一种多特征挖掘与协同约束的敦煌遗书残片缀合方法
文献发布时间:2023-06-28 06:30:04
技术领域
本发明涉及一种敦煌遗书残片缀合方法,尤其涉及一种多特征挖掘与协同约束的敦煌遗书残片缀合方法。
背景技术
敦煌遗书是研究中古时期中国、中亚、东亚及南亚的历史学、考古学、宗教学、人类学、社会学、语言学、文学史、艺术史、科技史及民族史的重要研究资料,具有极高的文物价值和文献研究价值,敦煌遗书残片图像则是进行敦煌遗书研究的主要材料。
现有的敦煌遗书研究过程中,研究专家通常利用领域专业知识手工缀合敦煌遗书,以判别两片敦煌遗书残片在破损前是否同属一处。上述手工缀合方法的准确性和效率较低,且工作强度较大。
申请号为CN202110440552.4,名称为《一种敦煌遗书残片图像的自动缀合方法》的发明授权专利,公开了一种敦煌遗书残片图像的自动缀合方法,能够兼顾断边碴口密合度以及断边缀合后所形成的网格单元宽度的精确度,提高敦煌遗书残片图像缀合的效率和准确性。但上述专利仅通过敦煌遗书残片图像的物理信息作为缀合参考因素,依赖书卷竖向网格线,参考因素较为单一,缀合准确率有待进一步提高。而且,当某个待缀合敦煌遗书残片图像的碴口是平齐状时,由于其边缘特征极不显著,极易导致其它边缘平齐状的敦煌遗书残片图像作为候选结果返回,从而带来大量干扰性的候选结果,最终导致缀合效果较差。
申请号为CN202211276002.4,名称为《基于语句通顺性的敦煌遗书残片图像缀合方法》的发明授权专利,公开了一种基于语句通顺性的敦煌遗书残片图像缀合方法,能够综合考虑待缀合敦煌遗书残片图像文字内容的语句通顺性和边缘相似度,提高敦煌遗书残片图像缀合的效率和准确性。上述专利虽然同时将语句通顺性和边缘相似度作为缀合参考因素,相较于授权发明专利《一种敦煌遗书残片图像的自动缀合方法》的参考因素有所增加,缀合准确率也有一定提高,但仍有进一步提高的空间。
发明内容
本发明的目的是提供一种多特征挖掘与协同约束的敦煌遗书残片缀合方法,构建基于Transformer编码器的多特征提取网络并通过对比学习模块进行网络训练,利用网络模型充分挖掘敦煌遗书残片的书写风格特征、文本布局特征、残边边缘特征和语句通顺性特征并进行特征聚合,获取每幅敦煌遗书残片图像的聚合特征,最终得到敦煌遗书残片的缀合匹配度,从而实现敦煌遗书残片的精准缀合。
本发明采用下述技术方案:
一种多特征挖掘与协同约束的敦煌遗书残片缀合方法,包括以下步骤:
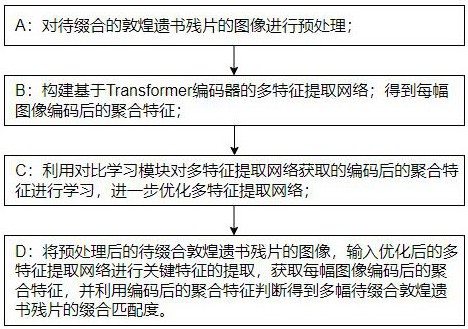
A:对待缀合的敦煌遗书残片的图像进行预处理,包括图像尺寸统一调整、图像中的文字列选取、图像中文字区域和非文字区域的二值化处理、图像残边描绘以及图像文字的提取和文字列集合的构建;
B:构建基于Transformer编码器的多特征提取网络;多特征提取网络用于挖掘敦煌遗书残片图像的多个关键特征,并通过特征聚合和基于Transformer编码器的特征编码,得到每幅图像编码后的聚合特征;多特征提取网络包含异构特征挖掘模块、特征聚合模块和特征编码模块;
异构特征挖掘模块包括书写风格特征嵌入学习网络、文本布局特征嵌入学习网络、残边边缘特征嵌入学习网络和语句通顺性特征嵌入学习网络,分别用于挖掘和提取图像中的书写风格特征、文本布局特征、残边边缘特征和语句通顺性特征;
特征聚合模块,用于对得到的书写风格特征、文本布局特征、残边边缘特征和语句通顺性特征进行聚合,通过并列叠放得到每幅图像的基于四种关键特征的聚合特征;
特征编码模块,用于对聚合特征进行融合学习,并通过Transformer编码器得到每幅图像编码后的聚合特征,编码后的聚合特征包含全局特征和局部特征;
