一种用于检测钓鱼网址的方法
文献发布时间:2023-06-19 11:52:33
技术领域
本发明涉及网络安全技术领域,尤其涉及一种用于检测钓鱼网址的方法。
背景技术
钓鱼网站攻击属于社会工程攻击的一种,是指攻击者假冒合法网站的网址和内容,并通过电子邮件、二维码、即时通讯工具、域名劫持等方式和手段诱导用户访问,从而导致用户隐私泄露、身份盗窃和财产损失的一种恶意攻击行为。
近年来,伴随互联网特别是移动互联网的飞速发展,网络钓鱼攻击现象也日益严峻。据国家计算机网络应急技术处理协调中心(CNCERT)的《2019年上半年我国互联网网络安全态势》报告显示,2019年上半年,CNCERT自主监测发现约4.6万个针对我国境内网站的仿冒页面,比2018年底增长了8.2%。而在国际范围内,国际反钓鱼工作组(APWG)2019年第三季度的钓鱼活动趋势报告表明,2019年1月至9月,全球钓鱼网站数量不断增长,创2016年监测以来的新高,且9月比1月增长近100%,达到86276个。与此同时,RSA公司的网上诈骗报告显示,2018年网络钓鱼攻击已经让全球组织损失约46亿美元,而这个数字仍然在进一步增长。
以中国工商银行网址(http://www.icbc.com)为例,攻击者首先克隆工商银行一样的网站内容,并将克隆网站的网址设为http://www.1cbc.com,同时借助于其他欺骗技巧,如DNS劫持、URL劫持、二维码、网络诱骗等诱导用户访问。由于不管从网站内容和网址形式均与真实网址高度相似,使得受害者误认为是真实网站并进行登录,攻击者就可以获取受害者的用户名、登录密码、银行卡号甚至支付密码等信息,并进一步利用这些信息可以进行非法操作(如转账等操作)。近年来随着移动网络及二维码的兴起,基于二维码的新兴网络钓鱼现象更加无法察觉,进一步加剧了钓鱼网站的危害。
目前钓鱼网站检测机制方法主要可以归为五类:基于黑白名单的方案、基于特征启发式的方案、基于图形特征的方案、基于机器学习的方案、以及基于深度学习的方案。黑白名单方案主要通过维护非法URL、IP地址或者关键字列表,从而判断当前链接地址的合法性,因此无法对许多随机生成或者没有被列入黑名单的钓鱼网站进行检测,也即无法阻止零日钓鱼攻击(0day phishing attack);基于特征启发式的方案则基于钓鱼网站存在的钓鱼特征,启发式进行多重特征验证,从而判别网站的真伪,但此方案或多或少地存在假阳性,并且判断精度不足;基于图形特征的检测方法通过绘制钓鱼网址与受害者网址的链接关系图,从而判断当前网站是否是钓鱼网站,该方案的计算需要大量的时间和内存,因此计算时延较为严重;基于机器学习方法采用成熟的机器学习模型对钓鱼网站URL或网站内容进行分析,其最大的优势在于可以识别零日攻击,并且经过训练的分类器识别效率高,但最大的缺点在于必须由研究人员手动指定样本的学习特征,因此判断的精度有依赖于专家的知识,并且于不同的机器学习方法精度也不一样,合理的分类器设计也是限制了判别率提高的因素之一;基于深度学习模型的检测方法可以自主地从样本中提取特征,因此可以更充分地进行分类训练并得出更准确的分类结果。然而,深度学习模型的设计及样本数据集是否均衡,是影响深度学习方案取得高精度结果的重要因素。
现有技术中缺乏一种兼顾效率与精度的检测方法用于检测钓鱼网址。
以上背景技术内容的公开仅用于辅助理解本发明的构思及技术方案,其并不必然属于本专利申请的现有技术,在没有明确的证据表明上述内容在本专利申请的申请日已经公开的情况下,上述背景技术不应当用于评价本申请的新颖性和创造性。
发明内容
本发明为了解决现有的问题,提供一种用于检测钓鱼网址的方法。
为了解决上述问题,本发明采用的技术方案如下所述:
一种用于检测钓鱼网址的方法,应用于网址URL字符串,用于判断所述URL字符串指示的网址是否为钓鱼网址,具体包括如下步骤:S1:建立基于卷积神经网络与多头自注意网络二者并行结合的深度学习网络钓鱼网址检测分类器模型;
S2:使用预先准备的均衡的URL样本集对所述分类器模型进行训练;S3:使用训练后的所述分类器模型对未知性质的URL字符串进行判别,判断其是否为钓鱼网址。
优选地,所述分类器模型包含四层:特征嵌入层、特征学习层、特征权重学习层及分类层;所述特征嵌入层,用于预处理后的所述URL字符串形成特征矩阵并降低所述特征矩阵的矩阵维度;所述特征学习层,包括五层URL特征学习网络,采用卷积神经网络自主地学习所述特征矩阵中的特征,输出URL特征的学习结果;所述特征权重学习层,包括五层URL特征权重学习网络,采用多头自注意网络自主地学习所述特征矩阵中URL特征的权重,输出URL特征权重的学习结果;所述分类层,用于整合所述特征学习层、以及所述特征权重学习层的输出结果,从而生成最终判别结果。
优选地,对所述URL字符串的预处理包括:对所述URL字符串的长度进行限制使其总长度不超过100个字符;对上述长度限制后的所述URL字符串采用独热编码进行编码;对所述URL字符串长度不足100个字符的,采用独热编码后,在整体编码在其前方补齐若干个0,缺省映射,使URL编码长度达到100。
优选地,所述特征嵌入层将所述URL字符串预处理后,转化为97*100的特征矩阵,并降低矩阵维度至64*100,具体包括:首先建立97*100且元素全为0的矩阵,将独热编码的0-96个编码视为行,所述URL字符串的独热编码串看成是列;对于URL独热编码串每一个编码,将编码+1所对应的行、当前编码在编码串中的顺序位置所对应列的值置为1,即形成所述URL的特征矩阵,即:
其中,L为字符串长度,格式化后L=100;所述特征矩阵的大小为97*100;将以上97*100的特征矩阵维度降低至64*100,即将
其中,
优选地,所述特征学习层中每一层所述URL特征学习网络由卷积层、残留层、全连接层和残留层在内的4层构成,具体设计如下:所述卷积层中有5个核,用于接受所述特征矩阵的输入或者上一层网络输出的结果,并使用最大池从5个特征图中选择特征;在所述卷积层之后提供一个所述残留层,用于将所述卷积层的输入与所述卷积层的输出相加;
所述全连接层将所述残留层的输出结果进行线性变换:
y=max(0,w
其中,x是所学习到的URL特征矩阵,W
优选地,所述特征权重学习层包括的每一层URL特征权重学习网络包含有多头自注意层、残留层、全连接层以及残留层四层,具体设计如下:所述多头自注意层,用于接受所述特征矩阵的输入或者上一层网络输出的结果,将输入的所述特征矩阵复制3份,分别赋予给多头自注意模型所需的三个参数,用于自主地学习所述特征矩阵的特征权重;所述残留层,用于将所述多头自注意层的输出与输入叠加;所述全连接层将所述残留层的输出结果进行线性变换;所述残留层将所述全连接层的输入与输出叠加,并输出结果。
优选地,所述分类层包括多头自注意层、残留层及全连接层、残留层以及全连接层连接的五层网络,具体设计如下:所述多头自注意层将经所述特征学习层输出结果、所述特征权重学习层的输出结果分别作为所述多头自注意层的三个参数的赋值;所述残留层将所述多头自注意层的输出与所述特征学习层的结界叠加;所述全连接层将所述残留层的输出结果进行线性变换;所述残留层使用以上所述全连接层的输出、以及上一个所述残留层的输出作为自身的输入进一步计算结果;所述全连接层将上一层的结果进行变换,并采用Sigmoid激活函数将输出结果转换成0到1之间的浮点数;Sigmod激活函数为:
其中,x是所学习到的URL特征矩阵,W
