上下文感知句子压缩
文献发布时间:2023-06-19 09:32:16
技术领域
本发明涉及自动化语言处理领域。
背景技术
最终用户需要消耗的大量文本数据激发了对文本自动概要的需求。自动概要生成器获得一个或多个文档作为输入,并且可能还获得对概要长度的限制(例如,最大字数)。然后,概要生成器产生文本概要,该概要捕获输入文档中显著的(一般的和信息性的)内容部分。通常,还可能需要概要生成器来满足来自用户的特定信息需求,由一个或多个查询(例如,网络搜索结果的概要)来表达。因此,概要任务包括生成一个既有重点又包括最相关信息的概要。
在某些情况下,文档概要由句子压缩辅助。基于删除的句子压缩旨在从源句子中删除不必要的单词以形成一个短句(压缩),同时保持语法和忠实于源句子的潜在含义。句子压缩有许多应用,包括文档概要。在这种情况下,目标是缩短句子,目的是用更相关的短语替换概要中不相关的短语。
相关技术的前述示例和与其相关的限制旨在说明性的而非排他性的。通过阅读说明书和研究附图,相关技术的其他限制对于本领域技术人员来说将变得显而易见。
发明内容
结合系统、工具和方法来描述和说明以下实施例及其方面,这些系统、工具和方法是示例性和说明性的,而不是对范围的限制。
在一个实施例中,提供了一种包括至少一个硬件处理器的系统;以及其上存储有程序指令的非暂时性计算机可读存储介质,该程序指令可由该至少一个硬件处理器执行以:接收一个或多个数字文档、查询语句和概要长度约束作为输入,至少部分基于所述查询语句、所述概要长度约束的修改版本和第一组质量目标,为所述一个或多个数字文档中的每一个自动识别句子子集;为所述句子子集中的每一个,自动生成随机森林表示;迭代地:(i)从所述随机森林表示中的每一个中自动采样多个标记(token),以至少部分地基于分配给所述标记中的每一个的权重创建相应的候选文档概要,(ii)至少部分地基于所述第一组质量目标和第二组质量目标,自动将质量排名分配给所述候选文档概要,以及(iii)至少部分地基于所述质量排名来自动调整所述权重,并且自动输出具有最高所述质量排名的所述候选文档概要之一作为压缩概要。
在一个实施例中,还提供了一种方法,包括操作至少一个硬件处理器以:接收一个或多个数字文档、查询语句和概要长度约束作为输入;至少部分地基于所述查询语句、所述概要长度约束的修改版本和第一组质量目标,为所述一个或多个数字文档中的每一个自动识别句子子集;为所述句子子集中的每一个,自动生成随机森林表示;迭代地:(i)从所述随机森林表示中的每一个中自动采样多个标记,以至少部分地基于分配给所述标记中的每一个的权重创建相应的候选文档概要,(ii)至少部分地基于所述第一组质量目标和第二组质量目标,自动将质量排名分配给所述候选文档概要,以及(iii)至少部分地基于所述质量排名来自动调整所述权重,并且自动输出具有最高所述质量排名的所述候选文档概要之一作为压缩概要。
在一个实施例中,还提供了一种计算机程序产品,包括具有体现在其中的程序指令的非暂时性计算机可读存储介质,该程序指令可由至少一个硬件处理器执行以:接收一个或多个数字文档、查询语句和概要长度约束作为输入;至少部分基于所述查询语句、所述概要长度约束的修改版本和第一组质量目标,为所述一个或多个数字文档中的每一个自动识别句子子集;为所述句子子集中的每一个,自动生成随机森林表示;迭代地:(i)从所述随机森林表示中的每一个中自动采样多个标记,以至少部分地基于分配给所述标记中的每一个的权重创建相应的候选文档概要,(ii)至少部分地基于所述第一组质量目标和第二组质量目标,自动将质量排名分配给所述候选文档概要,以及(iii)至少部分地基于所述质量排名来自动调整所述权重,并且自动输出具有最高所述质量排名的所述候选文档概要之一作为压缩概要。
在一些实施例中,所述调整包括(i)选择具有最高质量排名的指定数量的所述候选文档概要;以及(ii)调整包括在所述特定数量的所述候选文档概要中的所述标记的所述权重。
在一些实施例中,重复步骤(i)、(ii)和(iii),直到分配给所述指定数量的所述候选文档概要的所述质量排名的平均值对于指定数量的连续迭代没有改善。在一些实施例中,连续迭代的所述指定数量在5和20之间。
在一些实施例中,所述概要长度约束被表达为单词的数量。在一些实施例中,所述概要长度约束的所述修改版本比所述概要长度约束长10%至30%。
在一些实施例中,所述第一组质量目标包括以下中的至少一些:文档覆盖范围、句子位置偏差、概要长度、不对称覆盖范围、焦点漂移、概要显著性和概要多样性。
在一些实施例中,所述第二组质量目标包括以下中的至少一些:语法质量目标、长度目标、冗余目标和删除短语相似性目标。
在一些实施例中,所述选择和所述生成各自至少部分地基于使用一个或多个指定的优化框架来解决优化问题。
