Alberti等人关注到前期融合或后期融合的方法对于丰富跨模态表示的重要作用。ICCV2019中,Sun等人提出VideoBERT模型,它利用BERT模型生成视频描述,并舍弃了用视觉特征代表视频帧的方法,转而将框架级的特征转化为视觉标记作为模型的原始输入。
近期研究还探索了图片或对话历史的更高级语义表示,尤其是基于图结构对图片或对话历史的建模方式。AAAI2020中,Jiang等人提出的DualVD模型从视觉和语义两个角度详细描述图片的特征,具体而言,视觉图模型帮助提取包括实体和关系在内的表面信息,语义图模型推进对话问答系统从全局到局部视觉语义理解的转变。CVPR2020中,Guo等人设计的CAG模型以实体相关的视觉表示和历史相关的上下文表示建立图结点,以自适应的Top-K信息传递机制更新相应的边权,建立视觉-语义相关的动态图用于后续推理。ACL2021中,Chen等人提出的GoG模型考虑到不同关系之间同样具有交互,因此建模了基于对话历史的当前提问依存关系图和基于当前提问的物体(区域)关系图。
发明内容
本发明的目的是为了解决现有的多模态对话系统仅考虑场景序列化信息而导致现有模型效果一般的问题,进而提出一种基于多关系图模型的多模态对话问答生成方法。
一种基于多关系图模型的多模态对话问答生成方法,包括以下步骤:
S1、使用固定大小的滑动窗口将视频序列化切分为多个视频片段,对于每个片段,获取该片段的色彩特征
将色彩特征
其中,位置信息
S2、针对视听场景表示V=(V
将视频图输入图卷积神经网络,输出视频隐藏层序列G
S3、将视频隐藏层序列G
S4、基于视听场景标题C和对话历史H得到对应的词向量表示C
T
T=T
其中,位置信息T
S5、将S4得到的文本序列表示T中的每个词向量视作顶点,构建基于句子级依存关系的图结构
然后将句子级依存关系的图结构
S6、将句子级依存关系的图结构
S7、将
进一步地,S5中将S4得到的文本序列表示T中的每个词向量视作顶点构建基于句子级依存关系的图结构
首先使用GPT2 Tokenizer获得每个单词对应的词向量表示,使用StanfordCoreNLP文本解析工具分析该句子的句法依存关系,将每个词向量视作顶点,并依据句法依存关系建模图结构;然后输入图卷积神经网络,输出文本隐藏层序列G
或者,
S5中将S4得到的文本序列表示T中的每个词向量视作顶点,构建基于完整对话共指关系的图结构
首先使用GPT2 Tokenizer获得每个单词对应的词向量表示,使用StanfordCoreNLP文本解析工具分析该句子的共指关系,将每个词向量视作顶点,并依据句子的共指关系建模图结构;然后输入图卷积神经网络,输出文本隐藏层序列G
或者,
S5中将S4得到的文本序列表示T中的每个词向量视作顶点,构建基于句子级依存关系的图结构
首先使用GPT2 Tokenizer获得每个单词对应的词向量表示,使用StanfordCoreNLP文本解析工具分别分析该句子的句法依存关系和该句子的共指关系,将每个词向量视作顶点,分别构建基于句子级依存关系的图结构
进一步地,S5中所述图卷积神经网络的每层图卷积神经网络计算的表达式为:
其中,f(H
进一步地,S2中所述图卷积神经网络的每层图卷积神经网络计算的表达式为:
其中,f(H
进一步地,在基于GPT-2架构的多层Transformer模型进行处理时,还要将S3中的
优选地,S7中的基于GPT-2架构的多层Transformer模型为由12层具有带掩码的多头注意力机制的Transformer解码器模块堆叠而成。
进一步地,所述的基于GPT-2架构的多层Transformer模型在训练过程中使用负对数似然损失函数进行训练,训练过程包括以下步骤:
基于音视频特征V、标题C、对话历史H
其中,
或者,
所述的基于GPT-2架构的多层Transformer模型在训练过程中基于音视频、标题和对话历史特征的回答预测任务RPT、音视频的标题预测任务CPT和音视频-文本匹配任务VTMT进行联合训练,训练过程包括以下步骤:
RPT部分旨在基于音视频特征V、标题C、对话历史H
其中,
CPT部分和RPT部分相似,对于给定的音视频特征V,通过最小化负对数似然损失函数的方式生成标题C={c
其中,c
VTMT部分旨在判断给定的音视频特征V和给定的文本特征是否匹配,给定的文本特征包括标题C、对话历史H
其中,X=(V,C,H,Q,R),Y是表征音视频特征和文本特征是否匹配的标签。
有益效果:
本发明一种基于多关系图模型的多模态对话问答生成方法,根据不同模态的特点构建多关系图模型以丰富多模态特征表示。通过建模连续视频片段中实体的对应关系,以及连续对话中隐含的句法、语义关系,进一步加深系统对场景与对话的理解,改进了现有方法只考虑时序、语序编码的不足,进一步提高生成回答的质量。
本发明旨在改进当前预训练模型架构仅利用了视频或文本的序列化信息来获取每个视频片段或单词所对应的嵌入表示,导致多模态对话问答系统生成回答不理想的情况。额外加入图卷积神经网络,使模型具备了有效编码多关系图结构信息的能力。具体而言,该模型引入图卷积神经网络,通过计算当前结点的邻接点集的数据分布,赋予当前节点相应的权值,在堆叠多层图卷积神经网络后,模型具备了推理距当前节点多个跳跃的结点的能力,从而可以捕获当前结点和远距离结点之间的交互信息,进而在一个框架内同时表示所有单词之间的句法或语义关系。
该发明可以有效提升了系统生成响应的各项指标,包括BLEU、METEOR、ROUGE-L、CIDEr等。在视听场景感知对话相关数据集上,本发明将系统生成回答和人工标注的回答进行多指标对比,实验结果表明,该方法生成回答符合人类表述的基本习惯,与人工标注结果基本匹配,并且优于本任务下现有所有模型的效果。其中,在表征句子自然程度的CIDEr指标上的提升尤为明显,比最先进的基线结果平均提升了1%,这充分说明了其有效性与优越性。
附图说明
图1为本发明流程图;
图2为本发明整体模型架构;
图3为预训练语言模型的基础单元框图;
图4为基于依存关系的图模型构建示例;
图5为基于共指关系的图模型构建示例。
具体实施方式
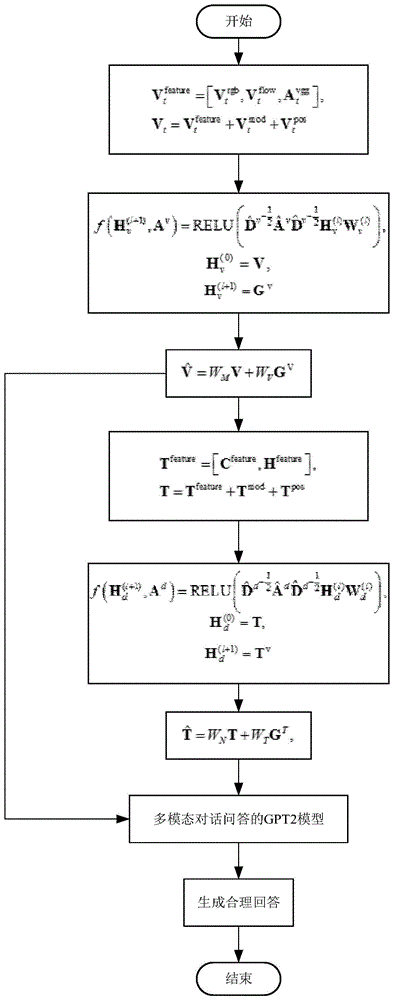
具体实施方式一:结合图1说明本实施方式,
本实施方式为一种基于多关系图模型的多模态对话问答生成方法,包括以下步骤:
步骤一、使用固定大小的滑动窗口将视频序列化切分为多个视频片段,对于每个片段,使用I3D模型获取该片段的色彩特征
其中,位置信息
步骤二、给定视听场景表示V=(V
将视频图输入图卷积神经网络,输出视频隐藏层序列G
其中,f(H
步骤三、将视频隐藏层序列G
其中,W
步骤四、使用GPT2 Tokenizer得到基于Word Pieces的视听场景标题C和对话历史H的词向量表示C
T
T=T
其中,位置信息T
步骤五、将每个词向量视作顶点,依据Stanford CoreNLP文本解析工具构建基于句子级依存关系的文本图
其中A
步骤六、将文本隐藏层序列G
其中,W
步骤七、构建多模态对话问答的GPT2模型(详见图2和图3)。图2给出了模型整体架构,这是一个基于GPT-2架构的多层Transformer模型。该模型是由12层具有带掩码的多头注意力机制的Transformer解码器模块堆叠而成。为了使模型同时具备融合多模态特征和生成合理回答的能力,对基于生成任务的GPT-2模型做出了一定改动,使之更符合多模态对话问答任务的需要。具体而言,该模型将步骤三的结果
图3展示了GPT-2模型中每个Transformer解码器模块的具体架构。该模块主要由带掩码的多头注意力机制和前馈神经网络构成。其中,掩码多头注意力机制Masked Self-Attention可以检测各模态输入自身和彼此间的细粒度的长期依赖关系,包括视频对象的时空关系、对话历史间的共指关系、视频局部特征和文本词汇的指代关系等,以生成基于视听觉特征并且符合用户提问的合理回答。
步骤八、将
训练时使用负对数似然损失函数,使模型具备基于音视频、标题和对话历史特征的预测回答的能力。形式化而言,模型基于音视频特征V、标题C、对话历史H