C:利用对比学习模块对多特征提取网络获取的编码后的聚合特征进行学习,进一步优化多特征提取网络;
D:将预处理后的待缀合敦煌遗书残片的图像,输入优化后的多特征提取网络进行关键特征的提取,获取每幅图像编码后的聚合特征,并利用编码后的聚合特征判断得到多幅待缀合敦煌遗书残片的缀合匹配度。
所述的书写风格特征嵌入学习网络包括文字无关的书写风格特征嵌入学习网络和文字有关的书写风格特征嵌入学习网络;文字无关的书写风格特征嵌入学习网络用于获取敦煌遗书残片的图像的书写风格特征;文字有关的书写风格特征嵌入学习网络用于获取单独文字的文字图像的书写风格特征;
文字无关的书写风格特征嵌入学习网络按照下述方法进行训练:
B111:构建训练集,训练集中包含多幅同一人书写的敦煌遗书残片和多幅非同一人书写的敦煌遗书残片;其中,多幅同一人书写的敦煌遗书残片作为正样本,多幅非同一人书写的敦煌遗书残片作为负样本;
B112:对所有文字列对应的图像分别进行图像切分,通过相同大小的滑动窗口按照设定的步长不断移动,将每列文字列对应的图像切分为不完全重叠的n个图像块;
B113:将得到的n个图像块送入文字无关的书写风格特征嵌入学习网络中,分别进行书写风格特征提取,最终得到n个图像特征,每个图像块均对应一个图像特征;
B114:将n个图像特征随机划分为两组图像特征组,将每个图像特征组内随机选取的
B115:将经过降维操作的两个书写风格特征送入对比学习模块进行学习;
B116:利用训练集中的正样本和负样本,对文字无关的书写风格特征嵌入学习网络进行训练,直至文字无关的书写风格特征嵌入学习网络的误差达到设定的阈值,或迭代训练的次数达到设定的迭代次数阈值;最终得到训练后的文字无关的书写风格特征嵌入学习网络;
在利用正样本进行训练的过程中,利用对比学习拉近两幅已确定为同一人书写的敦煌遗书残片图像的书写风格特征的欧氏距离;在利用负样本进行训练的过程中,利用对比学习拉远两幅已确定为非同一人书写的敦煌遗书残片图像的残边边缘特征的欧氏距离。
文字有关的书写风格特征嵌入学习网络按照下述方法进行训练:
B121:构建训练集,训练集中包含一幅或多幅敦煌遗书残片图像中同一个文字的多幅文字图像;其中,将同一人书写的同一个文字的两幅文字图像作为正样本,将不同人书写的同一个文字的两幅文字图像作为负样本;
B122:将训练集中的每个文字图像,输入到文字有关的书写风格特征嵌入学习网络中;
B123:文字有关的书写风格特征嵌入学习网络对输入的文字图像进行图像特征提取,经全连接层处理后,以解耦学习方式得到输入的文字图像的内容特征和书写风格特征;
B124:将两个相同文字的书写风格特征送入对比学习模块进行学习;
B125:利用训练集中的正样本和负样本,对文字有关的书写风格特征嵌入学习网络进行训练,直至文字有关的书写风格特征嵌入学习网络的误差达到设定的阈值,或迭代训练的次数达到设定的迭代次数阈值;最终得到训练后的文字有关的书写风格特征嵌入学习网络;
在利用正样本进行训练的过程中,利用对比学习拉近两个同一人书写的同一个文字的两幅文字图像的书写风格特征的欧氏距离;在利用负样本进行训练的过程中,利用对比学习拉远两个不同人书写的同一个文字的两幅文字图像的书写风格特征的欧氏距离。
所述的文本布局特征嵌入学习网络按照下述方法进行训练:
B21:构建训练集,训练集中包含多组已确定为能够缀合的敦煌遗书残片图像组,以及多组已确定为不能够缀合的敦煌遗书残片图像组,每个图像组中均包含两幅敦煌遗书残片图像的二值化图;其中,将能够缀合的图像组作为正样本,将不能够缀合的图像组作为负样本;