Sigmoid函数输出结果介于0到1之间,如果结果大于或等于0.5,则可以判别输入的所述URL字符串为合法网址;否则,则被判别为钓鱼网址:
优选地,所述均衡的URL样本集包括一定数量的合法网址作为正样本和钓鱼网址样本作为负样本、且二者数量一致。
优选地,使用预先准备的均衡的URL样本集对所述分类器模型进行训练,具体步骤包括:将所述均衡的URL样本集进行编码预处理后作为所述分类器模型的输入,并将所述均衡的URL样本集中URL字符串的性质赋予输出结果,即当所述URL字符串为合法网址,输出结果为1;当所述URL字符串为钓鱼网址,输出结果为0。
优选地,训练后的所述分类器模型对所述未知性质的URL字符串进行分类并生成输出结果,若输出结果大于等于0.5,则表明所述未知性质的URL字符串为合法网址;若输出结果小于0.5则为钓鱼网址。
本发明的有益效果为:提供一种用于检测钓鱼网址的方法,通过深度学习网络学习网址URL字符串的特征及权重,从而判断网站是否为钓鱼网站,并且特征学习网络和特征权重学习网络二者可以并行进行,有效的节省了处理时间,具有准确率高、判别时间短的特点。
进一步地,本发明首次将多头自注意网络引入到钓鱼检测场景中,与卷积神经网络并行结合处理,大大加快了处理效率。
再进一步地,本发明仅需以目标网址的URL字符串作为输入,即可获得高准确率及高效率的判别结果,适用于大型网络实时检测并阻止钓鱼网站对网络内部用户的侵害。
附图说明
图1是本发明实施例中一种用于检测钓鱼网址的方法的示意图。
图2是本发明实施例中一种用于检测钓鱼网址的方法的流程示意图。
图3是本发明实施例中一种用于检测钓鱼网址的分类器模型的示意图。
图4是本发明实施例中网址转化为特征矩阵的示意图。
图5是本发明实施例中一种用于检测钓鱼网址的分类器模型中特征学习层的结构示意图。
图6是本发明实施例中一种用于检测钓鱼网址的分类器模型中特征权重学习层的结构示意图.
图7是本发明实施例中一种用于检测钓鱼网址的分类器模型中分类层的结构示意图。
具体实施方式
为了使本发明实施例所要解决的技术问题、技术方案及有益效果更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
需要说明的是,当元件被称为“固定于”或“设置于”另一个元件,它可以直接在另一个元件上或者间接在该另一个元件上。当一个元件被称为是“连接于”另一个元件,它可以是直接连接到另一个元件或间接连接至该另一个元件上。另外,连接既可以是用于固定作用也可以是用于电路连通作用。
需要理解的是,术语“长度”、“宽度”、“上”、“下”、“前”、“后”、“左”、“右”、“竖直”、“水平”、“顶”、“底”、“内”、“外”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明实施例和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。
此外,术语“第一”、“第二”仅用于描述目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”的特征可以明示或者隐含地包括一个或者更多该特征。在本发明实施例的描述中,“多个”的含义是两个或两个以上,除非另有明确具体的限定。
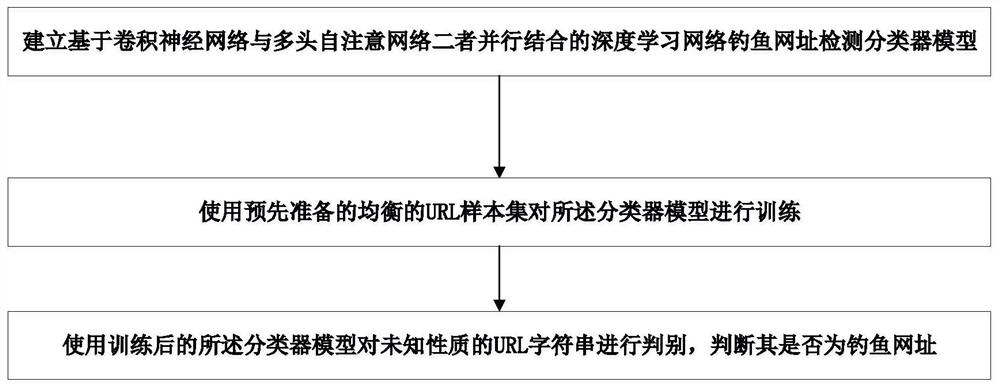
如图1所示,本发明提供一种用于检测钓鱼网址的方法,应用于网址URL字符串,用于判断所述URL字符串指示的网址是否为钓鱼网址,具体包括如下步骤:
S1:建立基于卷积神经网络与多头自注意网络二者并行结合的深度学习网络钓鱼网址检测分类器模型;
S2:使用预先准备的均衡的URL样本集对所述分类器模型进行训练;