在一些实施例中,所述优化框架是交叉熵框架。
除了上述示例性方面和实施例之外,通过参考附图和研究以下详细描述,进一步的方面和实施例将变得显而易见。
附图说明
示例性实施例在附图中示出。附图中示出的部件和特征的尺寸通常是为了方便和清楚的呈现而选择的,并且不一定按比例示出。这些附图如下。
图1是根据实施例的用于自动化句子压缩的示例性系统的框图;
图2A是根据实施例的用于自动化句子压缩的过程中的功能步骤的流程图;
图2B示意性地示出了根据实施例的用于自动化句子压缩的过程;
图3示意性地示出了根据实施例的随机森林表示;和
图4A-4E示出了根据实施例的示例性标记采样过程,其最终是候选概要。
具体实施方式
本文公开了一种用于自动化的、上下文感知的、无监督的句子压缩的系统、方法和计算机程序产品。在一些实施例中,本公开提供了文档内的句子压缩,其与文档概要同时执行。在一些实施例中,文档中的每个句子被压缩,同时考虑到查询中给出的信息需求以及概要中的前面的句子。在一些实施例中,本方法在各个领域都是有效的,并且不需要先前的领域知识、训练数据和/或参数调整。
在自然语言处理(natural language processing,NLP)领域中,文本概要通常被称为从语料库中提取文本片段的任务,该任务将语料库压缩到更短的长度,同时保留语料库的关键。在通过删除进行自动化句子压缩的任务中,计算机系统从句子中选择要删除的单词,以保持句子的原始意义和语法性。在形式上给定一个输入句子S=w
句子压缩有许多应用,诸如文档概要。在这种情况下,目标是缩短句子,目的是用更相关的短语替换概要中不相关的短语。例如,考虑以下两句话:
“Donald Trump,the president of the United States,plans to meet KimJong-Un in Singapore,reported in CNN.com.”
和
“Donald Trump,the president of the United States,has softened tonetoward North Korea,said Jared Kushner,a white house executive.”
传统的压缩算法倾向于,例如,简单地移除介词、后缀、前缀和/或名词修饰符(modifier),例如:
“Donald Trump,the president of the United States,plans to meet KimJong-Un in Singapore
和
“Donald Trump,the president of the United States,has sofiened tonetoward North Korea
然而,当执行文档概要时,对每个单独的句子执行压缩同时考虑概要中其他句子提供的上下文可能是有利的。例如,作为示例给出的前面两个句子包括了重复的同位语“Donald Trump,the president ofthe United States”。上下文感知的压缩试探可能能够识别这种冗余,并提供改进的结果:
“Donald Trump,the president of the United States,plans ti meet KimJong-Un in Singapore
和
“Donald Trump,
因此,在一些实施例中,本公开提供了上下文感知的,例如概要感知的句子压缩算法。在一些实施例中,本发明的上下文感知句子压缩算法可以用于以查询为中心的、提取的、无监督的文档概要。在一些实施例中,本算法采用有助于在给定查询中需要表达的信息和已经包括在概要中的内容的情况下,决定给定句子的哪些单词应该包括在概要中的句子压缩模型。
因此,本公开的潜在优点在于,它提供了上下文句子压缩,这可以使用通过删除的压缩来减少文档概要中的不相关性。本公开能够产生单个或多个文档的上下文感知概要。
在一些实施例中,本算法考虑了用户提供的信息需求,例如查询。假设以下查询:“Report Jared Kushner’s statements on the US-North Korea summit”。在这种情况下,我们可以认为第二个示例句子中的最后子句(clause)是一个重要的方面,因此应该保留在概要中:
“Donald Trump,the president of the United States,plans to meet KimJong-Un in Singapore
和
“Donald Trump,the president of the United States,has softened tonetoward North Korea,said Jared Kushner,a white house executive.”