其中,
具体实施方式二:
本实施方式为一种基于多关系图模型的多模态对话问答生成方法,本实施方式与具体实施方式一不同的是:
所述步骤五中将步骤四得到的文本序列表示T中的每个词向量视作顶点,依据Stanford CoreNLP文本解析工具构建基于完整对话共指关系的文本图
步骤六将步骤四和步骤五得到的文本隐藏层序列G
其中,
其它步骤及参数与具体实施方式一相同。
具体实施方式三:
本实施方式为一种基于多关系图模型的多模态对话问答生成方法,本实施方式与具体实施方式一或二不同的是:
所述步骤五中将步骤四得到的文本序列表示T中的每个词向量视作顶点,依据Stanford CoreNLP文本解析工具构建基于句子级依存关系的文本图
步骤六将步骤四和步骤五得到的文本隐藏层序列G
其中,
其它步骤及参数与具体实施方式一或二相同。
具体实施方式四:
本实施方式为一种基于多关系图模型的多模态对话问答生成方法,本实施方式与具体实施方式一至三之一不同的是:
所述步骤八中为促进不同模态信息的融合,模型训练时引入三个任务进行微调,包括基于音视频、标题和对话历史特征的回答预测任务(Response Prediction Task,RPT)、基于音视频的标题预测任务(Caption Prediction Task,CPT)和音视频-文本匹配任务(Video-Text Matching Task,VTMT)。前三个具体实施方式只使用了一个损失函数,是单任务学习的方式。具体实施方式四设计了三个损失函数,采用多任务学习的方式增强模型理解不同模态信息的能力。
RPT部分旨在基于音视频特征V、标题C、对话历史H
其中,
CPT部分和RPT部分相似,对于给定的音视频特征V,通过最小化负对数似然损失函数的方式生成标题C={c
其中,c
VTMT部分旨在判断给定的音视频特征V和给定的文本特征(包括标题C、对话历史H
其中,X=(V,C,H,Q,R),Y是表征音视频特征和文本特征是否匹配的标签。
其它步骤及参数与具体实施方式一至三之一相同。
采用以下实施例验证本发明的有益效果:
实施例一:
数据集选取ICASSP2019中Hori等人发布的第七届对话系统技术挑战赛(The 7thDialog System Technology Challenge,DSTC7)的视听场景感知对话数据集进行系统性能评估,为保证衡量不同模型间性能差异的公平性和合理性,数据集的划分方式与挑战赛中任务设置保持一致。该数据集大小和划分方式如表1所示。
表1 DSTC7-AVSD数据集概述
评估指标选用使用自然语言生成任务中常用的指标,包括BLEU、METEOR、ROUGE-L和CIDEr等,这些指标可以从不同角度计算预测回答和真实回答之间的语义相似度和语言流畅度,从而科学反映系统性能。
实验参数设置如表2所示。具体而言,在编码过程中,设置Adam优化器的学习率为6.25e-5,涉及对话历史最多为3轮,Transformer模块的隐藏状态为768,批处理大小为8。在解码过程中,采用波束搜索算法,设置波束宽度为5,句子最大长度为20,长度惩罚为0.3。
表2实验参数设置
表3比较了在DSTC7-AVSD上基线模型和本发明生成结果的差异。可以看到,在该样例中,提问者提及的“television”未在标题和对话历史中出现,因此系统需要结合音视频信息并进行简单的推理才能正确回答该问题。此时基线模型对于该问题的回答充分说明基线模型并没有完全理解提问者的问题指向,欠缺推理能力,对于无法在标题、摘要或对话历史中找到特定信息的问题,无法给出正确答案,甚至出现答非所问的情况。
而和基线模型相比,本发明可以基于给定的视频和文本,对两者信息进行充分交互,从而捕获不同模态输入之间隐藏的复杂依赖关系,提取更丰富的特征表示并基于推理生成高质量、自然的回答。
表3 VGPT模型生成的DSTC7-AVSD样例
为了客观全面地验证本发明的有效性,对于DSTC7-AVSD数据集将其与相关的基线方法进行比较,具体结果如表4所示,其中每个指标的最优结果均已加粗展示:
(1)ICASSP2019中Hori等人提出的朴素融合模型(Naive Fusion)为DSTC7组织者提供的多模态基线方法,它使用含有问题指向的LSTM模型分别提取视频和音频特征,同时使用分层LSTM编码对话历史,最后借由投影矩阵组合所有模态以生成回答。
(2)AAAI2019中Sanabria等人提出的分层注意力机制模型(HierarchicalAttention,HA)引入视频摘要任务的迁移学习,获取更多视觉细节,获得了DSTC7-AVSD挑战赛的第一名。
(3)ACL2019中Le等人提出的多模态Transformer网络(Multimodal TransformerNetworks,MTN)是DSTC8-AVSD挑战赛之前最高水平的系统,它采用基于Transformer的自动编码模块,以问题为导向关注视觉特征。
(4)TASLP2021中Li等人提出的通用多模态Transformer网络(UniversalMultimodal Transformer,UMT)是目前该任务下最先进的对话问答系统,它引入预训练的GPT-2模型,采用多任务学习的方式学习视听场景的融合表示。
表4基于DSTC7-AVSD数据集的客观评估结果
实验结果表明,本发明使用具体实施方式三在DSTC7-AVSD测试集的几乎所有自动化指标上都优于现有的方法,在BLEU-2、BLEU-2、BLEU-2和CIDEr指标上相较于该任务下目前最先进模型UMT平均提升了1%。这说明通过引入多关系图结构编码可以使对话系统生成更高质量的回答并显著提升模型的性能。得益于图卷积神经网络的结构特征,所有单词间的多种句法和语义信息可以在一个框架内展现。相较于多层感知器(MultilayerPerceptron,MLP),因此在计算当前结点的表示时可以综合考虑其邻居节点的信息,而对于远距离的连通点,可以通过堆叠多层图卷积神经网络获取,从而扩大了自身的“感受野”。
实施例二:
数据集选取TASLP2021中Kim等人发布的第八届对话系统技术挑战赛(The 8thDialog System Technology Challenge,DSTC8)的视听场景感知对话数据集进行系统性能评估,为保证衡量不同模型间性能差异的公平性和合理性,数据集的划分方式与挑战赛中任务设置保持一致。
该数据集大小和划分方式如表5所示。
表5 DSTC8-AVSD数据集概述
实验参数设置和表2一致。
为了客观全面地验证本发明的有效性,对于DSTC8-AVSD数据集将其与相关的基线方法进行比较,具体结果如表6所示,其中每个指标的最优结果均已加粗展示:
(1)arXiv2020中Chu等人提出的多步联合模态注意力网络(Multi-step Joint-Modality Attention Network,JMAN)设计了基于循环神经网络的模型架构,运用多步骤注意力机制,并将每次推理过程兼顾视觉和文本的表示,以更好地整合两种不同模态的信息。
(2)arXiv2020中Lee等人提出的多模态语义Transformer网络(MultimodalSemantic Transformer Network,MSTN)相较于传统Transformer体系架构,额外设计了一个基于注意力的单词嵌入层,使得模型在生成阶段可以更多地将单词含义纳入考虑范围。
表6基于DSTC8-AVSD数据集的客观评估结果
实验结果表明,本发明使用具体实施方式一在DSTC8-AVSD测试集的几乎所有自动化指标上都优于现有模型。其中,在表征句子自然程度的CIDEr指标上的提升尤为明显,提升了0.012(1.240vs.1.252),这说明局部依赖关系和全局共指关系可以从不同角度反映文本的功能相似性以编码文本信息,从而改善已有模型的表现。
本发明还可有其它多种实施例,在不背离本发明精神及其实质的情况下,本领域技术人员当可根据本发明作出各种相应的改变和变形,但这些相应的改变和变形都应属于本发明所附的权利要求的保护范围。