B22:将训练集中每个敦煌遗书残片图像的二值化图,送入文本布局特征嵌入学习网络,进行文本布局特征的提取,得到每幅敦煌遗书残片图像的文本布局特征;
B23:将两幅敦煌遗书残片图像的文本布局特征送入对比学习模块进行学习;
B24:利用训练集中的正样本和负样本,对文本布局特征嵌入学习网络进行训练,直至文本布局特征嵌入学习网络的误差达到设定的阈值,或迭代训练的次数达到设定的迭代次数阈值;最终得到训练后的文本布局特征嵌入学习网络;
在利用正样本进行训练的过程中,利用对比学习拉近两幅已确定为能够缀合的敦煌遗书残片图像的文本布局特征的欧氏距离;在利用负样本进行训练的过程中,利用对比学习拉远两幅已确定为不能够缀合的敦煌遗书残片图像的文本布局特征的欧氏距离。
所述的残边边缘特征嵌入学习网络按照下述方法进行训练:
B31:构建训练集,训练集中包含多组已确定为能够缀合的敦煌遗书残片图像组,以及多组已确定为不能够缀合的敦煌遗书残片图像组,每个图像组中均包含两幅敦煌遗书残片图像的残边边缘图像;其中,将能够缀合的图像组作为正样本,将不能够缀合的图像组作为负样本;
B32:将训练集中的敦煌遗书残片图像的残边边缘图像,送入残边边缘特征嵌入学习网络,进行残边边缘特征的提取,得到每幅敦煌遗书残片图像的残边边缘特征;
B33:将两幅敦煌遗书残片图像的残边边缘特征送入对比学习模块进行学习;
B34:利用训练集中的正样本和负样本,对残边边缘特征嵌入学习网络进行训练,直至残边边缘特征嵌入学习网络的误差达到设定的阈值,或迭代训练的次数达到设定的迭代次数阈值;最终得到训练后的残边边缘特征嵌入学习网络;
在利用正样本进行训练的过程中,利用对比学习拉近两幅已确定为能够缀合的敦煌遗书残片图像的残边边缘特征的欧氏距离;在利用负样本进行训练的过程中,利用对比学习拉远两幅已确定为不能够缀合的敦煌遗书残片图像的残边边缘特征的欧氏距离。
所述的语句通顺性特征嵌入学习网络按照下述方法进行训练:
B41:构建训练集,训练集中包含多组正样本和负样本;
B42:将训练集中的每段语句送入语句通顺性特征嵌入学习网络,进行语句通顺性特征的提取,得到每段语句的语句通顺性特征;
B43:利用训练集中的正样本和负样本,对语句通顺性特征嵌入学习网络进行调优训练,直至迭代训练的次数达到设定的迭代次数阈值;最终得到调优训练后的语句通顺性特征嵌入学习网络。
在利用调优训练后的语句通顺性特征嵌入学习网络进行图像的语句通顺性特征提取时,分别获取两幅敦煌遗书残片图像在各种相互位置关系下及对齐状态下对应的语句通顺性数值,然后确定语句通顺性数值中的最高值所对应的两幅敦煌遗书残片图像中相对应的两个语句,再将两个对应的语句利用语句通顺性特征嵌入学习网络,分别获取每个语句的语句通顺性特征。
所述的步骤C中,按照下述步骤对多特征提取网络获取的编码后的聚合特征进行学习:
C1:构建训练集,训练集中包含多组已确定为能够缀合的敦煌遗书残片图像组,以及多组已确定为不能够缀合的敦煌遗书残片图像组,每组图像组中均包含两幅预处理后的敦煌遗书残片图像;其中,将能够缀合的图像组作为正样本,将不能够缀合的图像组作为负样本;
C2:将训练集中每幅预处理后的敦煌遗书残片图像,送入多特征提取网络中;由异构特征挖掘模块分别挖掘和提取每幅图像的书写风格特征、文本布局特征、残边边缘特征和语句通顺性特征;然后由特征聚合模块对得到的书写风格特征、文本布局特征、残边边缘特征和语句通顺性特征进行聚合,通过并列叠放得到每幅图像的基于四种关键特征的聚合特征;最后由特征编码模块对聚合特征进行融合学习,并通过设定的编码器得到每幅图像编码后的聚合特征;编码后的聚合特征包含全局特征和局部特征;