图1是根据实施例的用于自动化句子压缩的示例性系统100的框图。系统100可以包括一个或多个硬件处理器102和非暂时性计算机可读存储设备104。这里描述的系统100仅仅是本发明的示例性实施例,并且在实践中可以仅用硬件、仅用软件或者硬件和软件的组合来实现。系统100可以具有比所示更多或更少的组件和模块,可以组合两个或更多的组件,或者可以具有不同的组件配置或布置。在各种实施例中,系统100可以包括一个或多个专用硬件设备、一个或多个软件模块,和/或可以形成对现有设备的添加或扩展。
存储介质104上可以编码有被配置为操作处理单元(也称为“硬件处理器”、“CPU”或简称为“处理器”)的软件指令或组件,诸如(多个)硬件处理器102。在一些实施例中,软件组件可以包括操作系统,包括用于控制和管理一般系统任务(例如,存储器管理、存储设备控制、电源管理等)的各种软件组件和/或驱动程序,并促进各种硬件和软件组件之间的通信。在一些实施例中,程序指令被分割成一个或多个软件模块,其可以包括例如概要模块106。
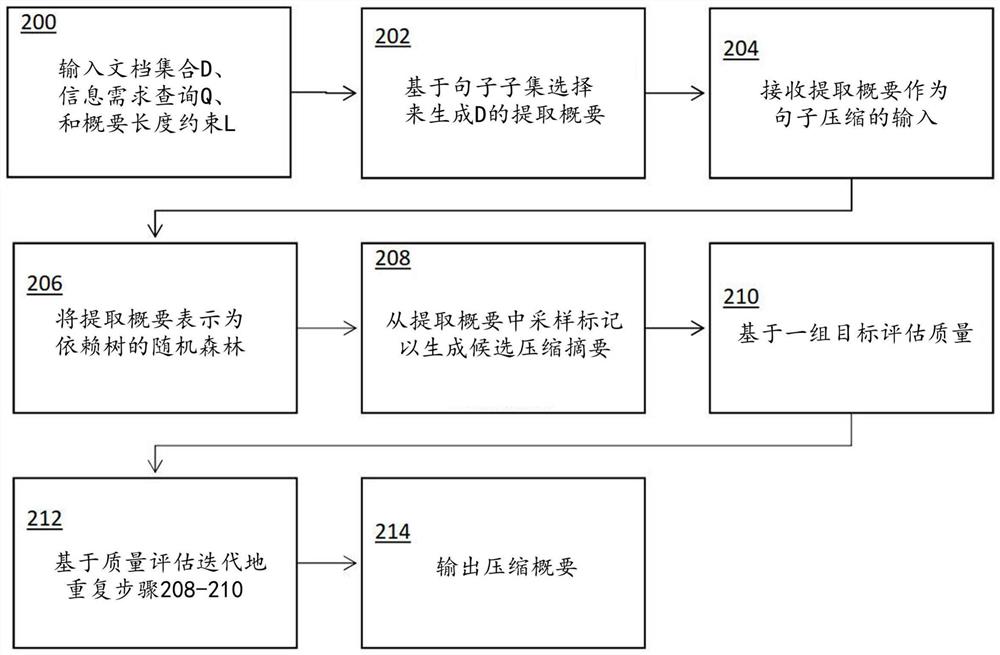
继续参考图2A中的流程图和图2B中的示意性过程概述,提供了用于自动化句子压缩和文档概要的过程中的功能步骤的概述。
在一些实施例中,在步骤200,q表示给定的信息需求(查询),D表示要进行概要的一个或多个匹配文档的集合,并且L是对概要长度的约束。在一些实施例中,本方法的目的是找到从D中提取的与查询相关且符合长度的概要
在一些实施例中,概要
在一些实施例中,假设每个文档D由其包括的句子序列来表示。因此,本算法基于句子子集选择方法。让SD表示文档集合D中所有句子的集合。对于表示潜在概要的给定子集
在一些实施例中,图1中的第一步骤202中的概要算法是基于Summit的,Summit是一种最先进的概要体系结构,如(i)2017年7月26日提交的美国专利申请序列号第16/005,815号,和(ii)Guy Feigenblat,Haggai Roitman,Odellia Boni,David Konopnicki,“Unsupervised Query-Focused Multi-Document Summarization using the CrossEntropy Method”,SIGIR 2017:961-964所述,其全部内容通过引用结合于此,两者都通过引用整体结合于此。
在一些实施例中,Summit获得文档集合D(其将被分割成句子S
为了在每次迭代后进行学习,Summit使用排名前1%的概要来调整S
在一些实施例中,在步骤204,在步骤202中选择的句子S、输入查询q和概要长度上限L被接收作为后续压缩步骤的输入。在一些实施例中,假设在步骤202中创建的概要的质量足够高,但是需要进一步压缩,以便在冗余和无关性被最小化的同时保留查询覆盖范围。
因此,在步骤206,可以采用另一个概括步骤,其中选择单词而不是句子。换句话说,不是决定一个句子是否被添加到概要中,而是对单词和句子进行采样以包括在内。在一些实施例中,交叉熵方法用于采样和优化。
在一些实施例中,在步骤206,在步骤202产生的提取概要被表示为依赖树或决策树的随机森林。因此,在一些实施例中,为了保持概要的语法水平高,可以使用依赖树结构。在这种结构中,每个单词都与其他单词的二元语法关系相关联——父节点是调控者(governor)节点,并且子节点是从属节点。这有助于确保仅在选择了其调控者节点的情况下才会选择从属节点。例如,下面的关系代表句子“My cat likes eating bananas”的依赖树。根(root)节点是模拟(mock)节点,充当树的根,并且没有语法角色:
-nmod(cat-2,My-1)
-nsubj(likes-3,cat-2)
-root(ROOT-0,likes-3)
