基于注意力的神经网络的硬件实施
文献发布时间:2024-04-18 19:58:53
本申请要求2022年6月17日提交的英国专利申请2208959.3和2208958.5的优先权,这些专利申请以引用方式全文并入本文中。
技术领域
本发明涉及神经网络领域,特别是基于注意力的神经网络。
背景技术
“注意力”指的是一种技术或结构配置,它允许神经网络专注于其输入的某一部分(或某些部分)。注意力可以用来表征不同数据的不同部分之间的关系。注意力的应用包括但不限于自然语言处理(NLP)和计算机视觉。例如,在NLP中,注意力机制可以使神经网络模型能够注意句子中的某些单词。例如,在计算机视觉中,注意力可以使神经网络注意场景的某些部分。
注意力机制可以分为两大类:
·“自我注意力”管理和量化一组输入元素本身之间的相互依赖。
·“交叉注意力”(也称为一般注意力)管理和量化两组输入元素之间的相互依赖。
这些不同类型的注意力被不同的神经网络架构不同地使用。例如,在NLP中,自我注意力本身可以用来理解句子的上下文。它以这种方式应用于谷歌的基于变换器的双向编码器表征(bidirectional encoder representations from transformers)(BERT)技术中。
在诸如机器翻译的应用中,自我注意力和交叉注意力可以一起应用,以允许网络专注于输入语言中的输入句子的不同部分,并建立输入句子的部分与目标语言中的目标句子之间的关系。
变换器网络目前是基于注意力的网络的一个主要示例。在Vaswani等人的(“Attention is all you need”,载于Advances in Neural Information ProcessingSystems 30(NIPS)2017,
·单个编码器堆栈、多个解码器堆栈——参见Vaswani等人的文章;
·单个编码器堆栈、单个解码器堆栈——例如,对象检测变换器(DETR)网络;
·单个编码器堆栈——示例包括BERT、视觉变换器和word语言模型;
·多个解码器堆栈——例如,生成式预训练变换器(GPT)1/2/3系列模型。
变换器网络已被证明提供了强大的基于注意力的架构,具有最先进的精度,跨多种模态和任务。对于2-D图像,这些包括:图像分类、对象检测、动作识别、分割、超分辨率、增强和彩色化;对于视频,这些包括:活动识别和视频预报(一种时间序列预报);对于3D表示(诸如网格或点云),这些包括:分类和分割;对于文本,这些包括:语言建模和生成、下一句预测、分类和问答;对于音频,这些包括:语音识别和声音合成。还存在多模态应用,其中输入和输出来自不同的模态。这方面的示例包括视觉问答、推理和图像字幕。
发明内容
提供本发明内容是为了以简化形式介绍下文在具体实施方式中进一步描述的一系列概念。本发明内容不旨在标识所要求保护的主题的关键特征或必要特征,也不旨在用以限制所要求保护的主题的范围。
希望能够在硬件中有效地实施基于注意力的神经网络。
本发明由权利要求书限定。
公开了一种用于选择数字格式的计算机实施的方法。数字格式适用于在配置基于注意力的神经网络的硬件实施中使用。获得用于神经网络的测试输入序列的数据集。用填充值填充每个测试输入序列。对于每个填充输入序列,生成填充掩码以标识填充输入序列的包含填充值的部分。使用外积运算从每个填充掩码生成注意力掩码。填充输入序列和注意力掩码通过神经网络进行处理。在处理期间,收集统计数据以描述在神经网络的各个层获得的值的范围。基于所收集的统计数据为各个层选择数字格式。
根据一个方面,提供了一种用于选择在配置基于注意力的神经网络的硬件实施中使用的数字格式的计算机实施的方法,该方法包括:获得基于注意力的神经网络的表示;将该表示实施为测试神经网络;获得用于基于注意力的神经网络的第一测试输入序列的数据集,其中该数据集包括可变长度的第一测试输入序列;用填充值填充每个第一测试输入序列,以产生第一固定长度的相应第一填充输入序列;为每个第一填充输入序列生成相应第一填充掩码,该第一填充掩码标识第一填充输入序列的包含填充值的部分;从每个第一填充掩码生成第一注意力掩码,其中该生成包括应用于第一填充掩码的外积运算;通过测试神经网络处理第一填充输入序列和第一注意力掩码;收集描述在所述处理期间获得的值的范围的统计数据,其中该统计数据描述用于基于注意力的神经网络的至少两个不同层的值的范围;以及基于所收集的统计数据为至少两个不同层选择数字格式。
数字格式可以是由一个或多个可配置参数定义的块可配置数字格式。
数字格式的选择可以标识预定义类型的块可配置数字格式的块可配置数字格式。
数字格式的选择可包括:
●对于不同层中的每一个不同层,独立地标识用于每个实例的数字格式;
●组合用于多个实例的数字格式,以便导出用于多个实例的公共数字格式。
数字格式的选择可以标识由用于每个实例的一个或多个可配置参数定义的块可配置数字格式。
数字格式选择可以是反向传播格式选择、贪婪线搜索和端到端格式选择、正交搜索格式选择、最大范围(或“MinMax”)格式选择、异常值拒绝格式选择、基于误差的启发式格式选择(例如,基于具有或不具有异常值加权的误差平方和)、加权异常值格式选择和梯度加权格式选择算法中的一者或多者。
基于它们不同的所收集的统计数据,为两个层中的一个层选择的数字格式可不同于为另一层选择的数字格式。
该方法特别包括为以下中的一者或两者选择数字格式:第一填充输入序列;和第一注意力掩码。
该方法可包括选择第一固定长度。第一固定长度可被选择为等于数据集中的第一测试输入序列之中的最大长度。
在注意力计算中,在处理中使用第一注意力掩码来忽略相应第一填充输入序列的某些元素。特别地,第一注意力掩码用于忽略第一填充输入序列的包含填充值的部分。第一注意力掩码也可用于忽略第一填充输入序列的其他部分。第一注意力掩码可以是自我注意力掩码。生成第一注意力掩码可包括第一填充掩码与其自身的外积。
基于注意力的神经网络可包括解码器,其中第一测试输入序列是用于解码器的测试输入序列,其中通过测试神经网络处理第一填充输入序列中的每一个第一填充输入序列和相应第一注意力掩码可选地包括将解码器执行等于第一固定长度的迭代次数,其中在所有迭代中收集统计数据。
如果基于注意力的神经网络仅包括解码器(即,它不包括编码器),则第一注意力掩码是自我注意力掩码。解码器可包括多个层的堆栈。
在每次迭代中,解码器可产生输出序列,并且在除初始迭代之外的每次迭代中,对解码器的输入包括来自前一次迭代的输出序列。在某些示例中,解码器的迭代可能会提前终止——例如,通过解码器输出或接收终止标记。或者,在一些其他示例中,对于给定的输入序列,解码器可以仅执行一次。
基于注意力的神经网络可包括编码器,并且第一测试输入序列可以是用于编码器的测试输入序列。编码器可包括多个层的堆栈。
基于注意力的神经网络还可包括解码器,并且该方法还可包括:获得第二测试输入序列的数据集,其中第二测试输入序列是用于解码器的测试输入序列;用填充值填充每个第二测试输入序列,以产生第二固定长度的相应第二填充输入序列;为每个第二填充输入序列生成相应第二填充掩码,该第二填充掩码标识第二填充输入序列的包含填充值的部分;以及从每个第二填充掩码生成第二注意力掩码,其中该生成包括应用于第二填充掩码的外积运算,其中该方法还包括为解码器的至少一个层选择数字格式。
第二测试输入序列可具有可变长度,小于或等于第二固定长度。第一固定长度可以不同于第二固定长度。该方法可包括选择第二固定长度。第二固定长度可被选择为等于数据集中的第二测试输入序列之中的最大长度。
该方法还可包括将解码器执行等于第二固定长度的迭代次数,其中,在每次迭代中,解码器产生输出序列,并且在除了初始迭代之外的每次迭代中,对解码器的输入包括来自前一次迭代的输出序列,其中在所有迭代中收集统计数据。
该方法还可包括从每个第一填充掩码和相应第二填充掩码生成交叉注意力掩码,该生成包括第一填充掩码与第二填充掩码的外积,其中该方法包括:通过测试神经网络处理第一填充输入序列、第二填充输入序列、第一注意力掩码、第二注意力掩码和交叉注意力掩码,以及为第一填充输入序列、第二填充输入序列、第一注意力掩码、第二注意力掩码和交叉注意力掩码中的任一者或两者或更多者的任何组合选择数字格式。
相对于第二填充输入序列的某些元素(即,解码器的输入序列的某些元素),在处理中使用交叉注意力掩码来忽略编码器的输出的某些元素。
基于注意力的神经网络可包括缩放点积注意力计算。缩放点积注意力计算可包括两个矩阵乘法和Softmax函数。特别地,如果存在单个输入批量和单头注意力层,可能就是这种情况。在多头注意力层的情况下(和/或如果存在多个输入批量),缩放点积注意力计算可包括两个批量矩阵乘法和Softmax函数。在一些示例中,在多头注意力层和多个批量的情况下,缩放点积注意力计算可包括两个批量矩阵乘法和用于多头注意力层的每个头的Softmax函数。缩放点积注意力计算还可包括其输入的一个或多个线性投影。一个或多个线性投影可以是计算的第一步骤。
填充输入序列(或每个填充输入序列)中的填充值可等于零。
每个填充掩码可包括1和0。特别地,对应于相应输入序列的元素的位置可等于一,并且对应于填充的位置可等于零。
可选地,每个第一注意力掩码:在对应于相应第一输入序列的元素的位置中包括多个零;以及在对应于相应第一填充输入序列的填充值的位置中包括一个或多个大负值。
每个第二注意力掩码可类似地在对应于相应第二输入序列的元素的位置中包含或包括零;以及在对应于相应第二填充输入序列的填充值的位置中包含或包括大负值。每个交叉注意力掩码可在对应于相应第一和第二输入序列的元素的位置中包含或包括零;以及在对应于任一相应填充输入序列的填充值的位置中包含或包括大负值。
大负值可等于可由为第一注意力掩码选择的数字格式表示的最大负值。在一些实施方案中,大负值不需要等于所述最大负值;然而,它们的值可能比输入到使用第一注意力掩码(针对每个第一测试输入序列)的任何层的数据张量中存在的最大负值更负。它们可能负到相差一个裕量。即,数据张量中存在的最大负值与所述大负值之间可能存在若干(未使用的)值。在一些示例中,大负值可具有大于数据张量的最大绝对值的绝对值。它们可能大到相差一个裕量——即,数据张量的最大绝对值与大负值的绝对值之间可能存在若干(未使用的)值。可选择大负值x,使得以为注意力掩码选择的数字格式,e^x=0(其中“e”是欧拉数)。所有这些同样适用于自我注意力掩码和交叉注意力掩码。
基于注意力的神经网络可包括Softmax函数,并且该处理可包括将第一注意力掩码添加到对Softmax函数的输入。填充掩码中的大负值可具有忽视对Softmax函数的对应输入值的作用。添加到输入中的大负值支配先前存在的输入值。例如,Softmax函数可以是缩放点积注意力计算的一部分(如上文已经提到的)。
基于注意力的神经网络可以包括(或者可以是)变换器网络。变换器网络可包含或包括编码器、或解码器、或编码器和解码器两者。
变换器网络可包括以下中的任一者或以下中的两者或更多者的任意组合:应用于第一填充输入序列的输入嵌入;添加到输入嵌入的第一位置编码;应用于第二填充输入序列的输出嵌入;添加到输出嵌入的第二位置编码。
变换器网络可包括耦合到解码器的输出的一个或多个分类或预测层。
基于注意力的神经网络可选地包括层归一化。例如,可在缩放点积注意力计算的输出处应用层归一化。可选地或附加地,可在编码器或解码器中的前馈层的输出处应用层归一化。
该硬件实施可被配置为执行可用基本神经网络运算集,该方法可选地包括:将层归一化映射到包括来自可用基本神经网络运算集的多个基本神经网络运算的等效表示;以及为所述多个基本神经网络运算选择数字格式,其中多个基本神经网络运算中的每一个基本神经网络运算选自包括以下各项的列表:卷积运算;逐元素减法运算;逐元素乘法运算;倒数运算;平方根运算;逐元素除法运算;整流线性激活函数;局部响应归一化;逐元素加法。
逐元素运算可由NNA的逐元素运算单元实施。整流线性激活函数可由NNA的激活单元实施。局部响应归一化、倒数运算和平方根运算可由NNA的局部响应归一化单元实施。(应当理解,可选择输入到LRN单元的参数,以针对要执行的期望运算对其进行适当配置。)卷积运算可由NNA的多个卷积引擎实施。
在一些示例中,多个基本神经网络运算实施:应用于对层归一化的输入的第一卷积运算,以计算输入的平均值;逐元素减法运算,以从输入中减去平均值;第一逐元素乘法运算,以计算逐元素减法运算的输出的平方;以及应用于第一逐元素乘法运算的输出的第二卷积运算,以计算关于平均值的方差。
多个基本神经网络运算还可实施被配置为控制层归一化的输出的标准偏差的第二逐元素乘法运算。它还可实施被配置为控制层归一化的输出的平均值的第一逐元素加法运算(可选地应用于第二逐元素乘法运算的输出)。
多个基本神经网络运算还可实施在第二卷积运算之后应用的平方根运算,以计算标准偏差。
多个基本神经网络运算还可实施被配置为将小(正)值添加到标准偏差的第二逐元素加法运算。通过避免被零除的情况,增加这个小值有助于确保数值稳定性。小正值的示例值是1e-5(0.00001)。
在一些示例中,多个基本神经网络运算实施:在第二卷积运算之后应用的平方根运算和倒数运算,以计算标准偏差的倒数;以及第二逐元素乘法运算,以将逐元素减法运算的输出乘以标准偏差的倒数。
在一些示例中,多个基本神经网络运算实施:应用于第二卷积运算的输出的平方根运算,以计算标准偏差;以及逐元素除法运算,以将逐元素减法运算的输出除以标准偏差。