C3:将两幅图像编码后的聚合特征送入对比学习模块进行学习;
C4:利用训练集中的正样本和负样本,对多特征提取网络进行训练;每轮训练后,对比学习模块均通过误差反向传播优化多特征提取网络,直至多特征提取网络的误差达到设定的阈值,或迭代训练的次数达到设定的迭代次数阈值;最终得到训练后的多特征提取网络;
在利用正样本对多特征提取网络进行训练的过程中,利用对比学习拉近两幅已确定为能够缀合的敦煌遗书残片图像编码后的聚合特征的欧氏距离;在利用负样本对多特征提取网络进行训练的过程中,利用对比学习拉远两幅已确定为不能够缀合的敦煌遗书残片图像编码后的聚合特征的欧氏距离。
所述的步骤D中,将预处理后的待缀合敦煌遗书图像A和B,同时输入到优化后的多特征提取网络,分别得到图像A和B编码后的聚合特征,然后利用得到的全局特征计算图像A和B编码后的聚合特征之间的欧氏距离;同理,依次获取图像A和其余图像编码后的聚合特征之间的欧氏距离;最终选取欧氏距离最小的前K个聚合特征,并将前K个聚合特征所对应的敦煌遗书图像,作为与敦煌遗书图像A缀合匹配度最高的K个敦煌遗书图像。
本发明通过挖掘书写风格特征、文本布局特征和残边边缘特征这三种敦煌遗书图像的物理特征,以及语句通顺性特征这种敦煌遗书图像中文字内容的内在逻辑特征,并对上述四种特征进行有机融合,以协同约束敦煌遗书图像的特征表达,能够有效提升敦煌遗书残片图像的缀合精度。
附图说明
图1为本发明的流程示意图。
具体实施方式
以下结合附图和实施例对本发明作以详细的描述:
如图1所示,本发明所述的多特征挖掘与协同约束的敦煌遗书残片缀合方法,包括以下步骤:
A:对待缀合的敦煌遗书残片的图像进行预处理,包括图像尺寸统一调整、图像中的文字列选取、图像中文字区域和非文字区域的二值化处理、图像残边描绘以及图像文字的提取和文字列集合的构建;
B:构建基于Transformer编码器的多特征提取网络;多特征提取网络用于挖掘敦煌遗书残片图像的多个关键特征,并通过特征聚合和基于Transformer编码器的特征编码,得到每幅图像编码后的聚合特征;多特征提取网络包含异构特征挖掘模块、特征聚合模块和特征编码模块;
异构特征挖掘模块包括书写风格特征嵌入学习网络、文本布局特征嵌入学习网络、残边边缘特征嵌入学习网络和语句通顺性特征嵌入学习网络,分别用于挖掘和提取图像中的书写风格特征、文本布局特征、残边边缘特征和语句通顺性特征这四种关键特征;
其中,书写风格特征是指书写者手写文字的笔迹特征,包括笔锋特征、运笔特征、粗细特征和连笔特征等特征;文本布局特征是指文字列排布规律特征,包括文字列的宽度和文字列之间的间隙;残边边缘特征是指残边的轮廓形状特征;语句通顺性特征是指两个句子连接后的语义正确性特征,包括逻辑正确性和语法正确性;
特征聚合模块,用于对得到的书写风格特征、文本布局特征、残边边缘特征和语句通顺性特征进行聚合,通过并列叠放得到每幅图像的基于四种关键特征的聚合特征;
特征编码模块,用于对聚合特征进行融合学习,并通过Transformer编码器得到每幅图像编码后的聚合特征,编码后的聚合特征包含全局特征(c
对Transformer编码器而言,在图像或特征在送入编码器之前,通常会切分为多个图像块或特征块,每个图像块或特征块对应的特征向量记为c
C:利用对比学习模块对多特征提取网络获取的编码后的聚合特征进行学习,进一步优化多特征提取网络;
D:将预处理后的待缀合敦煌遗书残片的图像,输入优化后的多特征提取网络进行关键特征的提取,获取每幅图像编码后的聚合特征,并利用编码后的聚合特征判断得到多幅待缀合敦煌遗书残片的缀合匹配度。
