基于航天软件缺陷数据集类不平衡的对抗验证方法及装置
文献发布时间:2023-06-19 09:57:26
技术领域
本发明涉及软件缺陷预测技术领域,特别是一种基于航天软件缺陷数据集类不平衡的对抗验证方法及装置。
背景技术
选择合适的学习算法进行适当的训练是基于机器学习的软件缺陷预测的核心。为了能够对建立的预测模型进行性能分析,往往会将历史数据划分为训练集和验证集两部分,其中测试集和验证集中的样本不重叠。为了使历史数据中所有的样本都能够得到检验,训练集和验证集的划分会重复多次进行,以对预测模型进行有效的测试,常用的划分方法为M×N交叉验证法。
在航天嵌入式软件缺陷预测真实的业务场景中,由于数据集采样和缺陷数据集分布规律的原因导致训练集和工程实践测试集存在分布不一致的情况,这时候交叉验证的方法无法准确的评估模型在工程实践测试集上的效果,模型在工程实践测试集上的效果远低于训练集。样本分布变化主要体现在训练集和工程实践测试集的数据分布存在差异,例如函数度量的非循环路径数目、基本圈复杂度、非重复操作符个数、广度优先调用层次、最大嵌套深度随着时间的变化,数据样本分布也发生了变化。
因此,更好的解决航天嵌入式软件缺陷预测工程实践测试集与训练集分布不一致的问题,提高软件缺陷预测的准确性,成为同行从业人员亟待解决的问题。
发明内容
本发明解决的技术问题是:克服现有技术的不足,提供了一种基于航天软件缺陷数据集类不平衡的对抗验证方法及装置。
为了解决上述技术问题,本发明实施例提供了一种基于航天软件缺陷数据集类不平衡的对抗验证方法,包括:
获取航天嵌入式软件对应的缺陷数据训练集和缺陷数据测试集;
合并所述缺陷数据训练集和所述缺陷数据测试集,生成合并数据集;
基于集成学习方法对所述合并数据集中的缺陷数据样本进行预测,确定所述缺陷数据样本对应的预测概率;
根据所述预测概率,对所述合并数据集中的缺陷数据样本进行升序排序,并从所述缺陷数据样本中筛选出设定比例的缺陷数据样本,得到所述航天嵌入式软件对应的验证数据样本。
可选地,在所需训练的模型为树模型时,所述缺陷数据训练集和所述缺陷数据测试集的度量元包括词汇数、词汇频率、语句平均复杂度、交点复杂度、非循环路径数目、可执行语句行数、代码行、非注释非空行、LCSAJ数目、最大LCSAJ密度、广度优先调用层次、深度优先调用层次、非重复操作符个数、基本圈复杂度和McCabe复杂度;
在所需训练的模型为神经网络模型时,所述缺陷数据训练集和所述缺陷数据测试集的度量元包括代码行数、空白行数、可执行行数、注释行数、路径数、基本圈复杂度和最大嵌套深度;
所述缺陷数据训练集和所述缺陷数据测试集类不平衡软件缺陷率的范围为[0.41%,9.50%]。
可选地,所述基于集成学习方法对所述合并数据集中的缺陷数据样本进行预测,确定所述缺陷数据样本对应的预测概率,包括:
基于LightGBM、XGBoost和Neural Network集成学习方法对所述合并数据集中的缺陷数据样本进行预测,以得到所述缺陷样本数据的预测概率。
可选地,所述基于LightGBM、XGBoost和Neural Network集成学习方法对所述合并数据集中的缺陷数据样本进行预测,以得到所述缺陷样本数据的预测概率,包括:
基于LightGBM、XGBoost和Neural Network调用机器学习算法库,通过特征工程、模型调参、模型融合,对所述合并数据集中的缺陷数据样本进行预测,得到所述缺陷样本数据的预测概率。
可选地,所述根据所述预测概率,对所述合并数据集中的缺陷数据样本进行升序排序,并从所述缺陷数据样本中筛选出设定比例的缺陷数据样本,得到所述航天嵌入式软件对应的验证数据样本,包括:
根据所述预测概率,对所述合并数据集中的缺陷数据样本进行升序排序,得到排序缺陷数据样本;
从所述排序缺陷数据样本中筛选出排序靠后的15%的缺陷数据样本,作为所述验证数据样本。
为了解决上述技术问题,本发明实施例还提供了一种基于航天软件缺陷数据集类不平衡的对抗验证装置,包括:
缺陷数据集获取模块,用于获取航天嵌入式软件对应的缺陷数据训练集和缺陷数据测试集;
合并数据集生成模块,用于合并所述缺陷数据训练集和所述缺陷数据测试集,生成合并数据集;
样本预测概率确定模块,用于基于集成学习方法对所述合并数据集中的缺陷数据样本进行预测,确定所述缺陷数据样本对应的预测概率;
验证数据样本获取模块,用于根据所述预测概率,对所述合并数据集中的缺陷数据样本进行升序排序,并从所述缺陷数据样本中筛选出设定比例的缺陷数据样本,得到所述航天嵌入式软件对应的验证数据样本。
可选地,在所需训练的模型为树模型时,所述缺陷数据训练集和所述缺陷数据测试集的度量元包括词汇数、词汇频率、语句平均复杂度、交点复杂度、非循环路径数目、可执行语句行数、代码行、非注释非空行、LCSAJ数目、最大LCSAJ密度、广度优先调用层次、深度优先调用层次、非重复操作符个数、基本圈复杂度和McCabe复杂度;
在所需训练的模型为神经网络模型时,所述缺陷数据训练集和所述缺陷数据测试集的度量元包括代码行数、空白行数、可执行行数、注释行数、路径数、基本圈复杂度和最大嵌套深度;
所述缺陷数据训练集和所述缺陷数据测试集类不平衡软件缺陷率的范围为[0.41%,9.50%]。
可选地,所述样本预测概率确定模块包括:
样本预测概率获取单元,用于基于LightGBM、XGBoost和Neural Network集成学习方法对所述合并数据集中的缺陷数据样本进行预测,以得到所述缺陷样本数据的预测概率。
可选地,所述样本预测概率获取单元包括:
预测概率获取单元,用于基于LightGBM、XGBoost和Neural Network调用机器学习算法库,通过特征工程、模型调参、模型融合,对所述合并数据集中的缺陷数据样本进行预测,得到所述缺陷样本数据的预测概率。
可选地,所述验证数据样本获取模块包括:
排序数据样本获取单元,用于根据所述预测概率,对所述合并数据集中的缺陷数据样本进行升序排序,得到排序缺陷数据样本;
验证数据样本获取单元,用于从所述排序缺陷数据样本中筛选出排序靠后的15%的缺陷数据样本,作为所述验证数据样本。
本发明与现有技术相比的优点在于:
本发明实施例提供的基于航天软件缺陷数据集类不平衡的对抗验证方法及装置,通过不同的特征工程、不同的结构模型防止了训练过程过拟合和欠拟合。通过模型调参、模型融合、对抗验证的方法揭示了航天嵌入式软件缺陷数据训练集与测试集分布一致性,在航天软件工程实践中提供了切实可行的缺陷数据集的对抗验证方法。本发明解决了航天嵌入式软件缺陷预测工程实践测试集与训练集分布不一致的问题。
附图说明
图1为本发明实施例提供的一种基于航天软件缺陷数据集类不平衡的对抗验证方法的步骤流程图;
图2为本发明实施例提供的一种基于航天软件缺陷数据集类不平衡的对抗验证装置的结构示意图。
具体实施方式
实施例一
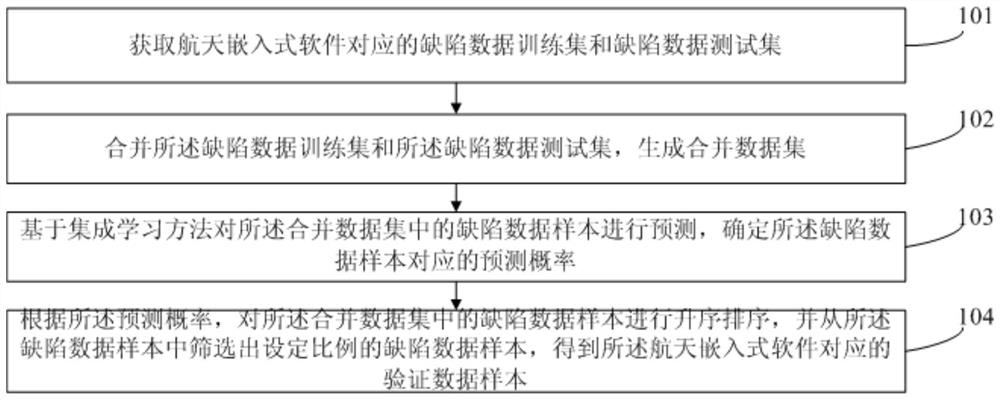
参照图1,示出了本发明实施例提供的一种基于航天软件缺陷数据集类不平衡的对抗验证方法的步骤流程图,如图1所示,该基于航天软件缺陷数据集类不平衡的对抗验证方法具体可以包括如下步骤:
步骤101:获取航天嵌入式软件对应的缺陷数据训练集和缺陷数据测试集。
在本发明实施例中,在所需训练的模型为树模型时,缺陷数据训练集和缺陷数据测试集的度量元包括词汇数、词汇频率、语句平均复杂度、交点复杂度、非循环路径数目、可执行语句行数、代码行、非注释非空行、LCSAJ数目、最大LCSAJ密度、广度优先调用层次、深度优先调用层次、非重复操作符个数、基本圈复杂度和McCabe复杂度等。
在所需训练的模型为神经网络模型时,缺陷数据训练集和缺陷数据测试集的度量元包括代码行数、空白行数、可执行行数、注释行数、路径数、基本圈复杂度和最大嵌套深度等。
缺陷数据训练集和缺陷数据测试集类不平衡软件缺陷率的范围为[0.41%,9.50%]。
