一种基于超大数据量的数据权限计算与碰撞方法
文献发布时间:2024-04-18 20:01:30
技术领域
本发明涉及大数据处理的技术领域,尤其是涉及一种基于超大数据量的数据权限计算与碰撞方法。
背景技术
随着软件行业的日益发展,软件项目所涉及的领域越来越多,但是在众多的软件项目中,万变不离其宗的重要属性就是这个软件中所拥有的数据,因此数据治理、数据的管控,几乎成为每一个软件应用不可或缺的一部分,这其中数据权限的管控显得尤为重要,所谓数据权限,就是依托某种规范或者软件开发者根据事先约定的规则,在数据产生的过程中,来给数据打上标识,后续在使用数据的时候,根据数据所拥有的标识作为判断标准,精准的获取当前使用过程中所需要用到的数据。
传统的软件工程,在解决数据权限的这些问题的时候,大多只是使用了简单基本的内容关联方式,也就是在用户组织层面,将人与组织的对应关系通过数据主键的关联关系保存下来,在使用的过程中,根据这些关联来判断某个组织与某个人的关系。在有限的数据下,使用这种配置化的方式这是无可厚非的,但是在极大数据量(此处的极大,以10亿条数据为基准)的情况之下,我们不可能手动维护每一个数据的归属标识,并且大数据在关联查询中带来的极大计算延迟在软件领域也是不可接受的(通常行业内约定,一次请求后,响应的最长时间不能超过3秒),这中间还会包括部分的网络耗时,所以留给数据计算的时间将会更少。
发明内容
为了高效准确的判断数据权限,并且减少数据间的碰撞,本发明提供一种基于超大数据量的数据权限计算与碰撞方法。
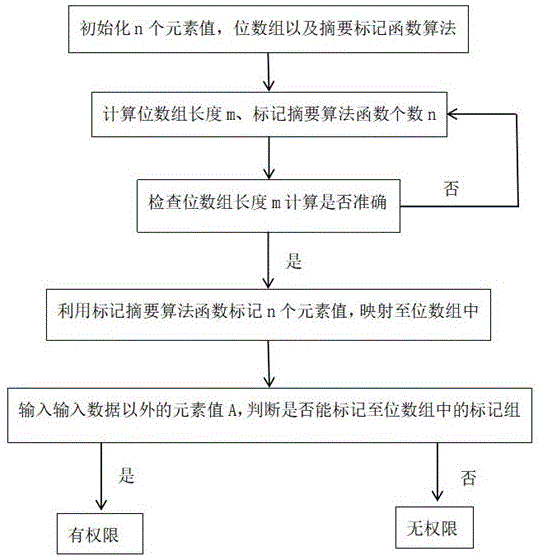
第一方面,一种基于超大数据量的数据权限计算与碰撞方法,包括:
S1:初始化一组数据,所述一组数据内有n个元素值;
S2:预制位数组以及标记摘要算法函数,计算位数组长度m,计算标记摘要算法函数个数 k;
S3:利用n个元素值以及k个标记摘要算法函数反推检查位数组长度m是否正确,如果正确,则进行下一步,如果不正确,则返回S2;
S4:利用k个标记摘要算法函数将每个元素值均标记至位数组中,形成标记组,其余位数组中未标记部位形成空白组;
S5:输入数据以外的元素值A,判断元素值A是否能标记至位数组中的标记组,输出结果。
进一步的,所述预制位数组,计算位数组长度m,具体为:
;
其中,n为元素值个数;m为位数组的长度;P为人为设定的预期误判率。
进一步的,所述计算标记摘要算法函数个数 k,具体为:
;
其中,n为元素值个数;m为位数组的长度。
进一步的,所述利用n个元素值以及k个标记摘要算法函数反推检查位数组长度m是否正确,具体为:
;
将n为元素值个数,P为人为设定的预期误判率以及标记摘要算法函数个数 k带入公式,得到m值,如果该m值与步骤2中的m值相同,则进行下一步,如果不相同,则返回S2。
进一步的,所述标记摘要算法函数包括:SHA-256算法、CityHash算法、位偏移标记算法以及位操作运算算法,根据所述k值,按顺序选取四个算法中的k个算法完成步骤4。
进一步的,所述利用k个标记摘要算法函数将每个元素值均标记至位数组中,具体的:
一个元素值经过k个标记摘要算法函数形成k个标记,n个元素值经过k个标记摘要算法函数形成n*k个标记,将n*k个标记值映射至m个位中;
每一个标记值映射到一个位数组中的位,位数组中的位有对应标记值映射后变为1,未被映射的为0,变为1的位组成标记组,其余位数组中未标记部位形成空白组。
进一步的,所述输入数据以外的元素值A,判断元素值A是否能标记至位数组中的标记组,输出结果,具体为:
在初始化的数据范围外选取一个元素值A,利用相同的k个标记摘要算法函数进行标记,形成k个标记值,映射至位数组中,如k个标记值均映射在位数组中标记组内,则数据值A有权限;否则,没有权限。