在一些示例中,多个基本神经网络运算实施:应用于第二卷积运算的输出的整流线性激活函数;应用于整流线性激活函数的输出的逐元素加法运算;应用于逐元素加法运算的输出的局部响应归一化,以计算标准偏差的倒数;以及第二逐元素乘法运算,以将逐元素减法运算的输出乘以标准偏差的倒数。
逐元素加法运算可包括将小的常数值添加到整流线性激活函数的输出。这样做是为了避免被零除的情况。
基于注意力的神经网络可包括Softmax函数,其中硬件实施被配置为执行可用基本神经网络运算集,该方法可选地包括:将Softmax函数映射到包括来自可用基本神经网络运算集的多个基本神经网络运算的表示;以及为所述多个基本神经网络运算选择数字格式,其中多个基本神经网络运算中的每一个基本神经网络运算选自包括以下各项的列表:转置或置换运算;最大池化运算;逐元素最大运算;逐元素减法运算;逐元素求反运算;逐元素加法运算;逐元素除法运算;逐元素乘法运算;逐元素位移位运算;逐元素运算f(z)=2^z,其中z通常是非整数值;卷积运算;函数近似运算;以及局部响应归一化。
基于注意力的神经网络可包括在维度为[...,P,...,Q,...]的第一张量X与维度为[...,Q,...,R,...]的第二张量Y之间的二维或更多维度中定义的矩阵乘法运算,该方法可选地包括:将矩阵乘法运算映射到包括至少一个变换和至少一个卷积运算的神经网络运算图;以及为神经网络运算图选择数字格式。
在一些示例中,基于注意力的神经网络可包括在维度为[...,P,...,Q,...]的第一张量X与维度为[...,Q,...,R,...]的第二张量Y之间的二维或更多维度中定义的矩阵乘法运算,该方法可选地包括:将矩阵乘法运算映射到包括至少一个逐元素运算的神经网络运算图;以及为神经网络运算图选择数字格式。
矩阵乘法运算可以是注意力计算的一部分。特别地,它可以是缩放点积注意力计算的一部分。矩阵乘法运算可以是批量矩阵乘法运算。
还提供了一种数据处理系统,该数据处理系统被配置为执行如上概述的方法。数据处理系统可以在集成电路上的硬件中体现。
还提供了一种使用集成电路制造系统来制造如上概述的数据处理系统的方法。
还提供了一种使用集成电路制造系统制造如上概述的数据处理系统的方法,该方法包括:使用布局处理系统对数据处理系统的计算机可读描述进行处理,以生成体现数据处理系统的集成电路的电路布局描述;以及使用集成电路生成系统,根据电路布局描述来制造数据处理系统。
还提供了一种计算机可读代码,该计算机可读代码被配置为使得当代码被运行时执行如上概述的方法。还提供了一种计算机可读存储介质(可选地是非暂时性的),在其上编码有所述计算机可读代码。
还提供了集成电路定义数据集,当在集成电路制造系统中进行处理时,该集成电路定义数据集配置集成电路制造系统以制造如上概述的数据处理系统。
还提供了一种计算机可读存储介质,该计算机可读存储介质上存储有如上概述的数据处理系统的计算机可读描述,该计算机可读描述在集成电路制造系统中处理时使集成电路制造系统制造体现该数据处理系统的集成电路。
还提供了一种计算机可读存储介质,该计算机可读存储介质上存储有如上概述的数据处理系统的计算机可读描述,该计算机可读描述在集成电路制造系统中处理时使集成电路制造系统执行以下运算:使用布局处理系统对数据处理系统的计算机可读描述进行处理,以生成体现该数据处理系统的集成电路的电路布局描述;并且使用集成电路生成系统根据电路布局描述来制造数据处理系统。
还提供了一种集成电路制造系统,该集成电路制造系统被配置为制造如上概述的数据处理系统。
还提供了一种集成电路制造系统,包括:计算机可读存储介质,该计算机可读存储介质上存储有如上概述的数据处理系统的计算机可读描述;布局处理系统,该布局处理系统被配置为处理计算机可读描述,以生成体现该数据处理系统的集成电路的电路布局描述;以及集成电路生成系统,该集成电路生成系统被配置为根据电路布局描述来制造数据处理系统。布局处理系统可被配置为确定从集成电路描述导出的电路的逻辑部件的位置信息,以生成体现数据处理系统的集成电路的电路布局描述。
如对本领域的技术人员显而易见的,上述特征可以适当地组合,并且可以与本文所述的示例的任何方面组合。
附图说明
现在将参考附图详细描述示例,在附图中:
图1A示出了根据一个示例的用于变换器网络的编码器堆栈的一个层的实施;
图1B示出了根据一个示例的用于变换器网络的解码器堆栈的一个层的实施;
图1C示出了根据一个示例的缩放点积注意力计算的实施;
图2是根据本公开的一个示例的包括固定功能硬件的硬件加速器的框图;
图3是图2中使用的卷积引擎的框图;
图4是根据一个示例的数据处理系统的框图;
图5是图4中的存储器操纵模块的框图;
图6A是示出根据一个示例的使用基于注意力的神经网络来实施推断的方法的流程图;
图6B是示出用于处理比先前选择的固定长度更长的输入序列的方法的流程图;
图7示出了根据一个示例的由用于使用卷积运算实施矩阵乘法的基本神经网络运算组成的计算图;
图8示出了根据一个示例的由用于使用卷积实施批量矩阵乘法的基本神经网络运算组成的计算图;
图9示出了基于图8中的计算图的批量矩阵乘法的实际实例;
图10示出了根据一个示例的由用于使用分组卷积实施批量矩阵乘法的基本神经网络运算组成的计算图;
图11示出了基于图10中的计算图的批量矩阵乘法的实际实例;
图12示出了根据一个示例的由用于使用逐元素运算实施批量矩阵乘法的基本神经网络运算组成的计算图;
图13示出了基于图12中的计算图的矩阵乘法的实际实例;
图14A示出了softmax层的计算图;
图14B是示出计算图14A中的指数运算的一种方式的计算图;
图15A示出了最大运算;
图15B是示出用于实施图15A的最大运算的一种方法的计算图;
图15C示出了通过连续逐元素比较来确定张量的最大值的方法;
图15D示出了通过连续逐元素比较来确定最大值的另一示例;
图16是示出用于实施图15A的最大运算的替代方法的计算图;
图17A示出了求和运算;
图17B是示出图17A的求和运算可以映射到基本神经网络运算的一种方式的计算图;
图18A示出了除法运算;
图18B是示出图18A的除法运算可以映射到基本神经网络运算的一种方式的计算图;
图18C是示出图18A的除法运算可以映射到基本神经网络运算的替代方式的计算图;
图19A至图19C示出了用于实施层归一化的三个不同的计算图;
图20A是示出根据一个示例的用于选择数字格式的方法的流程图;
图20B延续了图20A的流程图;
图21是示出根据一个示例的训练基于注意力的神经网络的方法的流程图;
图22示出了在其中实施数据处理系统的计算机系统;并且
图23示出了用于产生体现数据处理系统的集成电路的集成电路制造系统。
附图示出了各种示例。技术人员将了解,附图中所示出的元件边界(例如框、框的组,或其他形状)表示边界的一个示例。在一些示例中,情况可能是一个元件可以被设计为多个元件,或者多个元件可以被设计为一个元件。在适当的情况下,贯穿各附图使用共同的附图标记来指示类似的特征。
具体实施方式
借助于示例呈现以下描述,以使得本领域的技术人员能够制造和使用本发明。本发明不限于本文中所描述的实施方案,并且对所公开实施方案的各种修改对于本领域的技术人员将是明显的。
现在将仅借助于示例来描述实施方案。
在以下描述中,变换器网络将被用作基于注意力的神经网络的示例。这是一个方便且有用的示例,因为已经发现这样的网络在许多任务中产生良好的性能。然而,应当理解,本公开的范围不限于变换器网络。本公开同样适用于其他基于注意力的网络。为了理解以下描述中的变换器网络示例,假设读者已经获悉上文引用的Vaswani等人的文献。
图1A示出了变换器网络中的编码器堆栈的一个层100的实施。编码器堆栈中可存在许多这样的层,如图中的“Nx”标注所指示。层数N至少为1,但在许多示例中将大于1。编码器的一般结构将从Vaswani等人的文献中了解。编码器堆栈的输入包括“标记”或“元素”的序列。在将它们传递到编码器的第一层之前,输入101通过线性投影102被“嵌入”。在加法器104处,位置编码103被添加到嵌入的结果。位置编码103注入关于序列中的标记位置的信息。如同Vaswani等人的文献,本示例使用不同频率的周期函数进行位置编码。应当理解,嵌入和位置编码仅在对编码器堆栈的第一层的输入处是必要的。堆栈中的后续层(未示出)将直接从前一层的输出获取其输入。
编码器堆栈的层100包括:多头注意力块110;加法和归一化块120;前馈块130;以及另一加法和归一化块140。多头注意力块110对输入执行自我注意力。在本示例中,这是通过多个缩放点积注意力(SDPA)块112-1至112-n来完成的,其中n是头的数量。然而,应当理解,可以使用其他形式的注意力计算来代替SDPA。多个头的输出被连接起来并进行线性投影114。
多头注意力块110的输出作为输入被提供给加法和归一化块120。此块120包括加法器122,该加法器被配置为将多头注意力块110的输出添加到对该块的输入。层归一化124被应用于加法122的结果。
加法和归一化块120的输出作为输入被提供给前馈块130。此块包括一个或多个前馈神经网络层。在本示例中,存在两个前馈层132和134。
前馈块130的输出作为输入被提供给另一加法和归一化块140。此块具有与加法和归一化块120相似的结构。加法器142被配置为将前馈块132的输出添加到对该块的输入。层归一化144被应用于加法142的输出。另一加法和归一化块140的输出形成编码器堆栈的这一层的输出。如果当前层不是编码器堆栈的最后一层,则加法和归一化块140的输出被输入到编码器堆栈的下一层。如果当前层是编码器堆栈的最后一层,则加法和归一化块140的输出形成编码器的输出。取决于变换器网络的特定应用,此输出可被提供给一个或多个预测头,或者提供给解码器堆栈。即,编码器堆栈可单独使用或与解码器堆栈(诸如下文参考图1B所描述的解码器堆栈)结合使用。
图1B示出了变换器网络的解码器堆栈的一个层150的实施。取决于变换器网络的特定应用,解码器堆栈可单独使用,或与编码器堆栈(例如上文参考图1A所描述的编码器堆栈)结合使用。与编码器堆栈一样,解码器堆栈通常包括N个层,其中N大于或等于1。附图中所示的解码器堆栈的层150被示出为解码器堆栈的第一层。在将它们传递到层150之前,在块152处嵌入输入151,并且在块154处加上位置编码153。在这方面,块152和154类似于块102和104。然而,特定嵌入和位置编码在编码器与解码器之间通常是不相同的。输入通常也是不同的。例如,在为语言翻译而训练的变换器网络中,标记可以是单词。在训练阶段,编码器堆栈将源语言中的单词序列(例如句子)作为输入。解码器堆栈将目标语言中的单词序列(例如句子)作为输入。对于每种语言,嵌入(其可被学习)和位置编码可能不同。
与编码器层100一样,解码器层150的一般结构将从Vaswani等人的文献中获悉。解码器堆栈的层150包括:第一多头注意力块111;第一加法和归一化块121;第二多头注意力块161;第二加法和归一化块171;前馈块131;以及另一加法和归一化块141。多头注意力块111具有与编码器层的多头注意力块110相同的结构。它使用多个SDPA块(未示出)对输入执行自我注意力。
多头注意力块111的输出作为输入被提供给第一加法和归一化块121。此第一加法和归一化块在结构和功能上类似于编码器层的加法和归一化块120。当解码器堆栈与编码器堆栈一起使用时,加法和归一化块121的输出作为输入被提供给第二多头注意力块161。此块161还接收编码器堆栈的输出作为输入。第二多头注意力块161执行解码器输入与编码器输入之间的交叉注意力。第二多头注意力块161的输出作为输入被提供给第二加法和归一化块171。类似于加法和归一化块120和121,此块将第二多头注意力块161的输入和输出相加在一起,并对相加的结果执行层归一化。第二加法和归一化块171的输出作为输入被提供给前馈块131。(当单独使用解码器堆栈时——即,没有编码器堆栈——前馈块131直接从第一加法和归一化块121接收其输入。)
前馈块131在结构和功能上类似于编码器层的前馈块130。它包括一个或多个前馈神经网络层——例如,两个前馈层。前馈块131的输出作为输入被提供给另一加法和归一化块141,该另一加法和归一化块在结构和功能上类似于编码器层的结尾处的加法和归一化块140。另一加法和归一化块141的输出形成解码器堆栈的这一层的输出。如果当前层不是解码器堆栈的最后一层,则加法和归一化块141的输出被输入到解码器堆栈的下一层。如果当前层是解码器堆栈的最后一层,则加法和归一化块141的输出形成解码器的输出。此输出可被提供给一个或多个预测头。
在变换器网络的一些应用中,解码器堆栈被迭代执行,迭代次数可以是固定的或可变的。例如,使用上述机器翻译示例,解码器堆栈可被执行若干次迭代,直到解码器输出“结束”标记,该标记指示句子的结尾已经到达目标语言中,并且终止迭代。在每次迭代中,目标语言中的对应句子的再一个单词将被预测。
当试图在神经网络加速器(NNA)的固定功能硬件中实施基于注意力的网络(诸如图1A和图1B的变换器网络示例)时,会出现问题。编码器和解码器堆栈的输入通常是可变长度的序列。例如,在上文讨论的机器翻译示例中,序列长度取决于句子中的单词数。在示例性NNA架构中,处理可变长度的输入可能是低效的或者不可能的。固定功能硬件可能需要固定长度的输入(或者在处理这种输入时可能更有效)。
