一种基于云平台的分布式医学影像数据存储方法
文献发布时间:2023-06-19 11:49:09
技术领域
本发明涉及大数据技术领域,尤其涉及一种基于云平台的分布式医学影像数据存储方法。
背景技术
随着信息技术以及互联网技术的普及,人们已经步入了大数据时代,大数据是指数据的量和维度均很大,数据形式丰富,种类广泛,例如文本、图像、声音、数字等等。
在医疗行业引入信息技术的同时,也是医疗行业的信息化、自动化程度不断提高,医疗数据则呈现TB甚至PB级别的增长。根据现有数据统计分析,预计2020年,医疗数据将急剧增长到35ZB(1ZB=230TB),相当于2009年数据量的44倍,于中国卫计委权威发布,截至2015年5月底,全国医疗卫生机构数达98.7万个,其中:医院2.6万个,基层医疗卫生机构92.2万个,专业公共卫生机构3.5万个,其他机构0.3万个,如何合理的管理和存储这些海量的医疗数据和繁琐的数据类型给医疗行业带来了巨大的压力。
目前医疗数据中医学影像数据占比超过90%,是医学数据非常重要的组成部分,它具有文件格式特殊(国际统一的DICOM格式)、大多都是小文件(2KB~1MB之间)、数据量大、增长速度快、保存时间长等特点,并且医学影像技术在进十多年来取得了突飞猛进的发展,新技术、新设备不断涌现,医学影像信息被数字化、数据化后呈现了丰富多样、存储量庞大的医学大数据。
根据调研,医院放射科每天的影像压缩后也有40多GB,1年约10TB,并且医学影像一般要求能存储15年,一般国内的医院都采用的是“在线-近线-离线”三级存储模式,以商用集中式存储为核心的磁盘阵列和磁带机(或光盘库)的存储模式以及采用NAS、DAS、SAN三种存储架构,属于专用网络的集中式文件系统,其固然存在高速和隔离性好的优点,但随着日时间推移,数据量的增大,在扩展上性能较差,硬件设备的成本也非常高,也很难达到医院内部甚至是区域上的共享,灵活性很差。
云计算技术的出现和兴起为处理海量医学数据提供了一条新的有效途径,其具有资源整合、高可用、高性能、易扩展等显著优势外,为数据存储、检索、加工和分析提供了新的方法非常适用于医学影像数据的长期存储和快速有效的访问。
发明内容
为了现有技术存在的上述技术缺陷,本发明提供了一种基于云平台的分布式医学影像数据存储方法,可以有效解决背景技术中的问题。
为了解决上述技术问题,本发明提供的技术方案具体如下:
本发明实施例公开了一种基于云平台的分布式医学影像数据存储方法,其特征在于:所述方法包括以下步骤:
设计云存储架构,并生成“本地-云端”两级存储模式;
根据“本地-云端”两级存储模式,构建分布式医疗影像存储架构;
构建ProxmoxVE虚拟资源环境,并针对海量医学影像文件的访问特性,在云端FastDFS上搭建Nginx;
对云端FastDFS存储进行优化,并生成医学影像数据及元数据的存储。
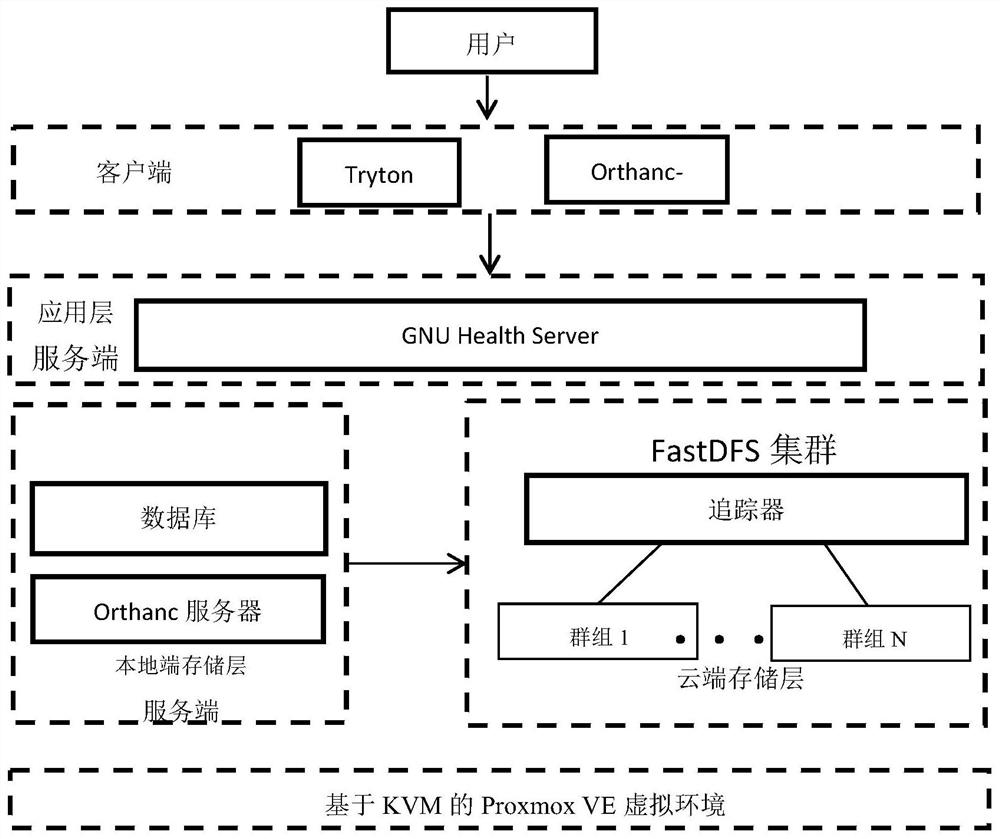
在上述任一方案中优选的是,所述云存储架构包括应用层、存储层和平台层,所述应用层包括HIS系统和PACS系统的客户端;所述存储层为本地端和云端的两级存储模式,所述本地端包括HIS server和PACS server,所述云端为FastDFS大规模分布式集群构建;所述平台层为通过虚拟化技术实现的构建在基础设施之上的虚拟平台。
在上述任一方案中优选的是,基于内存的key-value数据库系统Redis作为缓存系统搭建在Orthanc之上,Orthanc的服务端作为本地存储医学影像的服务器,用于存储近期的文件,并根据系统所定的时间阀值定期的向云端FastDFS进行数据传输。
