一种基于典型特征的可解释文本检测方法
文献发布时间:2023-06-19 18:37:28
技术领域
本发明涉及文本检测技术领域,特别是一种基于典型特征的可解释文本检测方法。
背景技术
随着网络和自媒体技术的不断发展,人类进入了一个知识爆炸的时代,在享受互联网带来的便捷和自媒体带来的愉悦的同时,也遭受着虚假新闻、谣言的很多困扰。
通常虚假新闻存在很多明显特征,比如主观动词、语气助词相对较多,感叹句、疑问句占比较高,存在夸张、煽动、引诱、疑惑等语义成分等等。但存在这些特征的文本并不能直接代表其是虚假新闻。如何利用这些典型的虚假新闻必要不充分特征,对新闻、谣言等文本进行综合检测,已经成为迫在眉睫的需求。
当前的文本检测方法存在以下不足:
(1)基于人工的虚假新闻检测方法会消耗大量的人力、物力、财力,辨识一篇文本需要花费大量的时间,难以做到线上实时辨识。
(2)基于人工智能的辨识方法大多采用黑盒分类模型,缺乏对真伪辨识结果的可解释性。
(3)辨识模型尚没有结合文本的语义特征和属性特征,难以准确对文本真伪情况进行综合辨识。
(4)目前基于人工智能的辨识模型需要在大量训练数据下才能达到较好的效果,而行业目前尚缺少这样的优质数据集。
发明内容
针对上述技术问题,本发明提供一种基于典型特征的可解释文本检测方法,能够基于深度学习模型,做到线上实时辨识,降低辨识过程的人工成本;能够对辨识结果进行可解释性分析,做到真伪辨识的有理有据;辨识过程不仅考虑了文本字、词、句、段、篇等固有属性,同时考虑了文本内容的语义特征,能够实现文本的多维度综合辨识;辨识结束后,能够对辨识数据进行优质性判断,从而不断积累和扩充辨识模型的训练数据集,通过对辨识模型进行定期或者定量的训练,使模型不断学习和生长,达到越用越准的效果。
本发明公开了一种基于典型特征的可解释文本检测方法,其包括:
步骤1:将待检测文本数据输入文本属性提取模型,得到待检测文本的固有属性;所述固有属性包括字词属性、句子属性、段落属性;
步骤2:将所述待检测文本数据输入训练好的语义特征提取模型,得到待检测文本的语义特征;所述语义特征包括夸张、煽动、怀疑、消极、恐慌、中性、积极;
步骤3:将待检测文本的固有属性和多类型语义特征以及所述待检测文本数据输入训练好的文本内容辨识模型,得到文本内容的辨识结果;所述辨识结果为真实的概率值。
进一步地,所述字词属性包括问号数量、感叹号数量、主观动词比例、祈使动词比例、语气助词比例;所述句子属性包括句子数量、最长句子字符总数量、最长句子正面情感词比例、最长句子负面情感词比例、平均句子字符数量;所述段落属性包括段落总数量、最长段落句子数量、最长段落字符数量、最长段落反问句比例、最长段落语法错误句子比例、平均段落句子数量、平均段落字符数量;
所述步骤1包括:
步骤11:基于基础词典和统计方法,对待检测文本数据进行字词属性提取,提取文本中的问号数量、感叹号数量,以及主观动词、祈使动词、语气助词占全文总字符数的比例;
步骤12:以典型句子结束标点符号作为依据对待检测文本数据进行分句,结合统计方法进行相关统计,同时参考字词属性提取结果,进行最长句子正面情感词比例、最长句子负面情感词比例的统计运算;其中,所述相关统计包括句子数量、最长句子字符总数量、平均句子字符数量;所述典型句子结束标点符号包括句号、感叹号、问号;
步骤13:以典型段落结束标记为依据对待检测文本数据进行段落分割,结合句子属性提取结果,统计段落相关量;其中,所述典型段落结束标记包括换行符;所述段落相关量包括段落总数量、最长段落句子数量、最长段落字符数量、最长段落反问句比例、最长段落语法错误句子比例、平均段落句子数量、平均段落字符数量。
进一步地,所述文本属性提取模型是基于规则的统计模型,以文本内容为输入,以文本的固有属性为输出;
所述语义特征提取模型和所述文本内容辨识模型的训练过程为:
将文本检测训练数据集输入语义特征提取模型,得到文本的语义特征;