在根据本公开的示例中,建议将可变长度输入序列填充到固定长度。编码器堆栈的输入被填充到第一固定长度,解码器堆栈的输入被填充到第二固定长度。这些固定长度可以是不同的,从而反映了与解码器相比,在编码器处可能期望不同长度的输入序列的事实。可基于在输入序列的训练数据集上遇到的可变长度的范围来选择固定长度。特别地,每个固定长度可被选择为等于训练数据集的相应输入序列的最大长度。
输入序列的填充在图1A和图1B中并不明显。然而,应当理解,这些图中的输入101和151已经被填充。这意味着每个输入张量的第一部分与对应的可变长度输入张量相同。每个输入张量的剩余部分包括填充值。在本示例中,这些值被设置为等于0。
当将可变长度输入序列填充到固定长度时,应注意确保填充不会过度影响基于注意力的网络中的计算。特别地,在根据本公开的示例中,建议修改注意力计算以适应填充。由于计算的形式,仅仅将填充值设置为0是不够的。
图1C示出了如在图1A中使用和示出的以及如在图1B中使用(但未示出)的缩放点积注意力计算112的实施。块112示出了单个SDPA计算。应当理解,此计算针对多头注意力计算中的每个头执行。SDPA计算的输入被标记为Q、K和V。张量Q被称为“查询”;张量K被称为“键”;而张量V被称为“值”。可选地,这些中的每一个可首先进行相应线性投影191-1、191-2和191-3,如由Vaswani等人的文献所描述。然后,(经投影的)张量Q和(经投影的)张量K被输入到矩阵乘法192。(一般地,如果存在多批量的输入数据,这可能是批量矩阵乘法。)
(批量)矩阵乘法192的输出向加法运算194提供一个输入。加法194的其他输入是针对输入序列定义的注意力掩码。注意力掩码的维度(如同张量Q、K和V的维度)由固定长度决定。根据本示例,注意力掩码在对应于原始可变长度输入序列的位置中包含零值。在对应于填充的位置中(在填充输入序列中),注意力掩码包含大负值。意图是加法194的输出应当由对应于填充的位置中的这些大负值支配。
举例来说:对于维度为(N,L
在自我注意力块110的情况下,输入V、K和Q是编码器的输入。同样,在自我注意力块111的情况下,输入V、K和Q是解码器的输入。在交叉注意力块161的情况下,张量V和K来自编码器的输出,而张量Q是对解码器的输入。
注意力掩码根据填充掩码计算,该填充掩码与相应填充输入序列相关联。每个填充掩码具有与相关联的填充输入序列相同的固定长度。填充掩码的对应于原始可变长度输入序列的部分包含等于一的值。填充掩码的对应于填充输入序列中的填充值的剩余部分包含等于零的值。第一填充掩码与编码器的输入相关联;第二填充掩码与对解码器的输入相关联。为了生成用于编码器的自我注意力块110的自我注意力掩码,计算第一填充掩码与其自身的外积。外积计算的结果在对应于原始可变长度编码器输入序列的位置处具有一,在对应于填充的位置处具有零。为了从外积计算的结果中产生自我注意力掩码,用大负值替换零,并且用零替换一。因此,自我注意力掩码在对应于原始可变长度编码器输入序列的位置处包含零,并且在对应于填充的位置处包含大负值。用于解码器的自我注意力块111的自我注意力掩码以相同的方式从第二填充掩码生成。用于解码器的交叉注意力块161的交叉注意力掩码从第一填充掩码和第二填充掩码生成。首先,计算这两个掩码的外积。然后,用大负值替换外积中的零,用零替换外积中的一。因此,交叉注意力掩码在对应于第一填充掩码和第二填充掩码两者中的“一”的位置处包含零。它在对应于任一填充掩码中的零的位置——即,在对应于任一掩码中的填充的位置处包含大负值。
根据本示例,填充值被附加到原始(可变长度)输入序列。因此,注意力掩码具有块结构,该块结构具有维度取决于原始可变长度输入序列的大小的零块,并且具有张量元素的等于大负值的剩余部分。
可以修改自我注意力掩码以防止网络注意(经由自我注意力或交叉注意力)原始(可变长度)输入序列的某些元素。这可以通过直接修改注意力掩码(通过将零改为大负值)或者通过在外积计算之前修改填充掩码(将一改为零)来完成。要防止网络注意的元素可由网络的外部输入来指示——例如,在实例化神经网络的函数调用中提供的附加变量。
加法194的输出被输入到Softmax函数196。这将计算其中正在计算注意力的特征上的Softmax。Softmax函数涉及将指数函数应用于输入。当x是大负数时,计算结果e
Softmax函数196的输出形成对(批量)矩阵乘法198的一个输入。对(批量)矩阵乘法198的其他输入是(经投影的)值的张量V。块192、194、196和198一起实施以下等式,没有来自相应输入向量的填充部分的干扰:
根据本示例,实施基于注意力的网络所需的所有计算都可以由示例性硬件加速器(NNA)上可用的基本神经网络运算来构建。这包括NNA上通常并不本地支持的计算,诸如(批量)矩阵乘法、Softmax和层归一化。这可在不必修改硬件加速器的硬件的情况下实现。
示例性硬件加速器
如图2所示,示例性硬件加速器200(在本文中也称为神经网络加速器或NNA)包括以下固定功能硬件单元:
●一组卷积引擎240,专门用于卷积运算;
●逐元素运算单元285,专门用于对具有对应大小的两个张量的每对相应元素执行相同的运算;
●激活单元255,专门用于将激活函数(可以是可选择的、可配置的或完全可编程的)应用于张量的每个元素;
●局部响应归一化(LRN)单元265(或简称为归一化单元),专门用于执行基于邻域的归一化运算;以及
●池化单元275,专门用于执行池化运算,诸如最大池化和最小池化。
更详细地,硬件加速器200包括数字逻辑电路系统,该数字逻辑电路系统被配置为接收数据(包括权重和输入张量)以及用于处理数据的命令。硬件加速器200包括存储器接口210、输入缓冲器控制器215、命令解码器220、系数缓冲器控制器225、系数缓冲器230、n输入缓冲器235、n卷积引擎240、n累加器245、累积缓冲器250、激活单元255、局部响应归一化(LRN)单元265、共享缓冲器270、池化单元275,以及逐元素运算单元285。硬件加速器200可用于评估基本神经网络运算。
存储器接口210被配置为提供硬件加速器200和外部存储器25(未在图2中示出,但在例如图4中示出)之间的接口。外部存储器25可被视为与硬件加速器200分开的模块。命令或配置信息可包括例如关于权重和数据大小和格式以及它们在外部存储器中的位置的信息。
存储器接口210被配置为从外部存储器25接收待在神经网络内的计算中使用的权重和数据以及用于控制硬件加速器200的运算的命令信息。所接收的权重(在本文中也称为系数)被传递到系数缓冲器控制器225,并且所接收的数据被传递到输入缓冲器控制器215。所接收的命令被传递到命令解码器220,该命令解码器继而被配置为对命令进行解码并且随后将控制信息发布到硬件加速器的元件,包括系数缓冲器控制器225和输入缓冲器控制器215,以控制权重和输入数据存储在缓冲器中的方式。
在读取外部存储器期间经由存储器接口210从外部存储器接收的权重和输入数据可形成单个层的仅一部分的权重和输入数据,所有权重和输入数据待用于处理单个层,或者可包括用于处理多个层的权重和输入数据。
在实践中,在从外部存储器25的单次读取中接收的权重和数据的数量将取决于系数缓冲器230和输入缓冲器235的大小。权重从系数缓冲器控制器225传递到系数缓冲器230,并且所接收的数据从输入缓冲器控制器215传递到多个输入缓冲器235a至235n。输入缓冲器的数量将取决于加速器200的具体实施,但可以取任何值。输入数据跨所有输入缓冲器235a至235n共享。输入缓冲器各自形成有效的存储库(bank),使得输入缓冲器的数量可以根据应用而增加或减少。
输入缓冲器235a至235n连接到多个多路复用器中的每一个多路复用器,因为每个卷积引擎240a至240n需要访问输入数据的所有有效的“存储库”。多路复用器各自被配置为从输入缓冲器235中的一个输入缓冲器选择输出,并且将从所选择的输入缓冲器235输出的值传递到相应的卷积引擎240a至240n。另外,来自系数缓冲器230的权重作为第二输入提供到每个卷积引擎240a至240n中。卷积引擎240被配置为使用从系数缓冲器230接收的权重对所接收的输入数据执行卷积计算。每个卷积引擎240a至240n的所得输出作为输入提供给多个累加器245a至245n的相应累加器。
每个累加器245a至245n连接到累积缓冲器250。累积缓冲器250被配置为存储从每个累加器245a至245n接收的累积结果。累积缓冲器250连接到存储器接口210。因而,累积缓冲器250被配置为经由存储器接口210将数据发送到外部存储器25以及从该外部存储器接收数据。具体地,累积缓冲器250被配置为能够经由存储器接口210存储并且从外部存储器25恢复其值,如下文将更详细描述的。累积缓冲器250连接到累加器245a至245n的输入,并且被配置为将值馈送回累加器245a至245n中,以使得能够进行累加计算。
累积缓冲器250被配置为将累积值传递到激活单元255和/或逐元素运算单元285。激活单元255被配置为执行多个不同激活函数中的至少一个激活函数。
由激活单元255计算出的所得值可以经由共享缓冲器270传递给LRN单元265和/或池化单元275进行处理。LRN单元265被配置为执行局部响应归一化。这可以在输入数据的单个平面内执行。替代地或另外,LRN运算也可以跨平面执行。
存储在共享缓冲器270中的结果被传递到存储器接口210,该存储器接口可将结果存储在外部存储器25中或者将结果传递回输入缓冲器以供进一步处理,而不必首先传递到外部存储器。
共享缓冲器270被配置为缓冲来自激活单元255、LRN单元265、池化单元275和逐元素运算单元285中的任何一者或多者的值,直到执行下一运算所需的所有值可用。以此方式,共享缓冲器270用于提高存储效率,因为它可以保持在稍后的运算中需要的值而不必使用外部存储器25。
逐元素运算单元285包括被配置为对从累积缓冲器250和/或激活单元255接收的张量执行逐元素运算的电路系统。支持的逐元素运算可包括张量的相应元素的逐元素加法、减法、乘法、除法和最大值(或最小值)。
逐元素运算是对至少一个张量的多个元素重复的运算。通常针对张量的所有元素重复所述运算。可以考虑两类逐元素运算:具有单个运算元的一元运算和具有两个运算元的二元运算。逐元素运算单元285处理二进制逐运算运算。硬件加速器的其他部件也可以执行逐元素运算。例如,激活单元255可以通过将函数应用于张量的每个元素来执行一元逐元素运算。
虽然图2的硬件加速器示出了布置单元的特定顺序以及硬件实施中的数据处理方式,但应当理解,所需特定计算和跨层处理数据的顺序可以变化。
在评估神经网络层的一些示例中,可以全部执行由激活255、LRN 265、池化275和逐元素285单元执行的功能。在其他示例中,可以仅执行这些函数中的一些函数,并且不一定按照硬件加速器200中列出的顺序执行。为了实现处理这些函数的可配置顺序,激活单元255、LRN单元265、池化单元275和逐元素单元285中的每一者可被配置为接收将单元配置成旁路模式的控制信令,在所述旁路模式中不执行函数,并且输入值仅传递通过单元而不发生变化。
有利地,由于激活、LRN、池化和逐元素单元255、265、275、285线性放置,因此可能顺序地执行这些运算,而不必从外部存储器25检索数据。在一些实施中,激活、LRN、池化和逐元素单元255、265、275、285的连接顺序可以变化。例如,激活、LRN和池化单元255、265、275可以反向连接,使得池化单元连接到累积缓冲器250,并且激活单元连接到存储器接口210。
图3示出了图2中的卷积引擎240中的每一者的结构。卷积引擎240包括乘法逻辑242的多个元素,每个元素被配置为将权重乘以输入数据元素,以及加法逻辑244的多个元素,以树结构配置以对乘法逻辑242的元素的输出求和。
示例性数据处理系统
图4是根据一个示例的用于在硬件加速器200(NNA)中实施基于注意力的神经网络的数据处理系统10的框图。数据处理系统包括硬件加速器200;映射单元12;存储器25;以及存储器操纵模块(MMM)40。至少硬件加速器200、存储器25和MMM 40通过数据总线30连接。映射单元12被配置为接收神经网络的定义,并且将其映射到可由硬件加速器200本地执行的基本神经网络运算图。映射单元12还被配置为控制硬件加速器200(以及如果需要的话,MMM40)以通过这些基本运算来评估固定功能硬件中的基于注意力的神经网络。作为其映射职责的一部分,映射单元12被配置为填充用于基于注意力的神经网络的每个输入序列,以产生适当的预先确定的固定长度的相应填充输入序列。如上所述,映射单元还被配置为生成适当固定长度的填充掩码,从而标识每个输入序列的包含填充值的部分,并且被配置为从填充掩码生成注意力掩码。
硬件加速器200被配置为处理每个填充输入序列和相关注意力掩码,以使用基于注意力的神经网络来执行推断。特别地,硬件加速器200被配置为评估由映射单元12输出的基本神经网络运算图。MMM 40被配置为以各种方式操纵存储器中的多维数据,包括修改数据维度顺序的置换运算。在一些示例中,MMM 40可被配置为通过在宽度维度或高度维度中的一者或两者中重新排列数据的通道维度,或者将通道维度与这些空间维度中的一者或两者交换来变换数据。在替代示例中,MMM可以置换输入数据的维度的任何其他组合,包括批量维度。从维度[B,C,H,W]到维度[B,1,HC,W]的变换是在空间维度中重新排列通道维度的一个示例。从维度[B,C,H,W]到维度[B,C/KL,HK,WL]的变换是另一种此类示例(其中K和L是整数)。从维度[B,C,H,W]到维度[B,H,C,W]的变换是将通道维度与空间维度中的一者交换的示例。