第二方面,一种基于超大数据量的数据权限计算与碰撞系统,包括:
初始化模块,被配置为,初始化一组数据,预制位数组以及标记摘要算法函数;
核检判断模块,被配置为,利用n个元素值以及k个标记摘要算法函数反推检查位数组长度m是否正确;
标记模块,被配置为,利用k个标记摘要算法函数将每个元素值均标记至位数组中,形成标记组,其余位数组中未标记部位形成空白组;
权限判别模块,被配置为,输入数据以外的元素值A,判断元素值A是否能标记至位数组中的标记组,输出结果。
第三方面,一种计算机可读存储介质,其中存储有多条指令,所述指令适于由终端设备的处理器加载并执行如权利要求1所述的一种基于超大数据量的数据权限计算与碰撞方法。
第四方面,一种终端设备,包括处理器和计算机可读存储介质,处理器用于实现各指令;计算机可读存储介质用于存储多条指令,所述指令适于由处理器加载并执行一种基于超大数据量的数据权限计算与碰撞方法。
综上所述,本发明具有如下的有益技术效果:
本发明通过一种基于超大数据量的数据权限计算与碰撞方法,预先计算得到一个位数组,用于后期元素值映射后进行对照,且该位数组的长度,不宜过长,过长会增大判断时间,也不宜过短,过短会使数据出现碰撞。
该方案不但确定位数组的长度,还利用4个标记摘要算法函数对元素值进行标记,大大的提高了标记的概率,将标记值映射至位数组中时,大大降低了碰撞的概率。
附图说明
图1是本发明一种基于超大数据量的数据权限计算与碰撞方法的流程图。
图2是本发明实施例2中元素值对应值位数组中的表示图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。
本发明实施例公开一种基于超大数据量的数据权限计算与碰撞方法。
实施例1
参照图1,本实施例的一种基于超大数据量的数据权限计算与碰撞方法,包括:
S1:初始化一组数据,所述一组数据内有n个元素值;
S2:预制位数组以及标记摘要算法函数,计算位数组长度m,计算标记摘要算法函数个数 k;
S3:利用n个元素值以及k个标记摘要算法函数反推检查位数组长度m是否正确,如果正确,则进行下一步,如果不正确,则返回S2;
S4:利用k个标记摘要算法函数将每个元素值均标记至位数组中,形成标记组,其余位数组中未标记部位形成空白组;
S5:输入数据以外的元素值A,判断元素值A是否能标记至位数组中的标记组,输出结果。
具体包括以下步骤:
第一步,初始化一组数据,其中一组数据内有n个元素值,n大于十亿,提前测算即使该方案适用于大数据的情况。
第二步,预制位数组,该位数组设置有多个位,每个位的长度都为1,位数组的长度,即为位数组的位数。利用初始化的元素值的个数n以及期望的误判率p计算位数组长度m,具体为:
;
其中,误判率为人为设定的,是工作人员希望的,能够达到的误判值。
得到位数组长度后,需要将元素值都映射至位数组中,形成一个待用的数据库,元素值采用标记摘要算法函数进行标记后,再进行映射,有效的使元素值扩展到大数据下的标记值,降低后续出现错误的概率,且通过标记值进行判断权限,速度相较于直接采用元素值对比更快,有效的降低了大数据运算的速度。
标记摘要算法函数中有四个,有两个现有哈希算法以及两个自编程的特定算法完成,分别是位偏移标记算法、位操作运算算法、SHA-256算法以及CityHash算法。
一、位偏移标记算法的基本流程为:
1.将初始哈希值初始化为种子值(seed),种子值通常是一个随机数,用于初始化哈希算法以增加其随机性。
2.将代码迭代遍历输入的键(key)中的每个字节。
3.在循环中,代码将当前哈希值 hash 与输入字节 byte 进行一系列运算,包括乘法和按位异或(XOR)操作。这些运算用于混合当前哈希值和输入字节的值。