将文本的固有属性和语义特征以及文本检测训练数据集输入所述文本内容辨识模型,得到文本内容辨识结果;
分别根据语义特征、文本内容辨识结果进行损失值计算及模型参数迭代,然后判断模型收敛性;
若语义特征提取模型和文本内容辨识模型均收敛,则模型训练结束;否则继续进行模型训练直到两个模型同时收敛。
进一步地,所述文本检测训练数据集中包含文本内容、语义特征标签、真伪标签,语义特征标签用于训练语义特征提取模型,真伪标签用于训练文本内容辨识模型;每一个检测训练数据对应的语义特征标签为一个m维向量,m为语义特征类别总数量,向量中1表示该条文本数据具有这类语义特征,0表示该条文本数据不具有这类语义特征,向量中允许出现多个1和多个0;其中,所述文本检测训练数据集由文本训练集、文本评估集和文本测试集构成。
进一步地,所述语义特征提取模型提取语义特征后输出一个m维向量
其中,
进一步地,计算语义特征提取模型损失值后,通过文本检测评估数据集进行模型收敛性判断,文本检测评估数据集中包含文本内容、语义特征标签、真伪标签,语义特征标签用于评估语义特征提取模型,真伪标签用于评估文本内容辨识模型;语义特征提取模型的收敛性判断方法如下:
首先通过如下公式计算评估数据的F1值:
其中,P表示准确率,R表示召回率,F1是P和R的调和平均数,TP表示模型辨识为真且辨识正确的数量,FP表示模型辨识为假且辨识错误的数量,TP+FP表示模型辨识为真的总数量,FN为模型辨识为假且辨识错误的数量,TP+FN表示实际为真的总数量;
记录每次模型迭代后,文本评估数据集计算的平均F1值,并保存模型;若本次计算的平均F1值高于上次计算结果则更新模型,否则不更新模型;连续进行预设迭代次数的迭代,若迭代模型未更新,则视为模型收敛。
进一步地,所述文本内容辨识模型与所述语义特征提取模型的收敛性判断方法相同。
进一步地,每个所述文本检测训练数据中对应的真伪标签为0或1,1表示该文本检测训练数据真实,0表示该文本检测训练数据虚假;所述文本内容辨识模型进行内容辨识后输出文本的真实的概率值
L
进一步地,所述文本属性提取模型、所述语义特征提取模型、所述文本内容辨识模型上线运行后,对于每一条待检测文本,判断所述语义特征提取模型和所述文本内容检测模型的输出概率是否同时大于预设阈值;
若是,则将所述待检测文本存入文本检测训练数据集中,当所述文本检测训练数据集中的文本检测训练数据达到预设数量时,重新开始进行所述语义特征提取模型和所述文本内容辨识模型的训练。
进一步地,所述语义特征提取模型和所述文本内容辨识模型训练结束后,利用文本测试集对所述语义特征提取模型和所述文本内容辨识模型进行测试,并分别与上一次训练的所述语义特征提取模型和所述文本内容辨识模型发布上线运行的测试结果进行比较,若性能优于上一次,则再次将其发布上线,否则将其删除。
由于采用了上述技术方案,本发明具有如下的优点:
(1)能够基于深度学习模型,做到线上实时辨识,降低辨识过程的人工成本;
(2)能够对辨识结果进行可解释性分析,做到真伪辨识的有理有据;
(3)辨识过程不仅考虑了文本字、词、句、段、篇等固有属性,同时考虑了文本内容的语义特征,能够实现文本的多维度综合辨识;
(4)辨识结束后,能够对辨识数据进行优质性判断,从而不断积累和扩充辨识模型的训练数据集,通过对辨识模型进行定期或者定量的训练,使模型不断学习和生长,达到越用越准的效果。
附图说明
为了更清楚地说明本发明实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明实施例中记载的一些实施例,对于本领域普通技术人员来讲,还可以根据这些附图获得其他的附图。
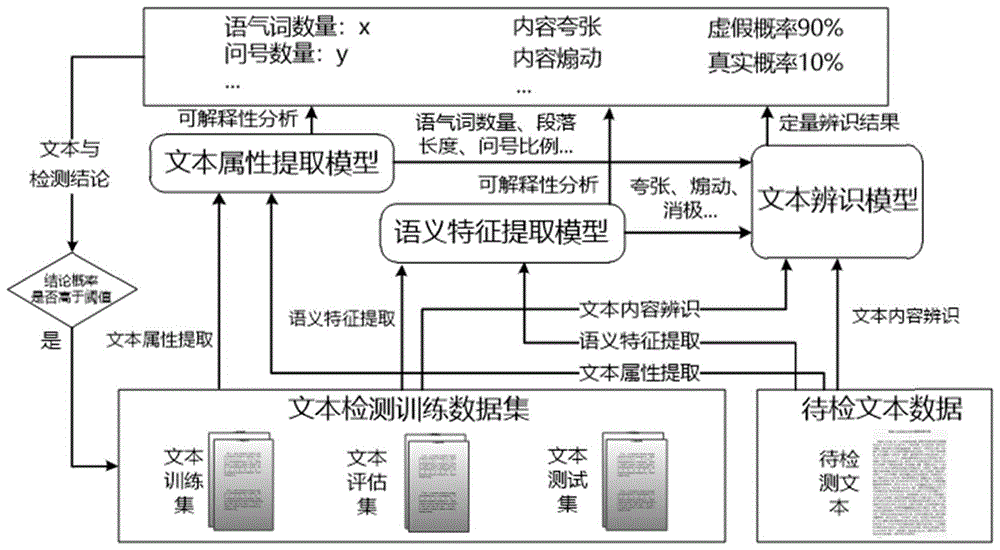
图1是本发明实施例的一种基于典型特征的可解释文本检测方法的实现原理图;
图2是本发明实施例的模型训练过程原理图;