-xcomp(1ikes-3,eating-4)
-dobj(eating-4,banana-5)
在一些实施例中,如图3所示,在步骤206生成的随机森林决策树表示代表每个单独句子S
在一些实施例中,在步骤208,迭代压缩过程开始。在一些实施例中,在步骤206中生成的依赖树上进行标记采样。
图4A-4E示出了根据实施例的示例性标记采样过程,其最终是候选概要。在一些实施例中,随机森林中的每个节点(除了全局根)用统一的权重(例如,不失一般性地,0.5)初始化。采样过程以迭代方式工作,迭代每个节点的直接后继。如果选择了节点,则该过程迭代地继续到树中它的直接子节点,否则,如果没有选择该节点或者该节点是叶子,则该过程终止。因此,步骤208生成多个候选概要。最后,对于每个局部根(句子),选择节点集合,其中这些节点是从句子中采样的单词,并表示其压缩版本。当没有选择本地根,则表示没有为压缩概要选择某些句子S
在一些实施例中,在步骤210,评估在步骤208中生成的每个候选概要的质量。在一些实施例中,使用与步骤202中相同的目标函数Q
-语法目标:这个目标计算概要中不符合语法的短语的数量。在一些实施例中,可以使用已知的语法试探法(例如,参见Clarke,James&Mirella Lapata(2008),“Globalinference for sentence compression:An integer linear programming approach”,Journal of Artificial Intelligence Research,31:399-429)。例如,限定词和/或数字修饰符只有在其调控者节点被包括时才应该被包括。
-长度目标:这个目标惩罚那些被压缩太多或者没有压缩的句子。在一些实施例中,可以在概要比率上使用高斯,其中μ=0.7。
-冗余度:这个目标衡量给定句子与概要中其余句子之间的冗余度(例如,使用成对的雅克卡(Jaccard)相似度)。
-删除的短语相似性:这个目标衡量所有句子中删除的短语与查询的反向相似性,如果相关上下文被移除,则会受到惩罚。
在步骤212,可以发生迭代过程,其中通过例如使用在步骤210中排名的顶部的指定数量(例如,1-5%)的概要来调整每个采样标记的概率分布,来迭代地重复步骤208-210。因此,包括在许多高排名概要(表示为“精英采样”)中的标记将具有在下一次迭代中被选择的更高概率。在精英采样中的概要的平均质量对于指定数量的连续迭代(例如十次迭代)没有改变之后,算法可以停止。为了确保概要长度,算法使用的目标之一是惩罚比L长的概要。终止时,算法输出压缩概要
本发明可以是系统、方法和/或计算机程序产品。计算机程序产品可以包括计算机可读存储介质,其上载有用于使处理器实现本发明的各个方面的计算机可读程序指令。
计算机可读存储介质可以是可以保持和存储由指令执行设备使用的指令的有形设备。计算机可读存储介质例如可以是——但不限于——电存储设备、磁存储设备、光存储设备、电磁存储设备、半导体存储设备或者上述的任意合适的组合。计算机可读存储介质的更具体的例子(非穷举的列表)包括:便携式计算机盘、硬盘、随机存取存储器(RAM)、只读存储器(ROM)、可擦式可编程只读存储器(EPROM或闪存)、静态随机存取存储器(SRAM)、便携式压缩盘只读存储器(CD-ROM)、数字多功能盘(DVD)、记忆棒、软盘、、其上存储有指令的机械编码设备、以及上述的任意合适的组合。这里所使用的计算机可读存储介质不被解释为瞬时信号本身,诸如无线电波或者其他自由传播的电磁波、通过波导或其他传输媒介传播的电磁波(例如,通过光纤电缆的光脉冲)、或者通过电线传输的电信号。而是,计算机可读存储介质是非瞬态(即,非易失性)介质。