图5是图4中使用的MMM 40的框图。如已经提到的,MMM 40经由总线30耦合到存储器25。MMM 40包括存储器读取块420;内部缓冲器410;以及存储器写入块430。控制通道440用于协调存储器读取块420和存储器写入块430执行的运算。存储器读取块420和存储器写入块430两者耦合到总线30。存储器读取块420的输出耦合到内部缓冲器410的输入。存储器写入块430的输入耦合到内部缓冲器410的输出。
存储器读取块420从存储器25读取数据。存储器读取块420将(从存储器25读取的)数据写入内部缓冲器410。存储器写入块430从内部缓冲器410读取数据并且将(从内部缓冲器410读取的)数据写回到外部存储器25。通过存储器读取块420和存储器写入块430执行的运算的组合,可以用前述方式变换数据。变换可以在将数据从存储器25移动到内部缓冲器410时发生,或者可以在将数据从内部缓冲器410移动到存储器25时发生。在一些情况下,变换可以部分地发生在存储器25和内部缓冲器410之间,部分地发生在内部缓冲器410和存储器25之间。
在存储器读取块420和存储器写入块430被提供为单独的硬件块(如图4的示例中)的情况下,它们可能能够并行操作。控制通道240提供存储器读取块220和存储器写入块230之间的通信,以保持两个块之间的同步。例如,该同步可以确保存储器写入块430在数据被存储器读取块420写入之前不尝试从内部缓冲器410读取数据。类似地,可以确保存储器读取块420在内部缓冲器410中的数据被存储器写入块430从该内部缓冲器读取之前不会覆盖该数据。
示例性数据处理方法
图6A是示出根据一个示例的使用基于注意力的神经网络来实施推断的方法的流程图。使用图4的数据处理系统来执行该方法。在本示例中,基于注意力的神经网络是包括编码器和解码器的变换器网络(也参见上文对图1A至图1C的描述)。
在步骤511中,映射单元12接收用于编码器的第一输入序列。在步骤512中,映射单元12填充第一输入序列以产生第一固定长度的第一填充输入序列。此第一固定长度已针对编码器堆栈预先选择(例如,在较早的训练阶段中)。在步骤513中,映射单元12生成对应于第一填充输入序列的第一填充掩码。在本示例中,映射单元12通过在填充位置中用零填充第一输入序列来产生第一填充输入序列。第一填充掩码对应于填充位置包含零以及在对应于(可变长度)第一输入序列的位置中包含一。在步骤514中,如上所述,映射单元12基于第一填充掩码与其自身的外积构建用于编码器的第一(自我)注意力掩码。第一注意力掩码对应于填充位置包含大负值,以及在对应于(可变长度)第一输入序列的位置中包含零。大负值都具有相同的值。在训练阶段,预先离线选择特定值。根据本示例,结合一组用于推断处理的数字格式来选择该特定值,使得当该特定值以所选择的数字格式作为输入应用于指数函数f(x)=e
对解码器执行类似的步骤序列。在步骤521中,映射单元12接收用于解码器的第二输入序列。这也具有可变长度。通常,它与用于编码器的第一输入序列的长度不同。(在一些示例中,当使用基于注意力的神经网络来执行推断时,第二输入序列最初可包括单个“开始”标记。)
在步骤522中,映射单元12用填充值(在此示例中为零)填充第二输入序列,以产生第二固定长度的第二填充输入序列。如同第一固定长度,第二固定长度可在训练阶段中预先离线选择。意图是第一固定长度和第二固定长度被选择为足够长,使得所有期望的输入序列(分别用于编码器和解码器)小于或等于相应固定长度。
在步骤523中,映射单元12生成对应于第二填充输入序列的第二填充掩码。类似地,对于编码器采用的方法,映射单元12通过在填充位置中放置零来产生用于解码器的第二填充输入序列。第二填充掩码对应于填充位置包含零以及在对应于(可变长度)第二输入序列的位置中包含一。在步骤524中,映射单元12基于第二填充掩码与其自身的外积构建用于解码器的第二(自我)注意力掩码。第二注意力掩码在对应于填充位置的位置中包含大负值,以及在对应于原始(可变长度)第二输入序列的位置中包含零。类似于编码器采用的方法,大负值都具有相同的值,选择该值使得在相关的数字格式中f(x)=e
在图6A所示的示例中,变换器网络包括编码器和解码器两者。因此,解码器使用两个注意力掩码。第一个是自我注意力掩码(上述的第二注意力掩码),其用于块111中的多头自我注意力计算中。第二个是交叉注意力掩码,其用于块161中的多头交叉注意力计算中。如上文已经解释的,交叉注意力掩码具有由第一固定长度定义的一个维度和由第二固定长度定义的另一个维度。自我注意力掩码的维度由第二固定长度决定。(应当理解,在其他示例中,如果变换器网络仅包括解码器而不包括编码器,则移除块161和171,并且不需要交叉注意力掩码。)
在步骤525中,映射单元生成交叉注意力掩码。相对于编码器输出,交叉注意力掩码控制解码器可注意和忽略第二输入序列的哪些元素。为了生成交叉注意力掩码,映射单元12计算第一填充掩码(在步骤513中生成)与第二填充掩码(在步骤523中生成)的外积。随后映射单元12取外积的结果,用大负值替换所有的零,并用零替换所有的一。因此,交叉注意力掩码在对应于允许注意的元素/标记的位置处具有零,并且在对应于将被交叉注意力计算忽略的元素/标记的位置处具有大负值。特别地,对应于第一填充输入序列或第二填充输入序列中的填充值的交叉注意力掩码中的位置被设置为大负值。
还可基于外部输入来修改各种注意力掩码。这些外部输入可指定在计算中应当忽略(即,不注意)填充输入序列的特定附加元素。这允许注意力计算忽略原始(可变长度)输入序列中存在的元素。通过将每个自我注意力掩码和交叉注意力掩码中的附加位置设置为大负值,可忽略指定的附加元素。这可以通过直接修改注意力掩码来完成。或者,这可以通过将第一和/或第二填充掩码的附加元素设置为零来完成。在从填充掩码生成注意力掩码之后,这将导致附加的大负值。(为了简单明了,这些步骤没有在图6A中示出。)
应当理解,自我注意力掩码和交叉注意力掩码包含对应于已经“可用”的元素(例如,单词标记)的零,以及用于剩余元素的由第二固定长度定义的数量的大负值。区分与填充相关的大负值和与在注意力计算中要“忽略”的元素相关的大负值不是必要的,并且在某些情况下不是特别有意义。在许多情况下,直到推断完成,才知道解码器的可变长度输入/输出序列将增长到什么长度。第二输入序列的“长度”仅由来自解码器的输出序列的长度定义,并且不能预先知道。在每次迭代结束时,解码器的输出被反馈到输入,以用于下一次迭代。因此,例如,在第二次迭代之后,第二填充输入序列可包括两个单词标记——一个在第一次迭代中产生,另一个在第二次迭代中产生。第二填充输入序列的剩余部分包括零,并且第二填充掩码中对应于这些填充零的位置包含零,而第二(自我)注意力掩码和交叉注意力掩码中的对应位置包含大负值。输出序列(并且因此输入序列)的长度可继续增长,直到已经达到预先确定的迭代次数——例如,迭代次数等于第二填充输入序列的第二固定长度(中的元素数),或者直到解码器输出终止标记,从而停止处理并防止任何进一步的迭代。
在步骤530中,硬件加速器200的固定功能硬件处理第一填充输入序列、第二填充输入序列、第一(自我)注意力掩码、第二(自我)注意力掩码和交叉注意力掩码,以使用基于注意力的神经网络来执行推断。通过编码器100处理第一填充输入序列和第一(自我)注意力掩码;通过解码器150处理第二填充输入序列、第二(自我)注意力掩码和交叉注意力掩码。
应当理解,并非变换器网络的所有示例都包括编码器堆栈和解码器堆栈两者。一些示例仅包括编码器堆栈;一些示例仅包括解码器堆栈。在包含或包括解码器堆栈的示例中,解码器堆栈可迭代多次,或者仅执行一次。具体配置将取决于由变换器网络执行的任务。
因为固定长度基于训练数据选择,所以有可能在推断阶段中出现比训练序列中的任何训练序列都长并且因此比相关的固定长度长的输入序列。图6B是示出能够响应这种可能性的方法的流程图。在步骤542中,映射单元12接收另一输入序列。在步骤544中,映射单元12确定此另一输入序列的长度。在步骤545中,映射单元12标识在步骤544中确定的长度大于相关的固定长度(在具有编码器的输入序列的情况下是第一固定长度;在用于解码器的输入序列的情况下是第二固定长度)。作为响应,在步骤546中,映射单元加载另一基于注意力的神经网络的表示。此另一网络与另一固定长度相关联,该另一固定长度足够长以适应另一输入序列的长度。即,另一固定长度大于或等于另一输入序列的长度。在一些示例中,映射单元12可从机载存储器25获得另一基于注意力的神经网络的表示。存储器可存储像这样的不同神经网络的阵列,这些神经网络被训练用于本质上相同的任务,但是在它们施加于输入序列上的固定长度方面不同。当映射单元发现当前加载的网络不能适应输入序列时,它可以加载具有更长固定长度参数的不同(但相关的)网络。在一些示例中,映射单元12可从外部源获得另一基于注意力的神经网络的表示,而不是从机载存储器25获得它。例如,映射单元可被配置为经由诸如无线LAN或蜂窝数据网络的通信网络从远程服务器下载该表示。
在加载另一基于注意力的神经网络之后,映射单元继续用填充值填充另一输入序列,以产生另一固定长度的另一填充输入序列。它还生成另一填充掩码和一个或多个另一注意力掩码(取决于网络的结构)。另一填充掩码标识另一填充输入序列的包含填充值的部分。从另一填充掩码生成至少一个另一注意力掩码。硬件加速器的固定功能硬件处理另一填充输入序列和一个或多个另一注意力掩码,以使用另一基于注意力的神经网络来执行推断。根据一个示例,这些步骤类似于图6A的步骤511、512、513、514和530。应当理解,另一基于注意力的神经网络将具有与其替换的神经网络相同的结构。这可能是任何基于注意力的神经网络。特别地,另一基于注意力的神经网络可仅包括编码器堆栈;或者仅包括解码器堆栈;或者包括编码器堆栈和解码器堆栈两者。在后一种情况下,另一基于注意力的神经网络将被设计成对分别用于编码器和解码器的第一和第二另一输入序列进行运算。这些将被填充到相应的第一和第二另一固定长度,它们中的一者或两者可不同于先前加载的基于注意力的神经网络中使用的第一和第二固定长度。在这种情况下,一个或多个另一注意力掩码将包括:用于另一第一输入序列的另一第一(自我)注意力掩码;用于另一第二输入序列的另一第二(自我)注意力掩码;以及另一交叉注意力掩码。
如果(在步骤545处)另一输入序列的长度小于或等于与当前加载的网络相关联的固定长度,则不需要加载不同网络的表示。该方法反而从步骤545前进到步骤548,从步骤548,该方法正常地继续到步骤512和/或522。
(批量)矩阵乘法
如上文已经解释的,在每次SDPA计算中出现两次(批量)矩阵乘法(见块192和198)。SDPA计算的多个实例存在于块110、111和161的每一个块中。网络中的其他地方也会重复出现乘法。例如,前馈块130和131中的前馈层是完全连接的层,其使用(批量)矩阵乘法来实施。因此,期望在硬件加速器中尽可能有效地实施这种批量矩阵乘法。
单矩阵乘法具有以下形式:
Z=XY
在该等式中,X是维度为[P,Q]的矩阵,并且Y是维度为[Q,R]的矩阵。输出Z是维度为[P,R]的矩阵。将矩阵视为4-D张量,X的维度为[1,1,P,Q],Y的维度为[1,1,Q,R],并且Z的维度为[1,1,P,R]。
在此处,数据张量采用“NCHW”符号,其中N是批量数,C是通道数量,H是高度,并且W是宽度。同样,权重/系数采用“OIHW”符号,其中O是输出通道数量,I是输入通道数量,H是内核高度,并且W是内核宽度。
矩阵乘法的任务可以推广到批量矩阵乘法,该批量矩阵乘法涉及在同一运算中执行多个矩阵乘法。对于批量矩阵乘法,允许上文定义的4-D张量的两个前导维度的大小大于1。因此,更一般的形式是维度为[M,N,P,Q]的张量X和维度为[M',N',Q,R]的张量Y。这表示(max(M,M′)max(N,N′))在同一运算中执行的大小为[P,Q]和[Q,R]的矩阵之间的相应乘法。
应当理解,上述批量矩阵乘法的定义适用于大于二的任何数量的维度。换句话讲,4-D张量的选择并不特别或重要,只是为了便于解释。一般来讲,可存在任何数量的维度。矩阵乘法在两个维度上执行,其余维度(通常称为“批量”维度)都具有匹配的大小(或具有等于1的大小,在这种情况下暗示广播)。将采用符号[...,P,...,Q,...]和[...,Q,...,R,...]来指示以上述方式匹配M、N、M'和N'的任何数量的附加维度,其中两个维度需要进行矩阵乘法。在该符号中,附加维度可以位于以下位置中的一者或多者中:进行矩阵乘法的两个维度之前、之间和之后。两个输入张量中大小为Q的维度可被称为“内部”维度。在此,为了示例的简单性并且不失一般性,将假设矩阵乘法是在最后两个维度上执行的。因此,示例中的张量将具有维度[...,P,Q]和[...,Q,R]。然而,应当理解,这并非旨在进行限制。
现有的神经网络加速器(NNA)硬件通常专门用于评估卷积层,并且可能本身不支持矩阵乘法。例如,上文参照图2描述的示例性NNA适用于在多个处理元件240处并行地将同一组权重同时乘以多组输入数据元素。卷积神经网络(CNN)中的大部分计算用于运算诸如卷积,这些运算需要在多组输入数据中应用相同的系数(权重)。出于这个原因,一些神经网络加速器专门用于这种运算。在某些情况下,此类NNA本身可能不支持矩阵乘法;在其他情况下,由于硬件的设计方式,可能支持矩阵乘法,但效率相对较低。