S3:使用训练后的所述分类器模型对未知性质的URL字符串进行判别,判断其是否为钓鱼网址。
本发明通过卷积神经网络自主学习URL字符串特征,多头自注意网络学习特征权重,从而判断网站是否为钓鱼网站,并且二者可以并行进行,有效的节省了处理时间,具有高准确率、高效率的特点。
传统基于机器学习的方案,需要专家手动指定样本特征,如URL长度、HTML内容、网页中的链接数量等,因此样本特征学习的准确率依赖于专家的知识;而基于深度学习的模型,尽管不依赖于专家的知识指定样本特征,但是无法区分样本特征的权重,因此判断准确率不足;本发明结合了卷积神经网络可以自主学习样本特征、多头自注意网络可以学习字符串样本特征权重的特点,具有高效准确的优势。
进一步地,本发明首次将多头自注意网络引入到钓鱼检测场景中,与卷积神经网络并行结合处理,大大加快了处理效率。
再进一步地,本发明仅需以目标网址的URL字符串作为输入,即可获得高准确率及高效率的判别结果,适用于大型网络实时检测并阻止钓鱼网站对网络内部用户的侵害。
如图2所示,是本发明中一种用于检测钓鱼网址的方法的流程示意图。本发明设计基于卷积神经网络(CNN)和多头自注意(MHSA)的钓鱼网址分类器模型,然后基于这个分类器模型进行钓鱼网址检测,方法包括四个阶段:URL样本集准备阶段、URL预处理阶段、模型训练阶段以及模型检测阶段。URL样本准备阶段收集并准备大量钓鱼网址和大致等量的合法网址作为样本集;URL预处理阶段用于对输入的URL字符串进行格式化,并采用独热编码进行编码;模型训练阶段使用样本集对本分类器模型进行训练;模型检测阶段采用训练后的模型对未知性质的URL进行判别其是否为钓鱼网址。
在本发明的一种实施例中,URL样本集准备阶段需要准备收集已知性质网站的URL样本组成均衡的URL样本集,其包括一定数量的合法网址作为正样本和钓鱼网址样本作为负样本且二者数量一致。同时,样本集中的样本数量越多,分类器模型训练得越充分,分类判别的准确率将越高。
可以理解的是,此处的均衡是指正样本和负样本的数量基本一致,只要相差不在10倍以内即可认为是均衡。
在本发明的一种实施例中,对于现实中钓鱼网址样本较少,而正常网址样本较多的情况所造成的正负样本集比例相差较大的非均衡样本集,本发明采用对抗生成网络(Generative Adversarial Network,GAN)生成钓鱼网址。本发明生成钓鱼网址样本具体方法是:
典型的GAN由两部分组成,生成器G和分类器D均为神经网络,前者接收噪声z来生成模拟数据,后者则尽可能地将模拟生成的数据和真实数据区分开来。通过不断地博弈,最终生成器G将生成足够多逼真的模拟数据,以至于分类器D无法把它和真实数据区开来。G的训练过程如下:
1)通过高斯随机分布生成m个数据,并形成数据集Z,其中z
2)输入Z得到G(Z),其为97维向量集。对于向量集中的每一个向量,97维中最大的元素置为1,其余置为0,这使得任一个向量均能表示一个URL。
3)使用真实钓鱼URL样本向量集(矩阵)X,其中x
4)使用X和G(Z)训练分类器D,并通过提升其随机梯度来更新D:
通过高斯随机分布生成一些噪声数据形成集合Z,并将Z输入生成G得到G(Z),同时通过提升其随机梯度来更新G:
交替训练D和G,如果D的准确率保持0.5,训练就可以结束,这时意味着D无法区分真实世界的网络钓鱼URL和自动生成的网络钓鱼网址,此时G可以用来生成网络钓鱼URL。
在一种更为具体的实施例中,从5000Best Websites
在一种具体的实施例中,使用预先准备的均衡的URL样本集对所述分类器模型进行训练包括:
将所述均衡的URL样本集进行编码预处理后作为分类器模型的输入,并将均衡的URL样本集中URL字符串的性质赋予输出结果,即当URL字符串为合法网址,输出结果为1;当URL字符串为钓鱼网址,输出结果为0。
训练后的分类器模型对未知性质的URL字符串进行分类并生成输出结果,若输出结果大于等于0.5,则表明未知性质的URL字符串为合法网址;若输出结果小于0.5则为钓鱼网址。
如图3所示,是本发明中一种用于检测钓鱼网址的分类器模型的示意图。本发明设计的基于卷积神经网络(CNN)和多头自注意(MHSA)的钓鱼网址分类器模型包含四层:特征嵌入层、特征学习层、特征权重学习层以及分类层。
特征嵌入层,用于预处理后的所述URL字符串形成特征矩阵并降低所述特征矩阵的矩阵维度;
特征学习层,包括五层URL特征学习网络,用于采用卷积神经网络自主地学习所述特征矩阵中的特征,输出URL特征学习的结果;
特征权重学习层,包括五层URL特征权重学习网络与特征学习层并行处理,采用多头自注意网络自主地学习所述特征矩阵中特征的权重,输出URL特征权重学习的结果;
分类层,用于整合所述特征学习层及所述特征权重学习层的输出结果,生成最终判别结果。
在本发明的一种实施例中,对URL字符串的预处理包括:
对URL字符串的长度进行限制使其总长度不超过100个字符;
对上述长度限制后的所述URL字符串采用独热编码进行编码;
对所述URL字符串长度不足100个字符的,采用独热编码后,在整体编码在其前方补齐若干个0,缺省映射,使URL编码长度达到100。
具体过程如下:
(1)若URL字符串的长度超过100个字符,则统一取URL字符串前100个字符进行截断:
(2)对长度限制后的URL字符串的编码采用独热编码(one-hot encoding)映射方案,将URL字符串S
表1独热编码映射关系
例如,对于URL字符串“http://”中,“h”对应8,“t”对应20,“p”对应16,“:”对应69,“/”对应72,整个字符串就对应(8,20,20,16,69,72,72)。
例如,网址“http://...com”若长度超过100,则直接截断前100个字符;然后使用独热编码对字符串中每一个字符进行替换,即:h->8,t>20,p->20,……最终使其变成一个一维数组(8,20,20,16,69,72,72,…,3,15,13)。
本发明中,分类器训练阶段选择事先准备好URL样本集,提取每一个URL字符串,按预处理阶段处理后对分类器模型进行训练。训练后的分类器就可以对未知性质的URL字符串进行判断,最终结果将输出为0到1之间的浮点数,对于[0.5,1]的结果将视为正常网址,而对于[0,0.5)的结果将视为钓鱼网址。
可以理解的是,本发明中首先对样本集进行均衡,之后对URL字符串进行预处理,后采用独热编码将URL转化为特征矩阵,之后将特征矩阵分别输入到CNN和MHSA相结合的网络,以分别获得URL特征和URL特征权重,最后采用多头自注意力网络,综合二者的数据,生成最终判断结果。
值得说明的是,URL截断最佳长度设置为100是经实验计算得出,不得将其视为对本发明的限制,长度数值的改变不应作为区分本发明的特征,可以根据具体情况作出改变。可以理解的是,当URL字符串长度超过100时,会影响分类器模型的处理效率,并且对判断的精度贡献不是特别明显,而字符串截断长度太短则会明显影响判断分类的精度。所以,在本发明中当URL字符串长度超过100时会作截断处理,当不足100时,将在编码后的串前面补0凑至长度100。