在上述任一方案中优选的是,GNU Health包含12个模块。
在上述任一方案中优选的是,FastDFS集群由9个节点组成,并在每个节点上都搭建了主流的web服务器Nignx,其中一个Tracker Server为其他8个Storage Server的协调节点,每两个存储节点作为一组,共4组,组内相互备份。
在上述任一方案中优选的是,当有下载的请求时,FastDFS下载流程如下:
首先解析路径,获取到组号和文件ID;
根据文件ID获取元数据信息,包括:源storage ip、文件路径、名称、大小;
通过调用trunk_file_stat_ex1判断文件是否存在,存在则输出文件;
当文件不存在时,则进行有效性检查,检查项A:源storage是本机或者当前时间与文件创建时间的差距已经超过阈值,报错;检查项B:若是redirect后的场景,同样报错。
在上述任一方案中优选的是,通过对Docker容器进行虚拟化,每个容器内运行一个应用,不同的容器互相隔离,容器间也可建立通信机制。
在上述任一方案中优选的是,将Redis数据库设计为5个字典,字典(0)存放原文件的元信息,字典(1)存放缓存图像序列化的数据,字典(2)存放预测集列表,字典(3)存放病人对应的文件信息,字典(4)存放LRU列表,用于缓存替换。
在上述任一方案中优选的是,医学影像文件下载流程如下:
用户向系统发送文件下载请求;
系统根据ID遍历缓存数据索引,根据文件ID判断缓冲区是否命中该文件,若命中,则从缓冲区读取HashMap的Value,反序列化后返回给用户,对应的数据被访问次数加1,若没有命中,则执行下一步;
遍历预测集,若文件ID在预测集中,并且缓存未满,则向FastDFS的管理节点tracker server发送文件请求,得到文件后返回给用户,并将文件序列化后存储在Redis中,对应的数据被访问次数加1,若缓存已经满,则将数据中最少访问的N个数据删除,若文件ID不在预测集中,则进入下一步;
向FastDFS的管理节点tracker server发送文件下载请求。得到文件后返回给用户,对应的数据被访问次数加1;
查询是否达到预测集更新时间,若时间到,则通过访问日志根据时间是否在m年内和访问次数重新生成新的预测集;
关闭连接,文件下载结束。
在上述任一方案中优选的是,医学影像文件上传流程如下:
用户向系统发送文件上传请求;
系统根据ID遍历缓存数据索引,若存在重复ID,则返回False,否则,进入下一步;
根据ID遍历元数据索引,若存在重复ID,则返回False,否则,进入下一步;
向FastDFS的管理节点tracker server发送文件上传请求,server返回false,则系统向用户返回false,否则将数据的元信息存入元数据,向用户返回true;
关闭连接,文件上传结束。
与现有技术相比,本发明的有益效果:
本发明通过“本地-云端”两级存储模式,集成了开源HIS系统GNU Health、开源WebPACS系统Orthanc、开源分布式文件系统FastDFS,提供了一个大规模分布式医疗影像存储架构,实现了医学影像云存储服务针对医学影像的特殊格式DICOM及应用场景,并针对海量医学影像文件的访问特性,通过在FastDFS上搭建Nginx解决集群中存储节点同步延迟的问题;
针对两级存储模式的云端FastDFS存储,提出了基于Redis的医学影像存储优化,同时通过对Redis的预测集缓存策略,进一步提高了缓存命中率和医学影像的存取速率。
附图说明