这里所描述的计算机可读程序指令可以从计算机可读存储介质下载到各个计算/处理设备,或者通过网络、例如因特网、局域网、广域网和/或无线网下载到外部计算机或外部存储设备。网络可以包括铜传输电缆、光纤传输、无线传输、路由器、防火墙、交换机、网关计算机和/或边缘服务器。每个计算/处理设备中的网络适配卡或者网络接口从网络接收计算机可读程序指令,并转发该计算机可读程序指令,以供存储在各个计算/处理设备中的计算机可读存储介质中。
用于执行本发明操作的计算机程序指令可以是汇编指令、指令集架构(ISA)指令、机器指令、机器相关指令、微代码、固件指令、状态设置数据、或者以一种或多种编程语言的任意组合编写的源代码或目标代码,所述编程语言包括面向对象的编程语言—诸如Java,Smalltalk、C++等,以及常规的过程式编程语言—诸如“C”语言或类似的编程语言。计算机可读程序指令可以完全地在用户计算机上执行、部分地在用户计算机上执行、作为一个独立的软件包执行、部分在用户计算机上部分在远程计算机上执行、或者完全在远程计算机或服务器上执行。在涉及远程计算机的情形中,远程计算机可以通过任意种类的网络—包括局域网(LAN)或广域网(WAN)—连接到用户计算机,或者,可以连接到外部计算机(例如利用因特网服务提供商来通过因特网连接)。在一些实施例中,通过利用计算机可读程序指令的状态信息来个性化定制电子电路,例如可编程逻辑电路、现场可编程门阵列(FPGA)或可编程逻辑阵列(PLA),该电子电路可以执行计算机可读程序指令,从而实现本发明的各个方面。
这里参照根据本发明实施例的方法、装置(系统)和计算机程序产品的流程图和/或框图描述了本发明的各个方面。应当理解,流程图和/或框图的每个方框以及流程图和/或框图中各方框的组合,都可以由计算机可读程序指令实现。
这些计算机可读程序指令可以提供给通用计算机、专用计算机或其它可编程数据处理装置的处理器,从而生产出一种机器,使得这些指令在通过计算机或其它可编程数据处理装置的处理器执行时,产生了实现流程图和/或框图中的一个或多个方框中规定的功能/动作的装置。也可以把这些计算机可读程序指令存储在计算机可读存储介质中,这些指令使得计算机、可编程数据处理装置和/或其他设备以特定方式工作,从而,存储有指令的计算机可读介质则包括一个制造品,其包括实现流程图和/或框图中的一个或多个方框中规定的功能/动作的各个方面的指令。
也可以把计算机可读程序指令加载到计算机、其它可编程数据处理装置、或其它设备上,使得在计算机、其它可编程数据处理装置或其它设备上执行一系列操作步骤,以产生计算机实现的过程,从而使得在计算机、其它可编程数据处理装置、或其它设备上执行的指令实现流程图和/或框图中的一个或多个方框中规定的功能/动作。
附图中的流程图和框图显示了根据本发明的多个实施例的系统、方法和计算机程序产品的可能实现的体系架构、功能和操作。在这点上,流程图或框图中的每个方框可以代表一个模块、程序段或指令的一部分,所述模块、程序段或指令的一部分包含一个或多个用于实现规定的逻辑功能的可执行指令。在有些作为替换的实现中,方框中所标注的功能也可以以不同于附图中所标注的顺序发生。例如,两个连续的方框实际上可以基本并行地执行,它们有时也可以按相反的顺序执行,这依所涉及的功能而定。也要注意的是,框图和/或流程图中的每个方框、以及框图和/或流程图中的方框的组合,可以用执行规定的功能或动作的专用的基于硬件的系统来实现,或者可以用专用硬件与计算机指令的组合来实现。
以上已经描述了本发明的各实施例,上述说明是示例性的,并非穷尽性的,并且也不限于所披露的各实施例。在不偏离所说明的各实施例的范围和精神的情况下,对于本技术领域的普通技术人员来说许多修改和变更都是显而易见的。本文中所用术语的选择,旨在最好地解释各实施例的原理、实际应用或对市场中的技术的技术改进,或者使本技术领域的其它普通技术人员能理解本文披露的各实施例。
- 上下文感知句子压缩
- 一种融合语法信息的句子压缩方法