在需要进行验证数据样本的筛选时,可以根据需要训练的模型获取对应的缺陷数据训练集和缺陷数据测试集,进而,执行步骤102。
步骤102:合并所述缺陷数据训练集和所述缺陷数据测试集,生成合并数据集。
在获取到缺陷数据训练集和缺陷数据测试集之后,可以合并缺陷数据训练集和缺陷数据测试集,以得到合并数据集,具体地,可以将缺陷数据训练集中的训练数据样本和缺陷数据测试集中的测试数据样本进行合并,以得到一个数据集,即合并数据集,在得到合并数据集之后,可以对合并数据集中的训练数据样本和测试数据样本进行标记,具体地,航天嵌入式软件缺陷数据训练集最后1列赋值新标签为Label_Tr_Te为0,航天嵌入式软件缺陷数据测试集最后1列赋值新标签为Label_Tr_Te为1,对航天嵌入式软件缺陷数据进行数据探索性分析。
在合并缺陷数据训练集和缺陷数据测试集生成合并数据集之后,执行步骤103。
步骤103:基于集成学习方法对所述合并数据集中的缺陷数据样本进行预测,确定所述缺陷数据样本对应的预测概率。
在生成合并数据集之后,可以基于集成学习方法对合并数据集中的缺陷数据样本进行预测,以确定缺陷数据样本对应的预测概率,具体地,可以基于LightGBM、XGBoost和Neural Network集成学习方法对所述合并数据集中的缺陷数据样本进行预测,以得到所述缺陷样本数据的预测概率。
在本发明实施例中,可以调用import lightgbm as lgb、import xgboost asxgb、import tensorflow as tf机器学习算法库,通过特征工程、模型调参、模型融合,对新标签Label_Tr_Te进行预测,得到航天嵌入式软件缺陷数据训练集的样本概率。
在本实施例中,LightGBM、XGBoost、Neural Network集成学习方法,构建步骤包括:
1、LightGBM和XGBoost都是树模型,训练收敛速度非常快;调整正则化系数防止过拟合;调整早停轮数,防止陷入过拟合或欠拟合。
2、设计一个十层的神经网络,全连接层的节点个数分别为16384、8192、4096、2048、1024、512、256、128、64、1。调整正则化系数,使用正则化防止过拟合;调整学习率,选择学习率下降的时机进行调整。选择梯度下降的优化器为Adam,具备计算高效,对内存需求少优点。
3、模型融合采用两层次Stacking和加权平均集成学习。由于两个树模型的训练数据一样并且结构相似,对两个树模型进行Stacking。树模型和神经网络模型是完全不同的架构,预测值差异较大,将树模型和神经网络模型加权平均效果更好,加权平均选择系数各为0.5。
采用LightGBM和XGBoost树模型,对输入的91个特征,按照重要度的相关性排序。训练收敛速度快,可以处理缺失值,计算取值的增益,择优录取,调整正则化系数,均使用正则化,防止过拟合;降低学习率,获得更小MAE的预测输出;调整早停轮数,防止陷入过拟合或欠拟合;
采用神经网络模型,通过设置model=tf.keras.Sequential()序贯模型,设置10层tf.keras.layers.Dense全连接网络,激活函数采用relu。对输入的32个特征按照重要度的相关性排序。训练使用小batchsize,虽然在下降方向上可能会出现小偏差,但是对收敛速度的收益大,2000代以内可以收敛。调整正则化系数,使用正则化,防止过拟合;调整学习率,对训练过程的误差进行分析,选择学习率下降的时机进行调整。
模型融合:由于两个树模型的训练数据一样且结构相似,首先对两个数模型进行Stacking,然后再与神经网络的输出进行加权平均。由于树模型和神经网络模型是完全不同的架构,得到的评价分数输出相近,预测值差异较大,因此加权平均选择系数为0.5,虽然神经网络模型的评价分数确实会比树模型高一些,但多组最优输出的结合,可以互相弥补优势。
在基于集成学习方法对所述合并数据集中的缺陷数据样本进行预测,确定所述缺陷数据样本对应的预测概率之后,执行步骤104。