附图用于对本发明的进一步理解,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。
图1是本发明医学影像存储架构图;
图2是本发明医学影像存储架构图;
图3是本发明GNU Health系统界面-HIS主要功能模块示意图;
图4是本发明Orhtanc系统界面-影像信息及图像展示图;
图5是本发明FastDFS集群示意图;
图6是本发明Fastdfs下载流程图
图7是本发明GNU Health系统界面-影像管理模块示意图;
图8是本发明医疗影像云存储架构图;
图9是本发明基于Docker的多租户架构图;
图10是本发明医学影像文件下载流程图;
图11是本发明医学影像文件上传流程图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
需要说明的是,当元件被称为“固定于”或“设置于”另一个元件,它可以直接在另一个元件上或者间接在该另一个元件上。当一个元件被称为是“连接于”另一个元件,它可以是直接连接到另一个元件或间接连接至该另一个元件上。
在本发明的描述中,需要理解的是,术语“长度”、“宽度”、“上”、“下”、“前”、“后”、“左”、“右”、“竖直”、“水平”、“顶”、“底”“内”、“外”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。
此外,术语“第一”、“第二”仅用于描述目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”的特征可以明示或者隐含地包括一个或者更多个该特征。在本发明的描述中,“多个”的含义是两个或两个以上,除非另有明确具体的限定。
为了更好地理解上述技术方案,下面将结合说明书附图及具体实施方式对本发明技术方案进行详细说明。
本发明提供了一种基于云平台的分布式医学影像数据存储方法,所述方法包括以下步骤:
步骤1,设计云存储架构,并生成“本地-云端”两级存储模式。
具体的,如图1所示,存储架构包括应用层、存储层和平台层,所述应用层包括HIS系统和PACS系统的客户端,用于向用户提供操作界面、信息管理、影像查看等功能;所述存储层为本地端和云端的两级存储模式,所述本地端包括HIS server和PACS server,用于存储和管理医院的结构化信息数据和近期的影像数据,所述云端为FastDFS大规模分布式集群构建,用于远期文件的永久性存储,存储层的数据由用户上传并会定期的从本地端上传到云端;所述平台层为通过虚拟化技术实现的构建在基础设施之上的虚拟平台,在实际操作中通过合理有效的利用服务器资源从而便于提供云服务。
进一步的,通过HIS系统GNU Health、PACS系统Orthanc和轻量级分布式文件系统FastDFS,生成“本地-云端”两级的医学数据存储模式,并搭建在云平台上,从而实现数据的永久保存和实时在线。
进一步的,基于内存的key-value数据库系统Redis作为缓存系统搭建在Orthanc之上,Orthanc的服务端作为本地存储医学影像的服务器,用于存储近期的文件,并根据系统所定的时间阀值定期的向云端FastDFS进行数据传输,本地只存一定大小的近期数据,云端则负责存储远期永久的所有数据,在实际操作中,FastDFS可实现更好的弹性扩容,充分的满足远期文件的存储需求。
步骤2,根据“本地-云端”两级存储模式,构建分布式医疗影像存储架构。
具体的,GNU Health包含12个模块,每个模块都可为系统添加一个新的功能,通过完整地安装所有模块,以实现支持HIS系统里各种业务流程以及相关的功能。