4.将当前哈希值与输入键的长度 length 进行按位异或运算,以进一步混合哈希值。
5.将哈希值右移 r 位,然后再与原哈希值进行按位异或运算,这个操作是为了更均匀地混合哈希值的位。
6.将哈希值乘以一个常数 m,以进一步混合哈希值。
7.再次将哈希值右移 r 位,然后与原哈希值进行按位异或运算,以进一步混合哈希值。
最终,hash 的值将作为哈希值返回。实现了一种快速散列函数,适用于将输入数据映射到一个哈希值。
二、位操作运算算法的基本流程为:
1.将初始哈希值 hash 初始化为种子值seed,并添加两个常数 PRIME32_1 和PRIME32_2。这些常数用于增加哈希算法的随机性和散列性。
2.代码将迭代遍历输入数据中的每个4字节(32位)的块。
3.在循环中,代码将当前哈希值 hash 增加当前处理的4字节块 chunk 乘以PRIME32_2。这个操作将输入数据的每个块混合到哈希值中。
4.将哈希值左移13位,然后与右移19位的哈希值进行按位或运算。这个操作是为了进一步混合哈希值的位。
5.哈希值与常数 PRIME32_1 相乘,以进一步混合哈希值。
6.最后,哈希值增加输入数据的长度 length。
最终,hash 的值将作为哈希值返回。
三、SHA-256算法的基本流程为:
1.数据预处理
SHA256算法对输入数据进行预处理,以确保输入数据的长度是512 位的整数倍。如果不是,则需要在末尾添加一定数量的填充位,使得输入数据的长度满足要求,填充位的数量取决于数据长度。
2.分块
将预处理后的数据分成若干个512位的块。每个块又分为16 个32位的字,用来进行后续的计算。
3.初始化
SHA256 算法使用一个256位的初始哈希值来进行计算。该初始哈希值是由SHA256标准定义的固定值,可以看作是SHA256 算法的种子。
4.迭代计算
对于每个512位的数据块,SHA256算法会进行64轮的迭代计算,分为4个阶段:
(1)消息扩展
在该阶段中,SHA256算法会将512位的数据块扩展为64 个32位字,以便后续计算使用。
(2)压缩函数
SHA256 算法使用一种称为“SHA256压缩函数”的算法来对输入数据进行处理。该函数接受256位的当前哈希值和512位的数据块作为输入,输出一个新的256位哈希值。
(3)更新哈希值
SHA256 算法会将当前的哈希值更新为压缩函数的输出值。
(4)处理下一个块
SHA256 算法会将当前处理的512位数据块移动到下一个块,并继续进行迭代计算,直到处理完所有的数据块。
5.输出结果
当SHA256 算法处理完所有的数据块后,最终的哈希值就是SHA256 算法的输出结果。哈希值的长度为256位,可以用于验证数据的完整性和真实性。
四、CityHash算法的基本流程为:
1.字符串划分:首先将输入的字符串按照固定的规则进行划分,将其分成若干个小段,每段的长度为16 字节。
2.哈希运算:对每个小段进行哈希运算,得到一个64位的哈希值,这个哈希值的计算过程比较复杂,涉及到多个位运算和混合操作以保证输出的哈希值具有良好的随机性和均匀性。
3.哈希混合:将每个小段的哈希值进行一系列的位运算和混合操作以保证最终的哈希值能够充分地利用输入字符串的信息,并且尽量避免冲突。
4.哈希合并:将所有小段的哈希值进行合并,得到最终的64位哈希值。合并的过程主要通过位运算和异或操作来完成,以确保合并后的哈希值能够充分地利用每个小段的哈希值。
通过以上的步骤,CityHash能够将任意长度的字符串映射为一个唯一的 64 位哈希值,从而实现对字符串的快速哈希运算。与其他哈希函数相比,CityHash在哈希速度和哈希质量方面都有很好的表现。
该四个算法用于将元素值标记形成标记值,由于数据仅在一个算法下标记时,与其他元素值碰撞的概率太大,则需要使用多个算法进行标记。