考虑到文本布局特征嵌入学习网络、残边边缘特征嵌入学习网络和语句通顺性特征嵌入学习网络在进行特征挖掘和提取时,需要对待缀合敦煌遗书残片的图像进行相应调整后方能作为嵌入学习网络的输入,因此本发明在步骤A中,通过下述步骤对待缀合敦煌遗书残片的图像进行预处理:
A1:进行图像尺寸统一调整;
设定文字大小的标准值,然后从所有待缀合敦煌遗书残片的图像中分别选取一个文字,并通过缩放图像将该文字的大小调整至设定的标准值,得到尺寸统一调整后的图像;
A2:进行图像中的文字列选取;
若图像中仅有一列文字,则选取该列文字作为待切分文字列;若图像中存在多列文字,则分别将每一列文字单独作为一列待切分文字列;
A3:进行图像中文字区域和非文字区域的二值化处理;
以图像中的区域是否包含文字为依据,对图像通过二值化算法进行处理,得到图像的二值化图,含有文字的区域为白色,未含有文字的区域为黑色;
A4:进行图像残边描绘;
对尺寸调整后的图像的残边进行描绘;残边是指待缀合的敦煌遗书残片的断裂处的边缘;
A5:进行图像文字的提取和文字列集合的构建;
按照专利号为“2022112760024”,专利名称为《基于语句通顺性的敦煌遗书残片图像缀合方法》的已公开发明专利中,步骤G2-2所述的方法,依次进行敦煌遗书残片图像中的文字提取以及文字列集合的构建,本申请中的文字列集合即为《基于语句通顺性的敦煌遗书残片图像缀合方法》专利中的文本列,具体过程在此不再赘述;
书写风格特征是确定两幅敦煌遗书图像是否能够缀合的关键特征之一,若两幅图像中的文字能够确定并非同一人所写,则两幅图像能够缀合的概率极低。因此,本发明通过构建文字无关的书写风格特征嵌入学习网络和文字有关的书写风格特征嵌入学习网络,鉴定两幅图像中书写者手写文字的笔迹特征是否一致,能够排除大量无关的候选缀合对象。
步骤B中,所构建的书写风格特征嵌入学习网络,包括文字无关的书写风格特征嵌入学习网络和文字有关的书写风格特征嵌入学习网络,可采用现有的Transformer神经网络或卷积神经网络。对敦煌遗书残片的图像,利用文字无关的书写风格特征嵌入学习网络和/或文字有关的书写风格特征嵌入学习网络进行特征提取,最终得到图像的书写风格特征。
其中,文字无关的书写风格特征嵌入学习网络用于获取敦煌遗书残片的图像的书写风格特征;文字有关的书写风格特征嵌入学习网络用于获取单独文字的文字图像的书写风格特征;
本发明中,在对文字无关的书写风格特征嵌入学习网络进行训练时,按照下述方法进行:
B111:构建训练集,训练集中包含多幅同一人书写的敦煌遗书残片和多幅非同一人书写的敦煌遗书残片;其中,多幅同一人书写的敦煌遗书残片作为正样本,多幅非同一人书写的敦煌遗书残片作为负样本;
B112:对所有文字列对应的图像分别进行图像切分,通过相同大小的滑动窗口按照设定的步长不断移动,将每列文字列对应的图像切分为不完全重叠的n个图像块;
本实施例中,滑动窗口的移动方向,可按照先水平向再竖直向滑动的方向进行,或按照先竖直向再水平向滑动的方向进行;
B113:将得到的n个图像块送入文字无关的书写风格特征嵌入学习网络中,分别进行书写风格特征提取,最终得到n个图像特征,每个图像块均对应一个图像特征;
B114:将n个图像特征随机划分为两组图像特征组,将每个图像特征组内随机选取的
B115:将经过降维操作的两个书写风格特征送入对比学习模块进行学习;
B116:利用训练集中的正样本和负样本,对文字无关的书写风格特征嵌入学习网络进行训练,直至文字无关的书写风格特征嵌入学习网络的误差达到设定的阈值,或迭代训练的次数达到设定的迭代次数阈值;最终得到训练后的文字无关的书写风格特征嵌入学习网络;