步骤104:根据所述预测概率,对所述合并数据集中的缺陷数据样本进行升序排序,并从所述缺陷数据样本中筛选出设定比例的缺陷数据样本,得到所述航天嵌入式软件对应的验证数据样本。
在确定合并数据集中的缺陷数据样本对应的预测概率之后,可以根据预测概率,对合并数据集中的缺陷数据样本进行升序排序,并从缺陷数据样本筛选出设定比例的缺陷数据样本,具体地,可以根据预测概率对合并数据集中的缺陷数据样本进行升序排序,以得到排序缺陷数据样本(即升序排序的数据样本),然后,从排序缺陷数据样本中筛选出排序靠后的15%的缺陷数据样本,以作为验证数据样本。
在本实施例中,航天嵌入式软件缺陷数据训练集的样本概率按照升序排列,截取后15%的样本作为验证集,验证集的数据分布规律比较接近测试集的数据分布规律,可用于后续软件缺陷预测工程实践。
本发明设计一个高性能、深层次、全连接网络模型和LightGBM和XGBoost树模型,采用不同的特征工程、不同的结构模型防止了训练过程过拟合和欠拟合。通过模型调参、模型融合、对抗验证的方法揭示了航天嵌入式软件缺陷数据训练集与测试集分布一致性,在航天软件工程实践中提供了切实可行的缺陷数据集的对抗验证方法。
实施例二
参照图2,示出了本发明实施例提供的一种基于航天软件缺陷数据集类不平衡的对抗验证装置的结构示意图,如图2所示,该基于航天软件缺陷数据集类不平衡的对抗验证装置具体可以包括如下模块:
缺陷数据集获取模块210,用于获取航天嵌入式软件对应的缺陷数据训练集和缺陷数据测试集;
合并数据集生成模块220,用于合并所述缺陷数据训练集和所述缺陷数据测试集,生成合并数据集;
样本预测概率确定模块230,用于基于集成学习方法对所述合并数据集中的缺陷数据样本进行预测,确定所述缺陷数据样本对应的预测概率;
验证数据样本获取模块240,用于根据所述预测概率,对所述合并数据集中的缺陷数据样本进行升序排序,并从所述缺陷数据样本中筛选出设定比例的缺陷数据样本,得到所述航天嵌入式软件对应的验证数据样本。
可选地,在所需训练的模型为树模型时,所述缺陷数据训练集和所述缺陷数据测试集的度量元包括词汇数、词汇频率、语句平均复杂度、交点复杂度、非循环路径数目、可执行语句行数、代码行、非注释非空行、LCSAJ数目、最大LCSAJ密度、广度优先调用层次、深度优先调用层次、非重复操作符个数、基本圈复杂度和McCabe复杂度;
在所需训练的模型为神经网络模型时,所述缺陷数据训练集和所述缺陷数据测试集的度量元包括代码行数、空白行数、可执行行数、注释行数、路径数、基本圈复杂度和最大嵌套深度;
所述缺陷数据训练集和所述缺陷数据测试集类不平衡软件缺陷率的范围为[0.41%,9.50%]。
可选地,所述样本预测概率确定模块230包括:
样本预测概率获取单元,用于基于LightGBM、XGBoost和Neural Network集成学习方法对所述合并数据集中的缺陷数据样本进行预测,以得到所述缺陷样本数据的预测概率。
可选地,所述样本预测概率获取单元包括:
预测概率获取单元,用于基于LightGBM、XGBoost和Neural Network调用机器学习算法库,通过特征工程、模型调参、模型融合,对所述合并数据集中的缺陷数据样本进行预测,得到所述缺陷样本数据的预测概率。
可选地,所述验证数据样本获取模块包括:
排序数据样本获取单元,用于根据所述预测概率,对所述合并数据集中的缺陷数据样本进行升序排序,得到排序缺陷数据样本;
验证数据样本获取单元,用于从所述排序缺陷数据样本中筛选出排序靠后的15%的缺陷数据样本,作为所述验证数据样本。
以上实施例对本发明进行了详细说明,本发明专利说明书中未作详细描述的内容属于本领域专业技术人员的公知技术。对本发明的技术方法进行修改或者等同替换,都不脱离本发明技术方法的核心思想和范围,其均应涵盖在本发明的权利要求范围当中。
- 基于航天软件缺陷数据集类不平衡的对抗验证方法及装置
- 一种不平衡数据集下基于多数类转化为少数类的分类方法