图3是本发明实施例的模型上线运行原理图。
具体实施方式
结合附图和实施例对本发明作进一步说明,显然,所描述的实施例仅是本发明实施例一部分实施例,而不是全部的实施例。本领域普通技术人员所获得的所有其他实施例,都应当属于本发明实施例保护的范围。
本实施例中所采用的技术术语解释如下:
文本特征:包含文本固有属性特征、文本语义特征。文本固有属性特征包含文本字词、句子、段落等数量的一些统计数据;语义特征用于描述文本的夸张、煽动、疑惑等语义成分。
文本辨识:对文本的真伪进行判断。
辨识结果:辨识模型的定量输出结果。
文本检测:从固有属性、语义、真伪三个方面对文本进行综合判断。
检测结论:包括文本的属性特征、语义特征以及辨识模型的定量判别结果。
可解释性:从属性特征、语义特征两个维度对辨识结果进行解释。
参见图1和图2,本发明提供了一种基于典型特征的可解释文本检测方法的实施例,其具体如下:
以文本检测训练数据集作为输入,利用文本属性提取模型进行固有属性提取。属性提取模型首先基于基础词典和统计方法,进行字词属性提取,提取文本中的问号数量、感叹号数量,以及主观动词、祈使动词、语气助词占全文总字符数的比例;然后以句号、感叹号、问号等典型句子结束标点符号作为依据进行分句,结合统计方法进行句子数量、最长句子字符总数量、平均句子字符数量等等的统计,同时参考字词属性提取结果,进行最长句子正面情感词比例、最长句子负面情感词比例的统计运算;接着以换行符等典型段落结束标记为依据进行段落分割,结合句子属性提取结果,统计段落总数量、最长段落句子数量、最长段落字符数量、最长段落反问句比例、最长段落语法错误句子比例、平均段落句子数量、平均段落字符数量等等。文本属性提取模型主要基于规则和统计方法实现,不需要大量数据进行模型训练,所提取的文本固有属性在一定程度上能够反映文本的真伪状况,可以作为后续文本辨识的重要输入之一。
以文本检测训练数据集作为输入,利用文本语义特征提取模型进行语义特征提取,语义特征类别包括但不限于夸张、煽动、怀疑、消极、恐慌、中性、积极等等。文本检测训练数据集中包含文本内容本身以及语义特征标签。每一个文本数据对应的语义特征标签为一个m维向量,m为语义特征类别总数量,向量中1表示该条文本数据具有这类语义特征,0表示该条文本数据不具有这类语义特征,向量中允许出现多个1和多个0。模型提取语义特征后与数据集标签按照如下公式进行损失值计算。
其中,
计算模型损失值后,通过文本检测评估数据集进行模型收敛性判断。文本检测评估数据集中包含文本内容本身以及语义特征类别标签。模型收敛性判断方法如下:
首先通过如下公式计算评估数据的F1值。
其中,P表示准确率,R表示召回率,F1是P和R的调和平均数,TP表示模型辨识为真且辨识正确的数量,FP表示模型辨识为假且辨识错误的数量,TP+FP表示模型辨识为真的总数量,FN为模型辨识为假且辨识错误的数量,TP+FN表示实际为真的总数量;
记录每次模型迭代后,文本评估数据集计算的平均F1值,并保存模型。若本次计算的平均F1值高于上次计算结果则更新模型,否则不更新模型。连续十次迭代模型未更新,则视为模型收敛。
文本属性提取模型和语义特征提取模型的输出结果和文本检测数据集作为共同输入,利用文本内容辨识模型进行文本真伪定量辨识。
辨识结果是真实和虚假的概率值。文本检测训练数据集中包含文本内容本身以及真伪标签。每一个文本数据对应的真伪标签为一个0或1的数值,1表示该条文本数据真实,0表示该条文本数据虚假。模型进行内容辨识后与数据集标签按照如下公式进行损失值计算。
L
根据上式计算损失值后,通过文本检测评估数据集进行模型收敛性判断。文本检测评估数据集中包含文本内容本身以及真伪标签。文本内容辨识模型收敛性判断方法与语义特征提取模型收敛性判断方法相同。
当语义特征提取模型和文本内容辨识模型同时收敛时,认为训练过程结束,否则继续进行模型训练直到两个模型同时收敛。
模型上线运行过程如下:
以待检测文本作为输入,首先利用文本属性提取模型和已训练好的语义特征提取模型进行文本固有属性和语义特征提取。然后将模型提取的结果与待检测文本本身作为输入,送入已训练好的文本内容辨识模型。辨识模型结合文本内容、固有属性、语义特征,对文本真伪进行定量判断。最终的文本检测结论包含文本属性、语义特征和辨识结果。文本检测结论不仅包含文本真伪的概率值,同时包含支撑检测结论的可解释依据,实现了结合典型属性、语义特征的文本可解释检测。
为了解决检测模型训练数据样本少的问题,本发明设计一个策略,参见图3,在检测样本中不断发现优质数据,沉淀入训练样本中,不断扩充训练数据样本的规模。在模型上线运行之前,首先设置一个优质数据沉淀参考阈值,作为判别待检测数据特征是否足够明显,足够作为优质数据沉淀到文本训练数据集的条件。优质数据判别方法如下:语义提取模型提取文本语义特征后,判断每个语义特征的概率值是否均高于参考阈值,如果是,则与文本辨识模型的输出概率值对比,如果文本辨识模型输出概率值也同时高于参考阈值,则认为该条文本数据属于优质数据,将其存放入文本检测训练数据集中,待沉淀的优质数据积累到一定数量时,重新启动模型训练过程。训练结束后,利用测试数据集对模型进行测试,与上一次模型发布上线运行的测试结果进行比较,若性能优于上一次,则再次发布上线,否则模型不上线并删除。
举例而言,有如下待检测文本:
“网传信息显示,一个6人的博士团队,在用cluster模拟某些产品的物理性能时,面临模型越复杂模拟失真越高的一个难题。
最后总结主要是因为他们对一道数学方程解题处理的有问题,但又搞不清楚具体是哪里错了,这问题困扰他们项目团队4个月还没有解决。
后来他们团队中的成员,托一位某大的朋友尝试联系韦某来帮忙,结果韦某只用了一晚上就把困扰他们4个月的难题给解决了,韦某把全部数学方程发过来,和过往的真实实验数据匹配率99.8%!
该团队为了感谢韦某,想给韦某一定的现金答谢,但是韦某坚决不要,并表示太简单了,没必要要钱。
后来,在他们团队的再三坚持下,为韦某充值了公交卡。”
文本属性提取结果:段落数量:5,句子数量:,5;最长句子字符数量:84;感叹句数量:1;语气助词占比:6.5%;
语义特征提取结果:97%概率夸张、95%概率怀疑;
将文本属性、语义特征与文本内容综合在一起,输入到文本辨识模型。具体文本辨识模型的输入如下:
正文:
网传信息显示,一个6人的博士团队,在用cluster模拟某些产品的物理性能时,面临模型越复杂模拟失真越高的一个难题。
最后总结主要是因为他们对一道数学方程解题处理的有问题,但又搞不清楚具体是哪里错了,这问题困扰他们项目团队4个月还没有解决。
后来他们团队中的成员,托一位某大的朋友尝试联系韦某来帮忙,结果韦某只用了一晚上就把困扰他们4个月的难题给解决了,韦某把全部数学方程发过来,和过往的真实实验数据匹配率99.8%!
该团队为了感谢韦某,想给韦某一定的现金答谢,但是韦某坚决不要,并表示太简单了,没必要要钱。
后来,在他们团队的再三坚持下,为韦某充值了公交卡。||固有属性:段落数量-5句子数量-5;最长句子字符数量-84;感叹号数量-1;语气助词占比-0.065;||语义特征:夸张0.97;怀疑0.95。
文本辨识模型输出为:96%概率虚假、4%概率真实。
预设优质数据沉淀参考阈值为0.95,经判别,语义特征模型输出的各项特征,以及文本辨识模型输出特征概率值均大于0.95,该条文本内容以及对应的语义特征值和真伪特征值可分别作训练数据、语义特征标签、真伪标签,沉淀到文本检测模型训练集中。
最后应当说明的是:以上实施例仅用以说明本发明的技术方案而非对其限制,尽管参照上述实施例对本发明进行了详细的说明,所属领域的普通技术人员应当理解:依然可以对本发明的具体实施方式进行修改或者等同替换,而未脱离本发明精神和范围的任何修改或者等同替换,其均应涵盖在本发明的权利要求保护范围之内。