本发明中,不论是使用样本URL字符串进行训练还是对未知性质的URL进行判别,经预处理后,即将进入本分类器模型的特征嵌入层。该层将编码预处理后的URL字符串转化97*100的特征矩阵,再降低其矩阵维度至64*100,从而便于神经网络模型处理。因为URL字符串的长度是100,映射表的长度是97;结合下面的转化矩阵可知,对于URL里的每个字符,将它看成一列,将对应字符标1,就形成了97*100的特征矩阵;因为模型只能处理固定的矩阵,并且只能处理行数是2n的矩阵,故将原97*100的稀疏矩阵降维至64*100。在本发明的一种实施例中,特征嵌入层将所述预处理后的URL字符串转化为97*100的特征矩阵,并予以降低矩阵维度至64*100,具体包括:
首先建立97*100且元素全为0的矩阵,将独热编码的0-96视为行,URL字符串的独热编码串看成是列。对于URL独热编码串每一个编码,将(编码+1)所对应的行、将当前编码在编码串中的顺序位置所对应列的元素值置为1,即形成所述URL的特征矩阵,即::
具体地,将URL字符串中0-96的编码映射关系当作列,若某字母出现时,其坐标对应的位置记为1,而这一列的其余96个位置填充0,从而将URL字符串中的每个字母变换成长度为97的一维数组,比如小写字母“c”就可以表示为g’=(0,0,0,1,0…0,0,0)。
如图4所示,网址“
为了便于统一处理,对于特征矩阵中字符串长度不足100的字符串,特征嵌入层还需要为该特征矩阵补充100-L含0列,使特征矩阵的列数达到100;
其中,L为字符串长度,格式化后L=100。所述特征矩阵的大小为97*100。
URL字符串所形成97*100的特征矩阵因含有大量的0,因此为稀疏矩阵,这使得URL字符串中字符之间关系在空间和语义上变得不明显,同时深度学习模型也只能处理2
其中,
之后,分类器模型分别将特征矩阵输入5层网络的特征学习层和5层网络的特征权重学习层进行处理,由其分别学习特征和特征权重。
如图5所示,是本发明分类器模型中特征学习层的结构示意图。特征学习层中每一层URL特征学习网络由卷积层(Convolutional Layer)、残留层(Residual Layer)、全连接层(Full Connected Layer)在内的4层构成,具体设计如下:
卷积层中有5个核(Kernel),用于接受特征矩阵的输入或者上一层网络输出的结果,并使用最大池(Max Pooling)从5个特征图中选择特征;
在卷积层之后提供一个残留层,用于将卷积层的输入与卷积层的输出相加;用于解决学习精度退化问题。
全连接层将所述残留层的输出结果进行线性变换:
y=max(0,w
其中,x是所学习到的URL特征矩阵,W
为了避免精度退化问题,最后一个所述残留层将所述全连接层的输入与输出相叠加后,再输出结果。
可以理解的是,这里仅显示了特征学习层五层中一层的结构,特征矩阵经过五层的处理后将会输出特征学习的结果。特征学习层层数的可以依据具体情况改变,比如多于或少于5层。
如图6所示,是本发明分类器模型中特征权重学习层的结构示意图。特征权重学习层包括的每一层URL特征权重学习网络包含有多头自注意层(Multi-head Self-AttentionLayer)、残留层(Residual Layer)、全连接层(Full Connected Layer)以及残留层四层,具体设计如下:
多头自注意层,用于接受所述特征矩阵的输入或者上一层网络输出的结果,将输入的特征矩阵复制3份,分别赋予给多头自注意模型所需的三个参数,同时
在一种具体的实施例中,该层设置头的数量为8,用于自主地学习所述特征矩阵的特征权重;可以理解的是,多头自注意层进行学习的公式参数,是公认熟知公式,三个参数为Q、K、V,此处不作赘述。
残留层,用于将所述多头自注意层的输出与输入叠加;以解决精度退化问题。
全连接层将所述残留层的输出结果进行线性变换;
为避免精度退化,最后的所述残留层将所述全连接层的输入与输出叠加,并输出结果。