例如元素值B经过一个算法标记后,出现的标记值为012,有可能其他元素值经过该算法后也出现012,但是这两个元素值不相同。但是如果采用多个算法进行标记,一个元素值B经过位偏移标记算法标记后得到012,经过位操作运算算法标记后得到123,在经过其他算法后,得到其他值,多个标记值进行标记后,两个元素值碰撞的概率极大的降低。
但是由于算法个数的增加,会导致运算速度降低,在保证碰撞概率降低的前提下,又要加快运算时间,所以需要判断,使用几个算法。
需要根据元素值的个数n以及位数组的长度m来确定使用算法的个数,假设一个标记摘要算法需要使用的算法个数为k,则依次从四个算法中,使用k个算法,完成后续的标记。
其中,标记摘要算法函数个数 k,具体为:
。
第三步,为保证预留的位数组的长度准确无误,需要利用n个元素值以及k个标记摘要算法函数反推检查位数组长度m是否正确,具体为:
;
将n为元素值个数,P为人为设定的预期误判率以及标记摘要算法函数个数 k带入公式,得到m值,如果该m值与步骤2中的m值相同,则进行下一步,如果不相同,则返回第一步,重新计算m值。
第四步,利用k个标记摘要算法函数将每个元素值均标记至位数组中,具体的:
位数组中的位都有对应的二进制值,一个元素值经过k个标记摘要算法函数形成k个标记,该标记也为二进制值,n个元素值经过k个标记摘要算法函数形成n*k个标记,将n*k个标记值利用一一对应的方式映射至m个位中;
每一个标记值映射到一个位数组中的位,位数组中的位有对应标记值映射后变为1,未被映射的为0,变为1的位组成标记组,其余位数组中未标记部位形成空白组。
第五步,判断是否能标记至位数组中的标记组,决定外输入元素值是否有权限,具体为:
在初始化的数据范围外选取一个元素值A,利用相同的k个标记摘要算法函数进行标记,形成k个标记值,映射至位数组中,如k个标记值均映射在位数组中标记组内,则数据值A有权限;否则,没有权限。
实施例2,
参照图2,预设一组数据的元素值n为10亿,预期的误判率为0.00001,带入m值计算公式,
利用m值以及n值计算需要的k值:k=
反推检查m值是否正确,0.00001=
使用3个标记摘要算法函数对10亿个元素值进行标记,形成30亿个标记值,该30亿个标记值映射至位数组中对应的位上,有标记值的位变为1,没有标记值的为0。
判断新元素值是否具有权限,则选取一个新元素d,将新元素经过3个标记摘要算法函数标记后,形成三个标记值,与位数组中的位进行对比,如果全部的标记值都在位为1的位置,则有该项权限,如果有任意一个对应在0上,则没有权限。
实施例3
一种基于超大数据量的数据权限计算与碰撞系统,包括:
初始化模块,被配置为,初始化一组数据,预制位数组以及标记摘要算法函数;
核检判断模块,被配置为,利用n个元素值以及k个标记摘要算法函数反推检查位数组长度m是否正确;
标记模块,被配置为,利用k个标记摘要算法函数将每个元素值均标记至位数组中,形成标记组,其余位数组中未标记部位形成空白组;
权限判别模块,被配置为,判输入数据以外的元素值A,判断元素值A是否能标记至位数组中的标记组,输出结果。
实施例4
一种计算机可读存储介质,其中存储有多条指令,所述指令适于由终端设备的处理器加载并执行如权利要求1所述的一种基于超大数据量的数据权限计算与碰撞方法。
实施例5
一种终端设备,包括处理器和计算机可读存储介质,处理器用于实现各指令;计算机可读存储介质用于存储多条指令,所述指令适于由处理器加载并执行一种基于超大数据量的数据权限计算与碰撞方法。
以上均为本发明的较佳实施例,并非依此限制本发明的保护范围,故:凡依本发明的结构、形状、原理所做的等效变化,均应涵盖于本发明的保护范围之内。