上文所讨论的示例性硬件加速器不适合矩阵乘法和批量矩阵乘法的直接评估。根据本公开的各方面,这些运算相反地被映射到示例性硬件加速器上直接支持的其他运算。根据硬件加速器的架构和能力,可以采用不同的方法。例如,在某些硬件加速器中,软件或硬件可能仅支持使用恒定权重(系数)的卷积,并且可能不支持动态权重。当希望将两个动态数据矩阵相乘时,这将限制使用基于卷积的方法(参见下文)。
面对在使用神经网络加速器(NNA)的系统中实施矩阵乘法的期望,一种可能性是设计专门用于评估矩阵乘法的专用固定功能硬件模块。然后可以将该硬件模块包括在NNA中,其中它将负责根据需要评估涉及矩阵乘法的任何层。
另一种替代方法是在NNA之外的通用硬件诸如通用CPU或DSP中评估矩阵乘法。
在NNA中提供专用固定功能硬件模块可以实现优化的快速评估。然而,其缺点是专用固定功能硬件模块在集成电路中占用附加的面积。该区域将处于非活动状态,除非被要求评估矩阵乘法。
同时,在通用硬件中评估矩阵乘法具有灵活性,并且避免使NNA的大面积得不到充分利用;然而,由于硬件的专业化程度较低,其效率通常较低。
另外,当使用NNA外部的通用硬件时,将必要的数据从NNA传输到通用硬件(例如,CPU)将产生开销。这通常涉及在评估矩阵乘法之前,NNA将数据写入存储器,以及CPU从存储器中读取数据。这有可能会减慢矩阵乘法的计算速度,特别是在(通常情况下)存储器访问速度占主导地位的情况下。此外,由于操作系统和其他正在运行的进程的要求,CPU时间通常非常宝贵。花费CPU时间来评估矩阵乘法可导致这些其他进程变慢并且资源使用效率低下。GPU和DSP也是如此。
根据本公开的示例基于在示例性NNA上可用的基本神经网络运算,提供了在硬件中实施矩阵乘法(包括批量矩阵乘法)的方法。这些基本神经网络运算包括逐元素运算、变换和卷积。映射单元12被配置为将(批量)矩阵乘法映射到基本神经网络运算图。硬件加速器被配置为评估基本神经网络运算图,以评估(批量)矩阵乘法运算。此图可包括(a)至少一个卷积运算或(b)至少一个逐元素运算。在硬件加速器200中的固定功能硬件中评估至少一个卷积运算或至少一个逐元素运算。
现在将更详细地描述实施矩阵乘法运算的方式的各种示例。在不失一般性的情况下,在这些示例中,假设批量大小B=(max(M,M′)max(N,N′))=MN,使得M>=M’并且N>=N'。然而,应当理解,这并不限制范围。如果批量大小与此不同(例如,如果M’>M并且/或者N’>N),则算法将只需要对对应的张量进行复制和/或置换和/或重塑。图7至图11示出了第一组示例。这些示例依赖于卷积运算来评估矩阵乘法运算。
在图7所示的计算图中,用于实施矩阵乘法的神经网络运算700的图包括卷积730和应用于卷积的输入和输出的变换710、720、740。第一张量X将为卷积提供数据张量;第二张量Y将为卷积提供权重。对第一张量X应用第一置换运算710。该置换运算将X的维度从[1,1,P,Q]重新排列为[1,Q,1,P]。大小为Q的宽度维度放置在通道维度中;并且大小为P的高度维度放置在宽度维度中。
在本发明的实施中,对于数据张量X优选地使用大于1的宽度维度,因为硬件加速器200被配置为在执行卷积时在宽度维度上并行,例如通过处理跨卷积引擎240的相邻窗口。在另一个实施中,硬件加速器可以被配置为在高度维度上并行。在这种情况下,相反地,将高度维度留在适当位置可能是有利的,使得重新配置的第一张量将具有维度[1,Q,P,1]。
对第二张量Y应用第二置换运算720。该运算将Y的维度从[1,1,Q,R]重新排列为[R,Q,1,1]。因此,大小为Q的高度维度被放置在输入通道维度中。大小为R的宽度维度被放置在输出通道维度中。第一置换运算和第二置换运算是第一变换的示例,用于在执行乘法计算之前准备输入数据。
然后可以通过1x1卷积730来实施矩阵乘法,使用重新配置的第一张量X作为数据,并且使用重新配置的第二张量Y作为权重。卷积730具有R滤波器、Q输入通道、步长1并且无填充。该卷积的输出将具有维度[1,R,1,P]。对此应用第三置换运算740,以将维度恢复到对应于原始输入X和Y的配置。在置换740之后,矩阵乘法的结果Z具有维度[1,1,P,R]。第三置换运算是第二变换的示例,应用于乘法计算的结果,用于恢复数据,使得维度处于所需的顺序。通常,这将匹配输入数据的维度的排序。应当理解,在某些情况下可以消除第二变换(第三置换运算740)。特别地,如果神经网络包括两个连续的矩阵乘法,则这些矩阵乘法的第一矩阵乘法中的卷积730的输出可以直接传递到第二个矩阵乘法中的卷积730的输入(也消除了第二矩阵乘法中的第二置换运算710)。实质上,第一矩阵乘法中的第三置换运算740和第二矩阵乘法中的第一置换运算710相互抵消。以此方式,第一置换运算710可仅在连续矩阵乘法序列开始时执行,并且第三置换运算可仅在该序列结束时执行。
图8扩展了图7的方法以构建用于实施批量矩阵乘法的神经网络运算图800。图8中采用的方法是将批量矩阵乘法拆分成单独的矩阵乘法,并且使用图7的方法来实施每个单独的矩阵乘法。维度为[M,N,P,Q]的第一张量X被拆分820成MN组成矩阵,每个组成矩阵的维度为[1,1,P,Q]。对于第二张量Y,如果需要广播(即,如果M'=1并且/或者N'=1),则重复Y的相关维度,使其具有形状[M,N,Q,R]。第二张量Y被拆分成MN组成矩阵,每个组成矩阵的维度为[1,1,Q,R]。使用图7所示的计算图中的神经网络运算700的图将相应的组成矩阵对各自相乘。这些中的每一者将矩阵乘法实施为卷积730,并且产生维度为[1,1,P,R]的相应张量。如果涉及广播,那么这可以通过将相同的组成矩阵馈送给运算700的多个实例来处理。MN运算的结果然后被连接840,以生成具有维度[M,N,P,R]的批量矩阵乘法的结果。
图9示出了依赖于图7至图8的方法的一个具体实例。在维度为[MN=2,P=4,Q=3]的第一张量X和维度为[MN=2,Q=3,R=5]的第二张量Y之间执行批量矩阵乘法。在此,在不失一般性的情况下,只考虑单个维度M和N的组合大小MN。该方法以相同的方式起作用,而不管M=1并且N=2,还是M=2并且N=1。第一张量X被拆分810成两个张量,每个张量的维度为[1,1,4,3]。这些中的每一者被置换710成维度为[1,3,1,4]的第一重新配置的张量。第二张量Y被拆分820成维度为[1,1,3,5]的两个张量,每个张量被置换720成维度为[5,3,1,1]的第二重新配置的张量。每个第一重新配置的张量(充当数据)与相应的第二个重新配置的张量(充当权重)进行卷积730,以产生维度为[1,5,1,4]的输出。这些被置换740为具有维度[1,1,4,5]并且连接840以产生维度为[MN=2,P=4,R=5]的输出张量Z。
图10示出包括神经网络运算图的计算图,神经网络运算提供实施批量矩阵乘法的另一种方式,该方式使用分组卷积。图11示出了应用该方法的具体实例。第一输入张量X(具有维度[M,N,P,Q])被置换910为维度为[M,N,Q,P]的张量。然后将其重塑912为维度为[1,MNQ,1,P]的张量。第二输入张量Y(具有维度[M',N',Q,R])被置换920为维度为[M',N',R,Q]的张量,然后被重塑922为维度为[M'N'R,Q,1,1]的张量。如果需要广播(即,如果M'=1并且/或者N'=1),则可以通过在Y中适当地重复相关维度从而使其具有形状[MNR,Q,1,1]来实施。然后使用第一重新配置的张量[1,MNQ,1,P]作为数据并且第二重新配置的张量[MNR,Q,1,1]作为权重,执行分组卷积930。存在各自具有Q通道的MN组。这会产生维度为[1,MNR,1,P]的张量,该张量首先被重塑940为具有维度[M,N,R,P],然后被置换950以产生维度为[M,N,P,R]的输出张量Z。为了便于比较,图11中的具体实例使用了维度与图9中的维度相同的输入张量X和Y。如果批量矩阵乘法是连续乘法序列的一部分,则可能不需要最终置换运算950。以与上文针对图7讨论的方式类似的方式,序列中下一批量乘法的初始置换910有效地与前一批量乘法的最终置换950相抵消。
存在各种替代方法可以实施矩阵乘法运算。图12至图13示出了第二组示例。这些示例依赖于逐元素运算来评估矩阵乘法运算。
图12示出了根据一个示例的用于使用逐元素乘法实施批量矩阵乘法的计算图。对于第二张量Y,如果需要广播(即,如果M'=1并且/或者N'=1),则重复Y的相关维度,使其具有形状[M,N,Q,R]。将置换运算1110应用于第二张量Y,以将其重新配置为具有维度[M,N,R,Q]的第三张量。然后,第三张量沿高度维度被拆分1120成R组成张量,每个组成张量的维度为[M,N,1,Q]。在这些R组成张量中的每一者和第一张量X之间执行逐元素乘法1130。回想第一张量X具有维度[M,N,P,Q];因此,这种元素逐位乘法涉及至少在高度维度上广播。替代地,在逐元素乘法之前,可以在高度维度上显式复制组成张量P次。逐元素乘法1130的输出由R张量组成,每个张量具有维度[M,N,P,Q]。这些张量沿宽度维度连接1140,从而产生维度为[M,N,P,RQ]的张量。接下来,连接张量被置换1150以将其重新配置为维度为[M,RQ,N,P]的张量。实质上,该运算将逐元素乘法的结果沿通道轴排列在大小为Q的R组中。下一个任务是对每组Q通道求和。在本发明的示例中,这借助于分组卷积1160,使用完全由1组成并具有维度[R,Q,1,1]的权重张量来完成。该分组卷积1160的输出具有维度[M,R,N,P]。在最后一步,该张量被置换1170以将其重新配置为输出Z,维度为[M,N,P,R]。
图13示出了基于图12中的计算图的矩阵乘法的实际实例。需注意——与图12相反——在图13中,箭头表示运算,并且张量表示为块。在该示例中,第一张量X具有维度[1,1,4,3]并且第二张量Y具有维度[1,1,3,5]。在步骤1110中,第二张量被置换以产生维度为[1,1,5,3]的第三张量。在步骤1120中,该第三张量被拆分成5个组成张量,每个组成张量的大小为[1,1,1,3]。在步骤1130中,将5个组成张量中的每一者逐元素乘以第一张量X。这会产生5个相应的张量,每个张量的维度为[1,1,4,3]。这些在步骤1140中沿水平(宽度)维度连接,以产生维度为[1,1,4,15]的连接张量。宽度维度现在包含5组,每一组4行,每一行有3个元素。连接张量被置换1150以将其重新配置为具有维度[1,15,1,4]。(需注意,该步骤未在图13中示出。)使用维度为[5,3,1,1]的权重张量对该张量执行分组卷积1160,以对3的组求和。该求和/分组卷积的结果具有维度[1,5,1,4]。将其置换1170以产生最终输出Z,其维度为[1,1,4,5]。
需注意,前面示例中使用的分组卷积只是根据需要对元素分组求和的一种方法。可能通过其他方式实施该步骤。例如,从维度为[1,1,4,15]的连接张量开始,可以改为与一行1[1,1,1,3]进行卷积运算,在水平方向上使用步长3,并且将其应用于实施求和。
尽管图13示出了应用于单矩阵乘法(M=N=1)的神经网络运算图,但该方法是通用的,也适用于批量矩阵乘法(MN>1),无需修改。
MMM可以根据需要用于实施各种置换、重塑、拆分和连接运算。可以使用逐元素运算单元285来实施逐元素运算。可以使用卷积引擎240来执行卷积(包括分组卷积)。以此方式,神经网络运算图中的所有神经网络运算可以在固定功能硬件中实施。
Softmax
如上文已经解释的,Softmax计算出现在SDPA计算的每个实例中。此外,尽管在图1A和图1B中没有明确示出,但在编码器堆栈或解码器堆栈的输出处的预测头可包括线性投影和另一Softmax。此Softmax可用于分类,例如,以从类别概率向量中标识最可能的类别。
对于值集或值向量中的任何值x
为了去掉下标符号,该等式可以用向量x重写:
Softmax将范围(-∞,+∞)内的输入值映射到范围[0,1]内的输出。此外,输出值的总和为1(如离散概率分布所需的)。
已知,如果输入值x的量值很大,则softmax层的评估可能会遇到数值不稳定问题。输入x可具有如此大的正值以至于在指数e
至少其中一些问题的解决方案是从张量(或向量)x中的所有值中减去最大值:
其中,M=max(x)。此重新定义的层与上述定义相同,但数值上更稳定。减去最大值将输入范围从(-∞,+∞)减小到(-∞,0],但不影响结果。
面对使用神经网络加速器(NNA)来实施softmax层的期望,类似的考虑适用于上文所讨论的矩阵乘法运算。使用本地支持的基本运算来实施该运算比潜在的替代可能性中的每种可能性都有优势。
根据本公开的示例基于示例性NNA上可用的基本神经网络运算,提供了在硬件中实施softmax层的方式。Softmax层可以被视为如图14A所示的计算图,并且图中的各个运算都可以替换为NNA硬件中的一个或多个运算。然后,可以由NNA评估包含这些替换运算的图。
根据本公开的示例使用由固定功能硬件单元执行的基本神经网络运算来实施softmax层。在本发明的实施中,计算以定点算术法执行。实验表明,定点实施足够准确,不会显著降低所测试的示例性神经网络的整体准确度。
Softmax层可以由以下运算构成:
● 最大运算;
● 减法;
● 实施函数f(x)=e
● 求和;以及
● 除法。
对于这些运算中的每一个运算,可能有不止一种方法可以重组运算以在硬件加速器上执行。下文将依次更详细地解释这些运算。