如图2和图3所示,①Modules模块进行GNU Health对所需的②模块进行选择,选择后再进入③Perform Pending Installation/Upgrade对所选模块进行安装或升级,也可根据用户所在的医院规模、使用习惯等对模块选择性的进行安装。
例如进入④Patients模块,可看到所有病人的列表,选择病人可查看病人详细信息,通过GNU Health系统获取医生、患者、机构、电子病历等信息,并通过GNU Health产生造影检查的请求,通过GNU Health可上传、查看、下载所有病人的影像检查结果,但由于GNUHealth仅支持普通格式的图片管理,进而,通过加入开源的PACS系统Orthanc,从而实现两个开源系统的接口和数据迁移,用户可以直接从GNU Health的界面进入到Orthanc的WEB端,从而进一步对DICOM文件进行操作和管理。
其中,通过SDK开发的动态库形式的插件可被导入到Orthanc服务中,插件通过注册回调函数来响应浏览器的HTTP请求,回调函数反过来可访问Orthanc数据库提取目标DICOM文件的信息。
如图4所示,通过Orthanc的WEB端查看病人的信息,不仅可以实现医学影像的图像显示,同时也会详细的列出所有DICOM Tags里的信息,包含图像里的所有详细的信息和数据,从而让用户更直接和清楚地了解到所观察影像的内容。
在一个更为具体的实施方式中,如图5所示,FastDFS集群由9个节点组成,并在每个节点上都搭建了主流的web服务器Nignx,其中仅选用一个Tracker Server为其他8个Storage Server的协调节点,每两个存储节点作为一组,共4组,组内相互备份。
每当有存入数据的操作时,每组内的启动状态、存储情况等都会上报给TrackerServer节点,根据各组的容量情况传输数据,数据会先传到组内某一个源数据服务器,上传完毕后,再进行组内同步。
Nginx是一个高性能的Web和反代理服务器,相比Apache,Nginx使用更少的资源,支持更多的并发连接,体现更高的效率。
作为反代理服务器,解决了storage的同步延迟问题,在每一台Storage Server上都部署Nginx以及FastDFS扩展模块fdfs-nginx-module,由Nginx模块对存储节点里的文件提供http下载服务,只有当存储节点找不到文件时会向源Storage Server发起redirect或proxy动作,以实现能够避免Storage之间的复制延迟而出现的问题。
搭建Nginx后的下载过程如图6所示,
当有下载的请求时,FastDFS下载流程如下:
(1)首先解析路径,获取到组号和文件ID;
(2)根据文件ID获取元数据信息,包括:源storage ip、文件路径、名称、大小等;
(3)通过调用trunk_file_stat_ex1判断文件是否存在,存在则输出文件;
(4)当文件不存在时,则进行有效性检查,检查项A:源storage是本机或者当前时间与文件创建时间的差距已经超过阈值,报错;检查项B:若是redirect后的场景,同样报错;
(5)重定向模式:配置项response_mode=redirect,此时服务端返回返回302响应码,url如下:
http://{源storage地址}:{当前port}{当前url}{参数"redirect=1"}(标记已重定向过)
(6)代理模式:配置项response_mode=proxy,该模式的工作原理如同反向代理的做法,而仅使用源storage地址作为代理proxy的host,其余部分保持不变。