本实施例中,正样本的特征融合过程中,由如下组成方式的图像特征融合生成书写风格特征:
1.同一人书写的一幅敦煌遗书残片的图像中的同一待切分文字列,经文字无关的书写风格特征嵌入学习网络生成的图像特征,并在训练时利用对比学习拉近两个书写风格特征的欧氏距离;
2.同一人书写的一幅或多幅敦煌遗书残片的图像中的不同的待切分文字列,经文字无关的书写风格特征嵌入学习网络生成的图像特征,并在训练时利用对比学习拉近两个书写风格特征的欧氏距离;
负样本的特征融合过程中,由如下组成方式的图像特征融合生成书写风格特征:
1.非同一人书写的多幅敦煌遗书残片图像中的不同的待切分文字列,经文字无关的书写风格特征嵌入学习网络生成的图像特征,并在训练时利用对比学习拉远两个书写风格特征的欧氏距离;
本发明中,在对文字有关的书写风格特征嵌入学习网络进行训练时,按照下述方法进行:
B121:构建训练集,训练集中包含一幅或多幅敦煌遗书残片图像中同一个文字的多幅文字图像;其中,将同一人在同一幅敦煌遗书残片图像中书写的同一个文字的两幅文字图像作为正样本,将不同人书写的两幅敦煌遗书残片图像中同一个文字的两幅文字图像作为负样本;
B122:将训练集中的每个文字图像,输入到文字有关的书写风格特征嵌入学习网络中;
B123:文字有关的书写风格特征嵌入学习网络对输入的文字图像进行图像特征提取,经全连接层处理后,以解耦学习方式得到输入的文字图像的内容特征和书写风格特征;
B124:将两个相同文字的书写风格特征送入对比学习模块进行学习;
B125:利用训练集中的正样本和负样本,对文字有关的书写风格特征嵌入学习网络进行训练,直至文字有关的书写风格特征嵌入学习网络的误差达到设定的阈值,或迭代训练的次数达到设定的迭代次数阈值;最终得到训练后的文字有关的书写风格特征嵌入学习网络;
在利用正样本对文字有关的书写风格特征嵌入学习网络进行训练的过程中,利用对比学习拉近两个正样本的书写风格特征的欧氏距离;在利用负样本对文字有关的书写风格特征嵌入学习网络进行训练的过程中,利用对比学习拉远两个负样本的书写风格特征的欧氏距离;
本发明中,无论两幅敦煌遗书残片图像中是否含有相同的文字,均可利用训练后的文字无关的书写风格特征嵌入学习网络进行图像的书写风格特征提取,将预处理后的待缀合敦煌遗书残片的图像,按照步骤B112至B114的方法进行特征提取,获得图像的书写风格特征;
当两幅敦煌遗书残片图像中含有相同的文字时,还可利用训练后的文字有关的书写风格特征嵌入学习网络进行单独文字的书写风格特征提取,若预处理后的两幅待缀合敦煌遗书残片图像含有一个相同文字,则将对应的两幅文字图像,按照步骤B122至B123中的方法进行特征提取,分别获得文字图像的书写风格特征。
步骤B中,所构建的文本布局特征嵌入学习网络,可采用现有的Transformer神经网络或卷积神经网络。对于敦煌遗书残片的图像,可根据图像对应的二值化图,通过文本布局特征嵌入学习网络进行特征提取,最终得到图像的文本布局特征。
在敦煌遗书残片缀合时,若两幅遗书残片图像能够缀合,则两者之间的文本布局特征(文字列排布规律)应基本一致,如文字列的宽度及文字列之间的间隙。因此,本发明选取文本布局特征作为图像缀合的关键特征之一。
本发明使用文本区域二值化图对敦煌遗书图像进行预处理,能够有效屏蔽背景、文字内容等多余信息的干扰,使构建的文本布局特征嵌入学习网络能够聚焦于两幅敦煌遗书图像的文本列排布规律是否一致的比对上,提高文本布局规律比对的准确性。
本发明中,在对文本布局特征嵌入学习网络进行训练时,按照下述方法进行:
B21:构建训练集,训练集中包含多组已确定为能够缀合的敦煌遗书残片图像组,以及多组已确定为不能够缀合的敦煌遗书残片图像组,每个图像组中均包含两幅敦煌遗书残片图像的二值化图;其中,将能够缀合的图像组作为正样本,将不能够缀合的图像组作为负样本;
由于能够缀合的两幅不同的敦煌遗书残片数量有限,为增加正样本数量,也可将一幅敦煌遗书残片经过旋转、缩放变换后生成变换后的敦煌遗书残片图像,然后将变换前和变换后的图像的二值化图作为正样本;还可将一幅敦煌遗书残片随机切分为两部分,然后分别进行旋转、缩放变换后生成变换后的敦煌遗书残片图像,然后将两幅变换后的图像的二值化图作为正样本;
B22:将训练集中每个敦煌遗书残片图像的二值化图,送入文本布局特征嵌入学习网络,进行文本布局特征的提取,得到每幅敦煌遗书残片图像的文本布局特征;
B23:将两幅敦煌遗书残片图像的文本布局特征送入对比学习模块进行学习;
B24:利用训练集中的正样本和负样本,对文本布局特征嵌入学习网络进行训练,直至文本布局特征嵌入学习网络的误差达到设定的阈值,或迭代训练的次数达到设定的迭代次数阈值;最终得到训练后的文本布局特征嵌入学习网络;
本实施例中,在利用正样本对文本布局特征嵌入学习网络进行训练的过程中,利用对比学习拉近两幅已确定为能够缀合的敦煌遗书残片图像的文本布局特征的欧氏距离;在利用负样本对文本布局特征嵌入学习网络进行训练的过程中,利用对比学习拉远两幅已确定为不能够缀合的敦煌遗书残片图像的文本布局特征的欧氏距离。
本发明中,在利用训练后的文本布局特征嵌入学习网络进行图像的文本布局特征提取时,对预处理后的待缀合敦煌遗书残片的图像的二值化图,按照步骤B22中的方法进行特征提取,获得图像的文本布局特征;
本发明中,所构建的残边边缘特征嵌入学习网络,可采用现有的Transformer神经网络或卷积神经网络。对于待缀合的敦煌遗书残片的图像,利用残边边缘特征嵌入学习网络进行特征提取,最终得到图像的残边边缘特征。
残边边缘特征,即两幅图像的残断边缘的匹配度,是图像缀合常用的特征之一。本发明中,通过挖掘和提取残边边缘特征,能够配合书写风格特征、文本布局特征和语句通顺性特征,进一步提升敦煌遗书残片的缀合精度。
步骤B中,在对残边边缘特征嵌入学习网络进行训练时,按照下述方法进行:
B31:构建训练集,训练集中包含多组已确定为能够缀合的敦煌遗书残片图像组,以及多组已确定为不能够缀合的敦煌遗书残片图像组,每个图像组中均包含两幅敦煌遗书残片图像的残边边缘图像;其中,将能够缀合的图像组作为正样本,将不能够缀合的图像组作为负样本;
B32:将训练集中的敦煌遗书残片图像的残边边缘图像,送入残边边缘特征嵌入学习网络,进行残边边缘特征的提取,得到每幅敦煌遗书残片图像的残边边缘特征;
B33:将两幅敦煌遗书残片图像的残边边缘特征送入对比学习模块进行学习;
B34:利用训练集中的正样本和负样本,对残边边缘特征嵌入学习网络进行训练,直至残边边缘特征嵌入学习网络的误差达到设定的阈值,或迭代训练的次数达到设定的迭代次数阈值;最终得到训练后的残边边缘特征嵌入学习网络;
本实施例中,在利用正样本对残边边缘特征嵌入学习网络进行训练的过程中,利用对比学习拉近两幅已确定为能够缀合的敦煌遗书残片图像的残边边缘特征的欧氏距离;在利用负样本对残边边缘特征嵌入学习网络进行训练的过程中,利用对比学习拉远两幅已确定为不能够缀合的敦煌遗书残片图像的残边边缘特征的欧氏距离。
本发明中,在利用训练后的残边边缘特征嵌入学习网络进行图像的残边边缘特征提取时,对预处理后的敦煌遗书残片图像的残边边缘图像,按照步骤B32中的方法进行特征提取,获得图像的残边边缘特征;