可以理解的是,这里仅显示了特征权重学习层五层中一层的结构,特征权重学习层的层数的可以依据具体情况改变,比如多于或少于5层。
如图7所示,是本发明分类器模型中分类层的结构示意图。分类层包括多头自注意层、残留层及全连接层、残留层以及全连接层连接的五层网络,具体的:
多头自注意层将经特征学习层输出结果(F-output)、特征权重学习层的输出结果(A-output),分别作为本层三个参数Q(A-output)、K(A-output复制),V(F-output)的赋值;
残留层将多头自注意层的输出与所述特征学习层的结界叠加;从而消除精度退化问题。
全连接层将残留层的输出结果进行线性变换;
残留层使用以上全连接层的输出、以及上一个残留层的输出作为自身的输入进一步计算结果;,从而消除精度退化问题。
最后的所述全连接层将上一层的结果进行变换,并采用Sigmoid激活函数将输出结果转换成0到1之间的浮点数,Sigmod激活函数为:
其中,x是所学习到的URL特征矩阵,W
本发明从“5000best website”网站(http://5000best.com/websites/)上获取了68030个正常网址,从PhishTank网站(https://www.phishtank.com)获取了12003个钓鱼网址,将其分为5个训练集对本模型进行训练。训练数据集具体情况如下:
训练之后的本发明所述分类模型,在正确率(Acc)、假正类率(FPR)、召回率(Rec)、精确率(Pre)、F1五大指标上取得的分类结果如下:
注:FPR值越小越好,其他指标值越大越好
从以上实验结果表明,在现实非均衡数据样本集上,本模型在最具有代表性的正确率Acc指标上获得了97.2%的最佳成绩,而平均正确率也达到95.6%。
本申请实施例还提供一种控制装置,包括处理器和用于存储计算机程序的存储介质;其中,处理器用于执行所述计算机程序时至少执行如上所述的方法。
本申请实施例还提供一种存储介质,用于存储计算机程序,该计算机程序被执行时至少执行如上所述的方法。
本申请实施例还提供一种处理器,所述处理器执行计算机程序,至少执行如上所述的方法。
所述存储介质可以由任何类型的易失性或非易失性存储设备、或者它们的组合来实现。其中,非易失性存储器可以是只读存储器(ROM,Read Only Memory)、可编程只读存储器(PROM,Programmable Read-Only Memory)、可擦除可编程只读存储器(EPROM,ErasableProgrammable Read-Only Memory)、电可擦除可编程只读存储器(EEPROM,ElectricallyErasable Programmable Read-Only Memory)、磁性随机存取存储器(FRAM,FerromagneticRandom Access Memory)、快闪存储器(Flash Memory)、磁表面存储器、光盘、或只读光盘(CD-ROM,Compact Disc Read-Only Memory);磁表面存储器可以是磁盘存储器或磁带存储器。易失性存储器可以是随机存取存储器(RAM,Random Access Memory),其用作外部高速缓存。