图14A是示出示例性NNA中可用的运算如何可用于实施softmax层的计算图。在该示例中,将考虑示例性输入张量x,该张量具有批量、高度、宽度和通道维度。在该示例中,假设将在输入的通道维度上评估softmax层。应当理解,可以在一个或多个其他维度上评估softmax层,并且它可以应用于具有以任何方式排序的任意数量维度的张量。
首先,对输入张量x进行最大运算2110。该运算在待评估softmax层的一个或多个维度上执行。在逐通道softmax的当前示例中,该运算沿通道维度执行。在一个或多个不同维度上评估softmax层的情况下,最大运算2110将改为沿所述那个或多个不同维度执行。最大运算2110返回x内相关维度上的最大正值,以产生最大值M的张量。在也被称为第一减法的减法运算2120中,从张量x的相应元素中减去最大值的张量M。(这可以使用广播来实施,如下文进一步详细讨论的)。该减法运算2120产生负移张量x-M。负移张量输入到指数运算2130。该计算将负移张量的每个元素应用为欧拉数e的幂。指数运算2130产生指数值的张量,在本文中称为指数张量e
图14B是示出示例性NNA中可用的运算如何用于实施指数运算2130的示例的计算图。根据该示例,指数运算2130包括以下运算:
●求反2132;
●S形函数2134;
●倒数运算2136;以及
●第二减法2138。
继续图14A的示例,指数运算2130的输入为负移张量x-M。该张量进行求反2132以产生求反的张量-(x-M)。求反2132可以多种方式实施—例如,通过从0中减去负移张量,或通过从其自身减去负移张量两次。取反的张量被输入到S形函数2134,该S形函数为取反的张量的每个元素确定S形值。S形函数2134的输出是S形求反值σ(-(x-M))的张量。对S形求反值的张量进行倒数运算2136,确定S形求反值中的每一个S形求反值的倒数。S形运算2136返回倒数S形值
将参考图15A、图15B、图15C和图16来解释最大运算2110的两个可能的实施。如参考图14A和图14B所解释,并且同样如图15A和图16所示,最大运算2110接收输入张量并且返回通道维度上的元素的最大值。以通道维度作为示例,因为softmax最常应用于通道维度。然而,应当理解,本公开的范围不限于该示例。
最大运算2110可被实施:
在池化单元275中;或者
,在逐元素运算(EWO)单元285中。
这些单元可以通过例如在存储器操纵模块40中执行的转置或置换运算来辅助。
图15B示出了使用EWO单元285的最大运算2110的实施。可以使用成对最大运算的迭代序列。输入张量在正在计算softmax的维度(本发明示例中的通道维度)上分为600两半,并且使用逐元素最大运算610来比较这两半。对于比较的每对元件,将两者中较高的(即,最大值)作为逐元素最大值610的结果输出。该运算的结果是大小为原始大小的一半的张量。这本身被分成两部分,并且使用另外的元素最大运算610来比较这两半。该过程迭代地继续,将每次迭代中的值数减半,直到找到通道维度上的总最大值。如果张量的大小不是2的幂,沿待应用最大运算的维度,则可能需要填充,以将大小增加到最接近的2的幂。在一些示例中,张量可以用零填充。如果原始张量中的值全部为负,将导致最大运算返回的最大值为零。替代地,为了更好地调节softmax层,可以用非常大的负值或通过复制原始张量中的一个或多个现有值来完成填充。这不太可能影响最大值的计算。(在一个或多个复制值的情况下,或者通过使用最大可表示负值的情况下,将保证不影响计算)。
图15C示出了迭代逐元素最大方法对示例性输入张量的应用,为简单起见,此处为向量“x”601。输入向量601具有4个通道,每个通道包含由x1、x2、x3和x4表示的数值。首先,向量601被分离600成两个子向量602、603,每个子向量具有两个元素。使用逐元素最大运算610,将第一子向量602的第一元素与第二子向量603的第一元素进行比较。类似地,将子向量602的第二元素与子向量603的第二元素进行比较。该比较产生向量604。在图15C的示例中,x1>x3并且x4>x2;因此,由第一逐元素最大运算输出的向量604由x1和x4组成。向量604被拆分600以产生子向量605和606,这些子向量再次使用逐元素最大运算610进行比较。这将返回输入向量601的最大元素“M”,在该例中正是x4。虽然该示例使用具有4个元素的向量,但该过程以相同的方式应用于具有更多元素的向量或具有更多维度的张量。它也可以应用于通道维度以外的维度。
填充的替代方法是将张量分成两个以上的子张量,每个子张量在相关维度上的大小是2的幂。例如,具有5个通道的张量可以被分成两个张量,每个张量具有2个通道,最后一个张量具有1个通道。如上所述,可以通过分离并且取元素最大值来减少具有2个通道的两个张量。可以比较生成的1通道张量以产生具有1个通道的张量。最后,可以将该张量与剩余的具有1个通道的张量进行比较,以返回通道维度上的原始张量的最大值。该过程在图15D中以举例的方式示出。示例性输入张量,向量“x”611,与图15C中的输入不同之处在于增加了第五通道,其中包含数值x5。前四个通道的处理如图15C所示。随后是最后的附加步骤,其中在进一步的逐元素最大运算610中,将前四个通道的最大值x4与第五通道x5进行比较。该比较的结果是五个通道的总体最大值。(在该示例中,如图所示,最大值仍为x4)。
割运算可由存储器运算模块40通过从一个位置读取数据,并且将数据的第一部分写入第一位置以及将数据的第二部分写入第二位置来执行。替代地,拆分可能不需要单独的运算,而是可以作为前述运算的输出的一部分来执行。在图15B的示例中,可以通过将输出的第一部分写入存储器25中的第一位置并且将输出的第二部分写入存储器25中的第二位置来拆分逐元素最大值610的输出
图16示出了使用池化单元275的最大运算2110的实施。如上所述,在本发明的示例中,softmax应用于通道维度。因此,最大运算2110也适用于通道。为了便于在池化单元275中实施最大运算2110,可以在池化单元275执行最大池化运算2520之前对输入张量应用转置或置换运算2510。这是由于在示例性硬件加速器中,池化单元专门用于在空间维度上进行池化。为了池化输入的通道元素,通道维度与空间维度中的一者转置。(这可以使用MMM40来完成)。然后,最大池化运算2520的结果可以通过另一个转置或置换运算2512转换回输入的原始维度,该另一个转置或置换运算反转转置或置换运算2510以恢复维度的原始排序。(此外,这可以使用MMM 40来完成)。如果在空间维度(例如,高度和/或宽度维度)中执行softmax,则可能不需要这些转置运算。类似地,在池化单元275被设计成在通道维度中运算的情况下,可能不需要转置运算。在一些情况下,池化单元275可以具有小于将计算最大值的维度的大小的最大窗口大小。如果出现这种情况,可以多次迭代最大池化,以便在更大的一组值上计算最大值。
减法2120、2138和求反2132可以由逐元素运算单元285执行。逐元素运算单元可以对张量的每个元素执行相应的减法运算。在减去常数的情况下—如在减法2138中—减法可以由逐元素运算单元285或由激活单元255执行。常数的减法(例如,减1)可以在激活单元中通过将函数y=x-c加载到LUT中来实施,其中c是要减去的常数。通过添加常数的负数(例如,添加-1),可以将常量的减法实施为逐元素运算单元中的逐元素加法。类似地,求反2132可以由逐元素运算单元285(通过从常数0减去输入张量)或由激活单元255(通过将函数y=-x加载到LUT中)来执行。
在本发明的示例中,通过从零减去张量的每个元素来执行求反2132。这还可以通过其他方式通过逐元素减法来执行,例如桶过将张量从自身中减去两次,或者将张量的每个元素乘以2,然后从原始张量中减去结果。替代地,可以通过改变张量的每个元素的符号位来执行求反,其中使用数字的符号和量值表示。在使用二进制补码表示的情况下,可以通过将表示数字的所有位反转然后加一来执行求反。
指数运算2130接收输入并且将e提高到该输入的幂。对于x的输入,指数运算2130的输出为e
可以评估指数运算:
1.直接在查找表(LUT)中,在激活单元255中;
2.通过S形函数2134、倒数2136、求反2132和减法2138,如图14B所示;或
3.通过倒数的S形函数、求反2132和减法2138。
第一实施相对简单,前提是硬件加速器的硬件和软件允许使用指数函数对LUT进行编程。然而,这并不总是可能的。因此,第二实施可用作替代方案。
第二实施使用以下恒等式:
其中σ(-x)为负S形函数。此处,与神经网络领域的大多数文献一样,使用与“逻辑函数”同义的术语“S形”。即,S形(逻辑)函数被定义为:
因此,负S形函数为:
第二实施使用基本神经网络运算来实施图14B所示的步骤。如上文所解释,可以由EWO单元285来评估求反2132和减法2138。S形函数2134可以由激活单元255评估为S形激活。换句话讲,不是将指数函数加载到LUT中,而是加载和评估S形函数。因为S形是一种常见的激活函数,因此很可能在激活单元255中本机可用。因此,在这种情况下,指数运算借助于S形激活(连同其他基本运算)间接地实施。
σ(-x)的值的倒数2136可以用几种方式评估,这取决于硬件加速器200的确切能力。评估倒数的选项包括:
使用LRN单元265在激活单元255
的LUT中进行倒数查找;以及
逐元素除法,使用EWO单元285。
在本发明的示例中,使用LRN单元来执行倒数函数。下文将更详细地描述三个选项中的每一个选项。
再次参考图14B,原则上,如果S形函数2134和倒数2136都借助于LUT中的查找来实施,则可以结合。与其在两个LUT中执行两次查找,不如将函数组合在一起并且执行一次查找。即,激活单元255的LUT可被编程为包含倒数的S形函数
图17A中所示的求和2140可以使用卷积引擎240通过具有多个1的内核的1×1卷积来实施。卷积运算2570在图17B中示出。使用图14A和图14B的示例,考虑指数张量e
在一个或多个空间维度上评估softmax层的情况下,可以使用深度卷积,这意味着内核分别应用于每个通道。在这种情况下,内核在通道维度上的大小为1,在高度和/或宽度维度上的大小大于1。如果硬件加速器被限制为某个最大内核大小,则可能需要迭代卷积以便捕获输入张量的所有元素,其方式与上述最大池化运算类似。应当理解,在其他示例中,可以在维度的其他组合诸如通道维度和一个或多个空间维度上评估softmax层。卷积内核将根据相关维度进行调整。
替代地,求和2140可以由EWO单元285使用迭代的成对加法运算来实施。该方法与关于图15B和图15C解释的逐元素最大运算非常相似。不同之处在于,并非在每个拆分之后实施逐元素最大运算,而是使用逐元素加法运算。该运算中产生的子向量的每个元素是其进行运算的向量的两个相应元素的总和。重复拆分和加法过程,直到所有元素都已经在通道维度上求和。类似于图15B和图15C中的最大运算,可能需要预先填充张量,使其在相关维度中的大小是2的幂(即,其大小为2
倒数2136可以被实施:
使用LRN单元265;
使用激活单元255,通过将倒数函数加载到激活单元的LUT中;或
作为逐元素除法,使用逐元素运算单元285,通过将常数1除以待计算倒数的输入值。
如果激活单元255的LUT可用并且是可编程的,则其可以用倒数函数f(x)=1/x编程。
特别地,如果LUT不可用,或者如果不可编程来实施任意函数,则可以使用LRN单元265。LRN单元265被设计为执行以下LRN计算:
通过设置α=1、β=1、k=n=0,该函数可以简化为:
b
这与所需的倒数相同:
b
这两种解决方案中的任何一种都可用于评估倒数。评估倒数的两种方法也可用于评估除法运算,如下文进一步解释。替代地,如上所述,倒数本身可以在逐元素运算单元285中通过逐元素除法来实施(假设支持逐元素除法)。
在图14B所示的指数运算的评估中,倒数2136(例如,由LRN单元265实施)产生倒数张量
在一些示例中,除法2150(在图18A中再现)可以使用逐元素运算单元285通过逐元素除法运算直接执行。然而,一些硬件加速器200可能不支持逐元素除法。对于这种可能性,希望能够以其他方式实施除法。
图18B和图18C示出了实施图18A中所示的除法2150的两种替代方式,特别是,如果不能由EWO单元285直接执行。这两种方法都利用了这样一种认识,即除法可以被评估为倒数运算和乘法的组合。在这两种情况下,乘法2580可以由EWO单元285执行。
图18B示出了使用LRN运算2552来评估倒数。使用这种方法,在图1A的示例的上下文中,可以评估包含指数值总和∑e
图18C示出了图18B的方法的替代方案,其中使用激活单元255的LUT中的倒数查找2545代替LRN 2552来实施倒数。在一些情况下,如果激活单元255可编程以实施任意函数,诸如倒数函数,则优选地使用激活单元255来执行倒数查找2545(如图18C所示),而不是使用LRN单元265来执行LRN运算2552(如图18B所示)。一旦倒数函数已加载到LUT中,查找可能比LRN运算更快且更节能。
层归一化
如上文已经解释的,参考图1A和图1B,层归一化出现在块120、121、140、141和171中的每一个块中。层归一化对其输入x应用以下归一化:
此处,E[x]是输入数据的平均值,并且Var[x]是其方差。层归一化首先从输入数据中减去平均值,并且然后通过标准偏差的倒数对其进行缩放。常数∈具有小正值,并且包含该小正值以便数值稳定,以避免被零除的情况。在本示例中,∈=0.00001。这些运算将数据归一化,以使平均值和单位标准偏差为零。乘法参数γ随后缩放数据,以使标准偏差等于γ。最后,加法参数β移动数据,以使平均值等于β。