如图7所示,GNU Health的①图像管理模块Imaging包括影像检查请求、影像检查请求的处理、影像检查的结果查看三个部分,通过影像检查结果模块可通过②选择患者可直接连接到Orthanc的模块界面查看影像信息。
步骤3,构建ProxmoxVE虚拟资源环境,并针对海量医学影像文件的访问特性,在云端FastDFS上搭建Nginx。
具体的,作为底层支持Promox VE的两种虚拟机技术,其中KVM(Kernel-basedVirtual Machine)是基于虚拟化扩展(Intel VT或AMD-V)的x86硬件,是Linux完全原生的全虚拟化解决方案,部分的准虚拟化支持,主要是通过准虚拟网络驱动程序的形式用于Linux和Windows客户机系统,KVM设计通过可加载的内核模块,支持广泛的客户机操作系统,LXC(Linux Containers)是一个操作系统级虚拟化环境,可运行多个独立的Linux系统在一个Linux主机控制,LXC为Linux内核是用户空间接口控制功能,Linux用户可以很容易地创建和管理系统或应用程序容器和一个强大的API和简单的工具。用户可根据自己的需求进行选择,若需要使用的是KVM,那么CPU就必须支持类似于Intel VT或者是AMD-V的硬件虚拟化技术。
如图8所示,本发明通过Proxmox VE内基于KVM技术实现的虚拟节点,从而将所有服务端和存储集群都将搭建在此平台上,用户通过Tryton和Orthanc-web客户端来进行影像信息的查看、上传、下载等操作,客户端会将命令传达给服务端,则会对服务端或云端存储层进行影像数据的相关管理操作,若为远期数据将从云端的FastDFS分布式文件系统集群获取,反之将从本地端存储层获取。
进一步的,通过SaaS(Software as a Service)模式提供HIS系统和PACS系统的所有相关的功能以及由FastDFS集群组成的云存储服务,采用的是Share Hardware的多租户架构,此模式减轻了客户构造、使用和维护软件应用的成本,此模式下,将具有共性需求的用户群体称为租户,最终用户以租户为单位租用软件,每一个租提供一个仅供试用的虚拟系统,同时,为多个租户提供软件服务,通过在租户间共享人力、设备等资源可降低成本、提高效益。
通过对Docker容器进行虚拟化,用户可以简单将Docker容器理解为一种沙盒(Sandbox)。每个容器内运行一个应用,不同的容器互相隔离,容器间也可以建立通信机制。
如图9所示,根据用户的需求可对应用层和数据层进行隔离,实现多种的多租户服务提供方式:
(1)应用层:用户可以直接通过网络客户端和网页远程地访问云端的服务器,故可以共享同一个服务端;也可以将服务端单独分配给租户,并隔离地址空间。
(2)数据层:由于本文使用的是分布式文件系统集群,可将租户的数据都放在同一个集群的不同组中,组内的子节点进行相互备份,组间无任何关联和影像;也可进一步提高隔离性和安全性,为单个租户单独提供集群和单独的地址空间。
步骤4,对云端FastDFS存储进行优化,并生成医学影像数据及元数据的存储。
具体的,当面对医院在短时间内对影像系统的高并发访问请求时,为了加快数据处理速度,避免服务器端频繁访问数据库,通过引入Redis缓存层来优化系统,将热点的医疗图像数据序列化后放入处理速度更快的Redis中,使得用户无需访问I/O代价较高的数据库就能快速得到热点数据。
在一个更为具体的实施方式中,由于FastDFS的元数据由Tracker节点管理,当系统发生CRUD(增删改查)操作时,系统会将操作写入binlog文件,记录文件元信息。