通过示例性但不是限制性说明,许多形式的RAM可用,例如静态随机存取存储器(SRAM,Static Random Access Memory)、同步静态随机存取存储器(SSRAM,SynchronousStatic Random Access Memory)、动态随机存取存储器(DRAM,Dynamic Random AccessMemory)、同步动态随机存取存储器(SDRAM,Synchronous Dynamic Random AccessMemory)、双倍数据速率同步动态随机存取存储器(DDRSDRAM,Double Data RateSynchronous Dynamic Random Access Memory)、增强型同步动态随机存取存储器(ESDRAMEnhanced Synchronous Dynamic Random Access Memory)、同步连接动态随机存取存储器(SLDRAM,Sync Link Dynamic Random Access Memory)、直接内存总线随机存取存储器(DRRAM,Direct Rambus Random Access Memory)。本发明实施例描述的存储介质旨在包括但不限于这些和任意其它适合类型的存储器。
在本申请所提供的几个实施例中,应该理解到,所揭露的系统和方法,可以通过其它的方式实现。以上所描述的设备实施例仅仅是示意性的,例如,所述单元的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,如:多个单元或组件可以结合,或可以集成到另一个系统,或一些特征可以忽略,或不执行。另外,所显示或讨论的各组成部分相互之间的耦合、或直接耦合、或通信连接可以是通过一些接口,设备或单元的间接耦合或通信连接,可以是电性的、机械的或其它形式的。
上述作为分离部件说明的单元可以是、或也可以不是物理上分开的,作为单元显示的部件可以是、或也可以不是物理单元,即可以位于一个地方,也可以分布到多个网络单元上;可以根据实际的需要选择其中的部分或全部单元来实现本实施例方案的目的。
另外,在本发明各实施例中的各功能单元可以全部集成在一个处理单元中,也可以是各单元分别单独作为一个单元,也可以两个或两个以上单元集成在一个单元中;上述集成的单元既可以采用硬件的形式实现,也可以采用硬件加软件功能单元的形式实现。
本领域普通技术人员可以理解:实现上述方法实施例的全部或部分步骤可以通过程序指令相关的硬件来完成,前述的程序可以存储于一计算机可读取存储介质中,该程序在执行时,执行包括上述方法实施例的步骤;而前述的存储介质包括:移动存储设备、只读存储器(ROM,Read-Only Memory)、随机存取存储器(RAM,Random Access Memory)、磁碟或者光盘等各种可以存储程序代码的介质。
或者,本发明上述集成的单元如果以软件功能模块的形式实现并作为独立的产品销售或使用时,也可以存储在一个计算机可读取存储介质中。基于这样的理解,本发明实施例的技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可以是个人计算机、服务器、或者网络设备等)执行本发明各个实施例所述方法的全部或部分。而前述的存储介质包括:移动存储设备、ROM、RAM、磁碟或者光盘等各种可以存储程序代码的介质。
本申请所提供的几个方法实施例中所揭露的方法,在不冲突的情况下可以任意组合,得到新的方法实施例。
本申请所提供的几个产品实施例中所揭露的特征,在不冲突的情况下可以任意组合,得到新的产品实施例。
本申请所提供的几个方法或设备实施例中所揭露的特征,在不冲突的情况下可以任意组合,得到新的方法实施例或设备实施例。
以上内容是结合具体的优选实施方式对本发明所做的进一步详细说明,不能认定本发明的具体实施只局限于这些说明。对于本发明所属技术领域的技术人员来说,在不脱离本发明构思的前提下,还可以做出若干等同替代或明显变型,而且性能或用途相同,都应当视为属于本发明的保护范围。
- 一种用于检测钓鱼网址的方法
- 通过远程验证并使用凭证管理器和已记录的证书属性来检测网址转接/钓鱼方案中对SSL站点的DNS重定向或欺骗性本地证书的方法