可在示例性硬件加速器200的固定功能硬件中以至少三种方式实施层归一化运算。这些将参考图19A至图19C进行描述。
图19A示出了用于根据第一示例实施层归一化的计算图。使用卷积运算1910(由卷积引擎240执行)计算输入数据的平均值。然后使用减法运算1920从原始输入数据中减去平均值。这可以使用逐元素运算单元285来完成。减法运算1920的输出在乘法运算1930中被平方。同样,这可以使用逐元素运算单元285来完成。第二卷积运算1940对由乘法运算1930输出的平方求和,从而计算输入数据的方差。标准偏差计算为方差的平方根。平方根运算1945可使用局部响应归一化单元265来实施。标准偏差被传递到倒数运算1950。这可使用激活单元255中的LUT来实施(尽管它也可以其他方式实施)。注意,在其他示例中,平方根运算1945和倒数运算1950的顺序可以颠倒。原则上,结果应当是相同的;实际上,由于舍入或其他数值影响,可能会有细微的差异。然后,在乘法运算1960中,由减法运算1920产生的减去平均值的数据乘以标准偏差的倒数。这可作为逐元素运算单元285中的逐元素乘法来实施。缩放因子γ被应用于另一逐元素乘法运算1970中。最后,加法偏移β被应用于逐元素加法运算1980中。
图19B的计算图在许多方面类似于图19A的计算图,并且相同的运算由相同的附图标记指示。唯一的区别是除法运算的实施。在图19A中,这被实施为倒数1950,随后是乘法1960,而在图19B的计算图中,它被直接实施为逐元素除法1952。这可使用逐元素运算单元285来执行。
图19C的计算图再次仅在除法运算的实施上有所不同。类似于图19A,除法被实施为倒数,随后是单独的乘法1960。在图19C中,倒数在三个步骤中实施。在步骤1954中,由激活单元255应用整流线性激活函数(ReLU)。加法运算1956加上小的正常数(例如,1x10
为实施层归一化而选择的方法通常将取决于目标硬件加速器的精确能力。例如,并非所有硬件加速器都可直接实施逐元素除法运算。并且实施倒数的不同方法在不同的平台上可能执行得更慢或更快。
格式选择
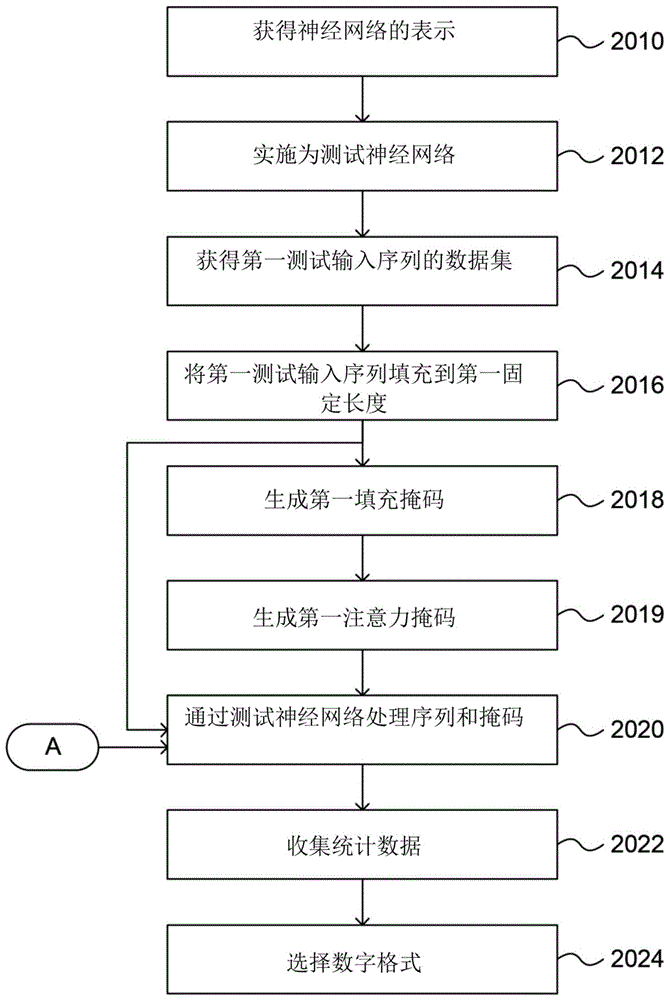
图20A和图20B示出了说明用于选择适用于基于注意力的神经网络(诸如图1A和图1B所示的神经网络)的硬件实施的数字格式的方法的流程图。期望选择能够足够精确地表示数据的数字格式,同时避免过度或冗余的精度。如果数据以非常精确的格式表示,这容易导致计算复杂度、功耗、存储器和带宽需求和/或芯片上面积占用的增加。所选择的数字格式可包含或包括定点格式。这可减少或避免以浮点格式存储数据的需要。例如,图20A至图20B的方法可由如图4所示的数据处理系统来执行,或者由诸如服务器计算机的通用数据处理系统来执行。
参考图20A,在步骤2010中,获得要在硬件中实施的基于注意力的神经网络的表示。在步骤2012中,数据处理系统将该表示实施为测试神经网络。在步骤2014中,数据处理系统获得第一测试输入序列的数据集。根据一个示例,这些可以是用于编码器堆栈的输入序列,诸如图1A的编码器堆栈。数据集包括不同长度的多个第一测试输入序列。在步骤2016中,数据处理系统用填充值填充这些测试输入序列中的每一个测试输入序列,以产生第一固定长度的相应第一填充输入序列。第一固定长度可被选择为等于数据集中的任何第一测试输入序列的最大长度。在步骤2018中,数据处理系统为每个第一填充输入序列生成第一填充掩码。每个第一填充掩码标识相应第一填充输入序列的包含填充值的部分。在步骤2019中,数据处理系统从第一填充掩码生成第一(自我)注意力掩码。这些掩码的生成对应于图6A中的步骤513和514。
用于实施基于注意力的神经网络的硬件(诸如加速器200),可支持网络值的一种类型的数字格式。例如,用于实施RNN的硬件可支持其中数字由b位尾数和指数exp表示的数字格式。为了允许使用不同的数字格式表示不同的网络值集合,用于实施RNN的硬件可以使用具有一个或多个可配置参数的数字格式类型,其中参数在两个或更多个值的集合中的所有值之间共享。这些类型的数字格式在本文中可以被称为块可配置类型的数字格式或集合可配置类型的数字格式。因此,非可配置格式,诸如INT32和浮点数格式,不是块可配置类型的数字格式。
为了为基于注意力的神经网络选择数字格式,基于注意力的神经网络在测试输入序列上执行,以便为数字格式选择提供统计数据。这种统计数据可以是网络值、值的平均值/方差、最小/最大值、汇总值的直方图、相对于输出计算的梯度或基于输出的误差度量,以及数字格式选择所需的由神经网络或监视神经网络的逻辑使用或生成的任何其他数据。在一些示例中,使用值的浮点数格式来执行基于注意力的神经网络。例如,基于注意力的神经网络可在软件中执行,对网络中的输入数据、权重、状态和输出数据值使用浮点数格式。32位或64位浮点数格式表现良好,因为数字格式通常应尽可能接近无损以尽可能获得最佳结果,但可使用具有大范围/大量的位的块可配置数字格式。
基于注意力的神经网络可以任何合适的方式执行,以便执行数字格式选择。例如,基于注意力的神经网络可在软件中(例如,使用深度学习框架)或在硬件中(例如,在诸如加速器的加速器处)执行。
为了执行数字格式选择,对合适的样本输入数据执行基于注意力的神经网络,以便能够捕获适当的统计数据用于数字格式选择。基于注意力的神经网络针对预先确定的数量的一个或多个步骤执行,以便在每个时间步骤处生成数字格式选择所需的统计数据。合适的测试输入序列可包括选择为表示将在硬件中实施的基于注意力的神经网络的典型或预期输入范围的示例性数据。在一些示例中,测试输入序列可以是来自基于注意力的神经网络将到达的实际源的输入序列。从神经网络捕获统计数据是本领域众所周知的,并且应当理解,统计数据的特定性质将取决于神经网络的性质、其应用以及正在使用的数字格式选择的要求。在基于注意力的神经网络和/或与基于注意力的神经网络相关联的逻辑处生成的统计数据(例如,数据值、最大值/最小值、直方图数据)可以任何合适的方式捕获。在一些示例中,统计数据中的至少一些统计数据包括在基于注意力的神经网络处生成的中间数据值。
将数字格式选择应用于从基于注意力的神经网络的运算收集的统计数据。数字格式选择可与基于注意力的神经网络同时运行,以及/或者随后可对所捕获的统计数据执行。数字格式选择可以是用于标识块可配置数字格式的任何算法。算法的特定选择通常由以下各项中的一种或多种决定:应用基于注意力的神经网络的应用程序;以及运行算法所需的时间和/或计算资源量(更复杂的算法可能会给出更好的结果,但可能需要更多倍的时间来运行)。
在本发明的示例中,数字格式选自块可配置类型的数字格式,指数的位数可以是固定的(例如,带符号的6个位)。因此,指数长度不必与每个数据值一起存储,而是可以针对数据值的群组来定义,例如,针对每个张量、针对每个张量的两个或更多个元素的集合、针对每种类型的张量(例如,针对输入和/或权重和/或输出的不同指数长度)、针对张量群组,或者针对所有张量,可以预定义指数长度。与存储网络值的实际尾数所需的位数相比,存储指数和尾数长度所需的数据量(例如,存储数字格式所需的位数)可以是固定的并且可以忽略不计。因此,尾数位数是表示网络值的数字格式所需的位数的主要决定因素。
数字格式选择算法可以确定块可配置类型的数字格式的尾数的长度(例如,以位为单位)。例如,基于注意力的神经网络用来表示数据值的每个块可配置数字格式都包括指数和尾数位长度,可减少归因于量化误差的最低部分的胞元所使用的块可配置数字格式的尾数位长度,或者可增加归因于量化误差的最高部分的胞元所使用的块可配置数字格式的尾数位长度。数据值的量化误差是原始浮点数格式的数据值(即,如出于数字格式选择的目的用于基于注意力的神经网络的实施)与块可配置数字格式的数据值(即,如建议用于基于注意力的神经网络的硬件实施)之间的差。
已经开发了若干方法来标识用于表示基于注意力的神经网络的网络值的数字格式。一种用于选择用于表示基于注意力的神经网络的一组参数的数字格式的简单方法(本文中可称为全范围法或最小值/最大值或MinMax方法)可包括,针对给定的尾数位深度n(或给定的指数exp),选择覆盖预期的网络值集合x的范围的最小指数exp(或最小尾数位深度n)用于运算。例如,对于给定的尾数位深度b,可以根据下式选择指数exp,使得数字格式覆盖x的整个范围,其中
然而,此类方法对异常值敏感。具体地,在网络值集合x有异常值的情况下,牺牲精度来覆盖异常值。这可导致大的量化错误(例如,第一数字格式(例如,浮点数格式)的网络值集合与所选择的数字格式的网络值集合之间的误差)。因此,由量化引起的运算和/或基于注意力的神经网络的输出数据中的误差可大于数字格式涵盖较小范围时的误差,但更精确。
在其他示例中,可使用具有异常值加权的平方误差算法的总和。在相对重要的值通常是在给定的两个或多个值的集合的值范围的较高端的值的情况下,所述算法可能是合适的。对于通过惩罚量值进行正则化的权重张量尤其如此,因此可期望具有较高值的元素比具有较低值的元素具有更大的相对重要性。另外,钳位是特别具有破坏性的噪声形式,可在所得的两个或更多个值的量化集合中引入强偏置。因此,在一些应用中,将误差偏置成保留大值,同时避免以牺牲定量误差为代价保留全范围的极端(例如,如在“MinMax”方法中)是有利的。例如,如下式中所示的加权函数a(x)与误差的平方度量组合可用于平方误差算法的总和:
/>
其中SAT是定义为2
在申请人的英国专利申请号1718293.2中描述了一种加权异常值方法,所述专利申请的全文以引用方式并入本文。在加权异常值的方法中,当使用特定的数字格式时,基于定量误差的加权总和,从多个潜在数字格式中选择值集合的数字格式,其中将恒定权重应用于落入数字格式的可表示范围内的网络值的定量误差,并且将线性增加的权重应用于落入可表示范围之外的值的定量误差。
申请人的英国专利申请号1821150.8中描述了另一种方法(可被称为后向传播方法),所述专利申请的全文以引用方式并入本文。在后向传播方法中,产生最佳成本的量化参数(例如,基于注意力的神经网络准确度与基于注意力的神经网络大小(例如,位数)的组合)通过使用后向传播迭代地确定相对于每个量化参数的成本的梯度来选择,并且调整定量参数直到成本收敛。此方法可以产生良好的结果(例如,(在位数方面)小且准确的基于注意力的神经网络),但是它可能需要很长时间才能收敛。
一般来讲,数字格式的选择可被设想为优化问题,所述优化问题可以对基于注意力的神经网络中的数字格式的参数中的一个、一些或全部参数执行。在一些示例中,可以同时优化数字格式的多个参数;在其他示例中,可以依次优化格式选择方法的一个或多个参数。在一些示例中,网络值的位深度可以用所应用的格式选择算法来预定义,以便为基于注意力的神经网络的网络值选择合适的指数。网络值的位深度可以是固定的,或者在一些示例中可以是待优化的参数。在一些示例中,应用数字格式选择可包括标识基于注意力的神经网络的适当位深度。为了确保测试神经网络的每次迭代是相同的,基于注意力的神经网络的不同迭代中的两个或更多个值的实例被约束为具有相同的位深度。
参考图20B,在步骤2054中,由数据处理系统获得第二测试输入序列的数据集。继续图1A和图1B的示例,第二测试输入序列可以是用于图1B的解码器堆栈的测试输入序列。同样,数据集包括不同长度的多个第二测试输入序列。确定第二固定长度,其等于所有第二测试输入序列上的最大序列长度。在步骤2056中,数据处理系统将第二测试输入序列中的每一个第二测试输入序列填充到第二固定长度,从而产生相应第二填充输入序列。在步骤2058中,数据处理系统为每个第二填充输入序列生成相应第二填充掩码。接下来,在步骤2059中,数据处理系统为每个第二填充输入序列生成相应第二(自我)注意力掩码。这些步骤对应于图6A中的步骤523和524。数据处理系统还生成对应于每对第一和第二填充输入序列的交叉注意力掩码(步骤2060)。此步骤对应于图6A中的步骤525。
再次参考图20A,在步骤2020中,数据处理系统通过测试神经网络处理第一和第二填充输入序列、第一和第二(自我)注意力掩码以及交叉注意力掩码。当执行此处理时,数据处理系统收集关于在处理期间获得的值的统计数据(见步骤2022)。当通过测试神经网络处理测试序列时,统计数据描述在神经网络的层中的每一层处遇到的值的范围。当神经网络最终在硬件中实施时,统计数据捕获关于合适的数字格式的相关信息,这些数字格式可用于表示(和存储)各层处的数据。在步骤2024中,数据处理系统根据所收集的统计数据选择数字格式。
如果运算将在硬件中实施为多个基本神经网络运算(例如,如上文针对批量矩阵乘法和Softmax所解释的),则数据处理系统可以为基本神经网络运算中的每一个基本神经网络运算收集统计数据并选择数字格式。
如果神经网络包括将在多次迭代中执行的解码器堆栈,则数据处理系统可以为所有(第一和第二)测试序列收集所有迭代的统计数据。然后,可以为解码器堆栈中的每一层选择数字格式,使得在任何给定层的每次迭代中使用相同的数字格式。这有助于避免在解码器堆栈的迭代之间重新配置硬件实施的需要,这在推断阶段中可能是复杂或耗时的。
数据处理系统可以为第一和第二(自我)注意力掩码以及交叉注意力掩码选择数字格式。此外,它可以为这些注意力掩码中的“大负值”选择一个值(或多个值)。