当文件成功上传后,FastDFS按照自己的自定义规则将文件重命名后返回给用户一个路径,分别由组名、磁盘、目录、新文件名组成,文件的原文件名会丢失,而且管理这样的路径也非常麻烦,对用户体验造成很大的损害。
其次,Tracker的元数据管理放在内存里,没有提供对外可操作的API,也对数据管理造成了很大困难。
针对以上“元数据管理难”的问题,本发明基于Redis的丰富数据结构生成了系统的元数据存储结构。
Redis是一个字典结构的存储系统,它当中没有表的概念,但它提供了多个用来存储数据的字典,用户可以指定将数据存储在具体的哪个字典,这与我们熟知的关系数据库实例当中可以创建多个数据库的设计类似。所以可以将字典理解为一个独立的数据库。通过设置配置文件Redis.config中的databases参数,可以设定字典的个数,默认情况下,字典个数为16。
优选的,将Redis数据库设计为5个字典,字典0存放原文件的元信息,字典1存放缓存图像序列化的数据,字典2存放预测集列表,字典3存放病人对应的文件信息,字典4存放LRU列表,用于缓存替换。
进一步的,由于数据全部放在内存中,会出现断电丢失的可能性,进而可通过快照方式对系统进行持久化,所述快照方式为在规定时间内某项操作即保存一次数据,如Save900 1的意思是在15分钟(900秒钟)内有至少一个键被更改则进行快照,Redis默认将快照数据保存在dump.rdb文件中,RDB文件是经过压缩后的文件,所以占用的空间会小于在内存中的文件大小,当数据丢失,系统可根据dump.rdb文件恢复系统。
更进一步的,医学影像文件存取流程包括影像文件下载流程和影像文件上传流程,所述影像文件下载流程如图10所示:
(1)用户向系统发送文件下载请求。
(2)系统根据ID遍历缓存数据索引,根据文件ID判断缓冲区是否命中该文件,若命中,则从缓冲区读取HashMap的Value,反序列化后返回给用户,对应的数据被访问次数加1。若没有命中,则执行下一步。
(3)遍历预测集,若文件ID在预测集中,并且缓存未满,则向FastDFS的管理节点tracker server发送文件请求。得到文件后返回给用户,并将文件序列化后存储在Redis中,对应的数据被访问次数加1。若缓存已经满,则将数据中最少访问的N个数据删除。若文件ID不在预测集中,则进入下一步。
(4)向FastDFS的管理节点tracker server发送文件下载请求。得到文件后返回给用户,对应的数据被访问次数加1。
(5)查询是否达到预测集更新时间,若时间到,则通过访问日志根据时间是否在m年内和访问次数重新生成新的预测集。
(6)关闭连接,文件下载结束。
所述影像文件上传流程如图11所示:
(1)用户向系统发送文件上传请求。
(2)系统根据ID遍历缓存数据索引,若存在重复ID,则返回False,否则,进入下一步。
(3)根据ID遍历元数据索引,若存在重复ID,则返回False,否则,进入下一步。
(3)向FastDFS的管理节点tracker server发送文件上传请求,server返回false,则系统向用户返回false,否则将数据的元信息存入元数据,向用户返回true。
(4)关闭连接,文件上传结束。
以上仅为本发明的优选实施例而已,并不用于限制本发明,尽管参照前述实施例对本发明进行了详细的说明,对于本领域的技术人员来说,其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 一种基于云平台的分布式医学影像数据存储方法
- 一种医学荧光成像影像数据分类云存储系统及其存储方法