语句通顺性特征,是指在逻辑和语法的角度,检查待缀合的两幅图像中的对应的文字内容在拼合后的语法正确性和逻辑合理性。本发明中通过挖掘提取语句通顺性特征,能够在书写风格特征、文本布局特征和残边边缘特征的基础上,进一步排除大量的无关候选缀合对象,提升缀合精度。
步骤B中,所构建的语句通顺性特征嵌入学习网络,可采用现有的BERT预训练语言模型。对于敦煌遗书残片图像中的文字列内容,通过语句通顺性特征嵌入学习网络进行特征提取,最终得到图像的语句通顺性特征。
本发明中,在对语句通顺性特征嵌入学习网络进行训练时,按照下述方法进行:
B41:构建训练集,训练集中包含多组正样本和负样本;
训练集构建的方法,可按照专利号为“2022112760024”,专利名称为《基于语句通顺性的敦煌遗书残片图像缀合方法》的已公开发明专利中,步骤G2-1所述的方法进行,在此不再赘述;
B42:将训练集中的每段语句送入语句通顺性特征嵌入学习网络,进行语句通顺性特征的提取,得到每段语句的语句通顺性特征;
B43:利用训练集中的正样本和负样本,对语句通顺性特征嵌入学习网络进行调优训练,直至迭代训练的次数达到设定的迭代次数阈值;最终得到调优训练后的语句通顺性特征嵌入学习网络;
本发明中,在利用调优训练后的语句通顺性特征嵌入学习网络进行图像的语句通顺性特征提取时,对预处理后的敦煌遗书残片图像,首先按照专利号为“2022112760024”,专利名称为《基于语句通顺性的敦煌遗书残片图像缀合方法》的已公开发明专利中步骤G2所述的方法,分别获取敦煌遗书残片图像A与敦煌遗书残片图像B,在各种相互位置关系下及对齐状态下对应的语句通顺性数值,然后确定语句通顺性数值中的最高值所对应的两幅敦煌遗书残片图像中相对应的两个语句,再将两个对应的语句利用步骤B42所述的方法,分别获取每个语句的语句通顺性特征。
所述的步骤C中,在利用对比学习模块对多特征提取网络获取的编码后的聚合特征进行学习时,按照下述步骤进行:
C1:构建训练集,训练集中包含多组已确定为能够缀合的敦煌遗书残片图像组,以及多组已确定为不能够缀合的敦煌遗书残片图像组,每组图像组中均包含两幅预处理后的敦煌遗书残片图像;其中,将能够缀合的图像组作为正样本,将不能够缀合的图像组作为负样本;
C2:将训练集中每幅预处理后的敦煌遗书残片图像,送入基于Transformer编码器的多特征提取网络中;由异构特征挖掘模块分别挖掘和提取每幅图像的书写风格特征、文本布局特征、残边边缘特征和语句通顺性特征;然后由特征聚合模块对得到的书写风格特征、文本布局特征、残边边缘特征和语句通顺性特征进行聚合,通过并列叠放得到每幅图像的基于四种关键特征的聚合特征;最后由特征编码模块对聚合特征进行融合学习,并通过设定的编码器得到每幅图像编码后的聚合特征;编码后的聚合特征包含全局特征c
C3:将两幅图像编码后的聚合特征送入对比学习模块进行学习;
C4:利用训练集中的正样本和负样本,对多特征提取网络进行训练;每轮训练后,对比学习模块均通过误差反向传播优化多特征提取网络,直至多特征提取网络的误差达到设定的阈值,或迭代训练的次数达到设定的迭代次数阈值;最终得到训练后的多特征提取网络;
在利用正样本对多特征提取网络进行训练的过程中,利用对比学习拉近两幅已确定为能够缀合的敦煌遗书残片图像编码后的聚合特征的欧氏距离;在利用负样本对多特征提取网络进行训练的过程中,利用对比学习拉远两幅已确定为不能够缀合的敦煌遗书残片图像编码后的聚合特征的欧氏距离。
所述的步骤D中,将预处理后的待缀合敦煌遗书图像A和B,同时输入到优化后的多特征提取网络,分别得到图像A和B编码后的聚合特征,然后利用得到的全局特征c
- 一种敦煌遗书残片图像的自动缀合方法
- 一种敦煌遗书残片图像的自动缀合方法