在一些情况下,大负值可被选择为等于可由为相关联的注意力掩码选择的数字格式表示的最大负值。在一些实施方案中,情况可能不是这样;然而,所选择的大负值可能仍然具有比在处理测试序列的过程中观察到的最大负值更负的值,该最大负值在输入到使用相应注意力掩码的层的数据张量中。所选择的大负值可能比此控制值负一个裕量。即,数据张量中存在的最大负值与所述大负值之间可能存在若干(未使用的)值。在一些示例中,可以选择大负值,使得它们具有大于数据张量的最大绝对值的绝对值。它们可能大到相差一个裕量——即,数据张量的最大绝对值与大负值的绝对值之间可能存在若干(未使用的)值。在一些情况下,可以选择大负值x,使得以为相关注意力掩码选择的数字格式,e^x=0。
训练
现在将参考图21描述一种训练适于硬件实施的基于注意力的神经网络的方法。该方法可由数据处理系统(诸如图4所示的数据处理系统)或者由通用数据处理系统(诸如服务器计算机)来执行。
在步骤2210中,获得第一训练输入序列的数据集。为简单起见,在此示例中,将假设基于注意力的神经网络仅包括解码器堆栈而不包括编码器堆栈。因此,第一训练输入序列是用于解码器的输入序列。然而,应当理解,在其他示例中,神经网络可包括编码器堆栈。在这样的示例中,可以为编码器提供第二训练输入序列的数据集。
在步骤2212中,用填充值填充第一训练输入序列中的每一个第一训练输入序列,以产生第一固定长度的相应第一填充输入序列。已经预先选择了第一固定长度——例如,在用诸如图20A至图20B所示的方法为神经网络的层选择数字格式的过程中。第一固定长度大于或等于所有训练输入序列中的最大长度。应当注意,训练输入序列的数据集(在步骤2210中获得)可能与测试输入序列的数据集(在步骤2014中获得)相同,但这不是必需的。一般来说,这些可能是不同的数据集。
在步骤2214中,为每个训练输入序列生成第一填充掩码。填充掩码指示相应填充输入序列的包含填充值的部分。如同上文讨论的其他填充掩码一样,填充掩码可在对应于原始训练输入序列的元素的位置中包含值一(在填充之前)。填充掩码可在对应于填充值的位置中包含零。
在步骤2216中,为训练输入序列中的每一个训练输入序列定义(自我)注意力掩码。在训练神经网络期间,注意力掩码防止基于注意力的神经网络注意填充输入序列的某些部分。特别地,注意力掩码防止网络注意每个训练输入序列的填充部分。在一些示例中,注意力掩码还可被配置为防止网络注意原始训练输入序列的某些元素。注意力掩码可在对应于应当防止网络注意的元素的位置处包含大负值,而在其他位置处包含零。以与上文已经描述的相同的方式从相应填充掩码生成注意力掩码。同样如上所述,可基于外部输入来修改注意力掩码,以防止网络注意训练输入序列的指定元素。
在步骤2220中,使用在步骤2212中生成的填充输入序列和在步骤2216中生成的(自我)注意力掩码来训练基于注意力的神经网络。注意力掩码用于忽略相应训练输入序列的某些元素。(这防止网络注意被忽略的元素。)因为基于注意力的神经网络仅包括解码器堆栈,所以在本示例中,不需要交叉注意力掩码。在网络包括编码器堆栈和解码器堆栈的其他示例中,将从与相应训练输入序列相关联的填充掩码为每对训练输入序列(分别到编码器和解码器)生成交叉注意力掩码。
在一些示例中,解码器堆栈将在多次迭代中执行。在每次迭代中(除了第一次迭代),解码器堆栈的来自前一次迭代的输出被用作对解码器堆栈的下一次迭代的输入。在这样的示例中,与每个训练输入序列相关联的自我注意力掩码可在每次迭代中被更新,以允许解码器堆栈比在前一次迭代中注意更多的(填充)训练输入序列。
在前述示例中,映射单元12和MMM 40被描述为硬件加速器200的独立部件。这不应理解为是限制性的。在一些示例中,映射单元12(或其至少一部分)和MMM 40可以集成为硬件加速器200的一部分。
本文所述的方法和数据处理系统可用于在多种应用程序中处理多种类型的输入数据。特别感兴趣的是图像处理应用程序,其中神经网络的输入包括图像或视频数据。神经网络可被配置为处理图像或视频数据并且产生另外的图像或视频数据,例如,分辨率得到增强、移除伪影,或者以其他方式,以某种方式修改了视觉内容的图像或视频数据。替代地,神经网络可被配置为分析图像或视频的视觉内容,例如,以检测面部、分割和/或分类对象等。还特别感兴趣的是音频处理应用程序,包括任务诸如去噪、扬声器检测/识别。同样特别感兴趣(并且在某些情况下与音频处理应用程序重叠)的是NLP应用程序。这些包括但不限于语音识别;文字转语音;以及机器翻译。在一些示例中,神经网络可被配置为处理多模态数据,即,两种或更多种不同类型/媒体的数据。一个示例是将图像数据和文本(标题)数据用于分类或验证任务。
图像和视频数据可以各种方式输入到基于注意力的神经网络。视频可作为帧序列输入,其中每一帧构成该序列的一个元素,并且该序列的长度(在其上计算注意力)等于帧的数量。图像数据也可呈现为元素序列。例如,每个像素可被视为一个元素。则序列的长度等于像素的数量。这种方法可允许基于注意力的神经网络处理具有不同帧数的视频或具有不同像素数的图像,而不需要作为预处理步骤调整数据的大小或对数据进行重新采样。
图22示出了可在其中实施本文描述的数据处理系统的计算机系统。计算机系统包括CPU 902、NNA 904、存储器906和其他装置914,诸如显示器916、扬声器918和相机919。处理块907(对应于映射单元12、MMM 40和硬件加速器200)在NNA 904上实施。计算机系统的部件可通过通信总线905彼此通信。存储装置908(对应于存储器25)被实施为存储器906的一部分。
图4的数据处理系统被示出为包括许多功能块。这仅是示意性的,并不旨在限定此类实体的不同逻辑元件之间的严格划分。每个功能块可以任何合适的方式提供。应理解,如由数据处理系统形成的本文中所描述的中间值不需要由数据处理系统在任何时间点处物理地产生,并且可仅表示方便描述由数据处理系统在其输入与输出之间执行的处理的逻辑值。
本文中描述的数据处理系统可以在集成电路上的硬件中体现。本文中所描述的数据处理系统可被配置成执行本文中所描述的方法中的任一种方法。一般来说,上文所描述的功能、方法、技术或部件中的任一者可在软件、固件、硬件(例如固定逻辑电路系统)或它们的任何组合中实施。本文中可以使用术语“模块”、“功能性”、“部件”、“元件”、“单元”、“块”和“逻辑”来概括地表示软件、固件、硬件或它们的任何组合。在软件具体实施的情况下,模块、功能性、部件、元件、单元、块或逻辑表示程序代码,该程序代码当在处理器上被执行时执行指定任务。本文中所描述的算法和方法可由执行代码的一个或多个处理器执行,所述代码促使处理器执行算法/方法。计算机可读存储介质的示例包括随机访问存储器(RAM)、只读存储器(ROM)、光盘、闪存存储器、硬盘存储器,以及可使用磁性、光学和其他技术来存储指令或其他数据并且可由机器访问的其他存储器设备。
如本文中所使用的术语计算机程序代码和计算机可读指令是指供处理器执行的任何种类的可执行代码,包含以机器语言、解释语言或脚本语言表达的代码。可执行代码包含二进制代码、机器代码、字节代码、定义集成电路的代码(例如硬件描述语言或网表),以及用例如C、
处理器、计算机或计算机系统可以是任何种类的设备、机器或专用电路,或者它们的具有处理能力以使得其可执行指令的集合或部分。处理器可以是任何种类的通用或专用处理器,诸如CPU、GPU、NNA、片上系统、状态机、媒体处理器、专用集成电路(ASIC)、可编程逻辑阵列、现场可编程门阵列(FPGA)等。计算机或计算机系统可包括一个或多个处理器。
其还旨在涵盖限定如本文中所描述的硬件的配置的软件,诸如HDL(硬件描述语言)软件,如用于设计集成电路或用于配置可编程芯片以实现所需功能。即,可提供一种计算机可读存储介质,其上编码有呈集成电路定义数据集形式的计算机可读程序代码,当在集成电路制造系统中进行处理(即运行)时,所述计算机可读程序代码将系统配置成制造被配置成执行本文中所描述的方法中的任一种方法的数据处理系统,或制造本文中所描述的包括任何设备的数据处理系统。集成电路定义数据集可以是例如集成电路描述。
因此,可提供一种在集成电路制造系统处制造如本文中所描述的数据处理系统的方法。此外,可提供一种集成电路定义数据集,当在集成电路制造系统中进行处理时,所述集成电路定义数据集促使制造数据处理系统的方法得以执行。
集成电路定义数据集可呈计算机代码的形式,例如作为网表,用于配置可编程芯片的代码,作为定义适合于在集成电路中以任何级别进行制造的硬件描述语言,包括作为寄存器传输级(RTL)代码,作为高级电路表示法,诸如Verilog或VHDL,以及作为低级电路表示法,诸如OASIS(RTM)和GDSII。在逻辑上定义适合于在集成电路中制造的硬件的更高级表示法(诸如RTL)可在计算机系统处进行处理,该计算机系统被配置用于在软件环境的上下文中产生集成电路的制造定义,该软件环境包括电路元件的定义以及用于组合这些元件以便产生由表示法如此定义的集成电路的制造定义的规则。如通常软件在计算机系统处执行以便定义机器的情况一样,可能需要一个或多个中间用户步骤(例如,提供命令、变量等),以便将计算机系统配置为生成集成电路的制造定义,以执行定义集成电路以便生成该集成电路的制造定义的代码。
现在将参考图23描述在集成电路制造系统处处理集成电路定义数据集以便将所述系统配置为制造数据处理系统的示例。
图23示出了集成电路(IC)制造系统1002的示例,该集成电路制造系统被配置为制造如本文任何示例中描述的数据处理系统。具体而言,IC制造系统1002包括布局处理系统1004和集成电路生成系统1006。IC制造系统1002被配置为接收IC定义数据集(例如,定义如本文任何示例中描述的数据处理系统)、处理IC定义数据集以及根据IC定义数据集来生成IC(例如,其体现如本文任何示例中所述的数据处理系统)。通过对IC定义数据集的处理,将IC制造系统1002配置为制造体现如本文任何示例中描述的数据处理系统的集成电路。
布局处理系统1004被配置为接收和处理IC定义数据集以确定电路布局。根据IC定义数据集确定电路布局的方法在本领域中是已知的,并且例如可涉及合成RTL代码以确定待生成电路的门级表示,例如就逻辑部件(例如,NAND、NOR、AND、OR、MUX和FLIP-FLOP部件)而言。通过确定逻辑部件的位置信息,可以根据电路的门级表示来确定电路布局。这可以自动完成或者在用户参与下完成,以便优化电路布局。当布局处理系统1004已经确定电路布局时,其可将电路布局定义输出到IC生成系统1006。电路布局定义可以是例如电路布局描述。
如本领域中所已知,IC生成系统1006根据电路布局定义来生成IC。例如,IC生成系统1006可实施用以生成IC的半导体装置制造工艺,所述半导体装置制造工艺可涉及光刻和化学处理步骤的多步骤序列,在此期间,在由半导体材料制成的晶片上逐渐形成电子电路。电路布局定义可呈掩模的形式,掩模可在光刻工艺中用于根据电路定义来生成IC。可替代地,提供给IC生成系统1006的电路布局定义可呈计算机可读代码的形式,IC生成系统1006可使用所述计算机可读代码来形成用于生成IC的合适的掩模。
由IC制造系统1002执行的不同过程可全部在一个位置例如由一方来实施。替代地,IC制造系统1002可以是分布式系统,使得一些过程可以在不同位置执行,并且可以由不同方来执行。例如,以下阶段中的一些可以在不同位置以及/或者由不同方来执行:(i)合成表示IC定义数据集的RTL代码,以形成待生成的电路的门级表示;(ii)基于门级表示来生成电路布局;(iii)根据电路布局来形成掩模;以及(iv)使用掩模来制造集成电路。
在一些实施方案中,当在集成电路制造系统中处理时,集成电路制造定义数据集可以使集成电路制造系统生成如本文中所描述的装置。例如,通过集成电路制造定义数据集以上文参考图23所描述的方式对集成电路制造系统进行配置,可以制造出如本文中所描述的装置。
在一些示例中,集成电路定义数据集可以包括在数据集处定义的硬件上运行的软件,或者与在数据集处定义的硬件组合运行的软件。在图23所示的示例中,IC产生系统还可以由集成电路定义数据集另外配置成在制造集成电路时根据在集成电路定义数据集中定义的程序代码将固件加载到所述集成电路上,或者以其他方式向集成电路提供与集成电路一起使用的程序代码。
与已知的实施相比,在本申请中阐述的概念在装置、设备、模块和/或系统中(以及在本文中实施的方法中)的实施可以提高性能。性能改进可包括计算性能提高、等待时间减少、吞吐量增大和/或功耗减小中的一者或多者。在制造这类设备、装置、模块和系统(例如在集成电路中)期间,可在性能提高与物理具体实现之间进行权衡,从而改进制造方法。例如,可在性能改进与布局面积之间进行权衡,从而匹配已知具体实施的性能,但使用更少的硅。例如,这可以通过以串行方式重复使用功能块或在设备、装置、模块和/或系统的元件之间共享功能块来完成。相反,本申请中所阐述的带来设备、装置、模块和系统的物理实现的改进(例如,硅面积减小)的概念可与性能提高进行权衡。这可以例如通过在预定义面积预算内制造模块的多个实例来完成。
申请人据此独立地公开了本文中所描述的每个单独的特征以及两个或更多个此类特征的任意组合,到达的程度使得此类特征或组合能够根据本领域的技术人员的普通常识基于本说明书整体来实行,而不管此类特征或特征的组合是否解决本文中所公开的任何问题。鉴于前文描述,本领域的技术人员将清楚,可以在本发明的范围内进行各种修改。
- 一种在硬件人工神经网络中实施的系统和方法
- 针对在硬件上的高效实施来训练神经网络